搜索到
60
篇与
的结果
-
 蓝桥杯|历届真题:子串分值和 1.题目【问题描述】对于一个字符串$S$,我们定义S的分值$f(S)$为$S$中恰好出现一次的字符个数。例如$f(aba)=1,f(abc)=3,f(aaa) = 0$。现在给定一个字符串$S[0..n-1]$(长度为n),请你计算对于所有S的非空子串$S[i..j](0 \leq i \leq j \lt n)$,$f(S[i..j])$的和是多少。【输入格式】输入一行包含一个由小写字母组成的字符串S。【输出格式】输出一个整数表示答案。【样例输入】ababc【样例输出】21【样例说明】子串,f值 a,1 ab,2 aba,1 abab,0 ababc,1 b,1 ba,2 bab,1 babc,2 a,1 ab,2 abc,3 b,1 bc,2 c,1【评测用例规模与约定】对于20%的评测用例, $1 \leq n \leq 10$;对于40%的评测用例, $1 \leq n \leq 100$;对于50%的评测用例, $1 \leq n \leq 1000$;对于60%的评测用例, $1 \leq n \leq 10000$;对于所有评测用例, $1 \leq n \leq 100000$;2. 题解2.1 思路分析思路1:暴力求解(50分) 首先需要写一个计算子串得分的函数 1.统计各个字符出现的次数 2.得到只出现一次的字符数 然后遍历所有的子串并对其得分进行求和 思路2:动态规划(50分) 考虑子串之间的关系,即新增一个字符对子串得分的影响,从避免重复统计字符出现次数导致耗时 思路3:考虑每个位置的字符只出现一次的子串总数(100分) 用 pre[i] 记录第 i 位置上的字母上一次出现的位置,用 next[i] 记录第 i 位置上的字母下一次出现的位置; 那么往左最多能延伸到 pre[i] + 1,其到第 i 个字母一共有 i - pre[i] 个字母; 同理往右最多能延伸到 next[i] - 1,其到第 i 个字母一共有 next[i] - i 个字母; 二者相乘,就是该 i 位置上的字符只出现一次的子串总数 具体可以结合上述输入输出例子思考。2.2 代码实现思路1:暴力求解import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static int getScore(String str){ int score = 0; char[] strChars = str.toCharArray(); int[] charCounter = new int[26]; for (int i = 0; i < 26; i++)charCounter[i]=0; for (int i = 0; i < strChars.length; i++) { charCounter[(int)(strChars[i]-'a')]++; } for (int i = 0; i <26 ; i++) { if(charCounter[i]==1)score++; } return score; } public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { StringBuilder sb = new StringBuilder(); for (int j = i; j < strChars.length; j++) { sb.append(strChars[j]); scoreSum+=getScore(sb.toString()); } } System.out.println(scoreSum); } }// 简化子串得分求解 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { Set<Character> set1 = new HashSet<>(); //统计所有字符串 Set<Character> set2 = new HashSet<>();//统计不止出现一次的字符串 for (int j = i; j < strChars.length; j++) { if(set1.contains(strChars[j])){ set2.add(strChars[j]); } set1.add(strChars[j]); scoreSum+= set1.size()-set2.size(); } } System.out.println(scoreSum); } }思路2:动态规划// 40分 会爆内存 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int[][] dp = new int[str.length()][str.length()]; int scoreSum = 0; for (int i = 0; i < str.length(); i++) { for (int j = 0; j < str.length();j++) { if(j<i){ dp[i][j] = 0; }else if(j==i){ dp[i][j] = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 dp[i][j]=dp[i][j-1]-1; }else {//旧的子串包含多个个待加入字符,之前已进行了-1操作,无需再减 dp[i][j]=dp[i][j-1]; } }else {//旧的子不包含待加入字符 dp[i][j]=dp[i][j-1]+1; } } scoreSum += dp[i][j]; } } System.out.println(scoreSum); } }// dp优化 避免爆内存 还是50分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int lastDpstate = 0; int scoreSum = 0; for (int i = 0; i < len; i++) { for (int j = 0; j < len;j++) { if(j<i){ lastDpstate=0; }else if(j==i){ lastDpstate = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子串包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 lastDpstate=lastDpstate-1; } }else { lastDpstate=lastDpstate+1; } } scoreSum += lastDpstate; } } System.out.println(scoreSum); } }思路3:考虑每个位置的字符只出现一次的子串总数// 60分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { int nextIndex = str.substring(i+1).indexOf(strChars[i]); //下一个strChars[i]字符的位置 nextIndex = nextIndex==-1? strChars.length : nextIndex+i+1; int preIndex = str.substring(0,i).lastIndexOf(strChars[i]);////前一个strChars[i]字符的位置 scoreSum += (nextIndex-i)*(i-preIndex); } System.out.println(scoreSum); } }// 优化 100分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int len = strChars.length; int scoreSum = 0; int[] pre = new int[len]; int[] next = new int[len]; Arrays.fill(pre,-1); Arrays.fill(next,len); // 求解next[i] for (int i = 0; i < len; i++) { for (int j = i+1; j < len; j++) { if(strChars[i]==strChars[j]){ next[i]=j; break; } } } // 求解pre[i] for (int i = 0; i < len; i++) { for (int j = i-1; j>=0; j--) { if(strChars[i]==strChars[j]){ pre[i]=j; break; } } } // 计算得分和 for (int i = 0; i < len; i++) { scoreSum += (next[i]-i)*(i-pre[i]); } System.out.println(scoreSum); } }2.3 提交结果思路1:暴力求解评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路2:动态规划评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路3:考虑每个位置的字符只出现一次的子串总数评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00109ms22.40MB输入 输出2正确10.0046ms22.40MBVIP特权3正确10.0078ms22.41MBVIP特权4正确10.0093ms22.39MBVIP特权5正确10.0078ms22.44MBVIP特权6正确10.00125ms23.34MBVIP特权7正确10.00125ms26.62MBVIP特权8正确10.00140ms26.70MBVIP特权9正确10.00109ms26.51MBVIP特权10正确10.00171ms26.66MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2858蓝桥杯试题 历届试题 子串分值和
蓝桥杯|历届真题:子串分值和 1.题目【问题描述】对于一个字符串$S$,我们定义S的分值$f(S)$为$S$中恰好出现一次的字符个数。例如$f(aba)=1,f(abc)=3,f(aaa) = 0$。现在给定一个字符串$S[0..n-1]$(长度为n),请你计算对于所有S的非空子串$S[i..j](0 \leq i \leq j \lt n)$,$f(S[i..j])$的和是多少。【输入格式】输入一行包含一个由小写字母组成的字符串S。【输出格式】输出一个整数表示答案。【样例输入】ababc【样例输出】21【样例说明】子串,f值 a,1 ab,2 aba,1 abab,0 ababc,1 b,1 ba,2 bab,1 babc,2 a,1 ab,2 abc,3 b,1 bc,2 c,1【评测用例规模与约定】对于20%的评测用例, $1 \leq n \leq 10$;对于40%的评测用例, $1 \leq n \leq 100$;对于50%的评测用例, $1 \leq n \leq 1000$;对于60%的评测用例, $1 \leq n \leq 10000$;对于所有评测用例, $1 \leq n \leq 100000$;2. 题解2.1 思路分析思路1:暴力求解(50分) 首先需要写一个计算子串得分的函数 1.统计各个字符出现的次数 2.得到只出现一次的字符数 然后遍历所有的子串并对其得分进行求和 思路2:动态规划(50分) 考虑子串之间的关系,即新增一个字符对子串得分的影响,从避免重复统计字符出现次数导致耗时 思路3:考虑每个位置的字符只出现一次的子串总数(100分) 用 pre[i] 记录第 i 位置上的字母上一次出现的位置,用 next[i] 记录第 i 位置上的字母下一次出现的位置; 那么往左最多能延伸到 pre[i] + 1,其到第 i 个字母一共有 i - pre[i] 个字母; 同理往右最多能延伸到 next[i] - 1,其到第 i 个字母一共有 next[i] - i 个字母; 二者相乘,就是该 i 位置上的字符只出现一次的子串总数 具体可以结合上述输入输出例子思考。2.2 代码实现思路1:暴力求解import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static int getScore(String str){ int score = 0; char[] strChars = str.toCharArray(); int[] charCounter = new int[26]; for (int i = 0; i < 26; i++)charCounter[i]=0; for (int i = 0; i < strChars.length; i++) { charCounter[(int)(strChars[i]-'a')]++; } for (int i = 0; i <26 ; i++) { if(charCounter[i]==1)score++; } return score; } public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { StringBuilder sb = new StringBuilder(); for (int j = i; j < strChars.length; j++) { sb.append(strChars[j]); scoreSum+=getScore(sb.toString()); } } System.out.println(scoreSum); } }// 简化子串得分求解 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { Set<Character> set1 = new HashSet<>(); //统计所有字符串 Set<Character> set2 = new HashSet<>();//统计不止出现一次的字符串 for (int j = i; j < strChars.length; j++) { if(set1.contains(strChars[j])){ set2.add(strChars[j]); } set1.add(strChars[j]); scoreSum+= set1.size()-set2.size(); } } System.out.println(scoreSum); } }思路2:动态规划// 40分 会爆内存 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int[][] dp = new int[str.length()][str.length()]; int scoreSum = 0; for (int i = 0; i < str.length(); i++) { for (int j = 0; j < str.length();j++) { if(j<i){ dp[i][j] = 0; }else if(j==i){ dp[i][j] = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 dp[i][j]=dp[i][j-1]-1; }else {//旧的子串包含多个个待加入字符,之前已进行了-1操作,无需再减 dp[i][j]=dp[i][j-1]; } }else {//旧的子不包含待加入字符 dp[i][j]=dp[i][j-1]+1; } } scoreSum += dp[i][j]; } } System.out.println(scoreSum); } }// dp优化 避免爆内存 还是50分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); int lastDpstate = 0; int scoreSum = 0; for (int i = 0; i < len; i++) { for (int j = 0; j < len;j++) { if(j<i){ lastDpstate=0; }else if(j==i){ lastDpstate = 1; }else { int startIndex = str.substring(i,j).indexOf(strChars[j]); if(startIndex!=-1){//旧的子串包含待加入字符 int endIndex = str.substring(i,j).lastIndexOf(strChars[j]); if(startIndex==endIndex){//旧的子串只包含1个待加入字符 lastDpstate=lastDpstate-1; } }else { lastDpstate=lastDpstate+1; } } scoreSum += lastDpstate; } } System.out.println(scoreSum); } }思路3:考虑每个位置的字符只出现一次的子串总数// 60分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int scoreSum = 0; for (int i = 0; i < strChars.length; i++) { int nextIndex = str.substring(i+1).indexOf(strChars[i]); //下一个strChars[i]字符的位置 nextIndex = nextIndex==-1? strChars.length : nextIndex+i+1; int preIndex = str.substring(0,i).lastIndexOf(strChars[i]);////前一个strChars[i]字符的位置 scoreSum += (nextIndex-i)*(i-preIndex); } System.out.println(scoreSum); } }// 优化 100分 import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { String str = scanner.next(); char[] strChars = str.toCharArray(); int len = strChars.length; int scoreSum = 0; int[] pre = new int[len]; int[] next = new int[len]; Arrays.fill(pre,-1); Arrays.fill(next,len); // 求解next[i] for (int i = 0; i < len; i++) { for (int j = i+1; j < len; j++) { if(strChars[i]==strChars[j]){ next[i]=j; break; } } } // 求解pre[i] for (int i = 0; i < len; i++) { for (int j = i-1; j>=0; j--) { if(strChars[i]==strChars[j]){ pre[i]=j; break; } } } // 计算得分和 for (int i = 0; i < len; i++) { scoreSum += (next[i]-i)*(i-pre[i]); } System.out.println(scoreSum); } }2.3 提交结果思路1:暴力求解评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路2:动态规划评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.17MB输入 输出2正确10.00109ms22.19MBVIP特权3正确10.00109ms22.19MBVIP特权4正确10.0093ms24.36MBVIP特权5正确10.00359ms233.1MBVIP特权6运行超时0.00运行超时281.0MBVIP特权7运行超时0.00运行超时283.3MBVIP特权8运行超时0.00运行超时435.0MBVIP特权9运行超时0.00运行超时282.5MBVIP特权10运行超时0.00运行超时282.6MBVIP特权思路3:考虑每个位置的字符只出现一次的子串总数评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.00109ms22.40MB输入 输出2正确10.0046ms22.40MBVIP特权3正确10.0078ms22.41MBVIP特权4正确10.0093ms22.39MBVIP特权5正确10.0078ms22.44MBVIP特权6正确10.00125ms23.34MBVIP特权7正确10.00125ms26.62MBVIP特权8正确10.00140ms26.70MBVIP特权9正确10.00109ms26.51MBVIP特权10正确10.00171ms26.66MBVIP特权参考资料http://lx.lanqiao.cn/problem.page?gpid=T2858蓝桥杯试题 历届试题 子串分值和 -
蓝桥杯|历届真题:重复字符串 1.题目【问题描述】如果一个字符串S恰好可以由某个字符串重复K次得到,我们就称S是K次重复字符串。例如"abcabcabc”可以看作是"abc”重复3次得到,所以"abcabcabc”是3次重复字符串。同理"aaaaaa"既是2次重复字符串、又是3次重复字符串和6次重复字符串。现在给定一个字符串S,请你计算最少要修改其中几个字符,可以使S变为一个K次字符串?【输入格式】输入第一行包含一个整数K。第二行包含一个只含小写字母的字符串S。【输出格式】输出一个整数代表答案。如果S无法修改成K次重复字符串,输出-1。【样例输入】2 aabbaa【样例输出】2【评测用例规模与约定】对于所有评测用例,$1 \leq K \leq 100000,1 \leq |S| \leq 100000$。其中$|S|$表示$S$的长度。2. 题解2.1 思路分析先判断字符串长度是否是K的整数倍,不是则输出-1 若是,则将字符串分为K组,对每组的第i位统计得到各字符出现次数的最大值maxAppear 则要想将该字符串变为重复字符串在第i位上需要修改的最少的次数为K-maxAppear 对每一位需要做的最小修改进行求和即可得到最终的结果2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); public static void main(String[] args) { int K = scanner.nextInt(); String str = scanner.next(); int len = str.length(); char[] strChars = str.toCharArray(); if(len%K!=0){ System.out.println(-1); }else { int minChange = 0; int groupLen = len/K; for (int i = 0; i < groupLen; i++) {//将字符串分成K组 // 统计每组字符串第j位的哪个字符出现的次数最多得到次数 int maxAppear = 0; int[] charCounter = new int[26]; for (int j = 0; j < 26; j++) { charCounter[j]=0; } for (int j = 0; j < K; j++) { int tmpIndex = (int)(strChars[j*groupLen+i]-'a'); charCounter[tmpIndex] += 1; } for (int j = 0; j < 26; j++) { maxAppear = Math.max(maxAppear,charCounter[j]); } minChange += (K-maxAppear); } System.out.println(minChange); } } }2.3 提交结果1正确10.0062ms22.22MB输入 输出2正确10.0093ms22.30MBVIP特权3正确10.00109ms22.30MBVIP特权4正确10.0093ms22.26MBVIP特权5正确10.00109ms22.23MBVIP特权6正确10.0078ms22.29MBVIP特权7正确10.00140ms22.99MBVIP特权8正确10.00171ms25.62MBVIP特权9正确10.00125ms25.64MBVIP特权10错误0.00125ms24.57MBVIP特权暂未看出错在哪了参考资料http://lx.lanqiao.cn/problem.page?gpid=T2890
-
-
蓝桥杯|历届真题:砝码称重 1.题目【问题描述】你有一架天平和 $N$个砝码,这 $N$个砝码重量依次是 $W_1, W_2, · · · , W_N$。 请你计算一共可以称出多少种不同的重量? 注意砝码可以放在天平两边。【输入格式】输入的第一行包含一个整数 $N$。第二行包含 $N$个整数:$W_1, W_2, · · · , W_N$。【输出格式】输出一个整数代表答案。【样例输入】3 1 4 6【样例输出】10【样例说明】能称出的 10 种重量是:1、2、3、4、5、6、7、9、10、11。 1 = 1; 2 = 6 − 4 (天平一边放 6,另一边放 4); 3 = 4 − 1; 4 = 4; 5 = 6 − 1; 6 = 6; 7 = 1 + 6; 9 = 4 + 6 − 1; 10 = 4 + 6; 11 = 1 + 4 + 6。2. 题解2.1 思路分析增加一个砝码会增加的新的称重组合为 1.原来的各种称重组合+该砝码的重量 2.原来的各种称重组合-该砝码的重量(0除外) 3.该砝码本身的重量 当只有一个砝码的时候称重组合为该砝码本身的重量 由此形成了动态规划链2.2 代码实现import java.util.*; public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int n = scanner.nextInt(); int[] weights = new int[n]; for (int i = 0; i < n; i++) { weights[i] = scanner.nextInt(); } Set<Integer> set = new HashSet<>();//用来存储最终可能的组合,set可以自动去重 set.add(weights[0]); for (int i = 1; i < n; i++) { List<Integer> tmpList = new ArrayList<>(set); for(Integer item:tmpList){ if(item!=weights[i]){//避免出现称出0的情况 set.add(Math.abs(item-weights[i])); } set.add(item+weights[i]); } set.add(weights[i]); } System.out.println(set.size()); } }2.3 提交结果评测点序号评测结果得分CPU使用内存使用下载评测数据1正确10.0078ms22.23MB输入 输出2正确10.00109ms22.33MBVIP特权3正确10.0078ms22.32MBVIP特权4正确10.00140ms22.33MBVIP特权5正确10.0062ms22.68MBVIP特权6正确10.00109ms23.85MBVIP特权7正确10.0078ms26.24MBVIP特权8正确10.00171ms33.07MBVIP特权9正确10.00218ms64.09MBVIP特权10正确10.00234ms90.59MBVIP特权参考资料蓝桥杯试题 历届真题 砝码称重【第十二届】【省赛】【JAVAB组】http://lx.lanqiao.cn/problem.page?gpid=T2895
-
蓝桥杯|历届真题:异或数列 1.题目【问题描述】Alice 和 Bob 正在玩一个异或数列的游戏。初始时,Alice 和 Bob 分别有一个整数$a$和$b$,有一个给定的长度为 $n$ 的公共数列 $X_1,X_2, \dots, X_{n_i}$ 。Alice 和 Bob 轮流操作,Alice 先手,每步可以在以下两种选项中选一种:选项 1:从数列中选一个 $Xi$ 给 Alice 的数异或上,或者说令 $a$ 变为 $a ⊕ Xi$。(其中 $⊕$ 表示按位异或)选项 2:从数列中选一个$Xi$ 给 Bob 的数异或上,或者说令 $b$变为$ b ⊕ Xi$。每个数 $X_i$ 都只能用一次,当所有 $Xi$ 均被使用后($n$ 轮后)游戏结束。游戏结束时,拥有的数比较大的一方获胜,如果双方数值相同,即为平手。现在双方都足够聪明,都采用最优策略,请问谁能获胜?【输入格式】每个评测用例包含多组询问。询问之间彼此独立。输入的第一行包含一个整数 $T$,表示询问数。接下来 $T$ 行每行包含一组询问。其中第 i 行的第一个整数 $n_i$ 表示数列长度,随后 $n_i$个整数 $X_1,X_2, \dots, X_{n_i}$ 表示数列中的每个数。【输出格式】输出 $T$ 行,依次对应每组询问的答案。每行包含一个整数 1、0 或 −1 分别表示 Alice 胜、平局或败。【样例输入】4 1 1 1 0 2 2 1 7 992438 1006399 781139 985280 4729 872779 563580【样例输出】1 0 1 1【评测用例规模与约定】对于所有评测用例,$1 ≤T≤ 200000,1 ≤ \sum^T_{i=1}n_i ≤ 200000,0 ≤X_i <2^{20}$。2. 题解2.1 思路分析a和b起始值都是0 两人数字相同时,即a^b=0时平局 a^b=X1^X2^……^Xn 因此 X1^X2^……^Xn=0-->平局 否则谁数字大就赢,也就是当a和b(二进制)从高到低有一位不同时,是1的那个人赢; 用 bitCount[] 数组 统计X1……Xn每一位为1的次数; eg: 4(100)、6(110)、5(101),这3个数统计后 bitCount[3]=3,bitCount[2]=1,bitCount[1]=1 从最高位遍历bitCount[i] bitCount[i]==1,该位数只要一个1,Alice 先手,胜 bitCount[i]是偶数,无影响,不处理 bitCount[i]是奇数: n是偶数,奇数个1奇数个0,只要后手把0先选完,后手就获得最后一个1的支配权,后手胜 n是奇数,奇数个1偶数个0,先手把0先选完,先手获得最后一个1的支配权,先手胜2.2 代码实现import java.util.*; public class Main { static Scanner scanner = new Scanner(System.in); // 统计x1-xn对应的2进制数的每1位的1的总数量 public static int[] getBitCount(int[] arr){ int[] bitCount = new int[20];//存储每一位对应的1的总数 for (int i = 0; i < bitCount.length; i++) { bitCount[i]=0; } for (int i = 0; i < arr.length ; i++) { int tmp = arr[i]; int bit=0; while (tmp>0){ bitCount[bit++]+=tmp&1; tmp = tmp>>1 ; } } return bitCount; } public static int playOneEpoch(){ int arrNum = scanner.nextInt(); int [] arr = new int[arrNum]; int xor = 0; // 用于计算X1^X2^……^Xn for (int j = 0; j < arrNum; j++) { arr[j]= scanner.nextInt(); xor ^= arr[j]; } if(xor==0)return 0; // 统计所有位的1的个数 int[] bitCountOf1 = getBitCount(arr); // 从高位到低位进行判断 for (int i = bitCountOf1.length-1; i >=0; i--) { if(bitCountOf1[i]==0 || bitCountOf1[i]%2==0){//无需进行处理,对结果没有影响 continue; }else if(bitCountOf1[i]==1){//先手Alice选中直接获胜 return 1; }else if(bitCountOf1[i]%2==1){ // 该位只有奇数个1,则拿到最后一个1的一方获胜 if(arrNum%2==0){//总数为偶数 后手有最后一个1的支配权,后手胜利 return -1; }else{//总数为奇数 先手有最后一个1的支配权,先手胜利 return 1; } } } return 0; } public static void main(String[] args) { int T = scanner.nextInt(); int[] res = new int[T]; for (int i = 0; i < T; i++) { res[i] = playOneEpoch(); } for (int i = 0; i < T; i++) { System.out.println(res[i]); } } }2.3 提交结果评测点序号评测结果得分CPU使用内存使用下载评测数据1正确20.00656ms94.55MB输入 输出2正确20.00687ms95.83MBVIP特权3正确20.00734ms95.92MBVIP特权4正确20.00500ms92.60MBVIP特权5正确20.00406ms92.29MBVIP特权参考资料异或数列(c++位运算)蓝桥杯2021年第十二届省赛-异或数列http://lx.lanqiao.cn/detail.page?submitid=7217417第十二届蓝桥杯大赛软件赛省赛 Python 大学 A 组 试题
-
tqdm:简单好用的python进度条 1.介绍Tqdm是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。安装方式如下:pip install tqdm2.简单使用2.1 用法一from tqdm import tqdm import time for i in tqdm(range(1000)): time.sleep(0.01) #do something100%|██████████| 1000/1000 [00:10<00:00, 95.17it/s]2.2 用法二from tqdm import trange import time for i in trange(100): time.sleep(0.01) #do something100%|██████████| 100/100 [00:01<00:00, 94.86it/s]2.3 用法三from tqdm import tqdm import timepython pbar = tqdm(total=100) for i in range(100): time.sleep(0.05) #do something pbar.update(1) pbar.close()100%|██████████| 100/100 [00:05<00:00, 19.35it/s2.4 用法四(具有前后缀描述功能)(推荐)from tqdm import tqdm import time import random pbar = tqdm(total=100) for i in range(100): time.sleep(0.05) #do something pbar.update(1) pbar.set_description("Epoch: %d" % 1) # 设置前缀 pbar.set_postfix({'loss':random.random()}) # 设置后缀 pbar.close()Epoch: 1: 100%|██████████| 100/100 [00:07<00:00, 14.28it/s, loss=0.709] 参考资料tqdm介绍及常用方法在tqdm中加入前缀和后缀详细介绍Python进度条tqdm的使用
-
Python通过opencv实现视频和图像互转 1.视频转图片import cv2 import numpy import math cap = cv2.VideoCapture("./帯広空港.mp4") vedio_frame_count = cap.get(7) # 获取视频总帧数 vedio_fps = math.ceil(cap.get(5)) # 获取视频帧率 frame_width = cap.get(3) # 获取视频帧宽度 frame_height = cap.get(4) # 获取视频帧高度 print(vedio_frame_count,vedio_fps) frame_id = 1 while(True): ret, frame = cap.read() if not ret or cv2.waitKey(30)==ord('q'): break; cv2.imshow("frame",frame) frame_id += 1 cap.release() cv2.destroyAllWindows()opencv参数列表0 CV_CAP_PROP_POS_MSEC Current position of the video file in milliseconds or video capture timestamp. 1 CV_CAP_PROP_POS_FRAMES 0-based index of the frame to be decoded/captured next. 2 CV_CAP_PROP_POS_AVI_RATIO Relative position of the video file: 0 - start of the film, 1 - end of the film. 3 CV_CAP_PROP_FRAME_WIDTH #视频帧宽度 4 CV_CAP_PROP_FRAME_HEIGHT #视频帧高度 5 CV_CAP_PROP_FPS #视频帧速率 6 CV_CAP_PROP_FOURCC 4-character code of codec. 7 CV_CAP_PROP_FRAME_COUNT #视频总帧数 8 CV_CAP_PROP_FORMAT Format of the Mat objects returned by retrieve() . 9 CV_CAP_PROP_MODE Backend-specific value indicating the current capture mode. 10 CV_CAP_PROP_BRIGHTNESS Brightness of the image (only for cameras). 11 CV_CAP_PROP_CONTRAST Contrast of the image (only for cameras). 12 CV_CAP_PROP_SATURATION Saturation of the image (only for cameras). 13 CV_CAP_PROP_HUE Hue of the image (only for cameras). 14 CV_CAP_PROP_GAIN Gain of the image (only for cameras). 15 CV_CAP_PROP_EXPOSURE Exposure (only for cameras). 16 CV_CAP_PROP_CONVERT_RGB Boolean flags indicating whether images should be converted to RGB. 17 CV_CAP_PROP_WHITE_BALANCE_U The U value of the whitebalance setting (note: only supported by DC1394 v 2.x backend currently) 18 CV_CAP_PROP_WHITE_BALANCE_V The V value of the whitebalance setting (note: only supported by DC1394 v 2.x backend currently) 19 CV_CAP_PROP_RECTIFICATION Rectification flag for stereo cameras (note: only supported by DC1394 v 2.x backend currently) 20 CV_CAP_PROP_ISO_SPEED The ISO speed of the camera (note: only supported by DC1394 v 2.x backend currently) 21 CV_CAP_PROP_BUFFERSIZE Amount of frames stored in internal buffer memory (note: only supported by DC1394 v 2.x backend currently)2.图片转视频# 图片转视频 import cv2 import os img_dir = "./data_handle/img/" # 必须保证图片是相同大小的,否则会转换失败 img_list = os.listdir(img_dir) frame_rate = 30 # 帧率 frame_shape = cv2.imread(os.path.join(img_dir,img_list[0])).shape[:-1] # 图片大小/帧shape frame_shape = (frame_shape[1],frame_shape[0]) # 交换w和h videoWriter = cv2.VideoWriter('result.mp4', cv2.VideoWriter_fourcc(*'MJPG'), frame_rate, frame_shape) # 初始化视频帧writer # 开始逐帧写入视频帧 frame_id = 1 for img_filename in img_list: img_path = os.path.join(img_dir,img_filename) img = cv2.imread(img_path) videoWriter.write(img) frame_id += 1 if frame_id%100 == 0: break videoWriter.release() 参考资料OpenCV|图片与视频的相互转换(C++&Python)python3 opencv获取视频的总帧数介绍
-
python使用opencv读取海康摄像头视频流rtsp pythons使用opencv读取海康摄像头视频流rtsp海康IPcamera rtsp地址和格式:rtsp://[username]:[password]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream 说明: username: 用户名。例如admin。 password: 密码。例如12345。 ip: 为设备IP。例如 192.0.0.64。 port: 端口号默认为554,若为默认可不填写。 codec:有h264、MPEG-4、mpeg4这几种。 channel: 通道号,起始为1。例如通道1,则为ch1。 subtype: 码流类型,主码流为main,辅码流为sub。python读取视频流import cv2 url = 'rtsp://admin:!itrb123@10.1.9.143:554/h264/ch1/main/av_stream' cap = cv2.VideoCapture(url) while(cap.isOpened()): # Capture frame-by-frame ret, frame = cap.read() # Display the resulting frame cv2.imshow('frame',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # When everything done, release the capture cap.release() cv2.destroyAllWindows()
-
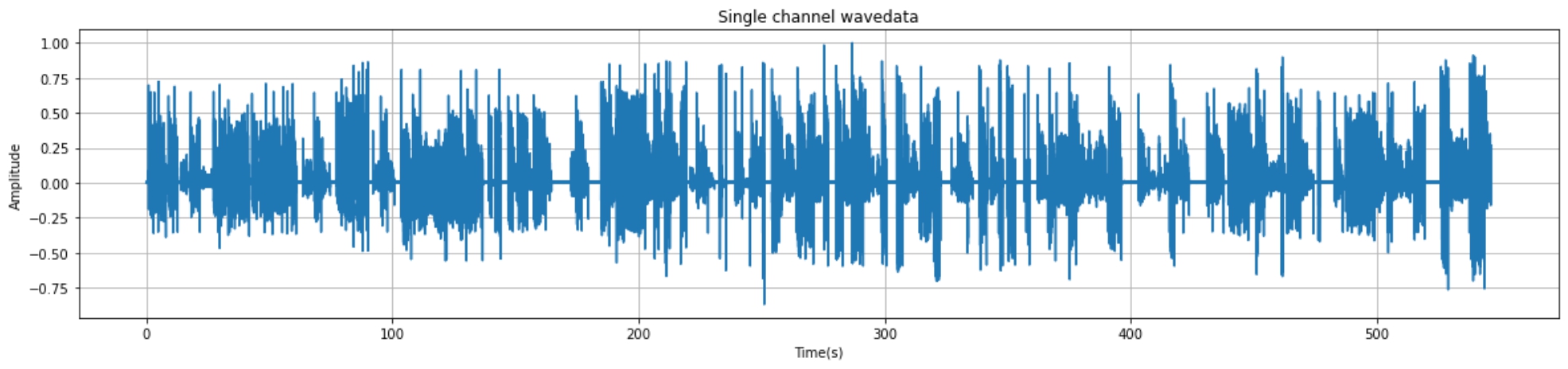
python实现音频读取与可视化+端点检测+音频切分 1.音频读取与可视化1.1 核心代码import wave import matplotlib.pyplot as plt import numpy as np import os filepath = "./audio/day0716_17.wav" f = wave.open(filepath,'rb') # 读取音频 params = f.getparams() # 查看音频的参数信息 print(params) # 可视化准备工作 strData = f.readframes(nframes)#读取音频,字符串格式 waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化 # 可视化 time = np.arange(0,nframes)*(1.0 / framerate) plt.figure(figsize=(20,4)) plt.plot(time,waveData) plt.xlabel("Time(s)") plt.ylabel("Amplitude") plt.title("Single channel wavedata") plt.grid('on')#标尺,on:有,off:无。1.2 实现效果_wave_params(nchannels=1, sampwidth=2, framerate=16000, nframes=8744750, comptype='NONE', compname='not compressed')2.端点检测2.1 环境准备pip install speechbrain2.2 核心代码from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") boundaries = VAD.get_speech_segments("./day0716_17.wav") print(boundaries)2.3 输出结果输出结果为包含语音数据的[开始时间,结束时间]区间序列tensor([[ 1.1100, 4.5700], [ 5.5600, 7.6100], [ 8.5800, 12.7800], ······ [508.7500, 519.0300], [526.0800, 537.1100], [538.0200, 546.5200]])3.pydub分割并保存音频3.1 核心代码from pydub import AudioSegment file_name = "denoise_0306.wav" sound = AudioSegment.from_mp3(file_name) # 单位:ms crop_audio = sound[1550:1900] save_name = "crop_"+file_name print(save_name) crop_audio.export(save_name, format="wav",tags={'artist': 'AppLeU0', 'album': save_name})4.汇总(仅供参考)汇总方式自行编写。以下案例为处理audio文件夹的的所有的wav结尾的文件从中提取出有声音的片段并进保存到相应的文件夹from pydub import AudioSegment import os from speechbrain.pretrained import VAD VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty") audio_dir = "./audio/" audio_name_list = os.listdir(audio_dir) for audio_name in audio_name_list: if not audio_name.endswith(".wav"): continue print(audio_name,"开始处理") audio_path = os.path.join(audio_dir,audio_name) word_save_dir = os.path.join(audio_dir,audio_name[:-4]) if not os.path.exists(word_save_dir): os.mkdir(word_save_dir) else: print(audio_name,"已经完成,跳过") continue boundaries = VAD.get_speech_segments(audio_path) sound = AudioSegment.from_mp3(audio_path) for boundary in boundaries: start_time = boundary[0] * 1000 end_time = boundary[1] * 1000 word = sound[start_time:end_time] word_save_path = os.path.join(word_save_dir,str(int(boundary[0]))+"-"+ str(int(boundary[1])) +".wav") word.export(word_save_path, format="wav") print("\r"+word_save_path,"保存成功",end="") print(audio_name,"处理完成")参考资料https://huggingface.co/speechbrain/vad-crdnn-libripartypydub分割并保存音频
-
python结合opencv调用谷歌tesseract-ocr实现印刷体的表格识别识别 环境搭建安装依赖-leptonica库下载源码git clone https://github.com/DanBloomberg/leptonica.gitconfiguresudo apt install automake bash autogen.sh ./configure编译安装make sudo make install这样就安装好了leptonica库谷歌tesseract-ocr编译安装下载源码git clone https://github.com/tesseract-ocr/tesseract.git tesseract-ocr安装依赖sudo apt-get install g++ autoconf automake libtool autoconf-archive pkg-config libpng12-dev libjpeg8-dev libtiff5-dev zlib1g-dev libleptonica-dev -y安装训练所需要的库(只是调用可以不用安装)sudo apt-get install libicu-dev libpango1.0-dev libcairo2-devconfigurebash autogen.sh ./configure编译安装make sudo make install # 可选项,不训练可以选择不执行下面两条 make training sudo make training-install sudo ldconfig安装对应的字体库并添加对应的环境变量下载好的语言包 放在/usr/local/share/tessdata目录里面。语言包地址:https://github.com/tesseract-ocr/tessdata_best。里面有各种语言包,都是训练好的语言包。简体中文下载:chi_sim.traineddata , chi_sim_vert.traineddata英文包:eng.traineddata。设置环境变量vim ~/.bashrc # 在.bashrc的文件末尾加入以下内容 export TESSDATA_PREFIX=/usr/local/share/tessdata source ~/.bashrc查看字体库tesseract --list-langs使用tesseract-ocr测试# 识别/home/app/1.png这张图片,内容输出到output.txt 里面,用chi_sim 中文来识别(不用加.traineddata,会默认加) tesseract /home/app/1.png output -l chi_sim # 查看识别结果 cat output.txt安装python调用依赖包pip install pytesseract配合opencv调用进行印刷体表格识别代码import cv2 import numpy as np import pytesseract import matplotlib.pyplot as plt import re #原图 raw = cv2.imread("table3.2.PNG") # 灰度图片 gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY) # 二值化 binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5) rows, cols = binary.shape # 识别横线 scale = 50 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_col = cv2.dilate(eroded, kernel, iterations=1) # 识别竖线 scale = 10 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_row = cv2.dilate(eroded, kernel, iterations=1) # 标识交点 bitwise_and = cv2.bitwise_and(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(bitwise_and,cmap="gray") # 标识表格 merge = cv2.add(dilated_col, dilated_row) plt.figure(dpi=300) # plt.imshow(merge,cmap="gray") # 两张图片进行减法运算,去掉表格框线 merge2 = cv2.subtract(binary, merge) plt.figure(dpi=300) # plt.imshow(merge2,cmap="gray") # 识别黑白图中的白色交叉点,将横纵坐标取出 ys, xs = np.where(bitwise_and > 0) # 提取单元格切分点 # 横坐标 x_point_arr = [] # 通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点 # 这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变) sort_x_point = np.sort(xs) for i in range(len(sort_x_point) - 1): if sort_x_point[i + 1] - sort_x_point[i] > 10: x_point_arr.append(sort_x_point[i]) i = i + 1 x_point_arr.append(sort_x_point[i]) # 要将最后一个点加入 # 纵坐标 y_point_arr = [] sort_y_point = np.sort(ys) for i in range(len(sort_y_point) - 1): if (sort_y_point[i + 1] - sort_y_point[i] > 10): y_point_arr.append(sort_y_point[i]) i = i + 1 # 要将最后一个点加入 y_point_arr.append(sort_y_point[i]) # 循环y坐标,x坐标分割表格 plt.figure(dpi=300) data = [[] for i in range(len(y_point_arr))] for i in range(len(y_point_arr) - 1): for j in range(len(x_point_arr) - 1): # 在分割时,第一个参数为y坐标,第二个参数为x坐标 cell = raw[y_point_arr[i]:y_point_arr[i + 1], x_point_arr[j]:x_point_arr[j + 1]] #读取文字,此为默认英文 text1 = pytesseract.image_to_string(cell, lang="chi_sim+eng") #去除特殊字符 text1 = re.findall(r'[^\*"/:?\\|<>″′‖ 〈\n]', text1, re.S) text1 = "".join(text1) print('单元格图片信息:' + text1) data[i].append(text1) plt.subplot(len(y_point_arr),len(x_point_arr),len(x_point_arr)*i+j+1) plt.imshow(cell) plt.axis('off') plt.tight_layout() plt.show()实现效果表格图片识别结果单元格图片信息:停机位Stands 单元格图片信息:空器避展限制Wingspanlimitsforaircraft(m) 单元格图片信息:Nr61.62.414-416.886.887.898,899.ZZ14 单元格图片信息:80 单元格图片信息:Nr101,102.105,212.219-222,228.417-419,874-876.895-897.910-912 单元格图片信息:65 单元格图片信息:NrZZ11 单元格图片信息:61 单元格图片信息:Nr103,104.106.107.109,117,890-894.ZL1,ZL2(deicingstands) 单元格图片信息:52 单元格图片信息:Nr878.879 单元格图片信息:51 单元格图片信息:Nr229.230 单元格图片信息:48 单元格图片信息:Nr877 单元格图片信息:42 单元格图片信息:Nr61R.62L 单元格图片信息:38.1 单元格图片信息:Nr61L.62R.108.110-116,118.201-211.213-218,223-227.409-413,414L.414R.415L.415R.416L,416R.417R.418R.419R.501-504.601-610,886L,886R.887L.887R.888.889.898L.898R.8991L.899R_901-909,910R.911R.912R.913-916.921-925.ZZ1IL.ZZ12.ZZ13 单元格图片信息:36 单元格图片信息:NrZZ11IR 单元格图片信息:32 单元格图片信息:Nr884.885 单元格图片信息:29(fuselagelength32.8) 单元格图片信息:Nr417L.418L.419L 单元格图片信息:24.9 单元格图片信息:Nr910L.911L.912L.931-946 单元格图片信息:24
-
使用python+opencv快速实现画风迁移效果 风格类型模型风格(翻译可能有误)candy糖果composition_vii康丁斯基的抽象派绘画风格feathers羽毛udnie乌迪妮la_muse缪斯mosaic镶嵌the_wave海浪starry_night星夜the_scream爱德华·蒙克创作绘画风格(呐喊)模型下载脚本BASE_URL="http://cs.stanford.edu/people/jcjohns/fast-neural-style/models/" mkdir -p models/instance_norm cd models/instance_norm curl -O "$BASE_URL/instance_norm/candy.t7" curl -O "$BASE_URL/instance_norm/la_muse.t7" curl -O "$BASE_URL/instance_norm/mosaic.t7" curl -O "$BASE_URL/instance_norm/feathers.t7" curl -O "$BASE_URL/instance_norm/the_scream.t7" curl -O "$BASE_URL/instance_norm/udnie.t7" mkdir -p ../eccv16 cd ../eccv16 curl -O "$BASE_URL/eccv16/the_wave.t7" curl -O "$BASE_URL/eccv16/starry_night.t7" curl -O "$BASE_URL/eccv16/la_muse.t7" curl -O "$BASE_URL/eccv16/composition_vii.t7" cd ../../代码调用import cv2 import matplotlib.pyplot as plt import os # 定义调用模型进行风格迁移的函数 def convert_img(model_path,img): # 加载模型 net = cv2.dnn.readNetFromTorch(model_path) net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) #设置后端 # 从图像中创建四维连通区域 w,h,_ = img.shape blob = cv2.dnn.blobFromImage(img,1.0,(h,w)) # 图片流经模型 net.setInput(blob) out = net.forward() # 模型输出修正 out = out.reshape(3,out.shape[2],out.shape[3]) out = out.transpose(1,2,0) out = out/255.0 return out # 读取图片 img = cv2.imread("./img/img2.jpg") # 调用模型进行风格迁移 out = convert_img("./model/feathers.t7",img) # 模型效果展示 plt.figure(dpi=200) plt.subplot(1,2,1) plt.title("origin") plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.subplot(1,2,2) plt.title("feathers") plt.imshow(cv2.cvtColor(out, cv2.COLOR_BGR2RGB)) plt.show()实现效果参考资料OpenCV4学习笔记(69)——dnn模块之基于fast_style模型实现快速图像风格迁移
-
图像padding为正方形并绘制网格(python+opencv实现) 代码实现import matplotlib.pyplot as plt import cv2 import numpy as np img = cv2.imread("./demo.jpg") """ 图像padding为正方形 """ def square_img(img_cv): # 获取图像的宽高 img_h,img_w = img_cv.shape[0:2] # 计算padding值并将图像padding为正方形 padw,padh = 0,0 if img_h>img_w: padw = (img_h - img_w) // 2 img_pad = np.pad(img_cv,((0,0),(padw,padw),(0,0)),'constant',constant_values=0) elif img_w>img_h: padh = (img_w - img_h) // 2 img_pad = np.pad(img_cv,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0) return img_pad """ 在图像上绘制网格 核心函数 cv2.line(img, (start_x, start_y), (end_x, end_y), (255, 0, 0), 1, 1) """ def draw_grid(img,grid_x,grid_y,line_width=5): img_x,img_y = img.shape[:2] # 绘平行y方向的直线 dx = int(img_x/grid_x) for i in range(0,img_x,dx): cv2.line(img, (i, 0), (i, img_y), (255, 0, 0), line_width) # 绘平行x方向的直线 dy = int(img_y/grid_y) for i in range(0,img_x,dx): cv2.line(img, (0, i), (img_x, i), (255, 0, 0), line_width) return img img = square_img(img) img = draw_grid(img,20,20) # 20,20为网格的shape img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) plt.figure(dpi=200) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show()调用效果代码参数需要稍作修改才能得到如下全部效果
-
python学习:正则表达式re模块的使用 1.常用常量1.1 re.I(re.IGNORECASE)执行不区分大小写的匹配;类似的表达式也[A-Z]将匹配小写字母。re.findall(r"[a-z]", "ah667GHD67DYT78") # Return:['a', 'h'] re.findall(r"[a-z]", "ah667GHD67DYT78",flags=re.IGNORECASE) # Return:['a', 'h', 'G', 'H', 'D', 'D', 'Y', 'T']1.2 re.S(re.DOTALL)使'.'特殊字符与任何字符都匹配,包括换行符;没有此标志,'.'将匹配除换行符以外的任何内容。s = '''first line second line third line''' re.findall(r".+", s) # Return:['first line', 'second line', 'third line'] re.findall(r".+", s, flags=re.DOTALL) # Return:['first line\nsecond line\nthird line']2.常用方法2.1 re.match(pattern,string,flags = 0 )对字符串从开头进行正则匹配 (匹配零个或者一个对象)如果字符串与模式匹配,则返回相应的匹配对象。re.match('a','abcade') # Return:<re.Match object; span=(0, 1), match='a'> re.match('\w+','abc123de') # Return:<re.Match object; span=(0, 8), match='abc123de'>如果字符串与模式不匹配,则返回None;re.match('z','abcade') # Return:None可以使用group()获取匹配结果re.match('a','abcade').group() # Return:'a'2.2 re.search(pattern,string,flags = 0 )扫描字符串以查找正则表达式模式产生匹配项的第一个位置(匹配零个或者一个对象),与re.match的区别re.match是从字符串的开头进行匹配re.search是从对字符串的挨个位置都进行尝试,指导匹配上或者尝试完所有位置如果匹配上,则返回相应的match对象。re.search('b','abcade') # Return:<re.Match object; span=(1, 2), match='b'> re.search('b','abcade').group() # Return:'b'如果字符串中没有位置与模式匹配,则返回None;re.search('z','abcade') # Return:None2.3 re.compile(pattern,flags = 0 )该方法同re.match和re.search将正则表达式模式编译为正则表达式对象,可使用match(),search()以及下面所述的其他方法将其用于匹配reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.search('12abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.search('12abc').group() # Return:12reg = re.compile('\d{2}') # 正则对象-匹配两个数字 reg.match('123abc') # Return:<re.Match object; span=(0, 2), match='12'> reg.match('12abc').group() # Return:122.4 re.fullmatch(pattern,string,flags = 0 )如果整个字符串与正则表达式模式匹配,则返回相应的match对象。re.fullmatch('\w+','abcade') # Return:<re.Match object; span=(0, 6), match='abcade'> re.fullmatch('\w+','abcade').group() # Return:'abcade'否则返回None;re.fullmatch('\w+','abca de') # Return:None2.5 re.split(pattern,string,maxsplit = 0,flags = 0 )通过正则表达式来split字符串。re.split(r'\W+', 'Words, words, words.') # Return:['Words', 'words', 'words', '']如果在pattern中使用了捕获括号,那么模式中所有组的文本也将作为结果列表的一部分返回。re.split(r'(\W+)', 'Words, words, words.') # Return:['Words', ', ', 'words', ', ', 'words', '.', '']如果分隔符中有捕获组,并且该匹配组在字符串的开头匹配,则结果将从空字符串开始。字符串的末尾也是如此:re.split(r'(\W+)', '...words, words...') # Return:['', '...', 'words', ', ', 'words', '...', '']如果maxsplit不为零,则最多会发生maxsplit分割,并将字符串的其余部分作为列表的最后一个元素返回。re.split(r'\W+', 'Words, words, words.',1) # Return:['Words', 'words, words.']2.6 re.findall(pattern,string,flags = 0 )从左到右扫描该字符串,以列表的形式返回所有的匹配项re.findall('a', 'This is a beautiful place!') # Return:['a', 'a', 'a'] re.findall('z', 'This is a beautiful place!') # Return:[]2.7 re.sub(pattern,repl,string,count = 0,flags = 0 )使用repl替换掉string中pattern成功匹配的匹配项,count参数表示将匹配到的内容进行替换的次数re.sub('\d', 'S', 'abc12jh45li78') #将匹配到所有的数字替换成S # Return:'abcSSjhSSliSS' re.sub('\d', 'S', 'abc12jh45li78', 2) #将匹配到的数字替换成S,只替换2次就停止 # Return:'abcSSjh45li78'如果找不到该模式, 则返回的字符串不变。re.sub('z', 'S', 'abc12jh45li78') # Return:'abc12jh45li78'2.8 re.subn(pattern,repl,string,count = 0,flags = 0 )执行与相同的操作sub(),但返回一个元组。(new_string, number_of_subs_made)re.subn('\d', 'S', 'abc12jh45li78') # Return:('abcSSjhSSliSS', 6) re.subn('\d', 'S', 'abc12jh45li78', 3) # Return:('abcSSjhS5li78', 3)3. 其他补充3.1 使用正则表达式匹配中文 re.findall(r"[\u4e00-\u9fa5]", "沿charlie在charlie五前等待。charlie charlie五前等四川八八六四") # Return:['沿', '在', '五', '前', '等', '待', '五', '前', '等', '四', '川', '八', '八', '六', '四']3.2 贪心匹配和非贪心匹配贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。re.search(r'(ha){3,5}','hahahahaha').group() # Return:'hahahahaha'非贪心匹配:匹配尽可能最短的字符串使用方式:在有二义的正则表达式的后面跟一个问号re.search(r'(ha){3,5}?','hahahahaha').group() # Return:'hahaha'参考资料使用正则表达式Python之re模块python 正则表达式详解
-
java学习:BigDecimal的使用 1、简介Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数。在实际应用中,需要对更大或者更小的数进行运算和处理。float和double只能用来做科学计算或者是工程计算,在商业计算中要用java.math.BigDecimal(原因见下文)。BigDecimal所创建的是对象,我们不能使用传统的+、-、*、/等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法。方法中的参数也必须是BigDecimal的对象。构造器是类的特殊方法,专门用来创建对象,特别是带有参数的对象。2、基本使用2.0 头文件导入import java.math.BigDecimal;2.1 Bigdecimal的初始化构造器描述BigDecimal(int) //创建一个具有参数所指定整数值的对象。 BigDecimal(double) //创建一个具有参数所指定双精度值的对象。 //不推荐使用 BigDecimal(long) //创建一个具有参数所指定长整数值的对象。 BigDecimal(String) //创建一个具有参数所指定以字符串表示的数值的对象。//推荐使用示例BigDecimal num3 = new BigDecimal(100); BigDecimal num2 = new BigDecimal(10L); BigDecimal num1 = new BigDecimal(0.005);//不推荐BigDecimal(double) //尽量用字符串的形式初始化 BigDecimal num12 = new BigDecimal("0.005"); BigDecimal num22 = new BigDecimal("10000"); BigDecimal num32 = new BigDecimal("-1000");为什么BigDecimal(double)不推荐使用+在商业计算中要用java.math.BigDecimal示例代码import java.math.BigDecimal; public class Solution { public static void main(String[] args){ BigDecimal doubleStr = new BigDecimal(1.11111111); System.out.println(doubleStr); } }运行结果C:\Users\itrb\Desktop\java>javac Solution.java C:\Users\itrb\Desktop\java>java Solution 1.111111109999999957409499984350986778736114501953125分析根本原因是:十进制值通常没有完全相同的二进制表示形式;十进制数的二进制表示形式可能不精确。只能无限接近于那个值但是,在项目中,我们不可能让这种情况出现,特别是金融项目,因为涉及金额的计算都必须十分精确,你想想,如果你的支付宝账户余额显示193.99999999999998,那是一种怎么样的体验?这也是在商业计算中要用java.math.BigDecimal的原因2.2 BigDecimal转回基本类型APItoString() //将BigDecimal对象的数值转换成字符串。 doubleValue() //将BigDecimal对象中的值以双精度数返回。 floatValue() //将BigDecimal对象中的值以单精度数返回。 longValue() //将BigDecimal对象中的值以长整数返回。 intValue() //将BigDecimal对象中的值以整数返回。2.3 Bigdecimal的基本运算APIadd(BigDecimal) //BigDecimal对象中的值相加,然后返回这个对象。 subtract(BigDecimal) //BigDecimal对象中的值相减,然后返回这个对象。 multiply(BigDecimal) //BigDecimal对象中的值相乘,然后返回这个对象。 divide(BigDecimal) //BigDecimal对象中的值相除,然后返回这个对象。 示例//加法 BigDecimal result1 = num1.add(num2); BigDecimal result12 = num12.add(num22); //减法 BigDecimal result2 = num1.subtract(num2); BigDecimal result22 = num12.subtract(num22); //乘法 BigDecimal result3 = num1.multiply(num2); BigDecimal result32 = num12.multiply(num22); //绝对值 BigDecimal result4 = num3.abs(); BigDecimal result42 = num32.abs(); //除法 BigDecimal result5 = num2.divide(num1,20,BigDecimal.ROUND_HALF_UP); BigDecimal result52 = num22.divide(num12,20,BigDecimal.ROUND_HALF_UP);备注如果进行除法运算的时候,结果不能整除,有余数,这个时候会报java.lang.ArithmeticException:这边要避免这个错误产生,在进行除法运算的时候,针对可能出现的小数产生的计算,必须要多传两个参数divide(BigDecimal,保留小数点后几位小数,舍入模式)舍入模式ROUND_CEILING //向正无穷方向舍入 ROUND_DOWN //向零方向舍入 ROUND_FLOOR //向负无穷方向舍入 ROUND_HALF_DOWN //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,向下舍入, 例如1.55 保留一位小数结果为1.5 ROUND_HALF_EVEN //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,如果保留位数是奇数,使用ROUND_HALF_UP,如果是偶数,使用ROUND_HALF_DOWN ROUND_HALF_UP //向(距离)最近的一边舍入,除非两边(的距离)是相等,如果是这样,向上舍入, 1.55保留一位小数结果为1.6,也就是我们常说的“四舍五入” ROUND_UNNECESSARY //计算结果是精确的,不需要舍入模式 ROUND_UP //向远离0的方向舍入需要对BigDecimal进行截断和四舍五入可用setScale方法import java.math.BigDecimal; public class Solution { public static void main(String[] args){ BigDecimal a = new BigDecimal("2.3366"); a = a.setScale(2,BigDecimal.ROUND_HALF_UP); //保留2位有效数字,且四舍五入 System.out.println(a); } }C:\Users\itrb\Desktop\java λ javac Solution.java C:\Users\itrb\Desktop\java λ java Solution 2.342.3 BigDecimal 比较大小BigDecimal a = new BigDecimal (101); BigDecimal b = new BigDecimal (111); //使用compareTo方法比较 //注意:a、b均不能为null,否则会报空指针 if(a.compareTo(b) == -1){ System.out.println("a小于b"); } if(a.compareTo(b) == 0){ System.out.println("a等于b"); } if(a.compareTo(b) == 1){ System.out.println("a大于b"); } if(a.compareTo(b) > -1){ System.out.println("a大于等于b"); } if(a.compareTo(b) < 1){ System.out.println("a小于等于b"); }参考资料java 中 BigDecimal 详解BigDecimal 比较大小BigDecimal加减乘除计算
-
PyAutoGUI—通过python控制鼠标与键盘实现图形界面自动化 简介基本信息PyAutoGUI是一个Python语言的键鼠自动化库,简单来说和按键精灵的功能一样。但是因为是Python的类库,所以可以使用Python代码配合一些其他类库完成更加强大的功能坐标轴系统pyautogui的鼠标函数使用x,y坐标,原点在屏幕左上角,向右x坐标增加,向下y坐标增加,所有坐标都是正整数,没有负数坐标。如图所示:功能使用1.获取屏幕宽高pyautogui.size() #返回屏幕宽高像素数的元组 #例如,如果屏幕分辨率为1920*1080,那么左上角的坐标为(0,0), #右下角的坐标是(1919,1079)2.控制鼠标确定鼠标当前位置pyautogui.position() #确定鼠标当前位置,返回x,y坐标的元组移动pyautogui.moveTo(x,y[,duration = t]) # 将鼠标移动到屏幕指定位置, #x,y是目标位置的横纵坐标,duration指定鼠标光标移动到目标位置 #所需要的秒数,t可以为整数或浮点数,省略duration参数表示 #立即将光标移动到指定位置(在PyAutoGUI函数中,所有的duration #关键字参数都是可选的) #Attention:所有传入x,y坐标的地方,都可以用坐标x,y #的元组或列表替代,(x,y)/[x,y] pyautogui.moveRel(x,y[,duration = t]) #相对于当前位置移动光标, #这里的x,y不再是目标位置的坐标,而是偏移量, #如,pyautogui.moveRel(100,0,duration=0.25) #表示光标相对于当前所在位置向右移动100个像素点击:按下鼠标按键,然后放开,同时不移动位置pyautogui.mouseDown() #按下鼠标按键(左键) pyautogui.mouseUp() #释放鼠标按键(左键) pyautogui.click() #向计算机发送虚拟的鼠标点击(click()函数只是前面两个函数调用的方便封装) #默认在当前光标位置,使用鼠标左键点击 pyautogui.click([x,y,button='left/right/middle']) #在(x,y)处点击鼠标左键、右键、中键 #但不推荐使用这种方法,下面这种方法效果更好 #pyautogui.moveTo(x,y,duration=t) #pyautogui.click() pyautogui.doubleClick() #双击鼠标左键 pyautogui.rightClick() #单击鼠标右键 pyautogui.middleClick() #单击鼠标中键拖动:按住一个键不放,同时移动鼠标pyautogui.dragTo(x,y[,duration=t) #将鼠标拖动到指定位置 #x,y:x坐标,y坐标 pyautogui.dragRel(x,y[,duration=t]) #将鼠标拖动到相对当前位置的位置 #x,y:水平移动,垂直移动滚动pyautogui.scroll() #控制窗口上下滚动(滚动发生在鼠标的当前位置) #正数表示向上滚动,负数表示向下滚动, #滚动单位的大小需要具体尝试3.控制键盘输入字符串pyautogui.typewrite(s[,duration=t]) #向文本框发送字符串 #可选的duration参数在输入单个字符之间添加短暂的时间暂停 #Attention:只能用于输入英文输入键字符串不是所有的键都很容易用单个文本字符来表示。例如,如何把Shift键或左箭头键表示为单个字符串?在PyAutoGUI中,这些键表示为短的字符串值,如'esc'表示Esc键,'enter'表示Enter,我们把这些字符串称之为键字符串。pyautogui.typewrite([键盘键字符串]) #除了单个字符串,还可以向typewrite()函数传递键字符串的列表 #如 pyautogui.typewrite(['a','b','left','left','X','Y']) #按'a'键,'b'键,然后按左箭头两次,然后按'X'和'Y' #输出结果为XYab pyautogui.keyDown() #根据传入的键字符串,向计算机发送虚拟的按键(按下) pyautogui.keyUp() #根据传入的键字符串,向计算机发送虚拟的释放(释放) pyautogui.press() #前面两个函数的封装,模拟完整的击键(按下并释放)举例:pyautogui.keyDown('shift');pyautogui.press('4');pyautogui.keyUp('shift') #按下Shift,按下并释放4,然后释放Shift完整的键字符串如下:键盘键字符串 含义 'a','b','c','A','C','1','2','3', 单个字符的键 '!','@','#'等 'enter' 回车 ‘esc' ESC键 'shiftleft','shiftright' 左右Shift键 'altleft','altright' 左右Alt键 'ctrlleft','ctrlright' 左右Ctrl键 ‘tab'(or '\t') Tab键 'backspace','delete' Backspace键和Delete键 'pageup','pagedown' Page Up 和Page Down键 'home','end' Home键和End键 'up','down','left','right' 上下左右箭头键 'f1','f2','f3'等 F1至F12键 'volumemute','volumeup',volumedown' 静音,放大音量和减小音量键 'pause' 暂停键 'capslock','numlock','scrolllock' Caps Lock,Num Lock和 Scroll Lock键 'insert' Insert键 'printscreen' Prtsc或Print Screen键 'winleft','winright' 左右Win键(在windows上) 'command' Command键(在OS X上) 'option' Option键(在OS X上)快捷键组合pyautogui.hotkey() #接收多个字符串参数,顺序按下,再按相反的顺序释放举例:pyautogui.hotkey('ctrl','c') #按住Ctrl键,然后按C键,然后释放C键和Ctrl键 相当于 pyautogui.keyDown('ctrl') pyautogui.keyDown('c') pyautogui.keyUp('c') pyautogui.keyUp('ctrl')参考资料Python键鼠操作自动化库PyAutoGUI简介PyAutoGUI——图形用户界面自动化