搜索到
368
篇与
的结果
-
 python文字转语音(可保存为mp3) 1.pyttsx3模块(亲测可用)这是一款优秀的文字转语音的模块,它生成的音频文件也比较具有个性化。可以调整声音的音量,频率,变声,当然设置方法都差不多,都是先拿到它对应功能的值然后在进行加减。下载pyttsx3模块pip install pyttsx3调用import pyttsx3 # 初始化 engine = pyttsx3.init(); # 设置个性化参数 engine.setProperty('rate',150) #调整语速 engine.setProperty('volume',2.0) #调整音量 voices = engine.getProperty('voices'); engine.setProperty('voice',voices[0].id); mp3_save_path = "./test.mp3" text="西游记" # 使用引擎进行渲染,亲测不能省略这一步,省略了就保存的文件为空 engine.say(text); engine.runAndWait(); #播放音频 # 保存到文件 engine.save_to_file(text,mp3_save_path);2.gtts模快(亲测没跑通)安装pip install gtts使用from gtts import gTTS mp3_save_path = "./test.mp3" text="西游记" # text:音频内容 # lang: 音频语言 tts = gTTS(text=text, lang='zh-tw') tts.save(mp3_save_path)
python文字转语音(可保存为mp3) 1.pyttsx3模块(亲测可用)这是一款优秀的文字转语音的模块,它生成的音频文件也比较具有个性化。可以调整声音的音量,频率,变声,当然设置方法都差不多,都是先拿到它对应功能的值然后在进行加减。下载pyttsx3模块pip install pyttsx3调用import pyttsx3 # 初始化 engine = pyttsx3.init(); # 设置个性化参数 engine.setProperty('rate',150) #调整语速 engine.setProperty('volume',2.0) #调整音量 voices = engine.getProperty('voices'); engine.setProperty('voice',voices[0].id); mp3_save_path = "./test.mp3" text="西游记" # 使用引擎进行渲染,亲测不能省略这一步,省略了就保存的文件为空 engine.say(text); engine.runAndWait(); #播放音频 # 保存到文件 engine.save_to_file(text,mp3_save_path);2.gtts模快(亲测没跑通)安装pip install gtts使用from gtts import gTTS mp3_save_path = "./test.mp3" text="西游记" # text:音频内容 # lang: 音频语言 tts = gTTS(text=text, lang='zh-tw') tts.save(mp3_save_path) -
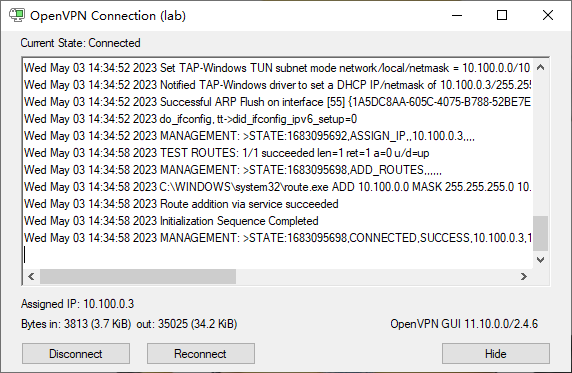
OpenVPN搭建:实现异地多设备组网 1.服务端一键安装脚本wget https://nos-public.nos-eastchina1.126.net/vpn -O openvpn-install.sh && bash openvpn-install.sh安装完毕后将 /root/ 下的 client.ovpn 文件,下载到本地导入 OpenVPN 客户端连接软件进行连接。注意:强烈建议不要使用默认的 VPN 端口 1194,建议修改为其他端口并防火墙开放该端口,使用云服务器的话还需要在安全组放行。还需要继续创建其他的client.ovpn文件继续执行该脚本即可。bash openvpn-install.sh2.客户端连接2.1 Linuxsudo apt-get install openvpn openvpn client.ovpn开机自启动服务sudo vim /etc/rc.local# exit 0 前面加入如下内容 /usr/sbin/openvpn --config /root/client.ovpn &2.2 windows使用客户端下载地址:https://nos-public.nos-eastchina1.126.net/openvpn-install-2.4.6-I602.exe参考资料搭建 OpenVPN脚本内容备份openvpn-install.sh#!/bin/bash # OpenVPN road warrior installer for Debian, Ubuntu and CentOS # This script will work on Debian, Ubuntu, CentOS and probably other distros # of the same families, although no support is offered for them. It isn't # bulletproof but it will probably work if you simply want to setup a VPN on # your Debian/Ubuntu/CentOS box. It has been designed to be as unobtrusive and # universal as possible. # Detect Debian users running the script with "sh" instead of bash if readlink /proc/$$/exe | grep -qs "dash"; then echo "This script needs to be run with bash, not sh" exit 1 fi if [[ "$EUID" -ne 0 ]]; then echo "Sorry, you need to run this as root" exit 2 fi if [[ ! -e /dev/net/tun ]]; then echo "The TUN device is not available You need to enable TUN before running this script" exit 3 fi if grep -qs "CentOS release 5" "/etc/redhat-release"; then echo "CentOS 5 is too old and not supported" exit 4 fi if [[ -e /etc/debian_version ]]; then OS=debian GROUPNAME=nogroup RCLOCAL='/etc/rc.local' elif [[ -e /etc/centos-release || -e /etc/redhat-release ]]; then OS=centos GROUPNAME=nobody RCLOCAL='/etc/rc.d/rc.local' else echo "Looks like you aren't running this installer on Debian, Ubuntu or CentOS" exit 5 fi newclient () { # Generates the custom client.ovpn cp /etc/openvpn/client-common.txt ~/$1.ovpn echo "<ca>" >> ~/$1.ovpn cat /etc/openvpn/easy-rsa/pki/ca.crt >> ~/$1.ovpn echo "</ca>" >> ~/$1.ovpn echo "<cert>" >> ~/$1.ovpn cat /etc/openvpn/easy-rsa/pki/issued/$1.crt >> ~/$1.ovpn echo "</cert>" >> ~/$1.ovpn echo "<key>" >> ~/$1.ovpn cat /etc/openvpn/easy-rsa/pki/private/$1.key >> ~/$1.ovpn echo "</key>" >> ~/$1.ovpn echo "<tls-auth>" >> ~/$1.ovpn cat /etc/openvpn/ta.key >> ~/$1.ovpn echo "</tls-auth>" >> ~/$1.ovpn } # Try to get our IP from the system and fallback to the Internet. # I do this to make the script compatible with NATed servers (lowendspirit.com) # and to avoid getting an IPv6. IP=$(ip addr | grep 'inet' | grep -v inet6 | grep -vE '127\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | grep -o -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | head -1) VPCSUBNETDEFAULT=$(route -n | grep eth0 | grep 255.255| awk '{print $1,$3}' | tail -n 1| awk '{print $1}') VPCMASKDEFAULT=$(route -n | grep eth0 | grep 255.255| awk '{print $1,$3}' | tail -n 1| awk '{print $2}') if [[ "$IP" = "" ]]; then IP=$(wget -4qO- "http://whatismyip.akamai.com/") fi if [[ -e /etc/openvpn/server.conf ]]; then while : do clear echo "Looks like OpenVPN is already installed" echo "" echo "What do you want to do?" echo " 1) Add a new user" echo " 2) Revoke an existing user" echo " 3) Remove OpenVPN" echo " 4) Exit" read -p "Select an option [1-4]: " option case $option in 1) echo "" echo "Tell me a name for the client certificate" echo "Please, use one word only, no special characters" read -p "Client name: " -e -i netease-b CLIENT cd /etc/openvpn/easy-rsa/ ./easyrsa build-client-full $CLIENT nopass # Generates the custom client.ovpn newclient "$CLIENT" echo "" echo "Client $CLIENT added, configuration is available at" ~/"$CLIENT.ovpn" exit ;; 2) # This option could be documented a bit better and maybe even be simplimplified # ...but what can I say, I want some sleep too NUMBEROFCLIENTS=$(tail -n +2 /etc/openvpn/easy-rsa/pki/index.txt | grep -c "^V") if [[ "$NUMBEROFCLIENTS" = '0' ]]; then echo "" echo "You have no existing clients!" exit 6 fi echo "" echo "Select the existing client certificate you want to revoke" tail -n +2 /etc/openvpn/easy-rsa/pki/index.txt | grep "^V" | cut -d '=' -f 2 | nl -s ') ' if [[ "$NUMBEROFCLIENTS" = '1' ]]; then read -p "Select one client [1]: " CLIENTNUMBER else read -p "Select one client [1-$NUMBEROFCLIENTS]: " CLIENTNUMBER fi CLIENT=$(tail -n +2 /etc/openvpn/easy-rsa/pki/index.txt | grep "^V" | cut -d '=' -f 2 | sed -n "$CLIENTNUMBER"p) cd /etc/openvpn/easy-rsa/ ./easyrsa --batch revoke $CLIENT EASYRSA_CRL_DAYS=3650 ./easyrsa gen-crl rm -rf pki/reqs/$CLIENT.req rm -rf pki/private/$CLIENT.key rm -rf pki/issued/$CLIENT.crt rm -rf /etc/openvpn/crl.pem cp /etc/openvpn/easy-rsa/pki/crl.pem /etc/openvpn/crl.pem # CRL is read with each client connection, when OpenVPN is dropped to nobody chown nobody:$GROUPNAME /etc/openvpn/crl.pem echo "" echo "Certificate for client $CLIENT revoked" exit ;; 3) echo "" read -p "Do you really want to remove OpenVPN? [y/n]: " -e -i n REMOVE if [[ "$REMOVE" = 'y' ]]; then PORT=$(grep '^port ' /etc/openvpn/server.conf | cut -d " " -f 2) PROTOCOL=$(grep '^proto ' /etc/openvpn/server.conf | cut -d " " -f 2) if pgrep firewalld; then IP=$(firewall-cmd --direct --get-rules ipv4 nat POSTROUTING | grep '\-s 10.8.0.0/24 '"'"'!'"'"' -d 10.8.0.0/24 -j SNAT --to ' | cut -d " " -f 10) # Using both permanent and not permanent rules to avoid a firewalld reload. firewall-cmd --zone=public --remove-port=$PORT/$PROTOCOL firewall-cmd --zone=trusted --remove-source=10.8.0.0/24 firewall-cmd --permanent --zone=public --remove-port=$PORT/$PROTOCOL firewall-cmd --permanent --zone=trusted --remove-source=10.8.0.0/24 firewall-cmd --direct --remove-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP firewall-cmd --permanent --direct --remove-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP else IP=$(grep 'iptables -t nat -A POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to ' $RCLOCAL | cut -d " " -f 14) iptables -t nat -D POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP sed -i '/iptables -t nat -A POSTROUTING -s 10.8.0.0\/24 ! -d 10.8.0.0\/24 -j SNAT --to /d' $RCLOCAL if iptables -L -n | grep -qE '^ACCEPT'; then iptables -D INPUT -p $PROTOCOL --dport $PORT -j ACCEPT iptables -D FORWARD -s 10.8.0.0/24 -j ACCEPT iptables -D FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT sed -i "/iptables -I INPUT -p $PROTOCOL --dport $PORT -j ACCEPT/d" $RCLOCAL sed -i "/iptables -I FORWARD -s 10.8.0.0\/24 -j ACCEPT/d" $RCLOCAL sed -i "/iptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT/d" $RCLOCAL fi fi if hash sestatus 2>/dev/null; then if sestatus | grep "Current mode" | grep -qs "enforcing"; then if [[ "$PORT" != '1194' || "$PROTOCOL" = 'tcp' ]]; then semanage port -d -t openvpn_port_t -p $PROTOCOL $PORT fi fi fi if [[ "$OS" = 'debian' ]]; then apt-get remove --purge -y openvpn else yum remove openvpn -y fi rm -rf /etc/openvpn echo "" echo "OpenVPN removed!" else echo "" echo "Removal aborted!" fi exit ;; 4) exit;; esac done else clear echo 'Welcome to this quick OpenVPN "road warrior" installer' echo "" # OpenVPN setup and first user creation echo "I need to ask you a few questions before starting the setup" echo "You can leave the default options and just press enter if you are ok with them" echo "" echo "First I need to know the IPv4 address of the network interface you want OpenVPN" echo "listening to." read -p "IP address: " -e -i $IP IP echo "" echo "Which protocol do you want for OpenVPN connections?" echo " 1) UDP (recommended)" echo " 2) TCP" read -p "Protocol [1-2]: " -e -i 1 PROTOCOL case $PROTOCOL in 1) PROTOCOL=udp ;; 2) PROTOCOL=tcp ;; esac echo "" echo "What port do you want OpenVPN listening to?" read -p "Port: " -e -i 1194 PORT echo "" echo "what VPC subnet?" read -p "VPC subnet(E.g 172.16.0.0): " -e -i $VPCSUBNETDEFAULT VPCSUBNET echo "" echo "what VPC mask?" read -p "VPC mask(E.g 255.255.0.0): " -e -i $VPCMASKDEFAULT VPCMASK echo "" # echo "Which DNS do you want to use with the VPN?" # echo " 1) Current system resolvers" # echo " 2) Google" # echo " 3) OpenDNS" # echo " 4) NTT" # echo " 5) Hurricane Electric" # echo " 6) Verisign" # read -p "DNS [1-6]: " -e -i 1 DNS # echo "" echo "Finally, tell me your name for the client certificate" echo "Please, use one word only, no special characters" read -p "Client name: " -e -i netease-b CLIENT echo "" echo "Okay, that was all I needed. We are ready to setup your OpenVPN server now" read -n1 -r -p "Press any key to continue..." if [[ "$OS" = 'debian' ]]; then apt-get update apt-get install openvpn iptables openssl ca-certificates -y else # Else, the distro is CentOS yum install epel-release -y yum install openvpn iptables openssl wget ca-certificates -y fi # An old version of easy-rsa was available by default in some openvpn packages if [[ -d /etc/openvpn/easy-rsa/ ]]; then rm -rf /etc/openvpn/easy-rsa/ fi # Get easy-rsa wget -O ~/EasyRSA-3.0.4.tgz "https://nos-public.nos-eastchina1.126.net/EasyRSA-3.0.4.tgz" tar xzf ~/EasyRSA-3.0.4.tgz -C ~/ mv ~/EasyRSA-3.0.4/ /etc/openvpn/ mv /etc/openvpn/EasyRSA-3.0.4/ /etc/openvpn/easy-rsa/ chown -R root:root /etc/openvpn/easy-rsa/ rm -rf ~/EasyRSA-3.0.4.tgz cd /etc/openvpn/easy-rsa/ # Create the PKI, set up the CA, the DH params and the server + client certificates ./easyrsa init-pki ./easyrsa --batch build-ca nopass ./easyrsa gen-dh ./easyrsa build-server-full server nopass ./easyrsa build-client-full $CLIENT nopass EASYRSA_CRL_DAYS=3650 ./easyrsa gen-crl # Move the stuff we need cp pki/ca.crt pki/private/ca.key pki/dh.pem pki/issued/server.crt pki/private/server.key pki/crl.pem /etc/openvpn # CRL is read with each client connection, when OpenVPN is dropped to nobody chown nobody:$GROUPNAME /etc/openvpn/crl.pem # Generate key for tls-auth openvpn --genkey --secret /etc/openvpn/ta.key # Generate server.conf echo "port $PORT proto $PROTOCOL dev tun sndbuf 0 rcvbuf 0 ca ca.crt cert server.crt key server.key dh dh.pem auth SHA512 tls-auth ta.key 0 topology subnet server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt" > /etc/openvpn/server.conf echo "push \"route $VPCSUBNET $VPCMASK vpn_gateway\"" >> /etc/openvpn/server.conf echo "keepalive 10 120 cipher AES-256-CBC comp-lzo user nobody group $GROUPNAME persist-key duplicate-cn max-clients 10 persist-tun status openvpn-status.log verb 3 crl-verify crl.pem" >> /etc/openvpn/server.conf # Enable net.ipv4.ip_forward for the system sed -i '/\<net.ipv4.ip_forward\>/c\net.ipv4.ip_forward=1' /etc/sysctl.conf if ! grep -q "\<net.ipv4.ip_forward\>" /etc/sysctl.conf; then echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf fi # Avoid an unneeded reboot echo 1 > /proc/sys/net/ipv4/ip_forward if pgrep firewalld; then # Using both permanent and not permanent rules to avoid a firewalld # reload. # We don't use --add-service=openvpn because that would only work with # the default port and protocol. firewall-cmd --zone=public --add-port=$PORT/$PROTOCOL firewall-cmd --zone=trusted --add-source=10.8.0.0/24 firewall-cmd --permanent --zone=public --add-port=$PORT/$PROTOCOL firewall-cmd --permanent --zone=trusted --add-source=10.8.0.0/24 # Set NAT for the VPN subnet firewall-cmd --direct --add-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP firewall-cmd --permanent --direct --add-rule ipv4 nat POSTROUTING 0 -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP else # Needed to use rc.local with some systemd distros if [[ "$OS" = 'debian' && ! -e $RCLOCAL ]]; then echo '#!/bin/sh -e exit 0' > $RCLOCAL fi chmod +x $RCLOCAL # Set NAT for the VPN subnet iptables -t nat -A POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP sed -i "1 a\iptables -t nat -A POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to $IP" $RCLOCAL if iptables -L -n | grep -qE '^(REJECT|DROP)'; then # If iptables has at least one REJECT rule, we asume this is needed. # Not the best approach but I can't think of other and this shouldn't # cause problems. iptables -I INPUT -p $PROTOCOL --dport $PORT -j ACCEPT iptables -I FORWARD -s 10.8.0.0/24 -j ACCEPT iptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT sed -i "1 a\iptables -I INPUT -p $PROTOCOL --dport $PORT -j ACCEPT" $RCLOCAL sed -i "1 a\iptables -I FORWARD -s 10.8.0.0/24 -j ACCEPT" $RCLOCAL sed -i "1 a\iptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT" $RCLOCAL fi fi # If SELinux is enabled and a custom port or TCP was selected, we need this if hash sestatus 2>/dev/null; then if sestatus | grep "Current mode" | grep -qs "enforcing"; then if [[ "$PORT" != '1194' || "$PROTOCOL" = 'tcp' ]]; then # semanage isn't available in CentOS 6 by default if ! hash semanage 2>/dev/null; then yum install policycoreutils-python -y fi semanage port -a -t openvpn_port_t -p $PROTOCOL $PORT fi fi fi # And finally, restart OpenVPN if [[ "$OS" = 'debian' ]]; then # Little hack to check for systemd if pgrep systemd-journal; then systemctl restart openvpn@server.service else /etc/init.d/openvpn restart fi else if pgrep systemd-journal; then systemctl restart openvpn@server.service systemctl enable openvpn@server.service else service openvpn restart chkconfig openvpn on fi fi # Try to detect a NATed connection and ask about it to potential LowEndSpirit users EXTERNALIP=$(wget -4qO- "http://whatismyip.akamai.com/") if [[ "$IP" != "$EXTERNALIP" ]]; then echo "" echo "Looks like your server is behind a NAT!" echo "" echo "If your server is NATed (e.g. LowEndSpirit), I need to know the external IP" echo "If that's not the case, just ignore this and leave the next field blank" read -p "External IP: " -e -i $EXTERNALIP USEREXTERNALIP if [[ "$USEREXTERNALIP" != "" ]]; then IP=$USEREXTERNALIP fi fi # client-common.txt is created so we have a template to add further users later echo "client dev tun proto $PROTOCOL sndbuf 0 rcvbuf 0 remote $IP $PORT resolv-retry infinite nobind max-clients 10 persist-key persist-tun remote-cert-tls server auth SHA512 cipher AES-256-CBC comp-lzo #setenv opt block-outside-dns key-direction 1 auth-nocache verb 3" > /etc/openvpn/client-common.txt # Generates the custom client.ovpn newclient "$CLIENT" echo "" echo "Finished!" echo "" echo "Your client configuration is available at" ~/"$CLIENT.ovpn" echo "If you want to add more clients, you simply need to run this script again!" fi
-
SpringBoot整合阿里云短信发送 0.业务场景短信发送验证码实现注册,登录...1.开通阿里云短信服务去到阿里云官方网址:https://www.aliyun.com/ 选择短信服务,在这里能获取到我们需要的4个参数,分别是accessKeyId、accessKeySecret、短信签名、模板code。2.整合进SpringBoot-方法一(推荐方法二)2.1导入依赖<dependency> <groupId>com.aliyun</groupId> <artifactId>aliyun-java-sdk-core</artifactId> <version>4.3.3</version> </dependency>2.2 封装成工具类或者服务类package top.inat.shop.utils; import com.aliyuncs.CommonRequest; import com.aliyuncs.CommonResponse; import com.aliyuncs.DefaultAcsClient; import com.aliyuncs.IAcsClient; import com.aliyuncs.http.MethodType; import com.aliyuncs.profile.DefaultProfile; import org.springframework.stereotype.Component; import java.util.Random; /** * @program: server * @ClassName AliMessageUtil * @description: 验证码工具类 * @author: jupiter * @create: 2023-04-23 10:17 * @Version 1.0 **/ @Component public class AliMessageUtil { /** * 需要配置的参数 */ // 阿里云的id和秘钥 从个人中心进行创建 private static final String accessKeyId="XXXXXXXX"; private static final String secret="XXXXXXXX"; //申请的阿里云的签名名称 private static final String SignName="smile佳"; //申请的阿里云的短信模板code private static final String TemplateCode = "SMS_147439706"; /** * 生成6位数字验证码函数 */ public static String generateVerifiCode() { int n = 6; StringBuilder code = new StringBuilder(); Random ran = new Random(); for (int i = 0; i < n; i++) { code.append(Integer.valueOf(ran.nextInt(10)).toString()); } return code.toString(); } /** * 通过阿里云短信发送验证码 * @param code 验证码 * @param phone 手机号 * @return */ public static boolean sendMsmVerifyCode(String phone,String code) { //default 地域节点,默认就好 后面是 阿里云的 id和秘钥 DefaultProfile profile = DefaultProfile.getProfile("default", accessKeyId, secret); IAcsClient client = new DefaultAcsClient(profile); // 组装请求对象 SendSmsRequest request = new SendSmsRequest(); request.putQueryParameter("PhoneNumbers", phone); request.putQueryParameter("SignName",SignName); request.putQueryParameter("TemplateCode", TemplateCode); request.putQueryParameter("TemplateParam", "{\"code\":\"" + code + "\"}"); try { CommonResponse response = client.getCommonResponse(request); System.out.println(response.getData()); return response.getHttpResponse().isSuccess(); } catch (Exception e) { e.printStackTrace(); } return false; } }进行测试 @Test void aliMessageTest(){ String code = AliMessageUtil.generateVerifiCode(); System.out.println("生成的验证码为:"+code); String phone = "18673918533"; boolean sendRes = AliMessageUtil.sendMsmVerifyCode(phone,code); System.out.println("短信发送结果:"+sendRes); }2.3 运行结果生成的验证码为:196573 {"Message":"OK","RequestId":"97D16831-6EB8-5300-AF5F-25EC86638C26","Code":"OK","BizId":"405312082956966726^0"} 短信发送结果:true2.整合进SpringBoot-方法二2.1导入依赖<dependency> <groupId>com.aliyun</groupId> <artifactId>dysmsapi20170525</artifactId> <version>2.0.9</version> </dependency> <!-- fastjson 打印详细的发送返回的结果用的,只看发送成功失败的话可以去掉 --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.35</version> </dependency>2.2 封装成工具类或者服务类package top.inat.shop.utils; import com.alibaba.fastjson.JSON; import com.aliyun.dysmsapi20170525.Client; import com.aliyun.dysmsapi20170525.models.SendSmsRequest; import com.aliyun.dysmsapi20170525.models.SendSmsResponse; import com.aliyun.dysmsapi20170525.models.SendSmsResponseBody; import com.aliyun.teaopenapi.models.Config; import org.springframework.stereotype.Component; import java.util.Random; /** * @program: server * @ClassName AliMessageUtil * @description: 验证码工具类 * @author: jupiter * @create: 2023-04-23 10:17 * @Version 1.0 **/ @Component public class AliMessageUtil { /** * 需要配置的参数 */ private static final String accessKeyId="LTAI5t7Lg3SECa8JSvyYrhoj";//这里修改为个人中心生成的AccessKey ID private static final String accessKeySecret="AXeyeLFKUU8MkgUSnTj2qTLqnZv2rL";//这里修改为个人中心生成的AccessKey Secret private static final String SignName="smile佳"; //申请的阿里云的签名名称 private static final String TemplateCode = "SMS_147439706"; ////申请的阿里云的短信模板code /** * 生成6位数字验证码 */ public static String generateVerifiCode() { int n = 6; StringBuilder code = new StringBuilder(); Random ran = new Random(); for (int i = 0; i < n; i++) { code.append(Integer.valueOf(ran.nextInt(10)).toString()); } return code.toString(); } /** * 通过阿里云短信发送验证码 * @param code 验证码 * @param phone 手机号 * @return */ public static boolean sendMsmVerifyCode(String phone,String code) throws Exception { Config config = new Config().setAccessKeyId(accessKeyId).setAccessKeySecret(accessKeySecret).setEndpoint( "dysmsapi.aliyuncs.com"); Client client = new Client(config); SendSmsRequest request = new SendSmsRequest(); request.setPhoneNumbers(phone); request.setSignName(SignName); request.setTemplateCode(TemplateCode); request.setTemplateParam("{\"code\":\"" + code + "\"}"); SendSmsResponse response = client.sendSms(request); SendSmsResponseBody body = response.getBody(); System.out.println(JSON.toJSONString(body));//不用fastjson打印结果就注释掉这一行 if("OK".equals(body.getCode())){ return true; } return false; } } 进行测试 @Test void aliMessageTest(){ String code = AliMessageUtil.generateVerifiCode(); System.out.println("生成的验证码为:"+code); String phone = "18673918533"; boolean sendRes = AliMessageUtil.sendMsmVerifyCode(phone,code); System.out.println("短信发送结果:"+sendRes); }2.3 运行结果生成的验证码为:196573 {"Message":"OK","RequestId":"97D16831-6EB8-5300-AF5F-25EC86638C26","Code":"OK","BizId":"405312082956966726^0"} 短信发送结果:true参考资料SpringBoot整合阿里云短信服务详细过程(保证初学者也能实现)SpringBoot集成阿里云短信服务发送短信阿里云——Java实现手机短信验证码功能
-
[微信小程序开发Bug]:redirectTo:fail can not redirectTo a tabbar page 1.应用场景最近在做一个小程序开发,用户登录功能登录后使用了wx.redirectTo()跳转回用户主页属于tabar的,使用调试器的时候跳转正常,用真机调试的发生了redirectTo:fail can not redirectTo a tabbar page的报错。查询后发现属于tabbar的页面,只能通过wx.switchTab来跳转。 wx.redirectTo({ url: '/pages/usercenter/index/index', })2.问题解决wx.switchTab({ url: '/pages/usercenter/index/index', success: function (e) { var page = getCurrentPages().pop(); if (page == undefined || page == null){ return; } page.onLoad(); } })备注:直接使用wx.switchTab跳转到已经创建的页面不会导致页面刷新,对于发生了用户信息修改的如修改个人信息后的跳转回原页面需要重新加载用户信息,可以在跳转参数里加入跳转成功后对页面的数据进行刷新。3.几种跳转方式比较wx.redirectTo:关闭当前所在页面,再跳转到指定的非TabBar页面。不受页面层数限制。wx.navigateTo:不关闭当前所在页面,跳转到指定的非TabBar页面,注意页面路径限制是五层。左上角会显示一个返回按钮,可以直接返回到上一层页面。wx.switchTab:只可以跳到属于tabBar的页面。参考资料微信小程序 报错:{“errMsg“:“redirectTo:fail can not redirectTo a tabbar page“}及路由跳转总结解决微信小程序switchTab后tab不刷新
-
[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集 1.创建环境创建虚拟环境conda create --name MEGA -y python=3.7 source activate MEGA安装基础包conda install ipython pip pip install ninja yacs cython matplotlib tqdm opencv-python scipy export INSTALL_DIR=$PWD安装pytorch在安装pytorch的时候,原作者是这样的:conda install pytorch=1.3.0 torchvision cudatoolkit=10.0 -c pytorch但实际上使用cuda11.0+pytorch1.7也可以编译跑通,所以在这一步我们将其替换成:conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch然后就是作者使用到的coco数据集和cityperson数据集的安装:cd $INSTALL_DIR git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPId python setup.py build_ext install cd $INSTALL_DIR git clone https://github.com/mcordts/cityscapesScripts.git cd cityscapesScripts/ python setup.py build_ext install安装apex:(可省略) (建议省略,没省略运行报错)git clone https://github.com/NVIDIA/apex.git cd apex python setup.py install --cuda_ext --cpp_ext如果使用的是cuda11.0+pytorch1.7这里会报错deform_conv_cuda.cu(155): error: identifier "AT_CHECK " is undefined解决:在mega_core/csrc/cuda/deform_conv_cuda.cu 和 mega_core/csrc/cuda/deform_pool_cuda.cu文件的开头加上如下代码:#ifndef AT_CHECK #define AT_CHECK TORCH_CHECK #endif实际上原作者并没有使用到apex来进行混合精度训练,这一步也可省略,若省略的话在代码中需要修改几处地方:首先是mega_core/engine/trainer.py中的开头导入apex包注释掉,108-109行改为:losses.backward()还有tools/train_net.py中33行-36行注释掉# try: # from apex import amp # except ImportError: # raise ImportError('Use APEX for multi-precision via apex.amp') 50行也注释掉:#model, optimizer = amp.initialize(model, optimizer, opt_level=amp_opt_level)还有mega_core/layers/nms.py,注释掉第5行第8行改为:nms = _C.nms还有mega_core/layers/roi_align.py注释掉第10、57行还有mega_core/layers/roi_pool.py注释掉第10、56行这样应该就可以了。2.下载和初始化mega.pytorch# install PyTorch Detection cd $INSTALL_DIR git clone https://github.com/Scalsol/mega.pytorch.git cd mega.pytorch # the following will install the lib with # symbolic links, so that you can modify # the files if you want and won't need to # re-build it python setup.py build develop pip install 'pillow<7.0.0'3.制作自己的数据集参考作者提供的customize.md文件3.1 数据集格式参考:https://github.com/Scalsol/mega.pytorch/blob/master/CUSTOMIZE.md【注意事项】1.图片编号是从0开始的6位数字;(不想实现自己的数据加载器这是必要的)2.annotation内的xml文件与train、val钟文件一一对应。datasets ├── vid_custom | |── train | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── val | | |── video_snippet_1 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | |── video_snippet_2 | | | |── 000000.JPEG | | | |── 000001.JPEG | | | |── 000002.JPEG | | | ... | | ... | |── annotation | | |── train | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ... | | |── val | | | |── video_snippet_1 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | | |── video_snippet_2 | | | | |── 000000.xml | | | | |── 000001.xml | | | | |── 000002.xml | | | | ... | | ...3.2 准备自己txt文件具体参考源MEGA代码中datasets\ILSVRC2015\ImageSets提供的文档。格式:每一行4列依次代表:video folder, no meaning(just ignore it),frame number,video length;训练集VID_train.txt 对应vid_custom/train文件夹train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 10 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 30 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 50 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 70 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 90 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 110 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 130 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 150 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 170 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 190 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 210 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 230 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 250 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 270 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 290 300 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 1 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 4 48 train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00001000 1 8 48 ···验证集VID_val.txt 对应vid_custom/val文件夹val/ILSVRC2015_val_00000000 1 0 464 val/ILSVRC2015_val_00000000 2 1 464 val/ILSVRC2015_val_00000000 3 2 464 val/ILSVRC2015_val_00000000 4 3 464 val/ILSVRC2015_val_00000000 5 4 464 val/ILSVRC2015_val_00000000 6 5 464 val/ILSVRC2015_val_00000000 7 6 464 val/ILSVRC2015_val_00000000 8 7 464 val/ILSVRC2015_val_00000000 9 8 464 val/ILSVRC2015_val_00000000 10 9 464 val/ILSVRC2015_val_00000000 11 10 464 val/ILSVRC2015_val_00000000 12 11 464 val/ILSVRC2015_val_00000000 13 12 464 val/ILSVRC2015_val_00000000 14 13 464 val/ILSVRC2015_val_00000000 15 14 464 val/ILSVRC2015_val_00000000 16 15 464 ···4.参数修改mega_core/data/datasets/vid.py修改VIDDataset内classes和classes_map:# classes=['__background__',#always index0 'car'] # classes_map=['__background__',# always index0 'n02958343'] # 自己标的数据集两个都填一样的就行 classes = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor'] classes_map = ['__background__', # always index 0 'BridgeVehicle', 'Person', 'FollowMe', 'Plane', 'LuggageTruck', 'RefuelingTruck', 'FoodTruck', 'Tractor']mega_core/config/paths_catalog.py修改 DatasetCatalog.DATASETS,在变量的最后加上如下内容"vid_custom_train":{ "img_dir":"vid_custom/train", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_train.txt" }, "vid_custom_val":{ "img_dir":"vid_custom/val", "anno_path":"vid_custom/annotation", "img_index":"vid_custom/VID_val.txt" }修改if函数下if语句,添加上vid条件if ("DET" in name) or ("VID" in name) or ("vid" in name):修改configs/BASE_RCNN_1gpu.yaml(取决于你用几张gpu训练)NUM_CLASSES: 9#(物体类别数+背景) TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”修改configs/MEGA/vid_R_101_C4_MEGA_1x.yamlDATASETS: TRAIN: ("vid_custom_train",)#记得加“,” TEST: ("vid_custom_val",)#记得加“,”5.训练和测试代码5.1 开始训练python -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/BASE_RCNN_1gpu.yaml \ OUTPUT_DIR training_dir/BASE_RCNNpython -m torch.distributed.launch \ --nproc_per_node=1 \ tools/train_net.py \ --master_port=$((RANDOM + 10000)) \ --config-file configs/DFF/vid_R_50_C4_DFF_1x.yaml \ OUTPUT_DIR training_dir/vid_R_50_C4_DFF_1x5.2 开始测试python -m torch.distributed.launch \ --nproc_per_node 1 \ tools/test_net.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ MODEL.WEIGHT training_dir/BASE_RCNN/model_0020000.pth python tools/test_prediction.py \ --config-file configs/BASE_RCNN_1gpu.yaml \ --prediction ./ 参考资料MEGA训练自己的数据集-dockerhttps://github.com/Scalsol/mega.pytorch/issues/63
-
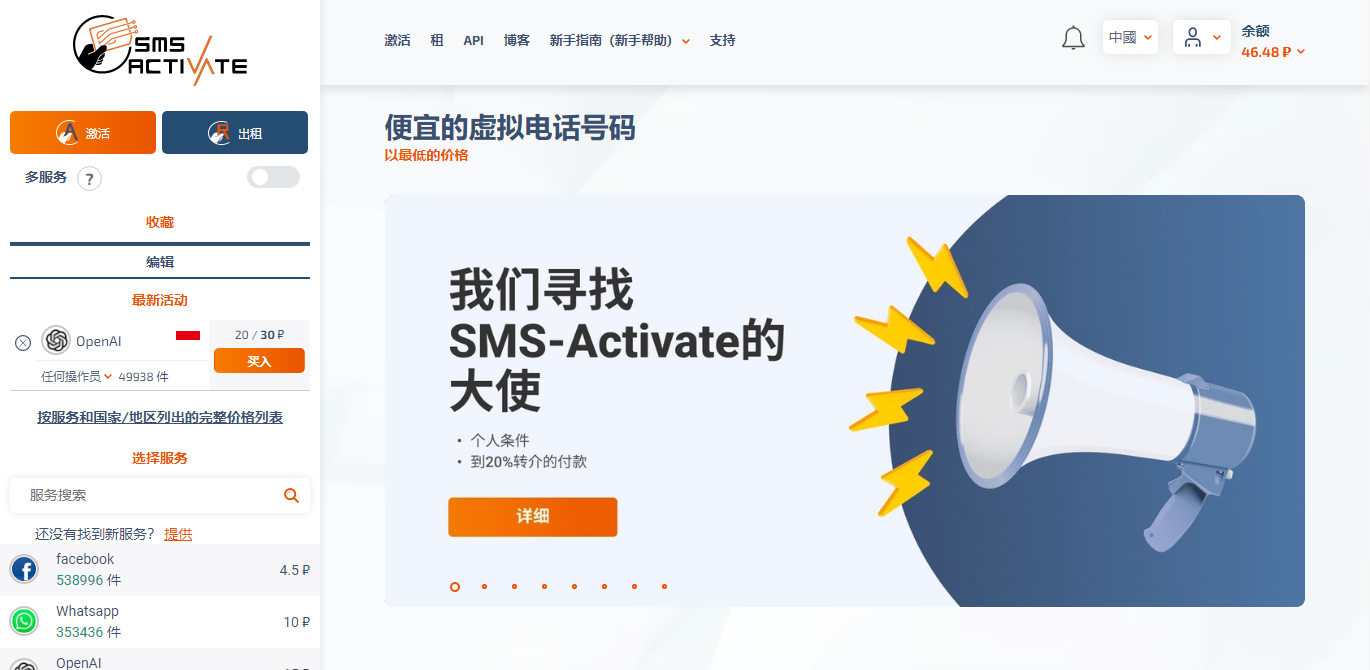
sms-activate:好用的国外虚拟手机接码平台(付费但很便宜|ChatGPT可用) sms-activate:好用的国外虚拟手机接码平台(付费但很便宜|ChatGPT可用)0.背景注册万ChatGPT激活需要验证手机号后才能正常使用,但是不支持中国地区只能使用国外手机号注册,可以通过接码平台sms-activate.org得到一个虚拟手机号并且接受注册码,平台费用很便宜并且支持国内的各个平台的支付方式。1.操作步骤1.1 注册一个 sms-activate 平台的账号访问接码平台:https://sms-activate.org/cn这个平台无需翻墙直接可以访问,并且支持中文。直接用邮箱注册,注册后通过邮箱验证完成注册并登陆网站。1.2 查看待接码的服务的价格在网站的左边下面一点可以看到,选择具体的项目点击查看具体价格。以chatGPT所需的openAI为例,最便宜需要30卢比。1.3 按需进行充值选择合适的支付方式即可,支持微信和支付宝。1.4 进行接码在待接码的平台注册好账号之后进入待接码的页面。从sms-activate 平台购买对应的激活接码服务,然后填入相应的号码,发送验证码即可稍后从平台收到相应的验证码。万一脸黑没收到验证码,可以在有效期内免费退一次的,我注册是立马就收到了,很顺利。
-
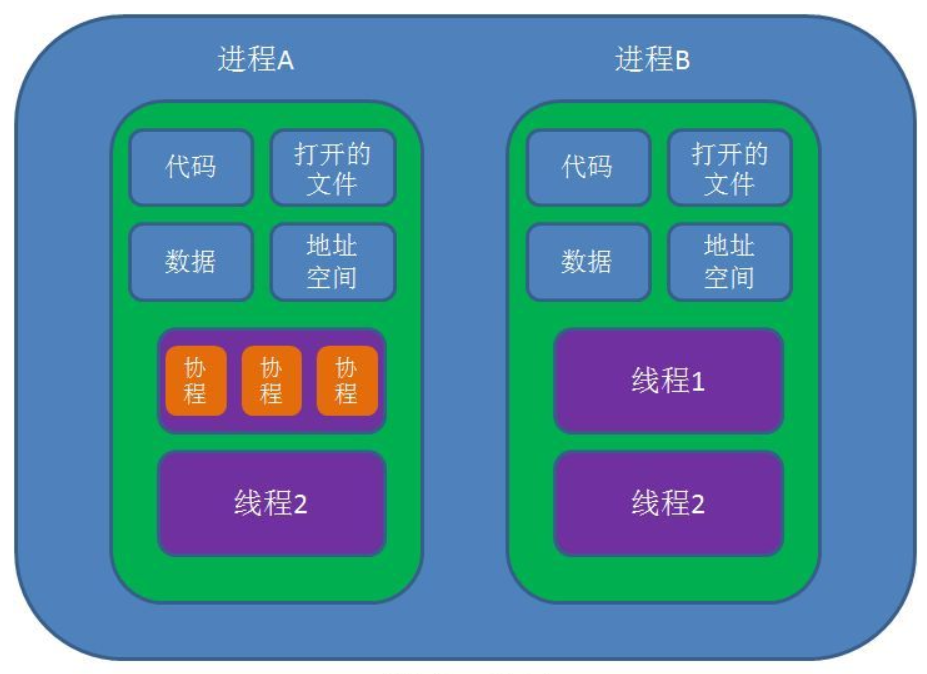
面试题:进程、线程及协程的区别 面试题:进程、线程及协程的区别1.概念进程: 进程是一个具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统资源分配和独立运行的最小单位;线程: 线程是进程的一个执行单元,是任务调度和系统执行的最小单位;协程: 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。2.进程与线程的区别1、根本区别: 进程是操作系统资源分配和独立运行的最小单位;线程是任务调度和系统执行的最小单位。2、地址空间区别: 每个进程都有独立的地址空间,一个进程崩溃不影响其它进程;一个进程中的多个线程共享该 进程的地址空间,一个线程的非法操作会使整个进程崩溃。3、上下文切换开销区别: 每个进程有独立的代码和数据空间,进程之间上下文切换开销较大;线程组共享代码和数据空间,线程之间切换的开销较小。3.进程与线程的联系一个进程由共享空间(包括堆、代码区、数据区、进程空间和打开的文件描述符)和一个或多个线程组成,各个线程之间共享进程的内存空间,而一个标准的线程由线程ID、程序计数器PC、寄存器和栈组成。进程和线程之间的联系如下图所示:4.进程与线程的选择1、线程的创建或销毁的代价比进程小,需要频繁创建和销毁时应优先选用线程;2、线程上下文切换的速度比进程快,需要大量计算时优先选用线程;3、线程在CPU上的使用效率更高,需要多核分布时优先选用线程,需要多机分布时优先选用进程4、线程的安全性、稳定性没有进程好,需要更稳定安全时优先使用进程。综上,线程创建和销毁的代价低、上下文切换速度快、对系统资源占用小、对CPU的使用效率高,因此一般情况下优先选择线程进行高并发编程;但线程组的所有线程共用一个进程的内存空间,安全稳定性相对较差,若其中一个线程发生崩溃,可能会使整个进程,因此对安全稳定性要求较高时,需要优先选择进程进行高并发编程。5.协程协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态。这个过程完全由程序控制,不需要内核进行调度。协程与线程的关系如下图所示:6.协程与线程的区别1、根本区别: 协程是用户态的轻量级线程,不受内核调度;线程是任务调度和系统执行的最小单位,需要内核调度。2、运行机制区别: 线程和进程是同步机制,而协程是异步机制。3、上下文切换开销区别: 线程运行状态切换及上下文切换需要内核调度,会消耗系统资源;而协程完全由程序控制,状态切换及上下文切换不需要内核参与。参考资料进程、线程及协程的区别
-
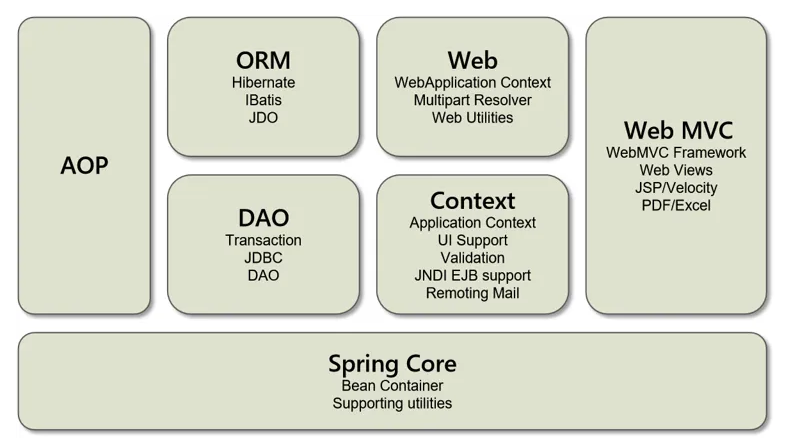
Spring&SpringMVC高频面试题梳理 0.题目汇总Spring的IOC和AOP机制?Spring中Autowired和Resouree关键字的区别和联系?依赖注入的方式有几种,各是什么?讲一下什么是Spring?Spring框架中都用到了哪些设计模式?Spring框架中都用到了哪些设计模式?1.Spring的IOC和AOP机制?IOC(Inversion of Control):IOC是控制反转的意思,这是一种面向对象编程的设计思想,可以帮我们维护对象与对象之间的依赖关系,降低对象之间的耦合度。简单来说,就是将原本在程序中自己手动创建对象的控制权,交由 Spring 框架来管理,Spring IOC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。 IOC 容器负责创建对象,将对象连接在一起,配置这些对象,并从创建中处理这些对象的整个生命周期,直到它们被完全销毁。在spring中IOC是通过DI(Dependency Injection)/依赖注入实现的。AOP(Aspect Oriented Programing)是面向切面编程思想,这种思想是对OOP的补充,它可以在OOP的基础上进一步提高编程的效率。简单来说,它可以统一解决一批组件的共性需求(如权限检查、记录日志、事务管理等)。它利用一种称为"横切"的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为"Aspect",即切面。所谓"切面",简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。2.Spring中Autowired和Resouree关键字的区别和联系?联系@Autowired和@Resource注解都是作为bean对象注入的时候使用的两者都可以声明在字段和setter方法上注意:如果声明在字段上,那么就不需要再写setter方法。但是本质上,该对象还是作为set方法的实参,通过执行set方法注入,只是省略了setter方法罢了区别@Autowired注解是Spring提供的,而@Resource注解是J2EE本身提供的@Autowired注解默认通过byType方式注入,而@Resource注解默认通过byName方式注入@Autowired注解注入的对象需要在IOC容器中存在,否则需要加上属性required=false,表示忽略当前要注入的bean,如果有直接注入,没有跳过,不会报错讲一下什么是Spring?3.依赖注入的方式有几种,各是什么?构造器注入将被依赖对象通过构造函数的参数注入给依赖对象,并且在初始化对象的时候注入。<!-- 第一种根据index参数下标设置 --> <bean id="userT" class="com.kuang.pojo.UserT"> <!-- index指构造方法 , 下标从0开始 --> <constructor-arg index="0" value="kuangshen2"/> </bean> <!-- 第二种根据参数名字设置 --> <bean id="userT" class="com.kuang.pojo.UserT"> <!-- name指参数名 --> <constructor-arg name="name" value="kuangshen2"/> </bean> <!-- 第三种根据参数类型设置 --> <bean id="userT" class="com.kuang.pojo.UserT"> <constructor-arg type="java.lang.String" value="kuangshen2"/> </bean>setter方法注入通过调用成员变量提供的setter函数将被依赖对象注入给依赖类。<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="address" class="com.hui.pojo.Address"> <property name="address" value="背景"/> </bean> <!-- 依赖注入之set注入 --> <bean id="student" class="com.hui.pojo.Student"> <!--1. 普通值注入,value--> <property name="name" value="李家辉"/> <!--2. bean注入,ref--> <property name="address" ref="address"/> <!--3. 数组注入,array-value --> <property name="books"> <array> <value>李</value> <value>家</value> <value>辉</value> </array> </property> <!--list注入,list-value --> <property name="hobbys"> <list> <value>语文</value> <value>数学</value> <value>英语</value> </list> </property> <!--Map注入,map-entry-key-value --> <property name="card"> <map> <entry key="身份证" value="123"/> <entry key="银行卡" value="456"/> </map> </property> <!--Set注入,set-value --> <property name="games"> <set> <value>IOC</value> <value>DI</value> </set> </property> <!--null注入--> <property name="wife"> <null/> </property> <!----> <property name="info"> <props> <prop key="学号">2019</prop> <prop key="username">男</prop> <prop key="password">123456</prop> </props> </property> </bean> </beans>c命名空间与p命名空间p命名空间就是对应setter注入(property);c命名空间就是对应构造方法注入(constructor-arg)。<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:c="http://www.springframework.org/schema/c" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!--p命名空间注入,可以直接注入属性的值:property。p命名空间注入就是对应set注入的属性注入--> <!--需要导入约束 xmlns:p="http://www.springframework.org/schema/p" --> <bean id="user" class="com.hui.pojo.User" p:name="李家辉" p:age="22"/> <!--c命名空间注入,对应所有的构造器注入,constructor-arg --> <!--需要导入约束 xmlns:c="http://www.springframework.org/schema/c" --> <bean id="user1" class="com.hui.pojo.User" c:name="李家毅" c:age="22"/> </beans>autowire byName (按名称自动装配)<bean id="user" class="com.kuang.pojo.User" autowire="byName"> <property name="str" value="qinjiang"/> </bean>autowire byType (按类型自动装配)<bean id="dog" class="com.kuang.pojo.Dog"/> <bean id="cat" class="com.kuang.pojo.Cat"/> <bean id="cat2" class="com.kuang.pojo.Cat"/> <bean id="user" class="com.kuang.pojo.User" autowire="byType"> <property name="str" value="qinjiang"/> </bean>使用注解实现自动装配@Autowired+@Qualifier@Autowired是根据类型自动装配的,加上@Qualifier则可以根据byName的方式自动装配@Qualifier不能单独使用。@Resource@Resource如有指定的name属性,先按该属性进行byName方式查找装配;其次再进行默认的byName方式进行装配;如果以上都不成功,则按byType的方式自动装配。都不成功,则报异常。4.讲一下什么是Spring?Spring是一个轻量级的IoC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。简单来说,它是一个容器框架,用来装 javabean(java对象),中间层框架(万能胶)可以起一个连接作用,可以把各种技术粘合在一起运用。主要由以下几个模块组成:Spring Core:SpringCore模块是Spring的核心容器,它实现了IOC模式,提供了Spring框架的基础功能。此模块中包含的BeanFactory类是Spring的核心类,负责JavaBean的配置与管理。它采用Factory模式实现了IOC即依赖注入。Spring AOP:Spring在它的AOP模块中提供了对面向切面编程的丰富支持,Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖组件,就可以将声明性事务管理集成到应用程序中,可以自定义拦截器、切点、日志等操作Spring DAO:提供了一个JDBC的抽象层和异常层次结构,消除了烦琐的JDBC编码和数据库厂商特有的错误代码解析, 用于简化JDBCSpring ORM:对现有的ORM框架的支持;Spring Context:提供框架式的Bean访问方式,以及企业级功能(JNDI、定时任务等);Spring Web:提供了基本的面向Web的综合特性,例如多方文件上传;Spring MVC:提供面向Web应用的Model-View-Controller实现。5.解释Spring支持的几种bean的作用域。类型说明singleton在Spring容器中仅存在一个实例,即Bean以单例的形式存在。prototype每次调用getBean()时,都会执行new操作,返回一个新的实例。request每次HTTP请求都会创建一个新的Bean。session同一个HTTP Session共享一个Bean,不同的HTTP Session使用不同的Bean。globalSession同一个全局的Session共享一个Bean,一般用于Portlet环境6.Spring框架中都用到了哪些设计模式?工厂模式:ApplicationContext类使用工厂模式创建Bean对象单例模式:Spring中的Bean的作用域默认就是单例Singleton的原型模式:在 spring 中用到的原型模式有: scope="prototype" ,每次获取的是通过克隆生成的新实例,对其进行修改时对原有实例对象不造成任何影响。代理模式:Spring AOP基于动态代理实现的模板模式:Spring中以Template结尾的类,比如jdbcTemplate、SqlSessionTemplate等,都是使用了模板方法模式装饰器模式(动态地给对象添加一些额外的属性或者行为 和继承相比,装饰器模式更加灵活):Spring中配置DataSource时 ,DataSource可以是不同的数据库和数据源.为了在少修改原有类的代码下动态切换不同的数据源,这时就用到了装饰器模式责任链模式:DispatcherServlet 中的 doDispatch() 方法中获取与请求匹配的处理器HandlerExecutionChain,this.getHandler() 方法的处理使用到了责任链模式。观察者模式:Spring 中的 Event 和 Listener7.什么是MVC?MVC是一种架构模式,在这种模式下软件被分为三层,即Model(模型)、View(视图)、Controller(控制器)。Model代表的是数据,View代表的是用户界面,Controller代表的是数据的处理逻辑,它是Model和View这两层的桥梁。将软件分层的好处是,可以将对象之间的耦合度降低,便于代码的维护。8.谈谈对 Spring MVC 的理解Spring MVC 是一款很优秀的 MVC 框架。可以让我们的开发更简洁,而且它和 Spring 是无缝集成,是 Spring 的一个子模块,是我们上面提到 Spring 大家族中 Web 模块。Spring MVC 框架主要由 DispatcherServlet 、处理器映射、处理器(控制器)、视图解析器、视图组成。Spring MVC框架像许多其他MVC框架一样, 以请求为驱动 , 围绕一个中心Servlet分派请求及提供其他功能,DispatcherServlet是一个实际的Servlet (它继承自HttpServlet 基类)。springMVC执行流程9.SpringMVC怎么样设定重定向和转发的?Spring MVC 请求方式分为转发、重定向 2 种,分别使用 forward 和 redirect 关键字在 controller 层进行处理。重定向是将用户从当前处理请求定向到另一个视图(例如 JSP)或处理请求,以前的请求(request)中存放的信息全部失效,并进入一个新的 request 作用域;转发是将用户对当前处理的请求转发给另一个视图或处理请求,以前的 request 中存放的信息不会失效。转发是服务器行为,重定向是客户端行为。1)转发过程客户浏览器发送 http 请求,Web 服务器接受此请求,调用内部的一个方法在容器内部完成请求处理和转发动作,将目标资源发送给客户;在这里转发的路径必须是同一个 Web 容器下的 URL,其不能转向到其他的 Web 路径上,中间传递的是自己的容器内的 request。在客户浏览器的地址栏中显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。2)重定向过程客户浏览器发送 http 请求,Web 服务器接受后发送 302 状态码响应及对应新的 location 给客户浏览器,客户浏览器发现是 302 响应,则自动再发送一个新的 http 请求,请求 URL 是新的 location 地址,服务器根据此请求寻找资源并发送给客户。在这里 location 可以重定向到任意 URL,既然是浏览器重新发出了请求,那么就没有什么 request 传递的概念了。在客户浏览器的地址栏中显示的是其重定向的路径,客户可以观察到地址的变化。重定向行为是浏览器做了至少两次的访问请求。在 Spring MVC 框架中,重定向与转发的示例代码如下:@RequestMapping(“/login”) public String login() { //转发到一个请求方法(同一个控制器类可以省略/index/) return “forward:/index/isLogin”; } @RequestMapping(“/isLogin”) public String isLogin() { //重定向到一个请求方法 return “redirect:/index/isRegister”; }在 Spring MVC 框架中,控制器类中处理方法的 return 语句默认就是转发实现,只不过实现的是转发到视图。@RequestMapping(“/register”) public String register() { return “register”; //转发到register.jsp }10.SpringMVC常用的注解有哪些?组件型注解:作用:被注解的类将被spring初始话为一个bean,然后统一管理。@Component 在类定义之前添加@Component注解,他会被spring容器识别,并转为bean。@Repository 对Dao实现类进行注解 (特殊的@Component)@Service 用于对业务逻辑层进行注解, (特殊的@Component)@Controller 用于控制层注解 , (特殊的@Component)==待完成==参考资料@Autowired和@Resource注解的区别和联系(十分详细,不看后悔)依赖注入三种方式设计模式_spring框架中常用的8种设计模式
-
代码绘制爱心 代码绘制爱心0.背景最近看到一个剧叫点燃我温暖你,剧中大一的学生用c++绘制了普通的和很炫酷的爱心,女朋友还蛮有兴趣的,今天有空了准备也来试试复现一下。2.绘制静态爱心2.0 相关知识爱心的绘制主要运用到的几何知识是笛卡尔的心形线,心形线的极坐标下的函数表达式为:$$ r=a(1-sinθ) $$其中a是一个a>0的系数,可以任意取正值,它决定心形的大小。转为直角坐标系下的函数表达式为:$$ x^2+y^2=a\sqrt{x^2+y^2} - ay $$然后经过了一通平移等操作,最后绘制用得心形线条曲线的方程为:$$ (x^2+y^2-1)^3-x^3y^3=0 $$2.1 代码#include<iostream> #include<windows.h> #include<cmath> using namespace std; int main() { float x, y, a; for (y = 1.5f; y > -1.5f; y -= 0.1f) { for (x = -1.5f; x < 1.5f; x += 0.05f) { // 逐行绘制爱心的每一行 float fx = pow(x*x+y*y-1,3)- pow(x,2)*pow(y,3); if(fx <= 0.0f) { cout<<'*'; } else { cout<<' '; } } cout<<endl; } system("pause"); return 0; }2.2 效果图3.绘制跳动的爱心3.0 原理github拷贝过来的,原理还在解读中,先码住。3.1 代码heart.pyfrom math import cos, pi import numpy as np import cv2 import os, glob class HeartSignal: def __init__(self, curve="heart", title="Love U", frame_num=20, seed_points_num=2000, seed_num=None, highlight_rate=0.3, background_img_dir="", set_bg_imgs=False, bg_img_scale=0.2, bg_weight=0.3, curve_weight=0.7, frame_width=1080, frame_height=960, scale=10.1, base_color=None, highlight_points_color_1=None, highlight_points_color_2=None, wait=100, n_star=5, m_star=2): super().__init__() self.curve = curve self.title = title self.highlight_points_color_2 = highlight_points_color_2 self.highlight_points_color_1 = highlight_points_color_1 self.highlight_rate = highlight_rate self.base_color = base_color self.n_star = n_star self.m_star = m_star self.curve_weight = curve_weight img_paths = glob.glob(background_img_dir + "/*") self.bg_imgs = [] self.set_bg_imgs = set_bg_imgs self.bg_weight = bg_weight if os.path.exists(background_img_dir) and len(img_paths) > 0 and set_bg_imgs: for img_path in img_paths: img = cv2.imread(img_path) self.bg_imgs.append(img) first_bg = self.bg_imgs[0] width = int(first_bg.shape[1] * bg_img_scale) height = int(first_bg.shape[0] * bg_img_scale) first_bg = cv2.resize(first_bg, (width, height), interpolation=cv2.INTER_AREA) # 对齐图片,自动裁切中间 new_bg_imgs = [first_bg, ] for img in self.bg_imgs[1:]: width_close = abs(first_bg.shape[1] - img.shape[1]) < abs(first_bg.shape[0] - img.shape[0]) if width_close: # resize height = int(first_bg.shape[1] / img.shape[1] * img.shape[0]) width = first_bg.shape[1] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[0] > first_bg.shape[0]: crop_num = img.shape[0] - first_bg.shape[0] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=0) img = np.delete(img, range(img.shape[0] - crop_bottom, img.shape[0]), axis=0) elif img.shape[0] < first_bg.shape[0]: fill_num = first_bg.shape[0] - img.shape[0] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=0) else: width = int(first_bg.shape[0] / img.shape[0] * img.shape[1]) height = first_bg.shape[0] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[1] > first_bg.shape[1]: crop_num = img.shape[1] - first_bg.shape[1] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=1) img = np.delete(img, range(img.shape[1] - crop_bottom, img.shape[1]), axis=1) elif img.shape[1] < first_bg.shape[1]: fill_num = first_bg.shape[1] - img.shape[1] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=1) new_bg_imgs.append(img) self.bg_imgs = new_bg_imgs assert all(img.shape[0] == first_bg.shape[0] and img.shape[1] == first_bg.shape[1] for img in self.bg_imgs), "背景图片宽和高不一致" self.frame_width = self.bg_imgs[0].shape[1] self.frame_height = self.bg_imgs[0].shape[0] else: self.frame_width = frame_width # 窗口宽度 self.frame_height = frame_height # 窗口高度 self.center_x = self.frame_width / 2 self.center_y = self.frame_height / 2 self.main_curve_width = -1 self.main_curve_height = -1 self.frame_points = [] # 每帧动态点坐标 self.frame_num = frame_num # 帧数 self.seed_num = seed_num # 伪随机种子,设置以后除光晕外粒子相对位置不动(减少内部闪烁感) self.seed_points_num = seed_points_num # 主图粒子数 self.scale = scale # 缩放比例 self.wait = wait def curve_function(self, curve): curve_dict = { "heart": self.heart_function, "butterfly": self.butterfly_function, "star": self.star_function, } return curve_dict[curve] def heart_function(self, t, frame_idx=0, scale=5.20): """ 图形方程 :param frame_idx: 帧的索引,根据帧数变换心形 :param scale: 放大比例 :param t: 参数 :return: 坐标 """ trans = 3 - (1 + self.periodic_func(frame_idx, self.frame_num)) * 0.5 # 改变心形饱满度度的参数 x = 15 * (np.sin(t) ** 3) t = np.where((pi < t) & (t < 2 * pi), 2 * pi - t, t) # 翻转x > 0部分的图形到3、4象限 y = -(14 * np.cos(t) - 4 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(trans * t)) ign_area = 0.15 center_ids = np.where((x > -ign_area) & (x < ign_area)) if np.random.random() > 0.32: x, y = np.delete(x, center_ids), np.delete(y, center_ids) # 删除稠密部分的扩散,为了美观 # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y # 原心形方程 # x = 15 * (sin(t) ** 3) # y = -(14 * cos(t) - 4 * cos(2 * t) - 2 * cos(3 * t) - cos(3 * t)) return x.astype(int), y.astype(int) def butterfly_function(self, t, frame_idx=0, scale=5.2): """ 图形函数 :param frame_idx: :param scale: 放大比例 :param t: 参数 :return: 坐标 """ # 基础函数 # t = t * pi p = np.exp(np.sin(t)) - 2.5 * np.cos(4 * t) + np.sin(t) ** 5 x = 5 * p * np.cos(t) y = - 5 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def star_function(self, t, frame_idx=0, scale=5.2): n = self.n_star / self.m_star p = np.cos(pi / n) / np.cos(pi / n - (t % (2 * pi / n))) x = 15 * p * np.cos(t) y = 15 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def shrink(self, x, y, ratio, offset=1, p=0.5, dist_func="uniform"): """ 带随机位移的抖动 :param x: 原x :param y: 原y :param ratio: 缩放比例 :param p: :param offset: :return: 转换后的x,y坐标 """ x_ = (x - self.center_x) y_ = (y - self.center_y) force = 1 / ((x_ ** 2 + y_ ** 2) ** p + 1e-30) dx = ratio * force * x_ dy = ratio * force * y_ def d_offset(x): if dist_func == "uniform": return x + np.random.uniform(-offset, offset, size=x.shape) elif dist_func == "norm": return x + offset * np.random.normal(0, 1, size=x.shape) dx, dy = d_offset(dx), d_offset(dy) return x - dx, y - dy def scatter(self, x, y, alpha=0.75, beta=0.15): """ 随机内部扩散的坐标变换 :param alpha: 扩散因子 - 松散 :param x: 原x :param y: 原y :param beta: 扩散因子 - 距离 :return: x,y 新坐标 """ ratio_x = - beta * np.log(np.random.random(x.shape) * alpha) ratio_y = - beta * np.log(np.random.random(y.shape) * alpha) dx = ratio_x * (x - self.center_x) dy = ratio_y * (y - self.center_y) return x - dx, y - dy def periodic_func(self, x, x_num): """ 跳动周期曲线 :param p: 参数 :return: y """ # 可以尝试换其他的动态函数,达到更有力量的效果(贝塞尔?) def ori_func(t): return cos(t) func_period = 2 * pi return ori_func(x / x_num * func_period) def gen_points(self, points_num, frame_idx, shape_func): # 用周期函数计算得到一个因子,用到所有组成部件上,使得各个部分的变化周期一致 cy = self.periodic_func(frame_idx, self.frame_num) ratio = 10 * cy # 图形 period = 2 * pi * self.m_star if self.curve == "star" else 2 * pi seed_points = np.linspace(0, period, points_num) seed_x, seed_y = shape_func(seed_points, frame_idx, scale=self.scale) x, y = self.shrink(seed_x, seed_y, ratio, offset=2) curve_width, curve_height = int(x.max() - x.min()), int(y.max() - y.min()) self.main_curve_width = max(self.main_curve_width, curve_width) self.main_curve_height = max(self.main_curve_height, curve_height) point_size = np.random.choice([1, 2], x.shape, replace=True, p=[0.5, 0.5]) tag = np.ones_like(x) def delete_points(x_, y_, ign_area, ign_prop): ign_area = ign_area center_ids = np.where((x_ > self.center_x - ign_area) & (x_ < self.center_x + ign_area)) center_ids = center_ids[0] np.random.shuffle(center_ids) del_num = round(len(center_ids) * ign_prop) del_ids = center_ids[:del_num] x_, y_ = np.delete(x_, del_ids), np.delete(y_, del_ids) # 删除稠密部分的扩散,为了美观 return x_, y_ # 多层次扩散 for idx, beta in enumerate(np.linspace(0.05, 0.2, 6)): alpha = 1 - beta x_, y_ = self.scatter(seed_x, seed_y, alpha, beta) x_, y_ = self.shrink(x_, y_, ratio, offset=round(beta * 15)) x = np.concatenate((x, x_), 0) y = np.concatenate((y, y_), 0) p_size = np.random.choice([1, 2], x_.shape, replace=True, p=[0.55 + beta, 0.45 - beta]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones_like(x_) * 2 tag = np.concatenate((tag, tag_), 0) # 光晕 halo_ratio = int(7 + 2 * abs(cy)) # 收缩比例随周期变化 # 基础光晕 x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_1, y_1 = self.shrink(x_, y_, halo_ratio, offset=18, dist_func="uniform") x_1, y_1 = delete_points(x_1, y_1, 20, 0.5) x = np.concatenate((x, x_1), 0) y = np.concatenate((y, y_1), 0) # 炸裂感光晕 halo_number = int(points_num * 0.6 + points_num * abs(cy)) # 光晕点数也周期变化 seed_points = np.random.uniform(0, 2 * pi, halo_number) x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_2, y_2 = self.shrink(x_, y_, halo_ratio, offset=int(6 + 15 * abs(cy)), dist_func="norm") x_2, y_2 = delete_points(x_2, y_2, 20, 0.5) x = np.concatenate((x, x_2), 0) y = np.concatenate((y, y_2), 0) # 膨胀光晕 x_3, y_3 = shape_func(np.linspace(0, 2 * pi, int(points_num * .4)), frame_idx, scale=self.scale + 0.2) x_3, y_3 = self.shrink(x_3, y_3, ratio * 2, offset=6) x = np.concatenate((x, x_3), 0) y = np.concatenate((y, y_3), 0) halo_len = x_1.shape[0] + x_2.shape[0] + x_3.shape[0] p_size = np.random.choice([1, 2, 3], halo_len, replace=True, p=[0.7, 0.2, 0.1]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones(halo_len) * 2 * 3 tag = np.concatenate((tag, tag_), 0) x_y = np.around(np.stack([x, y], axis=1), 0) x, y = x_y[:, 0], x_y[:, 1] return x, y, point_size, tag def get_frames(self, shape_func): for frame_idx in range(self.frame_num): np.random.seed(self.seed_num) self.frame_points.append(self.gen_points(self.seed_points_num, frame_idx, shape_func)) frames = [] def add_points(frame, x, y, size, tag): highlight1 = np.array(self.highlight_points_color_1, dtype='uint8') highlight2 = np.array(self.highlight_points_color_2, dtype='uint8') base_col = np.array(self.base_color, dtype='uint8') x, y = x.astype(int), y.astype(int) frame[y, x] = base_col size_2 = np.int64(size == 2) frame[y, x + size_2] = base_col frame[y + size_2, x] = base_col size_3 = np.int64(size == 3) frame[y + size_3, x] = base_col frame[y - size_3, x] = base_col frame[y, x + size_3] = base_col frame[y, x - size_3] = base_col frame[y + size_3, x + size_3] = base_col frame[y - size_3, x - size_3] = base_col # frame[y - size_3, x + size_3] = color # frame[y + size_3, x - size_3] = color # 高光 random_sample = np.random.choice([1, 0], size=tag.shape, p=[self.highlight_rate, 1 - self.highlight_rate]) # tag2_size1 = np.int64((tag <= 2) & (size == 1) & (random_sample == 1)) # frame[y * tag2_size1, x * tag2_size1] = highlight2 tag2_size2 = np.int64((tag <= 2) & (size == 2) & (random_sample == 1)) frame[y * tag2_size2, x * tag2_size2] = highlight1 # frame[y * tag2_size2, (x + 1) * tag2_size2] = highlight2 # frame[(y + 1) * tag2_size2, x * tag2_size2] = highlight2 frame[(y + 1) * tag2_size2, (x + 1) * tag2_size2] = highlight2 for x, y, size, tag in self.frame_points: frame = np.zeros([self.frame_height, self.frame_width, 3], dtype="uint8") add_points(frame, x, y, size, tag) frames.append(frame) return frames def draw(self, times=10): frames = self.get_frames(self.curve_function(self.curve)) for i in range(times): for frame in frames: frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) if len(self.bg_imgs) > 0 and self.set_bg_imgs: frame = cv2.addWeighted(self.bg_imgs[i % len(self.bg_imgs)], self.bg_weight, frame, self.curve_weight, 0) cv2.imshow(self.title, frame) cv2.waitKey(self.wait) if __name__ == '__main__': import yaml settings = yaml.load(open("./settings.yaml", "r", encoding="utf-8"), Loader=yaml.FullLoader) if settings["wait"] == -1: settings["wait"] = int(settings["period_time"] / settings["frame_num"]) del settings["period_time"] times = settings["times"] del settings["times"] heart = HeartSignal(seed_num=5201314, **settings) heart.draw(times)settings.yaml# 颜色:RGB三原色数值 0~255 # 设置高光时,尽量选择接近主色的颜色,看起来会和谐一点 # 视频里的蓝色调 #base_color: # 主色 默认玫瑰粉 # - 30 # - 100 # - 100 #highlight_points_color_1: # 高光粒子色1 默认淡紫色 # - 150 # - 120 # - 220 #highlight_points_color_2: # 高光粒子色2 默认淡粉色 # - 128 # - 140 # - 140 base_color: # 主色 默认玫瑰粉 - 228 - 100 - 100 highlight_points_color_1: # 高光粒子色1 默认淡紫色 - 180 - 87 - 200 highlight_points_color_2: # 高光粒子色2 默认淡粉色 - 228 - 140 - 140 period_time: 1000 * 2 # 周期时间,默认1.5s一个周期 times: 50 # 播放周期数,一个周期跳动1次 frame_num: 24 # 一个周期的生成帧数 wait: 60 # 每一帧停留时间, 设置太短可能造成闪屏,设置 -1 自动设置为 period_time / frame_num seed_points_num: 2000 # 构成主图的种子粒子数,总粒子数是这个的8倍左右(包括散点和光晕) highlight_rate: 0.2 # 高光粒子的比例 frame_width: 720 # 窗口宽度,单位像素,设置背景图片后失效 frame_height: 640 # 窗口高度,单位像素,设置背景图片后失效 scale: 9.1 # 主图缩放比例 curve: "heart" # 图案类型:heart, butterfly, star n_star: 7 # n-角型/星,如果curve设置成star才会生效,五角星:n-star:5, m-star:2 m_star: 3 # curve设置成star才会生效,n-角形 m-star都是1,n-角星 m-star大于1,比如 七角星:n-star:7, m-star:2 或 3 title: "Love Li Xun" # 仅支持字母,中文乱码 background_img_dir: "src/center_imgs" # 这个目录放置背景图片,建议像素在400 X 400以上,否则可能报错,如果图片实在小,可以调整上面scale把爱心缩小 set_bg_imgs: false # true或false,设置false用默认黑背景 bg_img_scale: 0.6 # 0 - 1,背景图片缩放比例 bg_weight: 0.4 # 0 - 1,背景图片权重,可看做透明度吧 curve_weight: 1 # 同上 # ======================== 推荐参数: 直接复制数值替换上面对应参数 ================================== # 蝴蝶,报错很可能是蝴蝶缩放大小超出窗口宽和高 # curve: "butterfly" # frame_width: 800 # frame_height: 720 # scale: 60 # base_color: [100, 100, 228] # highlight_points_color_1: [180, 87, 200] # highlight_points_color_2: [228, 140, 140]3.2 运行效果参考资料爱心函数https://github.com/131250208/FunnyToys/blob/main/heart.py
-
[LibreSpeed]:自建speedtest(服务器带宽测试工具) 1.背景自建了web服务有时候服务卡顿的时候想要测试一下客户端到服务器的带宽,使用专门的工具比较繁琐。因此考虑在服务器上搭建speedtest2.搭建步骤(基于宝塔)2.1 创建站点可以用域名-需要实现解析,也可以用IP:端口的方式访问$\color{red}{上面有个错误示范,PHP版本需要选,不能不指定PHP}$2.2 下载源码cd /www/wwwroot/speedtest.inat.top wget https://codeload.github.com/librespeed/speedtest/tar.gz/refs/tags/5.2.5/speedtest-5.2.5.tar.gz tar xzvf speedtest-5.2.5.tar.gz mv speedtest-5.2.5/* ./2.3 修改首页rm index.html cp example-singleServer-full.html index.html2.4 访问测试参考资料1.https://github.com/librespeed/speedtest
-
快速使用mobiledets-yolov4 1.下载项目git clone https://github.com/inacmor/mobiledets-yolov4-pytorch.git2.准备数据2.1 准备VOC格式的数据集put your trainset and labels(xml) in data/Imgs and data/Annotations.这里选择直接将一个VOC格式的数据集通过软链接链接过来ln -s /data_jupiter/dataset/209_VOC_new/Annotations ./ ln -s /data_jupiter/dataset/209_VOC_new/JPEGImages ./Imgs 2.2 修改classes.txtLuggageVehicle BridgeVehicle Plane RefuelVehicle Person FoodVehicle LuggageVehicleHead FollowMe TractorVehicle3.开始训练3.0 环境安装安装pytorch(略)安装apexgit clone https://github.com/NVIDIA/apex cd apex python setup.py install3.1 训练前准备工作python ready.py python kmeans.py3.2 开始训练没有预训练模型的话需要将模型加载注释掉,修改train.py#model.load_state_dict(torch.load(pretrained_weights), strict=False)# 执行训练 python train.py
-
PIP换源 PIP换源1.临时换源使用-i参数指定临时源,任选一个即可#清华源 pip3 install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple #阿里源 pip3 install markdown -i https://mirrors.aliyun.com/pypi/simple/ #腾讯源 pip3 install markdown -i https://mirrors.cloud.tencent.com/pypi/simple #豆瓣源 pip3 install markdown -i https://pypi.douban.com/simple/2.永久换源#清华源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #阿里源 pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ #腾讯源 pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple #豆瓣源 pip config set global.index-url https://pypi.douban.com/simple/ #换回默认源 pip config unset global.index-url
-
BaiduPCS-Go:仿 Linux shell 文件处理命令的百度网盘命令行客户端 BaiduPCS-Go:仿 Linux shell 文件处理命令的百度网盘命令行客户端1.简介当需要在没有图形界面的服务器上直接从百度云下载或者上传大量文件的时候,通过window中转会效率较低,BaiduPCS-Go是一款基于Go语言开发的仿 Linux shell 文件处理命令的百度网盘命令行客户端可以完美解决这个问题。项目地址:https://github.com/qjfoidnh/BaiduPCS-Go2.下载配置wget https://github.com/qjfoidnh/BaiduPCS-Go/releases/download/v3.8.7/BaiduPCS-Go-v3.8.7-linux-amd64.zip unzip BaiduPCS-Go-v3.8.7-linux-amd64.zip mv BaiduPCS-Go-v3.8.7-linux-amd64 BaiduPCS-Go cd BaiduPCS-Go3.使用方式进入BaiduPCS-Go命令模型BaiduPCS-Go用户登录login #根据提示登录 请输入百度用户名(手机号/邮箱/用户名), 回车键提交 >常用命令COMMANDS: tool 工具箱 help, ?, ? Shows a list of commands or help for one command 其他: clear, cls 清空控制台 env 显示程序环境变量 run 执行系统命令 sumfile, sf 获取本地文件的秒传信息 update 检测程序更新 百度帐号: login 登录百度账号 loglist 列出帐号列表 logout 退出百度帐号 su 切换百度帐号 who 获取当前帐号 百度网盘: cd 切换工作目录 cp 拷贝文件/目录 createsuperfile, csf 手动分片上传—合并分片文件 download, d 下载文件/目录 export, ep 导出文件/目录 fixmd5 修复文件MD5 locate, lt 获取下载直链 ls, l, ll 列出目录 match 测试通配符 meta 获取文件/目录的元信息 mkdir 创建目录 mv 移动/重命名文件/目录 offlinedl, clouddl, od 离线下载 pwd 输出工作目录 quota 获取网盘配额 rapidupload, ru 手动秒传文件 recycle 回收站 rm 删除文件/目录 search, s 搜索文件 share 分享文件/目录 transfer 转存文件/目录 tree, t 列出目录的树形图 upload, u 上传文件/目录 配置: config 显示和修改程序配置项4.使用下载效果image-20221104112121582.png
-
机场机坪作业特种车辆介绍 1.“旅客服务”三兄弟客梯车名称:客梯车技能:远机位登机特点:货车头 长扶梯这款旅客登机梯(电动式)是上海东方航空设备制造有限公司最新设计研制的一种新型登机梯。当飞机停靠在没有廊桥的远机位时,就需要用到登机梯。它的车头和普通货车类似,但底盘安装有可“伸缩”的扶梯,通过调整扶梯高度可以适应不同机型,机型越大,坡度越陡。行动不便旅客登机车名称:行动不便旅客登机车技能:运送特殊旅客特征:方形车厢 x型伸展臂车身加装了一个方形的车厢,和云梯一样可上可下,是登机的“无障碍”通道,方便残疾旅客、轮椅旅客及重病担架旅客上下飞机。车内还安置了用于固定残疾人轮椅的设备,防止轮椅侧滑。东航实业自主研发的这款“行动不便旅客登机车”还是国内首台新能源车型,相较内燃发动机而言,更为环保,是升级换代的新款,目前已经投入使用。摆渡车名称:摆渡车技能:远机位运输神器特征:形似大巴 低底盘 无台阶这是旅客最常接触也是最熟悉的大家伙——摆渡车,它是连接候机厅和远机位飞机的唯一通道。图中是东航实业开发的新一代新能源机场摆渡车,别看长得像个压扁的面包块,但却能容纳一百多人,并且还是个隐形的豪车,身价百万哦~2.“行李”三兄弟行李牵引车名称:行李牵引车技能:运送行李至停机位特征:火车头 小个子 多个车厢行李牵引车又叫行李拖车。如果说旅客最先接触到的特种车辆是摆渡车,那行李最先接触到的就是行李牵引车。它就像一个火车头,身后牵引着很多个小“车厢”,车厢里装载着行李、货物、邮件等,并负责将他们运送至停机位。别看它小小萌萌的,力气可一点也不打折,最多可同时牵引10个车厢。挂满车厢能达到25米,承载行李货物可达30吨。行李传送车名称:行李传送车技能:传送行李至货舱特征:长手臂这是上海东方航空设备制造有限公司研制的新型散装货物装载机。散装货物装载机,又叫行李传送车。行李传送车有一个长长的传送带,开关启动后,传送带会慢慢滚动起来,然后像机器人一样“变形”,缓缓上升,把行李一件件送上飞机。货物平台升降车名称:货物平台升降车技能:运送集装箱进货舱特征:扁平身材 大力水手 x型支撑架小件行李能通过传送带进入货舱,那么又大又重的集装箱货物怎么办呢?比如疫情期间的支援物资。这时候就需要“平台升降车”上场。就是上图这个扁扁的家伙,它的车身像一个秤盘,扁平而宽敞,车上有一个x形的支撑架,依靠液压升降设备支撑,可以将巨大的集装箱平稳地“托举”数米高,然后再将集装箱平面旋转送入机舱,名副其实的机场“大力士”3.“飞机保障”三兄弟飞机牵引车名称:飞机牵引车技能:推飞机特征:超低底盘 大轮子这种机坪上的大型“铁憨憨”,就是飞机牵引车。它的特点是有着四个大轮子+超低底盘,高度只有1.5米左右,看上去就像个方方正正的大盒子。牵引车是推着飞机向后行驶的,由于飞机没有“倒挡”,不能自己向后退,为了方便飞机从停机位进出就需要用到飞机牵引车;此外,进出狭窄或封闭空间的活动(诸如进出机库)也需要牵引车的帮助,因此飞机牵引车在机场的使用率很高。也有这种类型的牵引车。飞机除冰车名称:飞机除冰车技能:给“大白”洗热水澡特征:大长臂 方脑袋 行走的花洒飞机洗澡,专业术语叫“除防冰”。图中是东航实业与英国mallaghan工程技术公司的一款合作产品,拥有先进技术和先进模块化设计的“除冰车”。寒冷的冬天,“大白”的表面很容易落雪结冰,为保证航班安全运行,飞机起飞前必须除冰。除冰时,工作人员将加热到指定温度的除冰液和未加热的防冰液以一定的压力喷射到飞机结冰的机翼表面、进气道前缘、升降舵及垂直尾翼上面。飞机加油车名称:飞机加油车(管线式)技能:给飞机加油特征:货车头 车身有大量管线管线式加油车直接与地下的航油供给管路对接,将航油注入飞机油舱,避免了加油车携带大量燃油造成的不安全性,并且减轻车辆重量,提高了车辆运行的效率。4.“云上吃喝”四兄弟食品车名称:食品车技能:吃货的补给站特征:方形车厢 剪刀式升降装置这可能是吃货们最关心的车。航班上的飞机餐和各类物品(毛毯、耳机等)都是通过这类车辆运送上去的。图中的这款食品车也是由上海东方航空设备制造有限公司生产制造的。与残疾人升降车相似,它也有一个巨型车厢,车厢可以平行向上升举,连接飞机舱门,飞机餐就装在一个个手推车里推进机舱。垃圾车名称:垃圾车技能:清理飞机垃圾特征:梯形车斗飞机上用过的纸杯、餐盒、果皮等都去哪了呢?自然是飞机落地时倾倒进“垃圾车”。图中这款就是东东(上海东方航空设备制造有限公司)自主研制的lj-15e航空垃圾接收车。与食品车不同的是,垃圾车的车厢更小,并且向上升举时,不是平行的,而是倾斜的,为了方便工作人员向下倾倒垃圾。清水车名称:清水车技能:提供饮用水特征:扁长水箱 细长管子图中的特种车是东东自主研制的一款清水车,是给飞机提供清洁饮用水的车辆。机身有一个扁平的罐体,这个看似不大的“肚子”里装着大量饮用水,作业时通过一个细长的管子与飞机连接,将饮用水输送至飞机水箱,飞机上泡咖啡的水就是来自这里~污水车名称:污水车技能:清理排泄物特征:扁平水箱 粗长管子和清水车外形相似,但用途不同,污水车是用于吸收机上排泄物的。当飞机结束一段航程,风尘仆仆地落地,地勤工作人员就会驾驶着污水车前来清理飞机排泄物,与清水车的管子不同,污水车有一根又大又粗的真空吸管,将管子与飞机排污口相连,开关打开,排泄物就被吸入污水车里了。排泄物清理干净之后飞机才能进行下一航程。(p.s.图中也是东东自主研发款哦)5.APU-电源车|气源车|空调车飞机电源车、气源车,以及空调车比较容易混淆,它们有挂式的、有车载式的,型号众多,造型各异。但有一点却极其相似,3辆车加起来就是约等于飞机的APU,APU我们了解,在地面上有三个主要作用,给飞机供电、供气,以及依靠高压引气启动发动机。与此对应,3种车可以从外部提供相同的功能,电源车供电,空调车提供舒适的低压空气,气源车则提供启动发动机的高压空气。如何对它们进行区分呢?电源车一般停靠在机头下方,而气源车、空调车常停靠在位于机腹的位置,由于空调车给的是低压空气,所以管子会更加粗壮,从这一点上非常容易辨认。电源车气源车空调车参考资料大型揭秘现场!认识十个算我输!机场里的特种车,你认识多少?《机坪特种车识别指南》
-
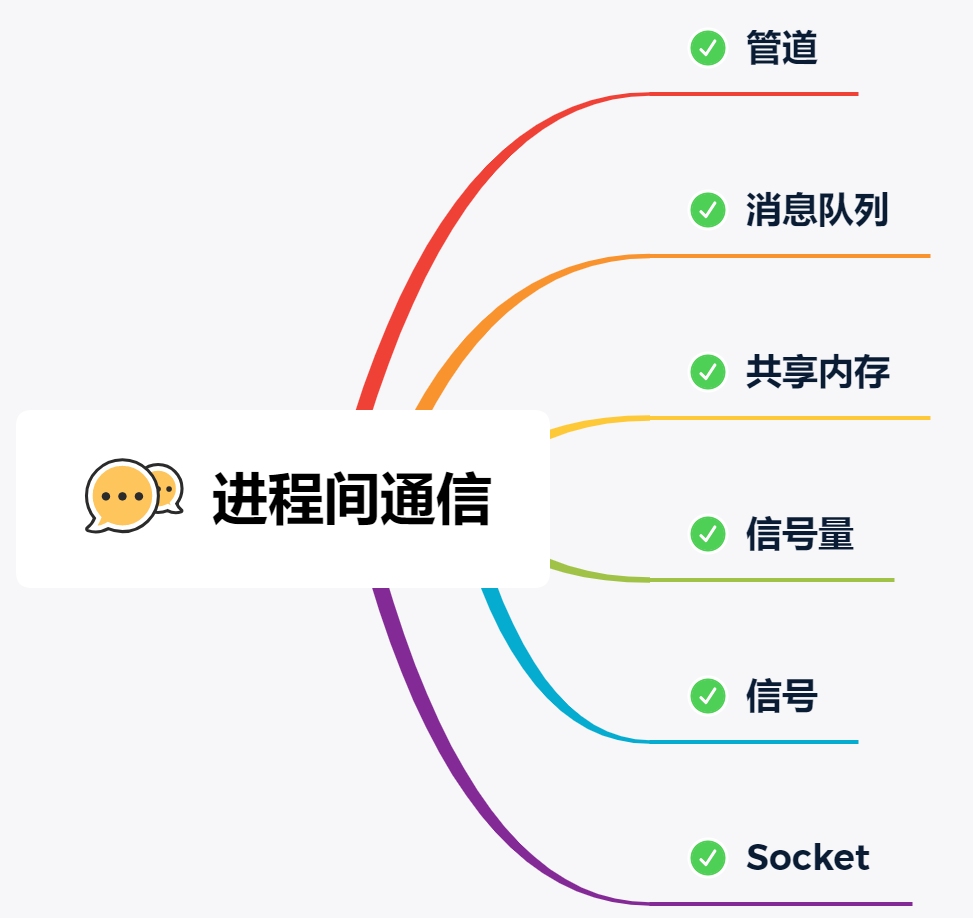
操作系统高频面试题梳理 0.题目汇总线程和进程的区别?进程之间的通信方式说一说进程的状态说说僵尸进程和孤儿进程。死锁的必要条件周转时间和带权周转时间的计算页面置换算法1.线程和进程的区别?1、根本区别: 进程是操作系统资源分配和独立运行的最小单位;线程是任务调度和系统执行的最小单位。2、地址空间区别: 每个进程都有独立的地址空间,一个进程崩溃不影响其它进程;一个进程中的多个线程共享该 进程的地址空间,一个线程的非法操作会使整个进程崩溃。3、上下文切换开销区别: 每个进程有独立的代码和数据空间,进程之间上下文切换开销较大;线程组共享代码和数据空间,线程之间切换的开销较小。2.进程之间的通信方式每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。管道(内核中的缓冲区)管道本质上就是内核中的一个缓冲区,程序通过对缓存进行读写完成通信匿名管道:在内核中申请一块固定大小的缓冲区,程序拥有写入和读取的权利。// 创建匿名管道,并返回了两个描述符,一个是管道的读取端描述符 fd[0],另一个是管道的写入端描述符 fd[1] int fd[2]; if(pipe(fd)==-1) ERR_EXIT("pipe error");看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?可以使用 fork 创建子进程,创建的子进程会复制父进程的文件描述符,这样就做到了两个进程各有两个「 fd[0] 与 fd[1]」,两个进程就可以通过各自的 fd 写入和读取同一个管道文件实现跨进程通信了。可以使用 fork 创建的两个子进程之间也可以使用匿名管道实现通信。命名管道: 在内核中申请一块固定大小的缓冲区,程序拥有写入和读取的权利,没有血缘关系的进程也可以进程间通信。mkfifo("tp",0644); int infd; infd = open("abc",o_RDONLY); if (infd ==-1)ERR_EXIT("open"); int outfd; outfd = open ("tp",O_WRONLY);优点实现简单,自带同步互斥机制缺点每个消息的最大长度是有上限的(MSGMAX)效率低下,不适合进程间频繁的交换数据半双工通信,同一时刻只有一个进程可以进行读写。(可以用两个管道实现双向通信)消息队列(内核中的队列)在内核中创建一队列,不同的进程可以通过句柄去访问这个队列,队列中每个元素是一个数据报。优点消息队列可实现双向通信。消息队列允许一个或多个进程写入或者读取消息。缺点每个消息的最大长度是有上限的(MSGMAX)消息队列的总数也有⼀个上限(MSGMNI)存在用户态和内核态之间的数据拷贝问题。进程往消息队列写入数据时,会发送用户态拷贝数据到内核态的过程,同理读取数据时会发生从内核态到用户态拷贝数据的过程。共享内存将同一块物理内存一块映射到不同的进程的虚拟地址空间中,实现不同进程间对同一资源的共享。这样一个进程写入的东西,另一个进程马上就能够看到,不需要进行拷贝。优点速度快:不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名缺点多进程竞争同个共享资源会造成数据的错乱:如果有多个进程同时往共享内存写入数据,有可能先写的进程的内容会被其他进程覆盖。信号量(内核中的信号量集合)在内核中创建一个信号量集合(本质是个数组),数组的元素(信号量)都是1,使用P操作进行-1,使用V操作+1,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据。P(sv):如果sv的值⼤大于零,就给它减1;如果它的值为零,就挂起该进程的执⾏ 。V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运⾏,如果没有进程因等待sv⽽挂起,就给它加1。信号上面说的进程间通信,都是常规状态下的工作模式。对于异常情况下的工作模式,就需要用「信号」的方式来通知进程。信号是进程间通信机制中唯一的异步通信机制。在Linux中,为了响应各种事件,提供了几十种信号,可以通过kill -l命令查看。$ kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX运行在 shell 终端的进程,我们可以通过键盘输入某些组合键的时候,给进程发送信号。例如Ctrl+C 产生 SIGINT 信号,表示终止该进程;Ctrl+Z 产生 SIGTSTP 信号,表示停止该进程,但还未结束;如果进程在后台运行,可以通过 kill 命令的方式给进程发送信号,但前提需要知道运行中的进程 PID 号,例如:kill -9 1050 ,表示给 PID 为 1050 的进程发送 SIGKILL 信号,用来立即结束该进程;Socket前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。实际上,Socket 通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信。针对 TCP 协议通信的 socket 编程模型针对 UDP 协议通信的 socket 编程模型3.说一说进程的状态创建状态:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行执行状态:进程处于就绪状态被调度后,进程进入执行状态阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行4.说说僵尸进程和孤儿进程。我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。5.死锁的必要条件互斥条件:一个资源每次只能被一个进程使用; 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺;循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系;6.周转时间和带权周转时间的计算$$ 周转时间=作业完成时刻-作业到达时刻\\ 带权周转时间=\frac{周转时间}{服务时间}\\ 平均周转时间=\frac{作业周转总时间}{作业个数}\\ 平均带权周转时间=\frac{带权周转总时间}{作业个数}\\ $$7.页面置换算法在进程运行的过程当中,进程所要访问的页面不在内存中,我们就需要把这个不存在的页面调入内存,但内存已经没有空闲空间了,这时候就要求系统从内存中调出一个页面,将其移入磁盘的对换区中。将哪个页面调出来,就要通过算法来确定。我们把选择换出页面的算法就叫做页面置换算法。先进先出置换算法FIFO思想:先进先出算法总是淘汰最先进入内存的页面。出发点是近期调入的页面被再次访问的概率要大于早期调入页面的概率。例题:考虑下述页面走向:1,2,3,4,2,1,5,6,2,1,2,3,7,6,3,2,1,2,3,6。当内存块数量分别为3时,试问先进先出置换算法(FIFO)的缺页次数是多少?最近最少使用页面置换算法LRU思想:每次选择内存中离当前时刻最久未使用过的页面淘汰,依据的原理是局部性原理例题:考虑下述页面走向:1,2,3,4,2,1,5,6,2,1,2,3,7,6,3,2,1,2,3,6。当内存块数量分别为3时,试问最近最少使用页面置换算法(LRU)的缺页次数是多少?最佳置换算法OPT思想:选择的被淘汰页面是以后用不使用的,或者是在未来最长一段时间内不再被访问的页面。例题:考虑下述页面走向:1,2,3,4,2,1,5,6,2,1,2,3,7,6,3,2,1,2,3,6。当内存块数量分别为3时,试问最佳置换法(OPT)的缺页次数是多少?Clock置换算法略参考资料面试题:进程、线程及协程的区别六种进程间通信方式进程间的通信方式(六种)


![[微信小程序开发Bug]:redirectTo:fail can not redirectTo a tabbar page](/usr/uploads/auto_save_image/bab76792419df1c1c265cf9703adee07.png)
![[视频目标检测]:使用MEGA|DFF|FGFA训练自己的数据集](https://blog.inat.top/usr/themes/Joe/assets/thumb/38.jpg)

![[LibreSpeed]:自建speedtest(服务器带宽测试工具)](/usr/uploads/auto_save_image/c9cf00b8b2cefe2c66828826908fcdd7.png)