搜索到
361
篇与
的结果
-
 CenterOS7防火墙常用命令 查看防火墙是否关闭[root@localhost ~]# firewall-cmd --state not running [root@localhost ~]#开启防火墙[root@localhost ~]# systemctl start firewalld [root@localhost ~]# firewall-cmd --state running关闭防火墙[root@localhost ~]# systemctl stop firewalld [root@localhost ~]# firewall-cmd --state not running禁止firewall开机启动[root@localhost ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. 这样设置的话,下次重启开机的时候就会禁止firewall的启动,即关闭状态。设置firewall开机启动[root@localhost ~]# systemctl enable firewalld Created symlink from /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service to /usr/lib/systemd/system/firewalld.service. Created symlink from /etc/systemd/system/multi-user.target.wants/firewalld.service to /usr/lib/systemd/system/firewalld.service.参考资料CENTER OS7关闭防火墙:https://www.cnblogs.com/gucb/p/11156935.html
CenterOS7防火墙常用命令 查看防火墙是否关闭[root@localhost ~]# firewall-cmd --state not running [root@localhost ~]#开启防火墙[root@localhost ~]# systemctl start firewalld [root@localhost ~]# firewall-cmd --state running关闭防火墙[root@localhost ~]# systemctl stop firewalld [root@localhost ~]# firewall-cmd --state not running禁止firewall开机启动[root@localhost ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. 这样设置的话,下次重启开机的时候就会禁止firewall的启动,即关闭状态。设置firewall开机启动[root@localhost ~]# systemctl enable firewalld Created symlink from /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service to /usr/lib/systemd/system/firewalld.service. Created symlink from /etc/systemd/system/multi-user.target.wants/firewalld.service to /usr/lib/systemd/system/firewalld.service.参考资料CENTER OS7关闭防火墙:https://www.cnblogs.com/gucb/p/11156935.html -
CentOS7设置上网代理 CentOS设置上网代理1、网页上网网页上网设置代理很简单,在firefox浏览器下 Edit-->>Preferences-->>Advanced-->>Network在Connection下点击Settings,里面的manual proxy configuration里设置IP和PORT即可,2、系统环境代理设置设置全局代理修改 /etc/profile 文件,添加下面内容:http_proxy=http://username:password@yourproxy:8080/ https_proxy=https://username:password@yourproxy:8080/ export http_proxy export https_proxy如果没有密码限制,则以上内容可以修改为以下内容:http_proxy=http://yourproxy:8080/ https_proxy=https://yourproxy:8080/ export http_proxy export https_proxy针对某个用户设置代理只修改 ~/.bash_profile 文件,文件内容与上面的 /etc/profile 相同http_proxy=http://username:password@yourproxy:8080/ https_proxy=https://username:password@yourproxy:8080/ export http_proxy export https_proxy如果没有密码限制,则以上内容可以修改为以下内容:http_proxy=http://yourproxy:8080/ https_proxy=https://yourproxy:8080/ export http_proxy export https_proxy3、设置yum 的代理对于 yum 的代理,还要另外设置 /etc/yum.conf 文件vi /etc/yum.conf 添加以下代码:http_proxy=http://username:password@yourproxy:8080/ #若无密码限制,则为以下方式 http_proxy=http://yourproxy:8080/4、wget代理设置编辑文件为:/etc/wgetrcvi /etc/wgetrc添加下面两行:http_proxy=http://username:password@yourproxy:8080/ https_proxy=https://username:password@yourproxy:8080/ #若无密码限制,则为以下方式 http_proxy=http://yourproxy:8080/ https_proxy=https://yourproxy:8080/参考资料CentOS设置网络代理:https://blog.csdn.net/u013063153/article/details/78120945CentOS设置上网代理:https://blog.csdn.net/bohenzong1654/article/details/100964835?utm_medium=distribute.pc_relevant.none-task-blog-searchFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-searchFromBaidu-1.control
-
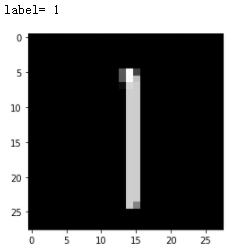
Pytorch 实战:卷积神经网络(CNN)实现MINIST手写数字识别 实验环境torch = 1.6.0torchvision = 0.7.0matplotlib = 3.3.3 # 绘图用progressbar = 2.5 # 绘制进度条用easydict # 超参数字典功能增强使用数据集手写数字集MINIST导入相关的包# 导包 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision from torchvision import datasets,transforms import matplotlib.pyplot as plt import random from progressbar import *设置超参数from easydict import EasyDict #增强python的dict的功能用 # 定义超参数 super_param = { "batch_size":256, "device": torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'), "epochs":10, "lr":0.3, } super_param = EasyDict(super_param) print(super_param){'batch_size': 16, 'device': device(type='cuda', index=0), 'epochs': 10, 'lr': 0.3, 'hidden_num': 15}数据处理(下载、处理、加载数据到DataLoader)# 下载、加载数据 # 构transform(pipeline),对图像做处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,)) #正则化 ]) # 下载数据 trainsets = datasets.MNIST('data',train=True,download=True,transform=transform) testsets = datasets.MNIST('data',train=False,download=True,transform=transform) # dataloader 加载数据 train_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True) test_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True)查看数据样例查看数据样例【单张】# 查看数据样例-单张 image,label = trainsets[random.randint(0,len(trainsets))] print('label=',label) plt.imshow(image.permute(1,2,0),cmap='gray') plt.show()查看数据样例【一批】# 查看数据样例-一批 images,labels = next(iter(test_loader)) data_sample_img = torchvision.utils.make_grid(images).numpy().transpose(1,2,0) print('labels=',labels) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(data_sample_img) plt.show()构建CNN网络模型 -简单版- 使用Sequential## 构建CNN模型-简单版-使用Sequential model = nn.Sequential( nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5,stride=1,padding=0),# b*1*28*28-->b*10*24*24 nn.ReLU(), nn.MaxPool2d(2),# b*10*24*24-->b*10*12*12 nn.Conv2d(10,20,3,1,0),# b*10*12*12-->b*20*10*10 nn.ReLU(), nn.Flatten(),#b*20*10*10-->b*2000 nn.Linear(2000,500),#b*2000-->b*500 nn.ReLU(), nn.Linear(500,10),#b*500-->b*10 nn.ReLU(), nn.Softmax(), ) print(model)Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): ReLU() (2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(10, 20, kernel_size=(3, 3), stride=(1, 1)) (4): ReLU() (5): Flatten(start_dim=1, end_dim=-1) (6): Linear(in_features=2000, out_features=500, bias=True) (7): ReLU() (8): Linear(in_features=500, out_features=10, bias=True) (9): ReLU() (10): Softmax(dim=None) )构建CNN网络模型 -使用自定义类# 构建网络模型 - 使用自定义类 class Digit_Rec(nn.Module): def __init__(self): super(Digit_Rec,self).__init__() self.conv1 = nn.Conv2d(1,10,5) #1:灰度图片的通道,10:输出通道,5:kernel self.relu1 = nn.ReLU() self.max_pool = nn.MaxPool2d(2,2) self.conv2 = nn.Conv2d(10,20,3) #10:输入通道,20:输出通道,3:Kernel self.relu2 = nn.ReLU() self.fc1 = nn.Linear(20*10*10,500) # 20*10*10:输入通道,500:输出通道 self.relu3 = nn.ReLU() self.fc2 = nn.Linear(500,10) # 500:输入通道,10:输出通道 self.relu4 = nn.ReLU() self.softmax = nn.Softmax(dim=1) def forward(self,x): batch_size = x.size(0) # x的格式:batch_size x 1 x 28 x 28 拿到了batch_size x = self.conv1(x) # 输入:batch*1*28*28 输出:batch*10*24*24 x = self.relu1(x) x = self.max_pool(x) # 输入:batch*10*24*24输出:batch*10*12*12 x = self.conv2(x) x = self.relu2(x) x = x.view(batch_size,-1) #fatten 展平 -1自动计算维度,20*10*10=2000 x = self.fc1(x) # 输入:batch*2000 输出:batch*500 x = self.relu3(x) x = self.fc2(x) # 输入:batch*500 输出:batch*10 x = self.relu4(x) output = self.softmax(x) # 计算分类后,每个数字的概率值 return output model = Digit_Rec() print(model)Digit_Rec( (conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (relu1): ReLU() (max_pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(10, 20, kernel_size=(3, 3), stride=(1, 1)) (relu2): ReLU() (fc1): Linear(in_features=2000, out_features=500, bias=True) (relu3): ReLU() (fc2): Linear(in_features=500, out_features=10, bias=True) (relu4): ReLU() (softmax): Softmax(dim=1) )定义损失函数和优化器# 定义损失函数和优化 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(),lr=super_param.lr)定义模型训练单个epoch函数# 定义模型训练单个epoch函数 def train_model_epoch(model,train_loader,super_param,criterion,optimzer,epoch): model.train()#训练声明 for batch_index,(images,labels) in enumerate(train_loader): # 数据上device images,labels = images.to(super_param.device),labels.to(super_param.device) # 梯度清零 optimzer.zero_grad() # 前向传播 output = model(images) # 计算损失 loss = criterion(output,labels) # 反向传播,计算梯度 loss.backward() # 参数更新(优化) optimzer.step() # 打印训练参考信息,每1000个batch打印一次 if batch_index % 1000 == 0: print("Epoch:{} Batch Index(batch_size={}):{}/{} Loss:{}". format(epoch,super_param.batch_size,batch_index,len(train_loader),loss.item()))定义模型验证方法# 定义模型验证方法 def test_model(model,test_loader,super_param,criterion): model.eval()#测试声明 # 数据统计 correct_num,test_loss = 0.0,0.0 #正确数,测试损失 #定义进度条 widgets = ['模型测试中: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=100).start() # 取消计算梯度,避免更新模型参数 with torch.no_grad(): for batch_index,(images,labels) in enumerate(test_loader): # 数据上devics images,labels = images.to(super_param.device),labels.to(super_param.device) # 模型预测 output = model(images) # 计算测试损失 test_loss += criterion(output,labels).item() # 确定预测结果是哪个数字 pred = output.argmax(dim=1) #argmax返回 值,索引 dim=1表示要索引 # 统计预测正确数量 correct_num += pred.eq(labels.view_as(pred)).sum().item() #更新进度条进度 pbar.update(batch_index/len(test_loader)*100) #释放进度条 pbar.finish() #打印测试信息 test_loss = test_loss/len(test_loader.dataset) test_accuracy = correct_num / len(test_loader.dataset) print("Test --- Avg Loss:{},Accuracy:{}\n".format(test_loss,test_accuracy)) return test_loss,test_accuracy模型训练和测试# 模型训练和测试 #模型上device mode = model.to(super_param.device) #记录每个epoch的测试数据、用于绘图 epoch_list = [] loss_list = [] accuracy_list = [] for epoch in range(super_param.epochs): train_model_epoch(model,train_loader,super_param,criterion,optimizer,epoch) test_loss,test_accuracy = test_model(model,test_loader,super_param,criterion) # 数据统计 epoch_list.append(epoch) loss_list.append(test_loss) accuracy_list.append(test_accuracy)查看数据统计结果# 查看数据统计结果 fig = plt.figure(figsize=(12,12),dpi=70) #子图1 ax1 = plt.subplot(2,1,1) title = "bach_size={},lr={}".format(super_param.batch_size,super_param.lr) plt.title(title,fontsize=15) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Loss',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,loss_list) #子图2 ax2 = plt.subplot(2,1,2) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Accuracy',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,accuracy_list,'r') plt.show()
-
Pytorch 实战:BP神经网络实现MINIST实现手写数字识别(单层感知机) Pytorch 实战:BP神经网络实现MINIST实现手写数字识别(单层感知机)实验环境torch = 1.6.0torchvision = 0.7.0matplotlib = 3.3.3 # 绘图用progressbar = 2.5 # 绘制进度条用easydict # 超参数字典功能增强使用数据集手写数字集MINIST导入相关的包# 导包 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader import torchvision from torchvision import datasets,transforms import matplotlib.pyplot as plt import random from progressbar import *设置超参数from easydict import EasyDict #增强python的dict的功能用 # 定义超参数 super_param = { "batch_size":128, "device": torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'), "epochs":10, "lr":0.3, 'hidden_num':15, #隐藏层神经元数量 } super_param = EasyDict(super_param) print(super_param){'batch_size': 16, 'device': device(type='cuda', index=0), 'epochs': 10, 'lr': 0.3, 'hidden_num': 15}数据处理(下载、处理、加载数据到DataLoader)# 下载、加载数据 # 构transform(pipeline),对图像做处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,)) #正则化 ]) # 下载数据 trainsets = datasets.MNIST('data',train=True,download=True,transform=transform) testsets = datasets.MNIST('data',train=False,download=True,transform=transform) # dataloader 加载数据 train_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True) test_loader = DataLoader(trainsets,batch_size=super_param.batch_size,shuffle=True)查看数据样例查看数据样例【单张】# 查看数据样例-单张 image,label = trainsets[random.randint(0,len(trainsets))] print('label=',label) plt.imshow(image.permute(1,2,0),cmap='gray') plt.show()查看数据样例【一批】# 查看数据样例-一批 images,labels = next(iter(test_loader)) data_sample_img = torchvision.utils.make_grid(images).numpy().transpose(1,2,0) print('labels=',labels) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(data_sample_img) plt.show()构建BP网络模型 -简单版- 使用Sequential## 构建网络模型-BP model = nn.Sequential( nn.Flatten(), nn.Linear(28*28,super_param.hidden_num), nn.ReLU(), nn.Linear(super_param.hidden_num,10), nn.ReLU(), nn.Softmax(), ) print(model)Sequential( (0): Flatten() (1): Linear(in_features=784, out_features=15, bias=True) (2): ReLU() (3): Linear(in_features=15, out_features=10, bias=True) (4): ReLU() (5): Softmax(dim=None) )构建BP网络模型 -使用自定义类## 构建BP网络模型 -使用自定义类 class Digit_Rec(nn.Module): def __init__(self,hidden_num): super(Digit_Rec,self).__init__() self.fc1 = nn.Linear(28*28,hidden_num) self.relu1 = nn.ReLU() self.fc2 = nn.Linear(hidden_num,10) self.relu2 = nn.ReLU() self.softmax = nn.Softmax(dim=1) def forward(self,x): batch_size = x.size(0) # x的格式:batch_size x 1 x 28 x 28 拿到了batch_size x = x.view(batch_size,28*28) # flatten out = self.fc1(x) out = self.relu1(out) out = self.fc2(out) out = self.relu2(out) out = self.softmax(out) return out model = Digit_Rec(super_param.hidden_num) print(model)Digit_Rec( (fc1): Linear(in_features=784, out_features=50, bias=True) (relu1): ReLU() (fc2): Linear(in_features=50, out_features=10, bias=True) (relu2): ReLU() (softmax): Softmax(dim=1) )定义损失函数和优化器# 定义损失函数和优化 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(),lr=super_param.lr)定义模型训练单个epoch函数# 定义模型训练单个epoch函数 def train_model_epoch(model,train_loader,super_param,criterion,optimzer,epoch): model.train()#训练声明 for batch_index,(images,labels) in enumerate(train_loader): # 数据上device images,labels = images.to(super_param.device),labels.to(super_param.device) # 梯度清零 optimzer.zero_grad() # 前向传播 output = model(images) # 计算损失 loss = criterion(output,labels) # 反向传播,计算梯度 loss.backward() # 参数更新(优化) optimzer.step() # 打印训练参考信息,每1000个batch打印一次 if batch_index % 1000 == 0: print("Epoch:{} Batch Index(batch_size={}):{}/{} Loss:{}". format(epoch,super_param.batch_size,batch_index,len(train_loader),loss.item()))定义模型验证方法# 定义模型验证方法 def test_model(model,test_loader,super_param,criterion): model.eval()#测试声明 # 数据统计 correct_num,test_loss = 0.0,0.0 #正确数,测试损失 #定义进度条 widgets = ['模型测试中: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()] pbar = ProgressBar(widgets=widgets, maxval=100).start() # 取消计算梯度,避免更新模型参数 with torch.no_grad(): for batch_index,(images,labels) in enumerate(test_loader): # 数据上devics images,labels = images.to(super_param.device),labels.to(super_param.device) # 模型预测 output = model(images) # 计算测试损失 test_loss += criterion(output,labels).item() # 确定预测结果是哪个数字 pred = output.argmax(dim=1) #argmax返回 值,索引 dim=1表示要索引 # 统计预测正确数量 correct_num += pred.eq(labels.view_as(pred)).sum().item() #更新进度条进度 pbar.update(batch_index/len(test_loader)*100) #释放进度条 pbar.finish() #打印测试信息 test_loss = test_loss/len(test_loader.dataset) test_accuracy = correct_num / len(test_loader.dataset) print("Test --- Avg Loss:{},Accuracy:{}\n".format(test_loss,test_accuracy)) return test_loss,test_accuracy模型训练和测试# 模型训练和测试 #模型上device mode = model.to(super_param.device) #记录每个epoch的测试数据、用于绘图 epoch_list = [] loss_list = [] accuracy_list = [] for epoch in range(super_param.epochs): train_model_epoch(model,train_loader,super_param,criterion,optimizer,epoch) test_loss,test_accuracy = test_model(model,test_loader,super_param,criterion) # 数据统计 epoch_list.append(epoch) loss_list.append(test_loss) accuracy_list.append(test_accuracy)查看数据统计结果# 查看数据统计结果 fig = plt.figure(figsize=(12,12),dpi=70) #子图1 ax1 = plt.subplot(2,1,1) title = "hidden_neuron_num={},bach_size={},lr={}".format(super_param.hidden_num,super_param.batch_size,super_param.lr) plt.title(title,fontsize=15) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Loss',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,loss_list) #子图2 ax2 = plt.subplot(2,1,2) plt.xlabel('Epochs',fontsize=15) plt.ylabel('Accuracy',fontsize=15) plt.xticks(fontsize=13) plt.yticks(fontsize=13) plt.plot(epoch_list,accuracy_list,'r') plt.show()隐藏层神经元数量=15隐藏层神经元数量=30隐藏层神经元数量=50
-
linux 路由表设置 之 route 指令详解 linux 路由表设置 之 route 指令详解3 种路由类型主机路由主机路由是路由选择表中指向单个IP地址或主机名的路由记录。主机路由的Flags字段为H。例如,在下面的示例中,本地主机通过IP地址192.168.1.1的路由器到达IP地址为10.0.0.10的主机。Destination Gateway Genmask Flags Metric Ref Use Iface ----------- ------- ------- ----- ------ --- --- ----- 10.0.0.10 192.168.1.1 255.255.255.255 UH 0 0 0 eth0网络路由网络路由是代表主机可以到达的网络。网络路由的Flags字段为N。例如,在下面的示例中,本地主机将发送到网络192.19.12的数据包转发到IP地址为192.168.1.1的路由器。Destination Gateway Genmask Flags Metric Ref Use Iface ----------- ------- ------- ----- ----- --- --- ----- 192.19.12 192.168.1.1 255.255.255.0 UN 0 0 0 eth0默认路由当主机不能在路由表中查找到目标主机的IP地址或网络路由时,数据包就被发送到默认路由(默认网关)上。默认路由的Flags字段为G。例如,在下面的示例中,默认路由是IP地址为192.168.1.1的路由器。Destination Gateway Genmask Flags Metric Ref Use Iface ----------- ------- ------- ----- ------ --- --- ----- default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0route 命令格式设置和查看路由表都可以用 route 命令,设置内核路由表的命令格式是:# route [add|del] [-net|-host] target [netmask Nm] [gw Gw] [[dev] If]其中:add : 添加一条路由规则del : 删除一条路由规则-net : 目的地址是一个网络-host : 目的地址是一个主机target : 目的网络或主机netmask : 目的地址的网络掩码gw : 路由数据包通过的网关dev : 为路由指定的网络接口route 命令使用查看路由表route命令查看 Linux 内核路由表# route Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.0.0 * 255.255.255.0 U 0 0 0 eth0 169.254.0.0 * 255.255.0.0 U 0 0 0 eth0 default 192.168.0.1 0.0.0.0 UG 0 0 0 eth0 # route 目标 网关 子网掩码 标志 跃点 引用 使用 接口 192.168.0.0 * 255.255.255.0 U 0 0 0 eth0 169.254.0.0 * 255.255.0.0 U 0 0 0 eth0 default 192.168.0.1 0.0.0.0 UG 0 0 0 eth0 route 命令的输出项说明字段含义Destination(目标)目标网段或者主机Gateway(网关)网关地址,”*” 表示目标是本主机所属的网络,不需要路由Genmask(子网掩码)网络掩码Flags(标志)标记。一些可能的标记如下: U — 路由是活动的 H — 目标是一个主机 G — 路由指向网关 R — 恢复动态路由产生的表项 D — 由路由的后台程序动态地安装 M — 由路由的后台程序修改 ! — 拒绝路由Metric(跃点)路由距离,到达指定网络所需的中转数(linux 内核中没有使用)Ref(引用)路由项引用次数(linux 内核中没有使用)Use(使用)此路由项被路由软件查找的次数Iface(接口)该路由表项对应的输出接口修改路由表添加路由添加到主机的路由# route add -host 192.168.1.2 dev eth0 # route add -host 10.20.30.148 gw 10.20.30.40 #添加到10.20.30.148的路由记录添加到网络的路由# route add -net 10.20.30.40 netmask 255.255.255.248 eth0 #添加10.20.30.40的网络 # route add -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41 #添加10.20.30.48的网络 # route add -net 192.168.1.0/24 eth1添加默认路由(网关)# route add default gw 192.168.1.1删除路由删除到主机的路由# route del -host 192.168.1.2 dev eth0:0 # route del -host 10.20.30.148 gw 10.20.30.40删除到网络的路由# route del -net 10.20.30.40 netmask 255.255.255.248 eth0 # route del -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41 # route del -net 192.168.1.0/24 eth1删除默认网关# route del default gw 192.168.1.1屏蔽路由# route add -net 224.0.0.0 netmask 240.0.0.0 reject查看结果Destination Gateway Genmask Flags Metric Ref Use Iface 224.0.0.0 - 240.0.0.0 ! 0 - 0 -说明:增加一条屏蔽的路由,目的地址为 224.x.x.x 将被拒绝参考资料linux 路由表设置 之 route 指令详解:https://blog.csdn.net/chenlycly/article/details/52141854
-
progressbar:python进度条功能 1.安装progressbar安装:pip install progressbar2.使用2.1 用法一import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) progress = ProgressBar() for i in progress(range(1000)): dosomework()用法一显示效果5% |### | 100% |#########################################################################|2.2 用法二import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) pbar = ProgressBar().start() for i in range(1000): pbar.update(int((i / (total - 1)) * 100)) dosomework() pbar.finish()用法二显示效果5% |### | 100% |#########################################################################|2.3 用法三import time from progressbar import * total = 1000 def dosomework(): time.sleep(0.01) widgets = ['Progress: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA(), ' ', FileTransferSpeed()] pbar = ProgressBar(widgets=widgets, maxval=10*total).start() for i in range(total): # do something pbar.update(10 * i + 1) dosomework() pbar.finish()widgets可选参数含义:Progress: ' :设置进度条前显示的文字Percentage() :显示百分比Bar('#') : 设置进度条形状Timer() :显示已用时间ETA() : 显示预计剩余时间用法三显示效果Progress: 100% |#############| Elapsed Time: 0:00:10 Time: 0:00:10 981.79 B/s
-
Python中将dataframe转换为字典 Python中将dataframe转换为字典有时候,在Python中需要将dataframe类型转换为字典类型,下面的方法帮助我们解决这一问题。构造dataframeimport pandas as pd a = ['Name', 'Age', 'Gender'] b = ['Ali', '19', 'China'] data = pd.DataFrame(zip(a, b), columns=['project', 'attribute']) print datadataframe转换为字典dict_country = data.set_index('project').T.to_dict('list') print dict_country结果 project attribute 0 Name Ali 1 Age 19 2 Gender China {'Gender': ['China'], 'Age': ['19'], 'Name': ['Ali']}注意事项转置之前需要设置指定的索引,否则会按照默认索引转换成这样:{0: ['Name', 'Ali'], 1: ['Age', '19'], 2: ['Gender', 'China']}参考资料Python中将dataframe转换为字典:https://blog.csdn.net/yuanxiang01/article/details/79634632
-
Python中的三目运算符 Python中的三目运算符语法格式Python语言不像Java、JavaScript等这些语言有类似: 判段的条件?条件为真时的结果:条件为假时的结果这样的三目运算,但是Python也有自己的三目运算符: 条件为真时的结果 if 判段的条件 else 条件为假时的结果举例例一:编写一个Python程序,输入两个数,比较它们的大小并输出其中较大者。x = int(input("please enter first integer:")) y = int(input("please enter second integer:")) #一般的写法 if (x == y): print("两数相同!") elif(x > y): print("较大的数为:",x) else: print("较大的数为:",y) # 三目运算符写法 print(x if(x>y) else y)
-
Ubuntu 修改用户的 Shell & 添加用户时指定 Shell Ubuntu 修改用户的 Shell & 添加用户时指定 Shell修改用户的 Shell如果你没有管理员权限, 那么你只能修改自己的 Shell, 输入 chsh 命令.chsh这时你会获得提醒, 要求输入新的 Shell 应用路径. 如果你要换成 bash, 请输入 /bin/bash 并回车确认.Enter the new value, or press ENTER for the default Login Shell [/bin/sh]:/bin/bash如果你是牛逼的管理员, 那么恭喜你, 除了使用 chsh 命令, 你还可以通过修改配置文件批量修改. vim /etc/passwd打开 /etc/passwd 文件, 你将看到所有用户及其使用的 Shell, 会有很多行类似这样的内容, 每行是一个用户.jupiter:x:1000:1000:jupiter,,,:/home/jupiter:/bin/sh这里只需要件 /bin/sh 改成 /bin/bash 即可.jupiter:x:1000:1000:jupiter,,,:/home/jupiter:/bin/bash添加用户时指定 Shelluseradd -s /bin/bash {用户昵称}参考资料修改 Ubuntu 用户的 Shell:https://blog.csdn.net/fightforyourdream/article/details/17609337
-
Python将字典中的键值对反转方法 Python将字典中的键值对反转方法应用背景(问题示例)src:{'1': 0, '10': 1, '100': 2, '11': 3, '12': 4, '13': 5, '14': 6, '15': 7, '16': 8, '17': 9, '18': 10, '19': 11, '2': 12, '20': 13, '21': 14, '22': 15, '23': 16, '24': 17, '25': 18, '26': 19, '27': 20, '28': 21, '29': 22, '3': 23, '30': 24, '31': 25, '32': 26, '33': 27, '34': 28, '35': 29, '36': 30, '37': 31, '38': 32, '39': 33, '4': 34, '40': 35, '41': 36, '42': 37, '43': 38, '44': 39, '45': 40, '46': 41, '47': 42, '48': 43, '49': 44, '5': 45, '50': 46, '51': 47, '52': 48, '53': 49, '54': 50, '55': 51, '56': 52, '57': 53, '58': 54, '59': 55, '6': 56, '60': 57, '61': 58, '62': 59, '63': 60, '64': 61, '65': 62, '66': 63, '67': 64, '68': 65, '69': 66, '7': 67, '70': 68, '71': 69, '72': 70, '73': 71, '74': 72, '75': 73, '76': 74, '77': 75, '78': 76, '79': 77, '8': 78, '80': 79, '81': 80, '82': 81, '83': 82, '84': 83, '85': 84, '86': 85, '87': 86, '88': 87, '89': 88, '9': 89, '90': 90, '91': 91, '92': 92, '93': 93, '94': 94, '95': 95, '96': 96, '97': 97, '98': 98, '99': 99}dst:{0: '1', 1: '10', 2: '100', 3: '11', 4: '12', 5: '13', 6: '14', 7: '15', 8: '16', 9: '17', 10: '18', 11: '19', 12: '2', 13: '20', 14: '21', 15: '22', 16: '23', 17: '24', 18: '25', 19: '26', 20: '27', 21: '28', 22: '29', 23: '3', 24: '30', 25: '31', 26: '32', 27: '33', 28: '34', 29: '35', 30: '36', 31: '37', 32: '38', 33: '39', 34: '4', 35: '40', 36: '41', 37: '42', 38: '43', 39: '44', 40: '45', 41: '46', 42: '47', 43: '48', 44: '49', 45: '5', 46: '50', 47: '51', 48: '52', 49: '53', 50: '54', 51: '55', 52: '56', 53: '57', 54: '58', 55: '59', 56: '6', 57: '60', 58: '61', 59: '62', 60: '63', 61: '64', 62: '65', 63: '66', 64: '67', 65: '68', 66: '69', 67: '7', 68: '70', 69: '71', 70: '72', 71: '73', 72: '74', 73: '75', 74: '76', 75: '77', 76: '78', 77: '79', 78: '8', 79: '80', 80: '81', 81: '82', 82: '83', 83: '84', 84: '85', 85: '86', 86: '87', 87: '88', 88: '89', 89: '9', 90: '90', 91: '91', 92: '92', 93: '93', 94: '94', 95: '95', 96: '96', 97: '97', 98: '98', 99: '99'}具体方法第一种:dict={"a":1,"b":2,"c":3} inverse_dic={} for key,val in dict.items(): inverse_dic[val]=key第二种(推荐):dict_list={"a":1,"b":2,"c":3} inverse_dict=dict([val,key] for key,val in dict_list.items())第三种:dict_list={"a":1,"b":2,"c":3} mydict_new=dict(zip(dict_list.values(),dict_list.keys())参考资料Python将字典中的键值对反转方法:https://blog.csdn.net/ityti/article/details/85098699
-
各类比赛数据集 各类比赛数据集【注意】所有数据仅限于科研所用,请勿用于商业用途!【Kaggle比赛】1.Kaggle-猫狗大战链接:https://pan.baidu.com/s/1cnnZXytaaCQjtsAxYE2s1w 密码:2mpc2.Kaggle-LUNA 2016肺部CT图像链接:https://pan.baidu.com/s/1S6VohLttXAr0dyx4qYx1Dw 密码:hy1b3.Kaggle-DSB2018链接:https://pan.baidu.com/s/10jbEZ6v6_mwoios08RlCSA 密码:74jr4.Kaggle-DSB2017链接:https://pan.baidu.com/s/1Io7IbusxfTe-SkfrvRNjOA 密码:vazw【天池大赛】1.天池大赛-肺部结节诊断链接:https://pan.baidu.com/s/1NDYJcXGqXf4uGgNkYVAG3Q 密码:84e52.Fashion-AI 服饰关键点定位链接:https://pan.baidu.com/s/1ZXzHCdbfTuegjSv8IFewOQ 密码:lhx53.Fashion-AI 服饰属性标签识别链接:https://pan.baidu.com/s/1DprZywohaqIioTvcNKzLFA 密码:0dom4.全球数据智能大赛(2019)——肺部CT多病种智能诊断链接:https://pan.baidu.com/s/1lZpJrJuER6NPnlcE2SQmWw 密码:0ng9【AI全球挑战赛】1.AI挑战赛-场景分类链接:https://pan.baidu.com/s/1rBqy7rUXrcLgeX45IRrHUQ 密码:7kn12.AI挑战赛-图像中文描述链接:https://pan.baidu.com/s/1m-yFj6ST2KJlx7D77de6DQ 密码:cprk【ICDAR比赛】1.ICDAR 2015自然场景文字识别数据链接:https://pan.baidu.com/s/1q03Lkat8Xw92iKJ8lhsqYw 密码:surk2.ICDAR 2017自然场景文字识别数据链接:https://pan.baidu.com/s/1UusfROUT4btNnoXF9yjdNw 密码:ndsa3.ICDAR 2019扫描小票数据(SROIE)链接:https://pan.baidu.com/s/1-2bYU6ufWOVNuxqzGuq2pQ 密码:uubm 4.ICDAR 2019商家招牌文本检测识别数据(ReCTS)链接:https://pan.baidu.com/s/1aJyJzOgSPVLZ6hoRilG8pw 密码:hcdp 5.ICDAR 2019自然场景文字识别数据(LSVT)链接:https://pan.baidu.com/s/1oJ2pPClwgXTKPIidElWi0Q 密码:x6ct 【其他类】1.RIDER LUNG CT 肺癌CT图像链接:https://pan.baidu.com/s/1n500txInMzoU1TUbqQQWUw 密码:ddpa2.RIDER Breast MRI数据链接:https://pan.baidu.com/s/1aEZjiR8_uvJLDvjOxTtG8Q 密码:s60s3.2018百度西交大大数据竞赛-商家招牌的分类与检测链接:https://pan.baidu.com/s/1jkNIaWPzEOKEx363iDrmCA 密码:ylyj4.Fundus Image Registration(FIRE) 眼底图像数据链接:https://pan.baidu.com/s/1sgDmo5rTe-HjsmFDhtKh1Q 密码:w7jm5.Digital Retinal Images for Vessel Extraction(DRIVE)眼底血管图像数据集链接:https://pan.baidu.com/s/1UpQtbhgtVdlqc0QGbESx3A 密码:4l7v参考资料各类比赛数据集:https://blog.csdn.net/u013063099/article/details/79467531
-
Python3实现局域网存活主机扫描(多线程) Python3实现局域网存活主机扫描import os import time import platform import threading def get_os(): ''''' get os 类型 ''' os = platform.system() if os == "Windows": return "n" else: return "c" def ping_ip(ip_str): cmd = ["ping", "-{op}".format(op=get_os()), "1", ip_str] output = os.popen(" ".join(cmd)).readlines() flag = False for line in list(output): if not line: continue if str(line).upper().find("TTL") >=0: flag = True break if flag: print("ip: %s is ok ***"%ip_str) def find_ip(ip_prefix): ''''' 给出当前的127.0.0 ,然后扫描整个段所有地址 ''' for i in range(1,256): ip = '%s.%s'%(ip_prefix,i) t = threading.Thread(target=ping_ip, args=(ip,)) # 注意传入的参数一定是一个元组! t.start() if __name__ == "__main__": print("start time %s"%time.ctime()) ip_prefix = "10.1.130" find_ip(ip_prefix) print("end time %s"%time.ctime())
-
YOLOv1学习:(二)损失函数理解和实现 YOLOv1学习:(二)损失函数理解和实现损失函数形式损失函数理解1预测框的中心点(x, y) 造成的损失(即对损失函数有贡献)是图中的第一行。其中$||_{ij}^{obj}$为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。预测框的高度(w, h)造成的损失(即对损失函数有贡献)是图中的第二行。其中 $||_{ij}^{obj}$为控制函数,含义与预测中心一样。1、2项就是边框回归。第三行与第四行,都是预测框的置信度C。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积)。其中第三行函数的$||_{ij}^{obj}$依然为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。第四行的$||_{ij}^{obj}$也控制函数,只是含义与第三项的相反,在标签中不含物体的那些格点处,该值为1;若格点含有物体,该值为 0。也就是只对那些没有真实物体所属的格点进行损失计算,若该格点包含物体(包含物体置信度损失已经在第三项计算了)则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。第五行为物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。其中此项$||_{ij}^{obj}$也为控制函数,在标签中包含物体的那些格点处,该值为1;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行物体类别损失计算,若该格点不包含物体则不进行此项损失计算,因此预测数值不对此项损失函数造成影响(因为这个预测数值根本不带入此项损失函数计算)。此时再来看${\lambda}_{coord}$ 与${\lambda}_{noobj}$ ,Yolo面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中49个格点,含有物体的格点往往只有3、4个,其余全是不含有物体的格点。此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。因此${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, ${\lambda}_{coord}$ 与 ${\lambda}_{noobj}$ 的取值分别为5与0.5。损失函数理解2-损失函数分为三个部分$$ ||_{ij}^{obj}表示cell中是否含有真实物体的中心,含有则1,否则取0 $$① 坐标误差为什么宽和高要带根号???对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width(主要为了平衡小目标检测预测的偏移)② IOU误差这里的$\hat{C_i}$分别表示 1 和 0 $,C_i=Pr(Object)*IOU_{pred}^{truth}$③ 分类误差这个很容易理解(激活函数的输出)。损失函数代码实现实现""" + input + pred: (batch_size,30,7,7)的网络输出数据 + labels: (batch_size,30,7,7)的样本标签数据 + output + 当前批次样本的平均损失 """ """ + YOLOv1 的损失分为3部分 + 坐标预测损失 + 置信度预测损失 + 含object的box的confidence预测损失 + 不含object的box的confidence预测损失 + 类别预测损失 """ class Loss_YOLOv1(nn.Module): def __init__(self,batch_size=1): super(Loss_YOLOv1,self).__init__() self.batch_size = batch_size """ box格式转换 + input + src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h] + output + dst_box : [box_x1,box_y1,box_x2,box_y2] """ def convert_box_type(self,src_box): x,y,w,h = tuple(src_box) x1,y1 = x,y x2,y2 = x+w,y+w return [x1,y1,x2,y2] """ iou计算 """ def cal_iou(self,box1,box2): # 求相交区域左上角的坐标和右下角的坐标 box_intersect_x1 = max(box1[0], box2[0]) box_intersect_y1 = max(box1[1], box2[1]) box_intersect_x2 = min(box1[2], box2[2]) box_intersect_y2 = min(box1[3], box2[3]) # 求二者相交的面积 area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1) # 求box1,box2的面积 area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1]) area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 求二者相并的面积 area_union = area_box1 + area_box2 - area_intersect # 计算iou(交并比) iou = area_intersect / area_union return iou def forward(self,pred,target): lambda_noobj = 0.5 # lambda_noobj参数 lambda_coord = 5 # lambda_coord参数 site_pred_loss = 0 # 坐标预测损失 obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失 noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失 class_pred_loss = 0 # 类别预测损失 for batch_size_index in range(self.batch_size): # batchsize循环 for x_index in range(7): # x方向网格循环 for y_index in range(7): # y方向网格循环 # 获取单个网格的预测数据和真实数据 pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20] true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20] if true_data[4]==1:# 如果包含物体 # 解析预测数据和真实数据 pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1] pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2] true_box_confidence = true_data[0:5] # [x,y,w,h,confidence] # 获取两个预测box并计算与真实box的iou iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4])) iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4])) # 在两个box中选择iou大的box负责预测物体 if iou1 >= iou2: better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2 better_iou,bad_iou = iou1,iou2 else: better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1 better_iou,bad_iou = iou2,iou1 # 计算坐标预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失 site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失 # 计算含object的box的confidence预测损失 obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2 # iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中 # 因此还需计算不含object的box的confidence预测损失 noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2 # 计算类别损失 class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2) else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss # [4,9]代表取两个预测框的confidence noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2) loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss return loss/self.batch_size调用测试label1 = torch.rand([1,30,7,7]) label2 = torch.rand([1,30,7,7]) print(label1.shape,label2.shape) print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7]) tensor(14.6910)参考资料YOLO V1损失函数理解:http://www.likecs.com/show-65912.htmlYOLOv1算法理解:https://www.cnblogs.com/ywheunji/p/10808989.html【目标检测系列】yolov1的损失函数详解(结合pytorch代码):https://blog.csdn.net/gbz3300255/article/details/109179751yolo-yolo v1损失函数理解:https://blog.csdn.net/qq_38236744/article/details/106724596
-
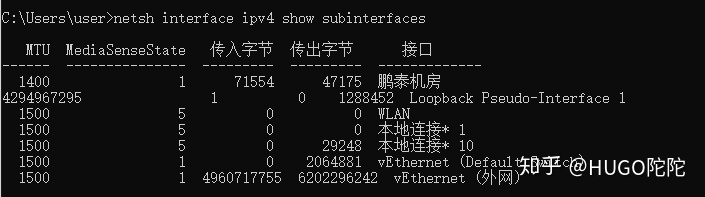
ubuntu 16.04 pptp搭建服务端和客户端及异常处理 服务端1. 安装pptpsudo apt-get install pptpd2. 修改pptpd.conf中的配置信息sudo vim /etc/pptpd.conf在末尾增加下面两行,或者打开的内容里面找到这两行,取消掉注释localip 192.168.0.1 remoteip 192.168.0.234-238,192.168.0.245分别为创建pptp时的主机ip和连接pptp的其他主机使用的ip段,可以自行修改。注意,这里的ip并不是指外网ip或者当前局域网ip,而是指创建(虚拟专用网络)会分配的ip地址。一般这个可以不用修改。3. 修改chap-secrets配置连接pptp 所需要的账号和密码,修改配置文件/etc/ppp/chap-secretssudo vim /etc/ppp/chap-secrets在末尾添加以下内容#用户名 pptpd 密码 * neo pptpd 123456 *末尾的表示可以使用任意IP连入,如果你要设置指定IP才能连接,可以将替换成对应的IP。支持添加多个账号。4. 设置ms-dns配置使用的dns,修改配置文件sudo vim /etc/ppp/pptpd-options在末尾增加下面两行,或者打开的内容里面找到这两行,取消掉注释# 这是谷歌的DNS 可以根据实际填写 ms-dns 8.8.8.8 ms-dns 8.8.4.45. 开启转发修改配置文件sudo vim /etc/sysctl.conf在末尾增加下面内容,或者打开的内容里面找到这一行,取消掉注释net.ipv4.ip_forward=1保存之后执行sudo sysctl -p6. 配置iptables若未安装iptables 执行脚本安装sudo apt-get install iptablestips:若之前安装pptp失败的。执行以下脚本;如果是第一次安装可忽略以下内容(目的为了清除iptables里旧的规则)sudo iptables -F sudo iptables -X sudo iptables -t nat -F sudo iptables -t nat -X然后,允许GRE协议以及1723端口、47端口:sudo iptables -A INPUT -p gre -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1723 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 47 -j ACCEPT7.下一步,开启NAT转发:sudo iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eno33 -j MASQUERADE注意,上面的eno33是连接网络的网卡的名称,不同机器这个可能是不一样的。可以在终端输入ifconfig来查看。例如neo@ubuntu:~$ ifconfig ens33 Link encap:Ethernet HWaddr 00:0c:29:37:79:85 inet addr:xxx.xxx.xxx.xxx Bcast:xxx.xxx.xxx.xxx Mask:255.255.255.0 inet6 addr: xxxx::20c:29ff:fe37:xxxx/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:293 errors:0 dropped:0 overruns:0 frame:0 TX packets:211 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:26801 (26.8 KB) TX bytes:41763 (41.7 KB)8 重启pptp服务sudo service pptpd restartubuntu客户端1. 安装pptp客户端sudo apt-get install pptp-linux2. 初始化一个连接通道:mypptp使用服务端设置的账号密码neo/6yhn^YHNsudo pptpsetup --create mypptp --server xxx.xxx.xxx.xxx --username neo --password 6yhn^YHN --encrypt --startxxx.xxx.xxx.xxx是pptp mypptp服务端的ip地址 根据实际情况填写(以下示例)root@ubuntu:~# sudo pptpsetup --create mypptp --server 172.31.1.112 --username neo --password 6yhn^YHN --encrypt --start Using interface ppp0 Connect: ppp0 <--> /dev/pts/2 CHAP authentication succeeded MPPE 128-bit stateless compression enabled local IP address 192.168.0.234 remote IP address 192.168.0.13. 查看连接是否成功root@ubuntu:~# ip addr show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:xx:86:5f brd ff:ff:ff:ff:ff:ff inet .31.1.113/24 brd xxx.31.1.2xxx5 scope global ens33 valid_lft forever preferred_lft forever inet6 fxx0::20c:29ff:fxx3e:8xxf/64 scope link valid_lft forever preferred_lft forever 8: ppp0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1496 qdisc pfifo_fast state UNKNOWN group default qlen 3 link/ppp inet 192.168.0.234 peer 192.168.0.1/32 scope global ppp0 valid_lft forever preferred_lft forever也可以在pptp 服务端查看neo@ubuntu:~$ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 xxx.xxx.1.1 0.0.0.0 UG 0 0 0 ens33 xxx.xxx.1.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33 192.168.0.234 0.0.0.0 255.255.255.255 UH 0 0 0 ppp04. 断开重启pptp客户端断开连接poff mypptp重接mypptppon mypptp5. 处理错误LCP: timeout sending Config-Requests执行:sudo modprobe nf_conntrack_pptp异常处理1.PPTP连接后无法打开网页,但QQ等软件又能使用的原因和解决方案PPTP连接后,能正常PING通局域网IP,DNS的IP,也能PING通百度这些网站的IP,但是网站偏偏打不开。直接PING域名,发现DNS也能解析域名,证明不是DNS出现的问题。在CMD里输入netsh interface ipv4 show subinterfaces发现PPTP连接“鹏泰机房”的MTU值是1400。而其它的连接都是1500。会不会是MTU没有自动协商造成了网络拥堵。参照下面这篇文章的方法PPTP拨入成功后在CMD里输入netsh interface ipv4 set subinterface "鹏泰机房" mtu=1400 store=persistent把pptp连接MTU固定修改为1400后。如飞的页面又能打开了。2.如果还是有些网页打不开服务器端执行iptables -I FORWARD -p tcp --syn -i ppp0 -j TCPMSS --set-mss 1356 或iptables -A FORWARD -p tcp --syn -s 192.168.0.0/24 -j TCPMSS --set-mss 1356参考资料ubuntu 16.04 pptp搭建服务端和客户端:https://blog.csdn.net/yanghao937170/article/details/105953256分析PPTP连接后无法打开网页,但QQ等软件又能使用的原因和解决方案:https://zhuanlan.zhihu.com/p/250068405PPTP MTU值设置导致主机无法上网问题解决:http://www.361way.com/pptp-mtu-mss/5173.html
-
被窝网电视剧爬虫 被窝网电视剧爬虫#抓取电视剧 from bs4 import BeautifulSoup from urllib.request import urlopen import urllib import re import requests import os from tqdm import tqdm def download_from_url(url, dst): """ @param: url to download file @param: dst place to put the file :return: bool """ # 获取文件长度 try: file_size = int(urlopen(url).info().get('Content-Length', -1)) except Exception as e: print(e) print("错误,访问url: %s 异常" % url) return False # 判断本地文件存在时 if os.path.exists(dst): # 获取文件大小 first_byte = os.path.getsize(dst) else: # 初始大小为0 first_byte = 0 # 判断大小一致,表示本地文件存在 if first_byte >= file_size: print("文件已经存在,无需下载") return file_size header = {"Range": "bytes=%s-%s" % (first_byte, file_size)} pbar = tqdm( total=file_size, initial=first_byte, unit='B', unit_scale=True, desc=url.split('/')[-1]) # 访问url进行下载 req = requests.get(url, headers=header, stream=True) try: with(open(dst, 'ab')) as f: for chunk in req.iter_content(chunk_size=1024): if chunk: f.write(chunk) pbar.update(1024) except Exception as e: print(e) return False pbar.close() return True #网站根地址 web_base_url="http://10.1.48.113/" vedio_episodes_page_url_list=[ "http://10.1.48.113/shipin/dianshijuji/2018-09-29/193.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/242.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/239.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/240.php", "http://10.1.48.113/shipin/dianshijuji/2018-10-26/238.php", "http://10.1.48.113/shipin/dianshijuji/2018-09-22/157.php" ] for vedio_episodes_page_url in vedio_episodes_page_url_list: #逐部电视剧解析 try: vedio_episodes_page_html = urlopen(vedio_episodes_page_url).read().decode('utf-8') vedio_episodes_page_soup = BeautifulSoup(vedio_episodes_page_html, features='lxml') #解析出电视剧名和设置保存文件夹 vedio_name=vedio_episodes_page_soup.head.find_all("meta")[2]["content"].replace(" ","") vedio_save_dir="./"+vedio_name if not os.path.exists(vedio_save_dir): os.mkdir(vedio_save_dir) #解析出单集播放页面地址 vedio_episode_href_list=vedio_episodes_page_soup.find_all('a', {"class": "meihua_btn"}) print("[开始下载]:"+vedio_name+"---"+vedio_episodes_page_url) #逐集解析 count=0 for vedio_episode_href in vedio_episode_href_list: vedio_episode_url = web_base_url + vedio_episode_href["href"] vedio_episode_html = urlopen(vedio_episode_url).read().decode('utf-8') vedio_episode_soup = BeautifulSoup(vedio_episode_html, features='lxml') count=count+1 vedio_episode_title = "第"+str(count)+"集" vedio_episode_save_path=vedio_save_dir+"/"+vedio_episode_title+".mp4" episode_url = web_base_url + re.findall("video:'(.*?)'",vedio_episode_html)[0] #逐集下载 print("[开始下载]:"+vedio_name+"---"+vedio_episode_title+"---"+episode_url) download_from_url(episode_url,vedio_episode_save_path) print("[下载完成]:"+vedio_name+"---"+vedio_episode_title) except Exception as e: print(e) print("错误,解析url: %s 异常" % vedio_episodes_page_url)