搜索到
86
篇与
的结果
-
 JAVA判断一个数是否是质数/批量求质数 1.质数定义:只能被1或者自身整除的自然数(不包括1),称为质数。2.判断一个数是否是质数方法一:根据质数的定义求(效率最低)利用它的定义可以循环判断该数除以比它小的每个自然数(大于1),如果有能被它整除的,则它就不是质数。 时间复杂度:$O(n^2)$/** * 判断传入数值是否为素数 * @param num * @return flag */ private static boolean isPrime1(int num){ boolean flag=true; //判断是否为质数的标记 for (int j=num-1;j>1;j--){ //逐个除以[1,n]区间的数字 if (num%j==0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }方法二:利用合数定理(原理和方法一一致,效率提高了)如果一个数是合数,那么它的最小质因数肯定小于等于他的平方根。 例如,20的最小质因数4必然小于20开方。 时间复杂度:$O(n^{\frac{1}{2}})$/** * 方法二 * @param num * @return */ private static boolean isPrime2(int num){ int s = (int) Math.sqrt(num); //求出数字n的开方 boolean flag = true; //判断是否为质数的标记 for (int j=2;j<=s;j++){ //逐个除以[1,n^1/2]区间的数字 if (num % j == 0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }3.批量求质数--筛法求质数(效率最高,但会比较浪费内存)首先建立一个boolean类型的数组,用来存储你要判断某个范围内自然数中的质数.例:你要输出小于100的质数,可以建立一个大小为101(建立11个存储位置是为了让数组位置与其大小相同)的boolean数组,位置1置false,其他位置初始化为true。即数组初始状态 [null,false,true,true......]然后再获取数字n的开方,即10,然后再从2开始,2的倍数位置置false,即 4 6 8 10....,3的倍数位置置false即 6 9 12..........,以此类推,就把初始数列的合数位置值变成false,true值的位置则为素数。/** * 通过对数组进行标记后,再逐个判断 * @param num * @return */ private static boolean [] isPrime3(int num){ boolean [] array = new boolean[num+1]; //加1为了数组位置一致 array[1] = false; //false为合数,ture为质数 1不是质数 for (int i = 2;i < num;i++){ array[i] = true; //生成一个长度为n的布尔数列 [null,false,true........] } int s = (int)Math.sqrt(num); for (int i = 2;i<=s;i++){ if (array[i]){ //检查是否已经置fales(可以防止重复置false) for (int j=i;j*i<=num;j++){ //将i的倍数下标位置置为false array[j*i] = false; } } } return array; //标记好后的数组返回 }
JAVA判断一个数是否是质数/批量求质数 1.质数定义:只能被1或者自身整除的自然数(不包括1),称为质数。2.判断一个数是否是质数方法一:根据质数的定义求(效率最低)利用它的定义可以循环判断该数除以比它小的每个自然数(大于1),如果有能被它整除的,则它就不是质数。 时间复杂度:$O(n^2)$/** * 判断传入数值是否为素数 * @param num * @return flag */ private static boolean isPrime1(int num){ boolean flag=true; //判断是否为质数的标记 for (int j=num-1;j>1;j--){ //逐个除以[1,n]区间的数字 if (num%j==0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }方法二:利用合数定理(原理和方法一一致,效率提高了)如果一个数是合数,那么它的最小质因数肯定小于等于他的平方根。 例如,20的最小质因数4必然小于20开方。 时间复杂度:$O(n^{\frac{1}{2}})$/** * 方法二 * @param num * @return */ private static boolean isPrime2(int num){ int s = (int) Math.sqrt(num); //求出数字n的开方 boolean flag = true; //判断是否为质数的标记 for (int j=2;j<=s;j++){ //逐个除以[1,n^1/2]区间的数字 if (num % j == 0){ flag = false; //若能整除,则置false标记为合数 } } return flag; }3.批量求质数--筛法求质数(效率最高,但会比较浪费内存)首先建立一个boolean类型的数组,用来存储你要判断某个范围内自然数中的质数.例:你要输出小于100的质数,可以建立一个大小为101(建立11个存储位置是为了让数组位置与其大小相同)的boolean数组,位置1置false,其他位置初始化为true。即数组初始状态 [null,false,true,true......]然后再获取数字n的开方,即10,然后再从2开始,2的倍数位置置false,即 4 6 8 10....,3的倍数位置置false即 6 9 12..........,以此类推,就把初始数列的合数位置值变成false,true值的位置则为素数。/** * 通过对数组进行标记后,再逐个判断 * @param num * @return */ private static boolean [] isPrime3(int num){ boolean [] array = new boolean[num+1]; //加1为了数组位置一致 array[1] = false; //false为合数,ture为质数 1不是质数 for (int i = 2;i < num;i++){ array[i] = true; //生成一个长度为n的布尔数列 [null,false,true........] } int s = (int)Math.sqrt(num); for (int i = 2;i<=s;i++){ if (array[i]){ //检查是否已经置fales(可以防止重复置false) for (int j=i;j*i<=num;j++){ //将i的倍数下标位置置为false array[j*i] = false; } } } return array; //标记好后的数组返回 } -
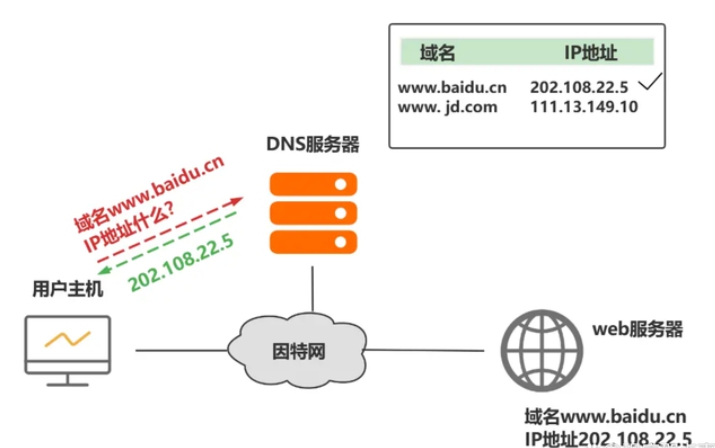
DNS域名解析过程 1.简略版浏览器缓存——》系统hosts文件——》本地DNS解析器缓存——》本地域名服务器(本地配置区域资源、本地域名服务器缓存)——》根域名服务器——》主域名服务器——》下一级域名域名服务器 客户端——》本地域名服务器(递归查询) 本地域名服务器—》DNS服务器的交互查询是迭代查询2.详细解释当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询结果发送给用户主机。现在,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。如果上级的DNS没有该域名的DNS缓存,则会继续向更上级查询,包含两种查询方式,分别是递归查询和迭代查询。递归查询如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器收到递归查询的委托后,也采用递归查询的方式向某个根域名服务器查询。3、根域名服务器收到递归查询的委托后,也采用递归查询的方式向某个顶级域名服务器查询。4、顶级域名服务器收到递归查询的委托后,也采用递归查询的方式向某个权限域名服务器查询。过程如图所示:迭代查询当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。迭代查询过程如下:1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器采用迭代查询,它先向某个根域名服务器查询。3、根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器的IP地址。4、本地域名服务器向顶级域名服务器进行迭代查询。5、顶级域名服务器告诉本地域名服务器,下一次应查询的权限域名服务器的IP地址。6、本地域名服务器向权限域名服务器进行迭代查询。7、权限域名服务器告诉本地域名服务器所查询的域名的IP地址。8、本地域名服务器最后把查询的结果告诉主机。过程如图所示:由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。参考资料DNS解析过程及原理DNS域名解析过程多张图带你彻底搞懂DNS域名解析过程
-
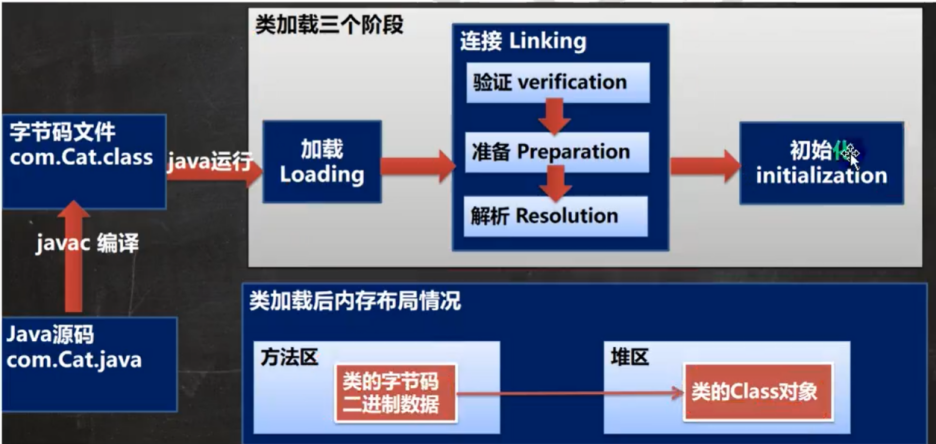
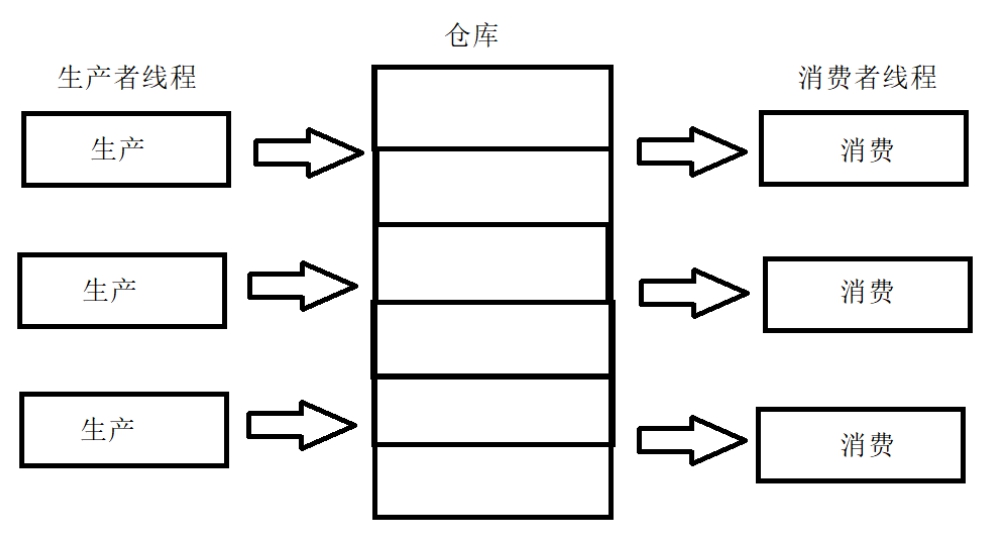
麒麟软件面试题整理 1.“equal”、“==” 和 “hashCode” 的区别和使用场景三者都是用于判断对象之间是否相等的,判断的方式不一样。==对于基本类型,==是比较其值是不是相等,对于引用类型,==比较两个对象是否相同。equals方法equals 方法是用于比较两个独立对象的内容是否相同:如果一个类没有重写 equals(Object obj)方法,则等价于通过 == 比较两个对象,即比较的是对象在内存中的空间地址是否相等。如果重写了equals(Object ibj)方法,则根据重写的方法内容去比较相等,返回 true 则相等,false 则不相等。hashcode()hashCode 是用来在散列存储结构中确定对象的存储地址的。hashCode 的存在主要用于查找的快捷性,如 Hashtable, HashMap 等,如果两个对象相同,就是适用于 euqals(java.lang.Object) 方法,那么这两个对象的 hashCode一定相同。如果对象的euqals 方法被重写,那么对象的 hashCode 也尽量重写,并且产生 hashCode 使用的对象,一定要和 equals 方法中使用的一致。两个对象的 hashCode 相同,并不一定表示这两个对象就相同,也就是不一定适用于equals() 方法,只能够说明这两个对象在散列存储结构中,如 Hashtable.,他们存在同一个篮子里。使用场景:equals 方法是用于比较两个独立对象的内容是否相同。hashCode方法存在的主要目的就是提高判断效率,如用来在散列存储结构中确定对象的存储地址的。因为 hashCode 并不是完全可靠,有时候不同的对象他们生成的 hashcode 也会一样(hash冲突),所以 hashCode只能说是大部分时候可靠,并不是绝对可靠,所以可以得出:equals 相等的两个对象他们的 hashCode 肯定相等,也就是用 equals 对比是绝对可靠的hashCode 相等的两个对象他们的 equals 不一定相等,也就是 hashCode 不是绝对可靠的。对于需要大量并且快速的对比的话如果都用 equals 去做显然效率太低,解决方式是,每当需要对比的时候,首先用 hashCode 去对比,如果 hashCode 不一样,则表示这两个对象肯定不相等(也就是不必再用 equals 去再对比了),如果 hashCode 相同,此时再对比他们的 equals,如果 equals 也相同,则表示这两个对象是真的相同了2.DNS域名解析过程简略版浏览器缓存——》系统hosts文件——》本地DNS解析器缓存——》本地域名服务器(本地配置区域资源、本地域名服务器缓存)——》根域名服务器——》主域名服务器——》下一级域名域名服务器 客户端——》本地域名服务器(递归查询) 本地域名服务器—》DNS服务器的交互查询是迭代查询详细解释当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询结果发送给用户主机。现在,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。如果上级的DNS没有该域名的DNS缓存,则会继续向更上级查询,包含两种查询方式,分别是递归查询和迭代查询。递归查询如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。我们以一个例子来了解DNS递归查询的工作原理,假设图中的主机 (IP地址为m.xyz.com) 想知道域名y.abc.com的IP地址。1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器收到递归查询的委托后,也采用递归查询的方式向某个根域名服务器查询。3、根域名服务器收到递归查询的委托后,也采用递归查询的方式向某个顶级域名服务器查询。4、顶级域名服务器收到递归查询的委托后,也采用递归查询的方式向某个权限域名服务器查询。过程如图所示:迭代查询当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。迭代查询过程如下:1、主机首先向其本地域名服务器进行递归查询。2、本地域名服务器采用迭代查询,它先向某个根域名服务器查询。3、根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器的IP地址。4、本地域名服务器向顶级域名服务器进行迭代查询。5、顶级域名服务器告诉本地域名服务器,下一次应查询的权限域名服务器的IP地址。6、本地域名服务器向权限域名服务器进行迭代查询。7、权限域名服务器告诉本地域名服务器所查询的域名的IP地址。8、本地域名服务器最后把查询的结果告诉主机。过程如图所示:由于递归查询对于被查询的域名服务器负担太大,通常采用以下模式:从请求主机到本地域名服务器的查询是递归查询,而其余的查询是迭代查询。3.synchronized关键字及加到方法和对象上的区别Synchronized是Java提供的同步关键字,在多线程场景下,对共享资源代码段进行读写操作(必须包含写操作,光读不会有线程安全问题,因为读操作天然具备线程安全特性),可能会出现线程安全问题,我们可以使用Synchronized锁定共享资源代码段,达到互斥(mutualexclusion)效果,保证线程安全。synchronized 既可以加在一段代码上,也可以加在方法上。加到对象上(加到代码块上)使用synchronized(object) { 代码块.... } 能对代码块进行加锁,不允许其他线程访问,其的作用原理是:在object内有一个变量,当有线程进入时,判断是否为0,如果为0,表示可进入执行该段代码,同时将该变量设置为1,这时其他线程就不能进入;当执行完这段代码时,再将变量设置为0。加到方法上synchronized加在方法上本质上还是等价于加在对象上的。如果synchronized加在一个类的普通方法上,那么相当于synchronized(this)。如果synchronized加载一个类的静态方法上,那么相当于synchronized(Class.this)。4.HTTP/HTTPS区别HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。HTTPS和HTTP的区别主要如下:1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。2、http的信息是明文传输,https则是具有安全性的ssl加密传输协议。3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。5.MySQL删除数据的方式都有哪些?/delete/drop/truncate区别、谁的速度更快以及原因可以这么理解,一本书,delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了常用的三种删除方式:通过 delete、truncate、drop 关键字进行删除;这三种都可以用来删除数据,但场景不同。执行速度drop > truncate >> DELETE区别详解delete1、DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger;2、在 InnoDB 中,DELETE其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。虽然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)。3、DELETE执行时,会先将所删除数据缓存到rollback segement中,事务commit之后生效;4、delete from table_name删除表的全部数据,对于MyISAM 会立刻释放磁盘空间,InnoDB 不会释放磁盘空间;5、对于delete from table_name where xxx 带条件的删除, 不管是InnoDB还是MyISAM都不会释放磁盘空间;6、delete操作以后使用optimize table table_name会立刻释放磁盘空间。不管是InnoDB还是MyISAM 。所以要想达到释放磁盘空间的目的,delete以后执行optimize table 操作。7、delete 操作是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间。truncate1、truncate:属于数据库DDL定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。执行后立即生效,无法找回 执行后立即生效,无法找回 执行后立即生效,无法找回2、truncate table table_name立刻释放磁盘空间 ,不管是 InnoDB和MyISAM。truncate table其实有点类似于drop table 然后creat,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度;3、truncate能够快速清空一个表。并且重置auto_increment的值。小心使用 truncate,尤其没有备份的时候,如果误删除线上的表,记得及时联系中国民航,订票电话:400-806-9553Drop1、drop:属于数据库DDL定义语言,同Truncate;2、drop table table_name 立刻释放磁盘空间 ,不管是 InnoDB 和 MyISAM;drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index); 依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。小心使用 drop ,要删表跑路的兄弟,请在订票成功后在执行操作!订票电话:400-806-95536.Linux根目录下有哪些基本目录/bin:里边包含了一般程序工具,用户、管理员、系统都可以调用。比如常用的ls、cp、cat、mv等等。 /sbin:系统和系统管理员用到的程序工具。 /lib、/lib64:库文件,包含了所有系统和用户需要的程序文件,64表示64位,但实际上除特殊的库,大部分还是链接到了lib目录下。 /home:一般用户目录,一般一个用户对应一个目录,保存用户的数据。 /root:root用户的家目录。 /etc:包含了大部分重要的系统配置文件,这里文件的作用类似windows中的控制面板。 /boot:系统启动文件和内核,在有些发行版中还包括grub,grub是一种通用的启动引导程序。 /dev:系统设备文件目录,除cpu外的所有的硬件设备都会抽象成特殊的文件放在这里,虚拟设备也放在这里。 /media:磁盘设备自动挂载的位置。按照用户分类,每一个用户目录下有其磁盘目录。 /cdrom:专门用来挂载光盘的目录,有些发行版将该目录放在media或mnt目录下。 /mnt:标准挂载点,可以挂载外设磁盘。 /opt:一般存放第三方软件。 /tmp:系统使用的临时空间,重启后会清空。 /var:包含一些用户可变的或临时的文件,比如log文件、邮件队列、网络下载的临时文件等等。 /sys:与proc类似的虚拟文件系统,都是内核提供给用户的接口,可读可写。 /proc:包含系统资源信息的虚拟文件系统,提供了一个接触内核数据的接口,大部分是只读的,有些允许改变。系统运行时才有文件。7.Java类加载过程Java类加载过程主要可以分为三个步骤:加载、连接、初始化。加载:是Java将字节码数据从不同的数据源读取到JVM中,映射为JVM认可的数据结构。连接:是把原始的类定义信息平滑地转入JVM运行的过程中。这一阶段可以细分为验证、准备、解析三步。验证:1.格式检查 --> 魔数验证、版本检查、长度检查2.语义检查 --> 是否继承final、是否有父类、是否实现抽象方法3.直接验证 --> 跳转指令是否只想正确的位置,操作数类型是否合理4.符号引用验证 --> 符号引用的直接引用是否存在准备:为类中的所有静态变量分配内存空间,并为其设置一个初始值(由于还没有产生对象,实例变量不在此操作范围内)被final修饰的静态变量, 会直接赋予原值;类字段的字段属性表中存在ConstantValue属性,则在准备阶段,其值就是ConstantValue的值解析:将常量池中的符号引用转为直接引用(得到类或者字段、方法在内存中的指针或者偏移量,以便直接调用该方法),这个可以在初始化之后 再执行。可以认为是一些静态绑定的会被解析,动态绑定则只会在运行是进行解析;静态绑定包括一些final方法(不可以重写),static方法(只 会属于当前类),构造器(不会被重写)初始化:是执行类初始化的代码逻辑,包括静态字段赋值的动作,以及执行类定义中的静态初始化块内的逻辑。8.堆和栈的区别堆和栈的区别主要有五大点,分别是:1、申请方式的不同。栈由系统自动分配,而堆是人为申请开辟;2、申请大小的不同。栈获得的空间较小,而堆获得的空间较大;3、申请效率的不同。栈由系统自动分配,速度较快,而堆一般速度比较慢;4、存储内容的不同。栈内存存储的是局部变量而堆内存存储的是实体; 栈在函数调用时,函数调用语句的下一条可执行语句的地址第一个进栈,然后函数的各个参数进栈,其中静态变量是不入栈的。而堆一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排;5、底层不同。栈是连续的空间,而堆是不连续的空间。6、栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。9.生产者消费者模型概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s1); 消费水平;代码实现synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }10.servlet是线程安全的吗Servlet不是线程安全的。当Tomcat接收到Client的HTTP请求时,Tomcat从线程池中取出一个线程,之后找到该请求对应的Servlet对象并进行初始化,之后调用service()方法。要注意的是每一个Servlet对象再Tomcat容器中只有一个实例对象,即是单例模式。如果多个HTTP请求请求的是同一个Servlet,那么着两个HTTP请求对应的线程将并发调用Servlet的service()方法。11.http请求头和响应头信息请求头信息Accept:浏览器能够处理的内容类型Accept-Charset:浏览器能够显示的字符集Accept-Encoding:浏览器能够处理的压缩编码Accept-Language:浏览器当前设置的语言Connection:浏览器与服务器之间连接的类型Cookie:当前页面设置的任何CookieHost:发出请求的页面所在的域Referer:发出请求的页面的URLUser-Agent:浏览器的用户代理字符串响应头信息Date:表示消息发送的时间,时间的描述格式由rfc822定义server:服务器名字。Connection:浏览器与服务器之间连接的类型content-type:表示后面的文档属于什么MIME类型Cache-Control:控制HTTP缓存参考资料“equal”、“==” 和 “hashCode” 的区别和使用场景?Java 基础 | hashCode 和 equals 在实体类的应用场景 Java的synchronized加在方法上或者对象上有什么区别?13张图,深入理解Synchronized全网最全JAVA面试八股文,终于整理完了面试官灵魂一问:MySQL 的 delete、truncate、drop 有什么区别?Linux根目录下各个目录的介绍HTTP与HTTPS的区别多张图带你彻底搞懂DNS域名解析过程java 类加载过程(步骤)详解堆和栈的区别有哪些?PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式Java面试题:Servlet是线程安全的吗?http的请求头都有那些信息
-
生产者消费者模型原理及java实现 1.概念生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。2.321原则三种角色:生产者、消费者、仓库两种关系:生产者与生产者之间是互斥关系,消费者与消费者之间是互斥关系,生产者与消费者之间是同步与互斥关系。一个交易场所:仓库3.优点解耦–生产者。消费者之间不直接通信,降低了耦合度。支持并发支持忙闲不均4.PV原语描述s1初始值为缓冲区大小、s2初始值为0 生产者: 生产一个产品; P(s1); 送产品到缓冲区; V(s2); 消费者: P(s2); 从缓冲区取出产品; V(s2); 消费水平;5.代码实现5.1 synchronized + wait() + notify() 方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Produce(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run() { while (true){ // 生产行为 synchronized (productBuffer){ // 如果某一个生产者能执行进来,说明此线程具有productBuffer对象的控制权,其它线程(生产者&消费者)都必须等待 if(productBuffer.size()==bufferCapacity){ // 缓冲区满了 try { productBuffer.wait(1); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); // 唤醒等待队列中所有线程 } } // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 public Consumer(int bufferCapacity,List<Object> productBuffer){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; } @Override public void run(){ while (true){//消费行为 synchronized (productBuffer){ if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { productBuffer.wait(1); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); productBuffer.notifyAll(); } } // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer).start(); } } }5.2 可重入锁ReentrantLock (配合Condition)方式package ProducerAndConsumer; import java.util.ArrayList; import java.util.List; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.ReentrantLock; class Produce extends Thread { List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Produce(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run() { while (true) { // 生产行为 lock.lock(); //加锁 if (productBuffer.size() == bufferCapacity) { // 缓冲区满了 try { producerCondition.await(); // 释放控制权并等待 } catch (InterruptedException e) { e.printStackTrace(); } } else { // 缓冲区没满可以继续生产 productBuffer.add(new Object()); System.out.println("生产者生产了1件物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); consumerCondition.signal(); // 唤醒消费者线程 } lock.unlock(); //解锁 // 模拟生产缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer extends Thread{ List<Object> productBuffer; // 产品缓冲区 int bufferCapacity; // 缓冲区容量 ReentrantLock lock; // 可重入锁 Condition producerCondition; // 生产者condition Condition consumerCondition; // 消费者condition public Consumer(int bufferCapacity,List<Object> productBuffer,ReentrantLock lock,Condition producerCondition,Condition consumerCondition){ this.productBuffer = productBuffer; this.bufferCapacity = bufferCapacity; this.lock = lock; this.producerCondition = producerCondition; this.consumerCondition = consumerCondition; } @Override public void run(){ while (true){//消费行为 lock.lock();//加锁 if(productBuffer.isEmpty()){ //产品缓冲区为空,不能消费,只能等待 try { consumerCondition.await(); } catch (InterruptedException e) { e.printStackTrace(); } }else { // 缓冲区没空可以继续消费 productBuffer.remove(0); System.out.println("消费者消费了1个物品,当前缓冲区里还有" + productBuffer.size() + "件物品"); producerCondition.signal(); // 唤醒生产者线程继续生产 } lock.unlock(); //解锁 // 模拟消费缓冲时间 try { Thread.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } } } } public class ProducerAndConsumer { public static void main(String[] args) { List<Object> productBuffer = new ArrayList<>(); // 产品缓冲区 int bufferCapacity = 3; // 缓冲区容量 ReentrantLock lock = new ReentrantLock(); // 可重入锁 Condition producerCondition = lock.newCondition(); // 生产者condition Condition consumerCondition = lock.newCondition(); // 消费者condition for (int i = 0; i < 3; i++) { new Produce(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } for (int i = 0; i < 3; i++) { new Consumer(bufferCapacity,productBuffer,lock,producerCondition,consumerCondition).start(); } } }参考资料PV操作-生产者/消费者关系Java 学习笔记 使用synchronized实现生产者消费者模式 经典面试题 -- 手写生产者消费者模式
-
java实现大数的十六进制转八进制 1.问题描述问题描述 给定n个十六进制正整数,输出它们对应的八进制数。输入格式 输入的第一行为一个正整数n (1<=n<=10)。 接下来n行,每行一个由0-9、大写字母A-F组成的字符串,表示要转换的十六进制正整数,每个十六进制数长度不超过100000。输出格式 输出n行,每行为输入对应的八进制正整数。注意 输入的十六进制数不会有前导0,比如012A。 输出的八进制数也不能有前导0。样例输入 2 39 123ABC样例输出 71 4435274提示 先将十六进制数转换成某进制数,再由某进制数转换成八进制。2.代码实现import java.util.Scanner; public class Main { //16进制转2进制 public static String hex2Bin(String hex){ StringBuilder sb = new StringBuilder(); char[] hex_chars = hex.toCharArray(); for(char item:hex_chars){ switch (item){ case '0':sb.append("0000");break; case '1':sb.append("0001");break; case '2':sb.append("0010");break; case '3':sb.append("0011");break; case '4':sb.append("0100");break; case '5':sb.append("0101");break; case '6':sb.append("0110");break; case '7':sb.append("0111");break; case '8':sb.append("1000");break; case '9':sb.append("1001");break; case 'A':sb.append("1010");break; case 'B':sb.append("1011");break; case 'C':sb.append("1100");break; case 'D':sb.append("1101");break; case 'E':sb.append("1110");break; case 'F':sb.append("1111");break; default:sb.append("ERROR");break; } } return sb.toString(); } //2进制转8进制 public static String bin2Otc(String bin){ StringBuilder sb = new StringBuilder(); //将字符串的长度补齐到3的整数倍 int binLength = bin.length(); if(binLength%3==1){ bin = "00"+bin; }else if(binLength%3==2){ bin = "0"+bin; } //每3位转换出一个8进制数 for(int i=0;i<bin.length()/3;i++){ String octItem = bin.substring(i*3,i*3+3); switch (octItem){ case "000":sb.append("0");break; case "001":sb.append("1");break; case "010":sb.append("2");break; case "011":sb.append("3");break; case "100":sb.append("4");break; case "101":sb.append("5");break; case "110":sb.append("6");break; case "111":sb.append("7");break; default:sb.append("ERROR");break; } } return sb.toString(); } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int num_count = scanner.nextInt(); String []nums = new String[num_count]; for(int i=0;i<num_count;i++){ nums[i] = scanner.next(); } for(int i=0;i<num_count;i++){ String bin = hex2Bin(nums[i]); String oct = bin2Otc(bin); if(oct.charAt(0)=='0'){ oct = oct.substring(1); } System.out.println(oct); } } }参考资料1.http://lx.lanqiao.cn/problem.page?gpid=T51
-
Nginx学习笔记 什么是Nginx?Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。2011年6月1日,nginx 1.0.4发布。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。在全球活跃的网站中有12.18%的使用比率,大约为2220万个网站。Nginx 是一个安装非常的简单、配置文件非常简洁(还能够支持perl语法)、Bug非常少的服务。Nginx 启动特别容易,并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够不间断服务的情况下进行软件版本的升级。Nginx代码完全用C语言从头写成。官方数据测试表明能够支持高达 50,000 个并发连接数的响应。Nginx作用?Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。正向代理反向代理Nginx提供的负载均衡策略有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。扩展策略,就天马行空,只有你想不到的没有他做不到的。轮询加权轮询iphash对客户端请求的ip进行hash操作,然后根据hash结果将同一个客户端ip的请求分发给同一台服务器进行处理,可以解决session不共享的问题。动静分离,在我们的软件开发中,有些请求是需要后台处理的,有些请求是不需要经过后台处理的(如:css、html、jpg、js等等文件),这些不需要经过后台处理的文件称为静态文件。让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作。提高资源响应的速度。目前,通过使用Nginx大大提高了我们网站的响应速度,优化了用户体验,让网站的健壮性更上一层楼!Nginx的安装windows下安装1、下载nginxhttp://nginx.org/en/download.html 下载稳定版本。以nginx/Windows-1.16.1为例,直接下载 nginx-1.16.1.zip。下载后解压,解压后如下:2、启动nginx有很多种方法启动nginx(1)直接双击nginx.exe,双击后一个黑色的弹窗一闪而过(2)打开cmd命令窗口,切换到nginx解压目录下,输入命令 nginx.exe ,回车即可3、检查nginx是否启动成功直接在浏览器地址栏输入网址 http://localhost:80 回车,出现以下页面说明启动成功!4、配置监听nginx的配置文件是conf目录下的nginx.conf,默认配置的nginx监听的端口为80,如果80端口被占用可以修改为未被占用的端口即可。当我们修改了nginx的配置文件nginx.conf 时,不需要关闭nginx后重新启动nginx,只需要执行命令 nginx -s reload 即可让改动生效5、关闭nginx如果使用cmd命令窗口启动nginx, 关闭cmd窗口是不能结束nginx进程的,可使用两种方法关闭nginx(1)输入nginx命令 nginx -s stop(快速停止nginx) 或 nginx -s quit(完整有序的停止nginx)(2)使用taskkill taskkill /f /t /im nginx.exetaskkill是用来终止进程的,/f是强制终止 ./t终止指定的进程和任何由此启动的子进程。/im示指定的进程名称 .linux下安装1、安装gcc安装 nginx 需要先将官网下载的源码进行编译,编译依赖 gcc 环境,如果没有 gcc 环境,则需要安装:yum install gcc-c++2、PCRE pcre-devel 安装PCRE(Perl Compatible Regular Expressions) 是一个Perl库,包括 perl 兼容的正则表达式库。nginx 的 http 模块使用 pcre 来解析正则表达式,所以需要在 linux 上安装 pcre 库,pcre-devel 是使用 pcre 开发的一个二次开发库。nginx也需要此库。命令:yum install -y pcre pcre-devel3、zlib 安装zlib 库提供了很多种压缩和解压缩的方式, nginx 使用 zlib 对 http 包的内容进行 gzip ,所以需要在 Centos 上安装 zlib 库。yum install -y zlib zlib-devel4、OpenSSL 安装OpenSSL 是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及 SSL 协议,并提供丰富的应用程序供测试或其它目的使用。nginx 不仅支持 http 协议,还支持 https(即在ssl协议上传输http),所以需要在 Centos 安装 OpenSSL 库。yum install -y openssl openssl-devel5、下载安装包手动下载.tar.gz安装包,地址:https://nginx.org/en/download.html下载完毕上传到服务器上 /root6、解压tar -zxvf nginx-1.18.0.tar.gzcd nginx-1.18.07、配置使用默认配置,在nginx根目录下执行./configure make make install查找安装路径: whereis nginxNginx常用命令cd /usr/local/nginx/sbin/ ./nginx 启动 ./nginx -s stop 停止 ./nginx -s quit 安全退出 ./nginx -s reload 重新加载配置文件 ps aux|grep nginx 查看nginx进程启动成功访问 服务器ip:80注意:如何连接不上,检查阿里云安全组是否开放端口,或者服务器防火墙是否开放端口!相关命令:# 开启 service firewalld start # 重启 service firewalld restart # 关闭 service firewalld stop # 查看防火墙规则 firewall-cmd --list-all # 查询端口是否开放 firewall-cmd --query-port=8080/tcp # 开放80端口 firewall-cmd --permanent --add-port=80/tcp # 移除端口 firewall-cmd --permanent --remove-port=8080/tcp #重启防火墙(修改配置后要重启防火墙) firewall-cmd --reload # 参数解释 1、firwall-cmd:是Linux提供的操作firewall的一个工具; 2、--permanent:表示设置为持久; 3、--add-port:标识添加的端口;参考资料狂神说-Nginx最新教程通俗易懂,40分钟搞定
-
Maven基础学习笔记 Maven基础学习笔记1. Maven简介1.1 Maven是什么Maven的本质是一个项目管理工具,将项目开发过程抽象成一个项目的对象模型(POM)POM(Project Object Model):项目对象模型1.2 Maven的作用项目构建:提供标准的、跨平台的自动化项目构建方式依赖管理:方便快捷的管理项目依赖的资源(jar包),避免资源间版本冲突问题统一开发结构:提供标准的、统一的项目结构2.下载与安装2.1 Maven下载官网:https://maven.apache.org/下载地址:https://maven.apache.org/download.cgi2.2 Maven安装Maven 属于绿色版软件,解压即安装2.3 Maven环境变量配置依赖java,需要配置JAVA_HOME设置Maven自身的环境变量,需要配置MAVEN_HOME并在Path下添加%MAVEN_HOME%\bin测试配置结果mvn3. Maven基础概念3.1 仓库仓库:用于存储资源,包含各种jar包仓库分类:本地仓库:自己电脑上存储资源的仓库,连接远程仓库获取资源远程仓库:非本机电脑的仓库,为本地仓库提供资源中央仓库:Maven团队维护,存储所有资源的仓库私服: 部门/公司范围内存储资源的仓库,从中央仓库获取资源私服的作用:保存具有版权的资源,包含购买或自主研发的jar包中央仓库的jar都是开源的,不能存储具有版权的资源一定范围内共享资源,仅对内部开放,不对外共享3.2 坐标什么是坐标?maven中的坐标用于描述资源的位置https://repo1.maven.org/maven2/Maven坐标组成groupId:定义当前Maven项目隶属于组织名称(通常是域名反写,例如:org.mybatis)artifactld:定义当前Maven项目名称(通常是模块名称,例如CRM\SMS)version:定义当前项目版本号packing:定义项目的打包方式示例:来自https://mvnrepository.com/<!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> <scope>test</scope> </dependency>Maven坐标的作用使用唯一标识,唯一性定位资源位置,通过该标识可以将资源的识别与下载工作交给机器(maven工具)来完成4.仓库配置4.1 本地仓库配置修改本地仓库的位置默认位置:${user.home}/.m2/repository自定义位置1.新建好本地文件夹2.修改%MAVEN_HOME%/conf/bin/settings.xml<!-- localRepository | The path to the local repository maven will use to store artifacts. | | Default: ${user.home}/.m2/repository <localRepository>/path/to/local/repo</localRepository> --> # 在下方添加如下内容 <localRepository>/path/to/local/repo</localRepository>4.2 远程仓库配置镜像在setting文件中配置阿里云镜像仓库修改%MAVEN_HOME%/conf/bin/settings.xml<mirrors> # 在这里面添加 <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>https://maven.aliyun.com/repository/public</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors>5. 第一个Maven项目(手工制作)5.1 Maven工程目录结构在src同层目录下创建pom.xml文件<!-- 属性 --> <properties> <spring.version>4.2.4.RELEASE</spring.version> <hibernate.version>5.0.7.Final</hibernate.version> <struts.version>2.3.24</struts.version> </properties> <!-- 锁定版本,struts2-2.3.24、spring4.2.4、hibernate5.0.7 --> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aspects</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>${hibernate.version}</version> </dependency> <dependency> <groupId>org.apache.struts</groupId> <artifactId>struts2-core</artifactId> <version>${struts.version}</version> </dependency> <dependency> <groupId>org.apache.struts</groupId> <artifactId>struts2-spring-plugin</artifactId> <version>${struts.version}</version> </dependency> </dependencies> </dependencyManagement> <!-- 依赖管理 --> <dependencies> <!-- spring --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aspects</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> </dependency> <!-- hibernate --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> </dependency> <!-- 数据库驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.6</version> <scope>runtime</scope> </dependency> <!-- c3p0 --> <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> <!-- 导入 struts2 --> <dependency> <groupId>org.apache.struts</groupId> <artifactId>struts2-core</artifactId> </dependency> <dependency> <groupId>org.apache.struts</groupId> <artifactId>struts2-spring-plugin</artifactId> </dependency> <!-- servlet jsp --> <dependency> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> <version>2.5</version> <scope>provided</scope> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>jsp-api</artifactId> <version>2.0</version> <scope>provided</scope> </dependency> <!-- 日志 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.2</version> </dependency> <!-- junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.9</version> <scope>test</scope> </dependency> <!-- jstl --> <dependency> <groupId>javax.servlet</groupId> <artifactId>jstl</artifactId> <version>1.2</version> </dependency> </dependencies> <build> <plugins> <!-- 设置编译版本为1.7 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.7</source> <target>1.7</target> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- maven内置 的tomcat6插件 --> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>tomcat-maven-plugin</artifactId> <version>1.1</version> <configuration> <!-- 可以灵活配置工程路径 --> <path>/Hello</path> <!-- 可以灵活配置端口号 --> <port>8080</port> </configuration> </plugin> </plugins> </build>5.2 Maven项目构建命令Maven构建命令使用mvn开头,后面添加功能参数,可以一次执行多个命令,使用空格分隔mvn compile #编译 mvn clean #清理 mvn test #测试 mvn package #打包 mvn install #安装到本地仓库手动执行的话在pom.xml文件目录下执行6.第一个Maven项目(IDEA生成)https://www.bilibili.com/video/BV1Ah411S7ZE?p=9&spm_id_from=pageDriverjava项目web项目7.依赖管理7.1 添加依赖在pom.xml文件里的<dependencies></dependencies>中添加<dependency></dependency>7.2 依赖传递依赖具有传递性直接依赖:在当前项目中通过依赖配置建立的依赖关系间接依赖:被资源的资源如果依赖其他资源,当前项目间接依赖其他资源7.3 依赖传递冲突问题路径优先:当依赖中出现相同资源时,层级越深,优先级越低,层级越浅,优先级越高声明优先:当资源在相同层级被依赖时,配置顺序靠前的覆盖顺序靠后的特殊优先:当同级配置了相同资源的不同版本,后配置的覆盖先配置的(在同一个pom.xml文件中进行配置)7.4 可选依赖与排除依赖可选依赖控制资源不被调用者看到具体的依赖情况排除依赖指主动断开依赖的资源,被排除的资源无需要指定具体的版本--不需要7.5 依赖范围依赖的jar默认情况可以在任何地方使用,可以通过scope标签设定其作用范围作用范围主程序范围内有效(main文件夹范围内)测试程序范围有效(test文件夹范围内)是否参与打包(package指令范围内)依赖范围传递性(了解即可)带有依赖范围的资源在进行传递时,作用范围将受到影响8.生命周期与插件8.1 项目构建生命周期maven构建生命周期描述的是一次构建过程经历了多少个事件maven对项目构建的生命周期划分为3套clean:清理工作default:核心工作,例如编译、测试、打包、部署等site:产生报告,发布站点等8.2 插件插件与生命周期内的阶段绑定,在执行到对应生命周期时执行对应的插件功能默认maven在各个生命周期上绑定有预设的功能通过插件可以自定义其他功能参考资料黑马程序员Maven全套教程,maven项目管理从基础到高级
-
MySQL学习:SQL查询语句中select、 from、 where、 group by 、having、 order by的执行顺序 1. 字段解释from:需要从哪个数据表检索数据where:过滤表中数据的条件group by:如何将上面过滤出的数据分组having:对上面已经分组的数据进行过滤的条件select:查看结果集中的哪个列,或列的计算结果order by:按照什么样的顺序来查看返回的数据2.书写顺序与执行顺序书写顺序依次为:select>from>where>group by>having>order by # 其中select和from是必须的。执行顺序依次为:from>where>group by>having>select>order byfrom后面的表关联,是自右向左解析的;而where条件的解析顺序是从左往右的。也就是说,在写SQL语句的时候,尽量把数据量小的表放在最右边来进行关联(用小表去匹配大表),而把能筛选出小量数据的条件放在where语句的最左边 (用小表去匹配大表)。参考资料sql语句中select、 from、 where、 group by 、having、 order by的执行顺序分析SQL查询语句中select from where group by having order by的执行顺序
-
java学习:字符串的格式化及日期时间格式化 1. 常规类型格式化为字符串1.1 转换符转 换 符说 明示 例%s字符串类型"mingrisoft"%c字符类型'm'%b布尔类型true%d整数类型(十进制)99%x整数类型(十六进制)FF%o整数类型(八进制)77%f浮点类型99.99%a十六进制浮点类型FF.35AE%e指数类型9.38e+5%g通用浮点类型(f和e类型中较短的) %h散列码 %%百分比类型%%n换行符 %tx日期与时间类型(x代表不同的日期与时间转换符 1.2.使用案例public static void main(String[] args) { String str=null; str=String.format("Hi,%s", "王力"); System.out.println(str); str=String.format("Hi,%s:%s.%s", "王南","王力","王张"); System.out.println(str); System.out.printf("字母a的大写是:%c %n", 'A'); System.out.printf("3>7的结果是:%b %n", 3>7); System.out.printf("100的一半是:%d %n", 100/2); System.out.printf("100的16进制数是:%x %n", 100); System.out.printf("100的8进制数是:%o %n", 100); System.out.printf("50元的书打8.5折扣是:%f 元%n", 50*0.85); System.out.printf("上面价格的16进制数是:%a %n", 50*0.85); System.out.printf("上面价格的指数表示:%e %n", 50*0.85); System.out.printf("上面价格的指数和浮点数结果的长度较短的是:%g %n", 50*0.85); System.out.printf("上面的折扣是%d%% %n", 85); System.out.printf("字母A的散列码是:%h %n", 'A'); }输出结果Hi,王力 Hi,王南:王力.王张 字母a的大写是:A 3>7的结果是:false 100的一半是:50 100的16进制数是:64 100的8进制数是:144 50元的书打8.5折扣是:42.500000 元 上面价格的16进制数是:0x1.54p5 上面价格的指数表示:4.250000e+01 上面价格的指数和浮点数结果的长度较短的是:42.5000 上面的折扣是85% 字母A的散列码是:411.3 搭配的标志标 志说 明示 例结 果+为正数或者负数添加符号("%+d",15)+15−左对齐("%-5d",15)\15 \ 0数字前面补0("%04d", 99)0099空格在整数之前添加指定数量的空格("% 4d", 99)\99\ ,以“,”对数字分组("%,f", 9999.99)9,999.990000(使用括号包含负数("%(f", -99.99)(99.990000)#如果是浮点数则包含小数点,如果是16进制或8进制则添加0x或0("%#x", 99)("%#o", 99)0x63 0143<格式化前一个转换符所描述的参数("%f和%<3.2f", 99.45)99.450000和99.45$被格式化的参数索引("%1$d,%2$s", 99,"abc")99,abc1.4.使用案例public static void main(String[] args) { String str=null; //$使用 str=String.format("格式参数$的使用:%1$d,%2$s", 99,"abc"); System.out.println(str); //+使用 System.out.printf("显示正负数的符号:%+d与%d%n", 99,-99); //补O使用 System.out.printf("最牛的编号是:%03d%n", 7); //空格使用 System.out.printf("Tab键的效果是:% 8d%n", 7); //,使用 System.out.printf("整数分组的效果是:%,d%n", 9989997); //空格和小数点后面个数 System.out.printf("一本书的价格是:% 50.5f元%n", 49.8); }输出结果格式参数$的使用:99,abc 显示正负数的符号:+99与-99 最牛的编号是:007 Tab键的效果是: 7 整数分组的效果是:9,989,997 一本书的价格是: 49.80000元 2. 日期格式化2.1 转换符转 换 符说 明示 例%tx日期与时间类型(x代表不同的日期与时间转换符 c包括全部日期和时间信息星期六 十月 27 14:21:20 CST 2007F“年-月-日”格式2007-10-27D“月/日/年”格式10/27/07r“HH:MM:SS PM”格式(12时制)02:25:51 下午T“HH:MM:SS”格式(24时制)14:28:16R“HH:MM”格式(24时制)14:282.2 使用案例public static void main(String[] args) { Date date=new Date(); //c的使用 System.out.printf("全部日期和时间信息:%tc%n",date); //f的使用 System.out.printf("年-月-日格式:%tF%n",date); //d的使用 System.out.printf("月/日/年格式:%tD%n",date); //r的使用 System.out.printf("HH:MM:SS PM格式(12时制):%tr%n",date); //t的使用 System.out.printf("HH:MM:SS格式(24时制):%tT%n",date); //R的使用 System.out.printf("HH:MM格式(24时制):%tR",date); }输出结果全部日期和时间信息:星期一 九月 10 10:43:36 CST 2012 年-月-日格式:2012-09-10 月/日/年格式:09/10/12 HH:MM:SS PM格式(12时制):10:43:36 上午 HH:MM:SS格式(24时制):10:43:36 HH:MM格式(24时制):10:43public static void main(String[] args) { Date date=new Date(); //b的使用,月份简称 String str=String.format(Locale.US,"英文月份简称:%tb",date); System.out.println(str); System.out.printf("本地月份简称:%tb%n",date); //B的使用,月份全称 str=String.format(Locale.US,"英文月份全称:%tB",date); System.out.println(str); System.out.printf("本地月份全称:%tB%n",date); //a的使用,星期简称 str=String.format(Locale.US,"英文星期的简称:%ta",date); System.out.println(str); //A的使用,星期全称 System.out.printf("本地星期的简称:%tA%n",date); //C的使用,年前两位 System.out.printf("年的前两位数字(不足两位前面补0):%tC%n",date); //y的使用,年后两位 System.out.printf("年的后两位数字(不足两位前面补0):%ty%n",date); //j的使用,一年的天数 System.out.printf("一年中的天数(即年的第几天):%tj%n",date); //m的使用,月份 System.out.printf("两位数字的月份(不足两位前面补0):%tm%n",date); //d的使用,日(二位,不够补零) System.out.printf("两位数字的日(不足两位前面补0):%td%n",date); //e的使用,日(一位不补零) System.out.printf("月份的日(前面不补0):%te",date); }输出结果英文月份简称:Sep 本地月份简称:九月 英文月份全称:September 本地月份全称:九月 英文星期的简称:Mon 本地星期的简称:星期一 年的前两位数字(不足两位前面补0):20 年的后两位数字(不足两位前面补0):12 一年中的天数(即年的第几天):254 两位数字的月份(不足两位前面补0):09 两位数字的日(不足两位前面补0):10 月份的日(前面不补0):103.时间格式化3.1 转换符转 换 符说 明示 例H2位数字24时制的小时(不足2位前面补0)15I2位数字12时制的小时(不足2位前面补0)03k2位数字24时制的小时(前面不补0)15l2位数字12时制的小时(前面不补0)3M2位数字的分钟(不足2位前面补0)03S2位数字的秒(不足2位前面补0)09L3位数字的毫秒(不足3位前面补0)015N9位数字的毫秒数(不足9位前面补0)562000000p小写字母的上午或下午标记中:下午英:pmz相对于GMT的RFC822时区的偏移量+0800Z时区缩写字符串CSTs1970-1-1 00:00:00 到现在所经过的秒数1193468128Q1970-1-1 00:00:00 到现在所经过的毫秒数11934681289843.2 使用案例public static void main(String[] args) { Date date = new Date(); //H的使用 System.out.printf("2位数字24时制的小时(不足2位前面补0):%tH%n", date); //I的使用 System.out.printf("2位数字12时制的小时(不足2位前面补0):%tI%n", date); //k的使用 System.out.printf("2位数字24时制的小时(前面不补0):%tk%n", date); //l的使用 System.out.printf("2位数字12时制的小时(前面不补0):%tl%n", date); //M的使用 System.out.printf("2位数字的分钟(不足2位前面补0):%tM%n", date); //S的使用 System.out.printf("2位数字的秒(不足2位前面补0):%tS%n", date); //L的使用 System.out.printf("3位数字的毫秒(不足3位前面补0):%tL%n", date); //N的使用 System.out.printf("9位数字的毫秒数(不足9位前面补0):%tN%n", date); //p的使用 String str = String.format(Locale.US, "小写字母的上午或下午标记(英):%tp", date); System.out.println(str); System.out.printf("小写字母的上午或下午标记(中):%tp%n", date); //z的使用 System.out.printf("相对于GMT的RFC822时区的偏移量:%tz%n", date); //Z的使用 System.out.printf("时区缩写字符串:%tZ%n", date); //s的使用 System.out.printf("1970-1-1 00:00:00 到现在所经过的秒数:%ts%n", date); //Q的使用 System.out.printf("1970-1-1 00:00:00 到现在所经过的毫秒数:%tQ%n", date); }输出结果2位数字24时制的小时(不足2位前面补0):11 2位数字12时制的小时(不足2位前面补0):11 2位数字24时制的小时(前面不补0):11 2位数字12时制的小时(前面不补0):11 2位数字的分钟(不足2位前面补0):03 2位数字的秒(不足2位前面补0):52 3位数字的毫秒(不足3位前面补0):773 9位数字的毫秒数(不足9位前面补0):773000000 小写字母的上午或下午标记(英):am 小写字母的上午或下午标记(中):上午 相对于GMT的RFC822时区的偏移量:+0800 时区缩写字符串:CST 1970-1-1 00:00:00 到现在所经过的秒数:1347246232 1970-1-1 00:00:00 到现在所经过的毫秒数:1347246232773参考资料Java 字符串格式化详解JAVA字符串格式化-String.format()的使用java字符串格式化(String类format方法)
-
nginx学习:nginx的请求转发算法(负载均衡配置) 1.nginx支持的负载均衡调度算法1.1 轮询(默认算法):每个请求按时间顺序分配到不同后端服务器,如果某个后端服务器宕机,能自动剔除掉。基于iphttp { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { server 192.168.0.161; server 192.168.0.162; server 192.168.0.163; } server { listen 80; location / { proxy_pass http://myweb1; } } }基于域名http { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { server 192.168.0.161; server 192.168.0.162; server 192.168.0.163; } server { listen 80; server_name www.sc.com; location / { proxy_pass http://myweb1; } } }1.2 weight轮询nginx反向代理接受到客户端收到的请求后,可以给不同的后端服务器设置一个权重值(weight),用于调整不同服务器上请求的分配率,权重数据越大,被分配到请求的几率越大;该权重值,主要是针对实际工作环境中不同的后端服务器配置进行配置的。比如说有些服务器的硬件配置高,比重就会比较大一点。http { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { server 192.168.0.161 weight=1; server 192.168.0.162 weight=3; server 192.168.0.163 weight=6; } server { listen 80; server_name www.sc.com; location / { proxy_pass http://myweb1; } } }1.3 ip_hash每个请求按照发起客户端ip的hash结果进行匹配,这样的算法每一个固定的ip地址的客户端总会访问到同一个后端服务器,这也在一定程度上解决了集群部署环境下session共享的问题。http { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { ip_hash; server 192.168.0.161; server 192.168.0.162; server 192.168.0.163; } server { listen 80; server_name www.sc.com; location / { proxy_pass http://myweb1; } } }1.4 least-connected–最小连接数将下一个请求分配给活动连接数量最少的服务器http { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { least_conn; server 192.168.0.161; server 192.168.0.162; server 192.168.0.163; } server { listen 80; server_name www.sc.com; location / { proxy_pass http://myweb1; } } }1.5 fair:智能调整调度算法(第三方)动态的根据后端服务器的请求处理器的请求处理响应的时间来进行均衡分配,响应时间短,处理效率高的服务器分配到请求的概率高,响应时间长,处理效率低的服务器分配到的请求少;结合了前两者的优点的一种调度算法。但是需要注意的是nginx默认不支持fair算法,如果要使用这种算法,需要安装upstream_fair模块。1.6 url_hash(第三方)按照访问的url的hash结果分配请求,每个请求的url会指向后端固定的某个服务器,可以在nginx作为静态服务器的情况下提高缓存效率。同样要注意Nginx默认不支持这种调度算法,要使用的话需要安装nginx的hash软件包。http { ..... 其他的内容 #定义上游服务器集群,定义一个负载均衡器 upstream myweb1 { server 192.168.0.161; server 192.168.0.162; server 192.168.0.163; hash $request_uri; } server { listen 80; server_name www.sc.com; location / { proxy_pass http://myweb1; } } }在upstream模块中,可以通过server命令指定后端服务器的IP地址和端口,同时还可以设置每台后端服务器在负载均衡调度中的状态,常用的状态有以下几种:1、down:表示当前server暂时不参与负载均衡。2、backup:预留的备份机,当其他所有非backup机器出现故障或者繁忙的时候,才会请求backup机器,这台机器的访问压力最轻。3、max_fails:允许请求的失败次数,默认为1,配合fail_timeout一起使用4、fail_timeout:经历max_fails次失败后,暂停服务的时间,默认为10s(某个server连接失败了max_fails次,则nginx会认为该server不工作了。同时,在接下来的 fail_timeout时间内,nginx不再将请求分发给失效的server。)参考资料你知道nginx的请求转发算法,如何配置根据权重转发3. nginx的请求转发算法,如何配置根据权重转发Nginx负载均衡调度算法及配置案例Nginx几种负载均衡算法及配置实例Nginx配置之实现多台服务器负载均衡
-
java学习:Junit4单元测试的基本用法及注解和执行顺序 1. Junit最简单的用法案例新建一个类被测试类,里面包含一些测试方法package junit.util; /** * 被测试类,通过Junit对此类的方法进行单元测试 */ public class Claculate { public int add(int a, int b) { return a + b; } public int subtract(int a, int b) { return a - b; } public int multiply(int a, int b) { return a * b; } public int divide(int a, int b) { return a / b; } }新建一个Junit的测试类用来测试上面的测试方法,新增Junit的测试类方法如下:package junit.util; import static org.junit.Assert.*; import junit.util.Claculate; import org.junit.Test; /** * junit的测试方法必须使用@Test注解 * 测试方法必须以public void修饰,并且不包含参数 */ public class ClaculateTest { @Test public void testAdd() { /** * assertEquals这个方法是一个断言方法 * 第一个参数表示预期的结果 * 第二个参数表示程序的执行结果 * 当预期结果与执行结果是一致的时候,则表示单元测试成功 */ assertEquals(4, new Claculate().add(1, 3)); } @Test public void testSubtract() { assertEquals(4, new Claculate().subtract(9, 5)); } @Test public void testMultiply() { assertEquals(6, new Claculate().multiply(2, 3)); } @Test(expected=ArithmeticException.class) public void testDivide() { assertEquals(3, new Claculate().divide(9, 0)); } }上面的这个测试类,分别对被测试类Claculate的四个方法进行了测试,测试是选择使用Junit方式进行执行,如果想要执行单个测试方法,可以选择单个方法进行执行2.junit中的常用注解及执行顺序2.1 常用注解为什么引入注解?在实际项目中,进行JUnit测试时,通常会涉及到一些初始化的东西,可能有些配置项需要在测试前进行加载的,JUnit提供了一些初始化的方法用于初始化注解名作用@Before初始化方法,对于每一个测试方法都要执行一次(注意与BeforeClass区别,后者是对于所有方法执行一次)@After释放资源,对于每一个测试方法都要执行一次(注意与AfterClass区别,后者是对于所有方法执行一次)@Test测试方法,在这里可以测试期望异常和超时时间@Ignore忽略的测试方法@BeforeClass针对所有测试,只执行一次,且必须为static void@AfterClass针对所有测试,只执行一次,且必须为static void2.2 执行顺序一个JUnit4的单元测试用例执行顺序为:@BeforeClass -> @Before -> @Test -> @After -> @AfterClass; 每一个测试方法的调用顺序为:@Before -> @Test -> @After; 参考资料junit用法,before,beforeClass,after, afterClass的执行顺序Junit4单元测试的基本用法 Junit的基本使用(详解)
-
[转载]:Java 相关一些面试题 junit 用法,before,beforeClass,after, afterClass 的执行顺序分布式锁nginx 的请求转发算法,如何配置根据权重转发用 hashmap 实现 redis 有什么问题(死锁,死循环,可用 ConcurrentHashmap)线程的状态线程的阻塞的方式sleep 和 wait 的区别hashmap 的底层实现一万个人抢 100 个红包,如何实现(不用队列),如何保证 2 个人不能抢到同一个红包,可用分布式锁java 内存模型,垃圾回收机制,不可达算法两个 Integer 的引用对象传给一个 swap 方法在方法内部交换引用,返回后,两个引用的值是否会发现变化aop 的底层实现,动态代理是如何动态,假如有 100 个对象,如何动态的为这 100 个对象代理是否用过 maven install。 maven test。git(make install 是安装本地 jar 包)tomcat 的各种配置,如何配置 docBasespring 的 bean 配置的几种方式web.xml 的配置spring 的监听器。zookeeper 的实现机制,有缓存,如何存储注册服务的IO 会阻塞吗?readLine 是不是阻塞的用过 spring 的线程池还是 java 的线程池?字符串的格式化方法 (20,21 这两个问题问的太低级了)时间的格式化方法定时器用什么做的线程如何退出结束java 有哪些锁?乐观锁 悲观锁 synchronized 可重入锁 读写锁,用过 reentrantlock 吗?reentrantlock 与 synmchronized 的区别ThreadLocal 的使用场景java 的内存模型,垃圾回收机制为什么线程执行要调用 start 而不是直接 run(直接 run,跟普通方法没什么区别,先调 start,run 才会作为一个线程方法运行)qmq 消息的实现机制 (qmq 是去哪儿网自己封装的消息队列)遍历 hashmap 的三种方式jvm 的一些命令memcache 和 redis 的区别mysql 的行级锁加在哪个位置ConcurrentHashmap 的锁是如何加的?是不是分段越多越好myisam 和 innodb 的区别(innodb 是行级锁,myisam 是表级锁)mysql 其他的性能优化方式linux 系统日志在哪里看如何查看网络进程统计一个整数的二进制表示中 bit 为 1 的个数jvm 内存模型,java 内存模型如何把 java 内存的数据全部 dump 出来如何手动触发全量回收垃圾,如何立即触发垃圾回收hashmap 如果只有一个写其他全读会出什么问题git rebasemongodb 和 hbase 的区别如何解决并发问题volatile 的用途java 线程池(好像之前我的理解有问题)mysql 的 binlog代理模式mysql 是如何实现事务的读写分离何时强制要读主库,读哪个从库是通过什么方式决定的,从库的同步 mysql 用的什么方式mysql 的存储引擎mysql 的默认隔离级别,其他隔离级别将一个链表反转(用三个指针,但是每次只发转一个)spring Aop 的实现原理,具体说说何时会内存泄漏,内存泄漏会抛哪些异常是否用过 Autowire 注解spring 的注入 bean 的方式sql 语句各种条件的执行顺序,如 select, where, order by, group byselect xx from xx where xx and xx order by xx limit xx; 如何优化这个(看 explain)四则元算写代码统计 100G 的 ip 文件中出现 ip 次数最多的 100 个 ipzookeeper 的事物,结点,服务提供方挂了如何告知消费方5 台服务器如何选出 leader (选举算法)适配器和代理模式的区别读写锁static 加锁事务隔离级别门面模式,类图 (外观模式)mybatis 如何映射表结构二叉树遍历主从复制mysql 引擎区别静态内部类加载到了哪个区?方法区class 文件编译后加载到了哪web 的 http 请求如何整体响应时间变长导致处理的请求数变少,该如何处理?用队列,当处理不了那么多 http 请求时将请求放到队列中慢慢处理,web 如何实现队列线程安全的单例模式快速排序性能考虑volatile 关键字用法求表的 size,或做数据统计可用什么存储引擎读多写少可用什么引擎假如要统计多个表应该用什么引擎concurrenhashmap 求 size 是如何加锁的,如果刚求完一段后这段发生了变化该如何处理1000 个苹果放 10 个篮子,怎么放,能让我拿到所有可能的个数可重入的读写锁,可重入是如何实现的?是否用过 NIOjava 的 concurrent 包用过没sting s=new string (“abc”) 分别在堆栈上新建了哪些对象java 虚拟机的区域分配,各区分别存什么分布式事务(JTA)threadlocal 使用时注意的问题(ThreadLocal 和 Synchonized 都用于解决多线程并发访问。但是 ThreadLocal 与 synchronized 有本质的区别。synchronized 是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而 ThreadLocal 为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而 Synchronized 却正好相反,它用于在多个线程间通信时能够获得数据共享)java 有哪些容器 (集合,tomcat 也是一种容器)二分查找算法myisam 的优点,和 innodb 的区别redis 能存哪些类型http 协议格式,get 和 post 的区别可重入锁中对应的 wait 和 notifyredis 能把内存空间交换进磁盘中吗 (这个应该是可以的,但是那个面试官非跟我说不可以)java 线程池中基于缓存和基于定长的两种线程池,当请求太多时分别是如何处理的?定长的事用的队列,如果队列也满了呢?交换进磁盘?基于缓存的线程池解决方法呢?synchronized 加在方法上用的什么锁可重入锁中的 lock 和 trylock 的区别innodb 对一行数据的读会枷锁吗?不枷锁,读实际读的是副本redis 做缓存是分布式存的?不同的服务器上存的数据是否重复?guavacache 呢?是否重复?不同的机器存的数据不同用 awk 统计一个 ip 文件中 top10对表做统计时可直接看 schema info 信息,即查看表的系统信息mysql 目前用的版本公司经验丰富的人给了什么帮助?(一般 boss 面会问这些)自己相对于一样的应届生有什么优势自己的好的总结习惯给自己今后的工作带了什么帮助,举例为证原子类,线程安全的对象,异常的处理方式4 亿个 int 数,如何找出重复的数(用 hash 方法,建一个 2 的 32 次方个 bit 的 hash 数组,每取一个 int 数,可 hash 下 2 的 32 次方找到它在 hash 数组中的位置,然后将 bit 置 1 表示已存在)4 亿个 url,找出其中重复的(考虑内存不够,通过 hash 算法,将 url 分配到 1000 个文件中,不同的文件间肯定就不会重复了,再分别找出重复的)有 1 万个数组,每个数组有 1000 个整数,每个数组都是降序的,从中找出最大的 N 个数,N<1000LinkedHashmap 的底层实现类序列化时类的版本号的用途,如果没有指定一个版本号,系统是怎么处理的?如果加了字段会怎么样?Override 和 Overload 的区别,分别用在什么场景java 的反射是如何实现的参考资料Java 相关一些面试题
-
MySQL学习:常用函数总结 1.数学函数针对数字-- ABS(x) 返回x的绝对值 SELECT ABS(-1); -- 返回1 -- ROUND(x)返回离 x 最近的整数 SELECT ROUND(1.23456); -- 返回1 -- CEIL(x)/CEILING(x) 返回大于或等于 x 的最小整数 SELECT CEIL(1.5); -- 返回2 SELECT CEILING(1.5); -- 返回2 -- FLOOR(x) 返回小于或等于 x 的最大整数 SELECT FLOOR(1.5); -- 返回1 -- POW(x,y)/POWER(x,y)返回 x 的 y 次方 SELECT POW(2,3); -- 返回8 SELECT POWER(2,3); -- 返回8 -- RAND()返回 0 到 1 的随机数 SELECT RAND(); -- SIGN(x)返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1 SELECT SIGN(-10); -- 返回-1 -- SQRT(x)返回x的平方根 SELECT SQRT(25); -- 返回5 -- TRUNCATE(x,y)返回数值 x 保留到小数点后 y 位的值,不会进行四舍五入 SELECT TRUNCATE(1.23456,3); -- 返回1.234针对字段-- AVG(expression) 返回一个表达式的平均值,expression 是一个字段 SELECT AVG(age) FROM student; -- MAX(expression)返回字段 expression 中的最大值 SELECT MAX(age) AS maxAge FROM Student; -- MIN(expression)返回字段 expression 中的最大值 SELECT MIN(age) AS minAge FROM Student; -- SUM(expression)返回指定字段的总和 SUM(expression)返回指定字段的总和2.字符串函数-- LENGTH/CHAR_LENGTH(s)/CHARACTER_LENGTH(s)返回字符串 s 的字符数 SELECT LENGTH('1234'); -- 返回4 -- CONCAT(s1,s2…sn)字符串 s1,s2 等多个字符串合并为一个字符串 SELECT CONCAT('hel','llo'); -- 返回hello -- LOCATE(s1,s)从字符串 s 中获取 s1 的开始位置 SELECT LOCATE('st','myteststring'); -- 返回5 -- LCASE(s)/LOWER(s)将字符串 s 的所有字母变成小写字母 SELECT LOWER('RUNOOB'); -- 返回runoob -- UCASE(s)/UPPER(s)将字符串 s 的所有字母变成大写字母 SELECT UCASE('runoob'); -- 返回RUNOOB -- TRIM(s)去掉字符串 s 开始和结尾处的空格 SELECT TRIM(' RUNOOB ');-- 返回RUNOOB -- SUBSTR/SUBSTRING(s, start, length)从字符串 s 的 start 位置截取长度为 length 的子字符串 SELECT SUBSTR/SUBSTRING("RUNOOB", 2, 3);-- 从字符串 RUNOOB 中的第 2 个位置截取 3个 字符,返回UNO -- REVERSE(s)将字符串s的顺序反过来 SELECT REVERSE('abc');-- 返回cba -- REPLACE()替换出现的指定字符串 SELECT REPLACE('狂神说坚持就能成功','坚持','努力'); -- 替换出现的指定字符串 SELECT REPIACE(studentname,'周','邹') FROM student WHERE studentname LIKE '%周';3.时间日期函数-- CURDATE()/CURRENT_DATE()返回当前日期 SELECT CURDATE();-- 返回2019-02-19 SELECT CURRENT_DATE(); -- 返回2019-02-19 -- CURRENT_TIME()/CURTIME()返回当前时间 SELECT CURRENT_TIME(); -- 返回11:40:45 -- NOW()返回当前日期和时间 SELECT NOW();-- 返回2019-02-19 11:41:32 SELECT LOCALTIME(); -- 本地时间 SELECT SYSDATE(); -- 系统时间 -- 提取年月日时分秒 SELECT YEAR(NOW()); SELECT MONTH(NOW()); SELECT DAY(NOW()); SELECT HOUR(NOW()); SELECT MINUTE(NOW()); SELECT SECOND(NOW());4.系统函数-- CURRENT_USER()/SESSION_USER()/SYSTEM_USER()/USER()返回当前用户 SELECT USER(); -- DATABASE()返回当前数据库名 SELECT DATABASE(); -- VERSION()返回数据库的版本号 SELECT VERSION();参考资料MySQL 5.7 参考手册12.6 数值函数和运算符12.8 字符串函数和运算符12.7 日期和时间函数MySQL常用函数大全(总结篇)
-
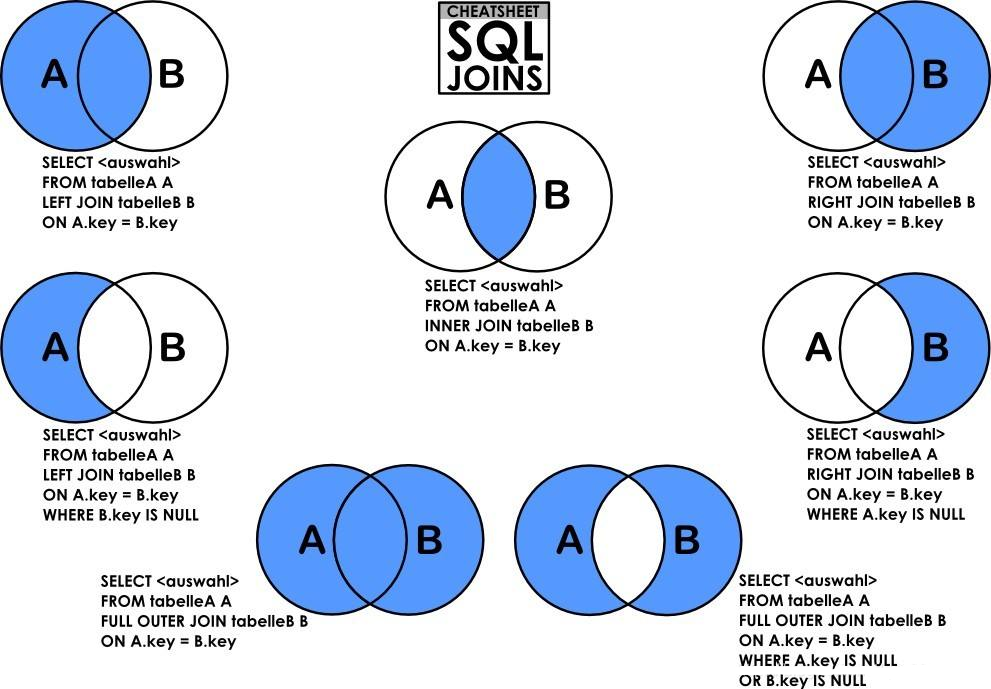
MySQL学习:SQL关联查询的七种JOIN 1.图示2.案例2.0 准备数据以一个简易问答系统为例,包括问题表和问题所属标签,问题表如下:CREATE TABLE `t_qa` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `title` varchar(200) NOT NULL DEFAULT '' COMMENT '标题', `answer_count` int(5) unsigned NOT NULL DEFAULT '0' COMMENT '回答个数', `label_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '标签id', `create_by` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '创建人', `create_date` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间', `update_by` bigint(20) unsigned DEFAULT NULL COMMENT '更新人', `update_date` datetime DEFAULT NULL COMMENT '更新时间', `del_flag` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '0:不删除,1:删除', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `t_qa` (`id`, `title`, `answer_count`, `label_id`, `create_by`, `create_date`, `update_by`, `update_date`, `del_flag`) VALUES (1, 'Java是什么?', 5, 1, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (2, 'PHP是什么?', 4, 2, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (3, '前端是什么?', 3, 3, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (4, 'nodejs是什么?', 2, 0, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (5, 'css是什么?', 1, 0, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (6, 'JavaScript是什么?', 0, 0, 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0);标签表如下:CREATE TABLE `t_label` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL DEFAULT '' COMMENT '名称', `create_by` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '创建人', `create_date` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间', `update_by` bigint(20) unsigned DEFAULT NULL COMMENT '更新人', `update_date` datetime DEFAULT NULL COMMENT '更新时间', `del_flag` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '0:不删除,1:删除', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `t_label` (`id`, `name`, `create_by`, `create_date`, `update_by`, `update_date`, `del_flag`) VALUES (1, 'java', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (2, 'php', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (3, '大前端', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (4, 'mybatis', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (5, 'python', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0), (6, '多线程', 0, '2017-08-24 17:43:53', 0, '2017-08-24 17:43:53', 0);2.1 左连接(LEFT JOIN)问题回答个数标签id标签名称Java是什么?51javaPHP是什么?42php前端是什么?33大前端nodejs是什么?2NULLNULLcss是什么?1NULLNULLJavaScript是什么?1NULLNULLSELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq LEFT JOIN t_label tl ON tq.label_id = tl.id2.2 右连接(RIGHT JOIN)问题回答个数标签id标签名称Java是什么?51javaPHP是什么?42php前端是什么?33大前端NULLNULL4mybatisNULLNULL5pythonNULLNULL6多线程SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq RIGHT JOIN t_label tl ON tq.label_id = tl.id2.3 内连接(INNER JOIN)问题回答个数标签id标签名称Java是什么?51javaPHP是什么?42php前端是什么?33大前端SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq INNER JOIN t_label tl ON tq.label_id = tl.id2.4 左独有连接(LEFT JOIN)问题回答个数标签id标签名称nodejs是什么?2NULLNULLcss是什么?1NULLNULLJavaScript是什么?0NULLNULLSELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq LEFT JOIN t_label tl ON tq.label_id = tl.id WHERE tl.id IS NULL2.5 右独有连接(RIGHT JOIN)问题回答个数标签id标签名称NULLNULL4mybatisNULLNULL5pythonNULLNULL6多线程SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq RIGHT JOIN t_label tl ON tq.label_id = tl.id WHERE tq.label_id IS NULL2.6 全连接(FULL JOIN)由于MySQL不支持FULL OUTER JOIN,所以如果有全连接需求时,可用表达式:full outer join = left outer join UNION right outer join来实现。问题回答个数标签id标签名称Java是什么?51javaPHP是什么?42php前端是什么?33大前端nodejs是什么?2NULLNULLcss是什么?1NULLNULLJavaScript是什么?0NULLNULLNULLNULL4mybatisNULLNULL5pythonNULLNULL6多线程SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq LEFT JOIN t_label tl ON tq.label_id = tl.id UNION SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq RIGHT JOIN t_label tl ON tq.label_id = tl.id 2.7 全连接去交集(FULL JOIN)问题回答个数标签id标签名称nodejs是什么?2NULLNULLcss是什么?1NULLNULLJavaScript是什么?0NULLNULLNULLNULL4mybatisNULLNULL5pythonNULLNULL6多线程SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq LEFT JOIN t_label tl ON tq.label_id = tl.id WHERE tl.id IS NULL UNION SELECT tq.title, tq.answer_count, tl.id, tl.name FROM t_qa tq RIGHT JOIN t_label tl ON tq.label_id = tl.id WHERE tq.label_id IS NULL参考资料一张图看懂 SQL 的各种 JOIN 用法SQL七种JOIN解析【MySQL笔记】七种JOIN的SQL
-
MySQL学习:MySQL常用命令 1.连接MySQL1.1 连接到本机上的MySQLmysql -u root -p # 如果刚安装好MySQL,root是没有密码的1.2 连接到远程主机上的MySQL假设远程主机的IP为:192.168.206.100,用户名为root,密码为12345678。mysql -h 192.168.206.100 -u root -p 12345678; 1.3 退出MySQLexit; # or quit;2. 修改root密码与简单权限管理2.1 修改root密码方法1: 用SET PASSWORD命令mysql -u root mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('newpass');方法2:用mysqladminmysqladmin -u root password "newpass" # 如果root已经设置过密码,采用如下方法 mysqladmin -u root password oldpass "newpass"方法3: 用UPDATE直接编辑user表mysql -u root mysql> use mysql; mysql> UPDATE user SET Password = PASSWORD('newpass') WHERE user = 'root'; mysql> FLUSH PRIVILEGES;方法4:在丢失root密码的时候mysqld_safe --skip-grant-tables& mysql -u root mysql mysql> UPDATE user SET password=PASSWORD("new password") WHERE user='root'; mysql> FLUSH PRIVILEGES;2.2 允许用户远程登录允许root使用密码admin123从任何主机连接到mysql服务器GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'admin123' WITH GRANT OPTION; -- 其中"*.*"代表所有资源所有权限, “'root'@%”其中root代表账户名,%代表所有的访问地址,也可以使用一个唯一的地址进行替换,只有一个地址能够访问。如果是某个网段的可以使用地址与%结合的方式,如10.0.42.%。IDENTIFIED BY 'root',这个root是指访问密码。WITH GRANT OPTION允许级联授权。 flush privileges; -- 刷新访问权限表允许用户root使用密码admin123从ip为192.168.12.16的主机连接到mysql服务器GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.1.16' IDENTIFIED BY 'admin123' WITH GRANT OPTION; flush privileges;3.库操作create database db_name; -- 创建数据库 show databases; -- 显示所有的数据库 drop database db_name; -- 删除数据库 use db_name; -- 使用数据库4.表操作建表与删表create table tb_name (字段名 varchar(20), 字段名 char(1)); -- 建表 show tables; -- 显示数据表 desc tb_name; -- 显示表结构 drop table tb_name; -- 删除表eg:-- 创建学生表 create table Student( Sno char(10) primary key, Sname char(20) unique, Ssex char(2), Sage smallint, Sdept char(20) );修改表结构-- 增加字段 alter table table_name add field_name field_type; -- 删除字段 alter table table_name drop field_name; -- 修改字段的注释 alter table `student` modify column `id` comment '学号'; -- 修改原字段名称及类型 alter table table_name change old_field_name new_field_name field_type; -- 加索引 alter table 表名 add index 索引名 (字段名1[,字段名2 …]); -- 删除某个索引 alter table employee drop index emp_name; -- 设置主关键字 alter table 表名 add primary key (字段名); -- 设置唯一限制条件 alter table 表名 add unique 索引名 (字段名); 5.数据操作5.1 插入数据(Add)-- 第一种形式无需指定要插入数据的列名,只需提供被插入的值即可: insert into tb_name values (value1,value2,value3,...); -- 第二种形式需要指定列名及被插入的值: insert into tb_name (column1,column2,column3,...) values (value1,value2,value3,...);eg:insert into Student values ( 20180001,张三,男,20,CS); insert into Student values ( 20180002,李四,男,19,CS); insert into Student (Sno,Sname,Ssex,Sage,Sdept) values ( 20180003,王五,男,18,MA); insert into Student (Sno,Sname,Ssex,Sage,Sdept) values ( 20180004,赵六,男,20,IS);5.2 查询数据(Select)select 语句的一般格式如下:select <目标列表达式列表> [into 新表名] from 表名或视图名 [where <条件>] [group by <分组表达式>] [having <条件>] [order by <排序表达式>[ASC|DESC]]查询所有-- 查询表中所有列 select * from tb_name; -- 查询表中指定的列 select tb_name.<字符型字段>,<字符型字段> ... from tb_name; -- 指定查询结果中的列名 select <字符型字段> as 列标题1,<字符型字段> as 列标题2, <字符型字段> as 列标题3 from bt_name; -- 查询经过计算的列(即表达式的值) select <字符型字段>,<字符型字段>,列标题 = <字符型字段> * n from tb_name;消除查询结果中的重复行select distinct <字符型字段>[,<字符型字段>,...] from tb_name;限制查询结果中的返回行数select top n from tb_name; -- 查询前 n 的数据 select top n percent from tb_name; -- 查询前 n% tb_name的数据对查询结果排序select * from tb_name order by <排序表达式> <排序方法>;查询满足条件的行模板select [all|distinct] [top n[percent]]<目标列表达式列表> from 表名 where <条件>; -- 说明:在查询条件中可使用以下运算符或表达式: -- 比较运算符 <=,<,=,>,>=,!=,<>,!>,!< -- 范围运算符 between... and,not between... and -- 列举运算符 in,not in -- 模糊匹配运算符 like,not like -- 空值运算符 is null,is not null -- 逻辑运算符 and,or,not具体应用-- 使用比较运算符 select * from tb_name where <字段> >= n ; -- 指定范围 select * from tb_name where <字段> [not] between <表达式1> and <表达式2>; -- 使用列举 select * from tb_name where <字段> [not] in(值1,值2,...,值n); -- 使用通配符进行模糊查询 匹配串中通常含有通配符%和_(下划线)。 select * from tb_name where <字符型字段> [not] like <匹配串>; -- 使用null的查询 select * from tb_name where <字符型字段> is [not] null; -- 多重条件查询:使用逻辑运算符 select * from tb_name where <字符型字段> = 'volues' and <字符型字段> > n;使用统计函数-- 求指定的数值型表达式的和或平均值 select avg(<字符型字段>) as 平均数,sum(<字符型字段>) as 总数 from tb_name where <字符型字段> ='字符串'; -- 求指定表达式的最大值或最小值。 select max(<字符型字段>) as 最大值,min(<字符型字段>) as 最小值 from tb_name; -- 统计记录总数。 select count(*) as 总数 from tb_name; -- 统计指定字段值不为空的记录个数 select count(<字符型字段>) as 总数 from tb_name;对查询结果分组-- group by子句用于将查询结果表按某一列或多列值进行分组,列值相等的为一组,每组统计出一个结果。该子句常与统计函数一起使用进行分组统计。格式为: -- group by 分组字段[,...n][having <条件表达式>]; -- 1.在使用group by子句后 -- select列表中只能包含:group by子句中所指定的分组字段及统计函数。 -- 2.having子句的用法 -- having子句必须与group by 子句配合使用,用于对分组后的结果进行筛选(筛选条件中常含有统计函数)。 -- 3. 分组查询时不含统计函数的条件 -- 通常使用where子句;含有统计函数的条件,则只能用having子句。 select <字符型字段>,count(*) as 列标题 from tb_name where <字符型字段>='字符串' group by <字符型字段>;5.3 修改数据(Update)update tb_name set 列名称 = 新值 where 列名称 = 某值;5.4 删除数据(Delete)-- 条件删除 delete from tb_name where 列名称 = 某值; -- 删除所有行 delete * from tb_name; -- 或 delete from tb_name;参考资料mysql修改root密码和设置权限MySQL允许root远程登录MySQL基础 — 常用命令







![[转载]:Java 相关一些面试题](https://blog.inat.top/usr/themes/Joe/assets/thumb/41.jpg)