搜索到
362
篇与
的结果
-
 docker快速部署nacos 注意Nacos是一个内部微服务组件,需要在可信的内部网络中运行,不可暴露在公网环境,防止带来安全风险。Nacos提供简单的鉴权实现,为防止业务错用的弱鉴权体系,不是防止恶意攻击的强鉴权体系。如果运行在不可信的网络环境或者有强鉴权诉求,请参考官方简单实现做进行自定义插件开发。1.单机模式 DerbyDocker 拉取镜像docker pull nacos/nacos-server启动nacos# 不开启鉴权 docker run -d \ --name nacos \ -p 8848:8848 -p 9848:9848 \ -e MODE=standalone \ nacos/nacos-server访问页面:http://192.168.124.10:8848/nacos/2.单机模式mysql+宿主机配置文件映射启动Docker 拉取镜像docker pull nacos/nacos-servermysql中创建nacos所需的表mysql中新建一个库,名字可自定义,这里就用nacos从github中找到创建表的文件,在nacos-config库中执行,创建所需的表创建配置文件的保存目录mkdir -p /data/nacos/logs/ #新建logs目录 mkdir -p /data/nacos/conf/ #新建conf目录将nacos里面的文件拷贝出到挂载目录中# 启动容器 docker run -p 8848:8848 --name nacos -d nacos/nacos-server# 复制文件 docker cp nacos:/home/nacos/logs/ /data/nacos/ docker cp nacos:/home/nacos/conf/ /data/nacos/# 删除并关闭容器 docker rm -f nacos再次启动nacosdocker run -d \ --name nacos \ -p 8848:8848 -p 9848:9848 -p 9849:9849 \ --privileged=true \ -e MODE=standalone \ -v /data/nacos/logs/:/home/nacos/logs/ \ -v /data/nacos/conf/:/home/nacos/conf/ \ nacos/nacos-server修改配置文件-application.properties# 在宿主机中修改application.properties文件 vim /data/nacos/conf/application.propertiesspring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://192.168.124.10:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=30000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user=nacos db.password=nacos访问页面:http://192.168.124.10:8848/nacos/3.开启登录验证修改配置文件-application.properties# 在宿主机中修改application.properties文件 vim /data/nacos/conf/application.properties# 开启登录验证 nacos.core.auth.enabled=true nacos.core.auth.server.identity.key=serverIdentity nacos.core.auth.server.identity.value=security # 自定义指定生成JWT的密钥,使用BASE64进行编码,编码前的key长度必须不小于32个字符 nacos.core.auth.plugin.nacos.token.secret.key=NzRmNzRiMGE3OTk5M2ZmOGQyOThhYzgwYWEyZjk4M2MxZTBlMjIyN2YyNGIwOWQzNGQwNGNiYjNiODRlYzQ4ZQ==nacos.core.auth.plugin.nacos.token.secret.key生成步骤:1、使用openssl rand -hex 32获取密钥值[root@centeros7 docker-test]# openssl rand -hex 32 74f74b0a79993ff8d298ac80aa2f983c1e0e2227f24b09d34d04cbb3b84ec48e2、将密钥值再进行base编码访问:https://base64.us/,输入密钥进行base64编码NzRmNzRiMGE3OTk5M2ZmOGQyOThhYzgwYWEyZjk4M2MxZTBlMjIyN2YyNGIwOWQzNGQwNGNiYjNiODRlYzQ4ZQ==参考资料Nacos部署(三)Docker部署Nacos2.3单机环境_nacos 2.3.2镜像-CSDN博客如何使用Docker部署Nacos服务?Nacos Docker 快速部署指南: 一站式部署与配置教程-腾讯云开发者社区-腾讯云 (tencent.com)
docker快速部署nacos 注意Nacos是一个内部微服务组件,需要在可信的内部网络中运行,不可暴露在公网环境,防止带来安全风险。Nacos提供简单的鉴权实现,为防止业务错用的弱鉴权体系,不是防止恶意攻击的强鉴权体系。如果运行在不可信的网络环境或者有强鉴权诉求,请参考官方简单实现做进行自定义插件开发。1.单机模式 DerbyDocker 拉取镜像docker pull nacos/nacos-server启动nacos# 不开启鉴权 docker run -d \ --name nacos \ -p 8848:8848 -p 9848:9848 \ -e MODE=standalone \ nacos/nacos-server访问页面:http://192.168.124.10:8848/nacos/2.单机模式mysql+宿主机配置文件映射启动Docker 拉取镜像docker pull nacos/nacos-servermysql中创建nacos所需的表mysql中新建一个库,名字可自定义,这里就用nacos从github中找到创建表的文件,在nacos-config库中执行,创建所需的表创建配置文件的保存目录mkdir -p /data/nacos/logs/ #新建logs目录 mkdir -p /data/nacos/conf/ #新建conf目录将nacos里面的文件拷贝出到挂载目录中# 启动容器 docker run -p 8848:8848 --name nacos -d nacos/nacos-server# 复制文件 docker cp nacos:/home/nacos/logs/ /data/nacos/ docker cp nacos:/home/nacos/conf/ /data/nacos/# 删除并关闭容器 docker rm -f nacos再次启动nacosdocker run -d \ --name nacos \ -p 8848:8848 -p 9848:9848 -p 9849:9849 \ --privileged=true \ -e MODE=standalone \ -v /data/nacos/logs/:/home/nacos/logs/ \ -v /data/nacos/conf/:/home/nacos/conf/ \ nacos/nacos-server修改配置文件-application.properties# 在宿主机中修改application.properties文件 vim /data/nacos/conf/application.propertiesspring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://192.168.124.10:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=30000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user=nacos db.password=nacos访问页面:http://192.168.124.10:8848/nacos/3.开启登录验证修改配置文件-application.properties# 在宿主机中修改application.properties文件 vim /data/nacos/conf/application.properties# 开启登录验证 nacos.core.auth.enabled=true nacos.core.auth.server.identity.key=serverIdentity nacos.core.auth.server.identity.value=security # 自定义指定生成JWT的密钥,使用BASE64进行编码,编码前的key长度必须不小于32个字符 nacos.core.auth.plugin.nacos.token.secret.key=NzRmNzRiMGE3OTk5M2ZmOGQyOThhYzgwYWEyZjk4M2MxZTBlMjIyN2YyNGIwOWQzNGQwNGNiYjNiODRlYzQ4ZQ==nacos.core.auth.plugin.nacos.token.secret.key生成步骤:1、使用openssl rand -hex 32获取密钥值[root@centeros7 docker-test]# openssl rand -hex 32 74f74b0a79993ff8d298ac80aa2f983c1e0e2227f24b09d34d04cbb3b84ec48e2、将密钥值再进行base编码访问:https://base64.us/,输入密钥进行base64编码NzRmNzRiMGE3OTk5M2ZmOGQyOThhYzgwYWEyZjk4M2MxZTBlMjIyN2YyNGIwOWQzNGQwNGNiYjNiODRlYzQ4ZQ==参考资料Nacos部署(三)Docker部署Nacos2.3单机环境_nacos 2.3.2镜像-CSDN博客如何使用Docker部署Nacos服务?Nacos Docker 快速部署指南: 一站式部署与配置教程-腾讯云开发者社区-腾讯云 (tencent.com) -
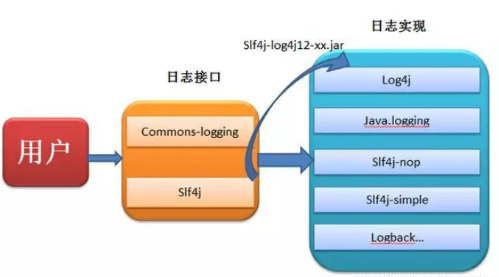
Java日志体系和springboot日志配置 1.日志框架的分类1.1 门面型日志框架日志门面定义了一组日志的接口规范,它并不提供底层具体的实现逻辑。JCL:Apache基金会所属的项目,是一套Java日志接口,之前叫Jakarta Commons Logging,后更名为Commons LoggingSLF4J:是一套简易Java日志门面,本身并无日志的实现。(Simple Logging Facade for Java,缩写Slf4j)1.2 记录型日志框架日志实现则是日志具体的实现,包括日志级别控制、日志打印格式、日志输出形式(输出到数据库、输出到文件、输出到控制台等)。Jul (Java Util Logging):JDK中的日志记录工具,也常称为JDKLog、jdk-logging,自Java1.4以来的官方日志实现。Log4j:Apache Log4j是一个基于Java的日志记录工具。它是由Ceki Gülcü首创的,现在则是Apache软件基金会的一个项目。 Log4j是几种Java日志框架之一。Log4j2:一个具体的日志实现框架,是Log4j 1的下一个版本,与Log4j 1发生了很大的变化,Log4j 2不兼容Log4j 1。Logback:一个具体的日志实现框架,和Slf4j是同一个作者,但其性能更好(推荐使用)。将日志门面和日志实现分离其实是一种典型的门面模式,这种方式可以让具体业务在不同的日志实现框架之间自由切换,而不需要改动任何代码,开发者只需要掌握日志门面的 API 即可。日志门面是不能单独使用的,它必须和一种具体的日志实现框架相结合使用。2.Java日志的恩怨情仇1996年早期,欧洲安全电子市场项目组决定编写它自己的程序跟踪API(Tracing API)。经过不断的完善,这个API终于成为一个十分受欢迎的Java日志软件包,即Log4j(由Ceki创建)。后来Log4j成为Apache基金会项目中的一员,Ceki也加入Apache组织。后来Log4j近乎成了Java社区的日志标准。据说Apache基金会还曾经建议Sun引入Log4j到Java的标准库中,但Sun拒绝了。2002年Java1.4发布,Sun推出了自己的日志库JUL(Java Util Logging),其实现基本模仿了Log4j的实现。在JUL出来以前,Log4j就已经成为一项成熟的技术,使得Log4j在选择上占据了一定的优势。接着,Apache推出了Jakarta Commons Logging,JCL只是定义了一套日志接口(其内部也提供一个Simple Log的简单实现),支持运行时动态加载日志组件的实现,也就是说,在你应用代码里,只需调用Commons Logging的接口,底层实现可以是Log4j,也可以是Java Util Logging。后来(2006年),Ceki不适应Apache的工作方式,离开了Apache。然后先后创建了Slf4j(日志门面接口,类似于Commons Logging)和Logback(Slf4j的实现)两个项目,并回瑞典创建了QOS公司,QOS官网上是这样描述Logback的:The Generic,Reliable Fast&Flexible Logging Framework(一个通用,可靠,快速且灵活的日志框架)。Java日志领域被划分为两大阵营:Commons Logging阵营和Slf4j阵营。Commons Logging在Apache大树的笼罩下,有很大的用户基数。但有证据表明,形式正在发生变化。2013年底有人分析了GitHub上30000个项目,统计出了最流行的100个Libraries,可以看出Slf4j的发展趋势更好。Apache眼看有被Logback反超的势头,于2012-07重写了Log4j 1.x,成立了新的项目Log4j 2, Log4j 2具有Logback的所有特性。3.项目中选择日志框架选择如果是在一个新的项目中建议使用Slf4j与Logback组合,这样有如下的几个优点。Slf4j实现机制决定Slf4j限制较少,使用范围更广。由于Slf4j在编译期间,静态绑定本地的LOG库使得通用性要比Commons Logging要好。Logback拥有更好的性能。Logback声称:某些关键操作,比如判定是否记录一条日志语句的操作,其性能得到了显著的提高。这个操作在Logback中需要3纳秒,而在Log4J中则需要30纳秒。LogBack创建记录器(logger)的速度也更快:13毫秒,而在Log4J中需要23毫秒。更重要的是,它获取已存在的记录器只需94纳秒,而Log4J需要2234纳秒,时间减少到了1/23。跟JUL相比的性能提高也是显著的。Commons Logging开销更高Logback文档免费。Logback的所有文档是全面免费提供的,不象Log4J那样只提供部分免费文档而需要用户去购买付费文档。4.Spring Boot 默认日志4.1 默认日志pom依赖Spring Boot 的日志支持依赖是 spring-boot-starter-logging,默认使用slf4j+logback的方式来记录日志。<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> <version>3.2.5</version> </dependency>备注:该依赖已经被spring-boot-starter所集成,无需重复引入4.2 默认日志级别配置Logback 支持 TRACE, DEBUG, INFO, WARN, ERROR 日志级别,优先级关系为 TRACE < DEBUG < INFO < WARN < ERROR , 可以在 application 配置文件中更改打印日志级别# Log level config logging.level.root=DEBUG4.3 默认日志打印测试手动创建logger@SpringBootTest class SpringBootLogStudyApplicationTests { private static final Logger logger = LoggerFactory.getLogger(SpringBootLogStudyApplicationTests.class); @Test void contextLoads() { logger.debug("debug日志"); logger.info("info日志"); logger.warn("warn日志"); logger.error("error日志"); } }使用@Slf4j注解需要实现引入lombok<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.28</version> </dependency>打印测试@Slf4j @SpringBootTest class SpringBootLogStudyApplicationTests { @Test void testPrintLog() { log.debug("debug日志"); log.info("info日志"); log.warn("warn日志"); log.error("error日志"); } }4.4 日志格式设置使用属性 logging.pattern.console 和 logging.pattern.file 可以分别自定义控制台日志和文件日志的格式#控制台显示日志的格式 logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{5}- %msg%n #文件显示日志的格式 logging.pattern.file=%d{yyyy-MM-dd HH:mm} [%thread] %-5level %logger- %msg%n上面用的一些标签含义如下:%d: 日期实践%thread: 线程名%-5level:级别从左显示5个字符宽度%logger{5}:表示logger名字最长5个字符,否则按照句点分割。%msg:日志消息%n:换行4. 使用application.yml 简单配置Logbacklogging: level: root: info # 根日志级别设置为info com.example: debug # 特定包的日志级别设置为debug pattern: console: "%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%thread] %logger{36} - %msg%n" file: name: application.log # 日志文件名称5. 使用自定义规则的xml配置Logback-配置详解(推荐使用)5.1 configuration节点相关属性属性名称默认值介绍debugfalse要不要打印 logback内部日志信息,true则表示要打印。scantrue配置发送改变时,要不要重新加载scanPeriod1 seconds检测配置发生变化的时间间隔。如果没给出时间单位,默认时间单位是毫秒5.2 configuration子节点介绍contextName节点用来设置上下文名称,每个logger都关联到logger上下文,默认上下文名称为default。但可以使用<contextName>设置成其他名字,用于区分不同应用程序的记录。一旦设置,不能修改,后面输出格式中可以通过定义 %contextName 来打印日志上下文名称(一般可以无需配置)示例:<configuration scan="true" scanPeriod="60 seconds" debug="false"> <contextName>myAppName</contextName> <!--其他配置省略--> </configuration> property节点用来设置相关变量,通过key-value的方式配置,然后在后面的配置文件中通过 ${key}来访问示例:<configuration scan="true" scanPeriod="60 seconds" debug="false"> <property name="APP_Name" value="myAppName" /> <contextName>${APP_Name}</contextName> <!--其他配置省略--> </configuration>appender 节点负责写日志的组件,它有两个必要属性name和class。name指定appender名称,class指定appender的全限定名。属性名称默认值介绍name无默认值appender组件的名称,后面给logger指定appender使用class无默认值appender的具体实现类。常用的有 ConsoleAppender、FileAppender、RollingFileAppenderConsoleAppender:向控制台输出日志内容的组件,只要定义好encoder节点就可以使用。示例:把>=DEBUG级别的日志都输出到控制台<configuration> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg %n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="STDOUT" /> </root> </configuration>FileAppender:向文件输出日志内容的组件,用法也很简单,不过由于没有日志滚动策略,一般很少使用:被写入的文件名,可以是相对目录,也可以是绝对目录,如果上级目录不存在会自动创建,没有默认值。:如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true。:对记录事件进行格式化。:如果是 true,日志会被安全的写入文件,即使其他的FileAppender也在向此文件做写入操作,效率低,默认是 false。示例:把>=DEBUG级别的日志都输出到testFile.log<configuration> <appender name="FILE" class="ch.qos.logback.core.FileAppender"> <file>testFile.log</file> <append>true</append> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="FILE" /> </root> </configuration>RollingFileAppender(推荐):向文件输出日志内容的组件,同时可以配置日志文件滚动策略,在日志达到一定条件后生成一个新的日志文件。有以下子节点::被写入的文件名,可以是相对目录,也可以是绝对目录,如果上级目录不存在会自动创建,没有默认值。 :如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true。:当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名。属性class定义具体的滚动策略类,最常用的是ch.qos.logback.core.rolling.TimeBasedRollingPolicy滚动测量配置详解: class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy": 最常用的滚动策略,它根据时间来制定滚动策略,既负责滚动也负责出发滚动。有以下子节点::必要节点,包含文件名及“%d”转换符,“%d”可以包含一个java.text.SimpleDateFormat指定的时间格式,如:%d{yyyy-MM}。如果直接使用 %d,默认格式是 yyyy-MM-dd。RollingFileAppender的file字节点可有可无,通过设置file,可以为活动文件和归档文件指定不同位置,当前日志总是记录到file指定的文件(活动文件),活动文件的名字不会改变;如果没设置file,活动文件的名字会根据fileNamePattern 的值,每隔一段时间改变一次。“/”或者“\”会被当做目录分隔符。:可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件。假设设置每个月滚动,且是6,则只保存最近6个月的文件,删除之前的旧文件。注意,删除旧文件是,那些为了归档而创建的目录也会被删除。 class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy": 查看当前活动文件的大小,如果超过指定大小会告知RollingFileAppender 触发当前活动文件滚动。只有一个节点::这是活动文件的大小,默认值是10MB。:当为true时,不支持FixedWindowRollingPolicy。支持TimeBasedRollingPolicy,但是有两个限制,1不支持也不允许文件压缩,2不能设置file属性,必须留空。: 告知 RollingFileAppender 合适激活滚动。 class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy" 根据固定窗口算法重命名文件的滚动策略。有以下子节点::窗口索引最小值:窗口索引最大值,当用户指定的窗口过大时,会自动将窗口设置为12。:必须包含“%i”例如,假设最小值和最大值分别为1和2,命名模式为 mylog%i.log,会产生归档文件mylog1.log和mylog2.log。还可以指定文件压缩选项,例如,mylog%i.log.gz 或者 没有log%i.log.zip示例:每天生成一个日志文件,保存30天的日志文件。<configuration> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>logFile.%d{yyyy-MM-dd}.log</fileNamePattern> <maxHistory>30</maxHistory> </rollingPolicy> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="FILE" /> </root> </configuration>logger节点和root节点logger节点:用来设置某一个包或具体的某一个类的日志打印级别、以及指定<appender>,<logger>仅有一个name属性,一个可选的level和一个可选的addtivity属性。可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个logger。name: 用来指定受此loger约束的某一个包或者具体的某一个类。level: 用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL和OFF,还有一个特殊值INHERITED或者同义词NULL,代表强制执行上级的级别。 如果未设置此属性,那么当前logger将会继承上级的级别。addtivity: 是否向上级logger传递打印信息。默认是true。可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个logger。root节点:它也是<logger>元素,但是它是根logger,是所有<logger>的上级。只有一个level属性,因为name已经被命名为"root",且已经是最上级了。level: 用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL和OFF,不能设置为INHERITED或者同义词NULL。 默认是DEBUG。示例:常用logger配置<!-- show parameters for hibernate sql 专为 Hibernate 定制 --> <logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE" /> <logger name="org.hibernate.type.descriptor.sql.BasicExtractor" level="DEBUG" /> <logger name="org.hibernate.SQL" level="DEBUG" /> <logger name="org.hibernate.engine.QueryParameters" level="DEBUG" /> <logger name="org.hibernate.engine.query.HQLQueryPlan" level="DEBUG" /> <!--myibatis log configure--> <logger name="com.apache.ibatis" level="TRACE"/> <logger name="java.sql.Connection" level="DEBUG"/> <logger name="java.sql.Statement" level="DEBUG"/> <logger name="java.sql.PreparedStatement" level="DEBUG"/>4.2.2 配置实例可以实现每天生成一个日志文件,日志文件按等级分文件保存,保存日期等 复杂规则日志<?xml version="1.0" encoding="UTF-8"?> <configuration debug="false"> <!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径--> <property name="LOG_HOME" value="C:/Users/vin/Desktop/log-test"/> <property name="appName" value="logbackStudy"/> <!--控制台日志, 控制台输出 --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度,%msg:日志消息,%n是换行符--> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> </appender> <!--文件日志, 按照每天生成日志文件 --> <!--RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件--> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true --> <append>true</append> <!--当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名--> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!--定义文件滚动时的文件名的格式--> <fileNamePattern>${LOG_HOME}/${appName}.%d{yyyy-MM-dd}.log </fileNamePattern> <!--30天的时间周期,日志量最大1GB--> <maxHistory>30</maxHistory> <!-- 该属性在 1.1.6版本后 才开始支持--> <totalSizeCap>1GB</totalSizeCap> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"> <!--每个日志文件最大10MB--> <MaxFileSize>10MB</MaxFileSize> </triggeringPolicy> </appender> <!-- 按日志级别打印 INFO --> <appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/INFO.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>INFO</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 按日志级别打印 WARN --> <appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/WARN.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>WARN</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 按日志级别打印 ERROR --> <appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/ERROR.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>ERROR</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 日志输出级别设置,ref 属性为 appender 的name--> <root level="INFO"> <appender-ref ref="STDOUT"/> <appender-ref ref="FILE"/> <appender-ref ref="INFO"/> <appender-ref ref="WARN"/> <appender-ref ref="ERROR"/> </root> </configuration>参考资料面试官:SpringBoot中关于日志工具的使用,我想问你几个常见问题-腾讯云开发者社区-腾讯云 (tencent.com)深入掌握Java日志体系,再也不迷路了 - 掘金 (juejin.cn)Java日志体系详解_Jeremy_Lee123的博客-CSDN博客Spring Boot中集成Slf4j 与Logback-腾讯云开发者社区-腾讯云 (tencent.com)Spring Boot 默认日志使用_logging.level.springfox__星辰夜风的博客-CSDN博客logback配置文件---logback.xml详解 - 马非白即黑 - 博客园 (cnblogs.com)logback介绍和配置详解 - 简书 (jianshu.com)
-
Docker日志大小限制配置 维护测试环境的时候发现磁盘使用达到100%从而导致服务异常,排查磁盘占用原因发现是docker的累计日志占用过大的,因此查阅相关资料进行配置维护并记录。1.背景知识Docker 是一个开源的应用容器引擎,允许开发者将应用以及依赖打包到一个可移植的容器中,并发布到任何流行的 Linux 或 Windows 机器上。由于 Docker 提供了隔离应用和底层系统的抽象层,因此应用可以在各种环境中一致地运行。然而,在运行 Docker 容器时,会产生大量日志,如果不加以管理,可能会占满主机的存储空间。Docker 默认使用 json-file 作为其日志驱动,但并未设置日志文件的大小上限,也就是说,如果不进行额外配置,Docker 日志会持续增长,直到耗尽所有可用的磁盘空间。2.具体配置方法方法一:使用 —log-opt 参数在启动容器时,可以使用 --log-opt 参数设置日志驱动程序的选项。通过该参数,我们可以限制容器日志的大小。示例命令:docker run -d --name example-container --log-opt max-size=500m --log-opt max-file=3 nginx:latestmax-size=500m:限制单个日志文件的最大大小为 500MB。max-file=3:限制日志文件的数量为 3 个。当日志文件达到 500MB 时,Docker 会自动轮换日志文件,保留最新的 3 个日志文件。日志json-file记录驱动程序支持以下日志记录选项:选项描述示例值max-size滚动之前日志的最大大小。一个正整数加上表示测量单位的修饰符(k、m或g)。默认为 -1(无限制)。--log-opt max-size=10mmax-file可以存在的日志文件的最大数量。如果滚动日志会产生多余的文件,则最旧的文件将被删除。仅当也设置时才有效。max-size正整数。默认为 1。--log-opt max-file=3labels启动 Docker 守护进程时适用。该守护进程接受的与日志记录相关的标签的逗号分隔列表。用于高级日志标记选项。--log-opt labels=production_status,geolabels-regex与 类似并兼容labels。用于匹配与日志记录相关的标签的正则表达式。用于高级日志标记选项。--log-opt labels-regex=xxxxxenv启动 Docker 守护进程时适用。该守护进程接受的与日志记录相关的环境变量的逗号分隔列表。用于高级日志标记选项。--log-opt env=os,customerenv-regex与 类似并兼容env。用于匹配与日志记录相关的环境变量的正则表达式。用于高级日志标记选项。--log-opt env-regex=^xxxxxcompress切换旋转日志的压缩。默认为disabled.--log-opt compress=true方法二:修改 Docker daemon 配置文件可以修改 Docker daemon 配置文件为所有容器设置默认的日志大小限制。配置文件的位置根据您的操作系统而异Ubuntu 和 Debian:/etc/docker/daemon.jsonCentOS:/etc/sysconfig/docker示例配置:{ "log-driver": "json-file", "log-opts": { "max-size": "500m", "max-file": "3" } }保存并关闭配置文件后,需要重启 Docker 服务以使更改生效。现在,所有新启动的容器都将遵循配置文件中定义的日志大小限制。$\color{red}{注意:该配置只对新容器生效,已经创建了的容器不生效,需要重新删除后再创建!!!}$systemctl restart docker参考资料Docker 控制容器日志大小的方法 - 知乎 (zhihu.com)限制 Docker 日志大小:配置与实践-百度开发者中心 (baidu.com)docker容器日志大小限制-CSDN博客
-
-
关于手机充电和快充相关的知识和问题梳理 1.手机快充协议1.1 快充协议有什么用对于手机与手机配件(如充电器、充电宝)来说,也存在这样的一种暗号,只有对上暗号了,才能进行快充,这就是快充协议。因此购买充电器的时候建议购买原装充电器,避免出现充电协议不兼容导致的充电速率上不去的问题。1.2 常见的手机品牌使用的快充协议小米/红米手机:高通QC协议、Turbo Charge(小米私有协议)苹果手机:iPhone8及以后的手机,都是PD协议(iPhone8以前的,使用的是Apple 2.4A充电协议)华为手机:FCP、SCP(这两个都是私有协议,目前18W和22.5W的已经公开,但大功率如66W的,还未公开)OPPO:VOOC、SuperVOOC(两个都是私有协议)一加(oneplus):Warp(私有协议)Realme:DART(私有协议)Vivo和IQOO:vivo超快闪充、vivo闪充、双引擎闪充(三个都是私有协议)1.3 主流快充协议1.通用的USB-PD协议(公有协议)这个是USB的标准化组织推出的一个快速充电的标准。不光是手机使用这一协议,很多笔记本等设备也是用这个充电协议。并且其他所有快充协议都要遵循PD协议,因为大家用的都是USB接口,所以只能按照它们制定的标准来。USB- PD快充协议是以Type-C作为输出接口,但不是说有Type-C接口就支持PD协议的快充。目前手机大部分都是支持USB-PD快充协议的,苹果在iphone8(plus)之后就开始支持USB-PD快充,不过需要另外配备USB C to Lighting数据线,最高达到18W的充电。而安卓手机方面,因为Type-C接口最大支持15W(5V 3A),不过在实现了USB-PD协议后,输出功率最大支持到100W(20V 5A),,所以只要你的充电接口是Type-c接口,基本都是可以支持USB-PD协议。时间协议充电规格2010年USB BC1.25V1.5A2012年7月USB PD1.0不详2014年8月USB PD2.05V 3A、9V 3A、15V3A、 20V2.25A、20V 3A、20V 5A2017年2月USB PD3.05V 3A、9V3A、15V3A、20V2.25A、 20V 3A、 20V 5A PPS: 3.3V-5.9V3A、 3.3-11V 3A、3.3-16V 3A、 3.3-21V 3A、 3.3-21V 5A2021年5月USB PD3.15V 3A、9V 3A、15V 3A、20V 3A、20V 5A<br/> PPS: 3.3-5.9V3A. 33-11V 3A、3.3-16V 3A、33-21V 3A、33-21V 5A<br/> EPR: 28V 5A、36V 5A、48V 5A AVS: 15-28V 5A、 15-36V 5A、15-48V 5A2.高通的QC协议由于高通是手机芯片的龙头,高通很早就已经在自家芯片上集成了快充协议。目前已经经历了5代,但市场主流的是QC2.0/3.0/4.0。在2013年率先发布QC1.0快充,电压电流为5V 2A,充电功率10W,节省了将近一半的充电时间从QC2.0开始开启了高电压充电时代,输出为9V、12V、20V电压档位,最高支持充电功率18W,向下兼容QC1.0;QC3.0时支持3.6-20V波动电压,最高充电功率依旧是18W,向下兼容QC2.0;QC4.0时则将电压细分0.2为一档,且加入PD快充协议,5V最大可输出5.6A,9V最大可输出3A,并且充电功率提升到了28W;QC4.0+时最高功率100W,同时可以给笔记本充电。在QC4.0的基础上向下兼容QC3.0和QC2.0。3.华为的FCP和SCP协议这两种都是华为自家的私有协议。FCP协议出得早一点,用的是跟QC2.0相似的“高压小电流”方案,输出规格是9V2A 18W。SCP协议是2016年后推出的,采用的跟OPPO相似的“低压大电流”方案。输出规格是5V 4.5A或10V 4A。后来华为又在SCP协议基础上增加了电荷泵技术,将电流从4A提升到8A,实现了充电功率40W的超级快充,后面也出现双电池充电的65W超级快充。但是SCP快充协议需要在充电线支持下才能使用,需要配备支持5A大电流的充电线。4.OPPO的VOOC和SuperVOOC闪充OPPO这个VOOC闪充相信很多人都不陌生,当时还是5V 2A的充电市场为主,OPPO另辟蹊径,喊出“充电5分钟,通话2小时”的口号,率先采用低压高电流方案,推出5V 4.5A的VOOC闪充,充电功率达22.5W。相比当时主流的高压快充,低压快充温控更好,效率更高。后来经过几次更新,现在闪充已经发展到SuperVOOC2.0版本,这是采用双电池串联方案和全新的电荷泵技术,将双电芯电压减半,兼顾安全性和效率,实现了10V 6.5A,充电功率65W的超级闪充。但由于电池系统,充电器,线材都被重新定制,所以条件比较苛刻,和华为SCP快充一样,OPPO也需要支持大电流的充电线才能支持VOOC闪充。2.手机充电功耗和实时数据测试软件Battery Guru| | |安兔兔评测-充电测试| | |3.关于手机充电相关的问题3.1 手机是否可以整晚充电不拔结论:最好不要,但是使用正版原厂的充电器,一般问题也不大。因为目前的智能手机都是使用锂电池,自带的PMU(也就是电源管理单元)能够在插上电源后自动检测当前电池电量是否需要充电;在充满电之后,PMU也会自动给出断电的信号进入待机状态;当电量下降之后就会给出充电的指示。3.2 手机还没充满电可以拔掉吗?可以。锂电池没有充电记忆的,讲究随用随充,所以没有充满也是可以停止充电的,对电池影响很小。只要不让手机长时间处于没有充满的状态之下,都是不会有什么影响的。3.3 手机可以不管剩余多少电量都可以随时充电吗是的。锂电池处于低电量时损耗比较大,因此等到电耗光再充电,这会加快它的损耗。长期处于40%~60%电量可以使电池长寿。参考资料手机快充协议是什么?一篇文章带你搞懂各个快充协议(PD、QC、FCP、SCP、VOOC) - 知乎 (zhihu.com)充电协议USB-PD、QC、FCP、SCP、VOOC有什么区别,充电宝哪个牌子好?充电宝品牌选购推荐 (zhihu.com)小米/红米手机支持的快充协议汇总及充电器(宝)兼容情况汇总(最近更新于2023年9月27日) - 知乎 (zhihu.com)手机充电“一夜不拔”,对电池到底有没有坏处呢? - 知乎 (zhihu.com)手机电量到 20% 就会提醒充电的原因是什么? - 知乎 (zhihu.com)为什么手机电量「低于20%」会提醒充电?_电池 (sohu.com)充电杂谈:同为USB-C,3A充电线与5A充电线有何不同?_哔哩哔哩_bilibili【九机学院】四分钟看懂什么是高通的快速充电技术QC 3.0_哔哩哔哩_bilibili
-
SSH客户端登录会话避免超时设置 1.背景通常默认公有云上的ECS远程连接,很容易断开,当你有什么事情被打断或者去操作别的机器同步做点其他事情,你会发现你SSH客户端登录窗口经常会断开掉,非常烦人,经常要重新登录。而且这时候终端会卡在那里,十分的不方便。所以在网上找了几个配置SSH的方法,能保证连接能够长时间不断开。 方法有两种,一般配置一种就可以。2.配置方式2.1 客户端配置$ vim ~/.ssh/config #添加如下内容 Host * ServerAliveInterval 60 ServerAliveCountMa 30说明:本地SSH Client每隔60s向Server端SSHD发送 keep-alive 包,如果发送30次, Server端还无回应则断开连接。2.2 服务端配置vim /etc/ssh/sshd_config然后找到下面两项:ClientAliveInterval 60 ClientAliveCountMax 30这两项默认可能是注释掉的,去掉#,然后如上设置.说明:ClientAliveInterval: 这个其实就是SSH Server与Client的心跳超时时间,也就是说,当客户端没有指令过来,Server间隔ClientAliveInterval的时间(单位秒)会发一个空包到Client来维持心跳,60表示每分钟发送一次,然后客户端响应,这样就保持长连接了保证Session有效, 默认是0, 不发送;ClientAliveCountMax:当心跳包发送失败时重试的次数,比如现在我们设置成了30,如果Server向Client连续发30次心跳包都失败了,就会断开这个session连接。参考资料保持SSH连接持续不断的配置方法-腾讯云开发者社区-腾讯云 (tencent.com)配置SSH服务远程连接空闲超时退出时间(包括SSH无法登录、登录缓慢)-腾讯云开发者社区-腾讯云 (tencent.com)
-
激活码 1.webstormI2A0QUY8VU-eyJsaWNlbnNlSWQiOiJJMkEwUVVZOFZVIiwibGljZW5zZWVOYW1lIjoiVU5JVkVSU0lEQURFIEVTVEFEVUFMIERFIENBTVBJTkFTIiwiYXNzaWduZWVOYW1lIjoiVGFvYmFv77yaSkVU5YWo5a625qG25r+AIOa0u+W3peS9nOWupCAgcmVuIHpodW4gZGlhbiBtaW5n77yBIiwiYXNzaWduZWVFbWFpbCI6IlJvYmJ5X1dlbmlnZXJAb3V0bG9vay5jb20iLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiJGb3IgZWR1Y2F0aW9uYWwgdXNlIG9ubHkiLCJjaGVja0NvbmN1cnJlbnRVc2UiOmZhbHNlLCJwcm9kdWN0cyI6W3siY29kZSI6IkRQTiIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiREIiLCJwYWlkVXBUbyI6IjIwMjQtMTAtMTQiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IlBTIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJJSSIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNDIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IkdPIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJETSIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNGIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IkRTIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJQQyIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUkMiLCJwYWlkVXBUbyI6IjIwMjQtMTAtMTQiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IkNMIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJXUyIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUkQiLCJwYWlkVXBUbyI6IjIwMjQtMTAtMTQiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IlJTMCIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUk0iLCJwYWlkVXBUbyI6IjIwMjQtMTAtMTQiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IlJTViIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJEQyIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNVIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJEUCIsInBhaWRVcFRvIjoiMjAyNC0xMC0xNCIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQREIiLCJwYWlkVXBUbyI6IjIwMjQtMTAtMTQiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFNJIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDV01QIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlJTIiwicGFpZFVwVG8iOiIyMDI0LTEwLTE0IiwiZXh0ZW5kZWQiOnRydWV9XSwibWV0YWRhdGEiOiIwMTIwMjMxMDE4TFBBQTAwMjAwOSIsImhhc2giOiI1MDY4MjM4OC8yNDQxMzAzMDotMjMxNDI0MDkzIiwiZ3JhY2VQZXJpb2REYXlzIjo3LCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-TVABo8WPqQXMBwop9hR4Jao5zPeU6ZWd/B4k0rUtT8YptqYZ0qcyA1w928ovkigORlHy4uIHKc75EmfkDc7V8jLUEyysKr3XGrJe/0ghkGtqTUaZ47SWiqm6TCR21PG2CtfByT0jZjw6AspsWqwyGmFeZAKfXkuAzmJ6psJOeZvaFn4qzzkjzCDdOGOdUXPEPdkG1t4a+rxgt4Ly06yEcpFpy87mx5SO/F9sus2/ZHnVCISqRQBil8hvYsQKP9TScHjyGe6I9KhRofs2SuUHe3+Wh5cSTQH4wy6mJZP+7ImX76BnOqjPWOh4sJwUJ+I+IfjOV4iG5bu25YNV9DF2eA==-MIIETDCCAjSgAwIBAgIBDzANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIyMTAxMDE2MDU0NFoXDTI0MTAxMTE2MDU0NFowHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMjEwMTAwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQC/W3uCpU5M2y48rUR/3fFR6y4xj1nOm3rIuGp2brELVGzdgK2BezjnDXpAxVDw5657hBkAUMoyByiDs2MgmVi9IcqdAwpk988/Daaajq9xuU1of59jH9eQ9c3BmsEtdA4boN3VpenYKATwmpKYkJKVc07ZKoXL6kSyZuF7Jq7HoQZcclChbF75QJPGbri3cw9vDk/e46kuzfwpGftvl6+vKibpInO6Dv0ocwImDbOutyZC7E+BwpEm1TJZW4XovMBegHhWC04cJvpH1u98xoR94ichw0jKhdppywARe43rGU96163RckIuFmFDQKZV9SMUrwpQFu4Z2D5yTNqnlLRfAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQU5FZqQ4gnVc+inIeZF+o3ID+VhcEwSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBANLG1anEKid4W87vQkqWaQTkRtFKJ2GFtBeMhvLhIyM6Cg3FdQnMZr0qr9mlV0w289pf/+M14J7S7SgsfwxMJvFbw9gZlwHvhBl24N349GuthshGO9P9eKmNPgyTJzTtw6FedXrrHV99nC7spaY84e+DqfHGYOzMJDrg8xHDYLLHk5Q2z5TlrztXMbtLhjPKrc2+ZajFFshgE5eowfkutSYxeX8uA5czFNT1ZxmDwX1KIelbqhh6XkMQFJui8v8Eo396/sN3RAQSfvBd7Syhch2vlaMP4FAB11AlMKO2x/1hoKiHBU3oU3OKRTfoUTfy1uH3T+t03k1Qkr0dqgHLxiv6QU5WrarR9tx/dapqbsSmrYapmJ7S5+ghc4FTWxXJB1cjJRh3X+gwJIHjOVW+5ZVqXTG2s2Jwi2daDt6XYeigxgL2SlQpeL5kvXNCcuSJurJVcRZFYUkzVv85XfDauqGxYqaehPcK2TzmcXOUWPfxQxLJd2TrqSiO+mseqqkNTb3ZDiYS/ZqdQoGYIUwJqXo+EDgqlmuWUhkWwCkyo4rtTZeAj+nP00v3n8JmXtO30Fip+lxpfsVR3tO1hk4Vi2kmVjXyRkW2G7D7WAVt+91ahFoSeRWlKyb4KcvGvwUaa43fWLem2hyI4di2pZdr3fcYJ3xvL5ejL3m14bKsfoOv2.全家桶UX394X3HLT-eyJsaWNlbnNlSWQiOiJVWDM5NFgzSExUIiwibGljZW5zZWVOYW1lIjoiSG9uZ2lrIFVuaXZlcnNpdHntmY3snbXrjIDtlZnqtZAiLCJsaWNlbnNlZVR5cGUiOiJDTEFTU1JPT00iLCJhc3NpZ25lZU5hbWUiOiLkvJfliJvkupEg5bel5L2c5a6kIiwiYXNzaWduZWVFbWFpbCI6ImhhbmF6YXdhbWl0b0BnbWFpbC5jb20iLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiJGb3IgZWR1Y2F0aW9uYWwgdXNlIG9ubHkiLCJjaGVja0NvbmN1cnJlbnRVc2UiOmZhbHNlLCJwcm9kdWN0cyI6W3siY29kZSI6IkdPIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJSUzAiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IkRNIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJDTCIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNVIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJSU0MiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUEMiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IkRTIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJSRCIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUkMiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IlJTRiIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJSTSIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiSUkiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IkRQTiIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiREIiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6ZmFsc2V9LHsiY29kZSI6IkRDIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJQUyIsInBhaWRVcFRvIjoiMjAyNC0xMi0xMyIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUlNWIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IldTIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOmZhbHNlfSx7ImNvZGUiOiJQU0kiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUENXTVAiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUlMiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiRFAiLCJwYWlkVXBUbyI6IjIwMjQtMTItMTMiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUERCIiwicGFpZFVwVG8iOiIyMDI0LTEyLTEzIiwiZXh0ZW5kZWQiOnRydWV9XSwibWV0YWRhdGEiOiIwMTIwMjMxMjI4TFBBQTAwNDAwOCIsImhhc2giOiI1MjY4NzM4Ny8yNTMxODE0MTotMTUwNDg0MzkwMSIsImdyYWNlUGVyaW9kRGF5cyI6NywiYXV0b1Byb2xvbmdhdGVkIjpmYWxzZSwiaXNBdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJ0cmlhbCI6ZmFsc2UsImFpQWxsb3dlZCI6dHJ1ZX0=-YqDHrEIEaf/x1JqIdTI64AYA1IpRoYiqoZ/1YDnfpEqSFNJIC4er7K1hjUm9tFslnY2XoNRs04JSUG8CgNkTgIKA4xLyxGBufJYyHv26UKQmyf1nb1pM9XATb3pWSQ3h6o8/4x3jacVk3zbAuXt3uV6eEj2bCZvhGpATFmK1JVsSor+XgPr5aYePCtyymiyPOq33ghW5onzSI5LsQR5motHvLgWmjf0Mkutys3SmWt13YVcIe5yCzhlTNCZw++CAuRh2Fx/JXZhRt+kUqW2yLbkIo3kNEg2I31H8qya+RDJ09Qz7DsDkrIgODqX4Wbd2fy1C7Q1CcjjksvjhswnpNA==-MIIETDCCAjSgAwIBAgIBDzANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIyMTAxMDE2MDU0NFoXDTI0MTAxMTE2MDU0NFowHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMjEwMTAwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQC/W3uCpU5M2y48rUR/3fFR6y4xj1nOm3rIuGp2brELVGzdgK2BezjnDXpAxVDw5657hBkAUMoyByiDs2MgmVi9IcqdAwpk988/Daaajq9xuU1of59jH9eQ9c3BmsEtdA4boN3VpenYKATwmpKYkJKVc07ZKoXL6kSyZuF7Jq7HoQZcclChbF75QJPGbri3cw9vDk/e46kuzfwpGftvl6+vKibpInO6Dv0ocwImDbOutyZC7E+BwpEm1TJZW4XovMBegHhWC04cJvpH1u98xoR94ichw0jKhdppywARe43rGU96163RckIuFmFDQKZV9SMUrwpQFu4Z2D5yTNqnlLRfAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQU5FZqQ4gnVc+inIeZF+o3ID+VhcEwSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBANLG1anEKid4W87vQkqWaQTkRtFKJ2GFtBeMhvLhIyM6Cg3FdQnMZr0qr9mlV0w289pf/+M14J7S7SgsfwxMJvFbw9gZlwHvhBl24N349GuthshGO9P9eKmNPgyTJzTtw6FedXrrHV99nC7spaY84e+DqfHGYOzMJDrg8xHDYLLHk5Q2z5TlrztXMbtLhjPKrc2+ZajFFshgE5eowfkutSYxeX8uA5czFNT1ZxmDwX1KIelbqhh6XkMQFJui8v8Eo396/sN3RAQSfvBd7Syhch2vlaMP4FAB11AlMKO2x/1hoKiHBU3oU3OKRTfoUTfy1uH3T+t03k1Qkr0dqgHLxiv6QU5WrarR9tx/dapqbsSmrYapmJ7S5+ghc4FTWxXJB1cjJRh3X+gwJIHjOVW+5ZVqXTG2s2Jwi2daDt6XYeigxgL2SlQpeL5kvXNCcuSJurJVcRZFYUkzVv85XfDauqGxYqaehPcK2TzmcXOUWPfxQxLJd2TrqSiO+mseqqkNTb3ZDiYS/ZqdQoGYIUwJqXo+EDgqlmuWUhkWwCkyo4rtTZeAj+nP00v3n8JmXtO30Fip+lxpfsVR3tO1hk4Vi2kmVjXyRkW2G7D7WAVt+91ahFoSeRWlKyb4KcvGvwUaa43fWLem2hyI4di2pZdr3fcYJ3xvL5ejL3m14bKsfoOv
-
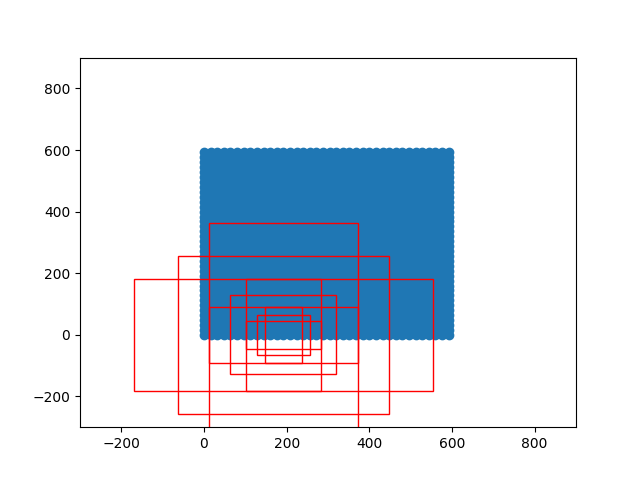
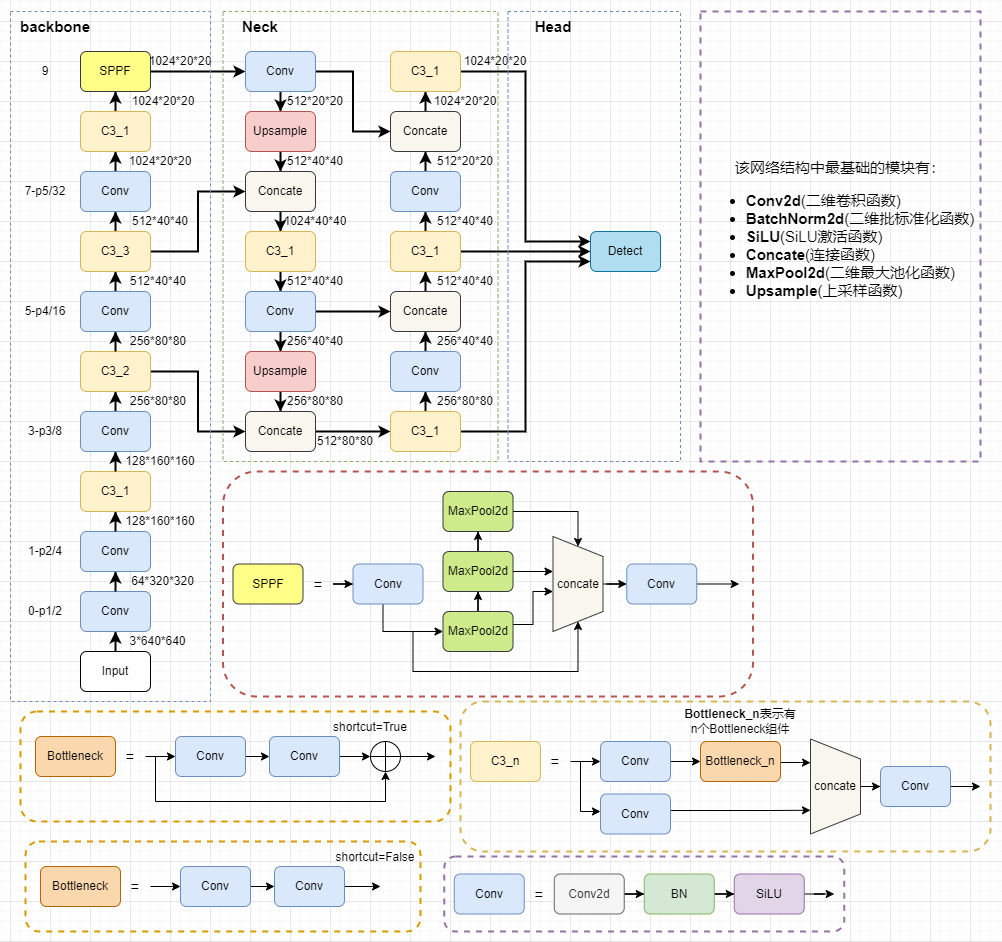
fastrcnn网络结构复现 1.backbone-restnet50import math import torch.nn as nn class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000): #-----------------------------------# # 假设输入进来的图片是600,600,3 #-----------------------------------# self.inplanes = 64 super(ResNet, self).__init__() # 600,600,3 -> 300,300,64 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) # 300,300,64 -> 150,150,64 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True) # 150,150,64 -> 150,150,256 self.layer1 = self._make_layer(block, 64, layers[0]) # 150,150,256 -> 75,75,512 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 75,75,512 -> 38,38,1024 到这里可以获得一个38,38,1024的共享特征层 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # self.layer4被用在classifier模型中 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None #-------------------------------------------------------------------# # 当模型需要进行高和宽的压缩的时候,就需要用到残差边的downsample #-------------------------------------------------------------------# if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc(x) return x def resnet50(): model = ResNet(Bottleneck, [3, 4, 6, 3]) #----------------------------------------------------------------------------# # 获取特征提取部分,从conv1到model.layer3,最终获得一个38,38,1024的特征层 #----------------------------------------------------------------------------# features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3]) #----------------------------------------------------------------------------# # 获取分类部分,从model.layer4到model.avgpool #----------------------------------------------------------------------------# classifier = list([model.layer4, model.avgpool]) features = nn.Sequential(*features) classifier = nn.Sequential(*classifier) return features, classifier extractor,classifier = resnet50() print(extractor)Sequential( (0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True) (4): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (5): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (6): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) )2.RPNimport numpy as np def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32]): anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32) for i in range(len(ratios)): for j in range(len(anchor_scales)): h = base_size * anchor_scales[j] * np.sqrt(ratios[i]) w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i]) index = i * len(anchor_scales) + j anchor_base[index, 0] = - h / 2. anchor_base[index, 1] = - w / 2. anchor_base[index, 2] = h / 2. anchor_base[index, 3] = w / 2. return anchor_base # 产生特征图上每个点对应的9个base anchor def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width): # 计算网格中心点 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) shift = np.stack((shift_x.ravel(),shift_y.ravel(), shift_x.ravel(),shift_y.ravel(),), axis=1) # 每个网格点上的9个先验框 A = anchor_base.shape[0] K = shift.shape[0] anchor = anchor_base.reshape((1, A, 4)) + \ shift.reshape((K, 1, 4)) # 所有的先验框 anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor import matplotlib.pyplot as plt nine_anchors = generate_anchor_base() # 产生特征图上每个点对应的9个base anchor height, width, feat_stride = 38,38,16 # 特征图的shape feature_map_w,feature_map_h,feature_map_c = 38,38,16 # 生成整个特征图对应的所有的base anchor ,总计feature_map_w*feature_map_h*9个 anchors_all = _enumerate_shifted_anchor(nine_anchors,feat_stride,height,width) print(np.shape(anchors_all)) fig = plt.figure() ax = fig.add_subplot(111) plt.ylim(-300,900) plt.xlim(-300,900) # 模拟绘制特征提取之前的原图 shift_x = np.arange(0, width * feat_stride, feat_stride) shift_y = np.arange(0, height * feat_stride, feat_stride) shift_x, shift_y = np.meshgrid(shift_x, shift_y) plt.scatter(shift_x,shift_y) # 绘制特征图上像素点(pix_x,pix_y)对应原图的所有anchor pix_x,pix_y = 12,0 index_begin = pix_y*width*9 + pix_x*9 index_end = pix_y*width*9 + pix_x*9 + 9 print(index_begin) box_widths = anchors_all[:,2]-anchors_all[:,0] box_heights = anchors_all[:,3]-anchors_all[:,1] for i in range(index_begin,index_end): rect = plt.Rectangle([anchors_all[i, 0],anchors_all[i, 1]],box_widths[i],box_heights[i],color="r",fill=False) ax.add_patch(rect) plt.show()# 将RPN网络预测结果转化成建议框 def loc2bbox(src_bbox, loc): if src_bbox.size()[0] == 0: return torch.zeros((0, 4), dtype=loc.dtype) src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1) src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1) src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height dx = loc[:, 0::4] dy = loc[:, 1::4] dw = loc[:, 2::4] dh = loc[:, 3::4] ctr_x = dx * src_width + src_ctr_x ctr_y = dy * src_height + src_ctr_y w = torch.exp(dw) * src_width h = torch.exp(dh) * src_height dst_bbox = torch.zeros_like(loc) dst_bbox[:, 0::4] = ctr_x - 0.5 * w dst_bbox[:, 1::4] = ctr_y - 0.5 * h dst_bbox[:, 2::4] = ctr_x + 0.5 * w dst_bbox[:, 3::4] = ctr_y + 0.5 * h return dst_bboxclass ProposalCreator(): def __init__(self, mode, nms_thresh=0.7, n_train_pre_nms=12000, n_train_post_nms=600, n_test_pre_nms=3000, n_test_post_nms=300, min_size=16): self.mode = mode self.nms_thresh = nms_thresh self.n_train_pre_nms = n_train_pre_nms self.n_train_post_nms = n_train_post_nms self.n_test_pre_nms = n_test_pre_nms self.n_test_post_nms = n_test_post_nms self.min_size = min_size def __call__(self, loc, score, anchor, img_size, scale=1.): if self.mode == "training": n_pre_nms = self.n_train_pre_nms n_post_nms = self.n_train_post_nms else: n_pre_nms = self.n_test_pre_nms n_post_nms = self.n_test_post_nms anchor = torch.from_numpy(anchor) if loc.is_cuda: anchor = anchor.cuda() #-----------------------------------# # 将RPN网络预测结果转化成建议框 #-----------------------------------# roi = loc2bbox(anchor, loc) #-----------------------------------# # 防止建议框超出图像边缘 #-----------------------------------# roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1]) roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0]) #-----------------------------------# # 建议框的宽高的最小值不可以小于16 #-----------------------------------# min_size = self.min_size * scale keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0] roi = roi[keep, :] score = score[keep] #-----------------------------------# # 根据得分进行排序,取出建议框 #-----------------------------------# order = torch.argsort(score, descending=True) if n_pre_nms > 0: order = order[:n_pre_nms] roi = roi[order, :] score = score[order] #-----------------------------------# # 对建议框进行非极大抑制 #-----------------------------------# keep = nms(roi, score, self.nms_thresh) keep = keep[:n_post_nms] roi = roi[keep] return roi3.合并backbone与rpn--记为FRCNN_RPNclass FRCNN_RPN(nn.Module): def __init__(self,extractor,rpn): super(FRCNN_RPN, self).__init__() self.extractor = extractor self.rpn = rpn def forward(self, x, img_size): print(img_size) feature_map = self.extractor(x) rpn_locs, rpn_scores, rois, roi_indices, anchor = self.rpn(feature_map,img_size) return rpn_locs, rpn_scores, rois, roi_indices, anchor# 加载模型参数 param = torch.load("./frcnn-restnet50.pth") param.keys() rpn = RegionProposalNetwork(in_channels=1024,mode="predict") frcnn_rpn = FRCNN_RPN(extractor,rpn) frcnn_rpn_state_dict = frcnn_rpn.state_dict() for key in frcnn_rpn_state_dict.keys(): frcnn_rpn_state_dict[key] = param[key] frcnn_rpn.load_state_dict(frcnn_rpn_state_dict)from PIL import Image import copy def get_new_img_size(width, height, img_min_side=600): if width <= height: f = float(img_min_side) / width resized_height = int(f * height) resized_width = int(img_min_side) else: f = float(img_min_side) / height resized_width = int(f * width) resized_height = int(img_min_side) return resized_width, resized_height img_path = os.path.join("xx.jpg") image = Image.open(img_path) image = image.convert("RGB") # 转换成RGB图片,可以用于灰度图预测。 image_shape = np.array(np.shape(image)[0:2]) old_width, old_height = image_shape[1], image_shape[0] old_image = copy.deepcopy(image) # 给原图像进行resize,resize到短边为600的大小上 width,height = get_new_img_size(old_width, old_height) image = image.resize([width,height], Image.BICUBIC) print(image.size) # 图片预处理,归一化。 photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1)) with torch.no_grad(): images = torch.from_numpy(np.asarray([photo])) rpn_locs, rpn_scores, rois, roi_indices, anchor = frcnn_rpn(images,[height,width]) fig = plt.figure(dpi=200) ax = fig.add_subplot(111) ax.imshow(image) # 绘制RPN的结果 for i in range(rois.shape[0]): x1,y1,x2,y2 = rois[i] w,h = x2-x1,y2-y1 rect = plt.Rectangle([x1,y1],w,h,color="r",fill=False) ax.add_patch(rect) plt.xticks([]) plt.yticks([]) plt.show() print(anchor.shape) print(rois.shape)
-
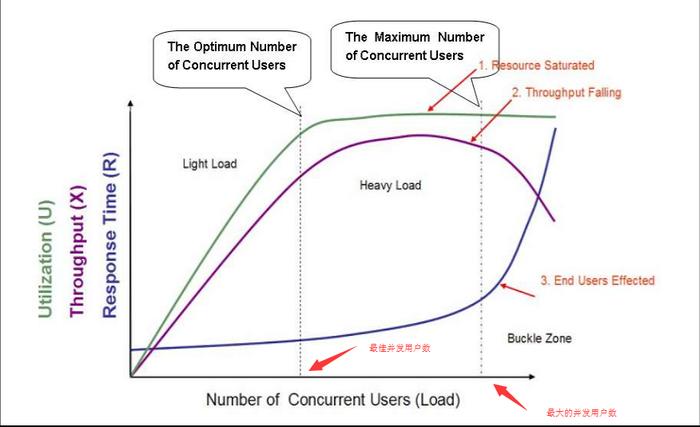
Jmeter性能测试学习笔记 1.性能测试理论1.1 性能的概念1.1.1 什么是性能对于应用和软件来说,主要包括时间和资源两个维度时间:系统处理用户请求的响应时间资源:系统运行过程中,系统资源的消耗情况1.1.2 什么是性能测试?使用自动化工具,模拟不同的场景,对软件各项性能指标进行测试和评估的过程。1.1.3 性能测试的目的?评估当前系统能力寻找性能瓶颈,优化性能评估软件是否能够满足未来的需要1.2 性能测试和功能测试:1.2.1 功能测试和性能测试有什么不同?功能测试:验证系统的功能需求规格。焦点:功能(正向、逆向)性能测试:验证系统的业务需求场景。焦点:时间、资源1.2.2 功能测试和性能测试有什么关系?一般项目中,先功能测试通过后,后进行性能测试。2 性能测试分类:2.1 基准测试:(1)概念:狭义上讲:就是单用户测试。(单用户循环多次得到的数据)广义上讲:建立基准线,当系统的软硬件环境发生变化之后再进行一次基准测试以确定变化对性能的影响。(2)作用基准测试不会单独存在为多用户并发测试和综合场景测试等提供参考依据为系统/环境配置、系统优化前后的性能提升/下降提供参考指标2.2 负载测试(1)概念:通过逐步增加系统负载,确定在满足系统的性能指标(如响应时间等)情况下,找出系统所能够承受的最大负载量的测试。(2)作用系统最大负载量达到用户要求时,系统才能正式上线使用。案例:电梯行业规范:电梯从1楼到5楼(15m)的运行时间不超过24s进行负载测试:case1: 1人乘坐电梯,从1楼到5楼,运行时间为20scase2:7人乘坐电梯,从1楼到5楼,运行时间为20scase3: 13人乘坐电梯,从1楼到5楼,运行时间为20s--->[最大负载量]case4: 16人乘坐电梯,从1楼到5楼,运行时间为25sCase5: 19人乘坐电梯,从1楼到5楼,运行时间为28sCase6: 21人乘坐电梯,从1楼到5楼,运行过程中绳子断了。。。注意:通过负载测试,可以确定系统的最大负载量和极限负载量系统对外宣称的最大负载量负载测试的时间一般为1-2小时2.3 稳定性测试:(1)概念在服务器稳定运行(用户正常的业务负载下)的情况下进行长时间测试(1天-1周等),并最终保证服务器能满足线上业务需求。(2)作用系统在用户要求的业务负载下运行达到规定的时间时,系统才能正式上线使用。2.4 其它分类-压力测试背景:1、软件实际使用时,用户量超过预期(系统最大负载量),该如何反应?2、软件由于意外情况出现问题,多久能恢复?(1)概念:在强负载下的测试,查看系统在峰值情况下是否功能隐患、系统是否具有良好的容错能力和可恢复能力。(2)测试场景极限负载情况下的破坏性压力测试。高负载下的长时间的稳定性压力测试。2.5 其它分类-压力并发测试:(1)概念:并发测试(绝对并发):是指在极短的时间内,发送多个请求,来验证服务器对并发的处理能力。(2)应用场景特定活动场景,如:抢红包、秒杀、抢购等。生活中的案例:悬赏任务:做菜一西红柿炒鸡蛋(但是只有一个鸡蛋和一个西红柿)(3)与负载测试对比:负载测试:主要目的是测试高负载情况下,对系统资源的消耗,是否会耗尽的问题(双11活动)并发测试:主要目的是测试极短时间内,并发请求时,系统资源争抢的问题(抢红包、秒杀)3 性能测试的指标3.1 响应时间:指从客户端发起请求开始,到客户端接收到结果的总时间包括:服务器处理时间 + 网络传输时间3.2 并发用户数:某一时刻同时向服务器发送请求的用户数案例:淘宝系统案例—哪个是并发数?3.3 吞吐量:吞吐量(Throughput):指的是单位时间内处理的客户端请求数量,直接体现软件系统的性能承载能力。从业务角度来看单位:“业务数/小时”、“业务数/天”、“访问人数/天”、“页面访问量/天”从网络角度来看单位:“字节数/小时”、“字节数/天”从技术角度来看单位:每秒事务数(TPS)、每秒查询数(QPS)QPS:QPS(Query Per Second)每秒查询数:即控制服务器每秒处理的指定请求的数量TPS:TPS(Transactions Per Second)每秒事务数:即控制服务器每秒处理的事务请求的数量事务:即业务,页面上的一次操作,可能对应一个请求/多个请求。3.4 点击数:所有的页面元素(如:图片、链接、框架等)的请求总数量.注意:点击数是请求数,不是页面上的一次点击3.5 错误率:指系统在负载情况下,失败业务的概率注意:错误率是性能指标,是高负载下的失败业务的概率随机bug是功能bug,先解决随机bug才能进行性能测试3.6 资源利用率:(1)什么是资源利用率?系统各种资源的使用情况,“资源的使用量/总的资源可用量×100%”(2)常见资源指标有哪些?CPU使用率:不高于75%-85%内存(大小)使用率:不高于80%磁盘IO(速率):不高于90%网络(速率):不高于80%4.性能测试的流程性能测试的核心:需求分析、性能测试执行、性能分析调优4.1 需求分析4.2 性能测试计划和方案测什么项目背景测试目的测试范围谁来测进度与分工交付清单怎么测测试策略4.3 编写性能测试用例用例模板:4.4 性能测试执行4.5 性能分析和调优性能测试分析人员经过对结果的分析以后,如果不符合性能需求,则会提出性能bug,然后由开发人员进行后续的调优。提示:调优-开发人员为主导,数据库管理员、系统管理员、网络管理员、性能测试分析人员配合进行验证-性能测试人员继续进行第二轮、第三轮.的测试,与以前的测试结果进行对比,从而确定经过调整以后系统的性能是否有提升4.6 性能测试报告总结测试报告是对性能测试工作的总结,为软件后续验收和交付打下基础。测试报告的主要内容:测试工作的经过回顾缺陷分析和调优风险评估性能测试结果测试工作总结与改进5.性能测试工具介绍5.1 Loadrunner简介HP Loadrunner是一种工业级标准性能测试负载工具,可以模拟上万用户实施测试,并在测试时可实时检测应用服务器及服务器硬件各种数据,来确认和查找存在的瓶颈支持多协议:Web(HTTP/HTML)、Windows Sockets、FTP、ODBC、MS SQL Server等协议采用c语言编写优点1.多用户(支持用户以万为单位)2.详细的分析报表(以秒为单位)3.支持IP欺骗功能缺点:1.收费2.体积庞大(安装包单位GB)3.无法定制功能5.2 JMeterJMeter是Apache组织开发的基于Java的开源软件,用于对系统做功能测试和性能测试。它最初被设计用于web应用测试,但后来扩展到其他测试领域,例如静态文件、Java程序、shell脚本、数据库、FTP、 Mail等。优点:1.开源免费2.小巧(安装包50MB左右)3.丰富的学习资料和扩展组件缺点:1.不支持IP欺骗2.分析和报表能力相对于LR欠缺精度(以分钟为单位)5.3 对比相同点1.都能模拟大量用户2.都能支持多协议(常见的协议都支持,如:HTTP)3.都有监控及分析报表功能不同点结论:项目日常性能测试Jmeter足够用,出商业报告优先Loadrunner6.JMeter安装和基本使用6.1 JMeter安装安装JDK安装 JMeter下载JMeterjmeter是免安装的,下载解压配置环境变量即可使用。官网下载地址:http://jmeter.apache.org/download_jmeter.cgi环境配置(可不配)jdk1.8环境配置:Java -version 查看jdk版本。jmeter环境配置(不配置不影响)1)桌面上选择“我的电脑”(右键),高级, 环境变量, 在“系统变量”—>“新建”, 在变量名中输:JMETER_HOME,变量值中输入:D:\apache-jmeter-2.112)再修改CLASSPATH变量,变量值中添加%JMETER_HOME%\lib\ext\ApacheJMeter_core.jar;% JMETER_HOME%\lib\jorphan.jar;%JMETER_HOME%\lib\logkit-1.2.jar; 然后确定即可。Jmeter启动三种方式:进入JMeter安装目录下的bin目录1、双击 jmeter.bat2、双击ApacheJMeter.jar3、命令行输入:java-jar ApacheJMeter.jar启动效果6.2 JMeter常用目录介绍和汉化设置6.2.1 常用文件目录介绍Bin目录:存放可执行文件和配置文件docs目录:是JMeter的api文档,用于开发扩展组件printable_docs目录:用户帮助手册lib目录:存放JMeter依赖的jar包和用户扩展所依赖的jar包6.2.2 JMeter界面的汉化临时性:启动JMeter->选择菜单、Options'->Choose Language->Chinese(Simplified)永久性 — 修改配置文件:1.找到jMeter安装目录下的bin目录2.打开jmeter.properties文件,把第37行修改为"language=zh_CN"3.重启JMeter即可7.JMeter原件和组件介绍7.1 元件的基本介绍元件:多个类似功能组件的容器(类似于类)如上图所示,主要包括:1.取样器:发送请求2.逻辑控制器:控制语句的执行顺序3.前置处理器:对请求参数进行预处理4.后置处理器:对响应结果进行提取5.断言:检查接口的返回结果是否与预期结果一致6.定时器:设置等待7.测试片段:封装一段代码,供其他脚本调用8.配置元件:测试数据的初始化配置7.2 组件的基本介绍组件:实现独立的某个功能(类似于方法)例如:取样器的组件7.3 小结如下接口自动化脚本的实现过程对应着Jmeter哪个元件?元件与组件有什么关系?元件:多个类似功能组件的容器(类似于类)组件:容器中实现独立的某个功能(类似于方法)7.4 Jmeter元件作用域和执行顺序元件的作用域:是靠测试计划的树形结构中元件的父子关系来确定的。提示:所有的组件都是以取样器为核心来运行的。组件添加的位置不同,生效的取样器也不同作用域的原则:取样器:核心,不和其他元件相互作用,没有作用域。逻辑控制器:只对其子节点中的取样器和逻辑控制器起作用。其他元件:如果是某个取样器的子节点,则该元件只对其父节点起作用。如果其父节点不是取样器,则其作用域是该元件父节点下的其他所有后代节点(包括子节点,子节点的子节点等)。元件的执行顺序同一个作用域下不同类型元件:1.配置元件(config elements)2.前置处理程序(Per-processors)3.定时器(timers)4.取样器(Sampler)5.后置处理程序(Post-processors)6.断言(Assertions)7.监听器(Listeners)同一个作用域下多个相同类型元件:按照在测试计划中从上到下的顺序依次执行执行顺序样例正确:定时器1-请求1-定时器1-定时器2-请求2-定时器1-定时器3-请求38.Jmeter第一个案例需求:使用JMeter访问百度首页接口,并查看请求和响应信息步骤:1.启动JMeter2.在测试计划下添加线程组3.在线程组,下添加HTTP请求取样器4.填写HTTP请求的相关请求数据5·在线程组下添加查看结果树监听器6.点启动按钮运行,并查看结果9.Jmeter三个重要组件(重点)9.1 线程组作用:线程组就是控制Jmeter用于执行测试的一组用户位置:右键点击、测试计划'-->添加-->线程(用户)-->线程组特点:模拟多人操作线程组可以添加多个,多个线程组可以并行或串行取样器(请求)和逻辑控制器必须依赖线程组才能使用线程组下可以添加其他元件下组件线程组分类:普通线程组:普通的、常用的线程组,可以看做一个虚拟用户组,线程组中的每一个线程都可以理解为一个虚拟用户setUp线程组:一种特殊类型的线程组,可用于执行预测试操作tearDown线程组:一种特殊类型的线程组,可用于执行测试后工作线程组的属性:练习:如下场景如何设置线程组?模拟10个用户并行执行:----线程数模拟10个用户5s内启动完成:----线程数10,ramp-up时间:5s模拟2个用户各循环3次:----线程数:2,循环次数:3模拟2个用户运行30s:----线程数:2,循环:永远,持续时间:30s模拟2个用户等待10s后开始执行:----在上一个的基础上,增加延迟启动时间:10s9.2 HTTP请求作用:向服务器发送http及https请求位置:选中线程组->右键->添加->取样器->HTTP请求参数:案例:案例一:GET请求,URL为http://www.baidu.com/S?wd=test要求:使用HTTP请求-路径来传递get请求参数案例二:GET请求,URL为https://www.baidu.com/S?wd=test要求:使用HTTP请求-参数列表来传递get请求的参数案例三:PosT请求,URL为https://www.baidu.com/S,请求体为:wd=test(form表单)要求:使用HTTP请求-参数列表来传递POST请求的form格式参数案例四:POST请求,URL为http://www.baidu.com/s,请求体为:wd=test(form表单)要求:使用HTTP请求-消息体数据来传递POST请求的form格式参数9.3 查看结果树作用:查看HTTP请求的请求和响应结果位置:选中测试计划/线程组->右键->添加->监听器->察看结果树组成:取样结果:查看响应信息头信息、响应状态码请求:查看请求相关信息(url、方法、参数)响应:查看响应信息10.Jmeter参数化定义:使用不同的测试数据,调用相同的测试方法进行测试本质:实现测试数据与测试方法的分离。JMeter中常见的参数化方式用户定义的变量——全局变量用户参数——为每个用户分配不同的参数值CSV数据文件设置——文件方式参数化函数——随机数据数据库全局变量步骤:1.添加线程组2.添加用户定义的变量。格式:变量名-变量值3.添加HTTP请求,引用定义的变量名。格式: ${变量名}4.添加查看结果树用户参数-[在线程组配置]作用:针对同一组参数,当不同的用户来访问时,可以获取到不同的值步骤:添加线程组,设置线程数为n(表示模拟的用户数)添加用户参数第一列添加多个变量含后续每一列为一组用户的数据3.添加HTTP请求用定义的变量名。格式: ${变量名}4.添加查看结果树CSV数据文件设置作用:当不同的用户,或者同一个用户多次循环时,都可以获取到不同的值位置:测试计划-->线程组--> 配置元件--> CSV 数据文件设置步骤:1.定义csv数据文件user01,123456,0000 user02, 123456, 1111 user03, 123456, 22222.添加线程组3.添加csv数据文件设置4.添加HTTP请求,引用定义的变量名。格式: ${变量名}5.添加查看结果树函数(案例:_counter函数)为什么要使用函数参数化?性能测试时,如果模拟1000个用户,每个用户循环执行10万次添加商品操作,请求参数要求不同,该怎么做?作用:计数函数,一般做执行次数统计使用位置:在菜单中选择-->选项-->函数助手对话框设置:TRUE,每个用户有自己的计数器;FALSE,使用全局计数器Name of variable in which to store the result(optional):用于存储结果的变量名(可选)操作步骤:1.添加线程组,设置虚拟用户数和循环次数2.生成_counter函数3.添加HTTP请求,使__counter函数4添加查看结果树4种参数化方式有何不同?如何选择适当的方式?用户定义的变量:-作用:定义全局变量-局限性:每次取值(无论是否相同的用户)都是固定值用户参数:-作用:保证不同的用户针对同一组参数,可以取到不同的值-局限性:同一个用户在多次循环时,取到相同的值csv数据文件设置:-作用:保证不同的用户及同一用户多次循环时,都可以取到不同的值-局限性:需要手动进行测试数据的设置函数:-作用:保证不同的用户及多次循环时,都可以取到。的值,不需要提前设置-局限性:输入数据有特定的业务要求时无法使用(如:登录时的用户名密码)参考资料黑马程序员性能测试全套教程,4天快速入门性能测试+项目商城实战JMeter安装教程
-
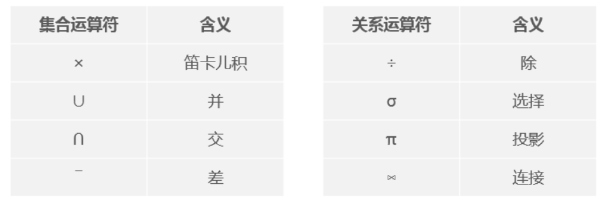
牛客刷题笔记 mysql1.MySQL的NULL值处理方法在MySQL中不能使用 = NULL 或 != NULL 等比较运算符在列中查找 NULL 值 。要用IS NULL 或 IS NOT NULL才会进行NULL值或非NULL值得查找。2.从一张表中选取数据插入到另一张表中INSERT INTO 语句用于向一张表中插入新的行。SELECT INTO 语句从一张表中选取数据插入到另一张表中。常用于创建表的备份复件或者用于对记录进行存档。3.关系代数运算中的集合运算符和关系运算符4.having必须跟在group By后面having必须跟在group By后面,不然会报错In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'db_sql.course_sku_publish_record.id'; this is incompatible with sql_mode=only_full_group_by ... 展开5.关于mysql的insert语句insert字段名顺序与字段值顺序一致即可,可以给部分或所有字段名加``。Mysql中表student_info(id,name,birth,sex),字段类型都是varchar,插入:1018 , 赵六 , 2003-08-02 , 男;SQL正确的是()?A insert overwrite student_info values('1018' , '赵六' , '2003-08-02' , '男');B insert into student_info values(1018 , '赵六' , '2003-08-02' , '男');C insert into student_info(birth,id,name,sex) values('2003-08-02' ,'1018' , '赵六' , '男');D insert into student_info value('1018' , '赵六' , '2003-08-02' , '男');正确答案:C你的答案:D官方解析:A执行报错,插入时是insert into不是insert overwrite;B执行报错,id是varchar类型,插入的1018需要加上单引号;D执行报错,插入时是values不是value;所以C正确,字段名顺序与字段值顺序一致即可,可以给部分或所有字段名加``。知识点:数据库、SQL6.MySQL中ALTER TABLE命令的用法MySQL中ALTER TABLE命令可以修改数据表的表名或数据表的字段。但是接不同后缀意义不同,比如:要修改表名或索引名时,可以用RENAME函数;当然RENAME也可以更改列名,但是后面要加TO,且它只会更改列的名字,并不更改定义。要修改字段定义和名称,可以用MODIFY或CHANGE函数。但是MODIFY只改字段定义,不改名字;CHANGE是两个都可以修改。要修改字段默认值,可以用ALTER 字段名 SET DEFULT 更改值。1.要将employee 的表名更改为 employee_info,下面MySQL语句正确的是:A ALTER TABLE employee RENAME employee_info;B ALTER TABLE employee MODIFY employee_info;C ALTER TABLE employee ALTER employee_info;D ALTER TABLE employee CHANGE employee_info;正确答案:A你的答案:B官方解析:本题考察知识点:MySQL中ALTER TABLE命令的用法MySQL中ALTER TABLE命令可以修改数据表的表名或数据表的字段。但是接不同后缀意义不同,比如:要修改表名或索引名时,可以用RENAME函数;当然RENAME也可以更改列名,但是后面要加TO,且它只会更改列的名字,并不更改定义。要修改字段定义和名称,可以用MODIFY或CHANGE函数。但是MODIFY只改字段定义,不改名字;CHANGE是两个都可以修改。要修改字段默认值,可以用ALTER 字段名 SET DEFULT 更改值。所以根据题意,要修改表名,只能用RENAME函数,因此A正确;BCD则分别是修改字段的方法。知识点:数据库、SQL7.MySql修改表名的两种方法rename table 旧表名 to 新表名; alter table 旧表名 rename [as] 新表名8.MySQL中ALTER TABLE修改字段用法-- 新增字段 ALTER TABLE 表名 ADD COLUMN 字段名 字段类型; -- 在name字段后面新增一个age列 ALTER TABLE tuser ADD COLUMN age int(11) DEFAULT NULL COMMENT '年龄' AFTER name; # AFTER:在某字段后, BEFOR:在某字段之前 -- 在表后追加一列 ALTER TABLE tuser ADD COLUMN age int(11) DEFAULT NULL COMMENT '年龄'; -- 修改字段 ALTER TABLE tuser CHANGE name user_name varchar(32) DEFAULT NULL COMMENT '姓名'; # ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型; -- 修改字段类型 ALTER TABLE tuser MODIFY name varchar(32) DEFAULT NULL COMMENT '姓名'; # ALTER TABLE 表名 MODIFY 字段名 数据类型; -- 删除字段 ALTER TABLE tuser DROP name; # ALTER TABLE 表名 DROP 字段名;9.多表删除时,delete和from之间必须要写明想要删除记录的表名。Mysql中表student_table(id,name,birth,sex),删除name重复的id最大的记录,比如'张三'重复2次,id分别是1、2,则删除id=2的记录,保留id=1的记录。如下SQL正确的是()?A delete from student_table where id in (select t2.*from(select name,count(*) as c1 from student_table GROUP BY name having c1 > 1)t1left join(select name, max(id) as id from student_table group by name ) t2on t1.name = t2.name ) ;B delete from student_table t0inner join (select t2.*from(select name,count(*) as c1 from student_table GROUP BY name having c1 > 1)t1left join(select name, max(id) as id from student_table group by name ) t2on t1.name = t2.name ) t3on t0.id = t3.id ;C delete t0from student_table t0inner join (select t2.*from(select name,count(*) as c1 from student_table GROUP BY name having c1 > 1)t1left join(select name, max(id) as id from student_table group by name ) t2on t1.name = t2.name ) t3on t0.id = t3.id ;D delete student_tablefrom student_table t0inner join (select t2.*from(select name,count(*) as c1 from student_table GROUP BY name having c1 > 1)t1left join(select name, max(id) as id from student_table group by name ) t2on t1.name = t2.name ) t3on t0.id = t3.id ;10.COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入)而COUNT(*) 函数才返回表中的记录数11.MySQL添加用户、删除用户、授权及撤销权限创建用户 insert into mysql.user(Host,User,Password) values("localhost","test",password("1234"));这样就创建了一个名为:test 密码为:1234 的用户。注意:==此处的"localhost",是指该用户只能在本地登录,不能在另外一台机器上远程登录。如果想远程登录的话,将"localhost"改为"%",表示在任何一台电脑上都可以登录。也可以指定某台机器(例如192.168.1.10),或某个网段(例如192.168.1.%)可以远程登录。==为用户授权:授权格式:grant 权限 on 数据库.* to 用户名@登录主机 identified by "密码"; 首先为用户创建一个数据库(testDB):mysql>create database testDB;授权test用户拥有testDB数据库的所有权限(某个数据库的所有权限):mysql>grant all privileges on testDB.* to test@localhost identified by '1234'; mysql>flush privileges;//刷新系统权限表,即时生效如果想指定某库的部分权限给某用户本地操作,可以这样来写:mysql>grant select,update on testDB.* to test@localhost identified by '1234'; mysql>flush privileges; 常用的权限有select,insert,update,delete,alter,create,drop等。可以查看mysql可授予用户的执行权限了解更多内容。2.4 授权test用户拥有所有数据库的某些权限的远程操作: mysql>grant select,delete,update,create,drop on *.* to test@"%" identified by "1234"; #test用户对所有数据库都有select,delete,update,create,drop 权限。2.5 查看用户所授予的权限:mysql> show grants for test@localhost;撤销已经赋予用户的权限:revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可:mysql>grant all on *.* to dba@localhost; mysql>revoke all on *.* from dba@localhost;12.drop、trustcate、delete1:处理效率:drop>trustcate>delete2:删除范围:drop删除整个表(结构和数据一起删除);trustcate删除全部记录,但不删除表结构;delete只删除数据3:高水位线:delete不影响自增ID值,高水线保持原位置不动;trustcate会将高水线复位,自增ID变为1。13.mysql select 字段重命名as可以做重命名,不过也可以省略as,空格隔开新名称即可。14.mysql设置外键todo2.java1.java中接口、接口属性、接口方法的修饰符合java接口的修饰符:abstract(默认不写。interface本身就是抽象的,加不加abstract都一样)接口中字段的修饰符:public static final(默认不写) 接口中方法的修饰符:public abstract(默认不写)2.java中的数组创建形式声明的二维数组中第一个中括号中必须要有值,它代表的是在该二维数组中有多少个一维数组。 下面哪个语句是创建数组的正确语句?( )A float f[][] = new float[6][6];B float []f[] = new float[6][6];C float f[][] = new float[][6];D float [][]f = new float[6][6];E float [][]f = new float[6][];正确答案:ABDE3.关于java继承在java中,下列对继承的说法,正确的是( )A 子类能继承父类的所有成员B 子类继承父类的非私有方法和状态C 子类只能继承父类的public方法和状态D 子类只能继承父类的方法正确答案:A官方解析:Constructors, static initializers, and instance initializers are not members andtherefore are not inherited.(构造器、静态初始化块、实例初始化块不继承)4.java线程的start()和run()的区别t.run直接执行代码,按顺序打印代码; t.start是另起线程,与当前线程同时竞争cpu资源,结果存在不确定性下面程序的运行结果是:( )public static void main(String args[]) { Thread t = new Thread() { public void run() { pong(); } }; t.run(); System.out.print("ping"); } static void pong() { System.out.print("pong"); }A pingpongB pongpingC pingpong和pongping都有可能D 都不输出E pongF ping5.java集合体系判断对错。List,Set,Map都继承自继承Collection接口。A 对B错正确答案:B你的答案:A参考答案:答案:B List,Set等集合对象都继承自Collection接口 Map是一个顶层结果,不继承自Collection接口6.this不能在static的方法中使用已知有下列Test类的说明,在该类的main方法的横线处,则下列哪个语句是正确的?()public class Test { private float f = 1.0f; int m = 12; static int n = 1; public static void main (String args[]) { Test t = new Test(); ———————— } }A t.f = 1;B this.n = 1;C Test.m = 1;D Test.f = 1;正确答案:A你的答案:BA的答案中变量虽然为private,但因为main函数在该类中,所以即使private也仍可使用,B的答案static变量不能使用this7.Java中的byte,short,char进行计算时都会提升为int类型。代码片段:byte b1=1,b2=2,b3,b6; final byte b4=4,b5=6; b6=b4+b5; b3=(b1+b2); System.out.println(b3+b6);关于上面代码片段叙述正确的是()A 输出结果:13B 语句:b6=b4+b5编译出错C 语句:b3=b1+b2编译出错D 运行期抛出异常正确答案:C你的答案:A参考答案:C. 被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了 而b1和b2是byte类型,java中进行计算时候将他们提升为int类型,再进行计算,b1+b2计算后已经是int类型,赋值给b3,b3是byte类型,类型不匹配,编译不会通过,需要进行强制转换。 Java中的byte,short,char进行计算时都会提升为int类型。8.boolean 类型不能转换成任何其它数据类型。Java中可以将布尔值与整数进行比较吗 ?A 可以B 不可以正确答案:B你的答案:A官方解析:boolean 类型不能转换成任何其它数据类型。9.java中的char是两个字节执行如下程序代码char chr = 127; int sum = 200; chr += 1; sum += chr;后,sum的值是()备注:同时考虑c/c++和Java的情况的话A 72B 99C 328D 327正确答案:AC你的答案:Ajava中只有byte, boolean是一个字节, char是两个字节, 所以对于java来说127不会发生溢出, 输出328 但是对于c/c++语言来说, char是一个字节, 会发生溢出, 对127加一发生溢出, 0111 1111 --> 1000 0000, 1000 0000为补码-128, 所以结果为200-128=7210.java中Object类的方法有哪些?equals(Object obj): 该方法用于比较当前对象与参数对象是否相等。hashCode(): 该方法返回该对象的哈希码值。toString(): 该方法返回该对象的字符串表示。clone(): 该方法创建并返回该对象的副本。finalize(): 该方法是垃圾回收器在对该对象进行清理之前调用的方法。getClass(): 该方法返回表示此对象的运行时类(包含该对象的类的对象)的Class对象。wait(long timeout): 该方法使当前线程等待,直到另一个线程调用该对象的notify()或notifyAll()方法,或者经过指定的时间量。wait(long timeout, int nanos): 该方法使当前线程等待,直到另一个线程调用该对象的notify()或notifyAll()方法,或者经过指定的时间量和纳秒数。notify(): 该方法唤醒正在等待该对象监视器的单个线程(如果没有线程在等待,则抛出IllegalMonitorStateException异常)。notifyAll(): 该方法唤醒正在等待该对象监视器的所有线程。在JAVA中,下列哪些是Object类的方法()A synchronized()B wait()C notify()D notifyAll()E sleep()正确答案:BCD你的答案:BCDE参考答案:A synchronized Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。 B C D 都是Object类中的方法 notify(): 是唤醒一个正在等待该对象的线程。 notifyAll(): 唤醒所有正在等待该对象的线程。 E sleep 是Thread类中的方法 wait 和 sleep的区别: wait指线程处于进入等待状态,形象地说明为“等待使用CPU”,此时线程不占用任何资源,不增加时间限制。 sleep指线程被调用时,占着CPU不工作,形象地说明为“占着CPU睡觉”,此时,系统的CPU部分资源被占用,其他线程无法进入,会增加时间限制。11.java中整数类型 默认为 int 带小数的默认为 double在基本JAVA类型中,如果不明确指定,整数型的默认是什么类型?带小数的默认是什么类型?A int floatB int doubleC long floatD long double正确答案:B你的答案:A参考答案:整数类型 默认为 int 带小数的默认为 double12.java访问控制修饰符default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)public : 对所有类可见。使用对象:类、接口、变量、方法protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。我们可以通过以下表来说明访问权限:修饰符当前类同一包内子孙类(同一包)子孙类(不同包)其他包publicYYYYYprotectedYYYY/N(说明)NdefaultYYYNNprivateYNNNN13.java中创建线程的方法实现Runnable接口:这是最常用的方法。创建一个实现了Runnable接口的类,然后实现run()方法。这个run()方法将包含线程应该运行的代码。然后,创建一个Thread对象,并将Runnable对象作为参数传递给Thread的构造函数。最后,调用Thread对象的start()方法来启动线程。继承Thread类:这是另一种创建线程的方法,但是通常不推荐使用,因为Java不支持多重继承。创建一个继承了Thread类的类,然后重写run()方法。然后,创建一个Thread对象,并调用start()方法来启动线程。使用Callable和Future:这是一种更现代的方法,主要用于并发编程。Callable接口与Runnable接口类似,但Callable可以返回结果并且可以抛出异常。Future接口代表异步计算的结果。通过使用ExecutorService,你可以执行Callable任务并获取Future对象,然后使用Future对象的get()方法获取结果。14.jvm内存:堆区栈区存储下列Java代码中的变量a、b、c分别在内存的____存储区存放。class A { private String a = “aa”; public boolean methodB() { String b = “bb”; final String c = “cc”; } }A 堆区、堆区、堆区B 堆区、栈区、堆区C 堆区、栈区、栈区D 堆区、堆区、栈区E 静态区、栈区、堆区F 静态区、栈区、栈区正确答案:C你的答案:F参考答案:答案是C a是类中的成员变量,存放在堆区 b、c都是方法中的局部变量,存放在栈区15.java流体系16.java异常体系17.java类加载过程Java类加载过程是Java虚拟机(JVM)运行时将类文件加载到内存中的过程。这个过程可以分为三个阶段:加载、链接(验证、准备、解析)和初始化。加载:这是类加载过程的第一个阶段,主要任务是加载类。JVM通过类的全限定名来获取定义此类的二进制字节流。这个过程主要通过以下几种方式完成:通过类路径(Classpath)查找类文件(.class文件)。从JAR或ZIP文件中读取,这些文件可能被放在类路径中。从网络或其他源动态加载。通过Java反射机制从已加载的类中生成。链接:这个阶段是验证、准备和解析阶段,主要任务是确保被加载的类文件的正确性,为类的静态变量分配内存并设置初始值,以及解析符号引用。验证:确保被加载的类文件的正确性,没有安全方面的隐患。准备:为类的静态变量分配内存,并设置默认的初始值。解析:将符号引用转换为直接引用。符号引用是在编译时生成的,包含了被引用的类的全限定名;而直接引用可以直接指向数据。初始化:这是类加载过程的最后一个阶段,主要任务是执行类构造器方法<clinit>()。这个方法是由编译器自动收集类中的所有类变量的赋值动作和静态代码块(但不执行其中的方法)组成的。JVM会创建Class对象,并执行<clinit>()方法。注意,类加载器在执行完这三个阶段后,会为这个类生成一个Class对象,这个Class对象在JVM中表示这个类的类型信息。每个Class对象都对应于Java虚拟机中的元空间的一个类或接口的符号引用。此外,Java类加载器有三种:启动类加载器(Bootstrap Class Loader):负责加载核心类库,如 rt.jar、resources.jar、charsets.jar等,它是其他所有类加载器的父类加载器。由于该类加载器负责加载的是核心类库,所以它是不负责扩展类的加载的。扩展类加载器(Extension Class Loader):该类加载器负责加载JRE的扩展目录(java.ext.dirs系统属性或者java.library.path)中的类库,它是ExtensionClassLoader的父类加载器。由于该类加载器是ClassLoader中的sun.misc.Launcher$ExtClassLoader的默认实现,所以一般情况下我们不需要直接使用扩展类加载器。系统类加载器(System Class Loader):也被称为应用程序类加载器(Application Class Loader),它负责在应用程序的classpath中查找并加载类。它是ClassLoader中的sun.misc.Launcher$AppClassLoader的默认实现,也是我们最常直接使用的类加载器。以下哪项不属于java类加载过程?A 生成java.lang.Class对象B nt类型对象成员变量赋予默认值C 执行static块代码D 类方法解析正确答案:B你的答案:D参考答案:不应该选D,而应该选B 类的加载包括:加载,验证,准备,解析,初始化。 选项A:生成java.lang.Class对象是在加载时进行的。生成Class对象作为方法区这个类的各种数据的访问入口。 选项B:既然是对象成员,那么肯定在实例化对象后才有。在类加载的时候会赋予初值的是类变量,而非对象成员。 选项C:这个会调用。可以用反射试验。 选项D:类方法解析发生在解析过程。18. sleep、wait、yield、join区别sleepsleep 方法是属于 Thread 类中的,sleep 过程中线程不会释放锁,只会阻塞线程,让出cpu给其他线程,但是他的监控状态依然保持着,当指定的时间到了又会自动恢复运行状态,可中断,sleep 给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会waitwait 方法是属于 Object 类中的,wait 过程中线程会释放对象锁,只有当其他线程调用 notify 才能唤醒此线程。wait 使用时必须先获取对象锁,即必须在 synchronized 修饰的代码块中使用,那么相应的 notify 方法同样必须在 synchronized 修饰的代码块中使用,如果没有在synchronized 修饰的代码块中使用时运行时会抛出IllegalMonitorStateException的异常yield和 sleep 一样都是 Thread 类的方法,都是暂停当前正在执行的线程对象,不会释放资源锁,和 sleep 不同的是 yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态,它只需要等待重新获取CPU执行时间,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。还有一点和 sleep 不同的是 yield 方法只能使同优先级或更高优先级的线程有执行的机会join等待调用join方法的线程结束之后,程序再继续执行,一般用于等待异步线程执行完结果之后才能继续运行的场景。例如:主线程创建并启动了子线程,如果子线程中药进行大量耗时运算计算某个数据值,而主线程要取得这个数据值才能运行,这时就要用到 join 方法了下列哪些操作会使线程释放锁资源?A sleep()B wait()C join()D yield()正确答案:BC你的答案:BD19.java ThreadLocalThreadLocal是Java中的一个类,它提供了线程局部变量(thread-local variables)的实现。线程局部变量允许程序员将与线程关联的特定值(通常是一个对象引用)存储在变量中。每个线程都可以拥有自己独立的变量副本,而不会与其他线程共享。ThreadLocal的主要用途是解决多线程中的数据同步问题,避免使用synchronized关键字来锁定整个方法或代码块,从而提高程序的性能。ThreadLocal的工作原理是:每个线程持有一个该变量的副本,当线程需要访问该变量时,它将获取自己的副本,而不是共享变量。因此,每个线程都可以独立地修改自己的变量副本,而不会影响其他线程的变量。ThreadLocal的使用方法如下:创建一个ThreadLocal对象:ThreadLocal<Integer> threadLocal = new ThreadLocal<>();将值设置为每个线程的变量副本:threadLocal.set(42); // 设置当前线程的变量副本为42从每个线程获取自己的变量副本:int value = threadLocal.get(); // 获取当前线程的变量副本的值在不再需要时清除当前线程的变量副本:threadLocal.remove(); // 清除当前线程的变量副本ThreadLocal在Web开发中经常被用于存储每个请求的上下文信息,例如用户信息、会话信息等。这样,每个请求都可以有自己的独立上下文,而不会与其他请求共享。20.关于HashMap的知识点a) HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。HashMap的底层结构是一个数组,数组中的每一项是一条链表。 b) HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子。 c) HashMap实现不同步,线程不安全。 HashTable线程安全 d) HashMap中的key-value都是存储在Entry中的。 e) HashMap可以存null键和null值,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性 f) 解决冲突主要有三种方法:定址法,拉链法,再散列法。HashMap是采用拉链法解决哈希冲突的。21.关于java的内存区域以下描述错误的一项是( )?A 程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行 到了第几行,是线程隔离的B 原则上讲,所有的对象都是在堆区上分配内存,是线程之间共享的C 方法区用于存储JVM加载的类信息、常量、静态变量,即使编译器编译后的代码等数据,是线程隔离的D Java方法执行内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的22.三元操作符如果遇到可以转换为数字的类型,会做自动类型提升。以下JAVA程序的运行结果是什么( )public static void main(String[] args) { Object o1 = true ? new Integer(1) : new Double(2.0); Object o2; if (true) { o2 = new Integer(1); } else { o2 = new Double(2.0); } System.out.print(o1); System.out.print(" "); System.out.print(o2); }A 1 1B 1.0 1.0C 1 1.0D 1.0 1正确答案:D你的答案:A23.类实现多个接口的时候,只需要一个implements,多个接口通过逗号进行隔开,先继承类再实现接口在java中,已定义两个接口B和C,要定义一个实现这两个接口的类,以下语句正确的是()A interface A extends B,CB interface A eimplements B,CC class A implements B,CD class A implements B,implements C正确答案:C你的答案:D24.类中实例变量可以不用初始化,使用相应类型的默认值即可;方法中的定义的局部变量必须初始化,否则编译不通过。下面代码的运行结果是()public static void main(String[] args){ String s; System.out.println("s="+s); }A 代码编程成功,并输出”s=”B 代码编译成功,并输出”s=null”C 由于String s没有初始化,代码不能编译通过。D 代码编译成功,但捕获到NullPointException异常正确答案:C你的答案:A参考答案:局部变量没有默认值25.switch支持 int及以下(char, short, byte),String, Enum 。不支持long类型在java7中,下列不能做switch()的参数类型是?A int型B 枚举类型C 字符串D 浮点型正确答案:D你的答案:B参考答案:Dswitch语句后的控制表达式只能是short、char、int整数类型和枚举类型,不能是float,double和boolean类型。String类型是java7开始支持。下面的switch语句中,x可以是哪些类型的数据:()switch(x) { default: System.out.println("Hello"); }A longB charC floatD byteE doubleF String正确答案:BDF你的答案:ABDF26.java是面向对象的,但是不是所有的都是对象,基本数据类型就不是对象,所以才会有封装类的;27.java多线程生命周期及对应的方法调用以下哪个事件会导致线程销毁?()A 调用方法sleep()B 调用方法wait()C start()方法的执行结束D run()方法的执行结束正确答案:D你的答案:C28.抛InterruptedException的代表方法有:java.lang.Object 类的 wait 方法java.lang.Thread 类的 sleep 方法java.lang.Thread 类的 join 方法29.线程安全的集合有Vector、Stack、Hashtable30. 数组无论是在定义为实例变量还是局部变量,若没有初始化,都会被自动初始化31. 发生继承关系时父子类代码执行顺序1.父类静态代码块:如果有多个静态代码块,按顺序执行,仅执行一遍2.子类静态代码块:同上3.父类非静态代码块: 有多个非静态代码块,按顺序执行,且每次new,每次执行4.父类构造函数5.子类非静态代码块: 有多个非静态代码块,按顺序执行,且每次new,每次执行6.子类构造函数32.序列化的是对象,不是类,类变量不会被序列化有以下一个对象:public class DataObject implements Serializable{ private static int i=0; private String word=" "; public void setWord(String word){ this.word=word; } public void setI(int i){ Data0bject.i=i; } }创建一个如下方式的DataObject:DataObject object=new Data0bject ( ); object.setWord("123"); object.setI(2);将此对象序列化为文件,并在另外一个JVM中读取文件,进行反序列化,请问此时读出的Data0bject对象中的word和i的值分别为:A "", 0B "", 2C "123", 2D "123", 0正确答案:D你的答案:C参考答案:这道题的答案应该是: D,序列化保存的是对象的状态,静态变量属于类的状态,因此,序列化并不保存静态变量。所以i是没有改变的33.java数组的复制效率:System.arraycopy>使用clone方法>Array.copyOf>for 循环逐一复制34.HashTable和HashMap的区别(7点):1.继承的父类不同:HashTable继承Dictory类,HashMap继承AbstractMap.但都实现了Map接口; 2.线程安全性不同:HashTable是线程安全的,适用于多线程;HashMap是非线程安全,更适合于单线程; 3.是否提供contains方法:HashTable中保留了contains方法,与constainsValue功能相同;HashMap中去掉了contains方法; 4.key和value是否可为null值:HashTable的key、value都不允许null值;HashMap,null可以作为key; 5.遍历方式的内部实现不同:HashTable、HashMap都使用了Iterator,HashTable还使用过Enumeration方式;6.hash值不同:HashTable直接使用对象的hashCode,而HashMap重新计算hash值。 7.内部使用的数组初始化和扩容方式不同:Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂;Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。35.Math 类三个用于数值处理的静态方法:ceil(), floor() 和 round().ceil()Math.ceil() 方法返回大于或等于给定数字的最小整数。换句话说,它会将给定的数字向上取整。floor()Math.floor() 方法返回小于或等于给定数字的最大整数。换句话说,它会将给定的数字向下取整。round()Math.round() 方法将给定的数字四舍五入为最接近的整数。36.关于父子类方法重写的错题:class Car extends Vehicle { public static void main (String[] args) { new Car(). run(); } private final void run() { System. out. println ("Car"); } } class Vehicle { private final void run() { System. out. println("Vehicle"); } }下列哪些针对代码运行结果的描述是正确的?A CarB VehicleC Compiler error at line 3D Compiler error at line 5E Exception thrown at runtime正确答案:A你的答案:D参考答案:答案:A 首先final声明的方法是不能被覆盖的,但是这里并不错误,因为方法是private的,也就是子类没有继承父类的run方法,因此子类的run方法跟父类的run方法无关,并不是覆盖。new Car().run()也是调用子类的run方法。37.Java ArrayList扩容在 Java 中,ArrayList 是一种动态数组,其大小(即容量)可以根据需要自动增长。当你向 ArrayList 中添加元素,并且当前的容量不足以容纳新的元素时,ArrayList 会自动进行扩容。下面是 ArrayList 扩容的基本过程:初始化容量:当你创建一个新的 ArrayList 时,你可以指定一个初始容量。如果你不指定,它会使用默认容量,通常是 10。添加元素:当你使用 add 方法向 ArrayList 中添加元素时,它会检查当前数组是否有足够的空间来容纳新元素。扩容:如果当前数组已满,ArrayList 会创建一个新的数组,其容量通常是当前数组的 1.5 倍(确切地说,新容量 = 当前容量 + (当前容量 >> 1)),然后将所有现有元素复制到新数组中。添加新元素:在新数组中,将新元素添加到适当的位置。ArrayList list = new ArrayList(20);中的list扩充几次A 0B 1C 2D 3正确答案:A你的答案:B38.类的final成员变量必须满足以下其中一个条件1、在构造函数中赋值 2、初始化赋值class Foo { final int i; int j; public void doSomething() { System.out.println(++j + i); } }的输出是?A 0B 1C 2D 不能执行,因为编译有错正确答案:D你的答案:B39.定义在同一个包(package)内的类可以不经过import而直接相互使用40.static不能修饰局部变量关于下面的程序Test.java说法正确的是( )。public class Test { static String x="1"; static int y=1; public static void main(String args[]) { static int z=2; System.out.println(x+y+z); } }A 3B 112C 13D 程序有编译错误正确答案:D你的答案:B41.java标识符规则标识符的组成元素是字母(a-z,A-Z),数字(0~9),下划线(_)和美元符号($)。 标识符不能以数字开头。 java的标识符是严格区分大小写的。 标识符的长度可以是任意的。 关键字以及null、true、false不能用于自定义的标识符。下列可作为java语言标识符的是()A a1B $1C _1D 11正确答案:ABC你的答案:AC42.replaceAll()函数的第一个参数是一个正则表达式以下代码将打印出public static void main (String[] args) { String classFile = "com.jd.". replaceAll(".", "/") + "MyClass.class"; System.out.println(classFile); }A com. jdB com/jd/MyClass.classC ///////MyClass.classD com.jd.MyClass正确答案:C你的答案:B官方解析:本题有一处陷阱,replaceAll()函数的第一个参数是一个正则表达式,而"."在正则表达式中代表了全部的字符,因此"com.jd."会全部被替换成"/"。之后字符串正常拼接,输出"///////MyClass.class",答案选择C。如想仅仅替换".",就需要使用转义字符"\."知识点:Java、正则表达式43.关于java的内部类44.Java一维数组的两种初始化方法1、静态初始化int array[] = new int[]{1,2,3,4,5} // 或者 int array[] = {1,2,3,4,5} //需要注意的是,写成如下形式也是错误的 int array[] = new int[5]{1,2,3,4,5}2、动态初始化int array[] = new int[5]; array[0] = 1; array[1] = 2; array[2] = 3; array[3] = 4; array[4] = 5;静态与动态初始化的区别就在于,前者是声明的时候就初始化,后者是先声明,再动态初始化。45.List<>赋值给List<>的限制只看尖括号里边的!!明确点和范围两个概念如果尖括号里的是一个类,那么尖括号里的就是一个点,比如List<A>,List<B>,List<Object>如果尖括号里面带有问号,那么代表一个范围,<? extends A>代表小于等于A的范围,<? super A>代表大于等于A的范围,<?>代表全部范围尖括号里的所有点之间互相赋值都是错,除非是俩相同的点尖括号小范围赋值给大范围,对,大范围赋值给小范围,错。如果某点包含在某个范围里,那么可以赋值,否则,不能赋值List<?>和List 是相等的,都代表最大范围补充:List既是点也是范围,当表示范围时,表示最大范围class A {}class B extends A {}class C extends A {}class D extends B {}下面的哪4个语句是正确的?A The type List<A>is assignable to List.B The type List<B>is assignable to List<A>.C The type List<Object>is assignable to List<?>.D The type List<D>is assignable to List<?extends B>.E The type List<?extends A>is assignable to List<A>.F The type List<Object>is assignable to any List reference.G The type List<?extends B>is assignable to List<?extends A>.正确答案:ACDG你的答案:CDEG46.关于final:修饰方法影响重写,但是不影响重载final修饰方法后,方法是不可被重写的,因为它已经是“最终形态”了。但不会影响重载以下说法错误的是( )A final修饰的方法不能被重载B final可以修饰类、接口、抽象类、方法和属性C final修饰的方法也不能被重写D final修饰的属性是常量,不可以修改正确答案:AB你的答案:B47.关于java的自动类型转换和强制类型转换数据类型的转换,分为自动转换和强制转换。自动转换是程序在执行过程中 “ 悄然 ” 进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换;强制类型转换则必须在代码中声明,转换顺序不受限制。 自动数据类型转换 自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下: 低 ---------------------------------------------> 高 byte,short,char-> int -> long -> float -> double运算中,不同类型的数据先转化为同一类型,然后进行运算,转换规则如下: 运算中,不同类型的数据先转化为同一类型,然后进行运算,转换规则如下:操作数 1 类型操作数 2 类型转换后的类型byte 、 short 、 charintintbyte 、 short 、 char 、 intlonglongbyte 、 short 、 char 、 int 、 longfloatfloatbyte 、 short 、 char 、 int 、 long 、 floatdoubledouble强制数据类型转换 强制转换的格式是在需要转型的数据前加上 “( )” ,然后在括号内加入需要转化的数据类型。有的数据经过转型运算后,精度会丢失,而有的会更加精确设计模式1.备忘录模式(Memento pattern)当你需要让对象返回之前的状态时(例如, 你的用户请求"撤销"), 你使用备忘录模式现在大多数软件都有撤销(Undo)的功能,快捷键一般都是Ctrl+Z。这些软件可能使用了()模式来进行。A 备忘录模式B 访问者模式C 模板方法模式D 责任链正确答案:A你的答案:Dspring1.Spring事务参考资料:Spring事务管理详解-CSDN博客Spring事务的传播属性Spring定义了7个以PROPAGATION\_开头的常量表示它的传播属性。名称值解释PROPAGATION\_REQUIRED0支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择,也是Spring默认的事务的传播。PROPAGATION\_SUPPORTS1支持当前事务,如果当前没有事务,就以非事务方式执行。PROPAGATION\_MANDATORY2支持当前事务,如果当前没有事务,就抛出异常。PROPAGATION\_REQUIRES\_NEW3新建事务,如果当前存在事务,把当前事务挂起。PROPAGATION\_NOT\_SUPPORTED4以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。PROPAGATION\_NEVER5以非事务方式执行,如果当前存在事务,则抛出异常。PROPAGATION\_NESTED6如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION\_REQUIRED类似的操作。Spring事务的隔离级别名称值解释ISOLATION\_DEFAULT-1这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别。另外四个与JDBC的隔离级别相对应ISOLATION\_READ\_UNCOMMITTED1这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻读。ISOLATION\_READ\_COMMITTED2保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。ISOLATION\_REPEATABLE\_READ4这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻读。ISOLATION\_SERIALIZABLE8这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻读。2.@Autowired注解用@Autowired注入的流程为 :1.先根据类型进行实现类的匹配,多个实现类则不适用 2.多个实现类则会变为根据名称来匹配,就是比较注入的变量名称是否与实现类的名称相同有如下接口:public interface Student{ public void introduce(); }该接口有两个实现类:@Component public class StudentImplXH implements Student { @Override public void introduce() { System.out.println("我叫小华"); } } @Component public class StudentImplXM implements Student{ @Override public void introduce() { System.out.println("我叫小明"); } }测试类中代码如下:@Autowired private Student student; @Test void StudentTest(){ student.introduce();运行测试代码,控制台会输出什么结果?( )A 我叫小华我叫小明B我叫小华C我叫小明D程序发生异常正确答案:D你的答案:C官方解析:@Autowired注解提供这样的规则,首先根据类型找到对应的Bean,如果对应类型的 Bean 不是唯一的,那么就根据属性名称和Bean的名称进行匹配。如果匹配得上,就会使用该Bean。如果还无法匹配,就会抛出异常。3.BeanFactory和FactoryBeanBeanFactory是所有Spring Bean的容器根接口,其给IoC容器提供了一套完整的规范。FactoryBean是 一种创建Bean的方式,是对Bean的一种扩展。4.Spring容器中Bean作用域• singleton:在每个Spring IoC容器中只有一个Bean实例。 • prototype:一个Bean的定义可以有多个实例。 • request:在Web应用中,为每个HTTP请求创建一个Bean实例。 • session:在Web应用中,为每个HTTP会话创建一个Bean实例。 • global session:在基于portlet的Web应用中,为每个全局HTTP会话创建一个Bean实例。数据库理论1. 在数据库系统中,产生不一致的原因数据库中可能存在不一致的数据,主要有以下三个方面:A.数据冗余;B.并发控制不当;C.故障或者错误下面选项中,在数据库系统中,产生不一致的最重要原因是( )A 数据存储量太大B 没有严格保护数据C 未对数据进行完整性控制D 数据冗余正确答案:D你的答案:C参考答案:选D 数据库中有可能会存在不一致的数据。 造成数据不一致的原因主要有: 数据冗余 如果数据库中存在冗余数据,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。 并发控制不当 比如某个订票系统中,两个用户在同一时间订同一张票,如果并发控制不当,可能会导致一张票被两个用户预订的情况。当然这也与元数据的设计有关。 故障和错误 如果软硬件发生故障造成数据丢失等情况,也可能引起数据不一致的情况。因此我们需要提供数据库维护和数据恢复的一些措施。知识点:数据库2.数据库设计的六个阶段1、需求分析:分析用户的需求,包括数据、功能和性能需求 2、概念结构设计:主要采用E-R模型进行设计,包括画E-R图 3、逻辑结构设计:通过将E-R图转换成表,实现从E-R模型到关系模型的转换 4、数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径 5、数据库的实施:包括编程、测试和试运行 6、数据库运行与维护:系统的运行与数据库的日常维护
-
移动光猫获取超级密码&开启公网ipv6 1.移动光猫获取超级密码本人采用的光猫型号:烽火吉比特HG6145F;所在地区:广东免责声明:本文仅供学习交流使用,由于本文所导致的光猫任何损坏,以及造成的利益损失,作者概不承担任何责任继续阅读本文即代表同意并充分且正确理解免责声明。1.1 获取光猫MAC地址方法一:直接看光猫的背面看到这串MAC号,把它记下来,比如说68-9A-21-27-53-60,并且把所有横杠删掉,就变成了689A21275360方法二:第一种方法找不到的情况打开cmd(Windows)或者 Terminal终端(macOS)、输入:arp -a并回车,对话框会显示一堆东西,你只需要找到192.168.1.1所对应的那一串接口: 192.168.1.3 --- 0x9 Internet 地址 物理地址 类型 192.168.1.1 68-9a-21-27-53-60 动态 192.168.1.4 5c-c9-99-16-e2-49 动态 192.168.1.255 ff-ff-ff-ff-ff-ff 静态 224.0.0.22 01-00-5e-00-00-16 静态 224.0.0.251 01-00-5e-00-00-fb 静态 224.0.0.252 01-00-5e-00-00-fc 静态 227.44.184.39 01-00-5e-2c-b8-27 静态 229.241.198.220 01-00-5e-71-c6-dc 静态 231.0.254.114 01-00-5e-00-fe-72 静态 239.255.255.250 01-00-5e-7f-ff-fa 静态 255.255.255.255 ff-ff-ff-ff-ff-ff 静态这里面,你只需要看到第一行192.168.1.1,并且把 68-9a-21-27-53-60 记下来,并删除-将对应的字母变成大写即可1.2 开启Telnet1、在浏览器中输入http:/192.168.1.1/cgi-bin/telnetenable.cgi?telnetenable=1&key=2、把你刚刚编辑过的MAC加到这堆东西后面,就变成了http:/192.168.1.1/cgi-bin/telnetenable.cgi?telnetenable=1&key=54E0052A4F203、回车此时,你应该看到“telnet开启”1.3 获取超级密码打开cmd(Windows)或者 Terminal终端(macOS)输入telnet 192.168.1.1 如果提示命令不存在需要去控制面板-程序-启动或关闭windows功能启动该命令然后,在login:后面输入admin,回车,对话框会提示你输入密码在Password:后面输入Fh@加上你获取的MAC的后6位,比如说我这里就是Fh@275360这时,对话框会出现一个#(none) login: admin Password: #然后依次输入load_cli factory show admin_name show admin_pwd对话框会显示#load_cli factory Config\factorydir# show admin_name Success! admin_name=CMCCAdmin Config\factorydir# show admin_pwd Success! admin_pwd=aDm8H%MdA里面admin_name=后面的CMCCAdmin就是超级账户名,admin_pwd=后面的aDm8H%MdA就是超级密码。访问192.168.1.1,把账户名和密码输进去,就进入管理员模式啦!2.移动光猫开启公网IPV6点击“网络”→“宽带设置”→ “网络连接”,找到业务类型为上网的连接名称,将IP模式该为IPV4&IPV6,并开启NPTv6,下面的端口绑定不确定需不需要可以自己摸索尝试.配置上IPV6信息的获取前缀、获取前缀方式、获取地址方式,如下图所示然后,在网络-LAN侧地址配置-IPv6配置启动DHCPv6服务最后,重启光猫,连接WIFI或者插上网线看新获取到的IP地址是否包含IPv6地址:PS C:\Users\jupiter> ipconfig Windows IP 配置 无线局域网适配器 WLAN: 连接特定的 DNS 后缀 . . . . . . . : IPv6 地址 . . . . . . . . . . . . : 2409:8a55:89a:e0f0::2 本地链接 IPv6 地址. . . . . . . . : fe80::57a8:f619:5256:9c90%9 IPv4 地址 . . . . . . . . . . . . : 192.168.1.3 子网掩码 . . . . . . . . . . . . : 255.255.255.0 默认网关. . . . . . . . . . . . . : fe80::6a9a:21ff:fe27:5360%9 192.168.1.1也可再访问一下[IPv6 测试 (test-ipv6.com)](http://test-ipv6.com/)进行测试:参考资料2023年移动光猫获取超级密码中国移动光猫CMCC H2-3启用IPv6
-
宝塔面板一键docker部署 原始地址:GitHub - pch18-docker/baota: 宝塔面板docker部署,个人笔记,方便访问1.通过host模式运行宝塔镜像docker run -tid --name baota --net=host --privileged=true --shm-size=1g --restart always -v ~/wwwroot:/www/wwwroot pch18/baota建议使用上述host网络模式启动,不需要设置映射端口,自动映射宝塔面板全端口到外网 正常的bridge模式可能会造成网站后台不能获取用户真实ip地址.2.通过bridge模式运行宝塔镜像如果特殊情况不能使用host网络模式(macos和windows不支持host), 使用下述命令重新以bridge网络模式运行docker run -tid --name baota -p 80:80 -p 443:443 -p 8888:8888 -p 888:888 --privileged=true --shm-size=1g --restart always -v ~/wwwroot:/www/wwwroot pch18/baota3.登录方式ttp://{{面板ip地址}}:8888`初始账号 username初始密码 password实测登录失败,通过docker exec -it 容器id /bin/bash如下命令进入容器,然后执行bt根据提示修改默认用户名和密码即可。由于docker镜像的特殊性,随机密码是安装面板的时候生成的, 所有用户的随机密码其实都相同,没有随机的意义, 为了方便部署,已经去除安全入口,且设置成上述密码, 请大家登陆后第一时间修改账号密码!!4.版本命名说明pch18/baota或pch18/baota:latest等同pch18/baota:lnmppch18/baota:lnmp为最新版本的官方纯净安装的基础上安装nginx,mysql,phppch18/baota:lnp 为官方版本纯净安装的基础上安装nginx,php(不内置mysql,用于外置数据库的环境)pch18/baota:lamp 为官方版本纯净安装的基础上安装apache,phppch18/baota:lap 为官方版本纯净安装的基础上安装apache,php(不内置mysql,用于外置数据库的环境)pch18/baota:clear 为官方版本纯净安装, 不默认安装nginx,mysql,php等程序5.使用建议/www文件夹建议保存在volume卷中, /www/wwwroot建议映射到宿主机的目录下,方便上传网站代码等文件安装完成后以后可以随时使用内置升级,升级到最新版本由于面板数据都保存在持久化的卷中, 即使删除容器(不删除volumn)后重新运行, 原来的面板和网站数据都能得到保留.启动容器时自动启动所有服务如果还没有安装docker的请运行这个安装脚本 https://pch18.cn/archives/install_docker.html参考资料GitHub - pch18-docker/baota: 宝塔面板docker部署
-
SpringBoot集成Redisson延迟队列 0. 使用场景下单成功,30分钟未支付。支付超时,自动取消订单订单签收,签收后7天未进行评价。订单超时未评价,系统默认好评下单成功,商家5分钟未接单,订单取消配送超时,推送短信提醒1.Redisson延迟队列原理redisson 使用了 两个list + 一个 sorted-set + pub/sub 来实现延时队列,而不是单一的sort-set。sorted-set:存放未到期的消息&到期时间,提供消息延时排序功能list1:存放未到期消息,作为消息的原始顺序视图,提供如查询、删除指定第几条消息的功能(分析源码得出的,查看哪些地方有使用这个list)list2:消费队列,存放到期后的消息,提供消费整体流程(对应画图PPT链接): 结合源码分析:org.redisson.RedissonDelayedQueue#RedissonDelayedQueue 首先创建延时队列的时候,会创建一个QueueTransferTask, 在里面会订阅一个topic,订阅成功后,执行其pushTask方法,里面会查询sorted-set中100个已到期的消息,将其push到lis2中,并从sorted-set和list1中移除。(这里是为了投递历史未处理的消息)protected RedissonDelayedQueue(QueueTransferService queueTransferService, Codec codec, final CommandAsyncExecutor commandExecutor, String name) { super(codec, commandExecutor, name); channelName = prefixName("redisson_delay_queue_channel", getRawName()); queueName = prefixName("redisson_delay_queue", getRawName()); timeoutSetName = prefixName("redisson_delay_queue_timeout", getRawName()); QueueTransferTask task = new QueueTransferTask(commandExecutor.getConnectionManager()) { @Override protected RFuture<Long> pushTaskAsync() { return commandExecutor.evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_LONG, "local expiredValues = redis.call('zrangebyscore', KEYS[2], 0, ARGV[1], 'limit', 0, ARGV[2]); " + "if #expiredValues > 0 then " + "for i, v in ipairs(expiredValues) do " + "local randomId, value = struct.unpack('dLc0', v);" + "redis.call('rpush', KEYS[1], value);" + "redis.call('lrem', KEYS[3], 1, v);" + "end; " + "redis.call('zrem', KEYS[2], unpack(expiredValues));" + "end; " // get startTime from scheduler queue head task + "local v = redis.call('zrange', KEYS[2], 0, 0, 'WITHSCORES'); " + "if v[1] ~= nil then " + "return v[2]; " + "end " + "return nil;", Arrays.<Object>asList(getRawName(), timeoutSetName, queueName), System.currentTimeMillis(), 100); } @Override protected RTopic getTopic() { return RedissonTopic.createRaw(LongCodec.INSTANCE, commandExecutor, channelName); } }; queueTransferService.schedule(queueName, task); this.queueTransferService = queueTransferService; } org.redisson.RedissonDelayedQueue#offerAsync(V, long, java.util.concurrent.TimeUnit) 发送延时消息时,会将消息写入 list1和 sorted-set 中,msg会添加一个randomId,支持发送相同的消息。并且判断sorted-set首条消息如果是刚插入的,则publish timeout(到期时间) 到 topicpublic RFuture<Void> offerAsync(V e, long delay, TimeUnit timeUnit) { if (delay < 0) { throw new IllegalArgumentException("Delay can't be negative"); } long delayInMs = timeUnit.toMillis(delay); long timeout = System.currentTimeMillis() + delayInMs; long randomId = ThreadLocalRandom.current().nextLong(); return commandExecutor.evalWriteAsync(getRawName(), codec, RedisCommands.EVAL_VOID, "local value = struct.pack('dLc0', tonumber(ARGV[2]), string.len(ARGV[3]), ARGV[3]);" + "redis.call('zadd', KEYS[2], ARGV[1], value);" + "redis.call('rpush', KEYS[3], value);" // if new object added to queue head when publish its startTime // to all scheduler workers + "local v = redis.call('zrange', KEYS[2], 0, 0); " + "if v[1] == value then " + "redis.call('publish', KEYS[4], ARGV[1]); " + "end;", Arrays.<Object>asList(getRawName(), timeoutSetName, queueName, channelName), timeout, randomId, encode(e)); }org.redisson.QueueTransferTask#scheduleTask 订阅到topic消息后,会先判断其是否临期(delay<10ms),如果是则调用pushTask方法,不是则启动一个定时任务(使用的netty时间轮),延时delay后执行pushTask方法。// 订阅topic onMessage 时调用 private void scheduleTask(final Long startTime) { TimeoutTask oldTimeout = lastTimeout.get(); if (startTime == null) { return; } if (oldTimeout != null) { oldTimeout.getTask().cancel(); } long delay = startTime - System.currentTimeMillis(); if (delay > 10) { // 使用 netty 时间轮 启动一个定时任务 Timeout timeout = connectionManager.newTimeout(new TimerTask() { @Override public void run(Timeout timeout) throws Exception { pushTask(); TimeoutTask currentTimeout = lastTimeout.get(); if (currentTimeout.getTask() == timeout) { lastTimeout.compareAndSet(currentTimeout, null); } } }, delay, TimeUnit.MILLISECONDS); if (!lastTimeout.compareAndSet(oldTimeout, new TimeoutTask(startTime, timeout))) { timeout.cancel(); } } else { pushTask(); } } private void pushTask() { RFuture<Long> startTimeFuture = pushTaskAsync(); startTimeFuture.onComplete((res, e) -> { if (e != null) { if (e instanceof RedissonShutdownException) { return; } log.error(e.getMessage(), e); scheduleTask(System.currentTimeMillis() + 5 * 1000L); return; } if (res != null) { scheduleTask(res); } }); }2.SpringBoot集成实验环境:SpringBoot版本3.0.12<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.0.12</version> <relativePath/> <!-- lookup parent from repository --> </parent>2.1 引入 Redisson 依赖 <!--redission--> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.19.0</version> </dependency>2.2 配置文件spring: data: redis: host: 172.19.236.66 port: 6379 #password: 123456 database: 0 timeout: 30002.3 创建 RedissonConfig 配置package com.example.redissionstudy.config; import org.redisson.Redisson; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author LuoJia * @version 1.0 * @description: Redis链接配置文件 * @date 2023/11/3 8:59 */ @Configuration public class RedissonConfig { @Value("${spring.data.redis.host}") private String host; @Value("${spring.data.redis.port}") private int port; @Value("${spring.data.redis.database}") private int database; //@Value("${spring.data.redis.password}") //private String password; @Bean public RedissonClient redissonClient() { Config config = new Config(); config.useSingleServer() .setAddress("redis://" + host + ":" + port) .setDatabase(database); //.setPassword(password) return Redisson.create(config); } }测试使用@SpringBootTest @Slf4j class RedissionStudyApplicationTests { @Resource RedissonClient redissonClient; @Test void testRedission() { //字符串操作 RBucket<String> rBucket = redissonClient.getBucket("strKey"); // 设置value和key的有效期 rBucket.set("张三", 30, TimeUnit.MINUTES); // 通过key获取value System.out.println(redissonClient.getBucket("strKey").get()); } }张三redis查看结果127.0.0.1:6379> keys str* 1) "strKey" 127.0.0.1:6379> get strKey "\x03\x83\xe5\xbc\xa0\xe4\xb8\x89"2.4 封装 Redis 延迟队列工具类package com.example.redissionstudy.utils; import lombok.extern.slf4j.Slf4j; import org.redisson.api.RBlockingDeque; import org.redisson.api.RDelayedQueue; import org.redisson.api.RedissonClient; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.util.Map; import java.util.concurrent.TimeUnit; /** * @author LuoJia * @version 1.0 * @description: Redission 延迟队列工具类 * @date 2023/11/3 9:51 */ @Slf4j @Component public class RedisDelayQueueUtil { @Autowired private RedissonClient redissonClient; /** * 添加延迟队列 * * @param value 队列值 * @param delay 延迟时间 * @param timeUnit 时间单位 * @param queueCode 队列键 * @param <T> */ public <T> void addDelayQueue(T value, long delay, TimeUnit timeUnit, String queueCode) { try { RBlockingDeque<Object> blockingDeque = redissonClient.getBlockingDeque(queueCode); RDelayedQueue<Object> delayedQueue = redissonClient.getDelayedQueue(blockingDeque); delayedQueue.offer(value, delay, timeUnit); log.info("(添加延时队列成功) 队列键:{},队列值:{},延迟时间:{}", queueCode, value, timeUnit.toSeconds(delay) + "秒"); } catch (Exception e) { log.error("(添加延时队列失败) {}", e.getMessage()); throw new RuntimeException("(添加延时队列失败)"); } } /** * 获取延迟队列 * * @param queueCode * @param <T> * @return * @throws InterruptedException */ public <T> T getDelayQueue(String queueCode) throws InterruptedException { RBlockingDeque<Map> blockingDeque = redissonClient.getBlockingDeque(queueCode); T value = (T) blockingDeque.take(); return value; } }2.5 创建延迟队列业务枚举package com.example.redissionstudy.enums; import lombok.AllArgsConstructor; import lombok.Getter; import lombok.NoArgsConstructor; /** * @author LuoJia * @version 1.0 * @description: 延迟队列业务枚举 * @date 2023/11/3 9:53 */ @Getter @AllArgsConstructor @NoArgsConstructor public enum RedisDelayQueueEnum { ORDER_PAYMENT_TIMEOUT("ORDER_PAYMENT_TIMEOUT", "订单支付超时,自动取消订单", "orderPaymentTimeout"), ORDER_TIMEOUT_NOT_EVALUATED("ORDER_TIMEOUT_NOT_EVALUATED", "订单超时未评价,系统默认好评", "orderTimeoutNotEvaluated"); /** * 延迟队列 RedisKey */ private String code; /** * 中文描述 */ private String name; /** * 延迟队列具体业务实现的 Bean * 可通过 Spring 的上下文获取 */ private String beanId; }2.6 定义延迟队列执行器package com.example.redissionstudy.handler; /** * @author LuoJia * @version 1.0 * @description: 延迟队列执行器接口 * @date 2023/11/3 9:58 */ public interface RedisDelayQueueHandle<T>{ void execute(T t); }2.7 创建枚举中定义的Bean,并实现延迟队列执行器OrderPaymentTimeout:订单支付超时延迟队列处理类package com.example.redissionstudy.handler.impl; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 订单支付超时处理类 * @date 2023/11/3 10:00 */ @Component @Slf4j public class OrderPaymentTimeout implements RedisDelayQueueHandle<Map> { @Override public void execute(Map map) { log.info("{} {}", RedisDelayQueueEnum.ORDER_PAYMENT_TIMEOUT.getName(), map); // TODO 订单支付超时,自动取消订单处理业务... } } OrderTimeoutNotEvaluated:订单超时未评价延迟队列处理类package com.example.redissionstudy.handler.impl; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 订单超时未评价处理类 * @date 2023/11/3 10:01 */ @Component @Slf4j public class OrderTimeoutNotEvaluated implements RedisDelayQueueHandle<Map> { @Override public void execute(Map map) { log.info("{} {}", RedisDelayQueueEnum.ORDER_TIMEOUT_NOT_EVALUATED.getName(), map); // TODO 订单超时未评价,系统默认好评处理业务... } }2.8 创建延迟队列消费线程,项目启动完成后开启package listener; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import com.example.redissionstudy.utils.RedisDelayQueueUtil; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.CommandLineRunner; import org.springframework.context.ApplicationContext; import org.springframework.stereotype.Component; /** * @author LuoJia * @version 1.0 * @description: 启动延迟队列 * @date 2023/11/3 10:02 */ @Slf4j @Component public class RedisDelayQueueRunner implements CommandLineRunner { @Autowired private RedisDelayQueueUtil redisDelayQueueUtil; @Autowired private ApplicationContext applicationContext; @Override public void run(String... args) { new Thread(() -> { while (true) { try { RedisDelayQueueEnum[] queueEnums = RedisDelayQueueEnum.values(); for (RedisDelayQueueEnum queueEnum : queueEnums) { Object value = redisDelayQueueUtil.getDelayQueue(queueEnum.getCode()); if (value != null) { RedisDelayQueueHandle redisDelayQueueHandle = (RedisDelayQueueHandle) applicationContext.getBean(queueEnum.getBeanId()); redisDelayQueueHandle.execute(value); } } } catch (InterruptedException e) { log.error("(Redis延迟队列异常中断) {}", e.getMessage()); } } }).start(); log.info("(Redis延迟队列启动成功)"); } }以上步骤,Redis 延迟队列核心代码已经完成,下面我们写一个测试接口,用 PostMan 模拟测试一下2.9 创建一个测试接口,模拟添加延迟队列package com.example.redissionstudy.controller; /** * @author LuoJia * @version 1.0 * @description: 延迟队列测试 * @date 2023/11/3 10:05 */ import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.utils.RedisDelayQueueUtil; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import java.util.HashMap; import java.util.Map; import java.util.concurrent.TimeUnit; @RestController public class RedisDelayQueueController { @Autowired private RedisDelayQueueUtil redisDelayQueueUtil; @GetMapping("/addQueue") public void addQueue() { Map<String, String> map1 = new HashMap<>(); map1.put("orderId", "100"); map1.put("remark", "其他信息"); Map<String, String> map2 = new HashMap<>(); map2.put("orderId", "200"); map2.put("remark", "其他信息"); // 添加订单支付超时,自动取消订单延迟队列。为了测试效果,延迟10秒钟 redisDelayQueueUtil.addDelayQueue(map1, 10, TimeUnit.SECONDS, RedisDelayQueueEnum.ORDER_PAYMENT_TIMEOUT.getCode()); // 订单超时未评价,系统默认好评。为了测试效果,延迟20秒钟 redisDelayQueueUtil.addDelayQueue(map2, 20, TimeUnit.SECONDS, RedisDelayQueueEnum.ORDER_TIMEOUT_NOT_EVALUATED.getCode()); } }运行结果2023-11-03T10:09:46.800+08:00 INFO 21480 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2023-11-03T10:09:46.816+08:00 INFO 21480 --- [ main] c.e.r.RedissionStudyApplication : Started RedissionStudyApplication in 4.888 seconds (process running for 5.743) 2023-11-03T10:09:46.825+08:00 INFO 21480 --- [ main] c.e.r.listener.RedisDelayQueueRunner : (Redis延迟队列启动成功) 2023-11-03T10:09:47.039+08:00 INFO 21480 --- [-10.108.155.252] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2023-11-03T10:09:47.040+08:00 INFO 21480 --- [-10.108.155.252] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2023-11-03T10:09:47.042+08:00 INFO 21480 --- [-10.108.155.252] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms 2023-11-03T10:10:25.798+08:00 INFO 21480 --- [nio-8080-exec-4] c.e.r.utils.RedisDelayQueueUtil : (添加延时队列成功) 队列键:ORDER_PAYMENT_TIMEOUT,队列值:{orderId=100, remark=其他信息},延迟时间:10秒 2023-11-03T10:10:25.802+08:00 INFO 21480 --- [nio-8080-exec-4] c.e.r.utils.RedisDelayQueueUtil : (添加延时队列成功) 队列键:ORDER_TIMEOUT_NOT_EVALUATED,队列值:{orderId=200, remark=其他信息},延迟时间:20秒 2023-11-03T10:10:35.779+08:00 INFO 21480 --- [ Thread-2] c.e.r.handler.impl.OrderPaymentTimeout : 订单支付超时,自动取消订单 {orderId=100, remark=其他信息} 2023-11-03T10:10:45.860+08:00 INFO 21480 --- [ Thread-2] c.e.r.h.impl.OrderTimeoutNotEvaluated : 订单超时未评价,系统默认好评 {orderId=200, remark=其他信息}参考资料SpringBoot集成Redisson实现延迟队列 - 掘金 (juejin.cn)SpringBoot集成Redisson实现延迟队列_redssion延时队列订阅_刘鹏博.的博客-CSDN博客Maven Repository: org.redisson » redisson-spring-boot-starter (mvnrepository.com)【进阶篇】Redis实战之Redisson使用技巧详解 - 知乎 (zhihu.com)Table of Content · redisson/redisson Wiki · GitHub浅析 Redisson 的分布式延时队列 RedissonDelayedQueue 运行流程 - 掘金 (juejin.cn)Redisson分布式延时队列 RedissonDelayedQueue - 掘金 (juejin.cn)
-
离线安装pytorch 离线安装pytorch针对网络不稳定在线安装总是中途失败的情况下采用离线安装的方式1.安装前准备1.1 安装显卡驱动略1.2 创建虚拟环境conda create -n torch1.9 python=3.8 conda activate torch1.92.离线安装2.1 版本对应关系2.2 离线下载安装包下载地址:download.pytorch.org/whl/torch_stable.html我们在这里可以找到我们需要的torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl以及torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl两个文件即可。注意,cu111代表CUDA11.1,cp38表示python3.8的编译环境,linux_x86_64表示x86的平台64位操作系统。下载完成后,我们将这两个文件传入你的离线主机(服务器)中。接着进入刚刚用conda创建好的虚拟环境后依次安装whl包:2.3 离线安装# CPU版 pip install torch-1.9.0+cpu-cp38-cp38-linux_x86_64.whl pip install torchvision-0.10.0+cpu-cp38-cp38-linux_x86_64.whl # GPU版 pip install torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl pip install torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl参考资料Pytorch1.9 CPU/GPU(CUDA11.1)安装_torch==1.9.0+cu111_太阳花的小绿豆的博客-CSDN博客
-
YOLOv5 四检测头配置 一、网络结构说明Yolov5原网络结构如下:增加一层检测层后,网络结构如下:(其中虚线表示删除的部分,细线表示增加的数据流动方向)二、网络配置第一步,在models文件夹下面创建yolov5s-add-one-layer.yaml文件。第二步,将下面的内容粘贴到新创建的文件中。# YOLOv5 by Ultralytics, GPL-3.0 license # Parameters nc: 2 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [4,5, 8,10, 22,18] # P2/4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 # add feature extration layer [-1, 3, C3, [256, False]], # 17 [-1, 1, Conv, [128, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 2], 1, Concat, [1]], # cat backbone P3 # add detect layer [-1, 3, C3, [128, False]], # 21 (P4/4-minium) [-1, 1, Conv, [128, 3, 2]], [[-1, 18], 1, Concat, [1]], # cat head P3 # end [-1, 3, C3, [256, False]], # 24 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 27 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 30 (P5/32-large) [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5) ]第三步,正常执行新模型的训练流程,参考:快速使用YOLOv5进行训练VOC格式的数据集 - jupiter's blog (inat.top)。参考资料【Yolov5】Yolov5添加检测层,四层结构对小目标、密集场景更友好_yolov5增加小目标检测层-CSDN博客