搜索到
30
篇与
的结果
-
 python-opencv限制图片长宽实现图片压缩 1.业务背景图片压缩前的预处理,适配手机端图片大小显示且尽可能的减少图片存储空间的占用。通过限制图片的最大宽度和最大高度来减少图片的大小。2.核心代码import cv2 import os import shutil import math def img_compress_by_openCV(img_path_local,img_size_thresh = 300,max_height=2560,max_width=1440): # 压缩前图片大小 img_src_size = os.path.getsize(img_path_local)/1024 # 压缩后图片保存地址 img_path_compress = "./images/opencvs_"+img_path_local.split("/")[-1] # 若压缩前图片大小已经大小阈值img_size_thresh则跳过压缩 if(img_src_size<img_size_thresh): print("图片大小小于"+str(img_size_thresh)+"KB,跳过压缩"); shutil.copyfile(img_path_local,img_path_compress) else: print("openCV压缩前图片大小:"+str(int(img_src_size))+"KB") # 计算压缩比 img = cv2.imread(img_path_local) heigh, width = img.shape[:2] print("openCV压缩前图片尺寸(heigh, width)=:("+str(int(heigh))+","+str(int(width))+")") compress_rate = min(max_height/heigh,max_width/width,1) # 调用openCV进行图片压缩 img_compress = cv2.resize(img, (int(heigh*compress_rate), int(width*compress_rate)),interpolation=cv2.INTER_AREA) # 双三次插值 cv2.imwrite(img_path_compress, img_compress) # 压缩后图片大小 img_compress_size = os.path.getsize(img_path_compress)/1024 print("openCV压缩后图片大小:"+str(int(img_compress_size))+"KB") print("openCV压缩前图片尺寸(heigh, width)=:("+str(heigh*compress_rate)+","+str(int(width*compress_rate))+")") return img_path_compress img_path_local = "./images/1684155324391.jpg" img_path_compress = img_compress_by_openCV(img_path_local)运行结果openCV压缩前图片大小:2219KB openCV压缩前图片尺寸(heigh, width)=:(4000,3000) openCV压缩后图片大小:469KB openCV压缩前图片尺寸(heigh, width)=:(1920.0,1440)
python-opencv限制图片长宽实现图片压缩 1.业务背景图片压缩前的预处理,适配手机端图片大小显示且尽可能的减少图片存储空间的占用。通过限制图片的最大宽度和最大高度来减少图片的大小。2.核心代码import cv2 import os import shutil import math def img_compress_by_openCV(img_path_local,img_size_thresh = 300,max_height=2560,max_width=1440): # 压缩前图片大小 img_src_size = os.path.getsize(img_path_local)/1024 # 压缩后图片保存地址 img_path_compress = "./images/opencvs_"+img_path_local.split("/")[-1] # 若压缩前图片大小已经大小阈值img_size_thresh则跳过压缩 if(img_src_size<img_size_thresh): print("图片大小小于"+str(img_size_thresh)+"KB,跳过压缩"); shutil.copyfile(img_path_local,img_path_compress) else: print("openCV压缩前图片大小:"+str(int(img_src_size))+"KB") # 计算压缩比 img = cv2.imread(img_path_local) heigh, width = img.shape[:2] print("openCV压缩前图片尺寸(heigh, width)=:("+str(int(heigh))+","+str(int(width))+")") compress_rate = min(max_height/heigh,max_width/width,1) # 调用openCV进行图片压缩 img_compress = cv2.resize(img, (int(heigh*compress_rate), int(width*compress_rate)),interpolation=cv2.INTER_AREA) # 双三次插值 cv2.imwrite(img_path_compress, img_compress) # 压缩后图片大小 img_compress_size = os.path.getsize(img_path_compress)/1024 print("openCV压缩后图片大小:"+str(int(img_compress_size))+"KB") print("openCV压缩前图片尺寸(heigh, width)=:("+str(heigh*compress_rate)+","+str(int(width*compress_rate))+")") return img_path_compress img_path_local = "./images/1684155324391.jpg" img_path_compress = img_compress_by_openCV(img_path_local)运行结果openCV压缩前图片大小:2219KB openCV压缩前图片尺寸(heigh, width)=:(4000,3000) openCV压缩后图片大小:469KB openCV压缩前图片尺寸(heigh, width)=:(1920.0,1440) -
python调用TinyPNG进行图片无损压缩 1.TinyPNG介绍TinyPNG是一种在线图片压缩工具,可以将图片压缩到更小的文件大小,而且不会对图片质量造成明显的影响。其实现原理主要是基于两个方面:压缩算法和颜色减少。压缩算法TinyPNG使用的是一种叫做Deflate的压缩算法。Deflate算法是一种无损压缩算法,可以将图片的二进制数据进行压缩,从而减小图片文件的大小。在Deflate算法中,压缩的主要思想是利用重复的数据进行替换,从而减小文件的大小。具体来说,Deflate算法主要包括两个步骤:压缩和解压缩。在压缩过程中,数据被分成多个块,并且每个块都有自己的压缩字典。在解压缩过程中,压缩字典用于还原压缩后的数据。2. 颜色减少另一个TinyPNG使用的技术是颜色减少。颜色减少是一种通过减少图片中使用的颜色数来减小文件大小的技术。在实践中,很多图片中使用的颜色实际上是不必要的,因此可以通过将这些颜色删除来减小文件的大小。具体来说,TinyPNG会先对图片进行一个预处理,找出图片中使用频率最低的颜色,并将其替换成使用频率更高的颜色。这个过程是基于一个叫做K-means的算法实现的。K-means算法是一种基于聚类的算法,可以将图片中使用的颜色分成多个聚类,从而找出使用频率最低的颜色。2.python调用TinyPNG API进行图片压缩安装依赖pip install tinify核心代码import tinify import os import shutil def img_compress_by_tinify(img_path_local,img_size_thresh = 200): if not os.path.exists("./images"): os.makedirs("./images") # 压缩前图片大小 img_src_size = os.path.getsize(img_path_local)/1024 # 压缩后图片保存地址 img_path_compress = "./images/compress_"+img_path_local.split("/")[-1] # 若压缩前图片大小已经大小阈值img_size_thresh则跳过压缩 if(img_src_size<img_size_thresh): print("图片大小小于"+str(img_size_thresh)+"KB,跳过压缩"); shutil.copyfile(img_path_local,img_path_compress) else: print("压缩前图片大小:"+str(int(img_src_size))+"KB") # 调用tinyPNG进行图片压缩 tinify.key = "V02hTQyPz4WRXPyCChGv6nJJTZYVtzcd" source = tinify.from_file(img_path_local) source.to_file(img_path_compress) # 压缩后图片大小 img_compress_size = os.path.getsize(img_path_compress)/1024 print("压缩后图片大小:"+str(int(img_compress_size))+"KB") return img_path_compress img_path_local = "./images/1684153992017.jpg" img_path_compress = img_compress_by_tinify(img_path_local) print(img_path_compress)调用结果压缩前图片大小:693KB 压缩后图片大小:148KB ./images/compress_1684153992017.jpg
-
python上传文件到阿里云oss 安装依赖包pip install oss2核心代码import oss2 access_key_id = 'LTA*******************' access_key_secret = 'ZAx*******************************' bucket_name = 'caucshop' endpoint = 'oss-cn-beijing.aliyuncs.com' # 创建bucket对象 bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name) # 待上传的文件路径 file_path_local = "./Snipaste_2023-05-13_18-54-02.jpg" # 上传到oss后保保存的路径 file_path_oss = "goodImgsCompresss/"+file_path_local.split("/")[-1] # 读取文件 with open(file_path_local, "rb") as f: data = f.read() # 上传文件 bucket.put_object(file_path_oss, data) # 获取文件的url file_url_oss = "https://"+bucket_name+"."+endpoint+"/"+file_path_oss; print(file_url_oss)执行结果,得到文件在oss中的存储地址,我这里采用的是公共读的权限https://caucshop.oss-cn-beijing.aliyuncs.com/goodImgsCompresss/Snipaste_2023-05-13_18-54-02.jpg参考资料【python】 文件/图片上传 阿里云OSS ,获取外网链接 实例_oss图片外链_维玉的博客-CSDN博客
-
python文字转语音(可保存为mp3) 1.pyttsx3模块(亲测可用)这是一款优秀的文字转语音的模块,它生成的音频文件也比较具有个性化。可以调整声音的音量,频率,变声,当然设置方法都差不多,都是先拿到它对应功能的值然后在进行加减。下载pyttsx3模块pip install pyttsx3调用import pyttsx3 # 初始化 engine = pyttsx3.init(); # 设置个性化参数 engine.setProperty('rate',150) #调整语速 engine.setProperty('volume',2.0) #调整音量 voices = engine.getProperty('voices'); engine.setProperty('voice',voices[0].id); mp3_save_path = "./test.mp3" text="西游记" # 使用引擎进行渲染,亲测不能省略这一步,省略了就保存的文件为空 engine.say(text); engine.runAndWait(); #播放音频 # 保存到文件 engine.save_to_file(text,mp3_save_path);2.gtts模快(亲测没跑通)安装pip install gtts使用from gtts import gTTS mp3_save_path = "./test.mp3" text="西游记" # text:音频内容 # lang: 音频语言 tts = gTTS(text=text, lang='zh-tw') tts.save(mp3_save_path)
-
Selenium:Python爬虫进阶 1.简介1.1 什么是Selenium?官网: Selenium是一个用于Web应用程序测试的工具。真实:大量用于网络爬虫,相比requests爬虫,完全模拟真人使用浏览器的流程,对于动态JS加载的网页更容易爬取1.2 Selenium的功能框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。可用于较难的爬虫:动态JS加载、登录验证、表单提交等使用简单,可使用Python、Java等多种语言编写用例脚本。1.3 为什么要学习Selenium?requests爬虫局限性较大,分析困难、被封禁概率高可用于较难的爬虫伪装成真实的浏览器,被封禁的概率更低动态JS加载登录验证表单提交等1.4 Selenium的缺点相比requests,性能比较差,爬取的慢1.5 Selenium运行框架2.Selenium环境搭建1.电脑安装谷歌Chrome浏览器(其他浏览器不推荐)需要看一下当前的Chrome版本号,下载对应ChromeDriver2.下载安装 ChromeDriverhttps://www.selenium.dev/documentation/getting_started/installing_browser_drivers/windowns 放到C:\WebDriver\bin目录,这个目录加入系统PATH3.Python安装selenium库pip install selenium3.Selenium实战案例3.1 爬取电影天堂的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 3); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://www.dy10000.com/wplay/68599-2-{}.html" # 生成下载脚本 for i in range(42,48): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') script_all = soup.body.find_all("script") for script in script_all: m3u8_search = re.search(r"http.*?m3u8", str(script)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break # 退出浏览器 browser.quit()ffmpeg -i https://new.iskcd.com/20220518/FhKxDhXk/index.m3u8 -c copy -bsf:a aac_adtstoasc 42.mp4 ffmpeg -i https://new.iskcd.com/20220518/2MSrEhUz/index.m3u8 -c copy -bsf:a aac_adtstoasc 43.mp4 ffmpeg -i https://new.iskcd.com/20220519/7o5nJxJ3/index.m3u8 -c copy -bsf:a aac_adtstoasc 44.mp4 ffmpeg -i https://new.iskcd.com/20220519/BB2x9BaG/index.m3u8 -c copy -bsf:a aac_adtstoasc 45.mp4 ffmpeg -i https://new.iskcd.com/20220520/AxB2XF4T/index.m3u8 -c copy -bsf:a aac_adtstoasc 46.mp43.2 爬取电影先生的视频真实下载地址用到selenium加载页面渲染出m3u8文件的地址from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from bs4 import BeautifulSoup import re # 实例化一个浏览器对象(传入浏览器的驱动程序) 通过Options实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') # 不显示浏览器在后台运行 chrome_service = Service("chromedriver.exe"); browser = webdriver.Chrome(service=chrome_service,options=chrome_options) # 封装通过selenium获取html的方法 def get_html_by_selenium(url): # 对url发起请求 browser.get(url) # 等待页面加载完成 wait = WebDriverWait(browser, 5); # 获取页面源代码 page_html = browser.page_source return page_html # 电视剧页面地址_base base_url = "https://dyxs15.com/paly-222156-5-{}/" # 生成下载脚本 for i in range(15,41): url = base_url.format(i) html = get_html_by_selenium(url) soup = BeautifulSoup(html, features='lxml') td_all = soup.body.find_all("td") for td in td_all: m3u8_search = re.search(r"http.*?m3u8", str(td)) if m3u8_search: url_m3u8 = m3u8_search.group(0).replace("\\", "") print("ffmpeg -i ", url_m3u8, " -c copy -bsf:a aac_adtstoasc " + str(i) + ".mp4") break break # 退出浏览器 browser.quit()ffmpeg -i https://new.qqaku.com/20220526/t5C1cVna/index.m3u8 -c copy -bsf:a aac_adtstoasc 15.mp4 ······ ffmpeg -i https://new.qqaku.com/20220617/Wpf7uowm/index.m3u8 -c copy -bsf:a aac_adtstoasc 40.mp4参考资料https://www.bilibili.com/video/BV1WF411z7qB自动化爬虫selenium基础教程selenium如何不显示浏览器在后台运行Python selenium的这三种等待方式一定要会!
-
python 抓取豆瓣影视数据 python 抓取豆瓣影视数据1.代码import re douban_id = 6965622 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' } url = "https://movie.douban.com/subject/%s/" % douban_id html = requests.get(url=url,headers=headers) soup = BeautifulSoup(html.text) data = soup.find_all("script",{"type":"application/ld+json"})[0].string data = data.replace("\n"," ") data =eval(data) data_handle = {} data_handle["name"] = data["name"] data_handle["image"] = data["image"] director_str = "" for director in data["director"]: director_str += director["name"].split(" ")[0]+";" data_handle["director"] = director_str actor_str = "" for actor in data["actor"]: actor_str += actor["name"].split(" ")[0]+";" data_handle["actor"] = actor_str author_str = "" for author in data["author"]: author_str += author["name"].split(" ")[0]+";" data_handle["author"] = author_str genre_str = "" for genre in data["genre"]: genre_str += genre+";" data_handle["genre"] = genre_str data_handle["datePublished"] = data["datePublished"] data_handle["year"] = data["datePublished"].split("-")[0] data_handle["avg_score"] = data["aggregateRating"]["ratingValue"] data_handle["description"] = data["description"] if re.findall("<span class=\"pl\">又名:</span>(.*?)<br/>",html.text): data_handle["sub"] = re.findall("<span class=\"pl\">又名:</span>(.*?)<br/>",html.text)[0] if re.findall("<span class=\"pl\">语言:</span>(.*?)<br/>",html.text): data_handle["lang"] = re.findall("<span class=\"pl\">语言:</span>(.*?)<br/>",html.text)[0] if re.findall("<span class=\"pl\">集数:</span>(.*?)<br/>",html.text): data_handle["total"] = re.findall("<span class=\"pl\">集数:</span>(.*?)<br/>",html.text)[0] if re.findall("<span class=\"pl\">制片国家/地区:</span>(.*?)<br/>",html.text): data_handle["area"] = re.findall("<span class=\"pl\">制片国家/地区:</span>(.*?)<br/>",html.text)[0] print(data_handle)2.执行结果{ 'name': '悬崖', 'image': '/usr/uploads/auto_save_image/35191c14b33cceb1e4d4d49bb49781c8.jpg', 'director': '刘进;', 'actor': '张嘉益;宋佳;程煜;李洪涛;咏梅;姬他;孙浩;徐程;林源;林龙麒;马丽;杨一威;封柏;刘宸希;涩谷天马;林千雯;张东升;孙鹏;施琅;钱漪;王兴君;宋家腾;张瀚文;', 'author': '全勇先;', 'genre': '剧情;历史;战争;悬疑;', 'datePublished': '2012-01-01', 'year': '2012', 'avg_score': '8.5', 'description': '上世纪30年代末,古老的中华大地正经受着最为苦难的时刻。外有日寇铁蹄进犯,内有不同派别势力的斗争碾压,战火连绵,生灵涂炭。为了获取重要的情报,共产党方面派出周乙(张嘉译 饰)和顾秋妍(宋佳 饰)假扮夫...', 'sub': ' The Brink', 'lang': ' 汉语普通话', 'total': ' 40', 'area': ' 中国大陆' }
-
Python字符串处理:过滤字符串中的英文与符号,保留汉字 使用Python 的re模块,re模块提供了re.sub用于替换字符串中的匹配项。1 re.sub(pattern, repl, string, count=0) 参数说明:pattern:正则重的模式字符串repl:被拿来替换的字符串string:要被用于替换的原始字符串count:模式匹配后替换的最大次数,省略则默认为0,表示替换所有的匹配例如import re str = "hello,world!!%[545]你好234世界。。。" str = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", str) print(str) 输出结果:你好世界
-
python读写csv文件 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)1.读csv文件# coding:utf-8 import csv data_list = csv.reader(open('data.csv','r',encoding="utf8")) for data_item in data_list: print(data_item) 代码结果: ['测试1', '软件测试工程师'] ['测试2', '软件测试工程师'] ['测试3', '软件测试工程师'] ['测试4', '软件测试工程师'] ['测试5', '软件测试工程师']2.写入CSV文件# coding:utf-8 import csv data_list = [ ("测试1",'软件测试工程师'), ("测试2",'软件测试工程师'), ("测试3",'软件测试工程师'), ("测试4",'软件测试工程师'), ("测试5",'软件测试工程师'), ] f = open('data.csv','w',encoding="utf8") csv_writer = csv.writer(f) for data_item in data_list: csv_writer.writerow(data_item) f.close()参考资料python读写csv文件
-
tqdm:简单好用的python进度条 1.介绍Tqdm是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。安装方式如下:pip install tqdm2.简单使用2.1 用法一from tqdm import tqdm import time for i in tqdm(range(1000)): time.sleep(0.01) #do something100%|██████████| 1000/1000 [00:10<00:00, 95.17it/s]2.2 用法二from tqdm import trange import time for i in trange(100): time.sleep(0.01) #do something100%|██████████| 100/100 [00:01<00:00, 94.86it/s]2.3 用法三from tqdm import tqdm import timepython pbar = tqdm(total=100) for i in range(100): time.sleep(0.05) #do something pbar.update(1) pbar.close()100%|██████████| 100/100 [00:05<00:00, 19.35it/s2.4 用法四(具有前后缀描述功能)(推荐)from tqdm import tqdm import time import random pbar = tqdm(total=100) for i in range(100): time.sleep(0.05) #do something pbar.update(1) pbar.set_description("Epoch: %d" % 1) # 设置前缀 pbar.set_postfix({'loss':random.random()}) # 设置后缀 pbar.close()Epoch: 1: 100%|██████████| 100/100 [00:07<00:00, 14.28it/s, loss=0.709] 参考资料tqdm介绍及常用方法在tqdm中加入前缀和后缀详细介绍Python进度条tqdm的使用
-
Python通过opencv实现视频和图像互转 1.视频转图片import cv2 import numpy import math cap = cv2.VideoCapture("./帯広空港.mp4") vedio_frame_count = cap.get(7) # 获取视频总帧数 vedio_fps = math.ceil(cap.get(5)) # 获取视频帧率 frame_width = cap.get(3) # 获取视频帧宽度 frame_height = cap.get(4) # 获取视频帧高度 print(vedio_frame_count,vedio_fps) frame_id = 1 while(True): ret, frame = cap.read() if not ret or cv2.waitKey(30)==ord('q'): break; cv2.imshow("frame",frame) frame_id += 1 cap.release() cv2.destroyAllWindows()opencv参数列表0 CV_CAP_PROP_POS_MSEC Current position of the video file in milliseconds or video capture timestamp. 1 CV_CAP_PROP_POS_FRAMES 0-based index of the frame to be decoded/captured next. 2 CV_CAP_PROP_POS_AVI_RATIO Relative position of the video file: 0 - start of the film, 1 - end of the film. 3 CV_CAP_PROP_FRAME_WIDTH #视频帧宽度 4 CV_CAP_PROP_FRAME_HEIGHT #视频帧高度 5 CV_CAP_PROP_FPS #视频帧速率 6 CV_CAP_PROP_FOURCC 4-character code of codec. 7 CV_CAP_PROP_FRAME_COUNT #视频总帧数 8 CV_CAP_PROP_FORMAT Format of the Mat objects returned by retrieve() . 9 CV_CAP_PROP_MODE Backend-specific value indicating the current capture mode. 10 CV_CAP_PROP_BRIGHTNESS Brightness of the image (only for cameras). 11 CV_CAP_PROP_CONTRAST Contrast of the image (only for cameras). 12 CV_CAP_PROP_SATURATION Saturation of the image (only for cameras). 13 CV_CAP_PROP_HUE Hue of the image (only for cameras). 14 CV_CAP_PROP_GAIN Gain of the image (only for cameras). 15 CV_CAP_PROP_EXPOSURE Exposure (only for cameras). 16 CV_CAP_PROP_CONVERT_RGB Boolean flags indicating whether images should be converted to RGB. 17 CV_CAP_PROP_WHITE_BALANCE_U The U value of the whitebalance setting (note: only supported by DC1394 v 2.x backend currently) 18 CV_CAP_PROP_WHITE_BALANCE_V The V value of the whitebalance setting (note: only supported by DC1394 v 2.x backend currently) 19 CV_CAP_PROP_RECTIFICATION Rectification flag for stereo cameras (note: only supported by DC1394 v 2.x backend currently) 20 CV_CAP_PROP_ISO_SPEED The ISO speed of the camera (note: only supported by DC1394 v 2.x backend currently) 21 CV_CAP_PROP_BUFFERSIZE Amount of frames stored in internal buffer memory (note: only supported by DC1394 v 2.x backend currently)2.图片转视频# 图片转视频 import cv2 import os img_dir = "./data_handle/img/" # 必须保证图片是相同大小的,否则会转换失败 img_list = os.listdir(img_dir) frame_rate = 30 # 帧率 frame_shape = cv2.imread(os.path.join(img_dir,img_list[0])).shape[:-1] # 图片大小/帧shape frame_shape = (frame_shape[1],frame_shape[0]) # 交换w和h videoWriter = cv2.VideoWriter('result.mp4', cv2.VideoWriter_fourcc(*'MJPG'), frame_rate, frame_shape) # 初始化视频帧writer # 开始逐帧写入视频帧 frame_id = 1 for img_filename in img_list: img_path = os.path.join(img_dir,img_filename) img = cv2.imread(img_path) videoWriter.write(img) frame_id += 1 if frame_id%100 == 0: break videoWriter.release() 参考资料OpenCV|图片与视频的相互转换(C++&Python)python3 opencv获取视频的总帧数介绍
-
python使用opencv读取海康摄像头视频流rtsp pythons使用opencv读取海康摄像头视频流rtsp海康IPcamera rtsp地址和格式:rtsp://[username]:[password]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream 说明: username: 用户名。例如admin。 password: 密码。例如12345。 ip: 为设备IP。例如 192.0.0.64。 port: 端口号默认为554,若为默认可不填写。 codec:有h264、MPEG-4、mpeg4这几种。 channel: 通道号,起始为1。例如通道1,则为ch1。 subtype: 码流类型,主码流为main,辅码流为sub。python读取视频流import cv2 url = 'rtsp://admin:!itrb123@10.1.9.143:554/h264/ch1/main/av_stream' cap = cv2.VideoCapture(url) while(cap.isOpened()): # Capture frame-by-frame ret, frame = cap.read() # Display the resulting frame cv2.imshow('frame',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything done, release the capture cap.release() cv2.destroyAllWindows()
-
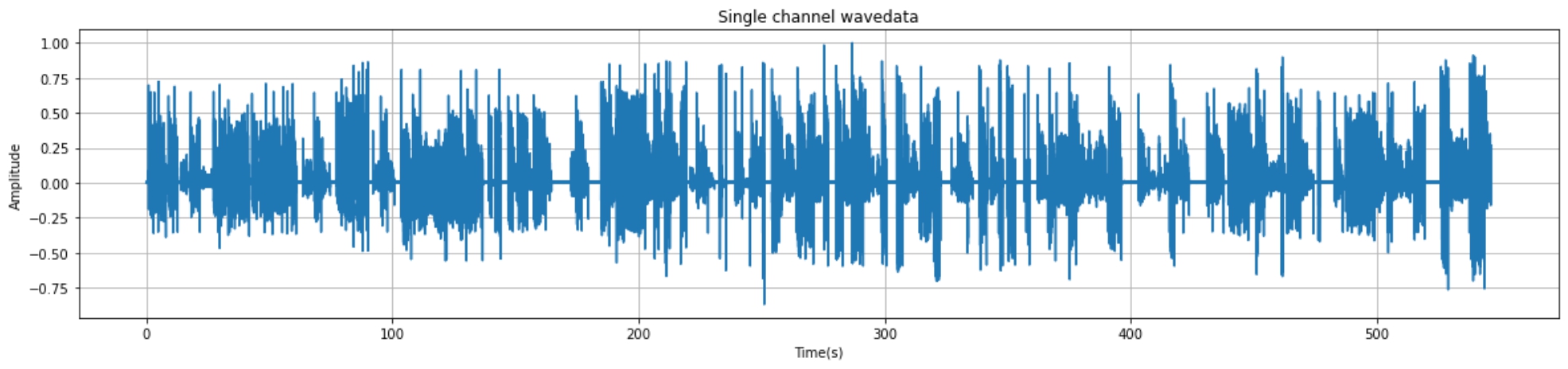
python实现音频读取与可视化+端点检测+音频切分 1.音频读取与可视化1.1 核心代码import wave import matplotlib.pyplot as plt import numpy as np import os filepath = "./audio/day0716_17.wav" f = wave.open(filepath,'rb') # 读取音频 params = f.getparams() # 查看音频的参数信息 print(params) # 可视化准备工作 strData = f.readframes(nframes)#读取音频,字符串格式 waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化 # 可视化 time = np.arange(0,nframes)*(1.0 / framerate) plt.figure(figsize=(20,4)) plt.plot(time,waveData) plt.xlabel("Time(s)") plt.ylabel("Amplitude") plt.title("Single channel wavedata") plt.grid('on')#标尺,on:有,off:无。1.2 实现效果_wave_params(nchannels=1, sampwidth=2, framerate=16000, nframes=8744750, comptype='NONE', compname='not compressed')2.端点检测2.1 环境准备pip install speechbrain2.2 核心代码from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") boundaries = VAD.get_speech_segments("./day0716_17.wav") print(boundaries)2.3 输出结果输出结果为包含语音数据的[开始时间,结束时间]区间序列tensor([[ 1.1100, 4.5700], [ 5.5600, 7.6100], [ 8.5800, 12.7800], ······ [508.7500, 519.0300], [526.0800, 537.1100], [538.0200, 546.5200]])3.pydub分割并保存音频3.1 核心代码from pydub import AudioSegment file_name = "denoise_0306.wav" sound = AudioSegment.from_mp3(file_name) # 单位:ms crop_audio = sound[1550:1900] save_name = "crop_"+file_name print(save_name) crop_audio.export(save_name, format="wav",tags={'artist': 'AppLeU0', 'album': save_name})4.汇总(仅供参考)汇总方式自行编写。以下案例为处理audio文件夹的的所有的wav结尾的文件从中提取出有声音的片段并进保存到相应的文件夹from pydub import AudioSegment import os from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") audio_dir = "./audio/" audio_name_list = os.listdir(audio_dir) for audio_name in audio_name_list: if not audio_name.endswith(".wav"): continue print(audio_name,"开始处理") audio_path = os.path.join(audio_dir,audio_name) word_save_dir = os.path.join(audio_dir,audio_name[:-4]) if not os.path.exists(word_save_dir): os.mkdir(word_save_dir) else: print(audio_name,"已经完成,跳过") continue boundaries = VAD.get_speech_segments(audio_path) sound = AudioSegment.from_mp3(audio_path) for boundary in boundaries: start_time = boundary[0] * 1000 end_time = boundary[1] * 1000 word = sound[start_time:end_time] word_save_path = os.path.join(word_save_dir,str(int(boundary[0]))+"-"+ str(int(boundary[1])) +".wav") word.export(word_save_path, format="wav") print("\r"+word_save_path,"保存成功",end="") print(audio_name,"处理完成")参考资料https://huggingface.co/speechbrain/vad-crdnn-libripartypydub分割并保存音频
-
python结合opencv调用谷歌tesseract-ocr实现印刷体的表格识别识别 环境搭建安装依赖-leptonica库下载源码git clone https://github.com/DanBloomberg/leptonica.gitconfiguresudo apt install automake bash autogen.sh ./configure编译安装make sudo make install这样就安装好了leptonica库谷歌tesseract-ocr编译安装下载源码git clone https://github.com/tesseract-ocr/tesseract.git tesseract-ocr安装依赖sudo apt-get install g++ autoconf automake libtool autoconf-archive pkg-config libpng12-dev libjpeg8-dev libtiff5-dev zlib1g-dev libleptonica-dev -y安装训练所需要的库(只是调用可以不用安装)sudo apt-get install libicu-dev libpango1.0-dev libcairo2-devconfigurebash autogen.sh ./configure编译安装make sudo make install # 可选项,不训练可以选择不执行下面两条 make training sudo make training-install sudo ldconfig安装对应的字体库并添加对应的环境变量下载好的语言包 放在/usr/local/share/tessdata目录里面。语言包地址:https://github.com/tesseract-ocr/tessdata_best。里面有各种语言包,都是训练好的语言包。简体中文下载:chi_sim.traineddata , chi_sim_vert.traineddata英文包:eng.traineddata。设置环境变量vim ~/.bashrc # 在.bashrc的文件末尾加入以下内容 export TESSDATA_PREFIX=/usr/local/share/tessdata source ~/.bashrc查看字体库tesseract --list-langs使用tesseract-ocr测试# 识别/home/app/1.png这张图片,内容输出到output.txt 里面,用chi_sim 中文来识别(不用加.traineddata,会默认加) tesseract /home/app/1.png output -l chi_sim # 查看识别结果 cat output.txt安装python调用依赖包pip install pytesseract配合opencv调用进行印刷体表格识别代码import cv2 import numpy as np import pytesseract import matplotlib.pyplot as plt import re #原图 raw = cv2.imread("table3.2.PNG") # 灰度图片 gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY) # 二值化 binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5) rows, cols = binary.shape # 识别横线 scale = 50 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_col = cv2.dilate(eroded, kernel, iterations=1) # 识别竖线 scale = 10 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_row = cv2.dilate(eroded, kernel, iterations=1) # 标识交点 bitwise_and = cv2.bitwise_and(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(bitwise_and,cmap="gray") # 标识表格 merge = cv2.add(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(merge,cmap="gray") # 两张图片进行减法运算,去掉表格框线 merge2 = cv2.subtract(binary, merge) plt.figure(dpi=300) # plt.imshow(merge2,cmap="gray") # 识别黑白图中的白色交叉点,将横纵坐标取出 ys, xs = np.where(bitwise_and > 0) # 提取单元格切分点 # 横坐标 x_point_arr = [] # 通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点 # 这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变) sort_x_point = np.sort(xs) for i in range(len(sort_x_point) - 1): if sort_x_point[i + 1] - sort_x_point[i] > 10: x_point_arr.append(sort_x_point[i]) i = i + 1 x_point_arr.append(sort_x_point[i]) # 要将最后一个点加入 # 纵坐标 y_point_arr = [] sort_y_point = np.sort(ys) for i in range(len(sort_y_point) - 1): if (sort_y_point[i + 1] - sort_y_point[i] > 10): y_point_arr.append(sort_y_point[i]) i = i + 1 # 要将最后一个点加入 y_point_arr.append(sort_y_point[i]) # 循环y坐标,x坐标分割表格 plt.figure(dpi=300) data = [[] for i in range(len(y_point_arr))] for i in range(len(y_point_arr) - 1): for j in range(len(x_point_arr) - 1): # 在分割时,第一个参数为y坐标,第二个参数为x坐标 cell = raw[y_point_arr[i]:y_point_arr[i + 1], x_point_arr[j]:x_point_arr[j + 1]] #读取文字,此为默认英文 text1 = pytesseract.image_to_string(cell, lang="chi_sim+eng") #去除特殊字符 text1 = re.findall(r'[^\*"/:?\\|<>″′‖ 〈\n]', text1, re.S) text1 = "".join(text1) print('单元格图片信息:' + text1) data[i].append(text1) plt.subplot(len(y_point_arr),len(x_point_arr),len(x_point_arr)*i+j+1) plt.imshow(cell) plt.axis('off') plt.tight_layout() plt.show()实现效果表格图片识别结果单元格图片信息:停机位Stands 单元格图片信息:空器避展限制Wingspanlimitsforaircraft(m) 单元格图片信息:Nr61.62.414-416.886.887.898,899.ZZ14 单元格图片信息:80 单元格图片信息:Nr101,102.105,212.219-222,228.417-419,874-876.895-897.910-912 单元格图片信息:65 单元格图片信息:NrZZ11 单元格图片信息:61 单元格图片信息:Nr103,104.106.107.109,117,890-894.ZL1,ZL2(deicingstands) 单元格图片信息:52 单元格图片信息:Nr878.879 单元格图片信息:51 单元格图片信息:Nr229.230 单元格图片信息:48 单元格图片信息:Nr877 单元格图片信息:42 单元格图片信息:Nr61R.62L 单元格图片信息:38.1 单元格图片信息:Nr61L.62R.108.110-116,118.201-211.213-218,223-227.409-413,414L.414R.415L.415R.416L,416R.417R.418R.419R.501-504.601-610,886L,886R.887L.887R.888.889.898L.898R.8991L.899R_901-909,910R.911R.912R.913-916.921-925.ZZ1IL.ZZ12.ZZ13 单元格图片信息:36 单元格图片信息:NrZZ11IR 单元格图片信息:32 单元格图片信息:Nr884.885 单元格图片信息:29(fuselagelength32.8) 单元格图片信息:Nr417L.418L.419L 单元格图片信息:24.9 单元格图片信息:Nr910L.911L.912L.931-946 单元格图片信息:24
-
使用python+opencv快速实现画风迁移效果 风格类型模型风格(翻译可能有误)candy糖果composition_vii康丁斯基的抽象派绘画风格feathers羽毛udnie乌迪妮la_muse缪斯mosaic镶嵌the_wave海浪starry_night星夜the_scream爱德华·蒙克创作绘画风格(呐喊)模型下载脚本BASE_URL="http://cs.stanford.edu/people/jcjohns/fast-neural-style/models/" mkdir -p models/instance_norm cd models/instance_norm curl -O "$BASE_URL/instance_norm/candy.t7" curl -O "$BASE_URL/instance_norm/la_muse.t7" curl -O "$BASE_URL/instance_norm/mosaic.t7" curl -O "$BASE_URL/instance_norm/feathers.t7" curl -O "$BASE_URL/instance_norm/the_scream.t7" curl -O "$BASE_URL/instance_norm/udnie.t7" mkdir -p ../eccv16 cd ../eccv16 curl -O "$BASE_URL/eccv16/the_wave.t7" curl -O "$BASE_URL/eccv16/starry_night.t7" curl -O "$BASE_URL/eccv16/la_muse.t7" curl -O "$BASE_URL/eccv16/composition_vii.t7" cd ../../代码调用import cv2 import matplotlib.pyplot as plt import os # 定义调用模型进行风格迁移的函数 def convert_img(model_path,img): # 加载模型 net = cv2.dnn.readNetFromTorch(model_path) net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) #设置后端 # 从图像中创建四维连通区域 w,h,_ = img.shape blob = cv2.dnn.blobFromImage(img,1.0,(h,w)) # 图片流经模型 net.setInput(blob) out = net.forward() # 模型输出修正 out = out.reshape(3,out.shape[2],out.shape[3]) out = out.transpose(1,2,0) out = out/255.0 return out # 读取图片 img = cv2.imread("./img/img2.jpg") # 调用模型进行风格迁移 out = convert_img("./model/feathers.t7",img) # 模型效果展示 plt.figure(dpi=200) plt.subplot(1,2,1) plt.title("origin") plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.subplot(1,2,2) plt.title("feathers") plt.imshow(cv2.cvtColor(out, cv2.COLOR_BGR2RGB)) plt.show()实现效果参考资料OpenCV4学习笔记(69)——dnn模块之基于fast_style模型实现快速图像风格迁移
-
图像padding为正方形并绘制网格(python+opencv实现) 代码实现import matplotlib.pyplot as plt import cv2 import numpy as np img = cv2.imread("./demo.jpg") """ 图像padding为正方形 """ def square_img(img_cv): # 获取图像的宽高 img_h,img_w = img_cv.shape[0:2] # 计算padding值并将图像padding为正方形 padw,padh = 0,0 if img_h>img_w: padw = (img_h - img_w) // 2 img_pad = np.pad(img_cv,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif img_w>img_h: padh = (img_w - img_h) // 2 img_pad = np.pad(img_cv,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) return img_pad """ 在图像上绘制网格 核心函数 cv2.line(img, (start_x, start_y), (end_x, end_y), (255, 0, 0), 1, 1) """ def draw_grid(img,grid_x,grid_y,line_width=5): img_x,img_y = img.shape[:2] # 绘平行y方向的直线 dx = int(img_x/grid_x) for i in range(0,img_x,dx): cv2.line(img, (i, 0), (i, img_y), (255, 0, 0), line_width) # 绘平行x方向的直线 dy = int(img_y/grid_y) for i in range(0,img_x,dx): cv2.line(img, (0, i), (img_x, i), (255, 0, 0), line_width) return img img = square_img(img) img = draw_grid(img,20,20) # 20,20为网格的shape img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()调用效果代码参数需要稍作修改才能得到如下全部效果