搜索到
372
篇与
的结果
-
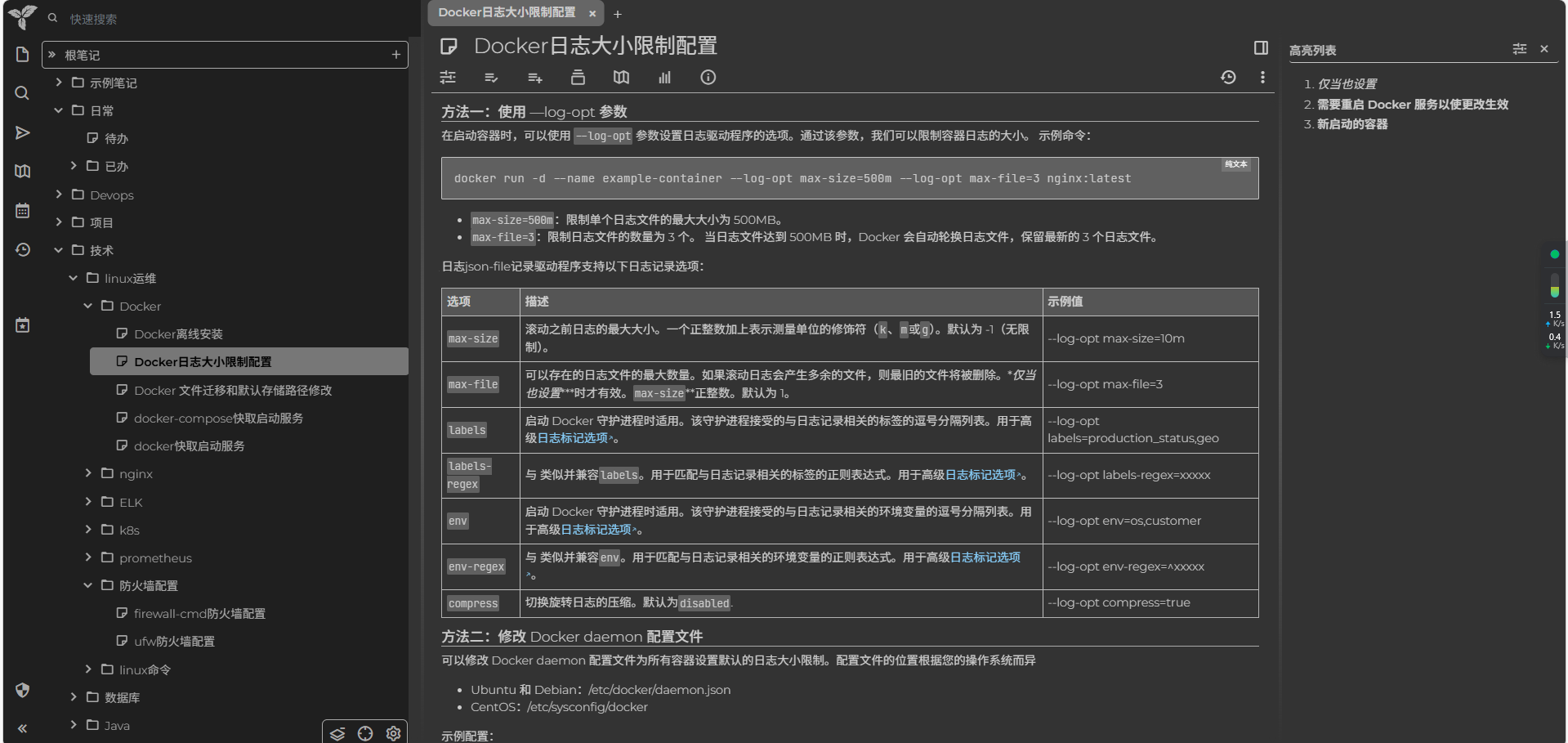
 Docker 离线安装 下载 Docker 二进制包# 创建下载目录 mkdir -p /data && cd /data # 下载 Docker 29.5.3 二进制包 wget https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-29.5.3.tgz # 解压 Docker 二进制包 sudo tar -xzvf docker-29.5.3.tgz # 将二进制文件复制到系统 PATH sudo cp docker/* /usr/bin/ # 验证安装 docker --version # 预期输出:Docker version 29.5.3, build xxx创建 systemd 服务文件# 创建 Docker 服务文件 sudo tee /etc/systemd/system/docker.service <<-'EOF' [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target EOFsystemctl daemon-reload systemctl start docker systemctl enable docker systemctl status docker
Docker 离线安装 下载 Docker 二进制包# 创建下载目录 mkdir -p /data && cd /data # 下载 Docker 29.5.3 二进制包 wget https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-29.5.3.tgz # 解压 Docker 二进制包 sudo tar -xzvf docker-29.5.3.tgz # 将二进制文件复制到系统 PATH sudo cp docker/* /usr/bin/ # 验证安装 docker --version # 预期输出:Docker version 29.5.3, build xxx创建 systemd 服务文件# 创建 Docker 服务文件 sudo tee /etc/systemd/system/docker.service <<-'EOF' [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target EOFsystemctl daemon-reload systemctl start docker systemctl enable docker systemctl status docker -
Kibana 8.14.3 完整部署方案 一、整体规划项目值运行用户appKibana 安装路径/data/app/kibana-serverKibana 配置目录/data/app/kibana-server/configKibana 日志目录/data/app/kibana-logs监听端口5601访问协议HTTP(可后续配置 HTTPS)对接 ES 地址https://192.168.101.44:9200(使用你之前服务器的 IP)二、完整部署步骤2.1 下载并解压 Kibana(使用国内镜像)# 切换到 app 用户 sudo -i -u app # 进入安装目录 cd /data/app # 使用华为云镜像下载 Kibana 8.14.3 wget https://mirrors.huaweicloud.com/kibana/8.14.3/kibana-8.14.3-linux-x86_64.tar.gz # 解压 tar xzvf kibana-8.14.3-linux-x86_64.tar.gz # 重命名目录 mv kibana-8.14.3 kibana-server # 清理安装包 rm -f kibana-8.14.3-linux-x86_64.tar.gz # 创建日志目录 mkdir -p /data/app/kibana-logs2.2 配置 Kibana# 备份原始配置 cp /data/app/kibana-server/config/kibana.yml /data/app/kibana-server/config/kibana.yml.bak # 编辑配置文件 vi /data/app/kibana-server/config/kibana.yml写入以下完整配置(根据你的实际环境修改 ES 地址和密码):# ======================== 服务器配置 ======================== server.host: "0.0.0.0" server.port: 5601 # ======================== Elasticsearch 连接配置 ======================== elasticsearch.hosts: ["http://192.168.101.44:9200"] elasticsearch.username: "kibana" elasticsearch.password: "YourKibanaPassword123!" elasticsearch.ssl.verificationMode: none # ======================== 新版日志配置(替代 logging.dest) ======================== logging: appenders: file: type: file fileName: /data/app/kibana-logs/kibana.log layout: type: json root: appenders: [file] level: info # ======================== 其他配置 ======================== i18n.locale: "zh-CN"2.3 设置目录权限# 退出 app 用户 exit # 确保所有目录属主为 app sudo chown -R app:app /data/app/kibana-server sudo chown -R app:app /data/app/kibana-logs2.4 配置系统参数(可选,提高并发)# 增加文件描述符限制(与 ES 保持一致) echo "app soft nofile 65535" | sudo tee -a /etc/security/limits.conf echo "app hard nofile 65535" | sudo tee -a /etc/security/limits.conf三、创建 Systemd 服务文件sudo vi /etc/systemd/system/kibana.service写入以下内容:[Unit] Description=Kibana Server Documentation=https://www.elastic.co After=network.target elasticsearch.service Wants=elasticsearch.service [Service] Type=simple User=app Group=app WorkingDirectory=/data/app/kibana-server Environment=NODE_OPTIONS="--max-old-space-size=512" ExecStart=/data/app/kibana-server/bin/kibana ExecReload=/bin/kill -HUP $MAINPID KillMode=process Restart=on-failure RestartSec=3 LimitNOFILE=65535 LimitNPROC=4096 TimeoutStopSec=20 [Install] WantedBy=multi-user.target四、启动并管理 Kibana4.1 启动服务# 重载 systemd 配置 sudo systemctl daemon-reload # 启动 Kibana sudo systemctl start kibana # 设置开机自启 sudo systemctl enable kibana # 查看服务状态 sudo systemctl status kibana4.2 查看日志(排查问题)# 查看 systemd 日志 sudo journalctl -u kibana -f # 查看 Kibana 自身日志 sudo tail -f /data/app/kibana-logs/kibana.log4.3 常用管理命令# 启动 sudo systemctl start kibana # 停止 sudo systemctl stop kibana # 重启 sudo systemctl restart kibana # 查看状态 sudo systemctl status kibana # 查看实时日志 sudo journalctl -u kibana -f # 禁用开机自启 sudo systemctl disable kibana五、防火墙配置# 开放 Kibana 端口 5601 sudo firewall-cmd --permanent --add-port=5601/tcp sudo firewall-cmd --reload六、验证 Kibana 部署6.1 本地测试# 访问 Kibana 首页 curl http://localhost:5601 # 应该返回 HTML 内容(包含 "Kibana" 字样)6.2 浏览器访问打开浏览器,访问 http://<你的服务器IP>:5601如果连接正常,会看到 Kibana 欢迎页面首次访问可能需要等待几分钟初始化索引不需要额外登录(Kibana 本身不设认证,但连接 ES 使用了认证)6.3 测试与 ES 的数据交互进入 Kibana 界面 → 点击左上角菜单 → Management → Dev Tools在控制台中执行以下命令(测试 ES 连接):# 查看集群健康状态 GET /_cluster/health # 创建测试索引 PUT /test-kibana-index # 添加文档 POST /test-kibana-index/_doc { "message": "Hello Kibana!", "timestamp": "2026-06-03" } # 搜索文档 GET /test-kibana-index/_search七、常见问题排查问题可能原因解决方案Kibana 无法启动端口被占用`sudo netstat -tlnpgrep 5601,修改 server.port`连接 ES 失败ES 地址/认证错误检查 elasticsearch.hosts、用户名、密码SSL 证书错误ES 使用自签名证书设置 elasticsearch.ssl.verificationMode: nonekibana 用户不存在未在 ES 中创建在 ES 中执行创建 kibana 用户的 API日志目录权限错误目录属主不是 appsudo chown -R app:app /data/app/kibana-logs访问 5601 无响应防火墙未开放检查防火墙规则,开放 5601 端口Kibana 一直显示“Kibana server is not ready yet”ES 未就绪或 Kibana 索引初始化慢等待 2-3 分钟,查看日志 journalctl -u kibana -f
-
Elasticsearch 8.14.3 完整部署方案 一、环境规划项目值运行用户appJDK 安装路径/data/app/jdk17ES 安装路径/data/app/es-serverES 数据目录/data/app/es-dataES 日志目录/data/app/es-logsES 配置目录/data/app/es-server/config证书目录/data/app/es-server/config/certs服务端口9200 (HTTPS)集群模式单节点二、完整部署命令2.1 创建 app 用户和基础目录# 创建 app 用户 sudo useradd app -m -s /bin/bash # 创建安装根目录并授权 sudo mkdir -p /data/app sudo chown app:app /data/app2.2 安装 JDK 17# 切换到 app 用户 sudo -i -u app # 进入安装目录 cd /data/app # 下载 JDK 17 wget https://mirrors.tuna.tsinghua.edu.cn/Adoptium/17/jdk/x64/linux/OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 解压 tar xzvf OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 重命名目录 mv jdk-17.0.19+10/ jdk17 # 清理安装包 rm -f OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 配置环境变量 echo 'export JAVA_HOME=/data/app/jdk17' >> /home/app/.bashrc echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /home/app/.bashrc source /home/app/.bashrc # 验证 JDK java -version2.3 安装 Elasticsearch# 仍在 app 用户下执行 cd /data/app # 下载 ES 8.14.3 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.3-linux-x86_64.tar.gz # 解压 tar xzvf elasticsearch-8.14.3-linux-x86_64.tar.gz # 重命名 mv elasticsearch-8.14.3 es-server # 清理安装包 rm -f elasticsearch-8.14.3-linux-x86_64.tar.gz # 创建数据和日志目录 mkdir -p /data/app/es-data mkdir -p /data/app/es-logs2.4 生成 SSL 证书(开启安全认证必需)# 仍在 app 用户下执行 cd /data/app/es-server # 生成 CA 证书(直接回车,不设密码) ./bin/elasticsearch-certutil ca # 生成节点证书(直接回车,不设密码) ./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 # 创建证书目录并移动证书 mkdir -p config/certs mv elastic-certificates.p12 config/certs/ mv elastic-stack-ca.p12 config/certs/ # 设置证书权限 chmod 644 config/certs/elastic-certificates.p122.5 配置 Elasticsearch# 备份原配置 cp /data/app/es-server/config/elasticsearch.yml /data/app/es-server/config/elasticsearch.yml.bak # 写入新配置 cat > /data/app/es-server/config/elasticsearch.yml << 'EOF' # ======================== 路径配置 ======================== path.data: /data/app/es-data path.logs: /data/app/es-logs # ======================== 集群配置 ======================== cluster.name: my-app-cluster node.name: node-1 network.host: 0.0.0.0 http.port: 9200 discovery.type: single-node # ======================== 安全认证配置 ======================== # 开启安全功能 xpack.security.enabled: true # 传输层 SSL 配置(节点间通信) xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12 # HTTP 层 SSL 配置(开启 HTTPS) xpack.security.http.ssl.enabled: false xpack.security.http.ssl.keystore.path: certs/elastic-certificates.p12 xpack.security.http.ssl.truststore.path: certs/elastic-certificates.p12 EOF2.6 配置 JVM 堆内存(可选,根据服务器内存调整)# 设置堆内存为 1G(根据实际情况调整) sed -i 's/^-Xms.*/-Xms1g/' /data/app/es-server/config/jvm.options sed -i 's/^-Xmx.*/-Xmx1g/' /data/app/es-server/config/jvm.options2.7 退出 app 用户,配置系统参数# 退出 app 用户 exit# 配置文件描述符限制 echo "app soft nofile 65535" | sudo tee -a /etc/security/limits.conf echo "app hard nofile 65535" | sudo tee -a /etc/security/limits.conf # 配置虚拟内存映射数 echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf sudo sysctl -p # 配置进程限制 echo "app soft nproc 4096" | sudo tee -a /etc/security/limits.conf echo "app hard nproc 4096" | sudo tee -a /etc/security/limits.conf2.8 创建 Systemd 服务文件sudo cat > /etc/systemd/system/elasticsearch.service << 'EOF' [Unit] Description=Elasticsearch Server Documentation=https://www.elastic.co After=network.target [Service] Type=simple User=app Group=app WorkingDirectory=/data/app/es-server Environment=JAVA_HOME=/data/app/jdk17 Environment=ES_PATH_CONF=/data/app/es-server/config ExecStart=/data/app/es-server/bin/elasticsearch ExecReload=/bin/kill -HUP $MAINPID KillMode=process LimitNOFILE=65535 LimitNPROC=4096 TimeoutStopSec=20 Restart=on-failure RestartSec=3 [Install] WantedBy=multi-user.target EOF2.9 设置目录权限并启动服务# 确保所有目录属主为 app sudo chown -R app:app /data/app # 重载 systemd sudo systemctl daemon-reload # 启动 Elasticsearch sudo systemctl start elasticsearch # 查看启动状态(等待 10-20 秒让服务完全启动) sleep 15 sudo systemctl status elasticsearch2.10 设置内置用户密码# 使用 auto 模式,自动生成随机密码 sudo -u app /data/app/es-server/bin/elasticsearch-setup-passwords auto --insecure执行后,系统会提示输入以下用户的密码(请务必牢记):用户说明密码建议elastic超级管理员强密码kibanaKibana 连接用强密码logstash_systemLogstash 监控随机密码beats_systemBeats 监控随机密码apm_systemAPM 监控随机密码remote_monitoring_user远程监控随机密码2.11 开启防火墙端口# 开放 9200 端口 sudo firewall-cmd --permanent --add-port=9200/tcp sudo firewall-cmd --reload2.12 设置开机自启sudo systemctl enable elasticsearch三、验证部署3.1 基础验证(HTTPS + 认证)# 使用 elastic 用户和密码访问(-k 忽略自签名证书验证) curl -u elastic:<你设置的密码> http://localhost:9200预期输出:{ "name" : "node-1", "cluster_name" : "my-app-cluster", "cluster_uuid" : "xxxxxxxxxxxxxxxxxxxxxx", "version" : { "number" : "8.14.3", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "d55f984299e0e88dee72ebd8255f7ff130859ad0", "build_date" : "2024-07-07T22:04:49.882652950Z", "build_snapshot" : false, "lucene_version" : "9.10.0", "minimum_wire_compatibility_version" : "7.17.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "You Know, for Search" }3.2 查看集群健康状态curl -k -u elastic:<密码> https://localhost:9200/_cluster/health?pretty3.3 查看节点信息curl -k -u elastic:<密码> https://localhost:9200/_cat/nodes?v3.4 远程访问验证(从其他机器执行)curl -k -u elastic:<密码> https://<服务器IP>:9200四、日常管理命令4.1 服务管理# 启动 sudo systemctl start elasticsearch # 停止 sudo systemctl stop elasticsearch # 重启 sudo systemctl restart elasticsearch # 查看状态 sudo systemctl status elasticsearch # 查看日志 sudo journalctl -u elasticsearch -f # 查看最近 100 行日志 sudo journalctl -u elasticsearch -n 1004.2 密码管理# 修改 elastic 用户密码 curl -k -u elastic:<旧密码> -X POST https://localhost:9200/_security/user/elastic/_password -H "Content-Type: application/json" -d '{"password":"<新密码>"}' # 创建新用户 curl -k -u elastic:<密码> -X POST https://localhost:9200/_security/user/monitor -H "Content-Type: application/json" -d '{"password":"<密码>","roles":["monitoring_user"]}'4.3 证书管理# 查看证书信息 openssl pkcs12 -info -in /data/app/es-server/config/certs/elastic-certificates.p12 -nokeys五、目录结构总览/data/app/ ├── jdk17/ # JDK 安装目录 │ ├── bin/ │ ├── lib/ │ └── ... ├── es-server/ # ES 安装目录 │ ├── bin/ # 可执行文件 │ ├── config/ │ │ ├── elasticsearch.yml # 主配置文件 │ │ ├── jvm.options # JVM 配置 │ │ └── certs/ # SSL 证书目录 │ │ ├── elastic-certificates.p12 │ │ └── elastic-stack-ca.p12 │ ├── lib/ # 依赖库 │ └── modules/ # 模块 ├── es-data/ # 数据目录 │ └── nodes/ # 节点数据 └── es-logs/ # 日志目录 └── elasticsearch.log # 主日志文件六、常见问题排查问题检查命令解决方案服务启动失败sudo systemctl status elasticsearch查看错误信息,检查配置文件语法证书错误sudo journalctl -u elasticsearch -n 50确认证书路径正确,权限为 644内存不足free -h调整 jvm.options 中的 -Xms 和 -Xmx端口被占用`sudo netstat -tlnpgrep 9200`修改 http.port 或停止占用进程认证失败检查密码是否正确使用 elasticsearch-setup-passwords 重置远程无法访问sudo firewall-cmd --list-all确认防火墙开放 9200 端口七、安全建议(生产环境)证书替换:自签名证书仅适用于测试环境,生产环境请使用 CA 签发的正式证书IP 绑定:network.host: 0.0.0.0 允许所有 IP 访问,建议改为具体内网 IP防火墙:仅允许可信 IP 访问 9200 端口定期改密:定期更换 elastic 等内置用户密码审计日志:开启审计功能 xpack.security.audit.enabled: true备份:定期备份 /data/app/es-data 目录和证书文件
-
三主三从 Redis 集群搭建与重启数据保障方案 一、环境规划与准备工作1.1 节点分配服务器 IP端口角色备注192.168.101.416379Master 1主节点192.168.101.416380Slave 1从节点(作为 .41 主节点的备用)192.168.101.426379Master 2主节点192.168.101.426380Slave 2从节点(作为 .42 主节点的备用)192.168.101.436379Master 3主节点192.168.101.436380Slave 3从节点(作为 .43 主节点的备用)注意:Redis 集群的总线通信端口会自动占用 port + 10000,即 16379 和 16380,也需要开放。1.2 软件环境要求操作系统:CentOS 7.xRedis 版本:5.0 或以上(推荐 6.2.x / 7.2.x,内置集群管理工具)网络互通:三台服务器之间需能互相 ping 通,所有端口可互相访问运行账号:app(如不存在则自动创建)二、每台服务器统一操作步骤(共三台)以下操作需在 192.168.101.41、192.168.101.42、192.168.101.43 三台服务器上各自执行一遍。2.1 创建 app 账号(如已存在可跳过)# 创建 app 用户组和用户(无登录 shell) groupadd app useradd -g app -m -s /sbin/nologin app # 设置目录权限(后续创建目录后需 chown)2.2 安装 Redis(三台机器)# 安装依赖 yum install -y gcc gcc-c++ make tcl # 下载源码 mkdir -p /data/app/src && cd /data/app/src wget https://download.redis.io/releases/redis-7.2.5.tar.gz tar -zxvf redis-7.2.5.tar.gz cd redis-7.2.5 # 编译并指定安装路径 make make install PREFIX=/data/app/redis # 将二进制路径加入 PATH(永久生效) echo 'export PATH=/data/app/redis/bin:$PATH' > /etc/profile.d/redis.sh source /etc/profile.d/redis.sh # 验证 /data/app/redis/bin/redis-server --version2.3 创建工作目录(每台机器)# 创建两个实例的工作目录 mkdir -p /data/redis-cluster/{6379,6380}/data mkdir -p /data/redis-cluster/{6379,6380}/conf mkdir -p /data/redis-cluster/{6379,6380}/logs # 创建集群节点配置文件目录 mkdir -p /var/run/redis-cluster # 修改目录所有者为 app chown -R app:app /data/redis-cluster chown -R app:app /var/run/redis-cluster2.4 生成主节点配置文件(端口 6379)编辑配置文件:vi /data/redis-cluster/6379/conf/redis.conf内容如下(以 192.168.101.41 为例,其他机器相同):# 基础配置 port 6379 bind 0.0.0.0 protected-mode no daemonize yes pidfile /var/run/redis-cluster/redis_6379.pid loglevel notice logfile /data/redis-cluster/6379/logs/redis.log # 工作目录和数据目录 dir /data/redis-cluster/6379/data # ========== 集群配置 ========== cluster-enabled yes cluster-config-file /data/redis-cluster/6379/conf/nodes-6379.conf cluster-node-timeout 5000 # ========== 数据持久化配置 ========== save 900 1 save 300 10 save 60 10000 rdbcompression yes dbfilename dump-6379.rdb appendonly yes appendfilename "appendonly-6379.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 访问密码 requirepass redispasswd # 主从同步认证密码 masterauth redispasswd2.5 生成从节点配置文件(端口 6380)vi /data/redis-cluster/6380/conf/redis.conf内容(将 6379 替换为 6380):port 6380 bind 0.0.0.0 protected-mode no daemonize yes pidfile /var/run/redis-cluster/redis_6380.pid loglevel notice logfile /data/redis-cluster/6380/logs/redis.log dir /data/redis-cluster/6380/data cluster-enabled yes cluster-config-file /data/redis-cluster/6380/conf/nodes-6380.conf cluster-node-timeout 5000 save 900 1 save 300 10 save 60 10000 rdbcompression yes dbfilename dump-6380.rdb appendonly yes appendfilename "appendonly-6380.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb requirepass redispasswd masterauth redispasswd2.6 配置防火墙(三台机器)# 开放 Redis 端口 firewall-cmd --permanent --add-port=6379/tcp firewall-cmd --permanent --add-port=6380/tcp # 开放集群总线端口 firewall-cmd --permanent --add-port=16379/tcp firewall-cmd --permanent --add-port=16380/tcp # 重载防火墙 firewall-cmd --reload # 验证 firewall-cmd --list-ports若生产环境不方便关闭 SELinux,可临时关闭:setenforce 0 sed -i 's/=enforcing/=disabled/g' /etc/selinux/config2.7 配置 systemd 开机自启(使用 app 账号):# 主节点 service cat > /etc/systemd/system/redis-6379.service << EOF [Unit] Description=Redis Server 6379 After=network.target [Service] Type=forking User=app Group=app ExecStart=/data/app/redis/bin/redis-server /data/redis-cluster/6379/conf/redis.conf ExecStop=/data/app/redis/bin/redis-cli -p 6379 -a 'redispasswd' shutdown Restart=always [Install] WantedBy=multi-user.target EOF # 从节点 service(端口改为 6380) cat > /etc/systemd/system/redis-6380.service << EOF [Unit] Description=Redis Server 6380 After=network.target [Service] Type=forking User=app Group=app ExecStart=/data/app/redis/bin/redis-server /data/redis-cluster/6380/conf/redis.conf ExecStop=/data/app/redis/bin/redis-cli -p 6380 -a 'redispasswd' shutdown Restart=always [Install] WantedBy=multi-user.target EOF # 启用 systemctl enable redis-6379 redis-6380 # 验证 ps aux | grep redis-server netstat -tuln | grep -E '6379|6380'三、创建 Redis 集群(只需在一台机器执行)当 三台服务器上的 6 个 Redis 实例全部启动后,在任意一台有 redis-cli 的机器上执行:redis-cli -a 'redispasswd' --cluster create \ 192.168.101.41:6379 \ 192.168.101.42:6379 \ 192.168.101.43:6379 \ 192.168.101.41:6380 \ 192.168.101.42:6380 \ 192.168.101.43:6380 \ --cluster-replicas 1系统会输出槽位分配,输入 yes 确认。看到以下输出即成功:text[OK] All 16384 slots covered.四、数据持久化配置详解4.1 双重持久化策略:AOF + RDBAOF 每秒同步:appendfsync everysec 最多丢失 1 秒数据。重启优先使用 AOF 恢复,数据更完整。AOF 重写:自动压缩,避免文件过大。4.2 验证持久化是否生效# 写入测试数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set test_key "test_value" # 检查持久化文件 ls -la /data/redis-cluster/6379/data/ # 应有 .rdb 和 .aof # 手动触发 AOF 重写 redis-cli -p 6379 -a 'redispasswd' BGREWRITEAOF五、重启与数据恢复验证方案5.1 重启单个 Redis 实例# 写入测试数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set user:1001 "test1001" # 停止实例(使用 app 账号) su - app -s /bin/bash -c "/data/app/redis/bin/redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown" # 重启 service redis-6379 restart # 验证数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' get user:1001 # 应返回 "test1001"5.2 模拟实例宕机(kill -9)# 写入 100 条数据 for i in {1..100}; do redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' --no-auth-warning set "test:key:$i" "value_$i" 2>/dev/null printf "Progress: %3d/100\r" $i done echo -e "\n✅ 写入完成" # 强制杀死进程(查找 app 用户的进程) systemctl stop redis-6379 redis-6380 # 重启 systemctl restart redis-6379 redis-6380 # 查询所有节点的key总数 echo "=== 分别查询每个节点 ===" for node in 192.168.101.41 192.168.101.42 192.168.101.43; do count=$(redis-cli -h $node -p 6379 -a 'redispasswd' --no-auth-warning keys "test:key:*" 2>/dev/null | wc -l) echo "$node:6379 - $count 条" done echo "" echo "总计:32 + 30 + 38 = 100 条 ✅"5.3 整机重启(模拟断电/维护)前提:已配置 systemd 开机自启。# 重启前写入标记 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set after_reboot_test "data_before_reboot" # 重启服务器 reboot # 重启后检查 systemctl status redis-6379 redis-6380 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' cluster info | grep cluster_state # 应为 ok redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' get after_reboot_test # 应返回原值5.4 主节点故障自动转移(高可用)# 写入 1000 条数据 for i in {1..1000}; do redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set hatest:$i "payload_$i" done # 关闭主节点 192.168.101.41:6379 redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown # 等待 15 秒,查看哪个从节点被提升 redis-cli -h 192.168.101.42 -p 6379 -a 'redispasswd' cluster nodes # 数据验证(连接新主节点) redis-cli -c -h 192.168.101.42 -p 6380 -a 'redispasswd' get hatest:500六、常用管理与监控命令6.1 集群状态检查redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' > cluster info > cluster nodes > cluster slots6.2 单节点管理# 停止节点(使用 app 账号) su -s /bin/bash -c "/data/app/redis/bin/redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown" app # 启动节点 su -s /bin/bash -c "/data/app/redis/bin/redis-server /data/redis-cluster/6379/conf/redis.conf" app # 查看日志 tail -f /data/redis-cluster/6379/logs/redis.log6.3 数据持久化验证ls -lh /data/redis-cluster/*/data/*.aof redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' BGSAVE redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' BGREWRITEAOF七、故障排查清单🔴 问题1:重启后节点未自动加入集群确保 cluster-config-file 目录可写且属主为 app检查网络:telnet 192.168.101.42 6379手动握手:redis-cli -h 192.168.101.42 -p 6379 -a 'redispasswd' CLUSTER MEET 192.168.101.41 6379🔴 问题2:数据恢复不完整检查 appendonly yes 是否配置修复 AOF:redis-check-aof --fix /path/to/appendonly.aof🔴 问题3:集群状态为 FAIL检查所有节点是否运行:ps aux | grep redis-server检查防火墙端口(包括 16379、16380)等待足够节点恢复后集群自动恢复🔴 问题4:权限不足导致启动失败检查目录权限:ls -la /data/redis-cluster(应为 app:app)检查 PID 目录权限:ls -la /var/run/redis-cluster使用 su 命令切换用户启动,或通过 systemd(已配置 User=app)启动八、Redis 集群版本升级方案(不停服滚动升级)8.1 升级前准备8.1.1 环境检查# 记录当前版本(三台机器) /data/app/redis/bin/redis-server --version # 记录集群状态 redis-cli -a 'redispasswd' --cluster check 192.168.101.41:6379 # 备份当前二进制及配置文件(三台机器) tar -czf /data/backup/redis-$(date +%Y%m%d)-bin.tar.gz /data/app/redis/ cp -r /data/redis-cluster /data/backup/redis-cluster-$(date +%Y%m%d)8.1.2 下载目标版本(以升级到 7.4.0 为例)cd /data/app/src wget https://download.redis.io/releases/redis-7.4.0.tar.gz tar -zxvf redis-7.4.0.tar.gz cd redis-7.4.0 # 编译 make8.2.1 升级从节点(以 192.168.101.41:6380 为例)# 1. 确认当前角色为从节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' role # 预期输出中 "role" 为 "slave" # 2. 停止旧版本实例 systemctl stop redis-6380 # 3. 替换二进制文件 mv /data/app/redis/bin /data/app/redis/bin.bak-$(date +%Y%m%d) mkdir -p /data/app/redis/bin cp /data/app/src/redis-7.4.0/src/{redis-server,redis-cli,redis-check-aof,redis-check-rdb,redis-sentinel} /data/app/redis/bin/ # 4. 验证新版本 /data/app/redis/bin/redis-server --version # 5. 启动新版本实例 systemctl start redis-6380 # 6. 验证同步状态 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' info replication | grep -E "role|master_link_status"8.2.2 执行主从切换(可选,如需升级主节点)# 手动触发故障转移,将从节点提升为主节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' cluster failover # 等待切换完成(约 5-10 秒) sleep 10 # 验证新主节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' role # 预期 "role" 变为 "master"8.2.3 升级原主节点(现在已降级为从节点)# 此时原主节点 6379 已变为从节点,重复 8.2.1 步骤升级 systemctl stop redis-6379 # ... 替换二进制 ... systemctl start redis-63798.2.4 依次升级其他机器机器升级顺序建议192.168.101.416380(从)→ 6379(原主)192.168.101.426380(从)→ 6379(原主)192.168.101.436380(从)→ 6379(原主)8.3 升级后验证8.3.1 集群健康检查# 检查集群状态 redis-cli -a 'redispasswd' --cluster check 192.168.101.41:6379 # 验证所有节点版本 for port in 6379 6380; do echo "=== 192.168.101.41:$port ===" redis-cli -h 192.168.101.41 -p $port -a 'redispasswd' info server | grep redis_version done8.3.2 数据完整性验证# 查询所有节点的key总数 echo "=== 分别查询每个节点 ===" for node in 192.168.101.41 192.168.101.42 192.168.101.43; do count=$(redis-cli -h $node -p 6379 -a 'redispasswd' --no-auth-warning keys "test:key:*" 2>/dev/null | wc -l) echo "$node:6379 - $count 条" done echo "" echo "总计:32 + 30 + 38 = 100 条 ✅"8.4 回滚方案(升级失败时)8.4.1 快速回滚(保留原二进制备份)# 停止问题实例 systemctl stop redis-6379 # 恢复旧版本二进制 rm -rf /data/app/redis/bin mv /data/app/redis/bin.bak-YYYYMMDD /data/app/redis/bin # 重启实例 systemctl start redis-63798.4.2 全量回滚(保留配置和数据)# 停止所有实例 systemctl stop redis-6379 redis-6380 # 恢复完整环境(从备份) rm -rf /data/app/redis tar -xzf /data/backup/redis-YYYYMMDD-bin.tar.gz -C / # 重启所有实例 systemctl start redis-6379 redis-63808.5 升级注意事项风险点应对措施客户端协议不兼容升级前确认业务使用的 Redis 命令未被废弃或变更RDB/AOF 加载失败升级前在测试环境验证,生产环境先升级单节点观察集群脑裂滚动升级期间避免同时重启多个主节点密码/ACL 变更新版本可能引入 ACL 规则变化,检查 requirepass 与 masterauth模块兼容性如使用了 Redis Module(如 RediSearch),需同步升级模块8.6 升级检查清单- [ ] 已记录当前版本与集群状态 - [ ] 已完成二进制及配置文件备份 - [ ] 已在测试环境完成版本兼容性验证 - [ ] 已通知业务方升级时间窗口 - [ ] 已准备回滚脚本与备份文件 - [ ] 滚动升级过程中每完成一个节点均验证同步状态 - [ ] 升级后完成集群健康检查与数据抽样验证 - [ ] 已更新运维文档中的版本信息
-
NFSv4服务搭建 1. 安装NFS服务端 yum install nfs-utils -y2. 创建并配置共享目录mkdir /data/nfs3.修改 /etc/exports 配置文件vim /etc/exports 在文件末尾添加一行,指定要共享的目录、允许的客户端网段和权限: /data/nfs 192.168.137.200(rw,sync,no_root_squash,fsid=0) \ 192.168.137.201(rw,sync,no_root_squash,fsid=0) \ 192.168.137.202(rw,sync,no_root_squash,fsid=0)参数说明fsid=0NFSv4 必需。标识根文件系统,NFSv4 通过此参数识别导出的根no_root_squash允许客户端 root 用户保留服务器端 root 权限rw读写权限sync同步写入,保证数据一致性4.重启服务# 重启 NFS 服务 systemctl restart nfs-server # 查看当前导出状态 exportfs -v5. 配置防火墙(NFSv4 只需开放 2049 端口)NFSv4 的优势:仅需 TCP 2049 端口!# firewalld(CentOS/RHEL) firewall-cmd --permanent --add-port=2049/tcp firewall-cmd --reload6. 客户端挂载与验证在客户端安装 NFS 支持:# CentOS/RHEL yum install nfs-utils -y挂载 NFSv4 共享:# 创建挂载点 mkdir /mnt/nfs_test # NFSv4 挂载(注意 vers=4 参数) mount -t nfs -o vers=4 192.168.137.3:/ /mnt/nfs_testdf -h验证[root@master ~]# df -h | grep nfs df: /mnt/nfs_client: Stale file handle 192.168.137.3:/ 119G 37G 76G 33%cd /mnt/nfs_test7.开机启动挂载sudo vim /etc/fstab # 在文件末尾添加以下内容: 192.168.137.3:/ /mnt/nfs_test nfs vers=4,noatime,hard,intr,_netdev 0 0 # 验证 umount /mnt/nfs_test mount -a
-
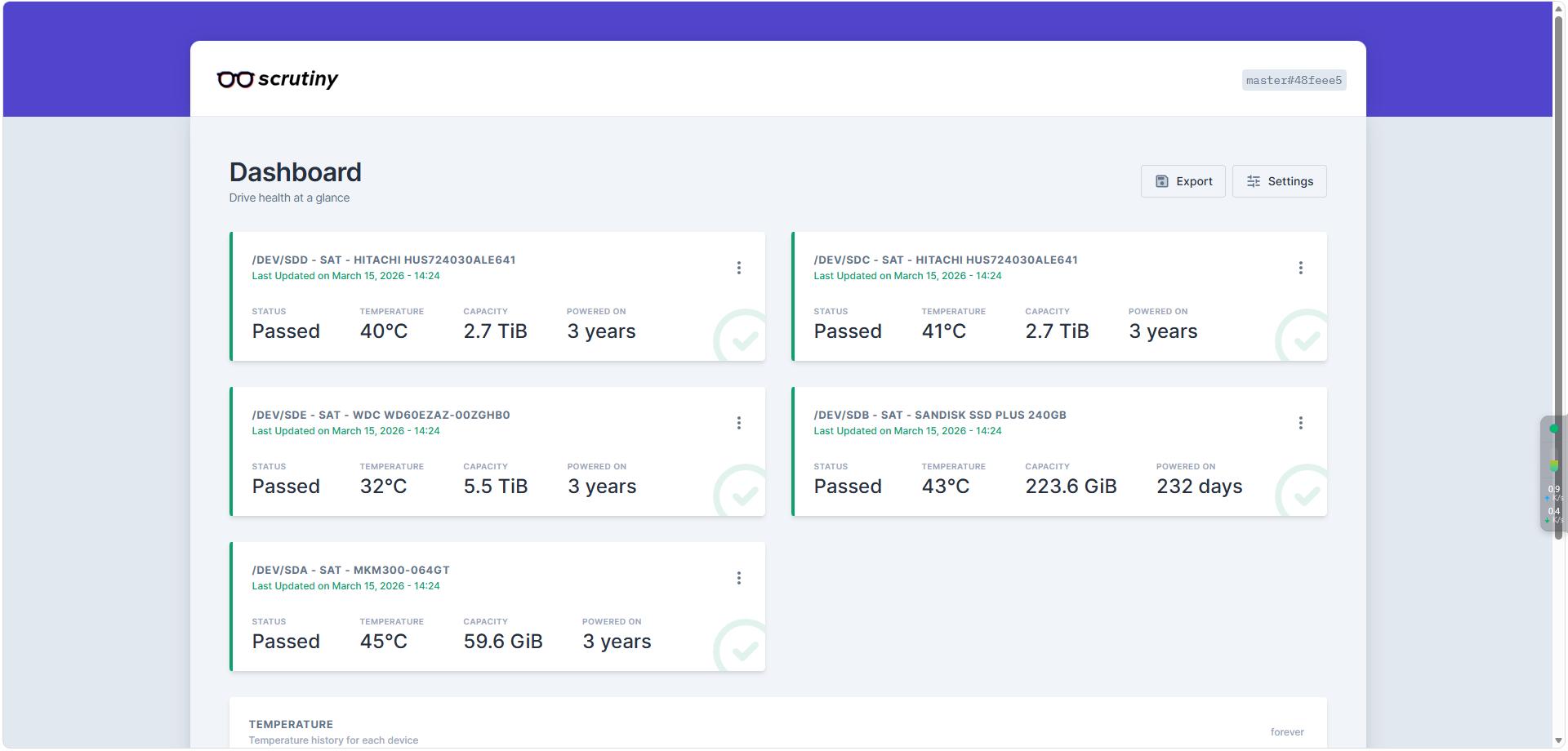
Scrutiny :一款基于web端的硬盘状态查看与监控工具 🔍 Scrutiny 是什么?Scrutiny 是一个专注于硬盘健康状况的开源监控工具。你可以把它想象成一个为硬盘准备的“健康监测中心”,它通过读取和分析硬盘的 S.M.A.R.T. 数据,为你提供一个清晰、美观的 Web 界面,让你能实时掌握每一块硬盘的状态、性能和潜在风险。它的核心亮点是:专业的数据分析:深入分析 S.M.A.R.T. 属性,不仅看当前值,还能追踪历史趋势,帮你判断硬盘是正常老化还是即将故障。智能预警系统:可以为不同的硬盘类型(如ATA、NVMe)设置告警阈值。一旦发现异常(比如温度过高、坏道增多),它能及时发出警报,让你有机会在数据丢失前采取行动。美观的可视化界面:它内置的仪表盘非常直观,可以一目了然地看到所有硬盘的健康状态概览,并支持深入查看每一块硬盘的详细报告和历史图表。灵活的部署方式:支持 Docker 一键部署,也支持在各种操作系统上手动安装,可以轻松实现多台主机的集中监控。🐳 Docker 部署 Scrutiny(一体化模式)你希望用 Docker 部署,这是最快、最省心的方式。官方推荐使用“一体化”(Omnibus)Docker 镜像,它把 Web 界面和后端数据收集都打包在了一个容器里,非常适合个人或家庭服务器使用。1. 准备工作在你的 Linux 服务器上,确保已经安装了 docker 和 docker-compose。2. 创建 docker-compose.yml 文件在你喜欢的目录下(例如 ~/scrutiny)创建一个名为 docker-compose.yml 的文件,并写入以下内容:version: '3.5' services: scrutiny: container_name: scrutiny image: ghcr.io/analogj/scrutiny:master-omnibus cap_add: - SYS_RAWIO # 获取机械硬盘的S.M.A.R.T 信息,默认即可 - SYS_ADMIN # 获取NVMe硬盘的S.M.A.R.T 信息,没有可以删除 ports: - "8183:8080" # webapp - "8184:8086" # influxDB admin(可以不映射) volumes: - /run/udev:/run/udev:ro - ./config:/opt/scrutiny/config - ./influxdb:/opt/scrutiny/influxdb devices: - "/dev/sda" - "/dev/sdb" - "/dev/sdc" - "/dev/sdd" - "/dev/sde"配置关键点说明:ports: 将容器的 8080 端口映射到宿主机的 8183 端口(你可以修改左侧端口避免冲突)。volumes: 挂载了主机的 udev 信息,这是容器正确识别你硬盘设备的关键。同时,也挂载了配置和数据目录到本地,方便备份和修改。devices: 这一步非常关键!你需要在这里列出所有想要监控的硬盘设备。把 /dev/sda、/dev/sdb 替换成你机器上实际的设备路径(可以通过 lsblk 命令查看)。cap_add: 添加 SYS_RAWIO 能力,赋予容器读取硬盘 SMART 数据所需的权限。environment: 设置环境变量,让这个容器同时运行 Web 服务和数据收集器(Collector)。3. 启动服务在 docker-compose.yml 文件所在的目录下,运行以下命令来启动服务:docker-compose up -d4. 访问 Web 界面服务启动后,在浏览器里打开 http://<你的Linux服务器IP>:8183(如果你修改了端口,请使用对应的端口)。稍等片刻(数据收集需要点时间),你就能看到一个漂亮的 Scrutiny 仪表盘了。界面加载后,你会看到所有被识别到的硬盘概览,绿色代表健康,黄色或红色则代表有需要关注的异常。点击任意一块硬盘,就能进入详情页,查看该硬盘完整的 S.M.A.R.T. 属性数据、温度变化曲线和历史故障记录。如果硬盘真的出了问题,这里就是第一手的“诊断报告”。5 如何实现 Scrutiny 汉化获取汉化文件你可以从以下网盘链接下载由用户“我是笨蛋小扁担”制作的汉化包:链接: https://pan.baidu.com/s/1djpIcCJB2XAClQw1Q8miEg (提取码: cnfb)在 Docker 部署中应用汉化准备目录:在与你 Scrutiny 容器映射的 config、data 目录同级的位置,创建一个名为 web 的新目录。放置文件:将下载的汉化压缩包内的所有文件解压到刚刚创建的 web 目录中。修改 Docker Compose 配置:在你原来的 docker-compose.yml 文件中,为 scrutiny 服务增加一个卷(volume)映射,将本地的 web 目录挂载到容器内的 /opt/scrutiny/web。添加的配置行如下:yamlversion: '3.5' services: scrutiny: container_name: scrutiny image: ghcr.io/analogj/scrutiny:master-omnibus cap_add: - SYS_RAWIO # 获取机械硬盘的S.M.A.R.T 信息,默认即可 - SYS_ADMIN # 获取NVMe硬盘的S.M.A.R.T 信息,没有可以删除 ports: - "8183:8080" # webapp - "8184:8086" # influxDB admin(可以不映射) volumes: - /run/udev:/run/udev:ro - ./config:/opt/scrutiny/config - ./influxdb:/opt/scrutiny/influxdb - ./web:/opt/scrutiny/web # 👈 新增这一行 devices: - "/dev/sda" - "/dev/sdb" - "/dev/sdc" - "/dev/sdd" - "/dev/sde"重建容器:保存文件后,在 docker-compose.yml 所在目录下执行 docker-compose down 和 docker-compose up -d 重新创建容器。参考资料Scrutiny 硬盘 S.M.A.R.T 可视化工具 - 踩坑、简体中文汉化 – 我是笨蛋小扁担
-
Copyparty:高颜值文件服务器(功能炸裂的“瑞士军刀”)(python -m强大模块) 零、Copyparty 深度介绍1. 核心哲学:极简到离谱的部署单文件即服务:整个服务器就是一个 Python 文件 (copyparty-sfx.py) 或 Windows 下的 .exe 文件,没有任何依赖,下载即用。开箱即用:无需配置数据库、无需安装复杂的依赖包,30秒内就能启动一个功能完整的文件服务器。兼容性怪兽:Python 版本:从 Python 2.7 到最新的 Python 3.x 都能运行。操作系统:Windows、Linux、macOS 是基本功,连 Windows 2000、Android(通过 Termux)、树莓派、甚至路由器都能跑。浏览器:从现代的 Chrome、Firefox,到古董级的 IE4、PSP 内置浏览器,都能访问它的 Web 界面。2. 核心功能:强得不像一个文件Copyparty 最让人着迷的是它那些超越普通文件分享的“黑科技”:功能类别具体特性体验与优势🚀 传输黑科技断点续传 (up2k 协议)上传大文件时,即使网络中断、浏览器崩溃甚至电脑重启,恢复后只需再次拖入同一个文件,它就能从中断处继续,而不是从头再来。 边传边下 (Race the Beam)上传者这边还在上传,接收方那边就可以开始下载了。上传进度即下载进度,非常适合团队紧急共享大文件。📺 媒体处理强悍的媒体能力自动为图片、视频和音频文件生成缩略图和波形图。内置的音乐播放器支持几乎所有常见格式(MP3、FLAC、AAC等),并支持实时转码,确保在任何浏览器上都能播放。🔍 搜索与去重全文搜索不仅能搜文件名,还能直接搜索文件内容里的关键词,比如在一堆 PDF 或 Word 文档里找一句话,这功能通常只有专业的文档管理系统才有。 智能去重当上传重复文件时,它不会傻傻地再存一份,而是指向已有的那份,帮你节省大量硬盘空间。🌐 多协议支持不止是 Web除了通过浏览器访问,它还原生支持 WebDAV、FTP(S)、TFTP、SMB。这意味着你可以直接把共享文件夹映射为电脑的本地磁盘来用。📦 一、安装# 使用pip安装 pip install copyparty # 如果需要增强功能(图片缩略图、音频元数据等),可以安装可选依赖 pip install copyparty[all] # 安装所有可选依赖 # 或者单独安装 pip install pillow # 图片缩略图支持 pip install mutagen # 音频元数据支持安装完成后,copyparty 命令就会添加到你的系统路径中。🚀 二、启动服务最简单启动python -m copyparty这会在当前目录启动服务,默认端口 3923,任何人都可以浏览、下载和上传文件。启动效果$ python -m copyparty Serving on http://0.0.0.0:3923 - Local: http://127.0.0.1:3923 - LAN: http://192.168.1.100:3923 - QR code: 扫描二维码用手机访问 Press Ctrl+C to stop常用启动参数场景命令说明局域网共享(读写)copyparty -v .:rw当前目录允许上传和下载自定义端口copyparty -p 8080使用8080端口启动指定共享目录copyparty -v D:\Share:rw共享指定目录只读模式copyparty -v .:r只能下载,不能上传带密码保护copyparty -a 用户名:密码 -v .:rw,用户名需要登录才能访问开启所有高级功能copyparty -e2dsa -e2ts启用搜索和音乐索引🌐 三、访问界面启动后,用浏览器访问:本机访问:http://localhost:3923局域网访问:http://你的IP:3923(如 http://192.168.1.100:3923)Web界面长什么样?🔧 四、实际使用示例示例1:快速共享当前目录(读写)# 在要共享的目录下执行 cd C:\Users\vin\Desktop\share python -m copyparty -v .:rw示例2:带密码的私人共享# 创建用户,设置权限 python -m copyparty -a alice:123456 -v ./private:rw,alice # 说明:-a 创建用户,-v 挂载目录,rw,alice 表示只有alice可读写示例3:音乐库服务器(带索引和播放)python -m copyparty -e2dsa -e2ts -v D:\Music:/music:r # 访问 http://localhost:3923/music 即可在线听歌示例4:临时接收文件(匿名上传,不暴露已有文件)python -m copyparty -v ./incoming:dropbox:w,G:c,fk=4 # - dropbox 特殊模式:匿名上传,不上传不能浏览 # - w 允许上传 # - G 上传后生成访问密钥 # - fk=4 密钥长度4位🎯 五、常用命令速查表命令作用copyparty默认启动(当前目录,端口3923)copyparty -p 8080指定端口copyparty -v D:\data:rw共享指定目录并允许读写copyparty -a user:pass添加用户认证copyparty --help查看所有参数copyparty --version查看版本
-
Windows netsh 端口转发完全指南[临时暴露内网服务解决方案 Windows netsh 端口转发完全指南[临时暴露内网服务解决方案netsh (Network Shell) 是 Windows 系统自带的强大网络配置命令行工具,其中的 interface portproxy 组件可以实现系统级的端口转发功能。📋 一、什么是 netsh 端口转发?端口转发是指将发往本机某个端口的网络流量,自动重定向到另一个目标地址和端口的过程。而 netsh 实现的是系统内核级别的端口转发,在 TCP/IP 协议栈层面完成流量转发。核心特点特性说明无需安装Windows 系统原生支持(Windows XP/Vista/7/8/10/11/Server 全系列)系统级转发在内核层面完成,对应用程序透明TCP 协议支持只支持 TCP 协议(不支持 UDP、ICMP 等)持久性规则永久生效(直到手动删除或系统重置)支持 IPv4 和 IPv6支持 v4tov4、v4tov6、v6tov4、v6tov6 四种组合🚀 二、核心命令详解2.1 添加端口转发规则基本语法:netsh interface portproxy add v4tov4 listenaddress=本地IP listenport=本地端口 connectaddress=目标IP connectport=目标端口参数说明:参数必填说明示例listenaddress否本机监听的IP地址192.168.1.100 或 0.0.0.0(所有接口)listenport是本机监听的端口8080connectaddress是目标服务器IP或域名10.0.0.5 或 example.comconnectport是目标服务器端口80常用示例:转发到内网服务器netsh interface portproxy add v4tov4 listenport=8080 connectaddress=192.168.1.100 connectport=80指定监听IP(多网卡环境)netsh interface portproxy add v4tov4 listenaddress=192.168.1.10 listenport=8080 connectaddress=10.0.0.5 connectport=3389IPv6 到 IPv4 转发netsh interface portproxy add v6tov4 listenport=8080 connectaddress=192.168.1.100 connectport=80转发到外部域名netsh interface portproxy add v4tov4 listenport=443 connectaddress=www.example.com connectport=4432.2 查看转发规则查看所有规则:netsh interface portproxy show all查看特定类型规则:netsh interface portproxy show v4tov4 netsh interface portproxy show v4tov6 netsh interface portproxy show v6tov4 netsh interface portproxy show v6tov6输出示例:侦听 ipv4: 连接到 ipv4: 地址 端口 地址 端口 --------------- ---------- --------------- ---------- 192.168.1.10 8080 10.0.0.5 3389 0.0.0.0 443 192.168.1.100 4432.3 删除转发规则删除单条规则:netsh interface portproxy delete v4tov4 listenaddress=192.168.1.10 listenport=8080批量删除:# 删除所有 v4tov4 规则 netsh interface portproxy reset🔧 三、完整实战案例场景1:远程桌面(RDP)转发将内网机器 A(192.168.1.100)的远程桌面(3389)通过本机(192.168.1.10)的 13389 端口暴露给外网。cmd# 1. 添加转发规则(管理员权限) netsh interface portproxy add v4tov4 listenport=13389 connectaddress=192.168.1.100 connectport=3389 # 2. 检查规则 netsh interface portproxy show all # 3. 开放防火墙端口 netsh advfirewall firewall add rule name="RDP Forward 13389" dir=in action=allow protocol=TCP localport=13389 # 4. 验证转发 # 从外网访问:你的公网IP:13389场景2:Web 服务临时共享将内网开发服务器(10.0.0.50:3000)的 Web 应用通过本机 8080 端口临时分享给团队。# 添加转发 netsh interface portproxy add v4tov4 listenport=8080 connectaddress=10.0.0.50 connectport=3000 # 开放防火墙 netsh advfirewall firewall add rule name="Web Share 8080" dir=in action=allow protocol=TCP localport=8080 # 通知同事访问:你的IP:8080场景3:多端口转发脚本创建一个批处理文件 setup_forward.bat:@echo off echo 正在设置端口转发规则... :: 转发 Web 服务 netsh interface portproxy add v4tov4 listenport=8080 connectaddress=192.168.1.101 connectport=80 :: 转发远程桌面 netsh interface portproxy add v4tov4 listenport=13389 connectaddress=192.168.1.102 connectport=3389 :: 转发数据库 netsh interface portproxy add v4tov4 listenport=3306 connectaddress=192.168.1.103 connectport=3306 :: 开放防火墙端口 for %%p in (8080 13389 3306) do ( netsh advfirewall firewall add rule name="Forward Port %%p" dir=in action=allow protocol=TCP localport=%%p ) echo 转发规则设置完成! netsh interface portproxy show all pause⚠️ 四、常见问题与解决方案问题1:转发不生效症状:规则添加成功,但访问失败排查步骤:# 1. 检查转发规则是否存在 netsh interface portproxy show all # 2. 检查防火墙是否开放端口 netsh advfirewall firewall show rule name="你的规则名" # 3. 检查端口监听状态 netstat -ano | findstr :8080 # 4. 检查 IP 路由是否启用 netsh interface ipv4 show interfaces # 需要确认"转发"状态为"已启用"问题2:只能本地访问,外部无法访问原因:listenaddress 设置了具体 IP 但防火墙或网络策略限制解决:# 修改为监听所有接口 netsh interface portproxy delete v4tov4 listenaddress=192.168.1.10 listenport=8080 netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=8080 connectaddress=10.0.0.5 connectport=80问题3:重启后规则消失原因:没有将规则保存为持久化配置解决:创建启动脚本# 创建 startup_forward.bat,放入启动文件夹 # shell:startup 打开启动文件夹 @echo off netsh interface portproxy add v4tov4 listenport=8080 connectaddress=192.168.1.100 connectport=80
-
Java try-with-resources 介绍 Java try-with-resources 介绍1. 什么是 try-with-resources?try-with-resources 是 Java 7 引入的一个特性,用于自动管理资源(如文件流、数据库连接、网络连接等)。它确保每个资源在语句结束时自动关闭,无需显式编写 finally 块。优点:代码简洁:减少样板代码安全可靠:自动确保资源关闭异常处理更完善:保留原始异常,关闭异常作为抑制异常可读性更好:清晰地看到资源声明和使用范围2. 基本语法try (ResourceType resource = new ResourceType()) { // 使用资源的代码 } catch (ExceptionType e) { // 异常处理 }3. 工作原理资源必须实现 AutoCloseable 或 Closeable 接口在 try 块结束后,资源会按照声明的相反顺序自动关闭资源关闭操作在 finally 块之前执行4. 支持多资源try (FileInputStream fis = new FileInputStream("input.txt"); FileOutputStream fos = new FileOutputStream("output.txt")) { byte[] buffer = new byte[1024]; int length; while ((length = fis.read(buffer)) > 0) { fos.write(buffer, 0, length); } } catch (IOException e) { e.printStackTrace(); }5. 异常处理机制try-with-resources 提供了更优雅的异常处理机制:public class ResourceExample { static class Resource1 implements AutoCloseable { public void use() throws Exception { throw new Exception("异常发生在使用资源时"); } @Override public void close() throws Exception { throw new Exception("异常发生在关闭资源时"); } } public static void main(String[] args) { try (Resource1 r1 = new Resource1()) { r1.use(); } catch (Exception e) { System.out.println("捕获的异常: " + e.getMessage()); Throwable[] suppressed = e.getSuppressed(); System.out.println("被抑制的异常数量: " + suppressed.length); } } }6. 实际应用示例文件操作示例import java.io.*; public class FileCopyExample { public static void copyFile(String source, String dest) { // 传统方式 /* FileInputStream fis = null; FileOutputStream fos = null; try { fis = new FileInputStream(source); fos = new FileOutputStream(dest); byte[] buffer = new byte[1024]; int length; while ((length = fis.read(buffer)) > 0) { fos.write(buffer, 0, length); } } catch (IOException e) { e.printStackTrace(); } finally { try { if (fis != null) fis.close(); if (fos != null) fos.close(); } catch (IOException e) { e.printStackTrace(); } } */ // try-with-resources 方式 try (FileInputStream fis = new FileInputStream(source); FileOutputStream fos = new FileOutputStream(dest)) { byte[] buffer = new byte[1024]; int length; while ((length = fis.read(buffer)) > 0) { fos.write(buffer, 0, length); } } catch (IOException e) { e.printStackTrace(); } } }数据库连接示例import java.sql.*; public class DatabaseExample { public static void queryDatabase() { String url = "jdbc:mysql://localhost:3306/mydb"; String user = "root"; String password = "password"; // 自动管理 Connection, Statement, ResultSet try (Connection conn = DriverManager.getConnection(url, user, password); Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM users")) { while (rs.next()) { System.out.println(rs.getString("username")); } } catch (SQLException e) { e.printStackTrace(); } } }8. Java 9 增强功能Java 9 允许在 try-with-resources 中使用 effectively final 的变量:public class Java9Example { public static void main(String[] args) throws Exception { // Java 9 之前 try (FileReader reader1 = new FileReader("file1.txt"); FileReader reader2 = new FileReader("file2.txt")) { // 使用资源 } // Java 9 及之后 FileReader reader1 = new FileReader("file1.txt"); FileReader reader2 = new FileReader("file2.txt"); // reader1 和 reader2 必须是 effectively final try (reader1; reader2) { // 使用资源 } } }9. 注意事项资源类必须实现 AutoCloseable 或 Closeable 接口资源在 try 块结束后自动关闭,无论是否发生异常多个资源按声明相反顺序关闭如果有多个异常,只有第一个异常被抛出,其他异常被抑制
-
Trilium Notes:个人笔记/个人知识库的开源神器 1.Trilium Notes 详细介绍Trilium Notes 是一款开源、免费、支持自部署的层级化知识管理软件。简单来说,它是一个专门为构建个人知识库(俗称"第二大脑")而设计的强大工具。1.1 核心定位与普通的笔记软件不同,Trilium 的设计理念是帮助你像管理文件系统一样管理知识。如果你觉得普通笔记本(如印象笔记)的笔记本-笔记两级结构不够用,或者觉得双链笔记(如 Obsidian)的网状结构过于自由而难以驾驭,Trilium 提供了一个介于两者之间的树状结构解决方案。1.2 核心特色1. 无限层级的树状结构这是 Trilium 最显著的特点。你可以像在电脑上创建文件夹一样,无限层级地组织笔记:📁 知识库 ├── 📁 编程学习 │ ├── 📁 前端 │ │ ├── 📄 React 笔记 │ │ └── 📄 Vue 笔记 │ └── 📁 后端 │ ├── 📄 Python │ └── 📄 数据库设计 ├── 📁 项目管理 │ ├── 📄 方法论 │ └── 📁 实际案例 └── 📁 生活记录 └── 📄 旅行日记💡 为什么重要:这种结构符合人类自然的分类思维,特别适合整理有明确归属关系的知识体系。2. 笔记克隆功能这是 Trilium 最强大的特性之一。一篇笔记可以同时出现在多个位置(类似于文件快捷方式或标签功能),但内容只有一份:示例:一篇关于"Python 装饰器"的笔记,既可以放在"编程语言/Python"目录下,又可以同时出现在"设计模式/Python实现"目录下更新同步:修改其中任何一个位置的笔记内容,所有克隆都会同步更新适用场景:一篇笔记涉及多个主题,或者需要多维度分类时非常实用3. 丰富的笔记类型Trilium 不只支持普通的富文本笔记,还内置了多种特殊类型:笔记类型用途文本笔记标准富文本编辑,支持表格、图片、待办清单等Markdown纯文本 Markdown 编辑代码笔记语法高亮,可直接运行部分代码画板笔记内置 Excalidraw,可以手绘流程图、思维导图关系图可视化展示笔记之间的连接关系书签保存网页链接文件直接存储 PDF、图片等文件4. 强大的搜索与脚本能力全文搜索:支持高级搜索语法(如 note.title:"Python" AND ~30d 表示搜索近30天内修改的标题含Python的笔记)脚本自动化:支持 JavaScript 脚本,可以:批量修改笔记属性自动生成日报/周报从外部 API 拉取数据生成笔记自定义导出格式5. 多端同步与加密同步机制:通过自部署的服务器,实现桌面端、移动端(Web 端)之间的笔记同步端到端加密:笔记在传输和存储时都可以加密,保护隐私版本控制:自动保存笔记历史版本,可以随时回溯2.Docker Compose 部署 (推荐)2.1 创建部署目录在你的服务器或NAS上创建一个目录,例如 trilium-cn,并进入该目录。2.2 创建 docker-compose.yml 文件在该目录下新建一个名为 docker-compose.yml 的文件,并将以下内容复制进去:version: '3' services: trilium-cn: image: nriver/trilium-cn:latest container_name: trilium-cn restart: always ports: - "8080:8080" # 左边端口可自定义,如 8070:8080 volumes: # 将当前目录下的 data 文件夹挂载到容器内,用于持久化存储你的笔记 - ./trilium-data:/root/trilium-data environment: # 告诉容器数据存储在哪里,必须与 volumes 中的容器内路径一致 - TRILIUM_DATA_DIR=/root/trilium-data2.3启动容器在 docker-compose.yml 所在目录下,打开终端并运行命令 docker-compose up -d 即可在后台启动服务。3.访问测试
-
解决 npm 全局安装后找不到命令的问题 解决 npm 全局安装后找不到命令的问题0.示例使用 npm 全局安装包后命令找不到时,通常是由于环境变量配置问题或 npm 配置路径不一致导致的。npm install -g asar asar -V # 提示找不到命令1.检查 npm 配置路径首先,检查 npm 的全局安装路径和缓存路径是否正确。npm config get prefix npm config get cache如果路径不正确,可以通过以下命令设置正确的路径:npm config set prefix "C:\Users\Administrator\AppData\Roaming\npm" npm config set cache "C:\Users\Administrator\AppData\Local\npm-cache"2.添加环境变量确保将 npm 的全局安装路径添加到系统环境变量中(prefix对应的值)。打开系统属性,选择“高级系统设置”。点击“环境变量”按钮。在“系统变量”中找到 Path,并编辑它。添加 npm 全局安装路径,例如 C:\Users\Administrator\AppData\Roaming\npm。3.验证asar -V v3.2.0
-
nginx编译安装 1.依赖安装yum install -y gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel2.下载安装包并解压官网地址:https://nginx.orgwget https://nginx.org/download/nginx-1.27.2.tar.gztar -zxvf nginx-1.27.2.tar.gz cd nginx-1.27.23.开始编译安装./configure --with-http_ssl_module make && make install安装完成后的安装目录在/usr/local/nginx4.配置开机启动项cd /usr/local/ngin useradd nginx vim nginx.service[Unit] Description=nginx After=network.target [Service] User=nginx Group=nginx Type=forking ExecStart=/usr/local/nginx/sbin/nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.targetln -s /usr/local/nginx/nginx.service /usr/lib/systemd/system/nginx.service systemctl daemon-reload service nginx status service nginx restart service nginx status5.配置启动bin的软连接ln -s /usr/local/nginx/sbin/nginx /usr/bin/nginx# nginx -V nginx version: nginx/1.27.2 built by gcc 7.3.0 (GCC) built with OpenSSL 1.1.1f 31 Mar 2020 TLS SNI support enabled configure arguments: --with-http_ssl_module [root@oa-app-7 nginx]#参考资料nginx源码编译安装(详解) - penngke - 博客园 (cnblogs.com)nginx: downloadnginx配置https后报错nginx: [emerg] https protocol requires SSL support in XXX.conf详细解决方法-CSDN博客nginx 普通用户使用80端口启动nginx nginx: [emerg] bind() to 0.0.0.0:80 failed (13: Permission denied)_nginx 端口80普通用户-CSDN博客
-
CenterOS ELK环境搭建 1.准备工作1.1 安装jdk8(可以省略)下载安装包wget https://mirrors.tuna.tsinghua.edu.cn/Adoptium/8/jdk/x64/linux/OpenJDK8U-jdk_x64_linux_hotspot_8u422b05.tar.gz解压并移动到目标路径tar xzvf OpenJDK8U-jdk_x64_linux_hotspot_8u422b05.tar.gz mv jdk8u422-b05 jdk8 mv jdk8 /software/配置环境变量 vim ~/.bashrcexport JAVA_HOME=/software/jdk8 export PATH=$PATH:$JAVA_HOME/bin source ~/.bashrc验证[root@localhost ~]# java -version2.Elasticsearch 部署2.1 源码部署[单节点]下载源码包并解压下载地址:https://www.elastic.co/cn/downloads/elasticsearchhttps://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.3-linux-x86_64.tar.gz tar xzvf elasticsearch-8.14.3-linux-x86_64.tar.gz mkdir /data/elasticsearch mv elasticsearch-8.14.3 /data/elasticsearch/ cd /data/elasticsearch/elasticsearch-8.14.3/创建es启动用户# 创建用户 useradd es # 目录授权 chown es:es -R /data/elasticsearch/elasticsearch-8.14.3/ES 不能用root启动,否则会出现报错cd bin [root@localhost bin]# ./elasticsearch warning: ignoring JAVA_HOME=/software/jdk8; using bundled JDK Jul 28, 2024 12:07:26 AM sun.util.locale.provider.LocaleProviderAdapter <clinit> WARNING: COMPAT locale provider will be removed in a future release [2024-07-28T00:07:26,940][INFO ][o.e.n.NativeAccess ] [localhost.localdomain] Using [jdk] native provider and native methods for [Linux] [2024-07-28T00:07:26,953][ERROR][o.e.b.Elasticsearch ] [localhost.localdomain] fatal exception while booting Elasticsearchjava.lang.RuntimeException: can not run elasticsearch as root at org.elasticsearch.server@8.14.3/org.elasticsearch.bootstrap.Elasticsearch.initializeNatives(Elasticsearch.java:286) at org.elasticsearch.server@8.14.3/org.elasticsearch.bootstrap.Elasticsearch.initPhase2(Elasticsearch.java:169) at org.elasticsearch.server@8.14.3/org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:74) See logs for more details. ERROR: Elasticsearch did not exit normally - check the logs at /software/elasticsearch-8.14.3/logs/elasticsearch.log ERROR: Elasticsearch died while starting up, with exit code 1系统参数配置#1、设置系统参数 *表示所有用户生效 echo '* soft nofile 100001' >> /etc/security/limits.conf echo '* hard nofile 100002' >> /etc/security/limits.conf echo '* soft nproc 100001' >> /etc/security/limits.conf echo '* hard nproc 100002' >> /etc/security/limits.conf #2、设置内存设置 echo 'vm.max_map_count=655360' >> /etc/sysctl.conf #3、加载sysctl配置,执行命令 sysctl -p# 重启生效 reboot不配置系统参数启动会出现如下报错[2024-07-28T02:28:31,731][ERROR][o.e.b.Elasticsearch ] [es-node1] node validation exception [2] bootstrap checks failed. You must address the points described in the following [2] lines before starting Elasticsearch. For more information see [https://www.elastic.co/guide/en/elasticsearch/reference/8.14/bootstrap-checks.html] bootstrap check failure [1] of [2]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]; for more information see [https://www.elastic.co/guide/en/elasticsearch/reference/8.14/_file_descriptor_check.html] bootstrap check failure [2] of [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]; for more information see [https://www.elastic.co/guide/en/elasticsearch/reference/8.14/_maximum_map_count_check.html] ERROR: Elasticsearch did not exit normally - check the logs at /software/elasticsearch-8.14.3/logs/es.log [2024-07-28T02:28:31,735][INFO ][o.e.n.Node ] [es-node1] stopping ... [2024-07-28T02:28:31,749][INFO ][o.e.n.Node ] [es-node1] stopped [2024-07-28T02:28:31,750][INFO ][o.e.n.Node ] [es-node1] closing ... [2024-07-28T02:28:31,756][INFO ][o.e.n.Node ] [es-node1] closed [2024-07-28T02:28:31,758][INFO ][o.e.x.m.p.NativeController] [es-node1] Native controller process has stopped - no new native processes can be started ERROR: Elasticsearch died while starting up, with exit code 78修改配置文件vim config/elasticsearch.yml修改数据和日志目录(这里可以不用修改,如果不修改,默认放在elasticsearch根目录下)# 数据目录位置 path.data: /data/elasticsearch/data # 日志目录位置 path.logs: /data/elasticsearch/logs 修改绑定的ip允许远程访问#默认只允许本机访问,修改为0.0.0.0后则可以远程访问 # 绑定到0.0.0.0,允许任何ip来访问 network.host: 0.0.0.0 初始化节点名称cluster.name: es node.name: es-node1 cluster.initial_master_nodes: ["es-node1"]开启xpack 认证功能# cd 到 elasticsearch文件夹下 # 创建一个证书颁发机构 #会要求输入密码直接回车即可 #执行完成之后会在bin目录的同级目录生成一个文件elastic-stack-ca.p12 ./bin/elasticsearch-certutil ca # 为节点生成证书和私钥 #会要求输入密码直接回车即可 #执行完成之后会在bin目录的同级目录生成一个文件elastic-certificates.p12 ./bin/elasticsearch-certutil cert --ca ./elastic-stack-ca.p12 # 移动到config/certs目录下 可以手动创建 mkdir config/certs mv *.p12 config/certs/xpack.security.enabled: true xpack.security.enrollment.enabled: true http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type xpack.security.http.ssl: enabled: false verification_mode: certificate keystore.path: certs/elastic-certificates.p12 truststore.path: certs/elastic-certificates.p12 xpack.security.transport.ssl: enabled: true verification_mode: certificate keystore.path: certs/elastic-certificates.p12 truststore.path: certs/elastic-certificates.p12xpack 认证功能认证未开启会出现问题访问http://IP:9200/测试,页面无法加载,后台日志出现报错[2024-07-28T02:51:56,319][WARN ][o.e.h.n.Netty4HttpServerTransport] [es-node1] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/192.168.124.16:9200, remoteAddress=/192.168.124.16:40472} [2024-07-28T02:52:05,731][WARN ][o.e.x.c.s.t.n.SecurityNetty4Transport] [es-node1] received plaintext traffic on an encrypted channel, closing connection Netty4TcpChannel{localAddress=/192.168.124.16:9300, remoteAddress=/192.168.124.16:57560, profile=default} ^[[B^[[B^[[B[2024-07-28T03:03:25,366][WARN ][o.e.h.n.Netty4HttpServerTransport] [es-node1] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/192.168.124.16:9200, remoteAddress=/192.168.124.16:40476}是因为ES8默认开启了 SSL 认证,解决办法1、使用 https 发送请求,需要完成https证书配置等,暂时跳过2、修改elasticsearch.yml配置文件将xpack.security.enabled设置为false[生产环境下不建议这么使用]cd /software/elasticsearch-8.14.3/conf/ vim elasticsearch.yml xpack.security.enabled: false再次重启访问访问即可正常切换用户启动测试# 目录授权 chown es:es -R /data/elasticsearch # 切换用户 su es cd /data/elasticsearch/elasticsearch-8.14.3/bin/ ./elasticsearch # -d 后台启动━ ✅ Elasticsearch security features have been automatically configured! ✅ Authentication is enabled and cluster connections are encrypted. ℹ️ Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`): ys42G-eSmGL*jqZF7iqL ❌ Unable to generate an enrollment token for Kibana instances, try invoking `bin/elasticsearch-create-enrollment-token -s kibana`. ❌ An enrollment token to enroll new nodes wasn't generated. To add nodes and enroll them into this cluster: • On this node: ⁃ Create an enrollment token with `bin/elasticsearch-create-enrollment-token -s node`. ⁃ Restart Elasticsearch. • On other nodes: ⁃ Start Elasticsearch with `bin/elasticsearch --enrollment-token <token>`, using the enrollment token that you generated.访问测试: http://172.21.58.47:9200/ 需要输入用户名和密码用户密码重置# 或者之前设置过忘记了,可以重新设置密码 ./bin/elasticsearch-reset-password -u elastic ./bin/elasticsearch-reset-password -u kibana3.Kibana部署3.1 源码部署下载源码包并解压下载地址:Download Kibana Free | Get Started Now | Elasticwget https://artifacts.elastic.co/downloads/kibana/kibana-8.14.3-linux-x86_64.tar.gz tar xzvf kibana-8.14.3-linux-x86_64.tar.gz mv kibana-8.14.3 /data/elasticsearch cd /data/elasticsearch/kibana-8.14.3/修改配置文件vim config/kibana.yml# 修改绑定的ip允许远程访问 server.host: "0.0.0.0" # Kibana汉化页面 i18n.locale: "zh-CN" # 配置 elasticsearch 登录用户 elasticsearch.username: "kibana" elasticsearch.password: "上面设置的密码"启动测试# 目录授权给es用户 chown es:es -R /data/elasticsearch/kibana-8.14.3/ # 通过es用户启动 su es cd /data/elasticsearch/kibana-8.14.3/ ./bin/kibana # 后台启动 nohup ./bin/kibana > /dev/null 2>&1 &访问测试http:// 172.21.58.47:5601/4.Logstash 部署4.1 源码部署下载源码包并解压下载地址:Download Logstash Free | Get Started Now | Elasticwget https://artifacts.elastic.co/downloads/logstash/logstash-8.14.3-linux-x86_64.tar.gz tar xzvf logstash-8.14.3-linux-x86_64.tar.gz mv logstash-8.14.3 /software/ cd /software/logstash-8.14.3参考资料Index of /Adoptium/8/jdk/x64/linux/ | 清华大学开源软件镜像站 | Tsinghua Open Source MirrorELK介绍、Elasticsearch单节点部署、Elasticsearch集群部署_systemctl 管理elsearch-CSDN博客[ES错误:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]-CSDN博客](https://blog.csdn.net/weixin_43950568/article/details/122459088)[vm.max_map_count [65530] is too low 问题解决(Windows 10、WSL 2、Docker Desktop)_容器化vm.max map count [65530] istoo low-CSDN博客](https://blog.csdn.net/Pointer_v/article/details/112395425)ELasticsearch基本使用——基础篇_elasticsearch使用-CSDN博客Elasticsearch 8.0报错:received plaintext http traffic on an https channel, closing connection_closing connection -1-CSDN博客ES 8.x 系列教程:ES 8.0 服务安装(可能是最详细的ES 8教程)-阿里云开发者社区 (aliyun.com)【ES三周年】吊打ElasticSearch和Kibana(入门保姆级教程-2)-腾讯云开发者社区-腾讯云 (tencent.com)SpringBoot整合Logstash,实现日志统计_springboot 整合 logstash-CSDN博客Logstash 安装与部署(无坑版)-腾讯云开发者社区-腾讯云 (tencent.com)
-
Kubernetes(k8s)环境搭建 Kubernetes(k8s)环境搭建1.机器准备实验环境用了3台centerOS的虚拟机节点类型IP主机名操作系统mater192.168.1.16node1centerOSslaver1192.168.1.17node2centerOSslaver2172.24.87.84node3centerOS2.准备工作三台机器都需要进行处理2.1关闭防火墙和禁用 selinux## 禁用selinux,关闭内核安全机制 sestatus setenforce 0 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config ## 关闭防火墙,并禁止自启动 systemctl stop firewalld systemctl disable firewalld systemctl status firewalld2.2 关闭交换分区# 临时关闭 swapoff -a # 永久关闭 sed -i '/swap/s/^/#/' /etc/fstab2.3 服务器内核优化# 这种镜像信息可以通过配置内核参数的方式来消除 cat >> /etc/sysctl.conf << EOF # 启用ipv6桥接转发 net.bridge.bridge-nf-call-ip6tables = 1 # 启用ipv4桥接转发 net.bridge.bridge-nf-call-iptables = 1 # 开启路由转发功能 net.ipv4.ip_forward = 1 # 禁用swap分区 vm.swappiness = 0 EOF ## # 加载 overlay 内核模块 modprobe overlay # 往内核中加载 br_netfilter模块 modprobe br_netfilter # 加载文件内容 sysctl -pmodprobe 动态加载的模块重启会失效,因此需要执行如下配置cat << EOF >>/etc/sysconfig/modules/iptables.modules modprobe -- overlay modprobe -- br_netfilter EOF chmod 755 /etc/sysconfig/modules/iptables.modules #设置权限 sh /etc/sysconfig/modules/iptables.modules #临时生效2.4 各节点时间同步## 安装同步时间插件 yum -y install ntpdate ## 同步阿里云的时间 ntpdate ntp.aliyun.com3. Containerd 环境部署3.1 安装Containerd(手动)# 安装containerd wget https://github.com/containerd/containerd/releases/download/v1.7.27/containerd-1.7.27-linux-amd64.tar.gz tar xzvf containerd-1.7.27-linux-amd64.tar.gz cp -f bin/* /usr/local/bin/ # 安装runc wget https://github.com/opencontainers/runc/releases/download/v1.2.6/runc.amd64 chmod +x runc.amd64 mv runc.amd64 /usr/local/bin/runc # 安装cni plugins wget https://github.com/containernetworking/plugins/releases/download/v1.6.2/cni-plugins-linux-amd64-v1.6.2.tgz rm -fr /opt/cni/bin mkdir -p /opt/cni/bin tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.6.2.tgz # 安装 nerdctl wget https://github.com/containerd/nerdctl/releases/download/v2.0.3/nerdctl-2.0.3-linux-amd64.tar.gz tar Cxzvf /usr/local/bin nerdctl-2.0.3-linux-amd64.tar.gz # 安装crictl wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.32.0/crictl-v1.32.0-linux-amd64.tar.gz tar Cxzvf /usr/local/bin crictl-v1.32.0-linux-amd64.tar.gz # 配置 crictl 配置文件 cat << EOF >> /etc/crictl.yaml runtime-endpoint: unix:///var/run/containerd/containerd.sock image-endpoint: unix:///var/run/containerd/containerd.sock timeout: 10 debug: false EOF# 初始化containerd的配置文件 mkdir -p /etc/containerd/ containerd config default > /etc/containerd/config.toml # 修改 /etc/containerd/config.toml 文件 # 配置镜像加速 很关键 要不后面会报错 sed -i 's#registry.k8s.io/pause:3.8#registry.aliyuncs.com/google_containers/pause:3.8#g' /etc/containerd/config.toml# 配置containerd到systemctl管理 cat <<EOF > /lib/systemd/system/containerd.service # Copyright The containerd Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. [Unit] Description=containerd container runtime Documentation=https://containerd.io After=network.target local-fs.target [Service] ExecStartPre=-/sbin/modprobe overlay ExecStart=/usr/local/bin/containerd Type=notify Delegate=yes KillMode=process Restart=always RestartSec=5 # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNPROC=infinity LimitCORE=infinity LimitNOFILE=infinity # Comment TasksMax if your systemd version does not supports it. # Only systemd 226 and above support this version. TasksMax=infinity OOMScoreAdjust=-999 [Install] WantedBy=multi-user.target EOF# 启动containerd服务 systemctl daemon-reload systemctl restart containerd systemctl enable containerd3.2 一键安装脚本#!/bin/bash set -e ContainerdVersion=$1 ContainerdVersion=${ContainerdVersion:-1.6.6} RuncVersion=$2 RuncVersion=${RuncVersion:-1.1.3} CniVersion=$3 CniVersion=${CniVersion:-1.1.1} NerdctlVersion=$4 NerdctlVersion=${NerdctlVersion:-0.21.0} CrictlVersion=$5 CrictlVersion=${CrictlVersion:-1.24.2} echo "--------------install containerd--------------" wget https://github.com/containerd/containerd/releases/download/v${ContainerdVersion}/containerd-${ContainerdVersion}-linux-amd64.tar.gz tar Cxzvf /usr/local containerd-${ContainerdVersion}-linux-amd64.tar.gz echo "--------------install containerd service--------------" wget https://raw.githubusercontent.com/containerd/containerd/681aaf68b7dcbe08a51c3372cbb8f813fb4466e0/containerd.service mv containerd.service /lib/systemd/system/ mkdir -p /etc/containerd/ containerd config default > /etc/containerd/config.toml echo "--------------install runc--------------" wget https://github.com/opencontainers/runc/releases/download/v${RuncVersion}/runc.amd64 chmod +x runc.amd64 mv runc.amd64 /usr/local/bin/runc echo "--------------install cni plugins--------------" wget https://github.com/containernetworking/plugins/releases/download/v${CniVersion}/cni-plugins-linux-amd64-v${CniVersion}.tgz rm -fr /opt/cni/bin mkdir -p /opt/cni/bin tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v${CniVersion}.tgz echo "--------------install nerdctl--------------" wget https://github.com/containerd/nerdctl/releases/download/v${NerdctlVersion}/nerdctl-${NerdctlVersion}-linux-amd64.tar.gz tar Cxzvf /usr/local/bin nerdctl-${NerdctlVersion}-linux-amd64.tar.gz echo "--------------install crictl--------------" wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v${CrictlVersion}/crictl-v${CrictlVersion}-linux-amd64.tar.gz tar Cxzvf /usr/local/bin crictl-v${CrictlVersion}-linux-amd64.tar.gz # 启动containerd服务 systemctl daemon-reload systemctl restart contaienrd4.部署Kubernetes集群4.1 配置 kubernetes 的 yum 源(三台机器均需执行)cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF4.2 安装Kubernetes基础服务及工具(三台机器均需执行)kubeadm:用来初始化集群的指令。kubelet:在集群中的每个节点上用来启动 Pod 和容器等。kubectl:用来与集群通信的命令行工具。## 安装所需 Kubernetes yum install -y kubelet-1.28.2 kubeadm-1.28.2 kubectl-1.28.2systemctl start kubelet systemctl enable kubelet systemctl status kubelet 4.3 master节点生成初始化配置文件(master节点执行)Kubeadm提供了很多配置项,kubeadm配置在kubernetes集群中是存储在ConfigMap中的,也可将这些配置写入配置文件,方便管理复杂的配置项。kubeadm配置内容是通过kubeadm config命令写入配置文件的kubeadm config view:查看当前集群中的配置值kubeadm config print join-defaults:输出kubeadm join默认参数文件的内容kubeadm config images list:列出所需的镜像列表kubeadm config images pull:拉取镜像到本地kubeadm config upload from-flags:由配置参数生成ConfigMap# 生成初始化配置文件,并输出到当前目录 kubeadm config print init-defaults > init-config.yaml # 执行上面的命令可能会出现类似这个提示,不用管,接着往下执行即可:W0615 08:50:40.154637 10202 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io] # 编辑配置文件,以下有需要修改部分 $ vi init-config.yamlapiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.1.16 # 修改此处为你 master 节点 IP 地址, bindPort: 6443 # 默认端口号即可 nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: node taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers # 修改默认地址为国内地址,国外的地址无法访问 kind: ClusterConfiguration kubernetesVersion: 1.28.0 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 # 默认网段即可,service资源的网段,集群内部的网络 scheduler: {} 4.4 master节点拉取所需镜像(master节点执行)# 根据指定 init-config.yaml 文件,查看初始化需要的镜像 kubeadm config images list --config=init-config.yaml ## 拉取镜像 kubeadm config images pull --config=init-config.yaml ## 查看拉取的镜像 crictl images4.5 master节点初始化和网络配置(master节点执行)( kubeadm init 初始化配置参数如下,仅做了解即可)--apiserver-advertise-address(string) API服务器所公布的其正在监听的IP地址--apiserver-bind-port(int32) API服务器绑定的端口,默认6443--apiserver-cert-extra-sans(stringSlice) 用于API Server服务证书的可选附加主题备用名称,可以是IP和DNS名称--certificate-key(string) 用于加密kubeadm-certs Secret中的控制平面证书的密钥--control-plane-endpoint(string) 为控制平面指定一个稳定的IP地址或者DNS名称--image-repository(string) 选择用于拉取控制平面镜像的容器仓库,默认k8s.gcr.io--kubernetes-version(string) 为控制平面选择一个特定的k8s版本,默认stable-1--cri-socket(string) 指定要连接的CRI套接字的路径--node-name(string) 指定节点的名称--pod-network-cidr(string) 知名Pod网络可以使用的IP地址段,如果设置了这个参数,控制平面将会为每一个节点自动分配CIDRS--service-cidr(string) 为服务的虚拟IP另外指定IP地址段,默认 10.96.0.0/12--service-dns-domain(string) 为服务另外指定域名,默认 cluster.local--token(string) 用于建立控制平面节点和工作节点之间的双向通信--token-ttl(duration) 令牌被自动删除之前的持续时间,设置为0则永不过期--upload-certs 将控制平面证书上传到kubeadm-certs Secret(kubeadm通过初始化安装是不包括网络插件的,也就是说初始化之后不具备相关网络功能的,比如k8s-master节点上查看信息都是"Not Ready"状态、Pod的CoreDNS无法提供服务等 4.5.0 若初始化失败执行: systemctl stop kubelet kubeadm resetrm -rf $HOME/.kube rm -rf /etc/kubernetes/ rm -rf /var/lib/etcd/4.5.1 使用 kubeadm 在 master 节点初始化k8s(master节点执行)kubeadm 安装 k8s,这个方式安装的集群会把所有组件安装好,也就免去了需要手动安装 etcd 组件的操作## 初始化 k8s ## 1)修改 kubernetes-version 为你自己的版本号; ## 2)修改 apiserver-advertise-address 为 master 节点的 IP kubeadm init --kubernetes-version=1.28.0 \ --apiserver-advertise-address=192.168.1.16 \ --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \ --service-cidr=10.96.0.0/12 \ --pod-network-cidr=10.244.0.0/16 \ --cri-socket=unix:///var/run/containerd/containerd.sock4.5.2 初始化 k8s 成功的日志输出(master节点展示)Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.1.16:6443 --token 9uln6k.edk5srichppjq6k6 \ --discovery-token-ca-cert-hash sha256:1a4c79509438b84756a5e4e66ee6914835f1235d2a6b4752b2f625366142c9424.5.3 master节点复制k8s认证文件到用户的home目录(master节点执行)mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config4.5.4 启动 kubelet 并设置开机自启(master节点执行)systemctl enable kubelet systemctl start kubelet4.6 node 节点加入集群(两台从节点执行)直接把k8s-master节点初始化之后的最后回显的token复制粘贴到node节点回车即可,无须做任何配置kubeadm join 192.168.1.16:6443 --token 9uln6k.edk5srichppjq6k6 \ --discovery-token-ca-cert-hash sha256:1a4c79509438b84756a5e4e66ee6914835f1235d2a6b4752b2f625366142c942 # 如果加入集群的命令找不到了可以在master节点重新生成一个 kubeadm token create --print-join-command4.7 在master节点查看各个节点的状态(master节点执行)前面已经提到了,在初始化 k8s-master 时并没有网络相关的配置,所以无法跟node节点通信,因此状态都是"Not Ready"。但是通过kubeadm join加入的node节点已经在k8s-master上可以看到。同理,目前 coredns 模块一直处于 Pending 也是正常状态。[root@node1 data]# kubectl get nodes \NAME STATUS ROLES AGE VERSION node1 NotReady control-plane 6m2s v1.28.2 node2 NotReady <none> 2m20s v1.28.2 node3 NotReady <none> 116s v1.28.2[root@node1 data]# kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system coredns-6554b8b87f-chcdt 0/1 Pending 0 6m7s <none> <none> <none> <none> kube-system coredns-6554b8b87f-l9kpk 0/1 Pending 0 6m7s <none> <none> <none> <none> kube-system etcd-node1 1/1 Running 0 6m21s 192.168.1.16 node1 <none> <none> kube-system kube-apiserver-node1 1/1 Running 0 6m21s 192.168.1.16 node1 <none> <none> kube-system kube-controller-manager-node1 1/1 Running 0 6m21s 192.168.1.16 node1 <none> <none> kube-system kube-proxy-8pnkb 1/1 Running 0 6m7s 192.168.1.16 node1 <none> <none> kube-system kube-proxy-hcnq2 0/1 ContainerCreating 0 2m15s 172.24.87.84 node3 <none> <none> kube-system kube-proxy-r5pvx 1/1 Running 0 2m39s 192.168.1.17 node2 <none> <none> kube-system kube-scheduler-node1 1/1 Running 0 6m21s 192.168.1.16 node1 <none> <none>5 部署 flannel 网络插件5.1 下载 flannel 的部署yaml文件wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml文件备份apiVersion: v1 kind: Namespace metadata: labels: k8s-app: flannel pod-security.kubernetes.io/enforce: privileged name: kube-flannel --- apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: flannel name: flannel namespace: kube-flannel --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: flannel name: flannel rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - get - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: flannel name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-flannel --- apiVersion: v1 data: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "EnableNFTables": false, "Backend": { "Type": "vxlan" } } kind: ConfigMap metadata: labels: app: flannel k8s-app: flannel tier: node name: kube-flannel-cfg namespace: kube-flannel --- apiVersion: apps/v1 kind: DaemonSet metadata: labels: app: flannel k8s-app: flannel tier: node name: kube-flannel-ds namespace: kube-flannel spec: selector: matchLabels: app: flannel k8s-app: flannel template: metadata: labels: app: flannel k8s-app: flannel tier: node spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux containers: - args: - --ip-masq - --kube-subnet-mgr command: - /opt/bin/flanneld env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: EVENT_QUEUE_DEPTH value: "5000" image: registry.cn-chengdu.aliyuncs.com/xcce/flannel:v0.26.0 name: kube-flannel resources: requests: cpu: 100m memory: 50Mi securityContext: capabilities: add: - NET_ADMIN - NET_RAW privileged: false volumeMounts: - mountPath: /run/flannel name: run - mountPath: /etc/kube-flannel/ name: flannel-cfg - mountPath: /run/xtables.lock name: xtables-lock hostNetwork: true initContainers: - args: - -f - /flannel - /opt/cni/bin/flannel command: - cp image: registry.cn-chengdu.aliyuncs.com/xcce/flannel-cni-plugin:v1.5.1-flannel2 name: install-cni-plugin volumeMounts: - mountPath: /opt/cni/bin name: cni-plugin - args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist command: - cp image: name: install-cni volumeMounts: - mountPath: /etc/cni/net.d name: cni - mountPath: /etc/kube-flannel/ name: flannel-cfg priorityClassName: system-node-critical serviceAccountName: flannel tolerations: - effect: NoSchedule operator: Exists volumes: - hostPath: path: /run/flannel name: run - hostPath: path: /opt/cni/bin name: cni-plugin - hostPath: path: /etc/cni/net.d name: cni - configMap: name: kube-flannel-cfg name: flannel-cfg - hostPath: path: /run/xtables.lock type: FileOrCreate name: xtables-lock5.2 提前下载镜像ctr images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/flannel-io/flannel:v0.26.5 ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/flannel-io/flannel:v0.26.5 ghcr.io/flannel-io/flannel:v0.26.5 ctr images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/flannel-io/flannel-cni-plugin:v1.6.2-flannel1 ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/flannel-io/flannel-cni-plugin:v1.6.2-flannel1 ghcr.io/flannel-io/flannel-cni-plugin:v1.6.2-flannel15.3 部署网络插件kubectl apply -f kube-flannel.yaml6 从节点支持 kubectl 命令(两台从节点执行)6.1 此时从节点执行 kubectl 命令会报错:(两台从节点执行)- E0709 15:29:19.693750 97386 memcache.go:265\] couldn't get current server API group list: Get "[http://localhost:8080/api?timeout=32s](http://localhost:8080/api?timeout=32s)": dial tcp \[::1\]:8080: connect: connection refused - The connection to the server localhost:8080 was refused - did you specify the right host or port?6.2 分析结果以及解决方法:(两台从节点执行)原因是 kubectl 命令需要使用 kubernetes-admin 来运行将主节点中的 /etc/kubernetes/admin.conf 文件拷贝到从节点相同目录下,然后配置环境变量echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile ## 立即生效 source ~/.bash_profile7. 查看各节点和组件状态[root@node1 data]# kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready control-plane 35m v1.28.2 node2 Ready <none> 31m v1.28.2 node3 Ready <none> 31m v1.28.2 [root@node1 data]# kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel kube-flannel-ds-5ggnx 1/1 Running 0 9m26s 192.168.1.16 node1 <none> <none> kube-flannel kube-flannel-ds-6zln6 1/1 Running 0 9m26s 192.168.1.17 node2 <none> <none> kube-flannel kube-flannel-ds-hqjpx 1/1 Running 0 9m26s 192.168.1.18 node3 <none> <none> kube-system coredns-6554b8b87f-vvn2d 1/1 Running 0 35m 10.244.0.3 node1 <none> <none> kube-system coredns-6554b8b87f-wklf8 1/1 Running 0 35m 10.244.0.2 node1 <none> <none> kube-system etcd-node1 1/1 Running 0 35m 192.168.1.16 node1 <none> <none> kube-system kube-apiserver-node1 1/1 Running 0 35m 192.168.1.16 node1 <none> <none> kube-system kube-controller-manager-node1 1/1 Running 5 35m 192.168.1.16 node1 <none> <none> kube-system kube-proxy-b4jpx 1/1 Running 0 35m 192.168.1.16 node1 <none> <none> kube-system kube-proxy-g7cw2 1/1 Running 0 31m 192.168.1.18 node3 <none> <none> kube-system kube-proxy-sgmcb 1/1 Running 0 31m 192.168.1.17 node2 <none> <none> kube-system kube-scheduler-node1 1/1 Running 5 35m 192.168.1.16 node1 <none> <none> [root@node1 data]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-6554b8b87f-vvn2d 1/1 Running 0 37m coredns-6554b8b87f-wklf8 1/1 Running 0 37m etcd-node1 1/1 Running 0 37m kube-apiserver-node1 1/1 Running 0 37m kube-controller-manager-node1 1/1 Running 5 37m kube-proxy-b4jpx 1/1 Running 0 37m kube-proxy-g7cw2 1/1 Running 0 33m kube-proxy-sgmcb 1/1 Running 0 33m kube-scheduler-node1 1/1 Running 5 37m参考资料最新 Kubernetes 集群部署 + flannel 网络插件(保姆级教程,最新 K8S 版本) - 技术栈安装Containerd | kubernetes-notesContainerd的两种安装方式-腾讯云开发者社区-腾讯云Containerd ctr、crictl客户端命令介绍_containerd crictl-CSDN博客GitHub - flannel-io/flannel: flannel is a network fabric for containers, designed for Kubernetesmodprobe 重启后失效,设置永久有效_服务器_闹玩儿扣眼珠子-K8S/Kubernetes
-
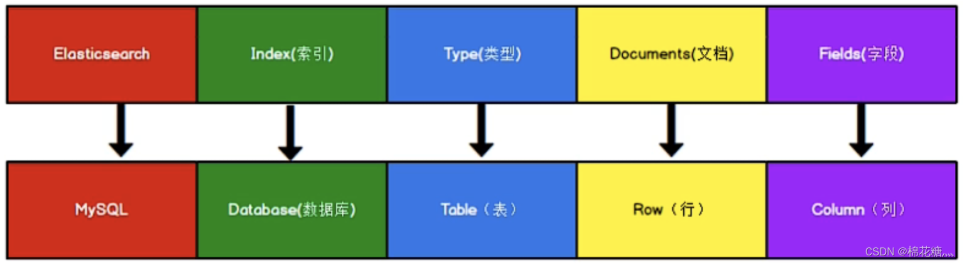
ElasticSearch操作命令学习笔记 一、ES概念1.ES vs MySQL下图是ES和MySQL中一些概念的对应,其中type的概念已经被弱化,在ES 7.X之后被删除。2. index(索引)一个索引就是一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除(CRUD)的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。相当于MySQL中的数据库。3. type(类型)一个索引中可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类/分区,其语义完全由你来定。相当于MySQL中的表。4. document(文档)一个文档是一个可被索引的基础信息单元,也就是一条数据。相当于MySQL中的一条记录。5. field(字段)相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。相当于MySQL中表的字段。6. mapping(映射)mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等。相当于MySQL中的建表过程中设置默认值、主外键、索引等。7. cluster(集群)一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。8. node(节点)一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。9. shard(分片)Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。它允许水平分割/扩展你的内容容量,或者在多个节点上上进行分布式的、并行的操作,进而提高性能/吞吐量。分片很重要,主要有两方面的原因:允许你水平分割扩展你的内容容量允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量10. replicas(副本)Elasticsearch允许你创建分片的一份或多份备份,这些备份叫做复制分片,或者直接叫副本。复制分片之所以重要,有两个主要原因:在分片/节点失败的情况下,提供了高可用性扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行11. allocation(分配)将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由master节点完成的。二、操作类型和操作对象2.1 GET/PUT/POST/DELETEES中主要有GET/PUT/POST/DELETE这四种操作,分别表示查询、更新或创建、创建、删除操作。其中PUT和POST的区别是:PUT在插入新数据的时候需要指定\_id,而POST则不需要,这个\_id是ES中文档的唯一标识。换种说法,PUT是幂等的,即多次执行的结果相同,而POST不是幂等的,多次执行会插入多条数据。2.2 \_mapping/\_settings/\_search/\_count/\_doc\_mapping:映射\_settings:索引设置\_search:查询记录值\_count:查询记录数\_doc:查询文档信息三、常用命令-基于HTTP3.1 索引操作3.1.1 查看ES中所有的索引curl -X GET localhost:9200/_cat/indices?vhealth status index uuid pri rep docs.count docs.deleted store.size pri.store.size dataset.size green open .internal.alerts-transform.health.alerts-default-000001 0jJ5YtamSbu_RMpyZsADWQ 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.logs.alerts-default-000001 8l82KL0aTYSyOixYMIFHUA 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.uptime.alerts-default-000001 mjN3TqVBT26Ucs4e_2T3Vw 1 0 0 0 249b 249b 249b yellow open my-index SfBZ1owlSlKgHmJbrnE01w 1 1 1 0 7.4kb 7.4kb 7.4kb green open .internal.alerts-ml.anomaly-detection.alerts-default-000001 3JuCHDUcRQ-96azpOnCudA 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.slo.alerts-default-000001 pUDfYaqwRUWvPulwpgYEDA 1 0 0 0 249b 249b 249b green open .internal.alerts-default.alerts-default-000001 0qH28FBgSHmQJV_NcHTW2Q 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.apm.alerts-default-000001 M-sFTRA0Sg2wyu_ap01LEQ 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.metrics.alerts-default-000001 5jpzq40eSH2Ff11UG9qdqg 1 0 0 0 249b 249b 249b green open .kibana-observability-ai-assistant-conversations-000001 cOnxLTJkTd2KDD1VH4jtxg 1 0 0 0 249b 249b 249b green open .internal.alerts-ml.anomaly-detection-health.alerts-default-000001 2muiWcoHSr64J67DukLKRA 1 0 0 0 249b 249b 249b green open .internal.alerts-observability.threshold.alerts-default-000001 yagwO-YsRauui9P269MUYg 1 0 0 0 249b 249b 249b green open .internal.alerts-security.alerts-default-000001 q1Hy67EOR6mnn60BDbt0DA 1 0 0 0 249b 249b 249b green open .kibana-observability-ai-assistant-kb-000001 2ZQnm6pkQMOWhBxUZLtIYg 1 0 0 0 249b 249b 249b green open .internal.alerts-stack.alerts-default-000001 yvP_JmetS4iQAjSy8h5dNg 1 0 0 0 249b 249b 249b3.1.2 创建索引简单创建curl -X PUT localhost:9200/test{"acknowledged":true,"shards_acknowledged":true,"index":"test"}创建索引时指定映射curl -X PUT "http://localhost:9200/my_index" -H 'Content-type:application/json' -d ' { "mappings": { "properties": { "title": { "type": "text" }, "price": { "type": "double" }, "published_date": { "type": "date" } } } } '{"acknowledged":true,"shards_acknowledged":true,"index":"my_index"}3.1.3 创建(查看)索引mapping(字段)为索引创建mappingcurl -X PUT "http://localhost:9200/test/_mapping" -H 'Content-type:application/json' -d ' { "properties": { "title": { "type": "text" } } } '查看索引mappingcurl -X GET "http://localhost:9200/test/_mapping"{"test":{"mappings":{"properties":{"title":{"type":"text"}}}}}修改索引mapping如果索引已经创建,也可以单独更新映射。但是需要注意的是,Elasticsearch不允许对已存在字段的类型进行修改(除了某些特殊情况)。curl -X PUT "http://localhost:9200/my_index/_mapping" -H 'Content-type:application/json' -d ' { "properties": { "new_field": { "type": "keyword" } } } '{"acknowledged":true}这里我们向已经存在的my_index索引中添加了一个新的字段new_field,类型为keyword。3.1.4 删除索引删除单个索引curl -X DELETE localhost:9200/test {"acknowledged":true}批量删除索引# 删除多个索引,中间用逗号隔开 curl -XDELETE http://localhost:9200/索引名称1,索引名称2 # 模糊匹配删除 $ curl -XDELETE -u elastic:changeme http://localhost:9200/索引名前缀* # 使用通配符,删除所有索引 二选一都可以 $ curl -XDELETE http://localhost:9200/_all $ curl -XDELETE http://localhost:9200/* # _all ,* 通配所有的索引,通常不建议使用通配符,误删了后果就很严重了,所有的index都被删除了,禁止通配符为了安全起见,可以在elasticsearch.yml配置文件中设置禁用_all和*通配符 `action.destructive_requires_name = true`这样就不能使用_all和*了!3.1.5 查看指定索引信息?pertty 表示让数据格式化,更好的展示curl -X GET localhost:9200/test?pretty{ "test" : { "aliases" : { }, "mappings" : { "properties" : { "title" : { "type" : "text" } } }, "settings" : { "index" : { "routing" : { "allocation" : { "include" : { "_tier_preference" : "data_content" } } }, "number_of_shards" : "1", "provided_name" : "test", "creation_date" : "1734017722530", "number_of_replicas" : "1", "uuid" : "tXo4Z_edQ1eRwkuzmWY33A", "version" : { "created" : "8505000" } } } } } 3.2 文档操作3.2.1 新增文档新增文档,并指定id字段(replace) curl -X PUT localhost:9200/test_index/_doc/1 -H 'Content-type:application/json' -d '{"name":"Jupiter","age":18}'{"_index":"test_index","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}[新增文档,并指定ID字段(insert)该模式下,若指定id对应的文档存在,则直接返回报错 curl -X PUT localhost:9200/test_index/_create/1 -H 'Content-type:application/json' -d '{"name":"Jupiter","age":18}'{"error":{"root_cause":[{"type":"version_conflict_engine_exception","reason":"[1]: version conflict, document already exists (current version [1])","index_uuid":"uxEK6rUiQIKRz4B48xvitQ","shard":"0","index":"test_index"}],"type":"version_conflict_engine_exception","reason":"[1]: version conflict, document already exists (current version [1])","index_uuid":"uxEK6rUiQIKRz4B48xvitQ","shard":"0","index":"test_index"},"status":409}[新增文档,不指定ID字段,系统自动生产ID curl -X POST localhost:9200/test_index/_doc -H 'Content-type:application/json' -d '{"name":"aaa","age":13}'{"_index":"test_index","_id":"m_6du5MBv8SIaajvQ-b4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1}[3.2.2 更新文档更新指定ID文档,存在则更新,不存在则新增(也是新增文档的一种) curl -X PUT localhost:9200/test_index/_doc/2 -H 'Content-type:application/json' -d '{"name":"bbb","age":18}'# curl -X GET localhost:9200/test_index/_doc/2?pretty { "_index" : "test_index", "_id" : "2", "_version" : 1, "_seq_no" : 2, "_primary_term" : 1, "found" : true, "_source" : { "name" : "bbb", "age" : 18 }更新指定ID文档,更新文档必须存在,否则报错 curl -X PUT localhost:9200/test_index/_doc/2 -H 'Content-type:application/json' -d '{"name":"ccc","age":18}'# curl -X GET localhost:9200/test_index/_doc/2?pretty { "_index" : "test_index", "_id" : "2", "_version" : 2, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "name" : "ccc", "age" : 18 } }3.2.3 删除文档删除指定ID文档curl -X DELETE localhost:9200/test_index/_doc/2# curl -X GET localhost:9200/test_index/_doc/2?pretty { "_index" : "test_index", "_id" : "2", "found" : false }删除满足条件查询文档 curl -X POST localhost:9200/test_index/_delete_by_query -H 'Content-type:application/json' -d '{ "query":{ "match":{ "name":"ccc" } } }'{"took":9,"timed_out":false,"total":1,"deleted":1,"batches":1,"version_conflicts":0,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1.0,"throttled_until_millis":0,"failures":[]}3.2.4 查询文档查询指定ID文档curl -X GET localhost:9200/test_index/_doc/1{"_index":"test_index","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"name":"Jupiter","age":18}}search api查询满足条件的文档curl -X GET localhost:9200/test_index/_search -H 'Content-type:application/json' -d '{ "query": { "match": { "age": "18" } } }'{"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":2,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"test_index","_id":"1","_score":1.0,"_source":{"name":"Jupiter","age":18}},{"_index":"test_index","_id":"2","_score":1.0,"_source":{"name":"bbb","age":18}}]}}[查询所有文档curl -X GET localhost:9200/users/_search?pretty -H 'Content-type:application/json' -d '{ "query": { "match_all": {} } }'3.2.5 bulk apibulk是es提供的一种批量增删改的操作API。bulk的操作类型:create 如果文档不存在就创建,但如果文档存在就返回错误index 如果文档不存在就创建,如果文档存在就更新update 更新一个文档,如果文档不存在就返回错误delete 删除一个文档,如果要删除的文档id不存在,就返回错误bulk的操作,某一个操作失败,是不会影响其他文档的操作的,它会在返回结果中告诉你失败的详细的原因。curl -X POST localhost:9200/_bulk -H 'Content-type:application/json' -d ' {"index":{"_index":"users","_id":"1"}} {"name":"aa"} {"create":{"_index":"users","_id":"2"}} {"name":"bb"} {"delete":{"_index":"users","_id":"2"}} {"update":{"_index":"users","_id":"1"}} {"doc":{"auto_inc":"11"}} 'curl -X GET localhost:9200/users/_search?pretty -H 'Content-type:application/json' -d '{ "query": { "match_all": {} } }'{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "users", "_id" : "2", "_score" : 1.0, "_source" : { "name" : "bb" } }, { "_index" : "users", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "aa", "auto_inc" : "11" } } ] } } 参考资料【学习笔记】ElasticSearch(ES)基本概念和语句学习笔记_es 建表-CSDN博客Elasticsearch(ES)常用命令整理_elasticsearch常用命令-CSDN博客ES命令行操作 - 吕振江 - 博客园如何在 Elasticsearch 中创建索引和映射?_es创建索引命令-CSDN博客Elasticsearch(037):es中批量操作之bulk_es bulk-CSDN博客elasticsearch bulk批量增删改(超详细)-CSDN博客