1.backbone-restnet50
import math
import torch.nn as nn
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
#-----------------------------------#
# 假设输入进来的图片是600,600,3
#-----------------------------------#
self.inplanes = 64
super(ResNet, self).__init__()
# 600,600,3 -> 300,300,64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 300,300,64 -> 150,150,64
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True)
# 150,150,64 -> 150,150,256
self.layer1 = self._make_layer(block, 64, layers[0])
# 150,150,256 -> 75,75,512
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
# 75,75,512 -> 38,38,1024 到这里可以获得一个38,38,1024的共享特征层
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
# self.layer4被用在classifier模型中
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
#-------------------------------------------------------------------#
# 当模型需要进行高和宽的压缩的时候,就需要用到残差边的downsample
#-------------------------------------------------------------------#
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50():
model = ResNet(Bottleneck, [3, 4, 6, 3])
#----------------------------------------------------------------------------#
# 获取特征提取部分,从conv1到model.layer3,最终获得一个38,38,1024的特征层
#----------------------------------------------------------------------------#
features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3])
#----------------------------------------------------------------------------#
# 获取分类部分,从model.layer4到model.avgpool
#----------------------------------------------------------------------------#
classifier = list([model.layer4, model.avgpool])
features = nn.Sequential(*features)
classifier = nn.Sequential(*classifier)
return features, classifier
extractor,classifier = resnet50()
print(extractor)
Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(5): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(6): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
2.RPN
import numpy as np
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32)
for i in range(len(ratios)):
for j in range(len(anchor_scales)):
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
anchor_base[index, 0] = - h / 2.
anchor_base[index, 1] = - w / 2.
anchor_base[index, 2] = h / 2.
anchor_base[index, 3] = w / 2.
return anchor_base
# 产生特征图上每个点对应的9个base anchor
def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width):
# 计算网格中心点
shift_x = np.arange(0, width * feat_stride, feat_stride)
shift_y = np.arange(0, height * feat_stride, feat_stride)
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shift = np.stack((shift_x.ravel(),shift_y.ravel(),
shift_x.ravel(),shift_y.ravel(),), axis=1)
# 每个网格点上的9个先验框
A = anchor_base.shape[0]
K = shift.shape[0]
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((K, 1, 4))
# 所有的先验框
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
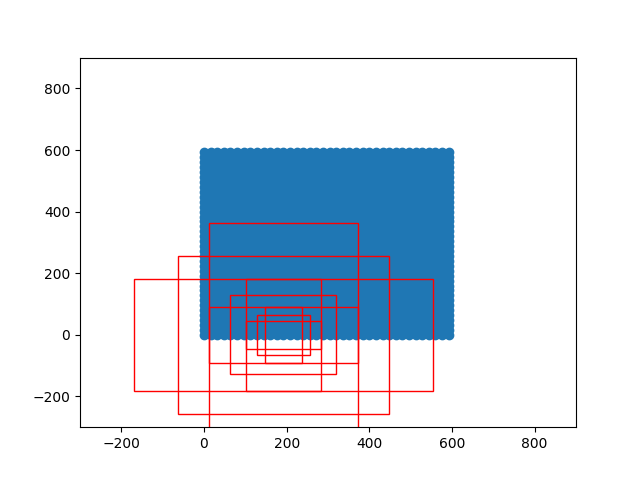
import matplotlib.pyplot as plt
nine_anchors = generate_anchor_base() # 产生特征图上每个点对应的9个base anchor
height, width, feat_stride = 38,38,16 # 特征图的shape feature_map_w,feature_map_h,feature_map_c = 38,38,16
# 生成整个特征图对应的所有的base anchor ,总计feature_map_w*feature_map_h*9个
anchors_all = _enumerate_shifted_anchor(nine_anchors,feat_stride,height,width)
print(np.shape(anchors_all))
fig = plt.figure()
ax = fig.add_subplot(111)
plt.ylim(-300,900)
plt.xlim(-300,900)
# 模拟绘制特征提取之前的原图
shift_x = np.arange(0, width * feat_stride, feat_stride)
shift_y = np.arange(0, height * feat_stride, feat_stride)
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
plt.scatter(shift_x,shift_y)
# 绘制特征图上像素点(pix_x,pix_y)对应原图的所有anchor
pix_x,pix_y = 12,0
index_begin = pix_y*width*9 + pix_x*9
index_end = pix_y*width*9 + pix_x*9 + 9
print(index_begin)
box_widths = anchors_all[:,2]-anchors_all[:,0]
box_heights = anchors_all[:,3]-anchors_all[:,1]
for i in range(index_begin,index_end):
rect = plt.Rectangle([anchors_all[i, 0],anchors_all[i, 1]],box_widths[i],box_heights[i],color="r",fill=False)
ax.add_patch(rect)
plt.show()
# 将RPN网络预测结果转化成建议框
def loc2bbox(src_bbox, loc):
if src_bbox.size()[0] == 0:
return torch.zeros((0, 4), dtype=loc.dtype)
src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1)
src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1)
src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width
src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height
dx = loc[:, 0::4]
dy = loc[:, 1::4]
dw = loc[:, 2::4]
dh = loc[:, 3::4]
ctr_x = dx * src_width + src_ctr_x
ctr_y = dy * src_height + src_ctr_y
w = torch.exp(dw) * src_width
h = torch.exp(dh) * src_height
dst_bbox = torch.zeros_like(loc)
dst_bbox[:, 0::4] = ctr_x - 0.5 * w
dst_bbox[:, 1::4] = ctr_y - 0.5 * h
dst_bbox[:, 2::4] = ctr_x + 0.5 * w
dst_bbox[:, 3::4] = ctr_y + 0.5 * h
return dst_bbox
class ProposalCreator():
def __init__(self, mode, nms_thresh=0.7,
n_train_pre_nms=12000,
n_train_post_nms=600,
n_test_pre_nms=3000,
n_test_post_nms=300,
min_size=16):
self.mode = mode
self.nms_thresh = nms_thresh
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
def __call__(self, loc, score,
anchor, img_size, scale=1.):
if self.mode == "training":
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
anchor = torch.from_numpy(anchor)
if loc.is_cuda:
anchor = anchor.cuda()
#-----------------------------------#
# 将RPN网络预测结果转化成建议框
#-----------------------------------#
roi = loc2bbox(anchor, loc)
#-----------------------------------#
# 防止建议框超出图像边缘
#-----------------------------------#
roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1])
roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0])
#-----------------------------------#
# 建议框的宽高的最小值不可以小于16
#-----------------------------------#
min_size = self.min_size * scale
keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0]
roi = roi[keep, :]
score = score[keep]
#-----------------------------------#
# 根据得分进行排序,取出建议框
#-----------------------------------#
order = torch.argsort(score, descending=True)
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
#-----------------------------------#
# 对建议框进行非极大抑制
#-----------------------------------#
keep = nms(roi, score, self.nms_thresh)
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
3.合并backbone与rpn--记为FRCNN_RPN
class FRCNN_RPN(nn.Module):
def __init__(self,extractor,rpn):
super(FRCNN_RPN, self).__init__()
self.extractor = extractor
self.rpn = rpn
def forward(self, x, img_size):
print(img_size)
feature_map = self.extractor(x)
rpn_locs, rpn_scores, rois, roi_indices, anchor = self.rpn(feature_map,img_size)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
# 加载模型参数
param = torch.load("./frcnn-restnet50.pth")
param.keys()
rpn = RegionProposalNetwork(in_channels=1024,mode="predict")
frcnn_rpn = FRCNN_RPN(extractor,rpn)
frcnn_rpn_state_dict = frcnn_rpn.state_dict()
for key in frcnn_rpn_state_dict.keys():
frcnn_rpn_state_dict[key] = param[key]
frcnn_rpn.load_state_dict(frcnn_rpn_state_dict)
from PIL import Image
import copy
def get_new_img_size(width, height, img_min_side=600):
if width <= height:
f = float(img_min_side) / width
resized_height = int(f * height)
resized_width = int(img_min_side)
else:
f = float(img_min_side) / height
resized_width = int(f * width)
resized_height = int(img_min_side)
return resized_width, resized_height
img_path = os.path.join("xx.jpg")
image = Image.open(img_path)
image = image.convert("RGB") # 转换成RGB图片,可以用于灰度图预测。
image_shape = np.array(np.shape(image)[0:2])
old_width, old_height = image_shape[1], image_shape[0]
old_image = copy.deepcopy(image)
# 给原图像进行resize,resize到短边为600的大小上
width,height = get_new_img_size(old_width, old_height)
image = image.resize([width,height], Image.BICUBIC)
print(image.size)
# 图片预处理,归一化。
photo = np.transpose(np.array(image,dtype = np.float32)/255, (2, 0, 1))
with torch.no_grad():
images = torch.from_numpy(np.asarray([photo]))
rpn_locs, rpn_scores, rois, roi_indices, anchor = frcnn_rpn(images,[height,width])
fig = plt.figure(dpi=200)
ax = fig.add_subplot(111)
ax.imshow(image)
# 绘制RPN的结果
for i in range(rois.shape[0]):
x1,y1,x2,y2 = rois[i]
w,h = x2-x1,y2-y1
rect = plt.Rectangle([x1,y1],w,h,color="r",fill=False)
ax.add_patch(rect)
plt.xticks([])
plt.yticks([])
plt.show()
print(anchor.shape)
print(rois.shape)



评论 (0)