


YOLOv1学习:(二)损失函数理解和实现
损失函数形式


损失函数理解1
- 预测框的中心点(x, y) 造成的损失(即对损失函数有贡献)是图中的第一行。其中$||_{ij}^{obj}$为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。
- 预测框的高度(w, h)造成的损失(即对损失函数有贡献)是图中的第二行。其中 $||_{ij}^{obj}$为控制函数,含义与预测中心一样。1、2项就是边框回归。
- 第三行与第四行,都是预测框的置信度C。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积)。其中第三行函数的$||_{ij}^{obj}$依然为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。第四行的$||_{ij}^{obj}$也控制函数,只是含义与第三项的相反,在标签中不含物体的那些格点处,该值为1;若格点含有物体,该值为 0。也就是只对那些没有真实物体所属的格点进行损失计算,若该格点包含物体(包含物体置信度损失已经在第三项计算了)则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。
- 第五行为物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。其中此项$||_{ij}^{obj}$也为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行物体类别损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。
此时再来看${\lambda}_{coord}$ 与${\lambda}_{noobj}$ ,Yolo面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中49个格点,含有物体的格点往往只有3、4个,其余全是不含有物体的格点。此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。因此${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, ${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$ 的取值分别为5与0.5。
损失函数理解2-损失函数分为三个部分
$$ ||_{ij}^{obj}表示cell中是否含有真实物体的中心,含有则1,否则取0 $$
① 坐标误差
为什么宽和高要带根号???
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width
(主要为了平衡小目标检测预测的偏移)
② IOU误差
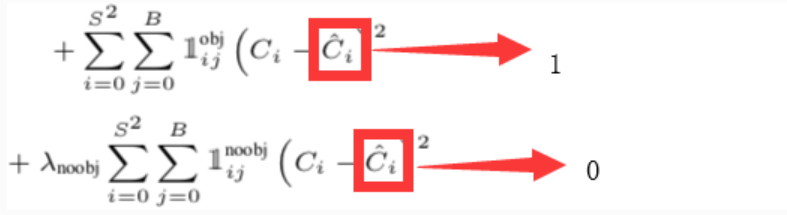
这里的$\hat{C_i}$分别表示 1 和 0 $,C_i=Pr(Object)*IOU_{pred}^{truth}$
③ 分类误差
这个很容易理解(激活函数的输出)。
损失函数代码实现
实现
"""
+ input
+ pred: (batch_size,30,7,7)的网络输出数据
+ labels: (batch_size,30,7,7)的样本标签数据
+ output
+ 当前批次样本的平均损失
"""
"""
+ YOLOv1 的损失分为3部分
+ 坐标预测损失
+ 置信度预测损失
+ 含object的box的confidence预测损失
+ 不含object的box的confidence预测损失
+ 类别预测损失
"""
class Loss_YOLOv1(nn.Module):
def __init__(self,batch_size=1):
super(Loss_YOLOv1,self).__init__()
self.batch_size = batch_size
"""
box格式转换
+ input
+ src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h]
+ output
+ dst_box : [box_x1,box_y1,box_x2,box_y2]
"""
def convert_box_type(self,src_box):
x,y,w,h = tuple(src_box)
x1,y1 = x,y
x2,y2 = x+w,y+w
return [x1,y1,x2,y2]
"""
iou计算
"""
def cal_iou(self,box1,box2):
# 求相交区域左上角的坐标和右下角的坐标
box_intersect_x1 = max(box1[0], box2[0])
box_intersect_y1 = max(box1[1], box2[1])
box_intersect_x2 = min(box1[2], box2[2])
box_intersect_y2 = min(box1[3], box2[3])
# 求二者相交的面积
area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1)
# 求box1,box2的面积
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
# 求二者相并的面积
area_union = area_box1 + area_box2 - area_intersect
# 计算iou(交并比)
iou = area_intersect / area_union
return iou
def forward(self,pred,target):
lambda_noobj = 0.5 # lambda_noobj参数
lambda_coord = 5 # lambda_coord参数
site_pred_loss = 0 # 坐标预测损失
obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失
noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失
class_pred_loss = 0 # 类别预测损失
for batch_size_index in range(self.batch_size): # batchsize循环
for x_index in range(7): # x方向网格循环
for y_index in range(7): # y方向网格循环
# 获取单个网格的预测数据和真实数据
pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20]
true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20]
if true_data[4]==1:# 如果包含物体
# 解析预测数据和真实数据
pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1]
pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2]
true_box_confidence = true_data[0:5] # [x,y,w,h,confidence]
# 获取两个预测box并计算与真实box的iou
iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4]))
iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4]))
# 在两个box中选择iou大的box负责预测物体
if iou1 >= iou2:
better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2
better_iou,bad_iou = iou1,iou2
else:
better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1
better_iou,bad_iou = iou2,iou1
# 计算坐标预测损失
site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失
site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失
# 计算含object的box的confidence预测损失
obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中
# 因此还需计算不含object的box的confidence预测损失
noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2
# 计算类别损失
class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2)
else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss
# [4,9]代表取两个预测框的confidence
noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2)
loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss
return loss/self.batch_size调用测试
label1 = torch.rand([1,30,7,7])
label2 = torch.rand([1,30,7,7])
print(label1.shape,label2.shape)
print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7])
tensor(14.6910)参考资料
- YOLO V1损失函数理解:http://www.likecs.com/show-65912.html
- YOLOv1算法理解:https://www.cnblogs.com/ywheunji/p/10808989.html
- 【目标检测系列】yolov1的损失函数详解(结合pytorch代码):https://blog.csdn.net/gbz3300255/article/details/109179751
- yolo-yolo v1损失函数理解:https://blog.csdn.net/qq_38236744/article/details/106724596
评论 (0)