搜索到
368
篇与
的结果
-
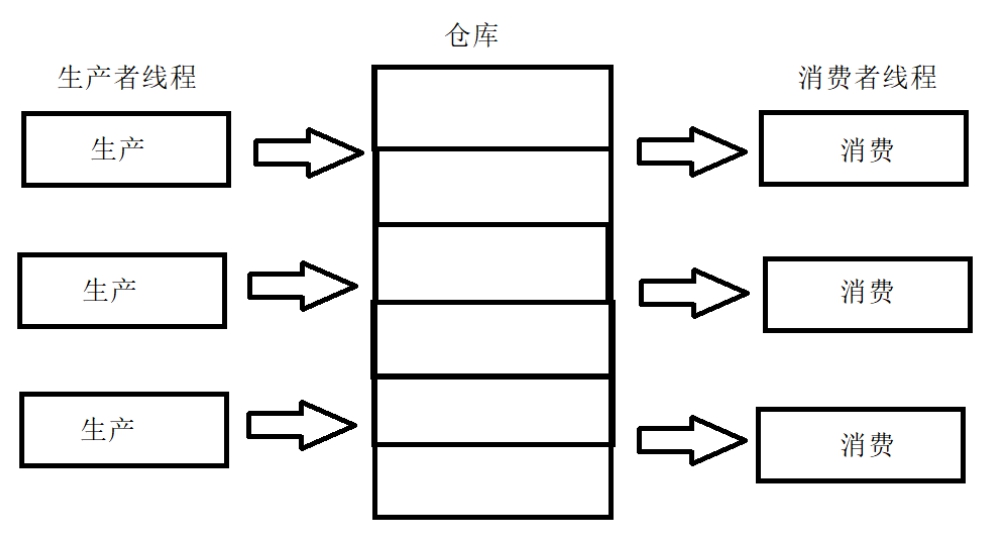
 生产者消费者模型原理及java实现 1.概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。2.321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库3.优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均4.PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s2); 消费水平;5.代码实现5.1 synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }5.2 可重入锁ReentrantLock (配合Condition)方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.ReentrantLock; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Produce(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run() { while (true) { // 生产行为 lock.lock(); //加锁 if (productBuffer.size() == bufferCapacity) { // 缓冲区满了 try { producerCondition.await(); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } } else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); consumerCondition.signal(); // 唤醒消费者线程 } lock.unlock(); //解锁 // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Consumer(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run(){ while (true){//消费行为 lock.lock();//加锁 if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { consumerCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); producerCondition.signal(); // 唤醒生产者线程继续生产 } lock.unlock(); //解锁 // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 ReentrantLock lock = new ReentrantLock(); // 可重入锁 Condition producerCondition = lock.newCondition(); // 生产者condition Condition consumerCondition = lock.newCondition(); // 消费者condition for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } } }参考资料PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式
生产者消费者模型原理及java实现 1.概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。2.321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库3.优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均4.PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s2); 消费水平;5.代码实现5.1 synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }5.2 可重入锁ReentrantLock (配合Condition)方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.ReentrantLock; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Produce(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run() { while (true) { // 生产行为 lock.lock(); //加锁 if (productBuffer.size() == bufferCapacity) { // 缓冲区满了 try { producerCondition.await(); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } } else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); consumerCondition.signal(); // 唤醒消费者线程 } lock.unlock(); //解锁 // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Consumer(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run(){ while (true){//消费行为 lock.lock();//加锁 if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { consumerCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); producerCondition.signal(); // 唤醒生产者线程继续生产 } lock.unlock(); //解锁 // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 ReentrantLock lock = new ReentrantLock(); // 可重入锁 Condition producerCondition = lock.newCondition(); // 生产者condition Condition consumerCondition = lock.newCondition(); // 消费者condition for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } } }参考资料PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式 -
Python字符串处理:过滤字符串中的英文与符号,保留汉字 使用Python 的re模块,re模块提供了re.sub用于替换字符串中的匹配项。1 re.sub(pattern, repl, string, count=0) 参数说明:pattern:正则重的模式字符串repl:被拿来替换的字符串string:要被用于替换的原始字符串count:模式匹配后替换的最大次数,省略则默认为0,表示替换所有的匹配例如import re str = "hello,world!!%[545]你好234世界。。。" str = re.sub("[A-Za-z0-9\!\%\[\]\,\。]", "", str) print(str) 输出结果:你好世界
-
python读写csv文件 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)1.读csv文件# coding:utf-8 import csv data_list = csv.reader(open('data.csv','r',encoding="utf8")) for data_item in data_list: print(data_item) 代码结果: ['测试1', '软件测试工程师'] ['测试2', '软件测试工程师'] ['测试3', '软件测试工程师'] ['测试4', '软件测试工程师'] ['测试5', '软件测试工程师']2.写入CSV文件# coding:utf-8 import csv data_list = [ ("测试1",'软件测试工程师'), ("测试2",'软件测试工程师'), ("测试3",'软件测试工程师'), ("测试4",'软件测试工程师'), ("测试5",'软件测试工程师'), ] f = open('data.csv','w',encoding="utf8") csv_writer = csv.writer(f) for data_item in data_list: csv_writer.writerow(data_item) f.close()参考资料python读写csv文件
-
mAP计算工具使用|快速计算mAP 计算mAP的工具:https://github.com/Cartucho/mAP1.使用步骤clone代码git clone https://github.com/Cartucho/mAPCreate the ground-truth files(将标签文件转为对应的格式,,工具参考2.1)format<class_name> <left> <top> <right> <bottom> [<difficult>]E.g. "image_1.txt"tvmonitor 2 10 173 238 book 439 157 556 241 book 437 246 518 351 difficult pottedplant 272 190 316 259Copy the ground-truth files into the folder input/ground-truth/Create the detection-results filesformat<class_name> <confidence> <left> <top> <right> <bottom>E.g. "image_1.txt"tvmonitor 0.471781 0 13 174 244 cup 0.414941 274 226 301 265 book 0.460851 429 219 528 247 chair 0.292345 0 199 88 436 book 0.269833 433 260 506 336Copy the detection-results files into the folder input/detection-results/Run the codepython main.py2.工具补充2.1 VOC_2_gt.py设置好xml_dir并执行即可得到对应的gt_txt文件import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 xml_dir = "/data/jupiter/project/dataset/帯広空港_per_frame/xml/" gt_dir = "./input/ground-truth/" shutil.rmtree(gt_dir) os.mkdir(gt_dir) """ 将voc xml 的数据转为对应的gt_str """ def voc_2_gt_str(xml_dict): objects = xml_dict["annotation"]["object"] obj_list = [] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) # 获取gt格式的数据信息 gt_str = "" for obj in obj_list: left = int(obj['bndbox']['xmin']) top = int(obj['bndbox']['ymin']) right = int(obj['bndbox']['xmax']) bottom = int(obj['bndbox']['ymax']) obj_name = obj['name'] gt_str += "%s %s %s %s %s\n" % (obj_name, left, top, right, bottom) return gt_str xml_list = os.listdir(xml_dir) pbar = tqdm(total=len(xml_list)) # 加入进度条支持 pbar.set_description("VOC2GT") # 设置前缀 for tmp_file in xml_list: xml_path = os.path.join(xml_dir,tmp_file) gt_txt_path = os.path.join(gt_dir,tmp_file.replace(".xml", ".txt")) # 读取xml文件+转为字典 with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dict = xmltodict.parse(xml_str) # 提取对应的数据 gt_str = voc_2_gt_str(xml_dict) # 写入对应的gt_txt文件 with open(gt_txt_path, "w") as f: f.write(gt_str) pbar.update(1) pbar.close()VOC2GT: 27%|██████████████████████████████████████████████████████████████▌ | 24013/89029 [03:25<09:54, 109.31it/s]2.2 YOLOv5_2_dr.py# YOLOv5_2_dr import os import xmltodict import shutil from tqdm import tqdm # TODO:需要修改的内容 yolov5_detect_txt_dir = "/data/jupiter/project/目标检测对比实验/yolov5/runs/detect/exp3/labels" cls_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] img_width = 1632 img_height = 1080 def txt_convert(txt_src,img_width,img_height,cls_list): txt_dst = "" for line in txt_src.split("\n"): if(len(line)==0):continue cls_id,dx,dy,dw,dh,conf = line.split(" ") cls_name = cls_list[int(cls_id)].replace(" ","") x_center = int(float(dx)*img_width) y_center = int(float(dy)*img_height) w = int(float(dw)*img_width) h = int(float(dh)*img_height) x1 = x_center - int(w/2) y1 = y_center - int(h/2) x2 = x1 + w y2 = y1 + h txt_dst += "{} {} {} {} {} {}\n".format(cls_name,conf,x1,y1,x2,y2) return txt_dst dr_dir = "./input/detection-results/" txt_list = os.listdir(yolov5_detect_txt_dir) pbar = tqdm(total=len(txt_list)) # 加入进度条支持 pbar.set_description("YOLOv5_2_dr") # 设置前缀 for file in txt_list: txt_path_src = os.path.join(yolov5_detect_txt_dir,file) txt_path_dst = os.path.join(dr_dir,"{:>05d}.txt".format(int(file.split("_")[1][:-4]))) # 读取原文件 with open(txt_path_src) as f: txt_src = f.read() # 转为目标格式 txt_dst = txt_convert(txt_src,img_width,img_height,cls_list) # 写入对应的dr_txt文件 with open(txt_path_dst,"w") as f: f.write(txt_dst) pbar.update(1) pbar.close()参考资料https://github.com/Cartucho/mAP.git目标检测中的mAP及代码实现
-
leetcode|中等:15. 三数之和 1.题目给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。注意:答案中不可以包含重复的三元组。示例 1:输入:nums = [-1,0,1,2,-1,-4] 输出:[[-1,-1,2],[-1,0,1]]示例 2:输入:nums = [] 输出:[]示例 3:输入:nums = [0] 输出:[]提示:$0 <= nums.length <= 3000$$-10^5 <= nums[i] <= 10^5$2. 题解2.1 思路分析首先对数组进行排序,排序后固定一个数 nums[i] 如果 nums[i]大于 0,则三数之和必然无法等于 0,结束循环 否则使用左右指针指向nums[i]后面的两端,数字分别为 nums[L]和 nums[R]计算三个数的和 sum 判断是否满足等于0 等于0则添加进结果集 小于0则L++(L<R) 大于0则R--(L<R) 关于去重: 如果 nums[i]== nums[i-1],则说明该数字重复,会导致结果重复,所以应该跳过 当 sum == 0 时,nums[L] == nums[L+1]则会导致结果重复,应该跳过,L++ 当 sum == 0 时,nums[R] == nums[R-1] 则会导致结果重复,应该跳过,R--2.2 代码实现import java.util.*; public class Solution { public List<List<Integer>> threeSum(int[] nums) { // 数组排序 Arrays.sort(nums); List<List<Integer>> res = new ArrayList<>(); if(nums.length>=3) { for (int i = 0; i < nums.length; i++) { if (nums[i] > 0) break; if(i > 0 && nums[i] == nums[i-1]) continue; // 去重 int L = i + 1; // 左指针 int R = nums.length - 1; // 右指针 while (L < R) { while (L < R && nums[L] == nums[L + 1]) L++; // 去重 while (L < R && nums[R] == nums[R - 1]) R--; // 去重 int sum = nums[i] + nums[L] + nums[R]; if (sum == 0) { res.add(Arrays.asList(nums[i], nums[L], nums[R])); L++; R--; } else if (sum < 0) { L++; } else { R--; } } } } return res; } public static void main(String[] args) { Solution solution = new Solution(); System.out.println(solution.threeSum(new int[]{-1, 0, 1, 2, -1, -4})); } }2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过19 ms45.6 MBJava2022/03/24 20:29添加备注参考资料https://leetcode-cn.com/problems/3sum/https://leetcode-cn.com/problems/3sum/solution/hua-jie-suan-fa-15-san-shu-zhi-he-by-guanpengchn/
-
leetcode|中等:12. 整数转罗马数字 1.题目罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。给你一个整数,将其转为罗马数字。示例 1:输入: num = 3 输出: "III"示例 2:输入: num = 4 输出: "IV"示例 3:输入: num = 9 输出: "IX"示例 4:输入: num = 58 输出: "LVIII" 解释: L = 50, V = 5, III = 3.示例 5:输入: num = 1994 输出: "MCMXCIV" 解释: M = 1000, CM = 900, XC = 90, IV = 4.提示:1 <= num <= 39992. 题解2.1 思路分析思路1:贪心 首先我们构造出所有可能会出现的元素 vals = {1,4,5,9,10,40,50,90,100,400,500,900,1000}; keys = {"I","IV","V","IX","X","XL","L","XC","C","CD","D","CM","M"}; 然后我们每次尽量使用最大的数来表示。 比如对于 1994 这个数,如果我们每次尽量用最大的数来表示,依次选 1000,900,90,4,会得到正确结果 MCMXCIV。2.2 代码实现public class Solution { public String intToRoman(int num) { int[] vals = {1,4,5,9,10,40,50,90,100,400,500,900,1000}; String[] keys = {"I","IV","V","IX","X","XL","L","XC","C","CD","D","CM","M"}; StringBuilder sb = new StringBuilder(); while (num>0){ // 先确定是要减哪一个 int targetIndex = vals.length-1; while (vals[targetIndex]>num){targetIndex--;}; sb.append(keys[targetIndex]); num -= vals[targetIndex]; } return sb.toString(); } public static void main(String[] args) { Solution solution = new Solution(); System.out.println(solution.intToRoman(1994)); } } 2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过3 ms40.7 MBJava2022/03/24 13:07添加备注参考资料https://leetcode-cn.com/problems/integer-to-roman/
-
leetcode|中等:11. 盛最多水的容器 1.题目给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。返回容器可以储存的最大水量。说明:你不能倾斜容器。示例 1:输入:[1,8,6,2,5,4,8,3,7] 输出:49 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。示例 2:输入:height = [1,1] 输出:1提示:n == height.length2 <= n <= 1050 <= height[i] <= 1042. 题解2.1 思路分析思路1:双指针 设两指针 i,j ,指向的水槽板高度分别为 h[i], h[j] ,此状态下水槽面积为 S(i,j)。由于可容纳水的高度由两板中的 短板 决定,因此可得如下 面积公式 : S(i, j) = min(h[i], h[j]) × (j - i) 在每个状态下,无论长板或短板向中间收窄一格,都会导致水槽 底边宽度 -1 变短: 若向内移动短板,水槽的短板 min(h[i],h[j])可能变大,因此下个水槽的面积可能增大 若向内移动长板,水槽的短板 min(h[i],h[j])不变或变小,因此下个水槽的面积一定变小 因此,初始化双指针分列水槽左右两端,循环每轮将短板向内移动一格,并更新面积最大值,直到两指针相遇时跳出;即可获得最大面积。2.2 代码实现public class Solution { public int maxArea(int[] height) { int max = 0; int left = 0,right = height.length-1; // 双指针 while (left<right){ int area = Math.min(height[left],height[right])*(right-left); max = Math.max(area,max); if(height[left]>height[right]){ right--; }else { left++; } } return max; } public static void main(String[] args) { Solution solution = new Solution(); System.out.println(solution.maxArea(new int[]{1,8,6,2,5,4,8,3,7})); } }2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过4 ms51.6 MBJava2022/03/24 12:32添加备注参考资料https://leetcode-cn.com/problems/container-with-most-water/https://leetcode-cn.com/problems/container-with-most-water/solution/container-with-most-water-shuang-zhi-zhen-fa-yi-do/
-
leetcode|中等:5. 最长回文子串 1.题目给你一个字符串 s,找到 s 中最长的回文子串。示例 1:输入:s = "babad" 输出:"bab" 解释:"aba" 同样是符合题意的答案。示例 2:输入:s = "cbbd" 输出:"bb"提示:1 <= s.length <= 1000s 仅由数字和英文字母组成2. 题解2.1 思路分析思路1:暴力求解 从每个字符开始向右延伸探索可能构成的最长回文子串并记录最长子串的开始位置和长度2.2 代码实现public class Solution { //判断子串是否构成回文 public boolean isPalindrome(char[] sChars,int indexStart,int indexEnd){ int len = indexEnd-indexStart; if(len==1)return true; for (int i = 0; i < len/2; i++) { if(sChars[indexStart+i]!=sChars[indexEnd-1-i]){ return false; } } return true; } public String longestPalindrome(String s) { char[] sChars = s.toCharArray(); //转为字符数组 int sLen = s.length(); // 字符串长度 int indexStart = 0; //记录最长子串的开始位置 int maxLen = 1; //记录最大子串长度 for (int i = 0; i < sLen-maxLen; i++) { // 子串开始下标 for (int j = maxLen; j <= sLen-i; j++) { // 子串长度 if(isPalindrome(sChars,i,i+j)){ indexStart = i; maxLen = j; } } } return s.substring(indexStart,indexStart+maxLen); } public static void main(String[] args) { Solution solution = new Solution(); String in = "babad"; String res = solution.longestPalindrome(in); System.out.println(res); } } 2.3 提交结果提交结果执行用时内存消耗语言提交时间备注通过265 ms41.2 MBJava2022/03/23 17:11添加备注参考资料https://leetcode-cn.com/problems/longest-palindromic-substring/submissions/
-
VOC2VID:将VOC格式的数据集转为视频进行查看|可视化视频标注结果 通常用于查看针对连续视频标注的结果,因博主有视频目标检测的需求所以写了该小工具# 可视化视频标注结果 import numpy as np import cv2 import xmltodict import os from tqdm import tqdm # 基本信息填充 xml_dir="./data_handle/xml/"# VOC xml文件所在文件夹 img_dir="./data_handle/img/"# VOC img文件所在文件夹 class_list = ['conveyor', 'refueller', 'aircraft', 'lounge', 'dining car', 'front of baggage car', 'tractor'] # class_list """ 将voc xml 的数据转为对应的bbox_list """ def voc_2_yolo_bbox_list(xml_dict): objects = xml_dict["annotation"]["object"] obj_list = [] if isinstance(objects,list): # xml文件中包含多个object for obj in objects: obj_list.append(obj) else: # xml文件中包含1个object obj_list.append(objects) bbox_list = [] for obj in obj_list: # 获取voc格式的数据信息 x1 = int(obj['bndbox']['xmin']) y1 = int(obj['bndbox']['ymin']) x2 = int(obj['bndbox']['xmax']) y2 = int(obj['bndbox']['ymax']) score = 1 cls_id = class_list.index(obj['name']) bbox_list.append([x1,y1,x2,y2,score,cls_id]) return bbox_list """ 生成color_list """ def random_color(color_num): color_list = [] for j in range(color_num): color_single = (int(np.random.randint(0,255)),int(np.random.randint(0,255)),int(np.random.randint(0,255))) color_list.append(tuple(color_single)) return color_list color_list = random_color(len(class_list)) """ 目标检测预测结果可视化函数 + img:进行目标检测的图片 + bbox_list:处理过的预测结果 + class_name_list:用于将cls_is转为cls_name + color_list:绘制不同的类别使用不同的颜色 + thresh:阈值 """ def vis_detections(img, bbox_list,class_name_list=class_list,color_list=color_list,thresh=0.5): for bbox in bbox_list: # 参数解析 x1,y1,x2,y2,score,cls_id = bbox[0],bbox[1],bbox[2], bbox[3],bbox[4],int(bbox[5]) cls_name = class_name_list[cls_id] color = color_list[cls_id] # 跳过低于阈值的框 if score<thresh:continue # 画框 cv2.rectangle(img, (int(x1),int(y1)), (int(x2),int(y2)),color_list[cls_id],2) # 画label label_text = '{:s} {:.3f}'.format(cls_name, score) cv2.putText(img, label_text, (x1-5, y1-5),cv2.FONT_HERSHEY_SIMPLEX, 0.8, color_list[cls_id], 2) return img img_list = os.listdir(img_dir) frame_rate = 30 # 帧率 frame_shape = cv2.imread(os.path.join(img_dir,img_list[0])).shape[:-1] # 图片大小/帧shape frame_shape = (frame_shape[1],frame_shape[0]) # 交换w和h videoWriter = cv2.VideoWriter('result.mp4', cv2.VideoWriter_fourcc(*'MJPG'), frame_rate, frame_shape) # 初始化视频帧writer # 加入进度条支持 pbar = tqdm(total=len(img_list)) pbar.set_description("VOC2VID") # 开始逐帧写入视频帧 frame_id = 1 for file in img_list: img_path = os.path.join(img_dir,file) # img地址 img = cv2.imread(img_path) # 读取img xml_path = os.path.join(xml_dir,file[:-3]+"xml") # xml地址 # 读取xml文件+转为字典+ 转为bbox_list with open(xml_path,'r',encoding="utf8") as f: xml_str = f.read() xml_dict = xmltodict.parse(xml_str) bbox_list = voc_2_yolo_bbox_list(xml_dict) # 绘制xml标注结果 img = vis_detections(img,bbox_list) frame_id += 1 # if frame_id%120 == 0: # break videoWriter.write(img) pbar.update(1) pbar.close() videoWriter.release()
-
目标检测结果可视化 1.核心函数# 目标检测效果可视化 import numpy as np import cv2 # class_list class_list = ['Plane', 'BridgeVehicle', 'Person', 'LuggageVehicle', 'RefuelVehicle', 'FoodVehicle', 'LuggageVehicleHead', 'TractorVehicle', 'RubbishVehicle', 'FollowMe'] """ 生成color_list """ # 生成number个color def random_color(color_num): color_list = [] for j in range(color_num): color_single = (int(np.random.randint(0,255)),int(np.random.randint(0,255)),int(np.random.randint(0,255))) color_list.append(tuple(color_single)) return color_list color_list = random_color(len(class_list)) """ 目标检测预测结果可视化函数 + img:进行目标检测的图片 + bbox_list:处理过的预测结果 + class_name_list:用于将cls_is转为cls_name + color_list:绘制不同的类别使用不同的颜色 + thresh:阈值 """ def vis_detections(img, bbox_list,class_name_list=class_list,color_list=color_list,thresh=0.5): for bbox in bbox_list: # 参数解析 x1,y1,x2,y2,score,cls_id = bbox[0],bbox[1],bbox[2], bbox[3],bbox[4],int(bbox[5]) cls_name = class_name_list[cls_id] color = color_list[cls_id] # 跳过低于阈值的框 if score<thresh:continue # 画框 cv2.rectangle(img, (int(x1),int(y1)), (int(x2),int(y2)),color_list[cls_id],2) # 画label label_text = '{:s} {:.3f}'.format(cls_name, score) cv2.putText(img, label_text, (x1-5, y1-5),cv2.FONT_HERSHEY_SIMPLEX, 0.8, color_list[cls_id], 2) return img2.调用测试img = cv2.imread("./data_handle/img/00001.jpg.") bbox_list = [ [882,549,1365,631,1,1] ] img = vis_detections(img,bbox_list) img_show = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) import matplotlib.pyplot as plt plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img_show) plt.show()
-
蓝桥杯|历届真题:作物杂交 1.题目【问题描述】作物杂交是作物栽培中重要的一步。已知有$N$种作物(编号$1$至$N$),第$i$种作物从播种到成熟的时间为$T_i$。作物之间两两可以进行杂交,杂交时间取两种中时间较长的一方。如作物$A$种植时间为5天,作物$B$种植时间为7天,则$AB$杂交花费的时间为7天。作物杂交会产生固定的作物,新产生的作物仍然属于N种作物中的一种。初始时,拥有其中$M$种作物的种子(数量无限,可以支持多次杂交)。同时可以进行多个杂交过程。求问对于给定的目标种子,最少需要多少天能够得到。如存在4种作物$ABCD$,各自的成熟时间为5天、7天、3天、8天。初始拥有AB两种作物的种子,目标种子为$D$,已知杂交情况为$A \times B→C,A \times C→D$。则最短的杂交过程为:第1天到第7天(作物B的时间),$A \times B→C$。第8天到第12天(作物A的时间),$A \ times C→D$。花费12天得到作物D的种子。【输入格式】输入的第1行包含4个整数$N,M,K,T,N$表示作物种类总数(编号1至$N$),$M$表示初始拥有的作物种子类型数量,$K$表示可以杂交的方案数,$T$表示目标种子的编号。第2行包含$N$个整数,其中第i个整数表示第i种作物的种植时间T;($1 \leq T_i \leq 100$)第3行包含$M$个整数,分别表示已拥有的种子类型$K_j( 1 \leq K_j \leq M)$,$K_j$两两不同。第4至$K+3$行,每行包含3个整数$A,B,C$,表示第$A$类作物和第$B$类作物杂交可以获得第$C$类作物的种子。【输出格式】输出一个整数,表示得到目标种子的最短杂交时间。【样例输入】6 2 4 6 5 3 4 6 4 9 1 2 1 2 3 1 3 4 2 3 5 4 5 6【样例输出】16【样例说明】第1天至第5天,将编号1与编号2的作物杂交,得到编号3的作物种第6天至第10天,将编号1与编号3的作物杂交,得到编号4的作物种第6天至第9天,将编号2与编号3的作物杂交,得到编号5的作物种第11天至第16天,将编号4与编号5的作物杂交,得到编号6的作物种总共花费16天【评测用例规模与约定】对于所有评测用例,$1 \leq N \leq 2000,2 \leq M \leq N,1 \leq K \leq 100000,1 \leq T \leq N$,保证目标种子一定可以通过杂交得到。2. 题解2.1 思路分析思路1:暴力求解 设置一个数字minGetTime用于保存每类种子的最小获取时间 循环遍历杂交方案: minGetTime[C] = min(minGetTime[C],maxAB获取时间+maxAB成熟数据) 直至数组minGetTime收敛(不再有任何位置发生变化)2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); // 判断minGetTime数组是否收敛|是否存在某位发生修改 无则返回true public static boolean isNoChange(boolean[] changeFlag){ boolean res = true; for (int i = 0; i < changeFlag.length; i++) { res = res&changeFlag[i]; } return res; } public static void main(String[] args) { int N = scanner.nextInt(); // 作物种类数 int M = scanner.nextInt(); // 初始时候拥有的种子数量 int K = scanner.nextInt(); // 可以杂交的方案数量 int T = scanner.nextInt(); // 目的种子编号 int[] timeSpendArr = new int[N];// 作物成熟时间 for (int i = 0; i < N; i++) { timeSpendArr[i] = scanner.nextInt(); } int[] startSeedArr = new int[M]; //初始拥有的种子 for (int i = 0; i < M; i++) { startSeedArr[i] = scanner.nextInt(); } int[][] methodArr = new int[K][3]; //杂交方案数 for (int i = 0; i < K; i++) { for (int j = 0; j < 3; j++) { methodArr[i][j] = scanner.nextInt(); } } int[] minGetTime = new int[N];//最小获取时间 // 初始化最小获取时间 for (int i = 0; i < N; i++) { minGetTime[i] = Integer.MAX_VALUE; } for (int i = 0; i < M; i++) { minGetTime[startSeedArr[i]-1] = 0; } boolean[] changeFlag = new boolean[K];//用于判断本轮处理杂交方案是否导致了最小时间发生修改|判断收敛 Arrays.fill(changeFlag,false); while (!isNoChange(changeFlag)){//知道未发生修改位置 Arrays.fill(changeFlag,true); for (int i = 0; i < K; i++) { int seedA = methodArr[i][0]-1; int seedB = methodArr[i][1]-1; if(minGetTime[seedA]==Integer.MAX_VALUE||minGetTime[seedB]==Integer.MAX_VALUE)continue; int newSeed = methodArr[i][2]-1;//新品种 int minGetTimeOfNewSeed = Math.min(minGetTime[newSeed],Math.max(minGetTime[seedA],minGetTime[seedB])+Math.max(timeSpendArr[seedA],timeSpendArr[seedB])); if(minGetTimeOfNewSeed!=minGetTime[newSeed]){ changeFlag[i] = false; minGetTime[newSeed] = minGetTimeOfNewSeed; } } } System.out.println(minGetTime[T-1]); } }2.3 提交结果评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00125ms25.54MB输入 输出2正确10.00109ms25.46MBVIP特权3正确10.00468ms75.14MBVIP特权4正确10.00406ms68.42MBVIP特权5正确10.00390ms77.67MBVIP特权6正确10.00296ms54.73MBVIP特权7正确10.00500ms99.37MBVIP特权8正确10.00453ms98.50MBVIP特权9正确10.00578ms97.82MBVIP特权10正确10.00500ms98.80MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2859
-
蓝桥杯|历届真题:修改数组 1.题目【问题描述】给定一个长度为N的数组$A=[A_1,A_2,\dots,A_N]$,数组中有可能有重复出现的整数。现在小明要按以下方法将其修改为没有重复整数的数组。小明会依次修改$A_2,A_3,\dots,A_N$当修改$A_i$;时,小明会检查$A_i$是否在$A_1 \rightarrow A_{i-1}$中出现过。如果出现过,则小明会给$A_i$加上$1$;如果新的$A_i$仍在之前出现过,小明会持续给$A_i$加上1直到$A_i$没有在$A_1 \rightarrow A_{i-1}$中出现过。当$A_n$也经过上述修改之后,显然A数组中就没有重复的整数了。现在给定初始的A数组,请你计算出最终的A数组。【输入格式】第一行包含一个整数$N$。第二行包含N个整数$A_1,A_2,\dots,A_N$【输出格式】输出N个整数,依次是最终的$A_1,A_2,\dots,A_N$【样例输入】5 2 1 1 3 4【样例输出】2 1 3 4 5【评测用例规模与约定】对于80%的评测用例,$1 \leq N \leq 10000$。对于所有评测用例,$1 \leq N \leq 100000,1 \leq A_i \leq 1000000$。2. 题解2.1 思路分析思路1:暴力求解(80分) 用一个set保存已遍历过的数字,当遍历到新的位置时,如果再set里则一直++,再将其加入回set 思路2:并查集 维护并查集并通过查操作直接找到A_i2.2 代码实现思路1:暴力求解// 暴力求解 80分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { int N = scanner.nextInt(); int[] arr = new int[N]; for (int i = 0; i < N; i++) { arr[i] = scanner.nextInt(); } Set<Integer> set = new HashSet<>(); for (int i = 0; i < N; i++) { while (set.contains(arr[i])){ arr[i]++; } set.add(arr[i]); } for (int i = 0; i < N-1; i++) { System.out.print(arr[i]+" "); } System.out.println(arr[N-1]); } }思路2:并查集// 并查集 80分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); static int[] find = new int[1000001]; // 查操作 找到x的真正祖先 public static int findRoot(int x){ return x==find[x]?x:findRoot(find[x]); } public static void main(String[] args) { int N = scanner.nextInt(); int[] arr = new int[N]; // 初始化find数组(用于查找祖先) for (int i = 0; i < find.length; i++) { find[i] = i; } for (int i = 0; i < N; i++) { arr[i] = scanner.nextInt(); int root = findRoot(arr[i]); //找到目标A_{i-1} arr[i] = root; find[root] = findRoot(root+1);// 并操作 用并查集维护大小关系 } for (int i = 0; i < N-1; i++) { System.out.print(arr[i]+" "); } System.out.println(arr[N-1]); } }// 并查集+路径压缩 100分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); static int[] find = new int[1000100]; // 查操作 找到x的真正祖先 增加路径压缩降低耗时 public static int findRoot(int x){ if(x==find[x]){ return x; }else { find[x] = findRoot(find[x]); return find[x]; } } public static void main(String[] args) { int N = scanner.nextInt(); int[] arr = new int[N]; // 初始化find数组(用于查找祖先) for (int i = 0; i < find.length; i++) { find[i] = i; } for (int i = 0; i < N; i++) { arr[i] = scanner.nextInt(); int root = findRoot(arr[i]); //找到目标A_{i-1} arr[i] = root; find[root] = findRoot(root+1);// 并操作 用并查集维护大小关系 } for (int i = 0; i < N-1; i++) { System.out.print(arr[i]+" "); } System.out.println(arr[N-1]); } }2.3 提交结果思路1:暴力求解评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00125ms22.51MB输入 输出2正确10.0093ms22.47MBVIP特权3正确10.0093ms22.62MBVIP特权4正确10.00125ms31.51MBVIP特权5正确10.00656ms158.1MBVIP特权6正确10.00484ms149.7MBVIP特权7正确10.00765ms242.9MBVIP特权8正确10.00531ms156.5MBVIP特权9运行超时0.00运行超时287.7MBVIP特权10运行超时0.00运行超时287.8MBVIP特权思路2:并查集评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00125ms26.23MB输入 输出2正确10.00125ms26.23MBVIP特权3正确10.0078ms26.39MBVIP特权4正确10.00156ms30.05MBVIP特权5正确10.00296ms40.35MBVIP特权6正确10.00296ms42.53MBVIP特权7正确10.00328ms40.65MBVIP特权8正确10.00281ms40.58MBVIP特权9正确10.00609ms96.44MBVIP特权10正确10.00484ms97.01MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2856图论——并查集(详细版)蓝桥杯 -2019年第十届真题 修改数组 暴力|并查集
-
蓝桥杯|历届真题:回文日期 1.题目【问题描述】2020年春节期间,有一个特殊的日期引起了大家的注意:2020年2月2日。因为如果将这个日期按"yyyymmdd”的格式写成一个8位数是20200202,恰好是一个回文数。我们称这样的日期是回文日期。有人表示20200202是“千年一遇”的特殊日子。对此小明很不认同,因为不到2年之后就是下一个回文日期:20211202即2021年12月2日。也有人表示20200202并不仅仅是一个回文日期,还是一个ABABBABA型的回文日期。对此小明也不认同,因为大约100年后就能遇到下一个ABABBABA 型的回文日期:21211212 即2121年12月12日。算不上“千年一遇”,顶多算“千年两遇”。给定一个8位数的日期,请你计算该日期之后下一个回文日期和下一个ABABBABA型的回文日期各是哪一天。【输入格式】输入包含一个八位整数N,表示日期。【输出格式】输出两行,每行1个八位数。第一行表示下一个回文日期,第二行表示下一个ABABBABA型的回文日期。【样例输入】20200202【样例输出】20211202 21211212【评测用例规模与约定】对于所有评测用例,$10000101 \leq N \leq 89991231$,保证N是一个合法日期的8位数表示。2. 题解2.1 思路分析本题需要求解下一个ABCDDCBA型的日期和下一个ABABBABA型的日期 只需先完成nextABCDDCBADate的求解并再此基础上增加ABCD-->ABAB的限制条件即可 nextABCDDCBADate(date)的求解包含内容: 1.date年月日拆解 2.4位数字反转 ABCD-->DCBA 为了降低时间复杂度,只对年进行遍历,月日根据ABCD-->DCBA生成 3.有效日期判断(年月日分别进行判断) 包含闰年判断 4.判断新的日期是否再当前日期之后2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); static int[] maxDayOfMonthList = {31,28,31,30,31,30,31,31,30,31,30,31}; // 判断闰年 public static boolean isUniqueYear(int year){ return (year%4==0&&year%100!=0)||year%400==0; } // 判断day是否有效 public static boolean isValidDay(int year,int month,int day){ // 求该月最大天数 int maxDayOfMonth = maxDayOfMonthList[month-1]; if(isUniqueYear(year)&&month==2){ maxDayOfMonth = 29; } return !(day==0||day>maxDayOfMonth); } // 判断month是否有效 public static boolean isValidMonth(int month){ return month>0&&month<13; } // 4位数字反转 ABCD-->DCBA public static int reverse4BitInt(int num){ // 从低位到高位进行分解 int bit1 = num%10; int bit2 = (num%100)/10; int bit3 = (num/100)%10; int bit4 = num/1000; return bit1*1000+bit2*100+bit3*10+bit4; } // 寻找下一个回文/ABCDDCBA日期 public static int nextABCDDCBADate(int date){ int year = date / 10000; int ABCDDCBADate = date; for (int i = year; i < 10000; i++) { int tmp_year = i; int tmp_year_reverse = reverse4BitInt(tmp_year); int tmp_day = tmp_year_reverse%100; int tmp_month = tmp_year_reverse/100; int tmp_date = tmp_year*10000+tmp_month*100+tmp_day; if (isValidMonth(tmp_month) && isValidDay(tmp_year, tmp_month, tmp_day)&&tmp_date>date){//有效日期+日期更后 ABCDDCBADate = tmp_date; break; } } return ABCDDCBADate; } // 寻找下一个符合ABABBABA的日期 public static int nextABABBABADate(int date) { int ABABBABA = nextABCDDCBADate(date); int month = (ABABBABA % 10000) / 100; int day = ABABBABA % 100; while (month!=day){ ABABBABA = nextABCDDCBADate(ABABBABA); month = (ABABBABA % 10000) / 100; day = ABABBABA % 100; } return ABABBABA; } public static void main(String[] args) { int date= scanner.nextInt(); System.out.println(nextABCDDCBADate(date)); System.out.println(nextABABBABADate(date)); } }2.3 提交结果评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00125ms22.52MB输入 输出2正确10.0078ms22.48MBVIP特权3正确10.00109ms22.49MBVIP特权4正确10.0062ms22.44MBVIP特权5正确10.00109ms22.44MBVIP特权6正确10.0093ms22.47MBVIP特权7正确10.0046ms22.50MBVIP特权8正确10.0093ms22.48MBVIP特权9正确10.0078ms22.51MBVIP特权10正确10.0078ms22.48MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2856
-
蓝桥杯|历届真题:子串分值和 1.题目【问题描述】对于一个字符串$S$,我们定义S的分值$f(S)$为$S$中恰好出现一次的字符个数。例如$f(aba)=1,f(abc)=3,f(aaa) = 0$。现在给定一个字符串$S[0..n-1]$(长度为n),请你计算对于所有S的非空子串$S[i..j](0 \leq i \leq j \lt n)$,$f(S[i..j])$的和是多少。【输入格式】输入一行包含一个由小写字母组成的字符串S。【输出格式】输出一个整数表示答案。【样例输入】ababc【样例输出】21【样例说明】子串,f值 a,1 ab,2 aba,1 abab,0 ababc,1 b,1 ba,2 bab,1 babc,2 a,1 ab,2 abc,3 b,1 bc,2 c,1【评测用例规模与约定】对于20%的评测用例, $1 \leq n \leq 10$;对于40%的评测用例, $1 \leq n \leq 100$;对于50%的评测用例, $1 \leq n \leq 1000$;对于60%的评测用例, $1 \leq n \leq 10000$;对于所有评测用例, $1 \leq n \leq 100000$;2. 题解2.1 思路分析思路1:暴力求解(50分) 首先需要写一个计算子串得分的函数 1.统计各个字符出现的次数 2.得到只出现一次的字符数 然后遍历所有的子串并对其得分进行求和 思路2:动态规划(50分) 考虑子串之间的关系,即新增一个字符对子串得分的影响,从避免重复统计字符出现次数导致耗时 思路3:考虑每个位置的字符只出现一次的子串总数(100分) 用 pre[i] 记录第 i 位置上的字母上一次出现的位置,用 next[i] 记录第 i 位置上的字母下一次出现的位置; 那么往左最多能延伸到 pre[i] + 1,其到第 i 个字母一共有 i - pre[i] 个字母; 同理往右最多能延伸到 next[i] - 1,其到第 i 个字母一共有 next[i] - i 个字母; 二者相乘,就是该 i 位置上的字符只出现一次的子串总数 具体可以结合上述输入输出例子思考。2.2 代码实现思路1:暴力求解import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static int getScore(String str){ int score = 0; char[] strChars = str.toCharArray(); int[] charCounter = new int[26]; for (int i = 0; i < 26; i++)charCounter[i]=0; for (int i = 0; i < strChars.length; i++) { charCounter[(int)(strChars[i]-'a')]++; } for (int i = 0; i <26 ; i++) { if(charCounter[i]==1)score++; } return score; } public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { StringBuilder sb = new StringBuilder(); for (int j = i; j < strChars.length; j++) { sb.append(strChars[j]); scoreSum+=getScore(sb.toString()); } } System.out.println(scoreSum); } }// 简化子串得分求解 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { Set<Character> set1 = new HashSet<>(); //统计所有字符串 Set<Character> set2 = new HashSet<>();//统计不止出现一次的字符串 for (int j = i; j < strChars.length; j++) { if(set1.contains(strChars[j])){ set2.add(strChars[j]); } set1.add(strChars[j]); scoreSum+= set1.size()-set2.size(); } } System.out.println(scoreSum); } }思路2:动态规划// 40分 会爆内存 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int[][] dp = new int[str.length()][str.length()]; int scoreSum = 0; for (int i = 0; i < str.length(); i++) { for (int j = 0; j < str.length();j++) { if(j<i){ dp[i][j] = 0; }else if(j==i){ dp[i][j] = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 dp[i][j]=dp[i][j-1]-1; }else {//旧的子串包含多个个待加入字符,之前已进行了-1操作,无需再减 dp[i][j]=dp[i][j-1]; } }else {//旧的子不包含待加入字符 dp[i][j]=dp[i][j-1]+1; } } scoreSum += dp[i][j]; } } System.out.println(scoreSum); } }// dp优化 避免爆内存 还是50分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int lastDpstate = 0; int scoreSum = 0; for (int i = 0; i < len; i++) { for (int j = 0; j < len;j++) { if(j<i){ lastDpstate=0; }else if(j==i){ lastDpstate = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子串包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 lastDpstate=lastDpstate-1; } }else { lastDpstate=lastDpstate+1; } } scoreSum += lastDpstate; } } System.out.println(scoreSum); } }思路3:考虑每个位置的字符只出现一次的子串总数// 60分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { int nextIndex = str.substring(i+1).indexOf(strChars[i]); //下一个strChars[i]字符的位置 nextIndex = nextIndex==-1? strChars.length : nextIndex+i+1; int preIndex = str.substring(0,i).lastIndexOf(strChars[i]);////前一个strChars[i]字符的位置 scoreSum += (nextIndex-i)*(i-preIndex); } System.out.println(scoreSum); } }// 优化 100分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int len = strChars.length; int scoreSum = 0; int[] pre = new int[len]; int[] next = new int[len]; Arrays.fill(pre,-1); Arrays.fill(next,len); // 求解next[i] for (int i = 0; i < len; i++) { for (int j = i+1; j < len; j++) { if(strChars[i]==strChars[j]){ next[i]=j; break; } } } // 求解pre[i] for (int i = 0; i < len; i++) { for (int j = i-1; j>=0; j--) { if(strChars[i]==strChars[j]){ pre[i]=j; break; } } } // 计算得分和 for (int i = 0; i < len; i++) { scoreSum += (next[i]-i)*(i-pre[i]); } System.out.println(scoreSum); } }2.3 提交结果思路1:暴力求解评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路2:动态规划评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路3:考虑每个位置的字符只出现一次的子串总数评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00109ms22.40MB输入 输出2正确10.0046ms22.40MBVIP特权3正确10.0078ms22.41MBVIP特权4正确10.0093ms22.39MBVIP特权5正确10.0078ms22.44MBVIP特权6正确10.00125ms23.34MBVIP特权7正确10.00125ms26.62MBVIP特权8正确10.00140ms26.70MBVIP特权9正确10.00109ms26.51MBVIP特权10正确10.00171ms26.66MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2858蓝桥杯试题 历届试题 子串分值和
-
蓝桥杯|历届真题:重复字符串 1.题目【问题描述】如果一个字符串S恰好可以由某个字符串重复K次得到,我们就称S是K次重复字符串。例如"abcabcabc”可以看作是"abc”重复3次得到,所以"abcabcabc”是3次重复字符串。同理"aaaaaa"既是2次重复字符串、又是3次重复字符串和6次重复字符串。现在给定一个字符串S,请你计算最少要修改其中几个字符,可以使S变为一个K次字符串?【输入格式】输入第一行包含一个整数K。第二行包含一个只含小写字母的字符串S。【输出格式】输出一个整数代表答案。如果S无法修改成K次重复字符串,输出-1。【样例输入】2 aabbaa【样例输出】2【评测用例规模与约定】对于所有评测用例,$1 \leq K \leq 100000,1 \leq |S| \leq 100000$。其中$|S|$表示$S$的长度。2. 题解2.1 思路分析先判断字符串长度是否是K的整数倍,不是则输出-1 若是,则将字符串分为K组,对每组的第i位统计得到各字符出现次数的最大值maxAppear 则要想将该字符串变为重复字符串在第i位上需要修改的最少的次数为K-maxAppear 对每一位需要做的最小修改进行求和即可得到最终的结果2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { int K = scanner.nextInt(); String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); if(len%K!=0){ System.out.println(-1); }else { int minChange = 0; int groupLen = len/K; for (int i = 0; i < groupLen; i++) {//将字符串分成K组 // 统计每组字符串第j位的哪个字符出现的次数最多得到次数 int maxAppear = 0; int[] charCounter = new int[26]; for (int j = 0; j < 26; j++) { charCounter[j]=0; } for (int j = 0; j < K; j++) { int tmpIndex = (int)(strChars[j*groupLen+i]-'a'); charCounter[tmpIndex] += 1; } for (int j = 0; j < 26; j++) { maxAppear = Math.max(maxAppear,charCounter[j]); } minChange += (K-maxAppear); } System.out.println(minChange); } } }2.3 提交结果1正确10.0062ms22.22MB输入 输出2正确10.0093ms22.30MBVIP特权3正确10.00109ms22.30MBVIP特权4正确10.0093ms22.26MBVIP特权5正确10.00109ms22.23MBVIP特权6正确10.0078ms22.29MBVIP特权7正确10.00140ms22.99MBVIP特权8正确10.00171ms25.62MBVIP特权9正确10.00125ms25.64MBVIP特权10错误0.00125ms24.57MBVIP特权暂未看出错在哪了参考资料http://lx.lanqiao.cn/problem.page?gpid=T2890