


Kmeans算法简介
算法介绍
人的“物以类聚”
新生入学后根据各自的喜好加入对应的社团。

数据的“物以类聚”
如果把人类比机器学习中的数据,那么聚类就很好理解了
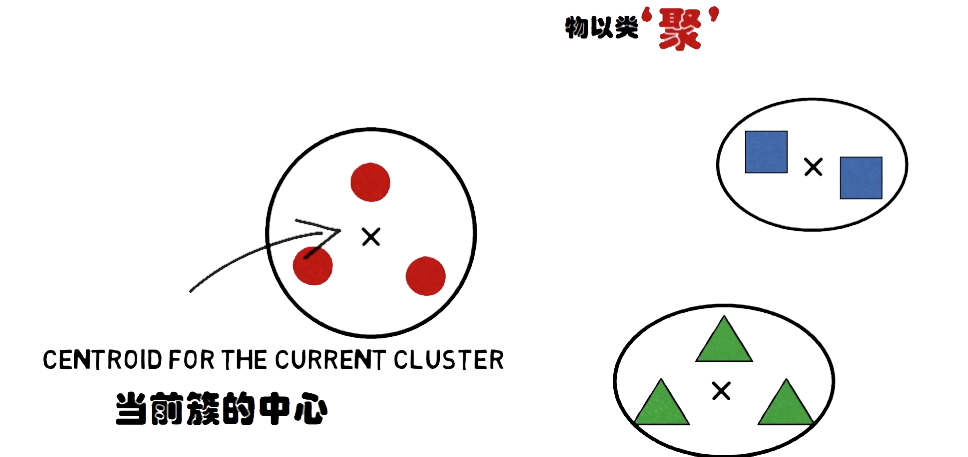
每当这个类别中有了新的数据加入的时候,我们要做的就是更新这个类别的中心位置,以方便这个新样本去适应这个类别,这便是kmeans算法的主要逻辑了。

如何定义相似
用两个点的距离:如欧式距离
引入cluster的相关概念
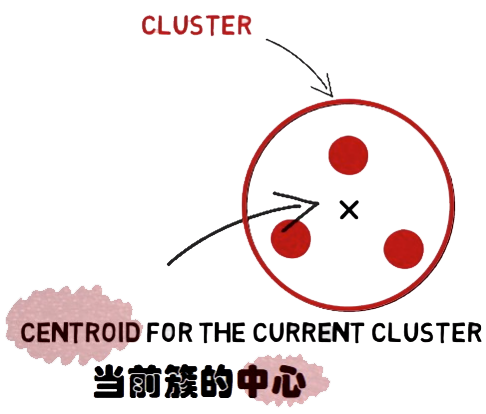
Kmean聚类实例

处理步骤:
- 随机从数据集中选取K个样本当做centroid
- 对于数据集中的每个点,计算它距离每个centroid的距离,并把它归为距离最近的那个cluster
- 更新新的centroid位置
- 重复2.3,直到centroid的位置不再改变
KMEANS的优缺点
优点
- 非监督类的算法不需要样本的标注信息
缺点
- 不能利用到数据的标注信息,意味着模型的性能不如其他监督学习
- 对于K的取值,也就是你认为数据集中的样本应该分为几类,这个参数的设置极为敏感!
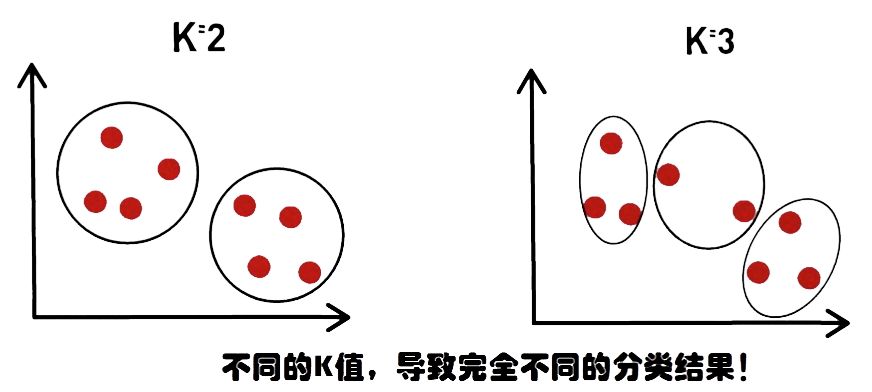
- 对于数据集本身样本的分布也很敏感

参考资料
- 【五分钟机器学习】物以类聚的Kmeans:https://www.bilibili.com/video/BV1ei4y1V7hX?from=search&seid=12931680004886943436
评论 (0)