搜索到
32
篇与
的结果
-
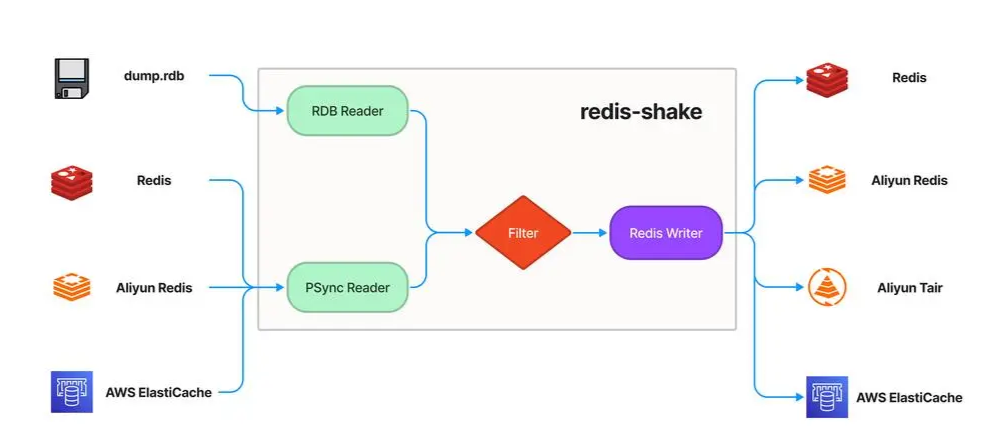
 RedisShake:redis全量/增量数据同步/迁移工具 1.概述RedisShake 是一个用于处理和迁移 Redis 数据的工具,它提供以下特性:Redis 兼容性:RedisShake 兼容从 2.8 到 7.2 的 Redis 版本,并支持各种部署方式,包括单机,主从,哨兵和集群。云服务兼容性:RedisShake 与主流云服务提供商提供的流行 Redis-like 数据库无缝工作,包括但不限于:阿里云-云数据库 Redis 版阿里云-云原生内存数据库TairAWS - ElastiCacheAWS - MemoryDBModule 兼容:RedisShake 与 TairString,TairZSet 和 TairHash 模块兼容。多种导出模式:RedisShake 支持 PSync,RDB 和 Scan 导出模式。数据处理:RedisShake 通过自定义脚本实现数据过滤和转换。RedisShake 支持三种模式的数据同步方式:2.下载安装下载地址:Releases · tair-opensource/RedisShake (github.com)wget https://github.com/tair-opensource/RedisShake/releases/download/v4.1.1/redis-shake-linux-amd64.tar.gz mkdir redis-shake tar xzvf redis-shake-linux-amd64.tar.gz -C redis-shake mv redis-shake /software/ cd /software/redis-shake/3.配置介绍一般用法下,只需要书写 xxx_reader、xxx_writer 两个部分即可sync_reader[sync_reader] cluster = false # set to true if source is a redis cluster address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "" # keep empty if no authentication is required tls = false sync_rdb = true # set to false if you don't want to sync rdb sync_aof = true # set to false if you don't want to sync aofcluster:源端是否为集群address:源端地址, 当源端为集群时,address 为集群中的任意一个节点即可鉴权:当源端使用 ACL 账号时,配置 username 和 password当源端使用传统账号时,仅配置 password当源端无鉴权时,不配置 username 和 passwordtls:源端是否开启 TLS/SSL,不需要配置证书因为 RedisShake 没有校验服务器证书sync_rdb:是否同步 RDB,设置为 false 时,RedisShake 会跳过全量同步阶段sync_aof:是否同步 AOF,设置为 false 时,RedisShake 会跳过增量同步阶段,此时 RedisShake 会在全量同步阶段结束后退出Redis Writerredis_writer 用于将数据写入 Redis-like 数据库。[redis_writer] cluster = false address = "127.0.0.1:6379" # when cluster is true, address is one of the cluster node username = "" # keep empty if not using ACL password = "" # keep empty if no authentication is required tls = falsecluster:是否为集群。address:连接地址。当目的端为集群时,address 填写集群中的任意一个节点即可鉴权:当使用 ACL 账号体系时,配置 username 和 password当使用传统账号体系时,仅配置 password当无鉴权时,不配置 username 和 passwordtls:是否开启 TLS/SSL,不需要配置证书因为 RedisShake 没有校验服务器证书注意事项:当目的端为集群时,应保证源端发过来的命令满足 Key 的哈希值属于同一个 slot。应尽量保证目的端版本大于等于源端版本,否则可能会出现不支持的命令。如确实需要降低版本,可以设置 target_redis_proto_max_bulk_len 为 0,来避免使用 restore 命令恢4 实战1- 单节点向一个一主一从伪集群发起同步4.1 配置文件vim shake.toml[sync_reader] cluster = false # set to true if source is a redis cluster address = "192.168.124.16:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "123456" # keep empty if no authentication is required tls = false # sync_rdb = true # set to false if you don't want to sync rdb sync_aof = true # set to false if you don't want to sync aof prefer_replica = false # set to true if you want to sync from replica node try_diskless = false # set to true if you want to sync by socket and source repl-diskless-sync=yes [redis_writer] cluster = false # set to true if target is a redis cluster sentinel = false # set to true if target is a redis sentinel master = "" # set to master name if target is a redis sentinel address = "192.168.124.17:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "123456" # keep empty if no authentication is required tls = false off_reply = false # ture off the server reply4.2 发起同步测试nohup ./redis-shake shake.toml &待同步节点写入数据[root@localhost redis-shake]# redis-cli -h 192.168.124.16 -p 6379 192.168.124.16:6379> auth 123456 OK 192.168.124.16:6379> set key1 value1 OK 192.168.124.16:6379> set key2 value2 OK同步节点读取测试[root@localhost redis]# redis-cli -h 192.168.124.17 -p 6379 192.168.124.17:6379> auth 123456 OK 192.168.124.17:6379> get key1 "value1" 192.168.124.17:6379> get key2 "value2" 192.168.124.17:6379>参考资料RedisShake (tair-opensource.github.io)【redis数据同步】redis-shake数据同步全量+增量-CSDN博客redis-shake数据同步&迁移&备份导入导出工具使用介绍-阿里云开发者社区 (aliyun.com)什么是 RedisShake | RedisShake (tair-opensource.github.io)GitHub - tair-opensource/RedisShake: RedisShake is a Redis data processing and migration tool.
RedisShake:redis全量/增量数据同步/迁移工具 1.概述RedisShake 是一个用于处理和迁移 Redis 数据的工具,它提供以下特性:Redis 兼容性:RedisShake 兼容从 2.8 到 7.2 的 Redis 版本,并支持各种部署方式,包括单机,主从,哨兵和集群。云服务兼容性:RedisShake 与主流云服务提供商提供的流行 Redis-like 数据库无缝工作,包括但不限于:阿里云-云数据库 Redis 版阿里云-云原生内存数据库TairAWS - ElastiCacheAWS - MemoryDBModule 兼容:RedisShake 与 TairString,TairZSet 和 TairHash 模块兼容。多种导出模式:RedisShake 支持 PSync,RDB 和 Scan 导出模式。数据处理:RedisShake 通过自定义脚本实现数据过滤和转换。RedisShake 支持三种模式的数据同步方式:2.下载安装下载地址:Releases · tair-opensource/RedisShake (github.com)wget https://github.com/tair-opensource/RedisShake/releases/download/v4.1.1/redis-shake-linux-amd64.tar.gz mkdir redis-shake tar xzvf redis-shake-linux-amd64.tar.gz -C redis-shake mv redis-shake /software/ cd /software/redis-shake/3.配置介绍一般用法下,只需要书写 xxx_reader、xxx_writer 两个部分即可sync_reader[sync_reader] cluster = false # set to true if source is a redis cluster address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "" # keep empty if no authentication is required tls = false sync_rdb = true # set to false if you don't want to sync rdb sync_aof = true # set to false if you don't want to sync aofcluster:源端是否为集群address:源端地址, 当源端为集群时,address 为集群中的任意一个节点即可鉴权:当源端使用 ACL 账号时,配置 username 和 password当源端使用传统账号时,仅配置 password当源端无鉴权时,不配置 username 和 passwordtls:源端是否开启 TLS/SSL,不需要配置证书因为 RedisShake 没有校验服务器证书sync_rdb:是否同步 RDB,设置为 false 时,RedisShake 会跳过全量同步阶段sync_aof:是否同步 AOF,设置为 false 时,RedisShake 会跳过增量同步阶段,此时 RedisShake 会在全量同步阶段结束后退出Redis Writerredis_writer 用于将数据写入 Redis-like 数据库。[redis_writer] cluster = false address = "127.0.0.1:6379" # when cluster is true, address is one of the cluster node username = "" # keep empty if not using ACL password = "" # keep empty if no authentication is required tls = falsecluster:是否为集群。address:连接地址。当目的端为集群时,address 填写集群中的任意一个节点即可鉴权:当使用 ACL 账号体系时,配置 username 和 password当使用传统账号体系时,仅配置 password当无鉴权时,不配置 username 和 passwordtls:是否开启 TLS/SSL,不需要配置证书因为 RedisShake 没有校验服务器证书注意事项:当目的端为集群时,应保证源端发过来的命令满足 Key 的哈希值属于同一个 slot。应尽量保证目的端版本大于等于源端版本,否则可能会出现不支持的命令。如确实需要降低版本,可以设置 target_redis_proto_max_bulk_len 为 0,来避免使用 restore 命令恢4 实战1- 单节点向一个一主一从伪集群发起同步4.1 配置文件vim shake.toml[sync_reader] cluster = false # set to true if source is a redis cluster address = "192.168.124.16:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "123456" # keep empty if no authentication is required tls = false # sync_rdb = true # set to false if you don't want to sync rdb sync_aof = true # set to false if you don't want to sync aof prefer_replica = false # set to true if you want to sync from replica node try_diskless = false # set to true if you want to sync by socket and source repl-diskless-sync=yes [redis_writer] cluster = false # set to true if target is a redis cluster sentinel = false # set to true if target is a redis sentinel master = "" # set to master name if target is a redis sentinel address = "192.168.124.17:6379" # when cluster is true, set address to one of the cluster node username = "" # keep empty if not using ACL password = "123456" # keep empty if no authentication is required tls = false off_reply = false # ture off the server reply4.2 发起同步测试nohup ./redis-shake shake.toml &待同步节点写入数据[root@localhost redis-shake]# redis-cli -h 192.168.124.16 -p 6379 192.168.124.16:6379> auth 123456 OK 192.168.124.16:6379> set key1 value1 OK 192.168.124.16:6379> set key2 value2 OK同步节点读取测试[root@localhost redis]# redis-cli -h 192.168.124.17 -p 6379 192.168.124.17:6379> auth 123456 OK 192.168.124.17:6379> get key1 "value1" 192.168.124.17:6379> get key2 "value2" 192.168.124.17:6379>参考资料RedisShake (tair-opensource.github.io)【redis数据同步】redis-shake数据同步全量+增量-CSDN博客redis-shake数据同步&迁移&备份导入导出工具使用介绍-阿里云开发者社区 (aliyun.com)什么是 RedisShake | RedisShake (tair-opensource.github.io)GitHub - tair-opensource/RedisShake: RedisShake is a Redis data processing and migration tool. -
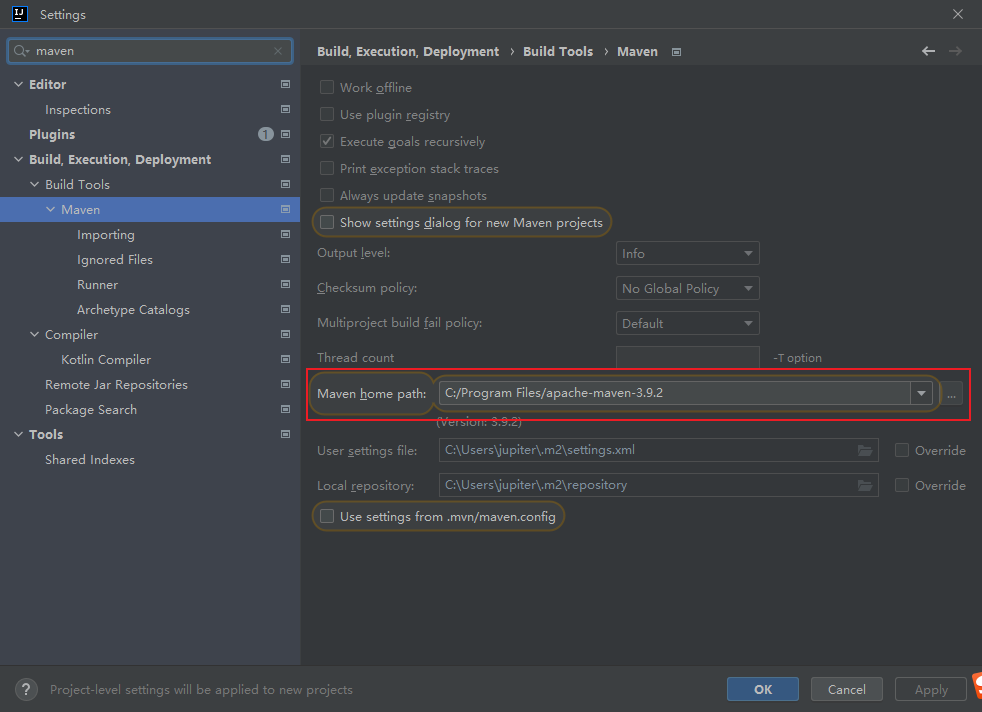
CenterOS7安装Maven 1.安装java环境参考:CenterOS7安装java环境 - jupiter's blog (inat.top)2.下载maven并解压下载地址:https://maven.apache.org/download.cgiwget https://dlcdn.apache.org/maven/maven-3/3.9.8/binaries/apache-maven-3.9.8-bin.tar.gztar xzvf apache-maven-3.9.8-bin.tar.gz创建本地仓库文件夹cd apache-maven-3.9.8 mkdir repository3.配置环境变量vim ~/.bashrc# 配置maven_home和Path环境变量 export MAVEN_HOME=/software/apache-maven-3.9.8 export PATH=$PATH:$MAVEN_HOME/bin # 配置本地仓库地址环境变量 export M2_HOME=/software/apache-maven-3.9.8/repositorysource ~/.bashrc4.配置镜像源vim conf/settings.xml# 在<mirrors></mirrors>标签中添加 mirror 子节点 <!-- 阿里云仓库 --> <mirror> <id>alimaven</id> <mirrorOf>central</mirrorOf> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/repositories/central/</url> </mirror>5.检查是否安装成功[root@localhost apache-maven-3.9.8]# mvn --version Apache Maven 3.9.8 (36645f6c9b5079805ea5009217e36f2cffd34256) Maven home: /software/apache-maven-3.9.8 Java version: 17.0.11, vendor: Eclipse Adoptium, runtime: /software/jdk17 Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-1160.119.1.el7.x86_64", arch: "amd64", family: "unix"参考资料CenterOS7安装java环境 - jupiter's blog (inat.top)Maven超细致史上最全Maven下载安装配置教学(2023更新...全版本)建议收藏...赠送IDEA配置Maven教程-CSDN博客
-
SpringBoot启动后执行方法 0.主启动类public class HikariDataSourceApplication { public static void main(String[] args) { SpringApplication.run(HikariDataSourceApplication.class, args); System.out.println("项目启动成功====================================="); } }1.@PostConstruct 注解在项目初始化过程中,就会调用此方法。如果业务逻辑执行很耗时,可能会导致项目启动失败。import jakarta.annotation.PostConstruct; import org.springframework.stereotype.Component; @Component public class StartInit1 { @PostConstruct public void init() { System.out.println("@PostConstruct==============================="); } }2024-06-22T22:51:22.978+08:00 INFO 18120 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http) 2024-06-22T22:51:22.990+08:00 INFO 18120 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-06-22T22:51:22.990+08:00 INFO 18120 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24] 2024-06-22T22:51:23.023+08:00 INFO 18120 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-06-22T22:51:23.024+08:00 INFO 18120 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 668 ms @PostConstruct=============================== 2024-06-22T22:51:23.303+08:00 WARN 18120 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2024-06-22T22:51:23.304+08:00 INFO 18120 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2024-06-22T22:51:23.391+08:00 INFO 18120 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@46468f0 2024-06-22T22:51:23.393+08:00 INFO 18120 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2024-06-22T22:51:23.503+08:00 INFO 18120 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/' 2024-06-22T22:51:23.509+08:00 INFO 18120 --- [ main] c.e.h.HikariDataSourceApplication : Started HikariDataSourceApplication in 1.415 seconds (process running for 1.729) 项目启动成功=====================================2.实现 CommandLineRunner 接口项目初始化完毕后,才会调用方法,提供服务import org.springframework.boot.CommandLineRunner; import org.springframework.stereotype.Component; @Component public class StartInit2 implements CommandLineRunner { @Override public void run(String... args) { System.out.println("CommandLineRunner===================="); } }2024-06-22T22:54:34.798+08:00 INFO 14312 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http) 2024-06-22T22:54:34.806+08:00 INFO 14312 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-06-22T22:54:34.806+08:00 INFO 14312 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24] 2024-06-22T22:54:34.845+08:00 INFO 14312 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-06-22T22:54:34.845+08:00 INFO 14312 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 660 ms 2024-06-22T22:54:35.128+08:00 WARN 14312 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2024-06-22T22:54:35.128+08:00 INFO 14312 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2024-06-22T22:54:35.214+08:00 INFO 14312 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@3a0b6a 2024-06-22T22:54:35.215+08:00 INFO 14312 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2024-06-22T22:54:35.324+08:00 INFO 14312 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/' 2024-06-22T22:54:35.328+08:00 INFO 14312 --- [ main] c.e.h.HikariDataSourceApplication : Started HikariDataSourceApplication in 1.408 seconds (process running for 1.722) CommandLineRunner==================== 项目启动成功===================================== 3.实现 ApplicationRunner 接口同 CommandLineRunner。只是传参格式不一样。CommandLineRunner:没有任何限制;ApplicationRunner:key-valueimport org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.stereotype.Component; @Component public class StartInit3 implements ApplicationRunner { @Override public void run(ApplicationArguments args) { System.out.println("ApplicationRunner================="); } }2024-06-22T22:57:50.064+08:00 INFO 19228 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http) 2024-06-22T22:57:50.071+08:00 INFO 19228 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-06-22T22:57:50.071+08:00 INFO 19228 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24] 2024-06-22T22:57:50.105+08:00 INFO 19228 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-06-22T22:57:50.105+08:00 INFO 19228 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 670 ms 2024-06-22T22:57:50.386+08:00 WARN 19228 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2024-06-22T22:57:50.387+08:00 INFO 19228 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2024-06-22T22:57:50.481+08:00 INFO 19228 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@539c4830 2024-06-22T22:57:50.483+08:00 INFO 19228 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2024-06-22T22:57:50.601+08:00 INFO 19228 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/' 2024-06-22T22:57:50.606+08:00 INFO 19228 --- [ main] c.e.h.HikariDataSourceApplication : Started HikariDataSourceApplication in 1.439 seconds (process running for 1.755) ApplicationRunner================= 项目启动成功=====================================4.实现 ApplicationListener 接口项目初始化完毕后,才会调用方法,提供服务。注意监听的事件,通常是 ApplicationStartedEvent 或者 ApplicationReadyEvent,其他的事件可能无法注入 bean。如果监听的是 ApplicationStartedEvent 事件,则 ApplicationListener 一定会在 CommandLineRunner 和 ApplicationRunner 之前执行;如果监听的是 ApplicationReadyEvent 事件,则 ApplicationListener 一定会在 CommandLineRunner 和import org.springframework.boot.context.event.ApplicationStartedEvent; import org.springframework.context.ApplicationListener; import org.springframework.stereotype.Component; @Component public class StartInit4 implements ApplicationListener<ApplicationStartedEvent> { @Override public void onApplicationEvent(ApplicationStartedEvent event) { System.out.println("ApplicationListener================ApplicationStartedEvent"); } }2024-06-22T23:01:14.615+08:00 INFO 21164 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http) 2024-06-22T23:01:14.627+08:00 INFO 21164 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-06-22T23:01:14.628+08:00 INFO 21164 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24] 2024-06-22T23:01:14.661+08:00 INFO 21164 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-06-22T23:01:14.661+08:00 INFO 21164 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 683 ms 2024-06-22T23:01:14.942+08:00 WARN 21164 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2024-06-22T23:01:14.942+08:00 INFO 21164 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2024-06-22T23:01:15.027+08:00 INFO 21164 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@6486fe7b 2024-06-22T23:01:15.028+08:00 INFO 21164 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2024-06-22T23:01:15.133+08:00 INFO 21164 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/' 2024-06-22T23:01:15.138+08:00 INFO 21164 --- [ main] c.e.h.HikariDataSourceApplication : Started HikariDataSourceApplication in 1.429 seconds (process running for 1.752) ApplicationListener================ApplicationStartedEvent 项目启动成功=====================================5.执行顺序2024-06-22T23:03:22.206+08:00 INFO 19432 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-06-22T23:03:22.207+08:00 INFO 19432 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24] 2024-06-22T23:03:22.244+08:00 INFO 19432 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-06-22T23:03:22.244+08:00 INFO 19432 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 613 ms @PostConstruct=============================== 2024-06-22T23:03:22.519+08:00 WARN 19432 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2024-06-22T23:03:22.519+08:00 INFO 19432 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2024-06-22T23:03:22.604+08:00 INFO 19432 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection com.mysql.cj.jdbc.ConnectionImpl@3e14d390 2024-06-22T23:03:22.605+08:00 INFO 19432 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2024-06-22T23:03:22.708+08:00 INFO 19432 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/' 2024-06-22T23:03:22.716+08:00 INFO 19432 --- [ main] c.e.h.HikariDataSourceApplication : Started HikariDataSourceApplication in 1.317 seconds (process running for 1.573) ApplicationListener================ApplicationReadyEvent ApplicationRunner================= CommandLineRunner==================== ApplicationListener================ApplicationReadyEvent 项目启动成功=====================================参考资料【SpringBoot】 启动后执行方法的五种方式_springboot启动后执行某个方法-CSDN博客Springboot启动后执行方法的四种方式_springboot 启动执行方法-CSDN博客
-
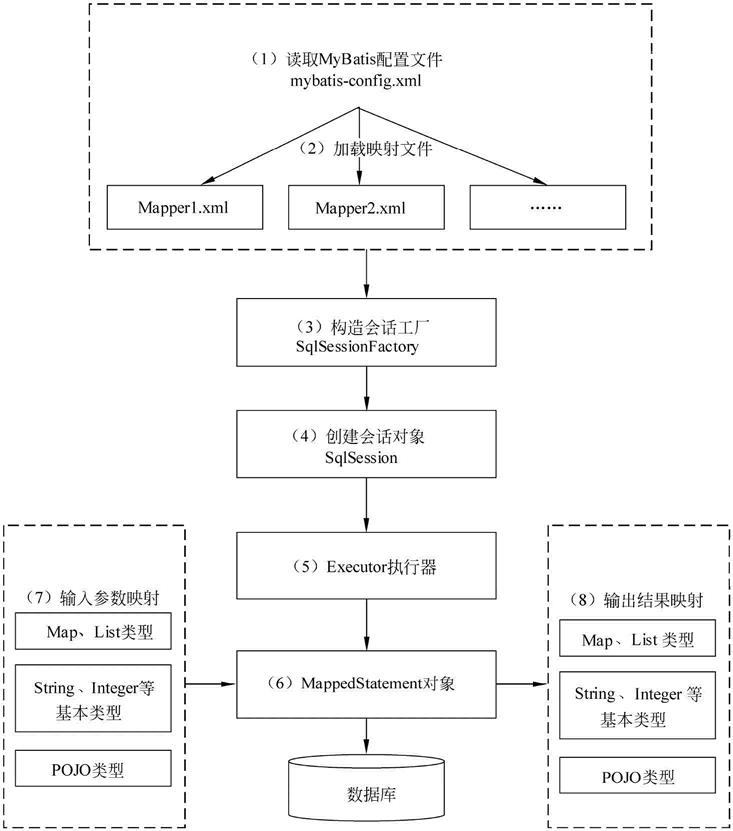
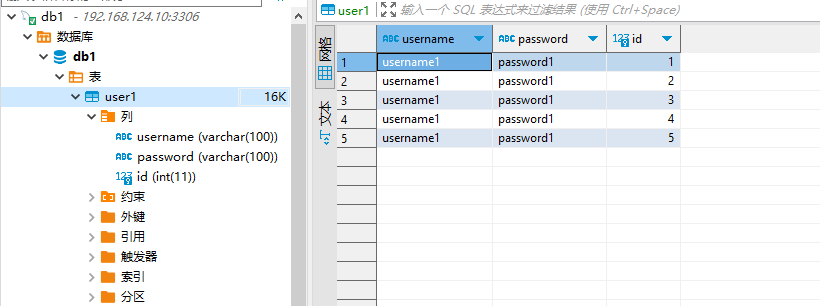
MyBatis的工作原理和SpringBoot快速集成Mybatis(极简) 1.MyBatis的工作原理1.1、传统的JDBC编程JAVA程序通过JDBC链接数据库,这样我们就可以通过SQL对数据库进行编程。JAVA链接数据库大致分为五步,如下所示:1、使用JDBC编程需要链接数据库,注册驱动和数据库信息。2、操作Connection,打开Statement对象。3、通过Statement执行SQL语句,返回结果放到ResultSet对象。4、使用ResultSet读取数据。5、关闭数据库相关的资源。JDBC 代码示例:import java.sql.*; public class JdbcDemo { public static void main(String[] args) throws SQLException, ClassNotFoundException { String username = "db1"; String password = "db1"; String url = "jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai"; // 使用JDBC编程需要链接数据库,注册驱动和数据库信息。 Connection conn = DriverManager.getConnection(url,username,password); // 编写待执行sql String sql = "select * from user1"; // 通过Statement执行SQL语句,返回结果放到ResultSet对象。 PreparedStatement preparedStatement = conn.prepareStatement(sql); ResultSet rs = preparedStatement.executeQuery(); //使用ResultSet读取数据。 // 获取 ResultSetMetadata 对象,它包含了 ResultSet 的结构信息 ResultSetMetaData metaData = rs.getMetaData(); // 打印列名 for (int i = 1; i <= metaData.getColumnCount(); i++) { System.out.print(metaData.getColumnName(i) + "\t"); } System.out.println(); // 换行 // 遍历 ResultSet 并打印数据 while (rs.next()) { for (int i = 1; i <= metaData.getColumnCount(); i++) { System.out.print(rs.getString(i) + "\t"); } System.out.println(); // 每行数据后换行 } // 关闭数据库相关的资源。 preparedStatement.close(); conn.close(); } }传统的JDBC方式存在一些弊端:(1)工作量比较大。我们需要先建立链接,然后处理JDBC底层业务,处理数据类型。我们还需要处理Connection对象,Statement对象和Result对象去拿数据,并关闭它们。(2)我们对JDBC编程处理的异常进行捕获处理并正确的关闭资源。1.2、MyBatis工作原理:对JDBC进行了封装MyBatis的四大核心组件:1、SQLSessionFactoryBuilder(构造器):它会根据配置信息或者代码生成SqlSessionFactory。2、SqlSessionFactory(工厂接口):依靠工厂生成SqlSession。3、SqlSession(会话):是一个既可以发送SQL去执行并且返回结果,也可以获取Mapper接口。4、SQL Mapper:是由一个JAVA接口和XML文件(或注解)构成,需要给出对应的SQL和映射规则。SQL是由Mapper发送出去,并且返回结果。MyBatis工作原理示意图:从上面的流程图可以看出MyBatis和JDBC的执行时相似的。MyBatis的底层操作封装了JDBC的API,MyBatis的工作原理以及核心流程与JDBC的使用步骤一脉相承,MyBatis的核心对象(SqlSession,Executor)与JDBC的核心对象(Connection,Statement)相互对应。1.3 @Mapper执行sql原理Mapper 接口与 @Mapper 注解:Mapper 接口是用户定义的,其中包含了与数据库表交互的方法。@Mapper 注解是 MyBatis-Spring 集成库中的一个注解,用于标识一个接口作为 MyBatis 的 Mapper 接口。当接口被 @Mapper 注解标记后,MyBatis 会自动为这个接口创建一个代理实现类。MyBatis 映射器(Mapper)的代理实现:MyBatis 使用 Java 动态代理技术为 Mapper 接口创建代理实现类。代理实现类会拦截对 Mapper 接口方法的调用,并根据方法的定义(包括方法名、参数等)来查找并执行相应的 SQL 语句。SQL 语句的查找与执行:MyBatis 会在配置的 SQL 映射文件(通常是 XML 文件)中查找与 Mapper 接口方法对应的 SQL 语句。SQL 映射文件定义了 Mapper 接口中每个方法对应的 SQL 语句,包括查询、插入、更新、删除等操作。MyBatis 会根据 Mapper 接口方法的定义和 SQL 映射文件中的配置,生成具体的 SQL 语句并执行。@Param 注解与参数绑定:如果 Mapper 接口方法中有参数,可以使用 @Param 注解来指定参数名。MyBatis 会根据 @Param 注解指定的参数名,在 SQL 语句中进行参数绑定。参数绑定是将 Java 对象的属性值或方法参数值设置到 SQL 语句的占位符中的过程。结果映射与返回类型:MyBatis 会根据 Mapper 接口方法的返回类型,将 SQL 语句执行的结果映射为相应的 Java 对象或集合。结果映射可以在 XML 映射文件中进行配置,包括结果集的列名与 Java 对象属性的对应关系等。Spring 集成与 SqlSessionTemplate:在 Spring 与 MyBatis 的集成中,SqlSessionTemplate 是一个关键的组件。SqlSessionTemplate 封装了 SqlSession 的使用,并提供了线程安全的 SQL 执行环境。当通过 Spring 容器注入 Mapper 接口时,实际上注入的是 SqlSessionTemplate 创建的 Mapper 代理实现类的实例。总结:@Mapper 注解使得 MyBatis 能够自动为 Mapper 接口创建代理实现类。MyBatis 通过动态代理和 SQL 映射文件来执行 Mapper 接口中定义的 SQL 语句。Spring 集成通过 SqlSessionTemplate 提供了线程安全的 SQL 执行环境,并简化了 Mapper 接口的注入和使用。2.MyBatis的优点MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。MyBatis是对JDBC的封装。相对于JDBC,MyBatis有以下优点:SQL映射:MyBatis 支持定制化 SQL、存储过程以及高级映射。它允许你直接在 XML 映射文件中编写 SQL 语句,或者使用注解的方式将 SQL 语句直接写在 Mapper 接口的方法上。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的麻烦,极大地简化了数据库操作。对象关系映射(ORM):MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java 对象)映射成数据库中的记录。提供了映射标签,支持对象与数据库的 ORM 字段关系映射,降低了耦合度,提高了代码的复用性和可维护性。动态SQL:MyBatis 提供了 XML 标签,支持编写动态 SQL 语句。你可以根据传入参数的不同,动态地生成不同的 SQL 语句,实现更复杂的数据库操作。事务管理:MyBatis 通过与 Spring 等框架的集成,提供了完整的事务管理功能。它支持编程式事务和声明式事务,可以确保数据的一致性。插件机制:MyBatis 提供了插件机制,允许你通过编写插件来扩展 MyBatis 的功能。例如,你可以编写一个插件来拦截 SQL 语句的执行,进行日志记录、性能监控等操作。缓存机制:MyBatis 提供了一级缓存(SqlSession 级别的缓存)和二级缓存(Mapper 级别的缓存)来提高查询性能。一级缓存默认是开启的,而二级缓存需要手动开启并进行配置。3.快速集成步骤3.1 引入mybatis-starter依赖<!-- mybatis --> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>3.0.3</version> </dependency>其他必备依赖<!-- springboot基础依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>3.3.0</version> </dependency> <!-- mysql数据库连接驱动--> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> </dependency> <!-- 引入Spring封装的jdbc,内部默认依赖了 HikariDataSource 数据源--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jdbc</artifactId> </dependency> <!-- lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.32</version> </dependency>测试辅助依赖<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <version>3.3.0</version> </dependency>3.2 配置数据源在 application.properties 或 application.yml 文件中配置你的数据源(如MySQL)。spring: #配置数据源 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai username: db1 password: db1 type: com.zaxxer.hikari.HikariDataSource hikari: # 连接池最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size minimum-idle: 10 # 连接池最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值。 maximum-pool-size: 20 # 连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短 max-lifetime: 600000 # 空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。 idle-timeout: 600000 # 连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒,如果在这个时间内无法建立连接,将会抛出异常。 connection-timeout: 30000 mybatis: mapper-locations: classpath:mapper/*.xml type-aliases-package: com.example.hikaridatasource.domain.entity3.3 创建数据源和Mybatis必备bean的Config文件@Configuration public class Db1DataSourceConfig { // jdbc连接信息 @Value(value = "${spring.datasource.url:}") private String url; @Value(value = "${spring.datasource.username:}") private String username; @Value(value = "${spring.datasource.password:}") private String password; @Value(value = "${spring.datasource.driver-class-name:}") private String driveClassName; // HikariDataSource配置参数 // 连接池最小空闲连接,默认值10 @Value(value = "${spring.datasource.hikari.minimum-idle:10}") private int minimumIdle; // 连接池最大连接数,默认值10 @Value(value = "${spring.datasource.hikari.maximum-pool-size:10}") private int maximumPoolSize; // 连接最大存活时间,默认值30分钟.设置应该比mysql设置的超时时间短,配置单位毫秒 @Value(value = "${spring.datasource.hikari.max-lifetime:600000}") private long maxLifetime; // 空闲连接超时时间,默认值600000(10分钟)配置单位毫秒 @Value(value = "${spring.datasource.hikari.idle-timeout:600000}") private long idleTimeout; // 连接超时时间,配置单位毫秒 @Value(value = "${spring.datasource.hikari.connection-timeout:60000}") private long connectionTimeout; // mybatis配置 // mapperXml文件地址 @Value(value = "${spring.datasource.hikari.mapper-locations:}") private String mapperLocations; /** * 配置db1 数据源 */ @Bean(name = "db1DataSource") public DataSource db1DataSource(){ HikariDataSource dataSource = new HikariDataSource(); // 设置jdbc连接信息 dataSource.setJdbcUrl(url); dataSource.setUsername(username); dataSource.setPassword(password); dataSource.setDriverClassName(driveClassName); // 设置HikariDataSource配置参数 dataSource.setMinimumIdle(minimumIdle); dataSource.setMaximumPoolSize(maximumPoolSize); dataSource.setMaxLifetime(maxLifetime); dataSource.setIdleTimeout(idleTimeout); dataSource.setConnectionTimeout(connectionTimeout); return dataSource; } /** * 配置db1 SqlSessionFactory mybatis必备(实现数据库连接会话管理) */ @Bean(name = "db1SqlSessionFactory") public SqlSessionFactory db1SqlSessionFactory(@Qualifier("db1DataSource") DataSource dataSource) throws Exception { SqlSessionFactoryBean factory = new SqlSessionFactoryBean(); factory.setDataSource(dataSource); // 设置mapperXml文件地址 //factory.setConfigLocation(new PathMatchingResourcePatternResolver().getResource(mapperLocations)); return factory.getObject(); } /** * 配置db1 SqlSessionTemplate mybatis必备(实现数据库连接sql执行和结果映射) */ @Bean(name = "db1SqlSessionTemplate") public SqlSessionTemplate db1SqlSessionTemplate(@Qualifier("db1SqlSessionFactory") SqlSessionFactory sqlSessionFactory){ return new SqlSessionTemplate(sqlSessionFactory); } /** * 配置db1 DataSourceTransactionManager 事务管理器(Spring的JDBC事务增强) */ @Bean(name = "db1DataSourceTransactionManager") public DataSourceTransactionManager db1DataSourceTransactionManager(@Qualifier("db1DataSource") DataSource dataSource) { return new DataSourceTransactionManager(dataSource); } }3.4 创建实体类(Entity)import lombok.Data; import lombok.experimental.Accessors; @Data @Accessors(chain = true) public class User1Entity { private Integer id; private String username; private String password; }3.5 创建 Mapper 接口Mapper 接口用于定义 SQL 语句和数据库交互。import com.example.hikaridatasource.domain.entity.User1Entity; import org.apache.ibatis.annotations.Mapper; import org.apache.ibatis.annotations.Select; import java.util.List; @Mapper public interface User1Mapper { @Select("SELECT * FROM user1") List<User1Entity> selectAllUsers(); }3.6 使用 Mapper测试自动注入Mapper代理对象的方式@SpringBootTest @Slf4j class HikariDataSourceApplicationTests { @Resource User1Mapper user1Mapper1; @Test void contextLoads() throws SQLException { List<User1Entity> user1List1Entity = user1Mapper1.selectAllUsers(); log.info("user1List1={}", user1List1Entity); } }2024-06-22T17:19:15.053+08:00 INFO 15316 --- [ main] c.e.h.HikariDataSourceApplicationTests : user1List1=[User1Entity(id=1, username=username1, password=password1), User1Entity(id=2, username=username1, password=password1), User1Entity(id=3, username=username1, password=password1), User1Entity(id=4, username=username1, password=password1), User1Entity(id=5, username=username1, password=password1)]通过SqlSessionTemplate手动获取Mapper代理对象的方式@SpringBootTest @Slf4j class HikariDataSourceApplicationTests { @Resource SqlSessionTemplate sqlSessionTemplate; @Test void contextLoads() throws SQLException { User1Mapper user1Mapper2 = sqlSessionTemplate.getMapper(User1Mapper.class); List<User1Entity> user1EntityList2 = user1Mapper2.selectAllUsers(); log.info("user1List2={}", user1EntityList2); } }2024-06-22T17:21:11.392+08:00 INFO 8368 --- [ main] c.e.h.HikariDataSourceApplicationTests : user1List2=[User1Entity(id=1, username=username1, password=password1), User1Entity(id=2, username=username1, password=password1), User1Entity(id=3, username=username1, password=password1), User1Entity(id=4, username=username1, password=password1), User1Entity(id=5, username=username1, password=password1)]参考资料MyBatis 入门介绍
-
SpringBoot默认数据源 HikariDataSource使用和配置及DataSource自动装配、手动装配 1.pom依赖 <!-- springboot基础依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <version>3.3.0</version> </dependency> <!-- mysql数据库连接驱动--> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> </dependency> <!-- 引入Spring封装的jdbc,内部默认依赖了 HikariDataSource 数据源--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jdbc</artifactId> </dependency>2.application.yml基本配置spring: #配置数据源 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai username: db1 password: db13.连接测试@SpringBootTest class HikariDataSourceApplicationTests { @Resource DataSource dataSource; @Test void contextLoads() throws SQLException { Connection connection = dataSource.getConnection(); DatabaseMetaData metaData = connection.getMetaData(); System.out.println("数据源>>>>>>" + dataSource.getClass()); System.out.println("连接>>>>>>>>" + connection); System.out.println("连接地址>>>>" + connection.getMetaData().getURL()); System.out.println("驱动名称>>>>" + metaData.getDriverName()); System.out.println("驱动版本>>>>" + metaData.getDriverVersion()); System.out.println("数据库名称>>" + metaData.getDatabaseProductName()); System.out.println("数据库版本>>" + metaData.getDatabaseProductVersion()); System.out.println("连接用户名称>" + metaData.getUserName()); connection.close(); } }数据源>>>>>>class com.zaxxer.hikari.HikariDataSource 连接>>>>>>>>HikariProxyConnection@902348321 wrapping com.mysql.cj.jdbc.ConnectionImpl@14998e21 连接地址>>>>jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai 驱动名称>>>>MySQL Connector/J 驱动版本>>>>mysql-connector-j-8.3.0 (Revision: 805f872a57875f311cb82487efcfb070411a3fa0) 数据库名称>>MySQL 数据库版本>>5.7.44-log 连接用户名称>db1@192.168.124.84.操作数据库测试数据库内容@SpringBootTest class HikariDataSourceApplicationTests { @Resource JdbcTemplate jdbcTemplate; @Test void contextLoads() throws SQLException { String sql = "select * from user1"; List<Map<String, Object>> selectRes = jdbcTemplate.queryForList(sql); System.out.println("selectRes="+selectRes); } } 5.数据源自动配置原理引入spring-boot-starter-data-jdbc后org.springframework.boot.autoconfigure.jdbc下定义的AutoConfiguration相关的类会触发DataSource、JdbcTemplate等的默认装配行为,会读取spring.datasource下的配置执行相关bean的装配引入spring-boot-starter-data-jdbc后不配置spring.datasource相关内容会导致如下异常*************************** APPLICATION FAILED TO START *************************** Description: Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured. Reason: Failed to determine a suitable driver class Action: Consider the following: If you want an embedded database (H2, HSQL or Derby), please put it on the classpath. If you have database settings to be loaded from a particular profile you may need to activate it (no profiles are currently active). Process finished with exit code 1也可以通过在启动类来解除自动配置行为@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) public class HikariDataSourceApplication { public static void main(String[] args) { SpringApplication.run(HikariDataSourceApplication.class, args); } }org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration 数据源配置类作用是根据逻辑判断之后,添加数据源,内部配置了默认使用的数据源是类型是com.zaxxer.hikari.HikariDataSource可以通过 spring.datasource.type 指定自定义的数据源类型,如DruidDataSource对应的配置文件为spring: #配置数据源 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai username: db1 password: db1 type: com.alibaba.druid.pool.DruidDataSource使用该数据源需要引入相关依赖<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.22</version> </dependency>6.HikariDataSource数据源配置参数6.1 常用配置及含义Hikari的配置参数配置为spring.datasource.hikari.*形式。最常用的配置及其参数说明如下spring: #配置数据源 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai username: db1 password: db1 type: com.zaxxer.hikari.HikariDataSource hikari: # 连接池最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size minimum-idle: 10 # 连接池最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值。 maximum-pool-size: 20 # 连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短 max-lifetime: 600000 # 空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。 idle-timeout: 600000 # 连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒,如果在这个时间内无法建立连接,将会抛出异常。 connection-timeout: 300006.2 完整配置参数说明name描述构造器默认值默认配置validate之后的值validate重置autoCommit自动提交从池中返回的连接TRUETRUE–connectionTimeout等待来自池的连接的最大毫秒数SECONDS.toMillis(30) = 3000030000如果小于250毫秒,则被重置回30秒idleTimeout连接允许在池中闲置的最长时间MINUTES.toMillis(10) = 600000600000如果idleTimeout+1秒>maxLifetime 且 maxLifetime>0,则会被重置为0(代表永远不会退出);如果idleTimeout!=0且小于10秒,则会被重置为10秒maxLifetime池中连接最长生命周期MINUTES.toMillis(30) = 18000001800000如果不等于0且小于30秒则会被重置回30分钟connectionTestQuery如果您的驱动程序支持JDBC4,我们强烈建议您不要设置此属性nullnull–minimumIdle池中维护的最小空闲连接数-110minIdle<0或者minIdle>maxPoolSize,则被重置为maxPoolSizemaximumPoolSize池中最大连接数,包括闲置和使用中的连接-110如果maxPoolSize小于1,则会被重置。当minIdle<=0被重置为DEFAULT\_POOL\_SIZE则为10;如果minIdle>0则重置为minIdle的值metricRegistry该属性允许您指定一个 Codahale / Dropwizard MetricRegistry 的实例,供池使用以记录各种指标nullnull–healthCheckRegistry该属性允许您指定池使用的Codahale / Dropwizard HealthCheckRegistry的实例来报告当前健康信息nullnull–poolName连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置nullHikariPool-1–initializationFailTimeout如果池无法成功初始化连接,则此属性控制池是否将 fail fast11–isolateInternalQueries是否在其自己的事务中隔离内部池查询,例如连接活动测试FALSEFALSE–allowPoolSuspension控制池是否可以通过JMX暂停和恢复FALSEFALSE–readOnly从池中获取的连接是否默认处于只读模式FALSEFALSE–registerMbeans是否注册JMX管理Bean(MBeans)FALSEFALSE–catalog为支持 catalog 概念的数据库设置默认 catalogdriver defaultnull–connectionInitSql该属性设置一个SQL语句,在将每个新连接创建后,将其添加到池中之前执行该语句。nullnull–driverClassNameHikariCP将尝试通过仅基于jdbcUrl的DriverManager解析驱动程序,但对于一些较旧的驱动程序,还必须指定driverClassNamenullnull–transactionIsolation控制从池返回的连接的默认事务隔离级别nullnull–validationTimeout连接将被测试活动的最大时间量SECONDS.toMillis(5) = 50005000如果小于250毫秒,则会被重置回5秒leakDetectionThreshold记录消息之前连接可能离开池的时间量,表示可能的连接泄漏00如果大于0且不是单元测试,则进一步判断:(leakDetectionThreshold < SECONDS.toMillis(2) or (leakDetectionThreshold > maxLifetime && maxLifetime > 0),会被重置为0 . 即如果要生效则必须>0,而且不能小于2秒,而且当maxLifetime > 0时不能大于maxLifetimedataSource这个属性允许你直接设置数据源的实例被池包装,而不是让HikariCP通过反射来构造它nullnull–schema该属性为支持模式概念的数据库设置默认模式driver defaultnull–threadFactory此属性允许您设置将用于创建池使用的所有线程的java.util.concurrent.ThreadFactory的实例。nullnull–scheduledExecutor此属性允许您设置将用于各种内部计划任务的java.util.concurrent.ScheduledExecutorService实例nullnull–7.通过Config文件手动创建数据源配置取消自动配置行为@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) public class HikariDataSourceApplication { public static void main(String[] args) { SpringApplication.run(HikariDataSourceApplication.class, args); } }手动创建配置文件package com.example.hikaridatasource.config; import com.zaxxer.hikari.HikariDataSource; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import org.springframework.jdbc.core.JdbcTemplate; import javax.sql.DataSource; @Configuration public class Db1DataSourceConfig { // jdbc连接信息 @Value(value = "${spring.datasource.url:}") private String url; @Value(value = "${spring.datasource.username:}") private String username; @Value(value = "${spring.datasource.password:}") private String password; @Value(value = "${spring.datasource.driver-class-name:}") private String driveClassName; // HikariDataSource配置参数 // 连接池最小空闲连接,默认值10 @Value(value = "${spring.datasource.hikari.minimum-idle:10}") private int minimumIdle; // 连接池最大连接数,默认值10 @Value(value = "${spring.datasource.hikari.maximum-pool-size:10}") private int maximumPoolSize; // 连接最大存活时间,默认值30分钟.设置应该比mysql设置的超时时间短,配置单位毫秒 @Value(value = "${spring.datasource.hikari.max-lifetime:600000}") private long maxLifetime; // 空闲连接超时时间,默认值600000(10分钟)配置单位毫秒 @Value(value = "${spring.datasource.hikari.idle-timeout:600000}") private long idleTimeout; // 连接超时时间,配置单位毫秒 @Value(value = "${spring.datasource.hikari.connection-timeout:60000}") private long connectionTimeout; @Bean(name = "db1DataSource") @Primary public DataSource db1DataSource(){ HikariDataSource dataSource = new HikariDataSource(); // 设置jdbc连接信息 dataSource.setJdbcUrl(url); dataSource.setUsername(username); dataSource.setPassword(password); dataSource.setDriverClassName(driveClassName); // 设置HikariDataSource配置参数 dataSource.setMinimumIdle(minimumIdle); dataSource.setMaximumPoolSize(maximumPoolSize); dataSource.setMaxLifetime(maxLifetime); dataSource.setIdleTimeout(idleTimeout); dataSource.setConnectionTimeout(connectionTimeout); return dataSource; } @Bean(name = "db1JdbcTemplate") @Primary public JdbcTemplate db1JdbcTemplate(@Qualifier("db1DataSource") DataSource dataSource){ return new JdbcTemplate(dataSource); } }application.ymlspring: #配置数据源 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai username: db1 password: db1 type: com.zaxxer.hikari.HikariDataSource hikari: # 连接池最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size minimum-idle: 10 # 连接池最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值。 maximum-pool-size: 20 # 空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。 idle-timeout: 600000 # 连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短 max-lifetime: 600000 # 连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒,如果在这个时间内无法建立连接,将会抛出异常。 connection-timeout: 60000连接测试测试数据源@SpringBootTest class HikariDataSourceApplicationTests { @Resource DataSource dataSource; @Test void contextLoads() throws SQLException { Connection connection = dataSource.getConnection(); DatabaseMetaData metaData = connection.getMetaData(); System.out.println("数据源>>>>>>" + dataSource.getClass()); System.out.println("连接>>>>>>>>" + connection); System.out.println("连接地址>>>>" + connection.getMetaData().getURL()); System.out.println("驱动名称>>>>" + metaData.getDriverName()); System.out.println("驱动版本>>>>" + metaData.getDriverVersion()); System.out.println("数据库名称>>" + metaData.getDatabaseProductName()); System.out.println("数据库版本>>" + metaData.getDatabaseProductVersion()); System.out.println("连接用户名称>" + metaData.getUserName()); System.out.println("连接超时时间>" + dataSource.getLoginTimeout() + "s"); connection.close(); } }数据源>>>>>>class com.zaxxer.hikari.HikariDataSource 连接>>>>>>>>HikariProxyConnection@42898626 wrapping com.mysql.cj.jdbc.ConnectionImpl@62b790a5 连接地址>>>>jdbc:mysql://192.168.124.10:3306/db1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai 驱动名称>>>>MySQL Connector/J 驱动版本>>>>mysql-connector-j-8.3.0 (Revision: 805f872a57875f311cb82487efcfb070411a3fa0) 数据库名称>>MySQL 数据库版本>>5.7.44-log 连接用户名称>db1@192.168.124.8 连接超时时间>60s操作数据源测试@SpringBootTest class HikariDataSourceApplicationTests { @Resource JdbcTemplate jdbcTemplate; @Test void contextLoads() throws SQLException { String sql = "select * from user1"; List<Map<String, Object>> selectRes = jdbcTemplate.queryForList(sql); System.out.println("selectRes="+selectRes); } }selectRes=[{username=username1, password=password1, id=1}, {username=username1, password=password1, id=2}, {username=username1, password=password1, id=3}, {username=username1, password=password1, id=4}, {username=username1, password=password1, id=5}]参考资料Spring Boot 如何通过jdbc+HikariDataSource 完成对Mysql 操作_hikaridatasource mysql-CSDN博客Spring Boot 默认数据源 HikariDataSource 与 JdbcTemplate 初遇-CSDN博客SpringBoot - 数据源注入 及其 自动配置原理_springboot 注入datasource-CSDN博客Spring Boot 2.x基础教程:默认数据源Hikari的配置详解 - 程序猿DD - 博客园 (cnblogs.com)Spring Boot 如何通过jdbc+HikariDataSource 完成对Mysql 操作_hikaridatasource mysql-CSDN博客
-
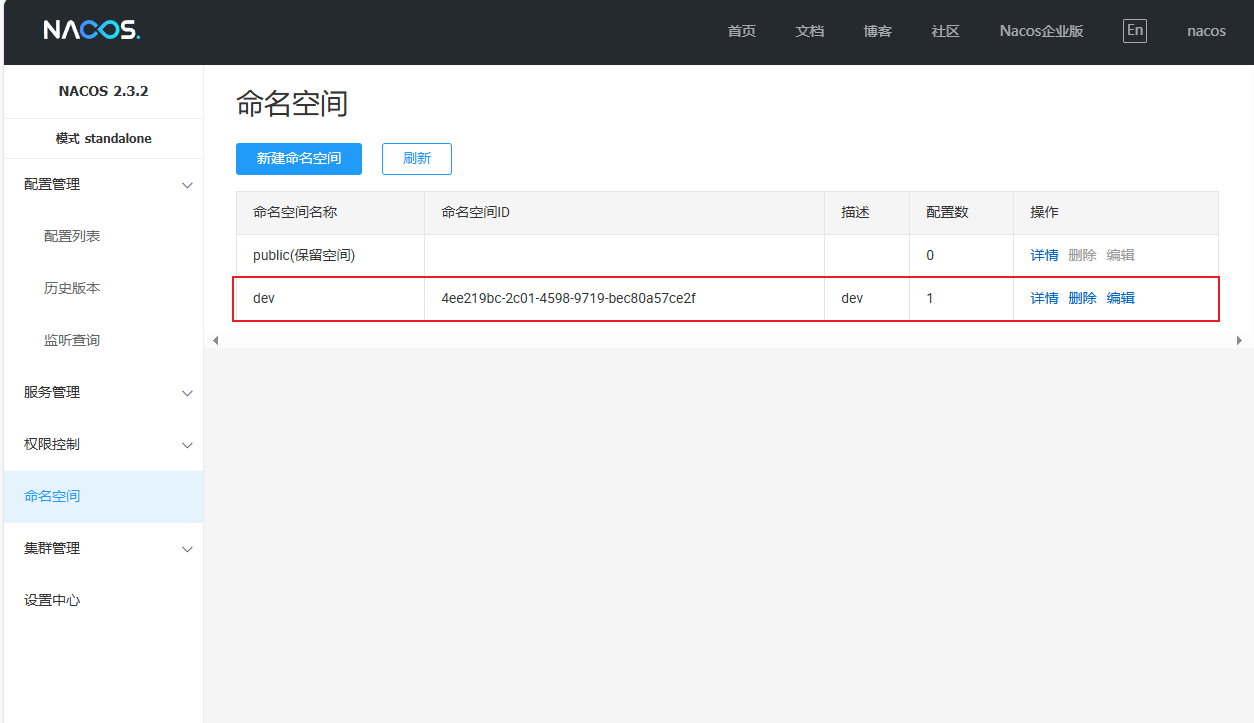
SpringBoot集成Nacos作为配置中心 1.Nacos安装参考:docker快速部署nacos - jupiter's blog (inat.top)2.SpringBoot集成Nacos作为配置中心2.1 引入依赖必要依赖 <!--nacos配置中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> <version>2023.0.1.0</version> </dependency> <!-- spring-cloud-starter-bootstrap --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> <version>4.1.2</version> </dependency>JSON转换依赖(测试用,可选)<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.28</version> </dependency>2.2 nacos新建命名空间和配置文件配置文件内容# 注入字符串 stringConfig: nacosStringConfig # 注入数组 arrayConfig: aaa,bbb,ccc # 注入list listConfig: aaa,bbb,ccc2.3 bootstrap.yml增加配置spring: cloud: nacos: username: nacos password: nacos123 config: namespace: 4ee219bc-2c01-4598-9719-bec80a57ce2f server-addr: 192.168.124.10:8848 extension-configs: - {data-id: "project-basic.yaml", group: "dev", refresh: "true"}2.4 配置映射类import lombok.Data; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.stereotype.Component; import java.util.List; @Component @RefreshScope @Data public class ProjectBasicConfig { @Value("${stringConfig:}") private String stringConfig; @Value("${arrayConfig:}") private String[] arrayConfig; @Value("#{'${listConfig:}'.empty ? null : '${listConfig:}'.split(',')}") private List<String> listConfig; }2.5 配置映射使用测试@RestController public class TestController { @Resource private ProjectBasicConfig projectBasicConfig; @GetMapping("/") public String testNacosConfig() { return "stringConfig=" + projectBasicConfig.getStringConfig() + ",arrayConfig=" + JSONUtil.toJsonStr(projectBasicConfig.getArrayConfig()) + ",listConfig=" +JSONUtil.toJsonStr(projectBasicConfig.getListConfig()); } }2.6 启动访问测试参考资料Nacos 融合 Spring Boot,成为注册配置中心 | NacosSpringBoot整合nacos实现配置中心(配置动态更新) - yvioo - 博客园 (cnblogs.com)SpringCloudAlibaba:Nacos配置的多文件加载与共享配置_nacos多文件配置-CSDN博客
-
SpringBoot RabbitMQ配置多vhost/多RabbitMQ实例+解决Exchange/Queue在vhost之间扩散造成交换机队列重复 1.添加maven依赖:<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>2.配置文件配置RabbitMQ连接信息:server: port: 8201 spring: application: name: RabbitMQ rabbitmq: vhost1: host: 192.168.124.10 port: 5672 username: user1 password: user1 virtual-host: /vhost1 vhost2: host: 192.168.124.10 port: 5672 username: user2 password: user2 virtual-host: /vhost23.RabbitMQConfig配置3.1 RabbitConstantpackage com.example.rabbitmq.config; public class RabbitConstant { // region vhost1 ConnectionFactory.RabbitTemplate.RabbitAdmin配置 public static final String VHOST_1_CONNECTION_FACTORY = "vhost1ConnectionFactory"; public static final String VHOST_1_RABBIT_LISTENER_CONTAINER_FACTORY = "vhost1RabbitListenerContainerFactory"; public static final String VHOST_1_RABBIT_TEMPLATE = "vhost1RabbitTemplate"; public static final String VHOST_1_RABBIT_ADMIN = "vhost1RabbitAdmin"; // endregion // region vhost2 ConnectionFactory.RabbitTemplate.RabbitAdmin配置 public static final String VHOST_2_CONNECTION_FACTORY = "vhost2ConnectionFactory"; public static final String VHOST_2_RABBIT_LISTENER_CONTAINER_FACTORY = "vhost2RabbitListenerContainerFactory"; public static final String VHOST_2_RABBIT_TEMPLATE = "vhost2RabbitTemplate"; public static final String VHOST_2_RABBIT_ADMIN = "vhost2RabbitAdmin"; // endregion // region vhost1 测试交换机.队列.路由配置 public static final String VHOST_1_TEST_EXCHANGE_1 = "vhost1TestExchange1"; public static final String VHOST_1_TEST_EXCHANGE_2 = "vhost1TestExchange2"; public static final String VHOST_1_TEST_EXCHANGE_1_QUEUE_1 = "vhost1TestExchange1Queue1"; public static final String VHOST_1_TEST_EXCHANGE_1_ROUTING_KEY_1 = "vhost1TestExchange1RoutingKey1"; public static final String VHOST_1_TEST_EXCHANGE_2_QUEUE_1 = "vhost1TestExchange2Queue1"; public static final String VHOST_1_TEST_EXCHANGE_2_ROUTING_KEY_1 = "vhost1TestExchange2RoutingKey1"; // endregion // region vhost2 测试交换机.队列.路由配置 public static final String VHOST_2_TEST_EXCHANGE_1 = "vhost2TestExchange1"; public static final String VHOST_2_TEST_EXCHANGE_2 = "vhost2TestExchange2"; public static final String VHOST_2_TEST_EXCHANGE_1_QUEUE_1 = "vhost2TestExchange1Queue1"; public static final String VHOST_2_TEST_EXCHANGE_1_ROUTING_KEY_1 = "vhost2TestExchange1RoutingKey1"; public static final String VHOST_2_TEST_EXCHANGE_2_QUEUE_1 = "vhost2TestExchange2Queue1"; public static final String VHOST_2_TEST_EXCHANGE_2_ROUTING_KEY_1 = "vhost2TestExchange2RoutingKey1"; // endregion }3.2 Vhost1RabbitMQConfigpackage com.example.rabbitmq.config; import org.springframework.amqp.core.AcknowledgeMode; import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory; import org.springframework.amqp.rabbit.connection.CachingConnectionFactory; import org.springframework.amqp.rabbit.connection.ConnectionFactory; import org.springframework.amqp.rabbit.core.RabbitAdmin; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; @Configuration public class Vhost1RabbitMQConfig { @Value("${spring.rabbitmq.vhost1.host}") private String host; @Value("${spring.rabbitmq.vhost1.port}") private int port; @Value("${spring.rabbitmq.vhost1.username}") private String username; @Value("${spring.rabbitmq.vhost1.password}") private String password; @Value("${spring.rabbitmq.vhost1.virtual-host}") private String vhost; // 为vhost1配置ConnectionFactory @Bean(name = RabbitConstant.VHOST_1_CONNECTION_FACTORY) @Primary public ConnectionFactory vhost1ConnectionFactory() { CachingConnectionFactory connectionFactory = new CachingConnectionFactory(host, port); connectionFactory.setUsername(username); connectionFactory.setPassword(password); connectionFactory.setVirtualHost(vhost); return connectionFactory; } // 为vhost1配置SimpleRabbitListenerContainerFactory @Bean(name = RabbitConstant.VHOST_1_RABBIT_LISTENER_CONTAINER_FACTORY) @Primary public SimpleRabbitListenerContainerFactory vhost1RabbitListenerContainerFactory( @Qualifier(RabbitConstant.VHOST_1_CONNECTION_FACTORY)ConnectionFactory connectionFactory) { SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); return factory; } // 为vhost1配置RabbitTemplate @Bean(name = RabbitConstant.VHOST_1_RABBIT_TEMPLATE) @Primary public RabbitTemplate vhost1RabbitTemplate( @Qualifier(RabbitConstant.VHOST_1_CONNECTION_FACTORY) ConnectionFactory connectionFactory) { RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory); // 可以设置其他属性,如消息转换器 return rabbitTemplate; } // 为vhost1配置RabbitAdmin @Bean(name = RabbitConstant.VHOST_1_RABBIT_ADMIN) @Primary public RabbitAdmin vhost1RabbitAdmin( @Qualifier(RabbitConstant.VHOST_1_CONNECTION_FACTORY) ConnectionFactory connectionFactory) { RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory); rabbitAdmin.setAutoStartup(true); return rabbitAdmin; } }3.3 Vhost2RabbitMQConfigpackage com.example.rabbitmq.config; import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory; import org.springframework.amqp.rabbit.connection.CachingConnectionFactory; import org.springframework.amqp.rabbit.connection.ConnectionFactory; import org.springframework.amqp.rabbit.core.RabbitAdmin; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; @Configuration public class Vhost2RabbitMQConfig { @Value("${spring.rabbitmq.vhost2.host}") private String host; @Value("${spring.rabbitmq.vhost2.port}") private int port; @Value("${spring.rabbitmq.vhost2.username}") private String username; @Value("${spring.rabbitmq.vhost2.password}") private String password; @Value("${spring.rabbitmq.vhost2.virtual-host}") private String vhost; // 为vhost2配置ConnectionFactory @Bean(name = RabbitConstant.VHOST_2_CONNECTION_FACTORY) public ConnectionFactory vhost2ConnectionFactory() { CachingConnectionFactory connectionFactory = new CachingConnectionFactory(host, port); connectionFactory.setUsername(username); connectionFactory.setPassword(password); connectionFactory.setVirtualHost(vhost); return connectionFactory; } // 为vhost2配置SimpleRabbitListenerContainerFactory @Bean(name = RabbitConstant.VHOST_2_RABBIT_LISTENER_CONTAINER_FACTORY) public SimpleRabbitListenerContainerFactory vhost2RabbitListenerContainerFactory( @Qualifier(RabbitConstant.VHOST_2_CONNECTION_FACTORY)ConnectionFactory connectionFactory) { SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); return factory; } // 为vhost2配置RabbitTemplate @Bean(name = RabbitConstant.VHOST_2_RABBIT_TEMPLATE) public RabbitTemplate vhost2RabbitTemplate( @Qualifier(RabbitConstant.VHOST_2_CONNECTION_FACTORY) ConnectionFactory connectionFactory) { RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory); // 可以设置其他属性,如消息转换器 return rabbitTemplate; } // 为vhost2配置RabbitAdmin @Bean(name = RabbitConstant.VHOST_2_RABBIT_ADMIN) public RabbitAdmin vhost2RabbitAdmin( @Qualifier(RabbitConstant.VHOST_2_CONNECTION_FACTORY) ConnectionFactory connectionFactory) { RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory); rabbitAdmin.setAutoStartup(true); return rabbitAdmin; } }4.消费者其中 @QueueBinding下的admins=的配置是交换机和队列数据不会在vhost之间扩散的必要条件4.1 Vhost1Consumerpackage com.example.rabbitmq.consumer; import com.example.rabbitmq.config.RabbitConstant; import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.core.ExchangeTypes; import org.springframework.amqp.rabbit.annotation.Exchange; import org.springframework.amqp.rabbit.annotation.Queue; import org.springframework.amqp.rabbit.annotation.QueueBinding; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.stereotype.Component; @Component @Slf4j public class Vhost1Consumer { @RabbitListener( containerFactory = RabbitConstant.VHOST_1_RABBIT_LISTENER_CONTAINER_FACTORY, bindings = @QueueBinding( value = @Queue(value = RabbitConstant.VHOST_1_TEST_EXCHANGE_1_QUEUE_1, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN), exchange = @Exchange(value = RabbitConstant.VHOST_1_TEST_EXCHANGE_1, type = ExchangeTypes.TOPIC, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN), key = RabbitConstant.VHOST_1_TEST_EXCHANGE_1_ROUTING_KEY_1, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN) ) public void vhost1Exchang1Queue1Consumer(String message) { log.info("vhost1 exchange1 queue1 consumer meaasge: {}", message); } @RabbitListener( containerFactory = RabbitConstant.VHOST_1_RABBIT_LISTENER_CONTAINER_FACTORY, bindings = @QueueBinding( value = @Queue(value = RabbitConstant.VHOST_1_TEST_EXCHANGE_2_QUEUE_1, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN), exchange = @Exchange(value = RabbitConstant.VHOST_1_TEST_EXCHANGE_2, type = ExchangeTypes.TOPIC, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN), key = RabbitConstant.VHOST_1_TEST_EXCHANGE_2_ROUTING_KEY_1, admins = RabbitConstant.VHOST_1_RABBIT_ADMIN)) public void vhost1Exchang2Queue1Consumer(String message) { log.info("vhost1 exchange2 queue1 consumer meaasge: {}", message); } }4.2 Vhost2Consumerpackage com.example.rabbitmq.consumer; import com.example.rabbitmq.config.RabbitConstant; import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.core.ExchangeTypes; import org.springframework.amqp.rabbit.annotation.Exchange; import org.springframework.amqp.rabbit.annotation.Queue; import org.springframework.amqp.rabbit.annotation.QueueBinding; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.stereotype.Component; @Component @Slf4j public class Vhost2Consumer { @RabbitListener( containerFactory = RabbitConstant.VHOST_2_RABBIT_LISTENER_CONTAINER_FACTORY, bindings = @QueueBinding( value = @Queue(value = RabbitConstant.VHOST_2_TEST_EXCHANGE_1_QUEUE_1, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN), exchange = @Exchange(value = RabbitConstant.VHOST_2_TEST_EXCHANGE_1, type = ExchangeTypes.TOPIC, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN), key = RabbitConstant.VHOST_2_TEST_EXCHANGE_1_ROUTING_KEY_1, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN) ) public void vhost2Exchang1Queue1Consumer(String message) { log.info("vhost2 exchange1 queue1 consumer meaasge: {}", message); } @RabbitListener( containerFactory = RabbitConstant.VHOST_2_RABBIT_LISTENER_CONTAINER_FACTORY, bindings = @QueueBinding( value = @Queue(value = RabbitConstant.VHOST_2_TEST_EXCHANGE_2_QUEUE_1, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN), exchange = @Exchange(value = RabbitConstant.VHOST_2_TEST_EXCHANGE_2, type = ExchangeTypes.TOPIC, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN), key = RabbitConstant.VHOST_2_TEST_EXCHANGE_2_ROUTING_KEY_1, admins = RabbitConstant.VHOST_2_RABBIT_ADMIN)) public void vhost2Exchang2Queue1Consumer(String message) { log.info("vhost2 exchange2 queue1 consumer meaasge: {}", message); } }5.生产者ProducerControllerpackage com.example.rabbitmq.producer; import com.example.rabbitmq.config.RabbitConstant; import jakarta.annotation.Resource; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/") public class ProducerController { @Resource(name = RabbitConstant.VHOST_1_RABBIT_TEMPLATE) RabbitTemplate vhost1RabbitTemplate; @Resource(name = RabbitConstant.VHOST_2_RABBIT_TEMPLATE) RabbitTemplate vhost2RabbitTemplate; @GetMapping("/") public String index() { return "rabbitmq study index"; } @GetMapping("/produceVhost1Exchange1Message") public String produceVhost1Exchange1Message() { String content1 = "vhost1 exchange1 message " + System.currentTimeMillis(); vhost1RabbitTemplate.convertAndSend( RabbitConstant.VHOST_1_TEST_EXCHANGE_1, RabbitConstant.VHOST_1_TEST_EXCHANGE_1_ROUTING_KEY_1, content1); return content1 + " send success"; } @GetMapping("/produceVhost1Exchange2Message") public String produceVhost1Exchange2Message() { String content1 = "vhost1 exchange2 message " + System.currentTimeMillis(); vhost1RabbitTemplate.convertAndSend( RabbitConstant.VHOST_1_TEST_EXCHANGE_2, RabbitConstant.VHOST_1_TEST_EXCHANGE_2_ROUTING_KEY_1, content1); return content1 + " send success"; } @GetMapping("/produceVhost2Exchange1Message") public String produceVhost2Exchange1Message() { String content1 = "vhost2 exchange1 message " + System.currentTimeMillis(); vhost2RabbitTemplate.convertAndSend( RabbitConstant.VHOST_2_TEST_EXCHANGE_1, RabbitConstant.VHOST_2_TEST_EXCHANGE_1_ROUTING_KEY_1, content1); return content1 + "send success "; } @GetMapping("/produceVhost2Exchange2Message") public String produceVhost2Exchange2Message() { String content1 = "vhost2 exchange2 message " + System.currentTimeMillis(); vhost2RabbitTemplate.convertAndSend( RabbitConstant.VHOST_2_TEST_EXCHANGE_2, RabbitConstant.VHOST_2_TEST_EXCHANGE_2_ROUTING_KEY_1, content1); return content1 + "send success "; } }6.启动测试日志 . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v3.2.5) 2024-05-15T23:12:32.832+08:00 INFO 20956 --- [RabbitMQ] [ main] c.example.rabbitmq.RabbitMqApplication : Starting RabbitMqApplication using Java 17.0.8 with PID 20956 (C:\Users\vin\Desktop\WorkSpace\StudyProject\RabbitMQ\target\classes started by vin in C:\Users\vin\Desktop\WorkSpace\StudyProject) 2024-05-15T23:12:32.834+08:00 INFO 20956 --- [RabbitMQ] [ main] c.example.rabbitmq.RabbitMqApplication : No active profile set, falling back to 1 default profile: "default" 2024-05-15T23:12:33.401+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8201 (http) 2024-05-15T23:12:33.408+08:00 INFO 20956 --- [RabbitMQ] [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-05-15T23:12:33.408+08:00 INFO 20956 --- [RabbitMQ] [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.20] 2024-05-15T23:12:33.438+08:00 INFO 20956 --- [RabbitMQ] [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-05-15T23:12:33.439+08:00 INFO 20956 --- [RabbitMQ] [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 577 ms 2024-05-15T23:12:33.738+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8201 (http) with context path '' 2024-05-15T23:12:33.740+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: 192.168.124.10:5672 2024-05-15T23:12:33.764+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: vhost1ConnectionFactory#6af91cc8:0/SimpleConnection@7bee8621 [delegate=amqp://user1@192.168.124.10:5672//vhost1, localPort=3708] 2024-05-15T23:12:33.789+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: 192.168.124.10:5672 2024-05-15T23:12:33.791+08:00 INFO 20956 --- [RabbitMQ] [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: vhost2ConnectionFactory#43acd79e:0/SimpleConnection@385d819 [delegate=amqp://user2@192.168.124.10:5672//vhost2, localPort=3709] 2024-05-15T23:12:33.800+08:00 INFO 20956 --- [RabbitMQ] [ main] c.example.rabbitmq.RabbitMqApplication : Started RabbitMqApplication in 1.212 seconds (process running for 1.512) 2024-05-15T23:13:00.260+08:00 INFO 20956 --- [RabbitMQ] [nio-8201-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2024-05-15T23:13:00.261+08:00 INFO 20956 --- [RabbitMQ] [nio-8201-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2024-05-15T23:13:00.261+08:00 INFO 20956 --- [RabbitMQ] [nio-8201-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 0 ms 2024-05-15T23:13:00.315+08:00 INFO 20956 --- [RabbitMQ] [ntContainer#0-1] c.e.rabbitmq.consumer.Vhost1Consumer : vhost1 exchange1 queue1 consumer meaasge: vhost1 exchange1 message 1715785980295 2024-05-15T23:13:04.012+08:00 INFO 20956 --- [RabbitMQ] [ntContainer#1-1] c.e.rabbitmq.consumer.Vhost1Consumer : vhost1 exchange2 queue1 consumer meaasge: vhost1 exchange2 message 1715785984008 2024-05-15T23:13:09.439+08:00 INFO 20956 --- [RabbitMQ] [ntContainer#2-1] c.e.rabbitmq.consumer.Vhost2Consumer : vhost2 exchange1 queue1 consumer meaasge: vhost2 exchange1 message 1715785989435 2024-05-15T23:13:15.260+08:00 INFO 20956 --- [RabbitMQ] [ntContainer#3-1] c.e.rabbitmq.consumer.Vhost2Consumer : vhost2 exchange2 queue1 consumer meaasge: vhost2 exchange2 message 1715785995257参考资料SpringBoot RabbitMQ配置多vhost/多RabbitMQ实例方案_rabbitmq springboot消费多个vhost-CSDN博客SpringBoot连接多RabbitMQ源 - 知乎 (zhihu.com)@QueueBinding RabbitMQ 多数据源 队列重复-CSDN博客【MQ系列】RabbitListener消费基本使用姿势介绍 | 一灰灰Blog (hhui.top)
-
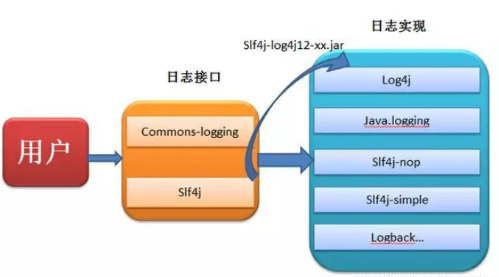
Java日志体系和springboot日志配置 1.日志框架的分类1.1 门面型日志框架日志门面定义了一组日志的接口规范,它并不提供底层具体的实现逻辑。JCL:Apache基金会所属的项目,是一套Java日志接口,之前叫Jakarta Commons Logging,后更名为Commons LoggingSLF4J:是一套简易Java日志门面,本身并无日志的实现。(Simple Logging Facade for Java,缩写Slf4j)1.2 记录型日志框架日志实现则是日志具体的实现,包括日志级别控制、日志打印格式、日志输出形式(输出到数据库、输出到文件、输出到控制台等)。Jul (Java Util Logging):JDK中的日志记录工具,也常称为JDKLog、jdk-logging,自Java1.4以来的官方日志实现。Log4j:Apache Log4j是一个基于Java的日志记录工具。它是由Ceki Gülcü首创的,现在则是Apache软件基金会的一个项目。 Log4j是几种Java日志框架之一。Log4j2:一个具体的日志实现框架,是Log4j 1的下一个版本,与Log4j 1发生了很大的变化,Log4j 2不兼容Log4j 1。Logback:一个具体的日志实现框架,和Slf4j是同一个作者,但其性能更好(推荐使用)。将日志门面和日志实现分离其实是一种典型的门面模式,这种方式可以让具体业务在不同的日志实现框架之间自由切换,而不需要改动任何代码,开发者只需要掌握日志门面的 API 即可。日志门面是不能单独使用的,它必须和一种具体的日志实现框架相结合使用。2.Java日志的恩怨情仇1996年早期,欧洲安全电子市场项目组决定编写它自己的程序跟踪API(Tracing API)。经过不断的完善,这个API终于成为一个十分受欢迎的Java日志软件包,即Log4j(由Ceki创建)。后来Log4j成为Apache基金会项目中的一员,Ceki也加入Apache组织。后来Log4j近乎成了Java社区的日志标准。据说Apache基金会还曾经建议Sun引入Log4j到Java的标准库中,但Sun拒绝了。2002年Java1.4发布,Sun推出了自己的日志库JUL(Java Util Logging),其实现基本模仿了Log4j的实现。在JUL出来以前,Log4j就已经成为一项成熟的技术,使得Log4j在选择上占据了一定的优势。接着,Apache推出了Jakarta Commons Logging,JCL只是定义了一套日志接口(其内部也提供一个Simple Log的简单实现),支持运行时动态加载日志组件的实现,也就是说,在你应用代码里,只需调用Commons Logging的接口,底层实现可以是Log4j,也可以是Java Util Logging。后来(2006年),Ceki不适应Apache的工作方式,离开了Apache。然后先后创建了Slf4j(日志门面接口,类似于Commons Logging)和Logback(Slf4j的实现)两个项目,并回瑞典创建了QOS公司,QOS官网上是这样描述Logback的:The Generic,Reliable Fast&Flexible Logging Framework(一个通用,可靠,快速且灵活的日志框架)。Java日志领域被划分为两大阵营:Commons Logging阵营和Slf4j阵营。Commons Logging在Apache大树的笼罩下,有很大的用户基数。但有证据表明,形式正在发生变化。2013年底有人分析了GitHub上30000个项目,统计出了最流行的100个Libraries,可以看出Slf4j的发展趋势更好。Apache眼看有被Logback反超的势头,于2012-07重写了Log4j 1.x,成立了新的项目Log4j 2, Log4j 2具有Logback的所有特性。3.项目中选择日志框架选择如果是在一个新的项目中建议使用Slf4j与Logback组合,这样有如下的几个优点。Slf4j实现机制决定Slf4j限制较少,使用范围更广。由于Slf4j在编译期间,静态绑定本地的LOG库使得通用性要比Commons Logging要好。Logback拥有更好的性能。Logback声称:某些关键操作,比如判定是否记录一条日志语句的操作,其性能得到了显著的提高。这个操作在Logback中需要3纳秒,而在Log4J中则需要30纳秒。LogBack创建记录器(logger)的速度也更快:13毫秒,而在Log4J中需要23毫秒。更重要的是,它获取已存在的记录器只需94纳秒,而Log4J需要2234纳秒,时间减少到了1/23。跟JUL相比的性能提高也是显著的。Commons Logging开销更高Logback文档免费。Logback的所有文档是全面免费提供的,不象Log4J那样只提供部分免费文档而需要用户去购买付费文档。4.Spring Boot 默认日志4.1 默认日志pom依赖Spring Boot 的日志支持依赖是 spring-boot-starter-logging,默认使用slf4j+logback的方式来记录日志。<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> <version>3.2.5</version> </dependency>备注:该依赖已经被spring-boot-starter所集成,无需重复引入4.2 默认日志级别配置Logback 支持 TRACE, DEBUG, INFO, WARN, ERROR 日志级别,优先级关系为 TRACE < DEBUG < INFO < WARN < ERROR , 可以在 application 配置文件中更改打印日志级别# Log level config logging.level.root=DEBUG4.3 默认日志打印测试手动创建logger@SpringBootTest class SpringBootLogStudyApplicationTests { private static final Logger logger = LoggerFactory.getLogger(SpringBootLogStudyApplicationTests.class); @Test void contextLoads() { logger.debug("debug日志"); logger.info("info日志"); logger.warn("warn日志"); logger.error("error日志"); } }使用@Slf4j注解需要实现引入lombok<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.28</version> </dependency>打印测试@Slf4j @SpringBootTest class SpringBootLogStudyApplicationTests { @Test void testPrintLog() { log.debug("debug日志"); log.info("info日志"); log.warn("warn日志"); log.error("error日志"); } }4.4 日志格式设置使用属性 logging.pattern.console 和 logging.pattern.file 可以分别自定义控制台日志和文件日志的格式#控制台显示日志的格式 logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{5}- %msg%n #文件显示日志的格式 logging.pattern.file=%d{yyyy-MM-dd HH:mm} [%thread] %-5level %logger- %msg%n上面用的一些标签含义如下:%d: 日期实践%thread: 线程名%-5level:级别从左显示5个字符宽度%logger{5}:表示logger名字最长5个字符,否则按照句点分割。%msg:日志消息%n:换行4. 使用application.yml 简单配置Logbacklogging: level: root: info # 根日志级别设置为info com.example: debug # 特定包的日志级别设置为debug pattern: console: "%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%thread] %logger{36} - %msg%n" file: name: application.log # 日志文件名称5. 使用自定义规则的xml配置Logback-配置详解(推荐使用)5.1 configuration节点相关属性属性名称默认值介绍debugfalse要不要打印 logback内部日志信息,true则表示要打印。scantrue配置发送改变时,要不要重新加载scanPeriod1 seconds检测配置发生变化的时间间隔。如果没给出时间单位,默认时间单位是毫秒5.2 configuration子节点介绍contextName节点用来设置上下文名称,每个logger都关联到logger上下文,默认上下文名称为default。但可以使用<contextName>设置成其他名字,用于区分不同应用程序的记录。一旦设置,不能修改,后面输出格式中可以通过定义 %contextName 来打印日志上下文名称(一般可以无需配置)示例:<configuration scan="true" scanPeriod="60 seconds" debug="false"> <contextName>myAppName</contextName> <!--其他配置省略--> </configuration> property节点用来设置相关变量,通过key-value的方式配置,然后在后面的配置文件中通过 ${key}来访问示例:<configuration scan="true" scanPeriod="60 seconds" debug="false"> <property name="APP_Name" value="myAppName" /> <contextName>${APP_Name}</contextName> <!--其他配置省略--> </configuration>appender 节点负责写日志的组件,它有两个必要属性name和class。name指定appender名称,class指定appender的全限定名。属性名称默认值介绍name无默认值appender组件的名称,后面给logger指定appender使用class无默认值appender的具体实现类。常用的有 ConsoleAppender、FileAppender、RollingFileAppenderConsoleAppender:向控制台输出日志内容的组件,只要定义好encoder节点就可以使用。示例:把>=DEBUG级别的日志都输出到控制台<configuration> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg %n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="STDOUT" /> </root> </configuration>FileAppender:向文件输出日志内容的组件,用法也很简单,不过由于没有日志滚动策略,一般很少使用:被写入的文件名,可以是相对目录,也可以是绝对目录,如果上级目录不存在会自动创建,没有默认值。:如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true。:对记录事件进行格式化。:如果是 true,日志会被安全的写入文件,即使其他的FileAppender也在向此文件做写入操作,效率低,默认是 false。示例:把>=DEBUG级别的日志都输出到testFile.log<configuration> <appender name="FILE" class="ch.qos.logback.core.FileAppender"> <file>testFile.log</file> <append>true</append> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="FILE" /> </root> </configuration>RollingFileAppender(推荐):向文件输出日志内容的组件,同时可以配置日志文件滚动策略,在日志达到一定条件后生成一个新的日志文件。有以下子节点::被写入的文件名,可以是相对目录,也可以是绝对目录,如果上级目录不存在会自动创建,没有默认值。 :如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true。:当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名。属性class定义具体的滚动策略类,最常用的是ch.qos.logback.core.rolling.TimeBasedRollingPolicy滚动测量配置详解: class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy": 最常用的滚动策略,它根据时间来制定滚动策略,既负责滚动也负责出发滚动。有以下子节点::必要节点,包含文件名及“%d”转换符,“%d”可以包含一个java.text.SimpleDateFormat指定的时间格式,如:%d{yyyy-MM}。如果直接使用 %d,默认格式是 yyyy-MM-dd。RollingFileAppender的file字节点可有可无,通过设置file,可以为活动文件和归档文件指定不同位置,当前日志总是记录到file指定的文件(活动文件),活动文件的名字不会改变;如果没设置file,活动文件的名字会根据fileNamePattern 的值,每隔一段时间改变一次。“/”或者“\”会被当做目录分隔符。:可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件。假设设置每个月滚动,且是6,则只保存最近6个月的文件,删除之前的旧文件。注意,删除旧文件是,那些为了归档而创建的目录也会被删除。 class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy": 查看当前活动文件的大小,如果超过指定大小会告知RollingFileAppender 触发当前活动文件滚动。只有一个节点::这是活动文件的大小,默认值是10MB。:当为true时,不支持FixedWindowRollingPolicy。支持TimeBasedRollingPolicy,但是有两个限制,1不支持也不允许文件压缩,2不能设置file属性,必须留空。: 告知 RollingFileAppender 合适激活滚动。 class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy" 根据固定窗口算法重命名文件的滚动策略。有以下子节点::窗口索引最小值:窗口索引最大值,当用户指定的窗口过大时,会自动将窗口设置为12。:必须包含“%i”例如,假设最小值和最大值分别为1和2,命名模式为 mylog%i.log,会产生归档文件mylog1.log和mylog2.log。还可以指定文件压缩选项,例如,mylog%i.log.gz 或者 没有log%i.log.zip示例:每天生成一个日志文件,保存30天的日志文件。<configuration> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>logFile.%d{yyyy-MM-dd}.log</fileNamePattern> <maxHistory>30</maxHistory> </rollingPolicy> <encoder> <pattern>%-4relative [%thread] %-5level %logger{35} - %msg%n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="FILE" /> </root> </configuration>logger节点和root节点logger节点:用来设置某一个包或具体的某一个类的日志打印级别、以及指定<appender>,<logger>仅有一个name属性,一个可选的level和一个可选的addtivity属性。可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个logger。name: 用来指定受此loger约束的某一个包或者具体的某一个类。level: 用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL和OFF,还有一个特殊值INHERITED或者同义词NULL,代表强制执行上级的级别。 如果未设置此属性,那么当前logger将会继承上级的级别。addtivity: 是否向上级logger传递打印信息。默认是true。可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个logger。root节点:它也是<logger>元素,但是它是根logger,是所有<logger>的上级。只有一个level属性,因为name已经被命名为"root",且已经是最上级了。level: 用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL和OFF,不能设置为INHERITED或者同义词NULL。 默认是DEBUG。示例:常用logger配置<!-- show parameters for hibernate sql 专为 Hibernate 定制 --> <logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE" /> <logger name="org.hibernate.type.descriptor.sql.BasicExtractor" level="DEBUG" /> <logger name="org.hibernate.SQL" level="DEBUG" /> <logger name="org.hibernate.engine.QueryParameters" level="DEBUG" /> <logger name="org.hibernate.engine.query.HQLQueryPlan" level="DEBUG" /> <!--myibatis log configure--> <logger name="com.apache.ibatis" level="TRACE"/> <logger name="java.sql.Connection" level="DEBUG"/> <logger name="java.sql.Statement" level="DEBUG"/> <logger name="java.sql.PreparedStatement" level="DEBUG"/>4.2.2 配置实例可以实现每天生成一个日志文件,日志文件按等级分文件保存,保存日期等 复杂规则日志<?xml version="1.0" encoding="UTF-8"?> <configuration debug="false"> <!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径--> <property name="LOG_HOME" value="C:/Users/vin/Desktop/log-test"/> <property name="appName" value="logbackStudy"/> <!--控制台日志, 控制台输出 --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度,%msg:日志消息,%n是换行符--> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> </appender> <!--文件日志, 按照每天生成日志文件 --> <!--RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件--> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--如果是 true,日志被追加到文件结尾,如果是 false,清空现存文件,默认是true --> <append>true</append> <!--当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名--> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!--定义文件滚动时的文件名的格式--> <fileNamePattern>${LOG_HOME}/${appName}.%d{yyyy-MM-dd}.log </fileNamePattern> <!--30天的时间周期,日志量最大1GB--> <maxHistory>30</maxHistory> <!-- 该属性在 1.1.6版本后 才开始支持--> <totalSizeCap>1GB</totalSizeCap> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"> <!--每个日志文件最大10MB--> <MaxFileSize>10MB</MaxFileSize> </triggeringPolicy> </appender> <!-- 按日志级别打印 INFO --> <appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/INFO.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>INFO</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 按日志级别打印 WARN --> <appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/WARN.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>WARN</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 按日志级别打印 ERROR --> <appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 文件名称 --> <fileNamePattern>${LOG_HOME}/ERROR.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- 文件最大保存历史数量 --> <MaxHistory>30</MaxHistory> </rollingPolicy> <!--定义输出格式--> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern> </encoder> <!--filter 过滤输出--> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>ERROR</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch> </filter> </appender> <!-- 日志输出级别设置,ref 属性为 appender 的name--> <root level="INFO"> <appender-ref ref="STDOUT"/> <appender-ref ref="FILE"/> <appender-ref ref="INFO"/> <appender-ref ref="WARN"/> <appender-ref ref="ERROR"/> </root> </configuration>参考资料面试官:SpringBoot中关于日志工具的使用,我想问你几个常见问题-腾讯云开发者社区-腾讯云 (tencent.com)深入掌握Java日志体系,再也不迷路了 - 掘金 (juejin.cn)Java日志体系详解_Jeremy_Lee123的博客-CSDN博客Spring Boot中集成Slf4j 与Logback-腾讯云开发者社区-腾讯云 (tencent.com)Spring Boot 默认日志使用_logging.level.springfox__星辰夜风的博客-CSDN博客logback配置文件---logback.xml详解 - 马非白即黑 - 博客园 (cnblogs.com)logback介绍和配置详解 - 简书 (jianshu.com)
-
SpringBoot集成Redisson延迟队列 0. 使用场景下单成功,30分钟未支付。支付超时,自动取消订单订单签收,签收后7天未进行评价。订单超时未评价,系统默认好评下单成功,商家5分钟未接单,订单取消配送超时,推送短信提醒1.Redisson延迟队列原理redisson 使用了 两个list + 一个 sorted-set + pub/sub 来实现延时队列,而不是单一的sort-set。sorted-set:存放未到期的消息&到期时间,提供消息延时排序功能list1:存放未到期消息,作为消息的原始顺序视图,提供如查询、删除指定第几条消息的功能(分析源码得出的,查看哪些地方有使用这个list)list2:消费队列,存放到期后的消息,提供消费整体流程(对应画图PPT链接): 结合源码分析:org.redisson.RedissonDelayedQueue#RedissonDelayedQueue 首先创建延时队列的时候,会创建一个QueueTransferTask, 在里面会订阅一个topic,订阅成功后,执行其pushTask方法,里面会查询sorted-set中100个已到期的消息,将其push到lis2中,并从sorted-set和list1中移除。(这里是为了投递历史未处理的消息)protected RedissonDelayedQueue(QueueTransferService queueTransferService, Codec codec, final CommandAsyncExecutor commandExecutor, String name) { super(codec, commandExecutor, name); channelName = prefixName("redisson_delay_queue_channel", getRawName()); queueName = prefixName("redisson_delay_queue", getRawName()); timeoutSetName = prefixName("redisson_delay_queue_timeout", getRawName()); QueueTransferTask task = new QueueTransferTask(commandExecutor.getConnectionManager()) { @Override protected RFuture<Long> pushTaskAsync() { return commandExecutor.evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_LONG, "local expiredValues = redis.call('zrangebyscore', KEYS[2], 0, ARGV[1], 'limit', 0, ARGV[2]); " + "if #expiredValues > 0 then " + "for i, v in ipairs(expiredValues) do " + "local randomId, value = struct.unpack('dLc0', v);" + "redis.call('rpush', KEYS[1], value);" + "redis.call('lrem', KEYS[3], 1, v);" + "end; " + "redis.call('zrem', KEYS[2], unpack(expiredValues));" + "end; " // get startTime from scheduler queue head task + "local v = redis.call('zrange', KEYS[2], 0, 0, 'WITHSCORES'); " + "if v[1] ~= nil then " + "return v[2]; " + "end " + "return nil;", Arrays.<Object>asList(getRawName(), timeoutSetName, queueName), System.currentTimeMillis(), 100); } @Override protected RTopic getTopic() { return RedissonTopic.createRaw(LongCodec.INSTANCE, commandExecutor, channelName); } }; queueTransferService.schedule(queueName, task); this.queueTransferService = queueTransferService; } org.redisson.RedissonDelayedQueue#offerAsync(V, long, java.util.concurrent.TimeUnit) 发送延时消息时,会将消息写入 list1和 sorted-set 中,msg会添加一个randomId,支持发送相同的消息。并且判断sorted-set首条消息如果是刚插入的,则publish timeout(到期时间) 到 topicpublic RFuture<Void> offerAsync(V e, long delay, TimeUnit timeUnit) { if (delay < 0) { throw new IllegalArgumentException("Delay can't be negative"); } long delayInMs = timeUnit.toMillis(delay); long timeout = System.currentTimeMillis() + delayInMs; long randomId = ThreadLocalRandom.current().nextLong(); return commandExecutor.evalWriteAsync(getRawName(), codec, RedisCommands.EVAL_VOID, "local value = struct.pack('dLc0', tonumber(ARGV[2]), string.len(ARGV[3]), ARGV[3]);" + "redis.call('zadd', KEYS[2], ARGV[1], value);" + "redis.call('rpush', KEYS[3], value);" // if new object added to queue head when publish its startTime // to all scheduler workers + "local v = redis.call('zrange', KEYS[2], 0, 0); " + "if v[1] == value then " + "redis.call('publish', KEYS[4], ARGV[1]); " + "end;", Arrays.<Object>asList(getRawName(), timeoutSetName, queueName, channelName), timeout, randomId, encode(e)); }org.redisson.QueueTransferTask#scheduleTask 订阅到topic消息后,会先判断其是否临期(delay<10ms),如果是则调用pushTask方法,不是则启动一个定时任务(使用的netty时间轮),延时delay后执行pushTask方法。// 订阅topic onMessage 时调用 private void scheduleTask(final Long startTime) { TimeoutTask oldTimeout = lastTimeout.get(); if (startTime == null) { return; } if (oldTimeout != null) { oldTimeout.getTask().cancel(); } long delay = startTime - System.currentTimeMillis(); if (delay > 10) { // 使用 netty 时间轮 启动一个定时任务 Timeout timeout = connectionManager.newTimeout(new TimerTask() { @Override public void run(Timeout timeout) throws Exception { pushTask(); TimeoutTask currentTimeout = lastTimeout.get(); if (currentTimeout.getTask() == timeout) { lastTimeout.compareAndSet(currentTimeout, null); } } }, delay, TimeUnit.MILLISECONDS); if (!lastTimeout.compareAndSet(oldTimeout, new TimeoutTask(startTime, timeout))) { timeout.cancel(); } } else { pushTask(); } } private void pushTask() { RFuture<Long> startTimeFuture = pushTaskAsync(); startTimeFuture.onComplete((res, e) -> { if (e != null) { if (e instanceof RedissonShutdownException) { return; } log.error(e.getMessage(), e); scheduleTask(System.currentTimeMillis() + 5 * 1000L); return; } if (res != null) { scheduleTask(res); } }); }2.SpringBoot集成实验环境:SpringBoot版本3.0.12<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.0.12</version> <relativePath/> <!-- lookup parent from repository --> </parent>2.1 引入 Redisson 依赖 <!--redission--> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.19.0</version> </dependency>2.2 配置文件spring: data: redis: host: 172.19.236.66 port: 6379 #password: 123456 database: 0 timeout: 30002.3 创建 RedissonConfig 配置package com.example.redissionstudy.config; import org.redisson.Redisson; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author LuoJia * @version 1.0 * @description: Redis链接配置文件 * @date 2023/11/3 8:59 */ @Configuration public class RedissonConfig { @Value("${spring.data.redis.host}") private String host; @Value("${spring.data.redis.port}") private int port; @Value("${spring.data.redis.database}") private int database; //@Value("${spring.data.redis.password}") //private String password; @Bean public RedissonClient redissonClient() { Config config = new Config(); config.useSingleServer() .setAddress("redis://" + host + ":" + port) .setDatabase(database); //.setPassword(password) return Redisson.create(config); } }测试使用@SpringBootTest @Slf4j class RedissionStudyApplicationTests { @Resource RedissonClient redissonClient; @Test void testRedission() { //字符串操作 RBucket<String> rBucket = redissonClient.getBucket("strKey"); // 设置value和key的有效期 rBucket.set("张三", 30, TimeUnit.MINUTES); // 通过key获取value System.out.println(redissonClient.getBucket("strKey").get()); } }张三redis查看结果127.0.0.1:6379> keys str* 1) "strKey" 127.0.0.1:6379> get strKey "\x03\x83\xe5\xbc\xa0\xe4\xb8\x89"2.4 封装 Redis 延迟队列工具类package com.example.redissionstudy.utils; import lombok.extern.slf4j.Slf4j; import org.redisson.api.RBlockingDeque; import org.redisson.api.RDelayedQueue; import org.redisson.api.RedissonClient; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.util.Map; import java.util.concurrent.TimeUnit; /** * @author LuoJia * @version 1.0 * @description: Redission 延迟队列工具类 * @date 2023/11/3 9:51 */ @Slf4j @Component public class RedisDelayQueueUtil { @Autowired private RedissonClient redissonClient; /** * 添加延迟队列 * * @param value 队列值 * @param delay 延迟时间 * @param timeUnit 时间单位 * @param queueCode 队列键 * @param <T> */ public <T> void addDelayQueue(T value, long delay, TimeUnit timeUnit, String queueCode) { try { RBlockingDeque<Object> blockingDeque = redissonClient.getBlockingDeque(queueCode); RDelayedQueue<Object> delayedQueue = redissonClient.getDelayedQueue(blockingDeque); delayedQueue.offer(value, delay, timeUnit); log.info("(添加延时队列成功) 队列键:{},队列值:{},延迟时间:{}", queueCode, value, timeUnit.toSeconds(delay) + "秒"); } catch (Exception e) { log.error("(添加延时队列失败) {}", e.getMessage()); throw new RuntimeException("(添加延时队列失败)"); } } /** * 获取延迟队列 * * @param queueCode * @param <T> * @return * @throws InterruptedException */ public <T> T getDelayQueue(String queueCode) throws InterruptedException { RBlockingDeque<Map> blockingDeque = redissonClient.getBlockingDeque(queueCode); T value = (T) blockingDeque.take(); return value; } }2.5 创建延迟队列业务枚举package com.example.redissionstudy.enums; import lombok.AllArgsConstructor; import lombok.Getter; import lombok.NoArgsConstructor; /** * @author LuoJia * @version 1.0 * @description: 延迟队列业务枚举 * @date 2023/11/3 9:53 */ @Getter @AllArgsConstructor @NoArgsConstructor public enum RedisDelayQueueEnum { ORDER_PAYMENT_TIMEOUT("ORDER_PAYMENT_TIMEOUT", "订单支付超时,自动取消订单", "orderPaymentTimeout"), ORDER_TIMEOUT_NOT_EVALUATED("ORDER_TIMEOUT_NOT_EVALUATED", "订单超时未评价,系统默认好评", "orderTimeoutNotEvaluated"); /** * 延迟队列 RedisKey */ private String code; /** * 中文描述 */ private String name; /** * 延迟队列具体业务实现的 Bean * 可通过 Spring 的上下文获取 */ private String beanId; }2.6 定义延迟队列执行器package com.example.redissionstudy.handler; /** * @author LuoJia * @version 1.0 * @description: 延迟队列执行器接口 * @date 2023/11/3 9:58 */ public interface RedisDelayQueueHandle<T>{ void execute(T t); }2.7 创建枚举中定义的Bean,并实现延迟队列执行器OrderPaymentTimeout:订单支付超时延迟队列处理类package com.example.redissionstudy.handler.impl; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 订单支付超时处理类 * @date 2023/11/3 10:00 */ @Component @Slf4j public class OrderPaymentTimeout implements RedisDelayQueueHandle<Map> { @Override public void execute(Map map) { log.info("{} {}", RedisDelayQueueEnum.ORDER_PAYMENT_TIMEOUT.getName(), map); // TODO 订单支付超时,自动取消订单处理业务... } } OrderTimeoutNotEvaluated:订单超时未评价延迟队列处理类package com.example.redissionstudy.handler.impl; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 订单超时未评价处理类 * @date 2023/11/3 10:01 */ @Component @Slf4j public class OrderTimeoutNotEvaluated implements RedisDelayQueueHandle<Map> { @Override public void execute(Map map) { log.info("{} {}", RedisDelayQueueEnum.ORDER_TIMEOUT_NOT_EVALUATED.getName(), map); // TODO 订单超时未评价,系统默认好评处理业务... } }2.8 创建延迟队列消费线程,项目启动完成后开启package listener; import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.handler.RedisDelayQueueHandle; import com.example.redissionstudy.utils.RedisDelayQueueUtil; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.CommandLineRunner; import org.springframework.context.ApplicationContext; import org.springframework.stereotype.Component; /** * @author LuoJia * @version 1.0 * @description: 启动延迟队列 * @date 2023/11/3 10:02 */ @Slf4j @Component public class RedisDelayQueueRunner implements CommandLineRunner { @Autowired private RedisDelayQueueUtil redisDelayQueueUtil; @Autowired private ApplicationContext applicationContext; @Override public void run(String... args) { new Thread(() -> { while (true) { try { RedisDelayQueueEnum[] queueEnums = RedisDelayQueueEnum.values(); for (RedisDelayQueueEnum queueEnum : queueEnums) { Object value = redisDelayQueueUtil.getDelayQueue(queueEnum.getCode()); if (value != null) { RedisDelayQueueHandle redisDelayQueueHandle = (RedisDelayQueueHandle) applicationContext.getBean(queueEnum.getBeanId()); redisDelayQueueHandle.execute(value); } } } catch (InterruptedException e) { log.error("(Redis延迟队列异常中断) {}", e.getMessage()); } } }).start(); log.info("(Redis延迟队列启动成功)"); } }以上步骤,Redis 延迟队列核心代码已经完成,下面我们写一个测试接口,用 PostMan 模拟测试一下2.9 创建一个测试接口,模拟添加延迟队列package com.example.redissionstudy.controller; /** * @author LuoJia * @version 1.0 * @description: 延迟队列测试 * @date 2023/11/3 10:05 */ import com.example.redissionstudy.enums.RedisDelayQueueEnum; import com.example.redissionstudy.utils.RedisDelayQueueUtil; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import java.util.HashMap; import java.util.Map; import java.util.concurrent.TimeUnit; @RestController public class RedisDelayQueueController { @Autowired private RedisDelayQueueUtil redisDelayQueueUtil; @GetMapping("/addQueue") public void addQueue() { Map<String, String> map1 = new HashMap<>(); map1.put("orderId", "100"); map1.put("remark", "其他信息"); Map<String, String> map2 = new HashMap<>(); map2.put("orderId", "200"); map2.put("remark", "其他信息"); // 添加订单支付超时,自动取消订单延迟队列。为了测试效果,延迟10秒钟 redisDelayQueueUtil.addDelayQueue(map1, 10, TimeUnit.SECONDS, RedisDelayQueueEnum.ORDER_PAYMENT_TIMEOUT.getCode()); // 订单超时未评价,系统默认好评。为了测试效果,延迟20秒钟 redisDelayQueueUtil.addDelayQueue(map2, 20, TimeUnit.SECONDS, RedisDelayQueueEnum.ORDER_TIMEOUT_NOT_EVALUATED.getCode()); } }运行结果2023-11-03T10:09:46.800+08:00 INFO 21480 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2023-11-03T10:09:46.816+08:00 INFO 21480 --- [ main] c.e.r.RedissionStudyApplication : Started RedissionStudyApplication in 4.888 seconds (process running for 5.743) 2023-11-03T10:09:46.825+08:00 INFO 21480 --- [ main] c.e.r.listener.RedisDelayQueueRunner : (Redis延迟队列启动成功) 2023-11-03T10:09:47.039+08:00 INFO 21480 --- [-10.108.155.252] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2023-11-03T10:09:47.040+08:00 INFO 21480 --- [-10.108.155.252] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2023-11-03T10:09:47.042+08:00 INFO 21480 --- [-10.108.155.252] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms 2023-11-03T10:10:25.798+08:00 INFO 21480 --- [nio-8080-exec-4] c.e.r.utils.RedisDelayQueueUtil : (添加延时队列成功) 队列键:ORDER_PAYMENT_TIMEOUT,队列值:{orderId=100, remark=其他信息},延迟时间:10秒 2023-11-03T10:10:25.802+08:00 INFO 21480 --- [nio-8080-exec-4] c.e.r.utils.RedisDelayQueueUtil : (添加延时队列成功) 队列键:ORDER_TIMEOUT_NOT_EVALUATED,队列值:{orderId=200, remark=其他信息},延迟时间:20秒 2023-11-03T10:10:35.779+08:00 INFO 21480 --- [ Thread-2] c.e.r.handler.impl.OrderPaymentTimeout : 订单支付超时,自动取消订单 {orderId=100, remark=其他信息} 2023-11-03T10:10:45.860+08:00 INFO 21480 --- [ Thread-2] c.e.r.h.impl.OrderTimeoutNotEvaluated : 订单超时未评价,系统默认好评 {orderId=200, remark=其他信息}参考资料SpringBoot集成Redisson实现延迟队列 - 掘金 (juejin.cn)SpringBoot集成Redisson实现延迟队列_redssion延时队列订阅_刘鹏博.的博客-CSDN博客Maven Repository: org.redisson » redisson-spring-boot-starter (mvnrepository.com)【进阶篇】Redis实战之Redisson使用技巧详解 - 知乎 (zhihu.com)Table of Content · redisson/redisson Wiki · GitHub浅析 Redisson 的分布式延时队列 RedissonDelayedQueue 运行流程 - 掘金 (juejin.cn)Redisson分布式延时队列 RedissonDelayedQueue - 掘金 (juejin.cn)
-
Java Stream学习笔记 1.Stream介绍1.1 概述什么是Stream?java 8 新增的Stream配合同版本出现的 Lambda ,给我们操作集合(Collection)提供了极大的便利。Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。Stream对流的操作分类中间操作,每次返回一个新的流,可以有多个。(筛选filter、映射map、排序sorted、去重组合skip—limit)终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。(遍历foreach、匹配find–match、规约reduce、聚合max–min–count、收集collect)Stream特性stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。stream不会改变数据源,通常情况下会产生一个新的集合或一个值。stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。1.2 Stream与传统遍历对比几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如现有一个需求:将list集合中姓张的元素过滤到一个新的集合中,然后将过滤出来的姓张的元素中,再过滤出来长度为3的元素,存储到一个新的集合中传统遍历import java.util.ArrayList; import java.util.List; public class Demo1List { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("小昭"); list.add("殷离"); list.add("张三"); list.add("张三丰"); List<String> listA = new ArrayList<>(); for ( String s : list) { if (s.startsWith("张")) listA.add(s); } List<String> listB = new ArrayList<>(); for (String s: listA) { if (s.length() == 3) listB.add(s); } for (String s: listB) { System.out.println(s); } } }使用Stream写法import java.util.ArrayList; import java.util.List; public class Demo2Steam { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("小昭"); list.add("殷离"); list.add("张三"); list.add("张三丰"); list.stream() .filter(name -> name.startsWith("张")) .filter(name -> name.length() == 3) .forEach(name -> System.out.println(name)); } }2.Stream的创建2.0 顺序流和并行流stream和parallelStream的简单区分: stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:如果流中的数据量足够大,并行流可以加快处速度。除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流2.1 通过 java.util.Collection.stream() 方法用集合创建流@Test public void testCreateStream(){ List<String> list = Arrays.asList("a", "b", "c"); // 创建一个顺序流 Stream<String> stream = list.stream(); System.out.println("创建顺序流:stream"); stream.forEach(x-> System.out.println(x)); // 创建一个并行流 Stream<String> parallelStream = list.parallelStream(); System.out.println("创建并行流:parallelStream"); parallelStream.forEach(x-> System.out.println(x)); }创建顺序流:stream a b c 创建并行流:parallelStream b c a2.2 使用java.util.Arrays.stream(T[] array)方法用数组创建流@Test public void testCreateStream(){ int[] array1={1,3,5,6,8}; IntStream stream1 = Arrays.stream(array1); stream1.forEach(x-> System.out.println(x)); String[] array2={"1","3","5","6","8"}; Stream<String> stream2 = Arrays.stream(array2); stream2.forEach(x-> System.out.println(x)); }2.3 使用Stream的静态方法:of()、iterate()、generate()@Test public void testCreateStream(){ Stream<Integer> stream1 = Stream.of(1, 2, 3); stream1.forEach(System.out::println); Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(3); stream2.forEach(System.out::println); Stream<Double> stream3 = Stream.generate(Math::random).limit(3); stream3.forEach(System.out::println); }3.Stream使用/Stream流的常用方法在使用stream之前,先理解一个概念:Optional 。Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。Stream流的常用方法分类:终结方法:返回值类型不再是Stream接口本身类型的方法,例如:forEach方法和count方法非终结方法/延迟方法:返回值类型仍然是Stream接口自身类型的方法,除了终结方法都是延迟方法。例如:filter,limit,skip,map,conat方法名称方法作用方法种类是否支持链式调用count统计个数终结方法否forEach逐一处理终结方法否filter过滤函数拼接是limit取用前几个函数拼接是skip跳过前几个函数拼接是map映射函数拼接是concat组合函数拼接是3.1 遍历/匹配(foreach、find、match)Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的@Test public void testStream(){ List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1); // 遍历输出符合条件的元素 list.stream().filter(x -> x > 6).forEach(System.out::println); // 匹配第一个 Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst(); // 匹配任意(适用于并行流) Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny(); // 是否包含符合特定条件的元素 boolean anyMatch = list.stream().anyMatch(x -> x > 6); System.out.println("匹配第一个值:" + findFirst.get()); System.out.println("匹配任意一个值:" + findAny.get()); System.out.println("是否存在大于6的值:" + anyMatch); }7 9 8 匹配第一个值:7 匹配任意一个值:8 是否存在大于6的值:true3.2 筛选(filter)@Test public void testStream(){ List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9); Stream<Integer> stream = list.stream(); stream.filter(x -> x > 7).forEach(System.out::println); }8 93.3 聚合(max、min、count)获取Integer集合中的最大/小值@Test public void testStream(){ List<Integer> list = Arrays.asList(7, 6, 9, 4, 11, 6); // 自然排序 Optional<Integer> max = list.stream().max(Integer::compareTo); Optional<Integer> min = list.stream().min(Integer::compareTo); // 自定义排序 Optional<Integer> max2 = list.stream().max(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2); } }); Optional<Integer> min2 = list.stream().min((o1, o2) -> o1.compareTo(o2)); System.out.println("自然排序的最大值:" + max.get()+",最小值:"+min.get()); System.out.println("自定义排序的最大值:" + max2.get()+",最小值:"+min2.get()); }自然排序的最大值:11,最小值:4 自定义排序的最大值:11,最小值:4获取String集合中最长/最低的元素@Test public void testStream(){ List<String> list = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd"); Optional<String> max = list.stream().max(Comparator.comparing(String::length)); Optional<String> min = list.stream().min(Comparator.comparing(String::length)); System.out.println("最长的字符串:" + max.get()); System.out.println("最短的字符串:" + min.get()); }最长的字符串:weoujgsd 最短的字符串:pot获取员工工资最高的人@Data class Person { private String name; // 姓名 private int salary; // 薪资 private int age; // 年龄 private String sex; //性别 private String area; // 地区 } @Test public void testStream(){ List<Person> personList = new ArrayList<Person>(); personList.add(new Person("Tom", 8900, 23, "male", "New York")); personList.add(new Person("Jack", 7000, 25, "male", "Washington")); personList.add(new Person("Lily", 7800, 21, "female", "Washington")); personList.add(new Person("Anni", 8200, 24, "female", "New York")); personList.add(new Person("Owen", 9500, 25, "male", "New York")); personList.add(new Person("Alisa", 7900, 26, "female", "New York")); Optional<Person> max = personList.stream().max(Comparator.comparingInt(Person::getSalary)); Optional<Person> min = personList.stream().min(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { return Integer.compare(o1.getSalary(), o2.getSalary()); } }); System.out.println("员工工资最大值:" + max.get().getSalary()); System.out.println("员工工资最小值:" + min.get().getSalary()); }员工工资最大值:9500 员工工资最小值:7000计算Integer集合中大于6的元素的个数@Test public void testStream(){ List<Integer> list = Arrays.asList(7, 6, 4, 8, 2, 11, 9); long count = list.stream().filter(x -> x > 6).count(); System.out.println("list中大于6的元素个数:" + count); }list中大于6的元素个数:43.4 映射(map、flatMap)映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。英文字符串数组的元素全部改为大写。整数数组每个元素+3@Test public void testStream(){ String[] strArr = { "abcd", "bcdd", "defde", "fTr" }; List<String> strList = Arrays.stream(strArr).map(String::toUpperCase).collect(Collectors.toList()); List<Integer> intList = Arrays.asList(1, 3, 5, 7, 9, 11); List<Integer> intListNew = intList.stream().map(x -> x + 3).collect(Collectors.toList()); System.out.println("每个元素大写:" + strList); System.out.println("每个元素+3:" + intListNew); }每个元素大写:[ABCD, BCDD, DEFDE, FTR] 每个元素+3:[4, 6, 8, 10, 12, 14]将两个字符数组合并成一个新的字符数组@Test public void testStream(){ List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7"); List<String> listNew = list.stream().flatMap(s -> { // 将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s2 = Arrays.stream(split); return s2; }).collect(Collectors.toList()); System.out.println("处理前的集合:" + list); System.out.println("处理后的集合:" + listNew); }处理前的集合:[m,k,l,a, 1,3,5,7] 处理后的集合:[m, k, l, a, 1, 3, 5, 7]3.5 规约(reduce)归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。@Test public void testStream(){ List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4); // 求和方式1 Optional<Integer> sum = list.stream().reduce((x, y) -> x + y); // 求和方式2 Optional<Integer> sum2 = list.stream().reduce(Integer::sum); // 求和方式3 Integer sum3 = list.stream().reduce(0, Integer::sum); // 求乘积 Optional<Integer> product = list.stream().reduce((x, y) -> x * y); // 求最大值方式1 Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y); // 求最大值写法2 Integer max2 = list.stream().reduce(1, Integer::max); System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3); System.out.println("list求积:" + product.get()); System.out.println("list求和:" + max.get() + "," + max2); }list求和:29,29,29 list求积:2112 list求和:11,113.6 收集(collect)collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。collect主要依赖java.util.stream.Collectors类内置的静态方法。3.6.1 归集(toList、toSet、toMap)因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。@Data class Person { private String name; // 姓名 private int salary; // 薪资 private int age; // 年龄 private String sex; //性别 private String area; // 地区 } @Test public void testStream(){ List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20); List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList()); Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet()); List<Person> personList = new ArrayList<Person>(); personList.add(new Person("Tom", 8900, 23, "male", "New York")); personList.add(new Person("Jack", 7000, 25, "male", "Washington")); personList.add(new Person("Lily", 7800, 21, "female", "Washington")); personList.add(new Person("Anni", 8200, 24, "female", "New York")); Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000) .collect(Collectors.toMap(Person::getName, p -> p)); System.out.println("toList:" + listNew); System.out.println("toSet:" + set); System.out.println("toMap:" + map); }toList:[6, 4, 6, 6, 20] toSet:[4, 20, 6] toMap:{Tom=Person{name='Tom', salary=8900, age=23, sex='male', area='New York'}, Anni=Person{name='Anni', salary=8200, age=24, sex='female', area='New York'}}3.7 排序(sorted)sorted,中间操作。有两种排序:sorted():自然排序,流中元素需实现Comparable接口sorted(Comparator com):Comparator排序器自定义排序员工按工资、年龄排序@Data class Person { private String name; // 姓名 private int salary; // 薪资 private int age; // 年龄 private String sex; //性别 private String area; // 地区 } @Test public void testStream(){ List<Person> personList = new ArrayList<Person>(); personList.add(new Person("Sherry", 9000, 24, "female", "New York")); personList.add(new Person("Tom", 8900, 22, "male", "Washington")); personList.add(new Person("Jack", 9000, 25, "male", "Washington")); personList.add(new Person("Lily", 8800, 26, "male", "New York")); personList.add(new Person("Alisa", 9000, 26, "female", "New York")); // 按工资升序排序(自然排序) List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)) .map(Person::getName) .collect(Collectors.toList()); // 按工资倒序排序 List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()) .map(Person::getName) .collect(Collectors.toList()); // 先按工资再按年龄升序排序 List<String> newList3 = personList.stream() .sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)) .map(Person::getName) .collect(Collectors.toList()); // 先按工资再按年龄自定义排序(降序) List<String> newList4 = personList.stream().sorted((p1, p2) -> { if (p1.getSalary() == p2.getSalary()) { return p2.getAge() - p1.getAge(); } else { return p2.getSalary() - p1.getSalary(); } }).map(Person::getName).collect(Collectors.toList()); System.out.println("按工资升序排序:" + newList); System.out.println("按工资降序排序:" + newList2); System.out.println("先按工资再按年龄升序排序:" + newList3); System.out.println("先按工资再按年龄自定义降序排序:" + newList4); }按工资升序排序:[Lily, Tom, Sherry, Jack, Alisa] 按工资降序排序:[Sherry, Jack, Alisa, Tom, Lily] 先按工资再按年龄升序排序:[Lily, Tom, Sherry, Jack, Alisa] 先按工资再按年龄自定义降序排序:[Alisa, Jack, Sherry, Tom, Lily]参考资料Java Stream流(详解)_java stream()-CSDN博客【java基础】吐血总结Stream流操作_java stream流操作-CSDN博客Java 8 Stream | 菜鸟教程 (runoob.com)
-
MapStruct学习笔记 1.MapStruct介绍在现在多模块多层级的项目中,应用于应用之间,模块于模块之间数据模型一般都不通用,每层都有自己的数据模型。这种对象与对象之间的互相转换,目前都是使用get,set方法,或者使用自定义的Beans.copyProperties进行转换。使用get,set方式会使得编码非常的麻烦,BeanUtils.copyProperties的方式是使用反射的方式,对性能的消耗比较大。Mapstruct的性能远远高于BeanUtils,对象转换次数属性个数BeanUtils耗时Mapstruct耗时5千万次614秒1秒5千万次1536秒1秒5千万次2555秒1秒MapStruct是一个开源的基于Java的代码生成器,用于创建实现Java Bean之间转换的扩展映射器。使用MapStruct,我们只需要创建接口,而该库会通过注解在编译过程中自动创建具体的映射实现,大大减少了通常需要手工编写的样板代码的数量。2.maven项目使用MapStruct2.1 pom依赖<dependency> <groupId>org.mapstruct</groupId> <artifactId>mapstruct</artifactId> <version>1.5.0.Final</version> </dependency> <dependency> <groupId>org.mapstruct</groupId> <artifactId>mapstruct-processor</artifactId> <version>1.5.0.Final</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency>2.2 配置打包插件<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>17</source> <target>17</target> <annotationProcessorPaths> <path> <groupId>org.mapstruct</groupId> <artifactId>mapstruct-processor</artifactId> <version>1.5.0.Final</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins> </build>2.3 创建实体类Source .java@Data public class Source { private Long id; private Date gmtCreate; private Date createTime; private Long buyerId; private Long age; private String userNick; private String userVerified; }Target.java@Data public class `Target { private Long id; private Date gmtCreate; private Date createTime; private Long buyerId; private Long age; private String userNick; private String userVerified; }2.4 创建映射接口定义一个接口,其中包含源类和目标类之间的映射方法。MapStruct将在编译时自动为这个接口生成实现import org.mapstruct.Mapper; import org.mapstruct.factory.Mappers; @Mapper public interface SourceTargetMapper { SourceTargetMapper INSTANCE = Mappers.getMapper(SourceTargetMapper.class); Target sourceToTarget(Source source); }2.5 测试映射接口@Test public void testMapStruct(){ Source source = new Source(); source.setId(1L); source.setGmtCreate(new Date()); source.setCreateTime(new Date()); source.setBuyerId(43252534643L); source.setAge(99L); source.setUserNick("mapstruct测试"); source.setUserVerified("ok"); System.out.println(source); Target target = SourceTargetMapper.INSTANCE.sourceToTarget(source); System.out.println(target); }运行结果Source{id=1, gmtCreate=Wed Oct 11 15:46:15 CST 2023, createTime=Wed Oct 11 15:46:15 CST 2023, buyerId=43252534643, age=99, userNick='mapstruct测试', userVerified='ok'} Target{id=1, gmtCreate=Wed Oct 11 15:46:15 CST 2023, createTime=Wed Oct 11 15:46:15 CST 2023, buyerId=43252534643, age=99, userNick='mapstruct测试', userVerified='ok'}3. @Mapping解决字段名不一致的问题@Mapping(target = "targetName", source = "sourceName"),此处的意思就是在转化的过程中,将Source的Target属性值赋值给sourceName的targetName属性。@Data public class Source { private String sourceName; } @Data public class Target { private String targetName; }import org.mapstruct.Mapper; import org.mapstruct.Mapping; @Mapper public interface SourceTargetMapper { @Mapping(target = "targetName", source = "sourceName") Target sourceToTarget(Source source); }4.String转日期&String转数字&忽略某个字端&给默认值等@Mapping(target = "createTime", source = "createTime", dateFormat = "yyyy-MM-dd") @Mapping(target = "age", source = "age", numberFormat = "#0.00") @Mapping(target = "id", ignore = true) @Mapping(target = "userVerified", defaultValue = "defaultValue-2")参考资料MapStruct使用指南 - 知乎 (zhihu.com)告别BeanUtils,Mapstruct从入门到精通 - 掘金 (juejin.cn)Maven中配置maven-compiler-plugin 插件和jdk 17版本 - 楼兰胡杨 - 博客园 (cnblogs.com)
-
EasyExcel学习笔记 1.简介1.1 EasyExcel简介Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便2.SpringBoot集成easyexcel2.1 pom依赖<dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.3.2</version> </dependency>2.2 简单使用实体类@Data public class ArticleScoreData { @ExcelProperty("姓名") private String name; @ExcelProperty("文章") private String title; @ExcelProperty("得分") private Double score; }读操作待读取article.xlsx姓名文章得分张三张三的文章87李四李四的文章34王五王五的文章99读操作代码@Test public void testRead() { String pathName = "C:\\Users\\jupiter\\Desktop\\article.xlsx"; // PageReadListener:excel一行一行的回调监听器 EasyExcel.read(pathName, ArticleScoreData.class, new PageReadListener<ArticleScoreData>(dataList -> { for (ArticleScoreData demoData : dataList) { log.info("读取到一条数据{}", "姓名:" + demoData.getName() + " 文章:" + demoData.getTitle() + " 得分:" + demoData.getScore()); } })).sheet().doRead(); }运行结果2023-09-14T21:41:36.957+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:张三 文章:张三的文章 得分:87.0 2023-09-14T21:41:36.962+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:李四 文章:李四的文章 得分:34.0 2023-09-14T21:41:36.962+08:00 INFO 81220 --- [ main] c.e.e.EasyExcelStudyApplicationTests : 读取到一条数据姓名:王五 文章:王五的文章 得分:99.0写操作代码@Test public void testWrite() { String xlsxPath = "C:\\Users\\jupiter\\Desktop\\output.xls"; List<ArticleScoreData> dataList = new ArrayList<>(); for (int i = 0; i < 5; i++) { ArticleScoreData data = new ArticleScoreData(); data.setName("姓名" + i) data.setTitle("文章" + i); data.setScore(80.0+i); dataList.add(data); } EasyExcel.write(xlsxPath, ArticleScoreData.class) .sheet("文章得分表") .doWrite(() -> dataList); }运行效果output.xls姓名文章得分姓名0文章080姓名1文章181姓名2文章282姓名3文章383姓名4文章4842.3 单独实现最简单的读的监听器进行文件读取待读取article.xlsx姓名文章得分张三张三的文章87李四李四的文章34王五王五的文章99实体类@Data public class ArticleScoreData { @ExcelProperty("姓名") private String name; @ExcelProperty("文章") private String title; @ExcelProperty("得分") private Double score; }SimpleDataListenerimport cn.hutool.json.JSONUtil; import com.alibaba.excel.context.AnalysisContext; import com.alibaba.excel.metadata.data.ReadCellData; import com.alibaba.excel.read.listener.ReadListener; import com.example.easyexcelstudy.domain.entity.ArticleScoreData; import lombok.extern.slf4j.Slf4j; import java.util.Map; @Slf4j public class SimpleDataListener implements ReadListener<ArticleScoreData> { /** * 解析excel的表头-第一行 */ @Override public void invokeHead(Map<Integer, ReadCellData<?>> headMap, AnalysisContext context) { ReadListener.super.invokeHead(headMap, context); log.info("读取到表头:{}",JSONUtil.toJsonStr(headMap)); } /** * 读取excel的每一行都会调用该方法 */ @Override public void invoke(ArticleScoreData articleScoreData, AnalysisContext analysisContext) { log.info("解析到一条数据:{}", JSONUtil.toJsonStr(articleScoreData)); } /** * 所有数据解析完成了,都会来调用 */ @Override public void doAfterAllAnalysed(AnalysisContext context) { log.info("所有数据解析完成!"); } } test @Test public void testReadBySimpleDataListener() { String xlsxPath = "C:\\Users\\jupiter\\Desktop\\article.xlsx"; EasyExcel.read(xlsxPath,new SimpleDataListener()).sheet().doRead(); } 运行结果2023-09-14T22:39:47.596+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 读取到表头: { "0": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "姓名", "rowIndex": 0, "columnIndex": 0 }, "1": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "文章", "rowIndex": 0, "columnIndex": 1 }, "2": { "dataFormatData": { "index": 0, "format": "General" }, "type": "STRING", "stringValue": "得分", "rowIndex": 0, "columnIndex": 2 } } 2023-09-14T22:39:47.689+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"张三的文章","score":87,"name":"张三"} 2023-09-14T22:39:47.690+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"李四的文章","score":34,"name":"李四"} 2023-09-14T22:39:47.690+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 解析到一条数据:{"title":"王五的文章","score":99,"name":"王五"} 2023-09-14T22:39:47.691+08:00 INFO 186196 --- [ main] c.e.e.util.excel.SimpleDataListener : 所有数据解析完成!2.4 (★★★)读取超级版本:无需实体类,实现任意excel文件的读取待读取excel文件sheet1sheet2正常情况2 表头1表头2表头3表头4表头5表头1表头2表头3表头4表头5列头1 列头2 列头3 ExcelSheetDataReadListenerpackage com.example.excelstudy.utils.excel; import cn.hutool.json.JSONUtil; import com.alibaba.excel.context.AnalysisContext; import com.alibaba.excel.enums.CellExtraTypeEnum; import com.alibaba.excel.event.AnalysisEventListener; import com.alibaba.excel.metadata.CellExtra; import lombok.extern.slf4j.Slf4j; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * @author LuoJia * @version 1.0 * @description: 万能excel的单个sheet读取Listener * @date 2023/9/15 11:24 */ @Slf4j public class ExcelSheetDataReadListener extends AnalysisEventListener<Map<Integer,String>> { // 表格sheet编号 int sheetNo; // 表格行数 int rowCount=0; // 表格列数 int colCount=0; // 用于存储原生读取到的数据 List<Map<Integer, String>> lineDataList = new ArrayList<>(); // 用于存储表格的合并单元格的区域列表 List<CellExtra> mergeAreaList = new ArrayList<>(); /** * 解析excel的表头-即读取第一行 */ @Override public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) { // 设置不忽略空行 context.readWorkbookHolder().setIgnoreEmptyRow(false); // 获取sheetNo sheetNo = context.readSheetHolder().getSheetNo(); // 更新表格行列数 rowCount += 1; colCount = Math.max(colCount, headMap.size()); // 保存原始的单行数据 lineDataList.add(headMap); //log.info("读取到表头:{}", JSONUtil.toJsonStr(headMap)); } /** * 读取excel的每一行都会调用该方法 */ @Override public void invoke(Map<Integer,String> lineData, AnalysisContext context) { // 更新表格行列数 rowCount += 1; colCount = Math.max(colCount, lineData.size()); // 保存原始的单行数据 lineDataList.add(lineData); //log.info("解析到一条数据:{}", JSONUtil.toJsonStr(lineData)); } /** * 获取合并单元格的范围 */ @Override public void extra(CellExtra extra, AnalysisContext context) { if (extra.getType() != CellExtraTypeEnum.MERGE) { return ; } mergeAreaList.add(extra); } /** * 所有数据解析完成了,都会来调用 */ @Override public void doAfterAllAnalysed(AnalysisContext context) { log.info("============================================================="); log.info("sheet{}-所有数据解析完成!sheet总行数:{},总列数:{}",sheetNo+1,rowCount,colCount); // 处理mergerList--即处理所有的合并单元格 for(CellExtra mergeArea:mergeAreaList){ // 获取填充部分的单元格的有效值 String value = lineDataList.get(mergeArea.getFirstRowIndex()).get(mergeArea.getFirstColumnIndex()); // 对合并单元格的为null值部分的数据进行有效填充 for (int i = mergeArea.getFirstRowIndex(); i <= mergeArea.getLastRowIndex(); i++) { for (int j = mergeArea.getFirstColumnIndex(); j <= mergeArea.getLastColumnIndex(); j++) { // 合并单元格的最最左上角已经被有效填充了,跳过 if(i==mergeArea.getFirstRowIndex()&&j== mergeArea.getFirstColumnIndex()){ continue; } // 对合并单元格的其他单元格进行数据填充 lineDataList.get(i).put(j,value); } } } // 打印表格数据 for (int i = 0; i < rowCount; i++) { log.info("sheet第{}行数据:{}",(i+1),JSONUtil.toJsonStr(lineDataList.get(i))); } log.info("============================================================="); } }test @Test public void testRead() throws FileNotFoundException { String pathName = "C:\\Users\\LuoJia\\Desktop\\test.xlsx"; InputStream inputStream = new FileInputStream(new File(pathName)); // 创建excel读取reader ExcelReader excelReader = EasyExcel.read(inputStream).extraRead(CellExtraTypeEnum.MERGE).ignoreEmptyRow(false).build(); // 创建每个sheet的读取listener并执行读取 List<ReadSheet> readSheets = excelReader.excelExecutor().sheetList(); List<ExcelSheetDataReadListener> listenerList = new ArrayList<>(readSheets.size()); // 用于进行数据和合并单元格区域保存 //读取多个sheet List<ReadSheet> sheetList = readSheets.stream().map(sheet -> { ExcelSheetDataReadListener listener = new ExcelSheetDataReadListener(); ReadSheet readSheet = EasyExcel.readSheet(sheet.getSheetName()).registerReadListener(listener).build(); listenerList.add(listener); return readSheet; }).collect(Collectors.toList()); excelReader.read(sheetList); // 释放资源 excelReader.finish(); }运行结果xxxx: ============================================================= xxxx: sheet1-所有数据解析完成!sheet总行数:10,总列数:6 xxxx: sheet第1行数据:{} xxxx: sheet第2行数据:{"0":"异常情况","1":"异常情况","2":"异常情况","3":"异常情况","4":"异常情况"} xxxx: sheet第3行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第4行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第5行数据:{} xxxx: sheet第6行数据:{} xxxx: sheet第7行数据:{"3":"dasdada","4":"dasdada"} xxxx: sheet第8行数据:{"3":"dasdada","4":"dasdada"} xxxx: sheet第9行数据:{} xxxx: sheet第10行数据:{"5":"saSASA"} xxxx: ============================================================= xxxx: ============================================================= xxxx: sheet2-所有数据解析完成!sheet总行数:2,总列数:5 xxxx: sheet第1行数据:{"0":"正常情况1","1":"正常情况1","2":"正常情况1","3":"正常情况1","4":"正常情况1"} xxxx: sheet第2行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: ============================================================= xxxx: ============================================================= xxxx: sheet3-所有数据解析完成!sheet总行数:5,总列数:5 xxxx: sheet第1行数据:{"0":"正常情况1","1":"正常情况1","2":"正常情况1","3":"正常情况1","4":"正常情况1"} xxxx: sheet第2行数据:{"0":"表头1","1":"表头2","2":"表头3","3":"表头4","4":"表头5"} xxxx: sheet第3行数据:{"0":"列头1"} xxxx: sheet第4行数据:{"0":"列头2"} xxxx: sheet第5行数据:{"0":"列头3"} xxxx: =============================================================2.5(★★★)带合并单元格的写入ExcelCustomMergeHandler(处理单元格合并的handler) /** * @author jupiter * @version 1.0 * @description: TODO * @date 2023/9/16 23:01 */ @Data @NoArgsConstructor @AllArgsConstructor @Slf4j public class ExcelCustomMergeHandler implements CellWriteHandler { // 表格行数 int rowCount; // 表格列数 int colCount; // 用于存储表格的合并单元格的区域列表 List<CellExtra> mergeAreaList = new ArrayList<>(); /** * @description: 在单元格被创建之前的处理 * @author jupiter * @date: 2023/9/16 23:12 */ @Override public void beforeCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Row row, Head head, Integer columnIndex, Integer relativeRowIndex, Boolean isHead) { CellWriteHandler.super.beforeCellCreate(writeSheetHolder, writeTableHolder, row, head, columnIndex, relativeRowIndex, isHead); } /** * @description: 在单元格被创建之后的处理 * @author jupiter * @date: 2023/9/16 23:12 */ @Override public void afterCellCreate(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) { CellWriteHandler.super.afterCellCreate(writeSheetHolder, writeTableHolder, cell, head, relativeRowIndex, isHead); } @Override public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) { // 获取当前的单元格 Sheet sheet = writeSheetHolder.getSheet(); // 设置单元格居中 CellStyle cellStyle = cell.getCellStyle(); cellStyle.setAlignment(HorizontalAlignment.CENTER); //log.info("当前处理的单元格序号:{},{}",cell.getRowIndex(),cell.getColumnIndex()); // 在最后一个单元格处理单元格合并 if(cell.getRowIndex()==rowCount-1&&cell.getColumnIndex()==colCount-1){ for(CellExtra mergeArea:mergeAreaList){ CellRangeAddress cellAddresses = new CellRangeAddress(mergeArea.getFirstRowIndex(),mergeArea.getLastRowIndex(),mergeArea.getFirstColumnIndex(),mergeArea.getLastColumnIndex()); log.info("写入添加合并区域:{}", JSONUtil.toJsonStr(mergeArea)); sheet.addMergedRegion(cellAddresses); } } } }test(这里为了避免构建数据直接衔接了2.4用的读取后的数据)@Test public void testCustomWrite() throws FileNotFoundException { String pathName = "C:\\Users\\jupiter\\Desktop\\test.xlsx"; // 创建excel读取reader ExcelReader excelReader = EasyExcel.read(pathName).extraRead(CellExtraTypeEnum.MERGE).ignoreEmptyRow(false).build(); // 创建每个sheet的读取listener并执行读取 List<ReadSheet> readSheets = excelReader.excelExecutor().sheetList(); List<ExcelSheetDataReadListener> listenerList = new ArrayList<>(readSheets.size()); // 用于进行数据和合并单元格区域保存 //读取多个sheet List<ReadSheet> sheetList = readSheets.stream().map(sheet -> { ExcelSheetDataReadListener listener = new ExcelSheetDataReadListener(); ReadSheet readSheet = EasyExcel.readSheet(sheet.getSheetName()).registerReadListener(listener).build(); listenerList.add(listener); return readSheet; }).collect(Collectors.toList()); excelReader.read(sheetList); // 释放资源 excelReader.finish(); // 开始执行excel写入 pathName = "C:\\Users\\jupiter\\Desktop\\testWrite.xlsx"; // 创建excel写入writer ExcelWriter excelWriter = EasyExcel.write(pathName).build(); // 写入多个sheetList for (int i = 0; i < sheetList.size(); i++) { // 单元格总行数 int rowCount = listenerList.get(i).getRowCount(); // 单元格总列数 int colCount = listenerList.get(i).getColCount(); // sheet的逐行数据 List<Map<Integer, String>> lineDataList = listenerList.get(i).getLineDataList(); // 需要合并的单元格区域 List<CellExtra> mergeAreaList = listenerList.get(i).getMergeAreaList(); // 处理单元格合并的handle ExcelCustomMergeHandler writeHandle = new ExcelCustomMergeHandler(rowCount,colCount,mergeAreaList); // 构建sheet写入对象 WriteSheet writeSheet = EasyExcel.writerSheet(i,sheetList.get(i).getSheetName()).registerWriteHandler(writeHandle).build(); // 执行sheet数据写入 excelWriter.write(lineDataList,writeSheet); } // 释放资源 excelWriter.finish(); }执行效果test.xlsxsheet1sheet2testWrite.xlsxsheet1sheet2参考资料EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel (alibaba.com)EasyExcel全面教程快速上手_easeexcel_知春秋的博客-CSDN博客解决EasyExcel工具读取Excel空数据行的问题_easyexcel空行导入问题_流沙QS的博客-CSDN博客EasyExcel导入(含表头验证+空白行读取)_easyexcel导入表头校验_MMO_的博客-CSDN博客阿里的easyExcel_easyexcel aftercelldispose_一直想成为大神的菜鸟的博客-CSDN博客easyexcel导出中自定义合并单元格,通过重写AbstractRowWriteHandler_easyexcel合并单元格策略_阿莫西林的博客-CSDN博客EasyExcel导出自定义合并单元格的策略_我可能在扯淡的博客-CSDN博客
-
idea配置优化-默认maven/自动导包/方法类注释模板 1.配置默认mavenSTEP1:配置本项目File-->Setting配置所有新项目File-->New Projects Setup-->Setting for New Projects...STEP2:2.配置自动导包STEP1:配置本项目File-->Setting配置所有新项目File-->New Projects Setup-->Setting for New Projects...STEP2:3.配置注释3.1 新建类的时候自动添加类注释STEP1:File-->SettingSTEP2:如上图所示添加注释:/** * @description: TODO * @author ${USER} * @date ${DATE} ${TIME} * @version 1.0 */给接口和枚举加上的方式同理。3.2 自定义模版配置(类,方法)按照上图的提示,找到位置1的Live Templates找到位置2,选择下拉框中的Enter选项到位置3点击“+”号,首先选择Template Group,新建一个自己的分组鼠标选中新建的分组,如位置4的ybyGroup,然后在点击位置3的“+”号,选择Live Template给模版添加快捷提示的字符,描述,和模版,比如我这里新增了两个,方法的注释,类注释*在位置5处的Template text里面贴上模版内容在位置6选择应用的范围,一般选择EveryWhere里面的Java就可以了在位置7配置Template Text里面用$修饰的属性,具体配置截图如下:params的default value:groovyScript("def result=''; def params=\"${_1}\".replaceAll('[\\\\[|\\\\]|\\\\s]', '').split(',').toList(); for(i = 0; i < params.size(); i++) {result+='' + params[i] + ((i < params.size() - 1) ? '\\n':'')}; return result", methodParameters())方法注释模版:** * @description: TODO * @param: $params$ * @return: $returns$ * @author $USER$ * @date: $date$ $time$ */ 类注释模版:** * @description: TODO * @author $user$ * @date $date$ $time$ * @version 1.0 */参考资料idea注释模版配置(吐血推荐!!!)_ida注释模板_骑着乌龟漫步的博客-CSDN博客IDEA设置方法注释模板_idea设置注释模板_布丁吖的博客-CSDN博客
-
JWT(JSON Web Token)学习笔记 1.简介1.1 什么是JWT?官网地址: https://jwt.io/introduction/定义: Json Web Token(JWT)是一个开放标准(rfc7519),它定义了一种紧凑的、自包含的方式,用于在各方之间以JSON对象安全地传输信息。此信息可以验证和信任,因为它是数字签名的。 jwt可以使用密钥(使用HMAC算法)或使用RSA或ECDSA的公钥/私钥对进行签名通俗解释:JSON Web Token,简称JWT,也就是通过JSON形式作为Web应用中的令牌,用于在各方之间安全地将信息作为JSON对象传输。在数据传输过程中还可以完成数据加密、签名等相关处理。1.2 JWT具体的作用/什么时候使用 JWT ?授权:这是使用 JWT 的最常见方案。用户登录后,每个后续请求都将包含 JWT,允许用户访问该令牌允许的路由、服务和资源。单点登录是当今广泛使用 JWT 的一项功能,因为它的开销很小,并且能够跨不同域轻松使用。信息交换:JSON Web令牌是在各方之间安全传输信息的好方法。由于 JWT 可以签名(例如,使用公钥/私钥对),因此您可以确定发送方就是他们所说的人。此外,由于签名是使用标头和有效负载计算的,因此您还可以验证内容是否未被篡改。1.3 为什么选择了使用JWT1.3.1 基于传统的 Session 认证认证过程http协议本身是一种无状态的协议,这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,即使验证通过后,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这就是传统的基于session认证。存在的问题每个用户经过应用认证之后,应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力。因为是基于cookie来进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。在前后端分离系统中就更加痛苦,前后端分离在应用解耦后增加了部署的复杂性。通常用户一次请求就要转发多次。如果用session 每次携带sessionid 到服务器,服务器还要查询用户信息。同时如果用户很多,这些信息存储在服务器内存中,给服务器增加负担。还有就是CSRF攻击(跨站伪造请求攻击),session是基于cookie进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。还有就是sessionid就是一个特征值,表达的信息不够丰富,不容易扩展。如果你后端应用是多节点部署。那么就需要实现session共享机制。集群应用的搭建将变得十分困难。1.3.2 基于JWT认证基于JWT认证首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT(Token)。形成的JWT就是一个形同xxxxx.yyyyy.zzzzz的字符串, token = head.payload.singurater后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。jwt的优点简洁(Compact): 可以通过URL,POST参数或者在HTTP header发送,由于其数据量小,并不会占用过多带宽自包含(Self-contained):负载中包含了所有用户所需要的信息,避免了多次查询数据库,减轻了数据库的压力因为Token是以JSON加密的形式保存在客户端的,所以JWT是跨语言的,原则上任何web形式都支持。不需要在服务端保存会话信息,特别适用于分布式微服务。2.JWT的结构JWT 由三部分组成2.1 Header(头部)是一个JSON 对象, 描述JWT的元数据,eg:# alg是签名算法,默认是HS256, # typ是token类型,一般JWT默认为JWT { "alg": "HS256", "typ": "JWT" }2.2 载荷-payload是一个JSON 对象, 用来存放实际需要传递的数据,eg:{ "iss": "songshu", "sub": "1234567890", "name": "haha", "admin": true }其中payload官方规定了7个字段:iss (issuer):签发人、 exp (expiration time):过期时间 sub (subject):主题 aud (audience):受众 nbf (Not Before):生效时间 iat (Issued At):签发时间 jti (JWT ID):编号$\color{red}{ 注意:对于已签名的令牌,此信息虽然受到保护以防止篡改,但任何人都可以读取。不要将机密信息放在 JWT 的有效负载或标头元素中,除非它已加密。}$2.3 签名(Signature)signature是对前两部分的签名,防止数据篡改。需要指定一个密钥(secret)这个密钥只有服务器才知道,不能泄露给客户端使用 Header 里面指定的签名算法(例如,如果要使用 HMAC SHA256 算法),按照下面的公式产生签名:HMACSHA256( base64UrlEncode(header) + "." +base64UrlEncode(payload), secret)把 Header、Payload、Signature 三个部分拼成一个字符串:Header.Payload.Signature = xxxx.yyy.zzz3.使用JWT3.1 引入jwt依赖<!--引入jwt--> <dependency> <groupId>com.auth0</groupId> <artifactId>java-jwt</artifactId> <version>3.4.0</version> </dependency>3.2 使用测试生成JWT令牌@Test public void testGetJWTToken() { Calendar instance = Calendar.getInstance(); instance.add(Calendar.SECOND, 900);//Calendar.SECOND代表单位为秒 //生成令牌 String token = JWT.create() .withClaim("username", "李四")//设置payload,保存自定义用户名,可设置多个 .withExpiresAt(instance.getTime())//设置过期时间 .sign(Algorithm.HMAC256("jupiter"));//设置加密算法及签名密钥,这里使用了默认的HMAC256 //输出令牌 System.out.println(token); }eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2OTM4OTcyOTUsInVzZXJuYW1lIjoi5p2O5ZubIn0.vO3kvqrFx4AlEs1qnFP7ghFeCIUAXFod4lH3SLhc5RE验证JWT令牌@Test public void testDecodeJWTToken(){ String token = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2OTM4OTcyOTUsInVzZXJuYW1lIjoi5p2O5ZubIn0.vO3kvqrFx4AlEs1qnFP7ghFeCIUAXFod4lH3SLhc5RE"; JWTVerifier jwtVerifier = JWT.require(Algorithm.HMAC256("jupiter")).build(); DecodedJWT decodedJWT = jwtVerifier.verify(token);//验证token System.out.println("用户名: " + decodedJWT.getClaim("username").asString()); // 存的是时候是什么类型,取得时候就是什么类型,否则取出来的是null。 System.out.println("过期时间: "+decodedJWT.getExpiresAt()); }用户名: 李四 过期时间: Tue Sep 05 15:01:35 CST 20233.3 验证过程中可能会出现的异常SignatureVerificationException: 签名不一致异常:系统中并未签发过该token,一般是恶意用户伪造出来的 TokenExpiredException: 令牌过期异常 AlgorithmMismatchException: 算法不匹配异常:签名算法和验签算法不一致 InvalidClaimException: 失效的payload异常:token无效3.4 封装工具类public class JWTUtils { private static final String SIGNATURE="jupiter";//加密密钥 /** * 生成token header.payload.signatureResult * @param map : 需要保存的payload,也就是用户信息 * @return */ public static String getToken(Map<String,String> map){ Calendar instance = Calendar.getInstance(); instance.add(Calendar.MINUTE,4320);//3天过期 JWTCreator.Builder builder = JWT.create(); //设置payload map.forEach((k,v)->{ builder.withClaim(k,v); }); //设置过期时间 builder.withExpiresAt(instance.getTime()); //设置加密算法和加密密钥 String token = builder.sign(Algorithm.HMAC256(SIGNATURE)); return token; } /** * 验证token的合法性,若验证不通过,直接抛出异常 * @param token */ public static DecodedJWT verify(String token){ return JWT.require(Algorithm.HMAC256(SIGNATURE)).build().verify(token); } }4.SpringBoot项目整合使用在实际场景当中,我们需要对用户每一次的请求做验证,如果将每次验证的代码都要写一遍,这将造成大量代码的冗余,因此采用springmvc当中的拦截器InterceptorJWTInterceptorpublic class JWTInterceptor implements HandlerInterceptor { /** * 这里我们只需要实现请求之前的验证即可,因此只要实现preHandle()方法即可 * @param request * @param response * @param handler * @return * @throws Exception */ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //一般我们要求将token放在请求的header中,所以这里我们从request中拿token String token = request.getHeader("token"); HashMap<Object, Object> map = new HashMap<>(); try { JWTUtils.verify(token); return true;//验证通过,放行 }catch (SignatureVerificationException e){ e.printStackTrace(); map.put("msg","签名错误"); }catch (AlgorithmMismatchException e){ e.printStackTrace(); map.put("msg","加密算法不一致"); }catch (TokenExpiredException e){ e.printStackTrace(); map.put("msg","token已过期"); }catch (Exception e) { e.printStackTrace(); map.put("msg","token无效"); } map.put("state",false);//设置状态 //这里返回json格式的map,只能手动将map处理成json 使用jackson String json = new ObjectMapper().writeValueAsString(map); response.setContentType("application/json;charset=UTF-8"); response.getWriter().println(json); return false; } }然后对拦截器进行配置JWTInterceptorConfig@Configuration public class JWTInterceptorConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new JWTInterceptor()) .addPathPatterns("/**")//拦截所有请求 .excludePathPatterns("/user/login");//放行登录请求 } }参考资料JWT的学习笔记_algorithmmismatchexception 算法不匹配是什么原因_'小竹子'的博客-CSDN博客JWT(JSON Web Token) 学习笔记(整合Spring Boot)_jwt.getclaims_songshu。的博客-CSDN博客JWT 的结构详解_jwt结构_荆茗Scaler的博客-CSDN博客
-
JVM GC日志输出配置 1.命令格式java <GC日志参数> -jar <your_application.jar>2. JDK8 具体的GC日志参数基本(必备)JVM配置描述-Xloggc:/path/to/gc.log写入 GC 日志的路径-XX:+UseGCLogFileRotation启用 GC 日志文件轮换-XX:NumberOfGCLogFiles=5要保留的轮换 GC 日志文件数-XX:GCLogFileSize=104857600用于启动轮换的每个 GC 日志文件的大小-XX:+PrintGCDetails详细的GC日志-XX:+PrintGCDateStamps实际日期和时间戳-XX:+PrintGCApplicationStoppedTime应用程序在 GC 期间停止的时间量-XX:+PrintGCApplicationConcurrentTime应用程序在 GC 之间运行的时间量-XX:-PrintCommandLineFlags打印 GC 日志中的所有命令行标志增强JVM配置描述-XX:+PrintAdaptiveSizePolicy有关GC工程的详细信息-XX:+PrintTenuringDistribution幸存者空间的使用和分配-XX:+PrintReferenceGC处理引用所花费的时间3.JDK17具体的GC日志参数基本(必备)-Xlog参数\JVM配置描述:file=/opt/gc-%t.log写入 GC 日志的路径,%t表示当前时间:filesize=104857600,filecount=5启用日志分割,保留分割 GC 日志文件数+单个GC日志文件的大小<br/>超过了限制将会执行循环写入,先进先出式写入gc*详细的GC日志level,tags,time,uptime,pid实际日期和时间戳 与关键信息safepoint应用程序在 GC 期间停止的时间量-XX:-PrintCommandLineFlags打印 GC 日志中的所有命令行标志java -Xlog:gc*,safepoint:file=gc-%t.log:level,tags,time,uptime,pid:filesize=104857600,filecount=5 -jar <your_application.jar> 增强-Xlog参数\JVM配置描述gc+ergo*=trace有关GC工程的详细信息gc+age=trace幸存者空间的使用和分配gc+phases*=trace处理引用所花费的时间java -Xlog:gc*,safepoint,gc+ergo*=trace,gc+age=trace,gc+phases*=trace:file=gc-%t.log:level,tags,time,uptime,pid:filesize=104857600,filecount=5 -jar <your_application.jar>参考资料Java中的GC(垃圾回收)log ,以及 JVM 介绍_gc java命令_sun0322的博客-CSDN博客Java GC算法——日志解读与分析(GC参数基础配置分析)-腾讯云开发者社区-腾讯云 (tencent.com)JVM 配置GC日志_jvm打印gc日志_Coco_淳的博客-CSDN博客一篇带你搞定⭐《生产环境JVM日志配置》⭐_不学会Ⅳ的博客-CSDN博客