


一.整理结构概览
1.数据格式转换部分
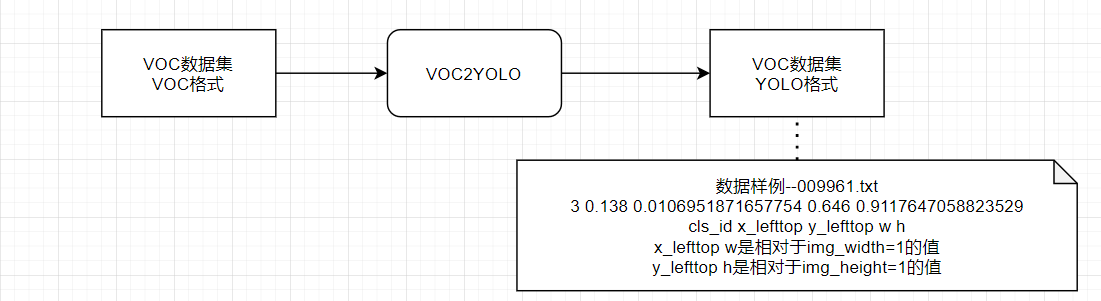
2.DataSet,DateLoader部分
2.1 主模块
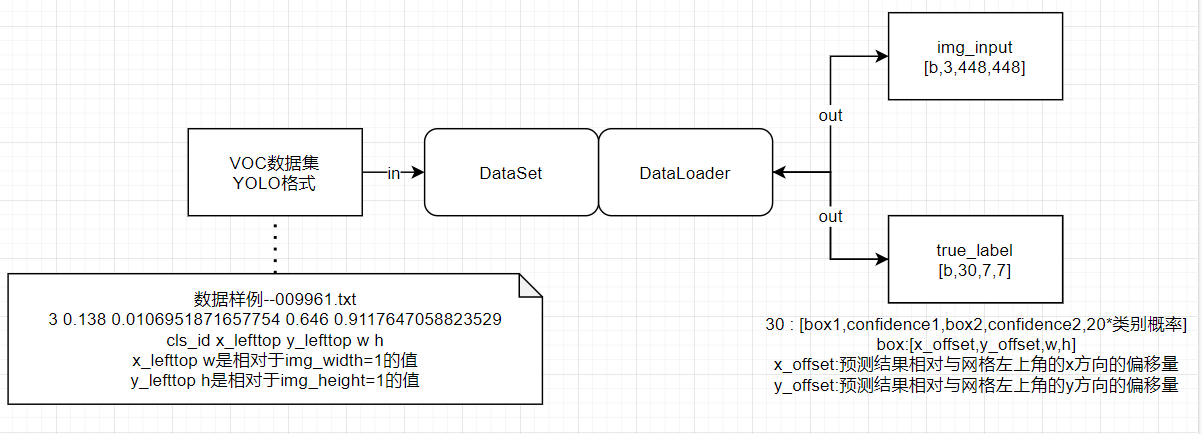
2.2 DataSet辅助模块--boxs2yololabel
将单个图片中yolo格式的所有box转为yolov1网络模型所需要的label
3.YOLOv1网络部分
4.YOLOv1损失函数部分
二.对每部分逐一进行实现
1.数据格式转换部分--VOC2YOLO.py
模块封装
import xmltodict
import os
from progressbar import *
"""
将单个xml文件中的单个object转换为yolov1格式
"""
def get_yolo_data(obj,img_width,img_height):
# 获取voc格式的数据信息
name = obj['name']
xmin = float(obj['bndbox']['xmin'])
xmax = float(obj['bndbox']['xmax'])
ymin = float(obj['bndbox']['ymin'])
ymax = float(obj['bndbox']['ymax'])
# 计算对应的yolo格式的数据信息,并进行归一化处理
class_idx = class_names.index(name)
x_lefttop = xmin / img_width
y_lefttop = ymin / img_height
box_width = (xmax - xmin) / img_width
box_height = (ymax - ymin) / img_height
# 组转YOLO格式的数据
yolo_data = "{} {} {} {} {}\n".format(class_idx,x_lefttop,y_lefttop,box_width,box_height)
return yolo_data
"""
逐一处理xml文件,转换为YOLO所需的格式
+ input
+ voc_xml_dir:VOC数据集的所有xml文件存储的文件夹
+ yolo_txt_dir:转化完成后的YOLOv1格式数据的存储文件夹
+ class_names:涉及的所有的类别
+ output
+ yolo_txt_dir文件夹下的文件中的对应每张图片的YOLO格式的数据
"""
def VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names):
#进度条支持
count = 0 #计数器
widgets = ['VOC2YOLO: ',Percentage(), ' ', Bar('#'),' ', Timer(),' ', ETA()]
pbar = ProgressBar(widgets=widgets, maxval=len(os.listdir(xml_dir))).start()
# 对xml文件进行逐一处理
for xml_file in os.listdir(xml_dir):
# 路径组装
xml_file_path = os.path.join(xml_dir,xml_file)
txt_file_path = os.path.join(txt_dir,xml_file[:-4]+".txt")
yolo_data = ""
# 读取xml文件
with open(xml_file_path) as f:
xml_str = f.read()
# 转为字典
xml_dic = xmltodict.parse(xml_str)
# 获取图片的width、height
img_width = float(xml_dic["annotation"]["size"]["width"])
img_height = float(xml_dic["annotation"]["size"]["height"])
# 获取xml文件中的所有object
objects = xml_dic["annotation"]["object"]
# 对所有的object进行逐一处理
if isinstance(objects,list): # xml文件中包含多个object
for obj in objects:
yolo_data += get_yolo_data(obj,img_width,img_height)
else: # xml文件中包含1个object
obj = objects
yolo_data += get_yolo_data(obj,img_width,img_height)
# 将图片对应的yolo格式的数据写入到对应的文件
with open(txt_file_path,'w') as f:
f.write(yolo_data)
#更新进度
count += 1
pbar.update(count)
pbar.finish() # 释放进度条调用测试
voc_xml_dir='../VOC2007/Annotations/' #原xml路径
yolo_txt_dir='../VOC2007/labels/' #转换后txt文件存放路径
# 所有待检测的labels
class_names = ['aeroplane', 'cat', 'car', 'dog', 'chair', 'person', 'horse', 'bird',
'tvmonitor', 'bus', 'boat', 'diningtable', 'bicycle', 'bottle', 'sofa',
'pottedplant', 'motorbike', 'cow', 'train', 'sheep']
VOC2YOLOv1(voc_xml_dir,yolo_txt_dir,class_names)VOC2YOLO: 100% |##########################| Elapsed Time: 0:01:18 Time: 0:01:182.DataSet,DateLoader部分
模块封装
from torch.utils.data import Dataset,DataLoader
from PIL import Image
"""
构建YOLOv1的dataset,用于加载VOC数据集(已对其进行了YOLO格式转换)
+ input
+ mode:调用模式,train/val
+ DATASET_PATH:VOC数据集的根目录,已对其进行了YOLO格式转换
+ yolo_input_size:训练和测试所用的图片大小,通常为448
"""
class Dataset_VOC(Dataset):
def __init__(self,mode = "train",DATASET_PATH = "../VOC2007/",yolo_input_size = 448):
self.filenames = [] # 储存数据集的文件名称
# 获取数据集的文件夹列表
if mode == "train":
with open(DATASET_PATH + "ImageSets/Main/train.txt", 'r') as f: # 调用包含训练集图像名称的txt文件
self.filenames = [x.strip() for x in f]
elif mode =='val':
with open(DATASET_PATH + "ImageSets/Main/val.txt", 'r') as f: # 调用包含训练集图像名称的txt文件
self.filenames = [x.strip() for x in f]
# 图像文件所在的文件夹
self.img_dir = os.path.join(DATASET_PATH,"JPEGImages")
# 图像对应的label文件(.txt文件)的文件夹
self.label_dir = os.path.join(DATASET_PATH,"labels")
def boxs2yololabel(self,boxs):
"""
将boxs数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num)
单个box数据格式:(cls,x_rela_width,y_rela_height,w_rela_width,h_rela_height)
x_rela_width:相对width=1的x的取值
"""
gridsize = 1.0/7 # 网格大小
# 初始化result,此处需要根据不同数据集的类别个数进行修改
label = np.zeros((7,7,30))
# 根据box的数据填充label
for i in range(len(boxs)//5):
# 计算当前box会位于哪个网格
gridx = int(boxs[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列
gridy = int(boxs[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行
# 计算box相对于网格的左上角的点的相对位置
# box中心坐标 - 网格左上角点的坐标)/网格大小 ==> box中心点的相对位置
x_offset = boxs[i*5+1] / gridsize - gridx
y_offset = boxs[i*5+2] / gridsize - gridy
# 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1
label[gridy, gridx, 0:5] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1])
label[gridy, gridx, 5:10] = np.array([x_offset, y_offset, boxs[i*5+3], boxs[i*5+4], 1])
label[gridy, gridx, 10+int(boxs[i*5])] = 1
return label
def __len__(self):
return len(self.filenames)
def __getitem__(self, index):
# 构建image部分
# 读取图片
img_path = os.path.join(self.img_dir,self.filenames[index]+".jpg")
img = cv2.imread(img_path)
# 计算padding值将图像padding为正方形
h,w = img.shape[0:2]
padw,padh = 0,0
if h>w:
padw = (h - w) // 2
img = np.pad(img,((0,0),(padw,padw),(0,0)),'constant',constant_values=0)
elif w>h:
padh = (w - h) // 2
img = np.pad(img,((padh,padh),(0,0),(0,0)), 'constant', constant_values=0)
# 然后resize为yolo网络所需要的尺寸448x448
yolo_input_size = 448 # 输入YOLOv1网络的图像尺寸为448x448
img = cv2.resize(img,(yolo_input_size,yolo_input_size))
# 构建label部分
# 读取图像对应的box信息,按1维的方式储存,每5个元素表示一个bbox的(cls_id,x_lefttop,y_lefttop,w,h)
label_path = os.path.join(self.label_dir,self.filenames[index]+".txt")
with open(label_path) as f:
boxs = f.read().split('\n')
boxs = [x.split() for x in boxs]
boxs = [float(x) for y in boxs for x in y]
# 根据padding、图像增广等操作,将原始的box数据转换为修改后图像的box数据
for i in range(len(boxs)//5):
if padw != 0:
boxs[i*5+1] = (boxs[i*5+1] * w + padw) / h
boxs[i*5+3] = (boxs[i*5+3] * w) / h
elif padh != 0:
boxs[i*5+2] = (boxs[i*5+2] * h + padh) / w
boxs[i*5+4] = (boxs[i*5+4] * h) / w
# boxs转为yololabel
label = self.boxs2yololabel(boxs)
# img,label转为tensor
img = transforms.ToTensor()(img)
label = transforms.ToTensor()(label)
return img,label调用测试
train_dataset = Dataset_VOC(mode="train")
val_dataset = Dataset_VOC(mode="val")
train_dataloader = DataLoader(train_dataset,batch_size=2,shuffle=True)
val_dataloader = DataLoader(val_dataset,batch_size=2,shuffle=True)
for i,(inputs,labels) in enumerate(train_dataloader):
print(inputs.shape,labels.shape)
break
for i,(inputs,labels) in enumerate(val_dataloader):
print(inputs.shape,labels.shape)
breaktorch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7])
torch.Size([2, 3, 448, 448]) torch.Size([2, 30, 7, 7])3.YOLOv1网络部分
网络结构

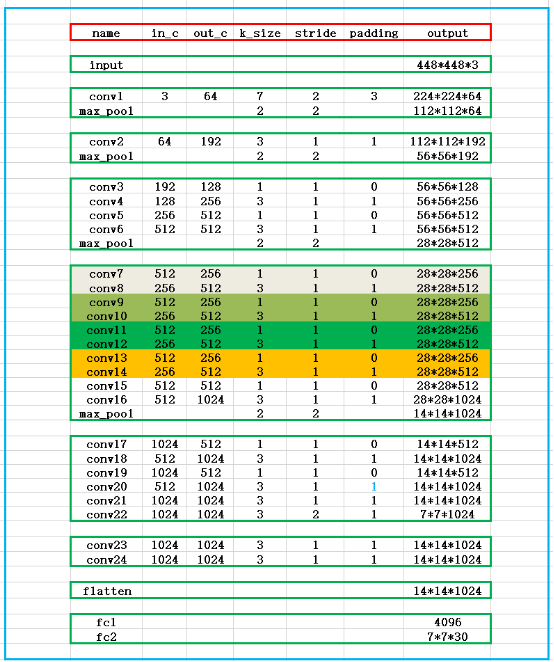
模块封装
import torch
import torch.nn as nn
class YOLOv1(nn.Module):
def __init__(self):
super(YOLOv1,self).__init__()
self.feature = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.LeakyReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=64,out_channels=192,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=192,out_channels=128,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=1,stride=1,padding=0),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=2,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
)
self.classify = nn.Sequential(
nn.Flatten(),
nn.Linear(1024 * 7 * 7, 4096),
nn.Dropout(0.5),
nn.Linear(4096, 1470) #1470=7*7*30
)
def forward(self,x):
x = self.feature(x)
x = self.classify(x)
return x调用测试
yolov1 = YOLOv1()
fake_input = torch.zeros((1,3,448,448))
print(fake_input.shape)
output = yolov1(fake_input)
print(output.shape)yolov1 = YOLOv1()
fake_input = torch.zeros((1,3,448,448))
print(fake_input.shape)
output = yolov1(fake_input)
print(output.shape)4.YOLOv1损失函数部分
损失函数详解
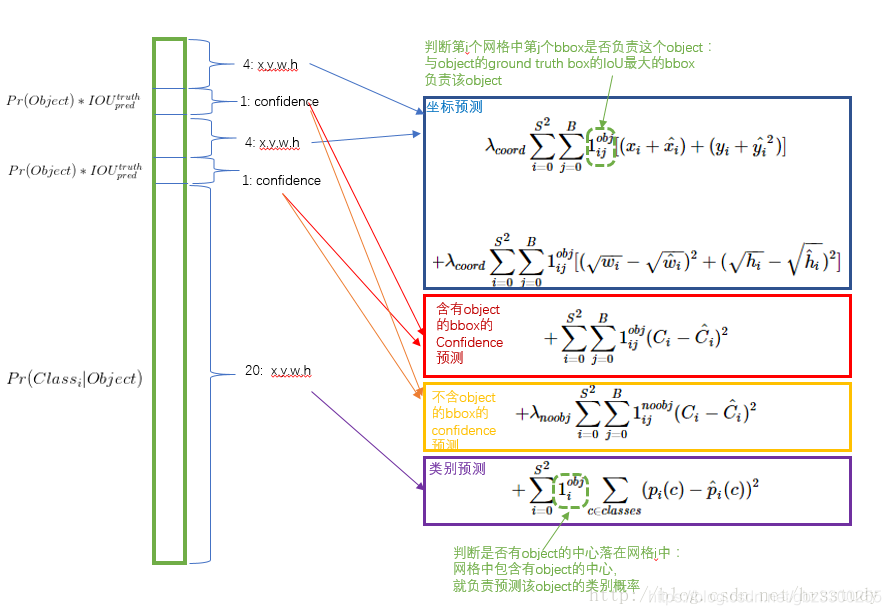
模块封装
"""
+ input
+ pred: (batch_size,30,7,7)的网络输出数据
+ labels: (batch_size,30,7,7)的样本标签数据
+ output
+ 当前批次样本的平均损失
"""
"""
+ YOLOv1 的损失分为3部分
+ 坐标预测损失
+ 置信度预测损失
+ 含object的box的confidence预测损失
+ 不含object的box的confidence预测损失
+ 类别预测损失
"""
class YOLOv1_Loss(nn.Module):
def __init__(self):
super(YOLOv1_Loss,self).__init__()
def convert_box_type(self,src_box):
"""
box格式转换
+ input
+ src_box : [box_x_lefttop,box_y_lefttop,box_w,box_h]
+ output
+ dst_box : [box_x1,box_y1,box_x2,box_y2]
"""
x,y,w,h = tuple(src_box)
x1,y1 = x,y
x2,y2 = x+w,y+w
return [x1,y1,x2,y2]
def cal_iou(self,box1,box2):
"""
iou计算
"""
# 求相交区域左上角的坐标和右下角的坐标
box_intersect_x1 = max(box1[0], box2[0])
box_intersect_y1 = max(box1[1], box2[1])
box_intersect_x2 = min(box1[2], box2[2])
box_intersect_y2 = min(box1[3], box2[3])
# 求二者相交的面积
area_intersect = (box_intersect_y2 - box_intersect_y1) * (box_intersect_x2 - box_intersect_x1)
# 求box1,box2的面积
area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
# 求二者相并的面积
area_union = area_box1 + area_box2 - area_intersect
# 计算iou(交并比)
iou = area_intersect / area_union
return iou
def forward(self,pred,target):
batch_size = pred.shape[0]
lambda_noobj = 0.5 # lambda_noobj参数
lambda_coord = 5 # lambda_coord参数
site_pred_loss = 0 # 坐标预测损失
obj_confidence_pred_loss = 0 # 含object的box的confidence预测损失
noobj_confidence_pred_loss = 0 #不含object的box的confidence预测损失
class_pred_loss = 0 # 类别预测损失
for batch_size_index in range(batch_size): # batchsize循环
for x_index in range(7): # x方向网格循环
for y_index in range(7): # y方向网格循环
# 获取单个网格的预测数据和真实数据
pred_data = pred[batch_size_index,:,x_index,y_index] # [x,y,w,h,confidence,x,y,w,h,confidence,cls*20]
true_data = target[batch_size_index,:,x_index,y_index] #[x,y,w,h,confidence,x,y,w,h,confidence,cls*20]
if true_data[4]==1:# 如果包含物体
# 解析预测数据和真实数据
pred_box_confidence_1 = pred_data[0:5] # [x,y,w,h,confidence1]
pred_box_confidence_2 = pred_data[5:10] # [x,y,w,h,confidence2]
true_box_confidence = true_data[0:5] # [x,y,w,h,confidence]
# 获取两个预测box并计算与真实box的iou
iou1 = self.cal_iou(self.convert_box_type(pred_box_confidence_1[0:4]),self.convert_box_type(true_box_confidence[0:4]))
iou2 = self.cal_iou(self.convert_box_type(pred_box_confidence_2[0:4]),self.convert_box_type(true_box_confidence[0:4]))
# 在两个box中选择iou大的box负责预测物体
if iou1 >= iou2:
better_box_confidence,bad_box_confidence = pred_box_confidence_1,pred_box_confidence_2
better_iou,bad_iou = iou1,iou2
else:
better_box_confidence,bad_box_confidence = pred_box_confidence_2,pred_box_confidence_1
better_iou,bad_iou = iou2,iou1
# 计算坐标预测损失
site_pred_loss += lambda_coord * torch.sum((better_box_confidence[0:2]- true_box_confidence[0:2])**2) # x,y的预测损失
site_pred_loss += lambda_coord * torch.sum((better_box_confidence[2:4].sqrt()-true_box_confidence[2:4].sqrt())**2) # w,h的预测损失
# 计算含object的box的confidence预测损失
obj_confidence_pred_loss += (better_box_confidence[4] - better_iou)**2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中
# 因此还需计算不含object的box的confidence预测损失
noobj_confidence_pred_loss += lambda_noobj * (bad_box_confidence[4] - bad_iou)**2
# 计算类别损失
class_pred_loss += torch.sum((pred_data[10:] - true_data[10:])**2)
else: # 如果不包含物体,则只有置信度损失--noobj_confidence_pred_loss
# [4,9]代表取两个预测框的confidence
noobj_confidence_pred_loss += lambda_noobj * torch.sum(pred[batch_size_index,(4,9),x_index,y_index]**2)
loss = site_pred_loss + obj_confidence_pred_loss + noobj_confidence_pred_loss + class_pred_loss
return loss/batch_size调用测试
loss = YOLOv1_Loss()
label1 = torch.zeros([1,30,7,7])
label2 = torch.zeros([1,30,7,7])
print(label1.shape,label2.shape)
print(loss(label1,label2))
loss = YOLOv1_Loss()
label1 = torch.randn([8,30,7,7])
label2 = torch.randn([8,30,7,7])
print(label1.shape,label2.shape)
print(loss(label1,label2))torch.Size([1, 30, 7, 7]) torch.Size([1, 30, 7, 7])
tensor(0.)
torch.Size([8, 30, 7, 7]) torch.Size([8, 30, 7, 7])
tensor(46.7713)三.整体封装测试
#TODO
评论 (0)